Обучение мозга методом вознаграждения
В основе TD-Gammon лежит метод временной разности, который был вдохновлен обучающими экспериментами с животными. Почти все виды, которые были протестированы, от пчел до людей, способны к ассоциативному обучению, как собака Павлова. В эксперименте Павлова после сенсорного раздражителя – звука колокольчика – собаке давали еду, что вызывало у той слюноотделение. После нескольких тренировок звон колокольчика сам по себе стал приводить к образованию слюны. У разных видов разные предпочтительные безусловные стимулы. Пчелы очень хорошо ассоциируют запах, цвет и форму цветка с полезным нектаром и используют эту выученную связь, чтобы искать похожие цветы. Что-то в этой универсальной форме обучения было важным, и в 1960-х годах психологи интенсивно изучали условия, которые привели к появлению ассоциативного обучения, и разрабатывали модели для его объяснения. Бихевиористы, такие как Беррес Фредерик Скиннер, обучили голубей распознавать людей на фотографиях. Похоже на то, что можно сделать с помощью глубокого обучения, но есть большая разница: обучение с использованием метода обратного распространения ошибки требует подробной обратной связи со всеми единицами выходного слоя, но ассоциативное обучение дает только один сигнал вознаграждения – правильно или неправильно.
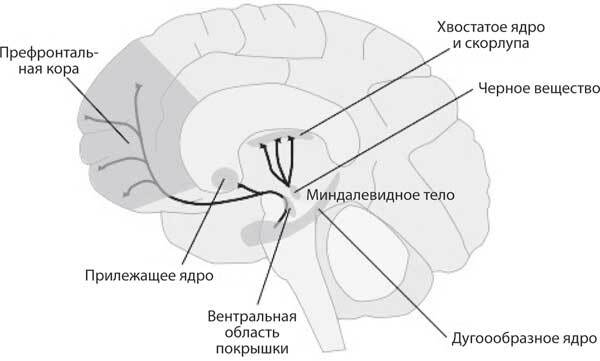
Рис. 10.4. Дофаминовые нейроны в человеческом мозге. Несколько ядер среднего мозга (овальные области, заполненные точками) проецируют аксоны в кору и базальные ганглии (подкорковые ядра). Временные всплески означают расхождения между ожидаемым и полученным вознаграждением, которые используются для выбора действий и изменения прогнозов
Только стимул, возникающий непосредственно перед вознаграждением, ассоциируется с вознаграждением. Это имеет смысл, потому что стимул с большей вероятностью вызвал вознаграждение, если он предшествовал вознаграждению, а не шел после него. Причинно-следственная связь – важный закон природы. Обратное происходит, когда условный стимул сопровождается наказанием, например ударом ноги, и животное учится избегать раздражителя. В некоторых случаях разрыв между условным стимулом и наказанием может быть довольно большим. В 1950-х годах Джон Гарсия показал, что, если крысу кормить подслащенной водой и затем через несколько часов вызывать рвоту, крыса начинает избегать подслащенной воды в последующие дни. Это называется условное отвращение ко вкусу, и у людей оно работает так же. Например, порой болезнь может ассоциироваться с неудачным приемом пищи, например с шоколадом, который съели в то время. Возникающее в результате отвращение может сохраняться годами, даже если умом вы понимаете, что проблема не в шоколаде.
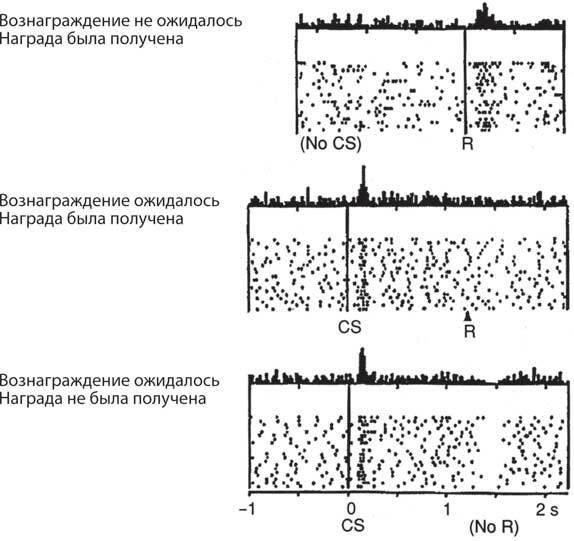
Рис. 10.5. Ответ дофаминового нейрона в мозге обезьяны, подтверждающий, что он сигнализирует об ошибке предсказания вознаграждения остальной части мозга. Каждая точка – всплеск в дофаминовых нейронах. Каждая строка – одна попытка обучения. Количество пиков в каждой временной ячейке отображается в верхней части каждого растра. Верхнее изображение: в начале обучения награда неожиданная, и дофамин раз за разом запускает всплеск импульсов вскоре после награды. Среднее изображение: после многих попыток, когда свет (CS) неоднократно мигает перед получением вознаграждения, клетка дофамина реагирует на свет, но не на вознаграждение. Согласно временной разнице в обучении, ответ после награды отменяется предсказанием награды. Нижнее изображение: когда в качестве эксперимента вознаграждение было удержано, обнаружилось падение активности в ожидании награды
Дофамин, нейромодулятор, содержащий набор диффузно проецирующихся нейронов в стволе мозга (рис. 10.4), уже давно ассоциировался с обучением методом вознаграждения, но не было известно, что за сигналы они передают в коре. Питер Даян и Рид Монтегю, будучи постдокторантами в моей лаборатории в 1990-х годах, поняли, что дофаминовые нейроны могут реализовать обучение с учетом временной разницы. Эти модели и их предсказания были опубликованы в один из самых захватывающих научных периодов моей жизни и впоследствии подтверждены на обезьянах Вольфрамом Шульцом, сделавшим запись единичных нейронов, и на людях с помощью визуализации мозга (рис. 10.5). В настоящее время установлено, что переходные изменения в активности дофаминовых нейронов сигнализируют об ошибке прогнозирования вознаграждения.
Мы добились прогресса в исследовании ошибки предсказания вознаграждения у приматов, когда в 1992 году я посетил в Берлине Рандольфа Менцеля, изучавшего быстрое обучение в мозге пчелы. Пчелы – лучшие ученики в мире насекомых. Пчеле нужно всего несколько раз посетить необходимый цветок, чтобы запомнить его. В мозге пчелы около миллиона крошечных нейронов, и из-за размеров их трудно регистрировать. Группа Менцеля обнаружила уникальный нейрон, названный VUMmx1, который реагировал на сахарозу, но не на запах, однако если после появления запаха сразу давали сахарозу, через какое-то время этот нейрон начинал реагировать на запах. Дофаминовая модель обучения методом временной разницы может быть реализована одним нейроном в мозге пчелы. VUMmx1 высвобождает октопамин – нейромодулятор, химически близкий к дофамину. Наша модель обучения пчелы может объяснить некоторые нюансы психологии пчелы, такие как неприятие риска: если у пчелы есть выбор между постоянной и удвоенной наградой, пчелы выберут постоянную награду.

