Продвижение
Во время творческого отпуска в 1987 году я выступал в Калтехе в качестве приглашенного профессора нейробиологии и посетил Фрэнсиса Крика в Институте Солка. Крик создавал исследовательскую группу, специализирующуюся на зрении, которым я тоже интересовался. На обеде с преподавателями я включил запись NETtalk, и она вызвала оживленную дискуссию. Вскоре, в 1989 году, я переехал в Ла-Хойя и основал при Институте Солка Лабораторию вычислительной нейробиологии, а также Институт нейронных вычислений при Калифорнийском университете в Сан-Диего. Это был потрясающий переход от младшего научного работника в Университете Хопкинса к ведущему преподавателю в Ла-Хойя, и в одночасье передо мной открылось множество возможностей, включая должность в Медицинском институте Говарда Хьюза, который оказывал щедрую поддержку моим исследованием более 25 лет.
Дэвид Румельхарт, преподававший метод обратного распространения ошибки, в 1987 году сменил Калифорнийский университет в Сан-Диего на Стэнфорд. Когда я перебрался в Сан-Диего, мне было жаль, что Дэвид уехал и мы виделись очень редко. С годами я заметил, что его поведение меняется. В конце концов ему поставили диагноз лобно-височная деменция – прогрессирующая потеря нейронов в лобной коре, влияющая на личность, поведение и речь. Румельхарт умер в 2011 году в возрасте 69 лет, уже не узнавая своих родственников и друзей.
Глава 9. Сверточные сети
К 2000 году одержимость нейронными сетями 1980-х спала, и все вернулось в нормальное русло исследований. Томас Кун однажды охарактеризовал время между научными революциями как регулярную работу ученых, теоретизирующих, наблюдающих и экспериментирующих в рамках устоявшейся парадигмы или объяснительной системы. Джеффри Хинтон перешел в Университет Торонто в 1987 году и продолжил работу над небольшими улучшениями, но ни одно из них не имело такого успеха, как машина Больцмана. Хинтон в 2000-х годах возглавил программу «Нейронные вычисления и адаптивное восприятие» (Neural Computation and Adaptive Perception; NCAP) в Канадском институте перспективных исследований, куда вошли около 25 исследователей из Канады и других стран, сосредоточенных на решении сложных проблем обучения. Я был членом их консультативного совета под председательством Яна Лекуна (рис. 9.1) и участвовал в ежегодных встречах непосредственно перед конференцией NIPS. Изучались новые стратегии обучения нейронных сетей, и прогресс шел медленно, но стабильно. Хотя у нейронных сетей было много полезных применений, высокие ожидания 1980-х годов не оправдались. Но это не поколебало первопроходцев. Оглядываясь назад, можно сказать, что они готовили почву для грандиозного прорыва.
Устойчивый прогресс в машинном обучении
Конференция NIPS обеспечила в 1980-х годах благоприятные условия для развития нейронных сетей и открыла двери для других алгоритмов, которые могут обрабатывать большие многомерные наборы данных. Метод опорных векторов (Support Vector Machine, SVM) ворвался на сцену в 1995 году и начал новый этап в сетях перцептронов, которые теперь называются неглубокими сетями. Мощным классификатором, который теперь в инструментарии каждого, SVM сделал так называемый kernel trick – математическое преобразование, которое эквивалентно прыжкам из пространства данных в гиперпространство, где точки данных перераспределяют, чтобы их было легче разделить. Томазо Поджио разработал иерархическую сеть HMAX с весами, задаваемыми вручную, которая могла классифицировать ограниченное количество объектов. Предположительно это должно было улучшить производительность и более глубоких сетей.

Рис. 9.1. Джеффри Хинтон и Ян Лекун, освоившие глубокое обучение. Фотография сделана примерно в 2000 году на заседании программы NCAP Канадского института перспективных исследований. Эта программа создала благодатную почву для исследования глубокого обучения, и участники на снимке довольны своими успехами
В 2000-х годах разработали графические модели, ставшие частью большого потока вероятностных моделей, называемых байесовскими сетями или сетями доверия. В их основу легло уравнение, выведенное Томасом Байесом в XVIII веке, которое позволяло новым доказательствам изменять исходные установки. Джуда Перл из Калифорнийского университета в Лос-Анджелесе ранее представлял сети на основе байесовского анализа, и его алгоритм расширили и усовершенствовали разработкой методов для изучения вероятностей. Этот и многие другие найденные алгоритмы создали мощный арсенал, ставший основой для машинного обучения.
Так как вычислительные мощности компьютеров росли по экспоненте, стало возможным обучать более крупные сети. Считалось, что широкие нейронные сети с большим числом скрытых единиц эффективнее, чем глубокие сети с большим количеством слоев, но выяснилось, что это не относится к сетям, которые обучаются слой за слоем. Отчасти причиной была проблема исчезающего градиента ошибки, которая замедляла обучение вблизи входного слоя. Когда ее решили, появились условия для обучения глубоких сетей обратного распространения ошибки, которые показывали прекрасные результаты на тестах. Сети глубокого обучения продемонстрировали, насколько в перспективе может улучшиться качество распознавания речи.
Глубокие сети обратного распространения ошибки бросили вызов традиционным подходам к компьютерному зрению. То, что внимание вновь было обращено к нейросетям, подняло шумиху на Конференции NIPS в 2012 году. Джеффри Хинтон и два студента, Алекс Крижевский и Илья Суцкевер, представили доклад о методе распознавания объектов на изображениях, использованный ими для обучения AlexNet – глубокой сверточной сети, которая будет в центре внимания в этой главе. В области компьютерного зрения последние 20 лет шел устойчивый, но медленный прогресс, и на тестах производительность росла на доли процента в год. Методы улучшались неспешно, поскольку каждая новая категория объектов требует, чтобы эксперт предметной области определил для нее неизменяющиеся признаки, по которым их можно отличить от других объектов.
Важную роль в сопоставлении различных методов играют контрольные показатели. Эталоном, который использовала команда из Университета Торонто, была база данных ImageNet, содержащая свыше 15 миллионов изображений с высоким разрешением более чем в 22 тысячах категорий. AlexNet добилась беспрецедентного снижения частоты ошибок на 18 процентов. Этот скачок производительности поразил специалистов по машинному зрению и задал курс его развития, так что в настоящее время компьютерное зрение почти достигло уровня человеческого. К 2015 году частота ошибок в базе данных ImageNet снизилась до 3,6 процента. Используемую сеть глубокого обучения, во многом напоминающую зрительную кору головного мозга, представил Ян Леку, и первоначально она называлась Le Net.
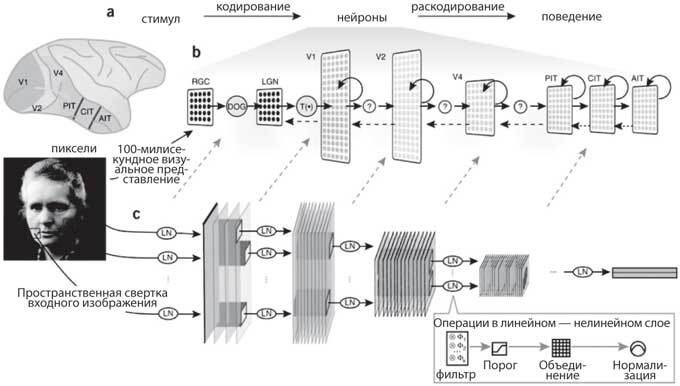
Рис. 9.2. Сравнение зрительной коры и сверточной сети для распознавания объектов на изображениях. Вверху: иерархия слоев зрительной коры, от входов V1 с сетчатки и таламуса (LGN) до нижней височной коры (PIT, CIT, AIT), показывающая соответствие между кортикальными областями и слоями сверточной сети. Внизу: входные данные с изображения слева проецируются на первый сверточный слой, состоящий из нескольких слоев признаков, каждый из которых представляет собой фильтр, как ориентированные простые клетки, найденные в зрительной коре. Фильтры с заданными границами объединяются параллельно первому слою и дают одинаковый отклик на определенном участке, подобно сложным клеткам в зрительной коре. Эта операция повторяется на каждом сверточном слое сети. Выходной слой полностью обменивается данными с последним сверточным слоем. (Yamins DLK, DiCarlo JJ. Using goaldriven deep learning models to understand sensory cortex. Nat. Neurosci. 19: 356–65, 2016)
Ян Лекун (рис. 9.1) был студентом, когда мы с Джеффри Хинтоном впервые встретились с ним в 1980-х годах во Франции. Он заинтересовался ИИ еще в девять лет, вдохновленный HAL 9000 – вымышленным компьютером из фильма «Космическая одиссея 2001 года». В 1987 году Лекун, когда писал свою кандидатскую диссертацию, самостоятельно выявил метод обратного распространения ошибки, после чего переехал в Торонто, чтобы работать с Хинтоном. Позже он перешел в Bell Labs в Холмделе, где обучил сеть читать рукописные почтовые индексы на письмах, используя набор данных MNIST – маркированный эталон из почтового отделения Буффало. Ежедневно приходится направлять в почтовые ящики миллионы писем, и сегодня это полностью автоматизировано. Та же технология позволяет банкоматам считывать сумму на банковском чеке. Интересно, что сложнее всего найти место, где на чеке записаны цифры, так как у каждого чека свой формат. Еще в 1980-х годах было очевидно, что у Лекуна огромный талант брать доказанный учеными принцип и заставлять его работать в реальном мире.

