Возрождение нейронных сетей
Двухтомник Румельхарта и Маклелланда «Параллельная распределенная обработка», изданный в 1986 году, уже стал классикой. Джеффри Хинтон тоже планировал принять участие в работе над ним, однако его отвлекла машина Больцмана. Эта книга – первая, в которой описано влияние сетей и алгоритмов многослойного обучения на понимание умственных и поведенческих процессов. Было продано более 50 тысяч экземпляров, изданных MIT Press, – бестселлер по академическим меркам. У сетей, обученных методом обратного распространения ошибки, были скрытые блоки со свойствами, напоминающими свойства нейронов зрительной коры. Кроме того, схемы распада нейронных сетей имели много общего с проблемами у человека после травмы мозга.
Фрэнсис Крик был членом группы параллельной распределенной обработки и посещал большинство встреч и семинаров. В спорах, насколько модели такой обработки схожи с биологическим процессом, он утверждал, что они должны рассматриваться как некий демонстрационный образец, а не как точная копия мозга. В книге, посвященной параллельной распределенной обработке, он написал главу о том, что на тот момент было известно о коре головного мозга. Я же добавил главу о том, чего мы не знали о ней. Пиши мы эти главы сегодня, обе вышли бы гораздо длиннее.
В 1980-х годах и истории успеха, о которых никто не знал. Одной из самых прибыльных компаний в сфере нейросетей стала HNC Software Inc., основанная Робертом Хехт-Нильсеном, который использовал нейронную сеть для предотвращения мошенничества с кредитными картами. Хехт-Нильсен преподавал на кафедре электрической и компьютерной инженерии Калифорнийского университета в Сан-Диего популярный курс по практическому применению нейронных сетей. Ежедневно в магазинах Южной Америки совершаются кражи с кредиток (что я лично испытал на себе), и они же являются объектами массовой киберпреступности. Мы проводим множество операций с картами, и порой сложно определить подозрительные транзакции. Например, отказ в оплате в ресторане в Рио-де-Жанейро может доставить проблем туристу. Людям в 1980-х годах приходилось принимать срочные решения. В итоге совершались мошеннические операции более чем на 150 миллиардов долларов в год. Компания HNC Software Inc. использовала алгоритмы обучения нейросетей, чтобы выявлять мошенничество с пластиковыми картами гораздо точнее, чем люди, экономя компаниям, выпускающим карты, миллиарды долларов в год. Компания HNC была приобретена в 2002 году за миллиард долларов компанией Fair Isaac and Company (FICO), известной своими кредитными рейтингами.
Есть что-то волшебное в наблюдении за тем, как сеть учится, становится все лучше, делая небольшие шаги. Процесс медленный, но если хватает обучающих примеров и сеть достаточно велика, алгоритмы обучения могут найти такое представление, которое хорошо обобщается на новые входные данные. Когда процесс повторяется при случайно выбранном наборе весов, каждый раз учится другая сеть, но со схожими характеристиками. Разные сети могут решить одну и ту же проблему; это влияет на то, что мы должны ожидать, когда сумеем восстановить полный набор связей в мозге разных людей. Если у многих сетей одинаковое поведение, ключ к их пониманию – используемые мозгом алгоритмы обучения, найти которые легче.
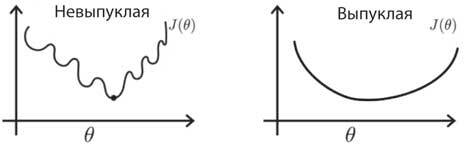
Рис. 8.4. Невыпуклые и выпуклые функции стоимости. Графики показывают зависимость функции стоимости J (θ) от параметра θ. Выпуклая функция (справа) имеет только один – глобальный – минимум, которого можно достичь, двигаясь вниз по кривой из любого места на ней. Представьте, что вы лыжник и всегда разворачиваете свои лыжи к самому крутому спуску. Вы гарантированно доберетесь до низа. Напротив, невыпуклая функция стоимости (слева) может иметь локальные минимумы, которые являются ловушками, мешающими найти глобальный минимум при спуске. Как следствие, невыпуклые функции стоимости трудно оптимизировать. Однако этот одномерный пример вводит в заблуждение. Когда есть много параметров (обычно миллионы в нейронной сети), могут быть определенные (седловые) точки, выпуклые в одних измерениях и вогнутые в других. Когда вы находитесь в такой точке, всегда есть направление, чтобы спуститься вниз
Понимание глубокого обучения
В задачах с выпуклой оптимизацией отсутствуют локальные минимумы и гарантируется сходимость к глобальному минимуму (рис. 8.4). Эксперты по оптимизации утверждали, что, так как обучение сетей со скрытыми элементами было задачей невыпуклой оптимизации, мы попадали в локальные минимумы и впустую тратили время (рис. 8.4). Опыт показал, что они ошибались. Но почему? Теперь мы знаем, что в многомерных пространствах локальные минимумы функции стоимости редки, пока вы не дойдете до заключительных этапов обучения. На ранних стадиях почти все направления ведут под гору, и на этом пути есть седловые точки, где в одних измерениях можно пойти вверх по ошибке, а в других – вниз. Предположение, что вы застрянете в локальных минимумах, основано на решении проблем в пространстве с малым числом измерений (см. рис. 8.4), где меньше запасных выходов.
У современных моделей глубоких сетей миллионы элементов и миллиарды весов. Миллиардномерное пространство параметров – кошмар для статистики. Специалисты по статистике традиционно анализируют простые модели с несколькими характеристиками, чтобы доказать предположения, используя небольшие наборы данных. Они заверили нас, что при таком множестве параметров мы добьемся безнадежной переподгонки данных, или чрезмерного обучения, то есть сеть просто запомнит примеры и не сможет обобщить их на новые тестовые наборы. Но мы использовали методы, такие как принудительное снижение весов, если они не делали ничего полезного, что помогло бы избежать переподгонки. Сейчас, чтобы обойти эту проблему, для обучения глубоких сетей используются еще более сложные методы регуляризации.
Джеффри Хинтон изобрел отлично продуманный метод регуляризации – исключение (дропаут, dropout). Во время каждой эпохи обучения, когда градиент оценивается по ряду примеров и делает шаг в пространстве весов, половина единиц случайным образом вырезается из сети. А значит, в следующую эпоху обучается другая сеть. Как следствие, в каждую эпоху остается меньше параметров для обучения, и у полученной в результате сети меньше зависимостей между единицами, чем если бы в каждую эпоху обучалась одна и та же большая сеть. Дропаут уменьшает частоту ошибок в глубоких сетях на 10 процентов, что стало значительным прогрессом. В 2009 году компания Netflix провела открытый конкурс, предложив приз в миллион долларов тому, кто сможет уменьшить ошибку их системы рекомендаций на 10 процентов. Это основная технология для онлайн-трансляций. Почти каждый магистрант в области машинного обучения принял участие в конкурсе.
Примечательно, что синапсы в коре головного мозга исключаются с высокой скоростью. На каждый входной импульс приходится 90 процентов отказов обычного возбуждающего синапса. Это похоже на бейсбольную команду, где почти все игроки имеют средний уровень 100. Как мозг может стабильно функционировать с такими ненадежными кортикальными синапсами? Когда в нейроне тысячи вероятностных синапсов, вариабельность их суммарной активности относительно невысока, так что производительность не падает так сильно, как вы можете себе представить. Польза от обучения с использованием исключения на уровне синапсов может перевешивать затраты на снижение точности. Исключение также экономит энергию, так как работа синапсов дорого обходится. Наконец, кора головного мозга применяет вероятности для вычисления предполагаемых результатов, а не точных, и для этого эффективно использование вероятностных компонентов.
Хотя кортикальные синапсы могут быть ненадежными, они удивительно точны в своей силе. Размеры кортикальных синапсов и, соответственно, их сила различаются более чем в сотню раз, и в этих пределах сила отдельных синапсов может быть увеличена или уменьшена. Недавно моя лаборатория совместно с Кристен Харрис, нейроанатомом из Техасского университета в Остине, воссоздала небольшой фрагмент крысиного гиппокампа – области мозга, необходимой для формирования долговременных воспоминаний, – которая содержала 450 синапсов. Чаще всего это были одиночные синапсы на дендритных ветвях, но в ряде случаев два синапса от одного аксона передавали сигналы одному и тому же дендриту. К нашему удивлению, они были почти идентичны по размеру, а значит, как мы знали из предыдущих исследований, одинаковы по силе. Многое известно об условиях, которые приводят к изменению силы синапсов в зависимости от истории входных импульсов и соответствующей электрической активности дендритов, одинаковых для парных синапсов. Из этих наблюдений мы сделали вывод, что точность хранения информации в силе синапсов значительная – не меньше пяти бит на синапс. Любопытно, что для достижения высокого уровня производительности алгоритмам обучения глубоких рекуррентных сетей требуется всего пять бит. Это может не быть совпадением.
Степень размерности сетей в мозге настолько высока, что мы даже не можем точно оценить ее. Общее количество синапсов в коре головного мозга – около ста триллионов, астрономически высокая грань. Человеческая жизнь длится не более нескольких миллиардов секунд. Таким образом, вы можете позволить себе посвящать сто тысяч синапсов каждой секунде своей жизни. На деле у нейронов, как правило, кластеризованные локальные соединения. Например, в кортикальном столбце сто тысяч нейронов соединены миллиардом синапсов – число довольное большое, но все же не заоблачное. Длинные соединения куда менее распространены, потому что требуют много места и энергии.
Число нейронов, которое нужно, чтобы представить в мозге объект или понятие, важно, и его необходимо определить. Предположительно требуется около миллиарда синапсов и около ста тысяч нейронов, распределенных по десяти кортикальным областям, что позволяет хранить около ста тысяч отдельных классов объектов и понятий в ста триллионах синапсов, что сходно с количеством слов в английском языке. На практике популяции нейронов, представляющих схожие объекты, перекрываются, благодаря чему растет способность коры головного мозга представлять связанные объекты и отношения между объектами. У человека эта способность развита намного лучше, чем у других млекопитающих, из-за сильно увеличенной ассоциативной коры, которая находится на вершине сенсорной и моторной иерархий.
Изучение вероятностных распределений в многомерных пространствах было относительно неисследованной областью статистики. Несколько ученых-статистиков из сообщества NIPS, таких как Лео Брейман из Стэнфордского университета, исследовали статистические проблемы, возникающие при навигации по пространствам с высокой размерностью и многомерным наборам данных. Некоторых из сообщества NIPS, например, Майкла Джордана из Калифорнийского университета в Беркли, приняли на работу в отдел статистики. В эпоху больших данных машинное обучение шагало там, куда статистики не решались ступать. Однако недостаточно просто обучить крупные сети делать удивительные вещи – нужно их проанализировать и понять, почему они эффективны. Физики взяли на себя инициативу на этом фронте, используя методы из статистической физики для анализа свойств обучения по мере того, как число нейронов и синапсов становится запредельно большим.

