NETtalk
В 1984 году я посетил Принстонский университет и послушал выступление студента магистратуры Чарльза Розенберга о машине Больцмана. Обычно я выступал с этим докладом, и я был впечатлен. Он спросил, может ли приехать в мою лабораторию для работы над летним проектом. К тому времени как Розенберг прибыл в Балтимор, мы переключились на изучение метода обратного распространения ошибки, что позволило нам думать о работе над реальной задачей, а не над демонстрационными моделями, над которыми я трудился ранее. Розенберг был учеником прославленного лингвиста Джорджа Миллера, поэтому мы искали оптимальное решение в языке, которое не было настолько сложным, чтобы нельзя было продвинуться вперед, но и не настолько легким, чтобы известные методы могли решить эту проблему. Лингвистика – широкая отрасль со множеством ответвлений. Фонология – раздел лингвистики, изучающий произношение слов. Синтаксис – объединение слов в фразы. Семантика – значение слов и предложений. Прагматика – влияние контекста на смысл речи. Мы решили начать с фонологии и продвигаться вверх.
Произношение в английском языке довольно трудное, поскольку в нем сложные правила с большим количеством исключений. Например, гласные долгие, если в конце слова есть буква е (gave, brave), однако слово have не подчиняется этому правилу. Я пошел в библиотеку и взял книгу с сотнями страниц правил и исключений, составленными фонологами. Часто были правила в исключениях и исключения из исключений. Короче, у лингвистов были правила на все случаи. Гораздо хуже, что не все произносят слова одинаково. Существует множество диалектов, в каждом из которых свой набор правил.
Джеффри Хинтон посетил меня в Университете Хопкинса на этапе раннего планирования проекта и сказал нам, что, по его мнению, произношение слишком сложно. В итоге мы снизили планку и взяли книгу для детей, которые только учатся читать, где была всего сотня слов. Сеть, которую мы создали, имела окно, рассчитанное на 7 букв, каждая из ячеек была представлена 29 элементами, включая пробелы и знаки пунктуации. В итоге получилось 203 единицы входных сигналов. Входные блоки были соединены с 80 скрытыми блоками, а скрытые блоки спроецированы на 26 выходных единиц, по одной для каждого из простых звуков, называемых фонемами, которые существуют в английском языке. Сеть содержала 18 629 весов (рис. 8.2), что много по меркам 1986 года и безумно много по меркам математической статистики. Нам сказали, что с таким количеством параметров обучающий набор будет очень большим и сеть не сможет его обобщить.
По мере того как слова по одной букве появлялись на экране, сеть назначала фонему средней букве. Часть проекта, которая заняла больше всего времени, – сопоставлять фонему с верной буквой вручную, поскольку не в каждом слове количество букв совпадает с количеством фонем. Но в то же время обучение происходило на наших глазах, становясь все лучше и лучше по мере того, как фразы циклически повторялись на экране, и когда результат на тренировочном наборе сходился, производительность сети была практически идеальной. Тестирование на новых словах нельзя было назвать успешным, но мы ожидали, что обобщение такого маленького тренировочного набора будет слабым. Тем не менее предварительный итог вселял оптимизм.
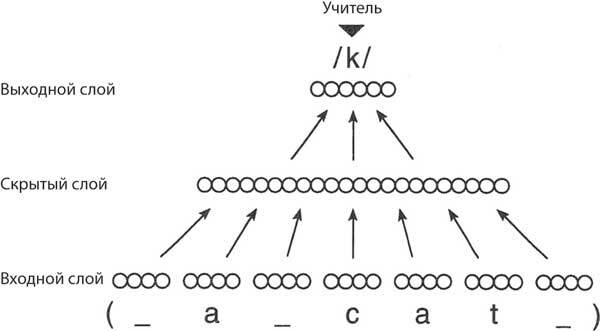
Рис. 8.2. Сетевая модель прямого распространения NETtalk. Семь групп элементов на нижнем уровне представляют собой буквы появляющегося в окне текста, по одной за раз. Цель сети – правильно предсказать звучание центральной буквы (твердый звук «к» в приведенном примере). Каждый элемент входного слоя связывается со всеми скрытыми элементами, которые, в свою очередь, проецируются на все элементы выходного слоя. Алгоритм обратного распространения ошибки использовался для тренировки весов под контролем учителя. Выходной образец для верной фонемы сравнивается с выходом сети, и ошибка возвращается к весам на более ранних уровнях. [Rosenberg C. R., Sejnowski T. J. “Parallel Networks That Learn to Pronounce English Text”, Complex Systems, 1, 145–168, 1987]
Затем мы использовали 20 тысяч слов из «Брауновского корпуса», в котором обозначили фонемы для каждой из букв и ударения. Сопоставление букв и звуков заняло несколько недель, но как только обучение началось, сеть впитала в себя весь сборник за одну ночь. Но как хорошо она смогла все обобщить? Прекрасно смогла! Сеть распознала закономерности английского произношения и научилась находить исключения при том же строении и том же алгоритме обучения. Та сеть была крошечной по нынешним стандартам, что подчеркивает, насколько эффективно сеть разобралась в английской фонологии. Это был первый намек на то, что нейронные сети можно связать с речью – основой символических представлений.
Сеть, преобразующую буквы в звуки, мы назвали NETtalk. Прежде чем научиться читать вслух, она прошла фазу «лепета», во время которой изучала разницу между согласными и гласными, но назначала фонему b для всех согласных и фонему a для всех гласных. Поначалу это звучало как «ба», но потом, после продолжительного обучения, превратилось в «ба-га-да», до жути напоминая лепет младенца. Зачем она начала правильно произносить короткие слова, и к концу обучения стала понятна большая часть того, что она говорила.
Чтобы проверить работу NETtalk с диалектом, мы нашли фонологическую транскрипцию интервью с латиноамериканским мальчиком из Лос-Анджелеса. Обученная сеть воссоздала испанский акцент ребенка, рассказывавшего, как он ходит в гости к бабушке и получает конфеты. Я записывал фрагменты во время последовательных этапов обучения, воспроизводя выходные данные NETtalk на синтезаторе речи DECtalk, который преобразовывал строку с обозначенными фонемами в слышимую речь. Когда я включил запись во время лекции, аудитория была ошеломлена: сеть будто говорила сама. Этот летний проект превзошел все наши ожидания и стал первым случаем обучения нейронных сетей для практического применения. В 1986 году меня пригласили продемонстрировать NETtalk на утреннем телешоу Today, и этот выпуск посмотрело на удивление много зрителей. До того момента нейронные сети оставались предметом загадочных исследований. Я до сих пор встречаю людей, которые впервые услышали о нейронных сетях, посмотрев эту передачу.
Хотя NETtalk ярко продемонстрировала, как сеть может отображать некоторые аспекты языка, она не достаточно хорошо моделирует то, как люди осваивают чтение Во-первых, сначала мы учимся говорить, и только потом – читать. Во-вторых, нам дают несколько фонетических правил, которые помогают справиться со сложной задачей – научиться хорошо читать вслух. Тем не менее чтение быстро превращается в распознавание образов, и не нужно прилагать сознательные усилия, чтобы применять правила. Как и NETtalk, большинство носителей английского языка без усилий произнесут лишенные смысла фразы, такие как стихотворение «Бармаглот»: «Варкалось. Хливкие шорьки…» Это псевдослова, которых нет в словарях, но их фонемы образуются из тех же сочетаний букв, что и в настоящих.
NETtalk сильно впечатлила аудиторию, но наука требовала проанализировать сеть, чтобы выяснить, как она работает. Мы с Чарли Розенбергом применили кластерный анализ к схемам активности в скрытых элементах и выяснили, что NETtalk обнаружила ту же закономерность, по которой схожие гласные и согласные звуки объединяются в группы, что нашли и лингвисты. Марк Зейденберг и Джей Макклелланд использовали такой же подход как точку отсчета и провели подробное сравнение с этапами, которые проходят дети, когда учатся читать.

Рис. 8.3. Летние нейросетевые курсы в Университете Карнеги – Мелона в 1986 году. Джефф Хинтон в первом ряду, по бокам от него – Джей Макклелланд и я. На этой фотографии – видные специалисты в области нейронных вычислений сегодняшнего дня. Нейронные сети в 1980-х годах были наукой XXI века в XX веке
Другая сеть, которая научилась образовывать прошедшее время английских глаголов, стала знаменитой в мире когнитивной психологии, поскольку опирающаяся на правила старая гвардия сражалась с передовой группой параллельно распределенной обработки. Обычный способ образовать прошедшее время – добавить – ed в конце слова, например, to train (тренироваться) – trained (тренировался). Однако есть и исключения, такие как to run (бежать) – ran (бежал). У сети нет проблем ни с правильными, ни с неправильными глаголами. И хотя эти споры уже неактуальны, фундаментальный вопрос о роли явного представления правил в мозге остается открытым. Недавние эксперименты подтверждают, что в процессе обучения постепенно осваивается и изменение формы слов в соответствии с их смыслом. Успех глубокого обучения Google Переводчика и других приложений для естественных языков в улавливании нюансов письменной речи еще сильнее подтверждает предположение, что мозгу не нужно постоянно использовать правила, даже если по поведению кажется, что он их применяет.
На первых посвященных нейросетевым моделям курсах, которые мы с Джеффри Хинтоном и Дэйвом Турецки организовали в Университете Карнеги – Меллона в 1986 году (рис. 8.3), студенты сделали пародию на NETtalk. Они выстроились в несколько рядов, каждый студент представлял единицу в сети. Когда они представляли «j» в фамилии «Sejnowski», то выдавали ошибку, потому что она произносится как буква «у» и не соответствует шаблону. В то время лишь в немногих вузах были преподаватели, которые читали курсы по нейронным сетям. Многие из этих студентов впоследствии совершили важные открытия и достигли карьерных высот. Вторые летние курсы были проведены в Университете Карнеги – Меллона в 1988 году, а третьи – в Калифорнийском университете в Сан-Диего в 1990 году. Необходима смена поколений, чтобы новые идеи стали популярными. Эти летние курсы были бесценным опытом и лучшими инвестициями, которые мы сделали на заре нейросетей.

