Глава 8. Метод обратного распространения ошибки
Калифорнийский университет в Сан-Диего был основан в 1960 году и со временем превратился в крупный центр биомедицинских исследований. В 1986 году в нем открыли первый в мире факультет когнитивной науки. Дэвид Румельхарт (рис. 8.1) был видным математиком и когнитивным психологом, работавшим с символьным, основанным на правилах, подходом к ИИ, который преобладал в 1970-х годах.

Рис. 8.1. Дэвид Румельхарт в Калифорнийском университете в Сан-Диего в 1986 году, примерно в то время, когда были изданы книги о параллельной распределенной обработке. Румельхарт оказал влияние на техническую разработку алгоритмов обучения для моделей многослойных сетей и использовал их, чтобы понять психологию языка и мышления
Когда я впервые встретил его в 1979 году на семинаре, организованном Джеффри Хинтоном в Калифорнийском университете в Сан-Диего, Румельхарт был одним из первых, кто использовал новый подход к психологии человека, который он вместе с Джеем Макклелландом назвали параллельной распределенной обработкой (Parallel Distributed Processing; PDP). Румельхарт мыслил глубоко и часто делал проницательные замечания.
Алгоритм обучения машины Больцмана доказуемо мог изучить проблемы, требующие скрытых элементов, показывая, что, вопреки мнению Минского и Пейперта, а также большей части научного мира, возможно обучить многослойную сеть и преодолеть ограничения перцептрона. При этом не ставилось никаких ограничений ни на количество слоев в сети, ни на связи внутри слоя. Казалось, прогрессу нет предела, но была одна проблема: при моделировании достижение равновесия и сбор статистики становились все медленнее, а сетям покрупнее требовалось гораздо больше времени, чтобы сбалансироваться.
Блок 5. Обратное распространение ошибки
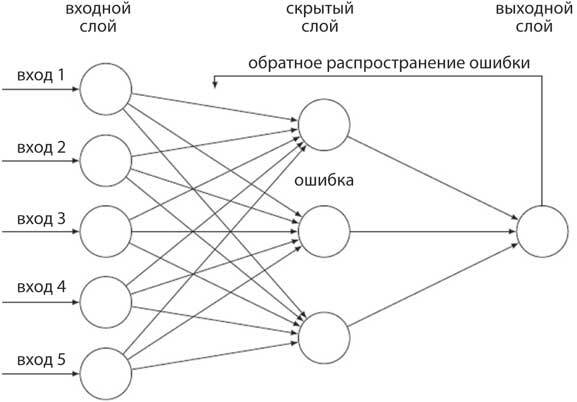
В сети с обратным распространением ошибки входные данные передаются с прямой связью: слева на схеме входные элементы распространяются вперед через соединительные узлы (указаны стрелками) к скрытому слою элементов, которые, в свою очередь, проецируются на выходной слой. Выходные данные сравниваются со значением, заданным учителем, и разница используется для обновления веса в выходном блоке, чтобы снизить вероятность ошибки. Затем веса между входными блоками и скрытым слоем обновляются на основе обратного распространения ошибки, исходя из того, насколько каждый вес влияет на ошибку. Обучаясь на множестве примеров, скрытые элементы совершенствуют избирательные свойства, которые используются, чтобы различать разнообразные входные данные и разделять их на категории в выходном слое. Это называется обучением представлениям.
В принципе, можно построить массово-параллельный компьютер, который намного быстрее, чем традиционная архитектура фон Неймана, выполняющая одно обновление за раз. Это путь, по которому пошла природа. В 1980-х мы использовали цифровые компьютеры, которые могли выполнять только около миллиона операций в секунду. Сегодня компьютеры выполняют миллиарды операций в секунду, а благодаря соединению тысяч ядер высокопроизводительные компьютеры работают в миллион раз быстрее. Такой рост беспрецедентен в технологиях. Стал ли ваш автомобиль в миллион раз мощнее, чем машины из 1980-х?
США поставили на Манхэттенский проект два миллиарда долларов без каких-либо гарантий, что атомная бомба получится, и строжайшей тайной было то, что она получилась. Как только стало известно, что многослойные сети можно обучать с помощью машины Больцмана, произошел взрыв новых обучающих алгоритмов. В то же время, когда мы с Джеффри Хинтоном работали над машиной Больцмана, Румельхарт разработал другой алгоритм обучения для многослойных сетей, который оказался более продуктивным.
Оптимизация
Оптимизация – ключевое математическое понятие в машинном обучении. Для многих задач можно найти функцию стоимости, решение которой – состояние системы с наименьшими затратами. Для сети Хопфилда функция стоимости – это энергия, как описано в главе 6, и цель – найти состояние сети с наименьшим расходом энергии. Для сети прямого распространения функция стоимости обучения – сумма квадрата ошибок выходного слоя обучающего набора. Градиентный спуск – общая процедура, которая минимизирует функцию стоимости, внося дополнительные изменения в веса в сетях в направлении наибольшего снижения стоимости. Представьте функцию стоимости в виде горного хребта, а градиентный спуск – в виде лыжни, по которой вы спускаетесь вниз по склону.
Румельхарт обнаружил, как вычислить градиент для каждого веса в сети с помощью процесса, называемого обратным распространением ошибок (блок 5). Начиная с выходного слоя, где известна ошибка, легко вычислить градиент от входных весов к выходным элементам. Следующим шагом было использование градиентов выходного слоя для вычисления градиентов на предыдущем слое весов, и так далее слой за слоем вплоть до входного. Это очень эффективный способ вычисления градиентов ошибки.
Хотя у метода обратного распространения ошибки нет такой же элегантности и глубоких корней в физике, как у алгоритма машинного обучения Больцмана, он более эффективен и значительно ускорил прогресс. Статья об этом за авторством Румельхарта, Хинтона и Рона Уильямса была опубликована в журнале Nature в 1986 году, и с тех пор ее процитировали более 25 тысяч раз в других научных работах. Статья, процитированная сто раз, играет большую роль в своей области, а статья об обратном распространении ошибки стала бестселлером.

