Часть II. Множество способов обучения: хронология
1949 – Дональд Хебб выпустил книгу «Организация поведения», в которой сформулировал правило пластичности синапса.
1982 – Джон Хопфилд опубликовал труд «Нейронные сети и физические системы с возникающими коллективными вычислительными способностями», в котором описал нейросеть Хопфилда.
1985 – Джеффри Хинтон и Терри Сейновски представили «Алгоритм обучения для машин Больцмана», что стало контрдоказательством широко распространенного мнения Минского и Пейперта, что алгоритм обучения для многослойных сетей невозможен.
1986 – Дэвид Румельхарт и Джеффри Хинтон написали «Обучение внутреннего представления путем распространения ошибки», где описали алгоритм обратного распространения ошибки, который используется для глубокого обучения в наши дни.
1988 – Ричард Саттон напечатал статью «Обучение прогнозированию методами временных различий» в журнале «Машинное обучение». Он был вдохновлен сутью ассоциативного обучения, и обучение с учетом временной разности стало считаться основным алгоритмом для обучения мозга методом вознаграждения.
1955 – Тони Белл и Терри Сейновски опубликовали труд «Подход к максимизации информации для слепого разделения и слепой обратной свертки», в котором описали неконтролируемый алгоритм для анализа независимых компонентов.
2013 – Работа Джеффри Хинтона «Классификация Image Net с глубокими сверточными нейросетями» позволила на 18 % снизить частоту ошибок при классификации объектов на изображениях.
2017 – сеть глубокого обучения Alpha Go победила Кэ Цзе на Чемпионате мира по го.
Глава 6. Проблема коктейльной вечеринки
На коктейльной вечеринке бывает сложно расслышать, что говорит человек рядом с тобой, среди какофонии других голосов вокруг. Наличие пары ушей помогает направить ваш слух в нужном направлении, и ваша память может заполнить недостающие обрывки разговора. Теперь вообразите шумную вечеринку с сотней людей в комнате и сотней ненаправленных микрофонов, которые собирают звуки ото всех, но с различным соотношением амплитуд для каждого человека на каждом микрофоне. Можно ли разработать алгоритм, который сумеет разделить голоса на отдельные выходные каналы? Чтобы усложнить задание, подумайте, что делать, если источники звука неизвестны – например, музыка, хлопки, звуки природы или даже случайный шум? Это называется проблемой слепого разделения сигналов (рис. 6.1).
На конференции, посвященной нейронным вычислительным сетям, – предшественнице NIPS, – проходившей с 13 по 16 апреля 1986 года в Сноуберде, в штате Юта, был представлен стендовый доклад «Пространственная или временная адаптивная обработка сигналов с помощью моделей нейронных сетей». Алгоритм обучения был использован для слепого разделения смесей синусоидальных волн – чистых частот, представленных в модели нейронной сети. Было неизвестно, существует ли общее решение, которое могло бы слепо разделять другие типы сигналов. Этот доклад указал на новый класс алгоритмов обучения без учителя. Десять лет спустя мы нашли алгоритм, который мог бы решить общую задачу.
Независимый компонентный анализ
Перцептрон – это однонейронная сеть. В следующей простейшей сетевой архитектуре больше одного модельного нейрона в выходном слое, при этом каждый входной нейрон соединен с каждым выходным нейроном, что преобразует схему и на входном и на выходном слое. Эта сеть может сделать гораздо больше, чем просто классифицировать входы. Ее можно научить выполнять слепое разделение источников.
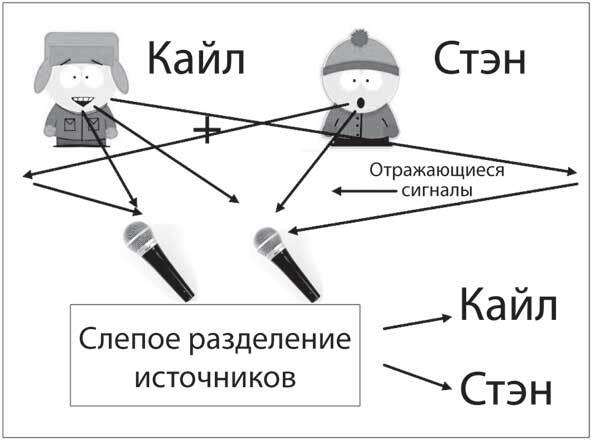
Рис. 6.1. Слепое разделение источников. Кайл и Стэн разговаривают одновременно в комнате с двумя микрофонами. Каждый микрофон улавливает сигналы, исходящие от разговаривающих, а также отражающиеся от стен помещения. Задача состоит в том, чтобы отделить два голоса друг от друга, не зная ничего о сигналах. Независимый компонентный анализ – алгоритм обучения, который решает эту проблему без информации об источниках
В 1986 году тогда еще студент Тони Белл (рис. 6.2) проходил летнюю практику в Швейцарской высшей технической школе в Цюрихе. Он был одним из первых, кто занялся нейронными сетями, и потому отправился в Женевский университет, чтобы послушать выступления четырех известных специалистов по сетям. После защиты диссертации в Брюссельском университете он в 1993 году переехал в Ла-Хойя, чтобы присоединиться к моей лаборатории в качестве постдокторанта.
Общий принцип обучения Infomax максимизирует поток информации в сети. Тони Белл работал над передачей сигнала в дендритах – разветвленных отростках нейронов, которые те используют для сбора информации из тысяч соединенных с ними синапсов. Белл чувствовал, что должна быть возможность максимизировать информацию, исходящую из дендрита, если изменить плотность его ионных каналов. Упростив задачу (игнорируя дендриты), он нашел новый теоретико-информационный алгоритм обучения, который решил проблему слепого разделения источников (блок 2).

Рис. 6.2. Тони Белл мыслит независимо. Эксперты знают много способов, которыми нельзя решить задачу, но часто кто-то, кто смотрит на нее впервые, видит новый подход и находит решение. Тони открыл итерационный (пошаговый) алгоритм для решения проблемы слепого разделения источников, который сейчас описан в учебниках по программированию и многократно применен на практике
Независимый компонентный анализ (Independent Component Analysis; ICA) – такое название получил новый алгоритм – с тех пор был использован для тысяч приложений и включен в учебники по обработке данных. При применении к изображениям природы независимые компоненты были вычленены фильтрами определения краев (рис. 6.3), похожими на простые клетки зрительной коры кошек и обезьян (рис. 6.4). Более того, чтобы восстановить часть изображения, требуются лишь некоторые из многочисленных источников, отчего реконструкция становится разреженной.
Блок 2. Как работает ICA

Сравнение метода анализа главных компонент (Principal Component Analysis; PCA) и анализа независимых компонент. Выходы с двух микрофонов на рисунке располагаются друг против друга по вертикальной и горизонтальной осям. Координаты каждой синей точки – это значения в один момент времени. Анализ главных компонент – популярный неконтролируемый метод обучения, подразумевающий выбор направления, которое делит два сигнала пополам, максимально смешивая их, а оси PCA всегда перпендикулярны друг другу. ICA находит красные оси, которые проходят вдоль направлений точек, представляющих разделенные сигналы, которые могут быть неперпендикулярны.
Эти результаты подтвердили гипотезу, выдвинутую в 1960-х годах выдающимся ученым в области зрения Хорасом Барлоу, когда Хьюбел и Визель обнаружили простые клетки в зрительной коре. На изображении много лишней информации, так как близлежащие пиксели часто имеют одинаковые значения (например, пиксели неба). Барлоу предположил, что простые клетки смогут уменьшить объем избыточной информации на представленных изображениях природы. Снижая избыточность, можно передать информацию с изображения более эффективно. Потребовалось 50 лет, чтобы разработать математический инструментарий, подтвердивший его идею.

Рис. 6.3. Фильтры ICA, полученные из изображений природы. Небольшие области (12×12 пикселей) снимков природных объектов (слева) использовались в качестве входных данных для сети ICA со 144 выходными блоками. Полученные независимые компоненты (справа) напоминают простые клетки первичной зрительной коры: они локализованы и распределены на положительные (белые) и отрицательные (черные) области, где серый равен нулю. Требуется только несколько фильтров, чтобы отобразить ту или иную часть. Это свойство называется разреженностью. (Bell A. J., Sejnowski T. J. The 'Independent Components' of natural scenes are edge filters, Vision Research, 37, 33273338, 1997)
Мы с Тони также показали, что, когда ICA применяется к естественным звукам, независимые компоненты являются временны́ми фильтрами с различными частотами и длительностью, похожими на фильтры, обнаруженные на низших уровнях слуховой системы. Это дало нам уверенность, что мы находимся на правильном пути и начинаем понимать фундаментальные принципы того, как сенсорные сигналы представлены на самых ранних этапах обработки в зрительной коре. Распространяя принцип на независимые подпространства признаков линейных фильтров, можно было моделировать сложные клетки зрительной коры.
Сеть ICA имеет равное количество входных и выходных блоков и один набор весов между ними. Звуки с микрофонов воспроизводятся через входной слой, один входной блок для каждого микрофона, а алгоритм обучения ICA, подобно алгоритму перцептрона, многократно изменяет вес выходного слоя, пока они не сойдутся. Однако, в отличие от перцептрона – контролируемого алгоритма обучения, независимый компонентный анализ не знает, какой должна быть выходная цель. ICA – алгоритм обучения без учителя, который использует меру независимости между выходными единицами в качестве функции потерь. Поскольку веса изменяются, чтобы сделать выходы как можно более независимыми, исходные источники звука становятся совершенно разделенными или как можно более невзаимосвязанными. Неконтролируемое обучение может обнаружить статистическую структуру в данных различного типа и объема, которые были ранее неизвестны.

