Факторный анализ
Факторный анализ позволяет сократить количество переменных, заменив их набором факторов. Кроме того, он может являться предварительной процедурой перед проведением регрессионного анализа в случае, если ряд предикторов коррелирует между собой.
Пример: предположим, вы разрабатываете батарею психологических тестов, предназначенную для диагностики способностей у школьников. После того, как вы составили ряд задач,
а также провели их на выборке учащихся, вам необходимо будет провести факторный анализ. Если высокий балл по одной задаче, как правило, сопровождается высоким баллом по другой задаче, значит, за ними скорее всего стоит некоторый общий фактор. Этот фактор и будет указывать на уровень развития той или иной способности.
Приложение 2. Работа в статистических пакетах
На сегодняшний день существует огромное количество программных продуктов, которые позволяют работать если не со всеми, то во всяком случае с большинством методов, о которых рассказывается в книге. В первом приближении их можно поделить на два класса: те, в которых все команды задаются с помощью текстового ввода (например R и Python), и те, где конкретный метод выбирается с помощью меню. Поскольку рядовой пользователь достаточно редко имеет дело с командной строкой, мы остановимся только на втором классе программ. Самыми популярными из них можно считать следующие.
1. IBM SPSS – мощный пакет, способный справиться с абсолютным большинством статистических задач. Является платным, однако существует и бесплатная 14-дневная версия.
2. StatSoft Statistica – главный конкурент SPSS на отечественном рынке. Также является коммерческим продуктом.
3. R-commander – графический интерфейс для языка программирования R. Как и сам R, распространяется бесплатно.
4. PSPP – бесплатный аналог SPSS со схожим интерфейсом.
5. Microsoft Excel с надстройкой «Анализ данных». Как ни странно, позволяет делать довольно много интересных вещей. Но его интерфейс не является типичным для статистических программ.
Здесь мы рассмотрим, как работать с SPSS. Однако многие вещи, о которых пойдет речь ниже, подходят и для других статистических пакетов. В частности, для любой статистической программы с меню характерна вот такая последовательность работы:
1. Вбить данные в таблицу;
2. Найти нужный метод;
3. Выбрать переменные для анализа;
4. Отметить необходимые опции;
5. Нажать «ОК»;
6. Проинтерпретировать результаты.
При этом первый, пятый и шестой шаги практически полностью идентичны. В частности, когда вы вбиваете данные в таблицу, абсолютное большинство пакетов следуют следующему правилу:
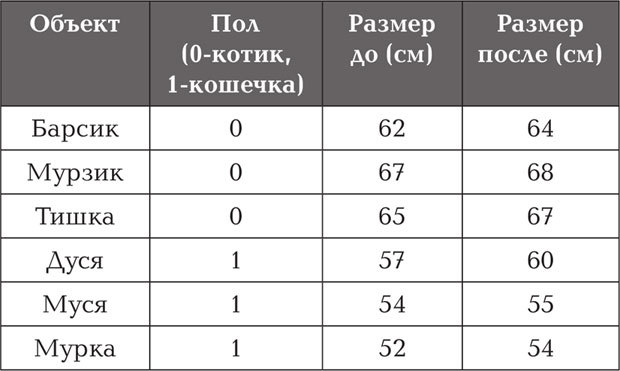
«По строкам – объекты, по столбцам – переменные».
При этом если у вас присутствуют несвязанные выборки, то этот факт кодируется отдельной переменной, которая обозначает принадлежность объекта к той или иной группе (например, 0 – котик и 1 – кошечка). В свою очередь каждая связанная выборка обозначается отдельной переменной (например, «Размер до» и «Размер после»).
Остальные шаги отличаются некоторыми нюансами, которые зависят как от пакета, так и от метода. В частности, в SPSS выбор переменных осуществляется с помощью переноса их в отдельные поля, а, допустим, в Statistica – простым выделением мыши.
Итак, ниже будут приведены алгоритмы работы в программе IBM SPSS Statistics 24 (пробная русская версия с официального сайта). Они будут состоять из четырех разделов:
1. КАК НАЙТИ, в котором указывается путь к конкретному методу. Он всегда начинается с верхнего меню (там, где «Файл», «Изменить» и т. д.);
2. ЧТО ВВОДИТЬ – что необходимо сделать для проведения анализа.
3. ДОПОЛНИТЕЛЬНЫЕ ОПЦИИ, которые позволяют приспособить метод под вашу конкретную задачу.
4. КУДА СМОТРЕТЬ – указание на таблицы и ячейки, в которых содержатся основные результаты анализа.
Описательная статистика и диаграммы
Как найти: Анализ –> Описательные статистики –> Частоты…
Что вводить: Выделите переменные, которые вы хотите проанализировать, и с помощью стрелочки перенесите их в поле «переменные».
Дополнительные опции:
Статистики… – позволяет выбрать конкретные меры центральной тенденции и меры изменчивости.
Диаграммы… – позволяет выбрать диаграммы (круговую или столбчатую).
Формат… – позволяет отрегулировать, в каком виде будет выдаваться результат. Например, можно вывести результаты по каждой переменной по отдельности, а можно – вместе.
Куда смотреть: в таблицы с описательными статистиками и на диаграммы.
T-Критерий стьюдента для несвязанных выборок
Как найти: Анализ –> Сравнение средних –> T-критерий для независимых выборок.
Что вводить:
1. Переместите переменные, по которым хотите найти различия, в поле «Проверяемые переменные».
2. Переместите переменную, которая делит ваши объекты на группы (т. е. На несвязанные выборки), в поле «Группировать по».
3. Задайте группы, либо указав конкретные значения (например 0 и 1), либо обозначив некоторое пороговое, ниже которого будет одна группа, а выше – другая.
Дополнительные опции: ничего интересного.
Куда смотреть: смотрим в таблицу «Критерий для независимых выборок». Слева будет два важных столбца, обозначающих критерий равенства дисперсий Ливиня, который определяет, равны ли между собой дисперсии ваших выборок.
Если значимость больше 0,05, то они равны и вам дальше нужно будет смотреть в первую строчку («Предполагаются равные дисперсии»). Если меньше 0,05 – то во вторую («Не предполагаются равные дисперсии»).
Следующие столбцы – сам t-критерий Стьюдента. Если его значимость меньше 0,05 (столбец «Знач. Двухсторонняя»), то средние значения ваших выборок различаются. Если же больше 0,05, то таких различий обнаружено не было.
Если вы хотите узнать, у какой группы соответствующий показатель больше, смотрите в таблицу «Статистика группы» (столбец «Средние»).

