Книга: Путеводитель для влюбленных в математику
Назад: Глава 11 Закон Бенфорда
Дальше: Часть II Геометрические фигуры
Глава 12
Алгоритм
Шеф-повара с фантазией редко руководствуются точными рецептами. Скорее, они следуют за вдохновением. А повара-новички покорно выполняют все указания поваренных книг.
Точно так же водителям с хорошей ориентацией на местности не нужны карты или детальные инструкции, как добраться до места назначения. А неопытным автомобилистам необходимы пошаговые указания.
В этом плане компьютеры похожи на новичков. Скажем, если нужно сложить несколько чисел, они скрупулезно выполняют операцию за операцией, руководствуясь инструкциями программистов. Эти инструкции называют алгоритмами. Компьютерные алгоритмы окружают нас повсюду: они высчитывают проценты для банков, определяют разрывы страниц в текстовых документах, превращают цифровые данные на DVD-диске в кино, предсказывают погоду, рыщут по интернету в поисках рецепта, включающего заданные ингредиенты, и дают советы, сверяясь со спутниками GPS, когда мы ищем дом с хитрым адресом.
Первый математический алгоритм, который изучает большинство людей, – как складывать числа. Когда нужно просуммировать в столбик 25 и 18, мы знаем: вначале нужно к 5 прибавить 8 (и запомнить результат: 13), записать 3 в колонке единиц, а 1 держать в уме. Затем сложить 2 и 1, увеличить результат на 1 и записать 4 в колонке десятков. Получится 43.
Разработчикам алгоритмов недостаточно записать корректную процедуру решения проблемы, им важно, чтобы найденный метод был эффективен. Если алгоритм корректен с математической точки зрения, но требует тысячелетий для осуществления, пользы от него немного. Приглядимся к нескольким примерам.
Сортировка
В конце каждого семестра у меня накапливается груда проверенных домашних заданий, которые необходимо вернуть студентам. Когда они заходят ко мне в кабинет за своими работами, у меня нет ни малейшего желания копаться в этой свалке, чтобы найти конкретную тетрадку. Конечно же, я сортирую все работы по алфавитному списку студентов. Прежде чем я объявлю, что проверенные тетради можно забирать, их необходимо систематизировать.
Итак, перед нами встает проблема: имеется стопка тетрадей, перемешанных в хаотичном порядке, необходимо разложить их по алфавиту. Как это сделать наилучшим образом?
Начнем с простой, но неэффективной идеи. Допустим, у меня учится 100 студентов. Я беру из стопки первую тетрадку и смотрю, должна ли она идти первой по алфавиту. Каким образом? Я сравниваю имена на всех тетрадках с именем на этой тетрадке. Если не повезло и тетрадка по алфавиту не первая, я кладу ее в самый низ стопки и начинаю сначала. Я стану действовать так, пока не обнаружу первую по алфавиту тетрадку. Тогда я переложу ее в новую стопку, где тетрадки будут лежать упорядоченным образом.
Дальше я вернусь к неупорядоченной стопке – сейчас там 99 тетрадей – и, как и раньше, начну искать первую по алфавиту тетрадку. Я возьму тетрадку сверху, сравню со всеми остальными и положу в самый низ стопки, если она не подойдет. Когда я найду искомую тетрадку, я положу ее во вторую стопку снизу.
Теперь у меня есть «всего-навсего» 98 тетрадей, и я повторяю все по новой: ищу первую по алфавиту тетрадь и кладу ее в низ второй стопки.
Сколько времени это займет?
Основная операция заключается в том, чтобы сравнить два имени и решить, какое следует первым по алфавиту. Мы будем оценивать эффективность алгоритма по количеству сравнений, которые необходимо провести. У меня 100 учащихся; как долго мне придется сопоставлять имена и решать, какое идет первым?
В неупорядоченной стопке из 100 тетрадей я сравниваю первую с 99 остальными. Необходимо проделать эту операцию со всеми 100 тетрадями (не исключено, что искомая лежит в самом конце). Поиск первой по алфавиту потребует максимум 100 × 99 = 9900 сопоставлений.
Я кладу свою находку во вторую стопку и повторяю процедуру с 99 неотсортированными тетрадями. Я сравниваю верхнюю тетрадь с 98 оставшимися. Поиск второй по алфавиту тетради потребует максимум 99 × 98 = 9702 сопоставления.
Третья тетрадь потребует максимум 98 × 97 сравнений, четвертая – максимум 97 × 96. Не исключено, что придется проделать 100 × 99 + 99 × 98 + 98 × 97 + … + 2 × 1 = 333 300 сравнений.
Мы проанализировали худший случай. На каждой итерации мы нашли максимум из возможного числа операций и посчитали, сколько их всего потребуется. Несомненно, такой результат настраивает нас на пессимистический лад и показывает, насколько неэффективным был наш алгоритм. Давайте попробуем что-нибудь другое.
Мы снова начинаем со стопки из 100 тетрадей, перемешанных случайным образом. Берем первые две тетради. Если они идут не в правильном порядке, меняем их местами (первая станет второй, вторая – первой). Если порядок верный, оставляем все без изменений. Дальше смотрим на вторую и третью тетрадь. Если порядок верный, идем дальше. Если нет, меняем их местами. Так мы действуем по этому алгоритму, пока не доберемся до конца стопки. Один заход требует 99 сравнений.
Когда мы дойдем до конца стопки, тетради с именами из начала алфавита сместятся вверх, а тетради с именами в конце алфавита сместятся вниз. Но одного захода может быть недостаточно. В худшем случае первая по алфавиту тетрадь изначально лежала в самом низу, и в первом заходе мы переместили ее всего-навсего на 99-ю позицию. В этом случае сортировка потребует 99 операций.
Таким образом, нам придется проделать максимум 99 × 99 = 9801 операцию. Это гораздо лучше первого метода, но все еще неэффективно. Если сравнение и смена позиции требует двух секунд, я закончу спустя пять часов. Это никуда не годится.
И вот я в расстроенных чувствах выхожу из кабинета, чтобы развеяться. В коридоре я встречаю двух постдоков, которые работают под моим научным руководством. Зловещая улыбка змеится на моих губах. Я спешу обратно в кабинет, делю стопку неотсортированных тетрадей пополам и даю по 50 тетрадей каждому постдоку. «Вот вам стопка тетрадей, – говорю я. – Пожалуйста, рассортируйте их по алфавиту и принесите ко мне в кабинет, когда закончите». После чего с воодушевлением возвращаюсь к основной работе.
Мне предстоит доделать сортировку, когда постдоки выполнят задание. Нужно превратить две упорядоченные стопки в одну. Насколько это будет трудно? Допустим, у меня есть две стопки тетрадей в алфавитном порядке. Я смотрю на верхние тетради в той и другой стопке, выбираю первую по алфавиту и кладу в итоговую стопку. Диаграмма иллюстрирует процесс.
Когда одна из стопок иссякает, я просто-напросто кладу оставшуюся в конец итоговой стопки. В худшем случае придется проделать 99 операций. Это потребует всего несколько минут!
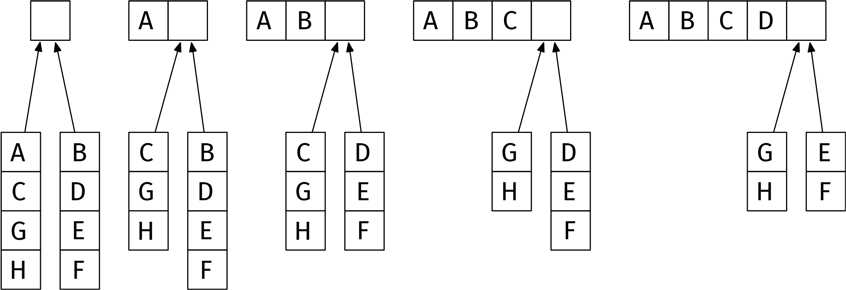
Но как насчет моих постдоков? У каждого стопка с 50 тетрадями. Постдоки – люди смышленые, поэтому не станут сортировать тетради самостоятельно. Они, в свою очередь, поделят свои стопки пополам (таким образом, в каждой окажется по 25 тетрадей) и передоверят сортировку аспирантам! Когда те закончат, постдокам останется соединить две отсортированные стопки по 25 тетрадей в одну общую по 50. Это потребует максимум 49 операций.
Но четыре аспиранта тоже не дураки. Они делят свои стопки на две части (в одной 12, в другой 13 тетрадей) и находят восемь старшекурсников, чтобы передоверить работу. В результате каждому аспиранту остается соединить две маленькие стопки и отдать их постдокам.
Как старшекурсники сортируют тетради? Несложно догадаться: они делят свои стопки на две части (в одной 6 тетрадей, в другой 7), ловят 16 третьекурсников и отдают им эти стопки. Те находят 32 второкурсника и отдают им раздербаненные стопки (в одних по 3, в других по 4 тетради). Наконец, второкурсники отлавливают 64 первокурсника и отдают им стопки по 1 и по 2 тетради. Первокурсникам делать нечего: они быстро сортируют свою часть и отдают обратно.
Очевидно, эта «схема Понци» экономит мое время, но насколько она эффективна в целом? Посмотрим, как много операций она потребует в худшем случае. Занесем все данные в таблицу:
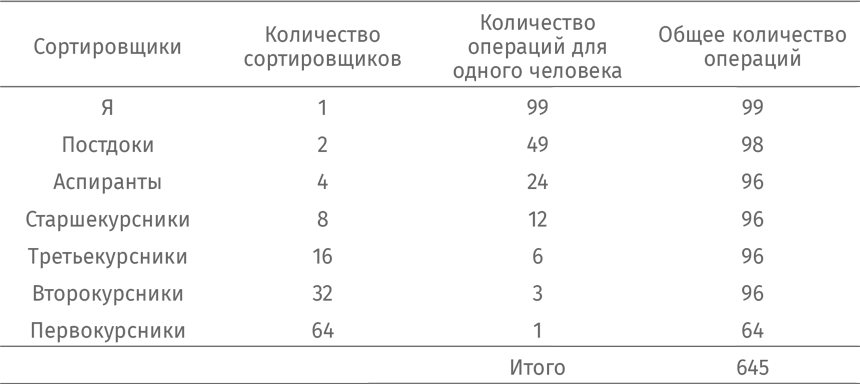
Максимальное количество операций оказывается существенно меньше, чем при сортировке пузырьковым методом.
К несчастью, в этой схеме есть изъян: у меня сейчас нет постдоков! Так что вместо вербовки целой армии помощников придется работать самому.
Для начала я найду большой незагроможденный стол. Я поделю стопку из 100 тетрадей пополам и положу две стопки по краям стола. Как я их отсортирую? По тому же алгоритму! Поделю две стопки по 50 тетрадей на четыре по 25, а их буду сортировать тем же методом. В худшем случае понадобится 645 операций. Правда, на сей раз мне придется действовать в одиночку. Однако это лучше, чем почти что 10 000 операций при сортировке пузырьковым методом.
Словарное определение не должно включать определяемого слова. Вообразите, что вы ищете в словаре слово оскудение и находите такое определение:
Оскудение: результат оскудения.
Что за чушь! Однако наш алгоритм сортировки и слияния грешит именно этой ссылкой на самого себя. Вот более точное определение.
Алгоритм сортировки и слияния
На входе: объекты a1, a2, a3, …, an.На выходе: те же объекты в отсортированном виде.1. Если n = 1, сортировка закончена. Пускаем данные на выход. В противном случае переходим к пункту 2.2. Поделить множество объектов на равные подмножества, если их количество четно, или на подмножества, отличающиеся на единицу, если количество нечетно. Использовать алгоритм сортировки и слияния.3. Соединить подмножества и пустить результат на выход.
Алгоритм, ссылающийся сам на себя, называют рекурсивным. В отличие от неудачного определения слова оскудение, наш алгоритм работает, потому что рано или поздно дойдет до конечной точки. Когда-нибудь множество объектов сведется к одному, и больше не придется проделывать процедуру заново. Поэтому нет опасности уйти в «бесконечный цикл».
Наибольший общий делитель
Каково наибольшее среди чисел, на которые нацело делятся одновременно 986 и 748? Простейший способ ответить на вопрос – перепробовать все варианты. Разумеется, 986 и 748 делятся на 1. Несложно видеть, что на 2 они тоже делятся. Но ни то ни другое число не делится на 3. Одно из них, 748, делится на 4, а другое нет. Нам «всего-навсего» нужно перебрать все делители и сравнить их. Мы остановимся после 748, потому что дальше числа не могут быть делителями 748. Наконец мы выясним, что у 748 и 986 четыре общих делителя: 1, 2, 17 и 34. Наибольший общий делитель 748 и 986 равен 34. Для любых положительных целых чисел a и b запись НОД (a, b) означает их наибольший общий делитель.
Описанный выше метод дает незамысловатый и неоспоримый алгоритм поиска наибольшего общего делителя. Его слабая сторона – неэффективность. Для поиска НОД двух трехзначных чисел придется перебрать сотни вариантов. Может быть, есть что-нибудь попроще?
Присмотримся к числам 986 и 748 повнимательней. Мы ищем наибольший общий делитель, поэтому естественно разложить оба числа на простые множители (см. главу 1). Вот результат:
986 = 2 × 17 × 29;748 = 2 × 2 × 11 × 17.
С помощью этого разложения на простые множители мы можем найти НОД, пуская в дело все простые числа, на которые делятся оба наших числа. Оба делятся на 2 и на 17, потому наибольший общий делитель очевидным образом равен 2 × 17 = 34.
Как разложить число на простые множители самым эффективным способом? Ответ неутешителен: мы этого не знаем (как уже отмечалось в главе 1). Нам нужна идея получше.
Еще одну идею нам подсказал Евклид. Допустим, d – общий делитель 986 и 748. Это означает, что
986 = xd, 748 = yd,
где x и y – целые числа. Следовательно, d также является делителем разности 986 – 748. Это следует из нехитрых алгебраических выкладок:
986 – 748 = xd – yd = (x – y) d.
Так как x и y целые числа, их разность тоже целое число. Потому разность 986 и 748 тоже нацело делится на d. Заметим, что 986–748 = 238.
Точно так же общий делитель 748 и 238 является делителем 986. Почему? Если e – общий делитель 748 и 238, то
748 = ue, 238 = ve,
где u и v – целые числа. Таким образом,
986 = 748 + 238 = ue + ve = (u + v) e,
откуда мы делаем заключение, что e – делитель 986.
Вывод: общие делители 986 и 748 являются также общими делителями 748 и 238. Для иллюстрации запишем делители всех трех чисел, подчеркивая общие делители:
делители 986 → 1, 2, 17, 29, 34, 58, 493, 986;
делители 748 → 1, 2, 4, 11, 17, 22, 34, 44, 68, 187, 374, 748;
делители 238 → 1, 2, 7, 14, 17, 34, 119, 238.
Отсюда следует, что
НОД (986, 748) = НОД (748, 238). (A)
Таким образом, поиск наибольшего общего делителя 986 и 748 свелся к поиску наибольшего общего делителя 748 и 238. Прогресс, теперь мы имеем дело с числами поменьше. Проделаем то же самое еще раз.
Если некое d – общий делитель 238 и 748, оно также делитель их разности. Этим дело не ограничивается. Мы можем вычесть 238 из 748 несколько раз, и d будет оставаться делителем разностей. Точнее говоря, если 238 и 748 делятся на d, разность 748 – 3 × 238 тоже делится на d. Обратимся к алгебре, чтобы доказать это.
748 = xd, 238 = yd,
где x и y – целые числа. Следовательно,
748 – 3 × 238 = xd – 3yd = (x – 3y) d.
Таким образом, d – делитель 748 – 3 × 238 = 34. И наоборот: если e – делитель 34 и 238, это также делитель 748. Вернемся к алгебре.
238 = ue, 34 = ve,
где u и v – целые числа. Таким образом,
748 = 3 × 238 + 34 = 3ue + ve = (3u + v) e.
Таким образом, e – делитель 748. Следовательно, у 748, 238 и 34 есть общие делители, и мы можем сделать вывод, что
НОД (748, 238) = НОД (238, 34). (B)
На основе тождеств (A) и (B) мы имеем:
НОД (986, 748) = НОД (748, 238) = НОД (238, 34).
Мы почти у цели. Обратим внимание, что 238 делится на 34 (потому что 238 = 34 × 7), и поэтому НОД (238, 34) = 34. Финальный аккорд:
НОД (986, 748) = НОД (748, 238) = НОД (238, 34) = 34.
Подытожим: через какие этапы мы пришли к этому результату? Мы вычли 748 из 986 и получили 238. Мы трижды вычли 238 из 748. Почему мы совершили одну операцию вычитания в первом случае и три операции во втором? Мы хотели свести задачу к операциям с как можно меньшими числами, потому что так удобнее. Поэтому мы вычитали меньшее число из большего до упора. Заметим: 748 умещается в 986 всего один раз, и разница между ними равна 238. Однако 238 умещается внутри 748 три раза, и остаток равен 34. Мы можем вычесть 748 из 986 всего один раз, и в то же время мы можем вычесть 238 из 748 три раза.
Теперь мы обобщим этот пример и построим алгоритм вычисления наибольшего общего делителя для двух целых положительных чисел. Нам даны два целых положительных числа a, b, и мы хотим определить НОД (a, b). При этом a больше b. Мы должны вычесть b из a как можно большее число раз. Чтобы выяснить, сколько именно, поделим a на b. Мы получим частное q и остаток c. На языке алгебры:
a – qb = c.
Если окажется, что b – делитель a, тогда остаток будет равен нулю. В ином случае c больше нуля и меньше b (если бы c оказалось больше b, мы смогли бы вычесть b из a еще раз).
Теперь предположим, что d – общий делитель a и b. Тогда
a = xd, b = yd,
где x и y – целые числа. Следовательно,
c = a – qb = xd – q (yd) = (x – qy) d,
и c тоже без остатка делится на d (потому что x – qy входит в множество целых чисел).
С другой стороны, если e – общий делитель b и c, тогда
b = ue, c = ve,
где u и v – целые числа. Следовательно,
a = c + qb = ve + q (ue) = (v + qu) e,
и e – еще и делитель a.
Итак, мы доказали, что общие делители a и b совпадают с общими делителями b и c. Таким образом,
НОД (a, b) = НОД (b, c). (C)
Посмотрим, как тождество (C) позволит нам эффективно вычислить наибольший общий делитель двух больших целых чисел: a = 10 693 и b = 2220.
Мы делим a на b и видим, что 2220 умещается в 10 693 четыре раза, при этом остаток c = 1813. Следовательно,
НОД (10 693, 2220) = НОД (2220, 1813).
Переходим к следующей итерации. Введем обозначения a' = 2220 и b' = 1813. Поделим a' на b' и увидим, что 1813 умещается в 2220 всего один раз и остаток c' = 407. На основании тождества (C)
НОД (10 693, 2220) = НОД (2220, 1813) = НОД (1813, 407).
На новом шаге a'' = 1813 и b'' = 407. После деления мы обнаружим, что 407 умещается внутри 1817 четыре раза и остаток c'' = 185. Опять-таки на основании (C)
НОД (10 693, 2220) = НОД (2220, 1813) = НОД (1813, 407) = НОД (407, 185).
На сей раз мы имеем дело с числами a''' = 407 и b''' = 185. Деление показывает, что 185 умещается внутри 407 два раза и остаток равен c''' = 37. Таким образом,
НОД (10 693, 2220) = НОД (2220, 1813) = НОД (1813, 407) = НОД (407, 185) = НОД (185, 37).
Мы почти у цели! Делим a'''' = 185 на b'''' = 37 и – подумать только! – получаем ровно 5. Следовательно, НОД (185, 37) = 37. Завершаем наши выкладки:
НОД (10 693, 2220) = НОД (2220, 1813) = НОД (1813, 407) = НОД (407, 185) = НОД (185, 37) = 37.
Мы нашли наибольший общий делитель 10693 и 2220, проделав всего пять операций деления!
Алгоритм Евклида для поиска наибольшего общего делителя можно сформулировать так:
Поиск НОД: алгоритм Евклида
На входе: два положительных целых числа a и b.На выходе: НОД (a, b).1. Найти частное q и остаток c при делении a на b.2. Если c = 0, то НОД (a, b) = b.3. В противном случае вычислить НОД (b, c) = НОД (a, b).
Проверьте, насколько хорошо вы усвоили алгоритм Евклида, и вычислите НОД (1309, 1105). Можете воспользоваться калькулятором. Сверьтесь с ответом в конце главы.
Наименьшее общее кратное
Концепция наибольшего общего делителя тесно связана с концепцией наименьшего общего кратного. Для двух положительных целых чисел (допустим, 10 и 15) наименьшее общее кратное – это самое маленькое положительное целое число, которое делится на то и на другое; в нашем случае ответ равен 30. Мы будем использовать обозначение НОК (a, b).
Наименьшее общее кратное полезно при сложении дробей. Например, для сложения 1/10 и 1/15 вначале нужно привести обе дроби к общему знаменателю. Это может быть любое число, которое делится на 10 и на 15; проще всего найти НОК. Так как НОК (10, 15) = 30, то
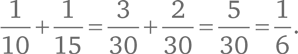
Найти наименьшее общее кратное для маленьких чисел не слишком сложно, но как быть с большими числами? Скажем, чему равно наименьшее общее кратное 364 и 286?
Один вариант состоит в том, чтобы последовательно выписывать числа, кратные первому и второму, и уповать, что рано или поздно они совпадут:
числа, кратные 364 → 364, 728, 1092, 1456, 1820, 2184, …числа, кратные 286 → 286, 572, 858, 1144, 1430, 1716, 2002, …
Вскоре мы дойдем до 4004 и запишем ответ: НОК (364, 286) = 4004.
Вот еще одна идея. Разложим 364 и 286 на простые множители:
364 = 2 × 2 × 7 × 13;286 = 2 × 11 × 13.
Числа, кратные 364, должны делиться на 2 × 2 × 7 × 13, а числа, кратные 286, должны делиться на 2 × 11 × 13. При конструировании наименьшего общего кратного мы должны воспользоваться этими простыми числами – два раза по 2, затем 7, 11 и 13 (нам ни к чему брать два раза по 13):
2 × 2 × 7 × 11 × 13 = 4004.
Разумеется, 4004 и есть наименьшее общее кратное 364 и 286.
Этот метод выглядит потрясающе, однако – как я уже объяснил в главе 1 – мы не знаем эффективного алгоритма разложения больших чисел на простые множители.
Хотя разложение на простые множители не дает достаточно эффективного алгоритма вычисления НОК двух чисел, оно делает важную подсказку. Давайте сравним, как используется разложение на множители при вычислении НОК и НОД.
Вот семь простых множителей двух чисел, взятые вместе:
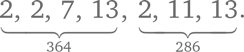
Мы находим НОД (364, 286) с помощью двух общих простых делителей: 2 и 13.
Для вычисления НОК (364, 286) нам нужны все простые числа в двух списках, хотя нет нужды брать два раза по 13 (достаточно одного) и три раза по 2 (достаточно двух). Иными словами, мы берем каждое простое число из того списка, где оно встретилось большее число раз. Таким образом, нам нужны пять чисел: 2, 2, 7, 11 и 13.
Проверяем:
НОД (364, 286) = 26 = 2 × 13;НОК (364, 286) = 4004 = 2 × 2 × 7 × 11 × 13.
Заметим, что при подсчете НОК мы выкинули именно те числа, которые нужны для вычисления НОД:
Иначе говоря,
364 × 286 = (2 × 2 × 7 × 13) × (2 × 11 × 13) = (2 × 2 × 7 × 11 × 13) × (2 × 13) = НОК (364, 286) × НОД (364, 286).
Мы можем обобщить этот пример. Для любых двух целых положительных чисел a и b
a × b = НОК (a, b) × НОД (a, b).
Таким образом,
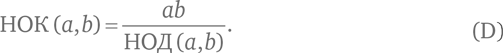
Так как алгоритм Евклида позволяет эффективно вычислить наибольший общий делитель двух чисел, он также годится – с учетом тождества (D) – для эффективного вычисления наименьшего общего кратного.

Назад: Глава 11 Закон Бенфорда
Дальше: Часть II Геометрические фигуры

