Книга: Десять уравнений, которые правят миром. И как их можете использовать вы
Назад: Глава 6. Уравнение рынка
Дальше: Глава 8. Уравнение вознаграждения
Глава 7. Уравнение рекламы
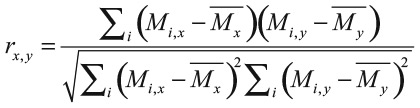
Сначала я подумал, что это электронное письмо – спам. Оно начиналось с приветствия: «Мистер Самптер:», а в мире мало реальных людей, которые используют двоеточие в начале письма. Даже когда я прочитал текст – просьбу комитета по предпринимательству, науке и транспорту Сената США в Вашингтоне, округ Колумбия, о беседе со мной, – я оставался скептиком. Странным показался уже сам факт, что просьба пришла в форме электронного письма. Не знаю, чего стоило ожидать, но я с подозрением отнесся к соседству длинного и подробного названия комитета и неформального обращения за помощью. Не сходилось.
Однако все было правильно. Комитет Сената действительно хотел побеседовать со мной. Я отправил короткий положительный ответ, и через несколько дней мы общались по скайпу с людьми из республиканской части комитета. Они желали узнать о компании Cambridge Analytica, которую Дональд Трамп нанял для обращения к избирателям в соцсетях и которая предположительно собирала данные о десятках миллионов пользователей Facebook. В СМИ уже имелись две стороны истории Cambridge Analytica. Одна сторона – блестящее представление Александра Никса, тогдашнего CEO, который заявлял, что использует алгоритмы в политических кампаниях для микротаргетинга. Другая – разоблачитель Крис Уайли с крашеными волосами, который утверждал, что помогал Никсу и его компании создать инструмент для «психологической войны». Впоследствии Уайли сожалел о своих действиях, которые позволили избрать Трампа, а Никс создавал свой бизнес в Африке, опираясь на свой «успех».
В 2017 году, за год до скандала, я детально исследовал алгоритм, который использовала Cambridge Analytica, и пришел к заключению, противоречащему обеим версиям событий – и Никса, и Уайли. Я сомневался, что компания могла повлиять на президентские выборы в США. Она, конечно, пыталась, но я обнаружил, что методы, которые, по их словам, использовались для таргетинга избирателей, были с изъяном. Мои заключения привели к странной ситуации, когда я оспаривал оба имеющихся варианта изложения. Вот почему комитет Сената желал поговорить со мной. Больше всего республиканцы из администрации Трампа весной 2018 года хотели узнать, что делать с грандиозным скандалом вокруг рекламы в социальных сетях.
* * *
Прежде чем мы сможем помочь сенаторам, нам нужно понять, как нас видят создатели соцсетей. Для этого мы будем рассматривать людей как наблюдения (так делают и компании) и начнем с самых активных и важных: подростков. Эта группа желает увидеть как можно больше и как можно быстрее. Каждый вечер можно наблюдать, как они – либо вместе на диване, либо (всё чаще) в одиночестве в спальне – быстро щелкают и листают странички на своих любимых платформах в соцсетях: Snapchat и Instagram. Через окошко своих телефонов они могут видеть невероятные картины мира: гномов, падающих со скейтбордов; пары, идущие на свидания «правда или действие»; собак, играющих в Fortnite; маленьких детей, сующих руки в пластилин Play-Doh; девочек-подростков, стирающих макияж; или «сцепленные» истории из текстовых диалогов между воображаемыми студентами колледжа. Они перемежаются сплетнями о знаменитостях, крайне редкими реальными новостями и, конечно, регулярной нескончаемой рекламой.
Внутри Instagram, Snapchat и Facebook создается матрица наших интересов. Это набор чисел в виде таблицы, где в строках – люди, а в столбцах – типы «постов» или «снимков», на которые они нажимают. В математике мы представляем таблицу подростковых кликов в виде матрицы, которую обозначим M. Вот пример для иллюстрации в гораздо меньшем масштабе: так выглядит матрица некой соцсети для двенадцати пользователей.
Каждое число в матрице показывает, сколько раз подросток кликнул по конкретному типу постов. Например, Мэдисон посмотрела 8 постов о еде, по 6 о косметике и Кайли Дженнер, ни одного о ютьюбере Пьюдипае и видеоигре Fortnite и 2 публикации о рэпере Дрейке.
Просто глядя на эту матрицу, мы можем получить хорошее представление о том, что за человек Мэдисон. Попробуйте представить ее себе, а потом потратьте несколько секунд, чтобы вообразить некоторых других персонажей, которых я ввел здесь, используя в качестве ориентиров просмотренные ими снимки. Не беспокойтесь. Это не настоящие люди. Вы можете быть сколь угодно категоричными.
В матрице есть еще несколько человек, похожих на Мэдисон. Например, Сэм любит косметику, Кайли Дженнер и еду, но проявляет незначительный интерес к другим категориям. Есть и люди, которые резко отличаются от Мэдисон. Джейкоб, как и Лорен, предпочитает Пьюдипая и Fortnite. Некоторые не совсем вписываются в два этих типа. Скажем, Тайлер любит Дрейка и косметику, но интересуется Пьюдипаем.
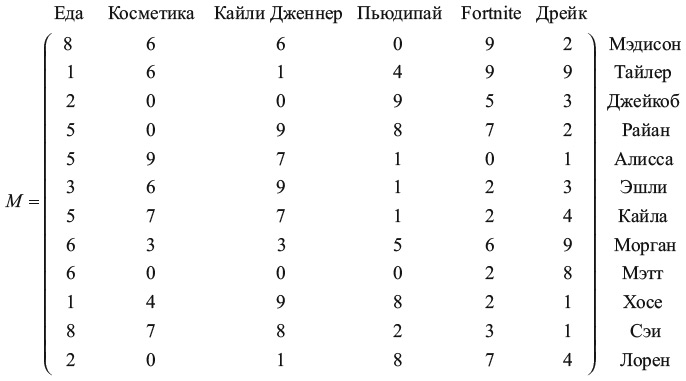
Уравнение рекламы – математический способ автоматически определять тип людей. Оно имеет следующую форму:
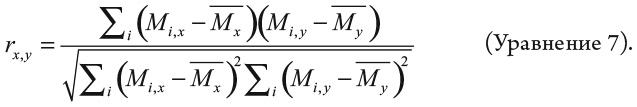
Оно измеряет корреляцию между различными категориями снимков. Например, если люди, которые обычно ставят лайк Кайли Дженнер, также ставят лайк и косметике, то rкосметика, Кайли будет положительным числом. В этом случае мы говорим, что существует положительная корреляция между Кайли и косметикой. Но если люди, которые ставят лайки Кайли, обычно не ставят их Пьюдипаю, rПьюдипай, Кайли будет отрицательным числом, и мы назовем это отрицательной корреляцией.
Чтобы понять, как работает уравнение 7, разберем его шаг за шагом начиная с Mi,x. Это число в строке i и столбце x нашей матрицы M. Мэдисон 6 раз просматривала посты о косметике, поэтому MМэдисон, косметика = 6: у нас строка i = Мэдисон, а столбец x = косметика. В общем случае каждый раз, когда мы смотрим на число в строке i и столбце x матрицы, то видим Mi,x. Взглянем на 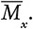 Эта величина – среднее число постов в категории x, приходящееся на одного пользователя. Например, среднее число просмотренных публикаций о косметике для наших подростков таково:
Эта величина – среднее число постов в категории x, приходящееся на одного пользователя. Например, среднее число просмотренных публикаций о косметике для наших подростков таково: 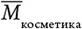 = (6 + 6 + 0 + 0 + 9 + 6 + 7 + 3 + 0 + 4 + 7 + 0)/12 = 4.
= (6 + 6 + 0 + 0 + 9 + 6 + 7 + 3 + 0 + 4 + 7 + 0)/12 = 4.
Эта величина – среднее число постов в категории x, приходящееся на одного пользователя. Например, среднее число просмотренных публикаций о косметике для наших подростков таково: = (6 + 6 + 0 + 0 + 9 + 6 + 7 + 3 + 0 + 4 + 7 + 0)/12 = 4.Если мы вычтем среднюю заинтересованность в косметике из общего числа публикаций, просмотренных Мэдисон, то получим Mi,x – 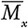 = 6–4 = 2. Это говорит нам, что Мэдисон интересуется косметикой выше среднего. Аналогично, вычислив
= 6–4 = 2. Это говорит нам, что Мэдисон интересуется косметикой выше среднего. Аналогично, вычислив 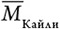 = 5, мы видим, что она также (слегка) выше среднего интересуется Кайли Дженнер, поскольку Mi,y –
= 5, мы видим, что она также (слегка) выше среднего интересуется Кайли Дженнер, поскольку Mi,y – 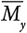 = 6–5 = 1, если i = Мэдисон, а y = Кайли.
= 6–5 = 1, если i = Мэдисон, а y = Кайли.
= 6–4 = 2. Это говорит нам, что Мэдисон интересуется косметикой выше среднего. Аналогично, вычислив = 5, мы видим, что она также (слегка) выше среднего интересуется Кайли Дженнер, поскольку Mi,y – = 6–5 = 1, если i = Мэдисон, а y = Кайли.А теперь переходим к мощной интересной идее, лежащей в основе уравнения 7: если мы перемножим (Mi,x – ) ∙ (Mi,y – ), то определим те интересы, которые, как правило, у людей общие. Для Мэдисон мы получаем:
) ∙ (Mi,y – ), то определим те интересы, которые, как правило, у людей общие. Для Мэдисон мы получаем:= (6–4) ∙ (6–5) = 2 ∙ 1 = 2.
Это говорит нам о том, что между ее интересом к Кайли и косметике существует положительная корреляция.
Для Тайлера взаимоотношения между косметикой и Кайли отрицательные – (6–4) ∙ (1–5) = 2 ∙ (–4) = –8, – поскольку он проявляет интерес только к первой. Для Джейкоба величина снова положительна: (0–4) ∙ (0–5) = (–4) ∙ (–5) = 20, так как ему не нравятся ни первая, ни вторая (см. рис. 7). Обратите внимание на один нюанс. И у Джейкоба, и у Мэдисон положительное значение, хотя у них противоположные взгляды на Кайли и косметику. Однако их взгляды предполагают, что Кайли и косметика коррелируют между собой, хотя Джейкоб вообще никогда не смотрел ни на ту ни на другую. Поведение Тайлера в социальной сети не соответствует такой закономерности.
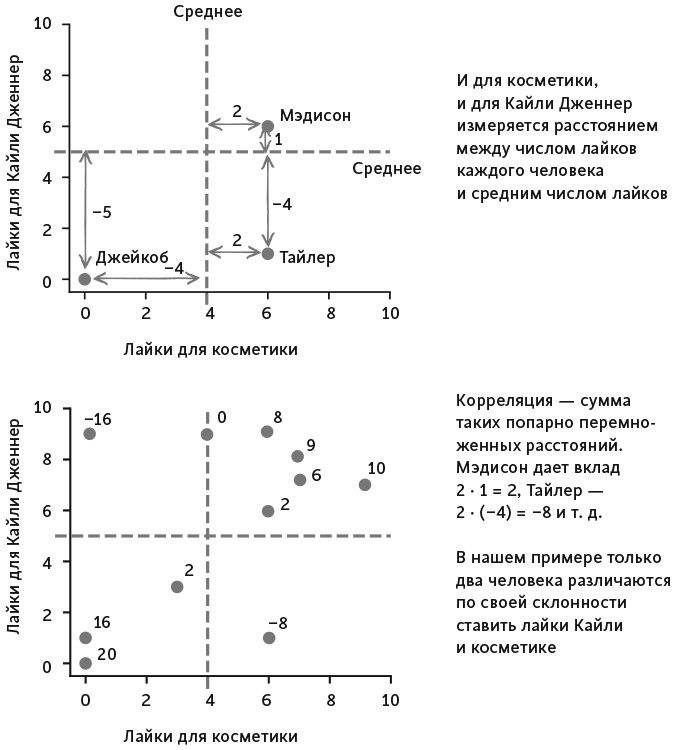
Рис. 7. Иллюстрация к вычислению корреляции между Кайли и косметикой
Мы можем произвести расчеты для каждого из подростков и сложить все такие величины. Получится сумма
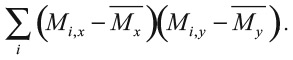
Знак Σi указывает, что мы берем сумму по всем двенадцати тинейджерам. Сложив все произведения, где перемножены отношения подростков к косметике и к Кайли, получим:
2 – 8 + 20–16 + 10 + 8 + 6 + 2 + 20 + 0 + 9 + 16 = 69.
Большая часть слагаемых положительна: это показывает, что дети имеют схожее отношение к Кайли и косметике. Среди тех, кто вносит свой положительный вклад в сумму, – Мэдисон и Джейкоб: 2 и 20 соответственно. Исключения – Тайлер, которому не нравится Кайли, и Райан, которому не нравится косметика; зато Кайли Дженнер по душе. Именно эта пара дала слагаемые –8 и – 16.
Математики не любят больших чисел вроде 69. Мы предпочитаем, чтобы они были меньше, лучше между 0 и 1, так их удобно сравнивать. Для этого мы добавим в уравнение 7 знаменатель (нижнюю часть дроби). Я не стану подробно разбирать это вычисление, но если мы подставим все наши числа, то получим
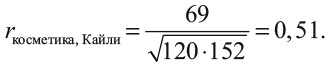
Мы получили одно-единственное число 0,51, которое измеряет корреляционную зависимость между косметикой и Кайли. Значение 1 показывало бы идеальную корреляцию между этими двумя типами постов, значение 0 говорило бы об отсутствии связи. Так что реальное значение 0,51 дает нам среднюю корреляцию между любовью к косметике и к Кайли Дженнер.
Я понимаю, что провел уже довольно много вычислений, но мы нашли только одно из пятнадцати важных чисел, отражающих предпочтения подростков! Нам бы хотелось узнать корреляцию не только между косметикой и Кайли, но и между всеми категориями: еда, косметика, Кайли, Пьюдипай, Fortnite и Дрейк. К счастью, мы уже в курсе, как вычислить один коэффициент корреляции с помощью уравнения 7, – остается только подставлять в это уравнение каждую пару категорий. Именно это я сейчас и сделаю. Получится то, что известно под названием корреляционной матрицы, которую мы обозначим как R. Если вы посмотрите на пересечение строки «Кайли» и столбца «Косметика», то увидите найденное нами ранее число 0,51. Точно так же заполняются и остальные строки матрицы – для всех пар категорий. Например, Fortnite и Пьюдипай дают корреляцию 0,71. Но есть и такие пары, как Fortnite и косметика, которые дают коэффициент –0,74, то есть коррелируют отрицательно. Это означает, что геймеры, как правило, не особо интересуются косметикой.
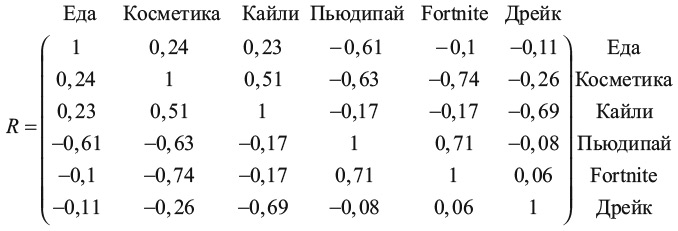
Корреляционная матрица группирует людей по типам. Когда я просил вас представить себе этих подростков и не стесняться быть категоричными, я предлагал вам самим построить такую матрицу. Корреляция Кайли/косметика относит к одному типу таких подростков, как Мэдисон, Алисса, Эшли и Кайли, а корреляция Пьюдипай/Fortnite относит к другой группе Джейкоба, Райана, Моргана и Лорен. А вот Тайлер и Мэтт не вполне подходят под такую простую категоризацию.
В мае 2019 года я спрашивал Дуга Коэна, специалиста по данным из Snapchat, о той информации о пользователях, которую они хранят в корреляционных матрицах. «Ну, это почти всё, что вы делаете в Snapchat, – отвечал он. – Мы смотрим, как часто наши пользователи разговаривают в чатах с друзьями, сколько у них полос общения, какими фильтрами пользуются, как долго разглядывают карты, в скольких групповых чатах сидят, сколько времени тратят на просмотр контента или когда читают истории своих друзей. И мы смотрим, как эти действия коррелируют друг с другом».
Данные анонимны, поэтому Дуг не знает, чем занимаетесь конкретно вы. Но такие корреляции позволяют Snapchat категоризировать пользователей – от «одержимых селфи» и «документалистов» до «див макияжа» и «королев фильтров», если пользоваться внутренней терминологией компании.
Как только компания узнаёт, что привлекает определенного пользователя, она дает ему это в большом количестве. Слушая, как Дуг описывает свою работу по привлечению людей, я не мог не прокомментировать: «Погодите! Я, как родитель, стараюсь, чтобы мои дети пользовались телефоном меньше, а вы трудитесь, чтобы повысить их вовлеченность!»
Дуг парировал, слегка уколов конкурентов: «Мы не просто стараемся максимизировать время, проведенное в приложении, как традиционно делал Facebook. Мы следим за уровнем участия, смотрим, как часто пользователи возвращаются. Мы помогаем им общаться с друзьями».
Snapchat не претендует на то, чтобы мои дети проводили у них всё свое время, но компания желает, чтобы они снова и снова возвращались. И по личному опыту могу сказать, что это работает.
* * *
Большинство хотели бы, чтобы их уважали как личностей, а не изображали в виде каких-то стандартных типов. Уравнение 7 полностью игнорирует наши желания. Оно сводит нас к корреляциям между вещами, которые нам нравятся.
Математики, работающие в Facebook, осознали силу корреляций еще на ранних стадиях разработки платформы. Каждый раз, когда вы ставите лайк на странице или комментируете какую-то тему, ваши действия предоставляют соцсети сведения о вас как о личности. Со временем Facebook стал использовать эти сведения иначе. В 2017 году, когда я впервые начал наблюдать, как аналитики отслеживают наши действия, категории казались забавными: среди коробок, по которым нас раскладывали, были «Брит-поп», «королевские свадьбы», «буксиры», «шея» или «верхушка среднего класса».
Такие категории оставляли у многих пользователей Facebook ощущение дискомфорта, и, что важнее для выгоды компании, они не были полезны рекламодателям. К 2019 году Facebook пересмотрел свою категоризацию, сделав ее более ориентированной на конкретный продукт. Знакомства, воспитание, архитектура, ветераны войн, защита окружающей среды – вот некоторые из нескольких сотен категорий, которые использует компания для описания пользователей.
Одна из возможных реакций на такую типизацию – говорить, что все это неправильно, и кричать: «Я не наблюдение, не точка данных, я человек, личность!» Не хочу вас огорчать, но вы не так уникальны, как вам может показаться. Вас разоблачает то, как вы ведете себя в интернете. Есть и другие люди с тем же сочетанием интересов, что и у вас, с тем же любимым фильтром для фотографий, которые делают столько же селфи, что и вы, подписаны на тех же знаменитостей и щелкают по той же рекламе. По сути, это не один человек, а много людей, объединенных Facebook, Snapchat или другими используемыми приложениями.
Бессмысленно расстраиваться или сердиться на то, что вы наблюдение в матрице. Вы должны принять это. Чтобы понять почему, необходимо подумать о группировании людей с какой-нибудь другой точки зрения, об ином способе разделения на категории.
Представьте, что матрица M содержит не социальные интересы Мэдисон, Тайлера и других детей, а их гены. Современные генетики действительно рассматривают нас как отдельные наблюдения: матрицы из 1 и 0, которые указывают, есть ли у нас определенные гены. Взгляд на людей с помощью такой корреляционной матрицы спасает жизни. Этот подход позволяет ученым определять причину заболеваний, подбирать лекарства, подходящие для вашей ДНК, и лучше понимать развитие различных форм рака.
Это также помогает нам ответить на вопросы о наших предках. Ной Розенберг со своими коллегами из Стэнфордского университета построили матрицу из 4199 различных генов и 1056 людей со всего мира. Для любого из этих генов в исследовании найдутся минимум два человека, у которых они отличны. Это важно, поскольку у всех людей есть множество общих генов (они делают нас людьми). Розенберг специально искал различия между людьми и то, как на них влияет место рождения и проживания. Чем африканцы отличаются от европейцев? А выходцы из разных частей Европы? Можно ли объяснить различия в генах тем, что мы обычно называем расой?
В поисках ответа Ной сначала использовал уравнение 7, чтобы найти корреляцию между людьми в терминах общих генов. Затем он применил метод, который называется дисперсионным анализом (ANOVA, от Analysis of Variance), чтобы посмотреть, объясняются ли эти различия географическим местом происхождения. На такой вопрос не бывает ответов «да» или «нет». ANOVA дает ответ в виде определенного процентного соотношения – от 0 до 100 процентов. Хотите попробовать угадать, какая часть нашей генетики объясняется нашими предками? 98 процентов? 50? 30? 80?
Ответ – примерно 5–7 процентов. Не больше. Результаты Ноя подтверждены и другими исследованиями. Да, некоторые гены создают весьма заметные изменения между расами, самые яркие примеры – гены, регулирующие производство мелатонина и цвет кожи. Но когда дело доходит до категоризации людей, концепция расы приводит к путанице. Географическое происхождение наших предков не объясняет различия между нами.
Возможно, с моей стороны слегка снисходительно объяснять наивность расовой биологии в XXI веке, но, к сожалению, некоторые верят, что определенные расы по своей природе обладают, например, сниженным интеллектом. Эти люди расисты, и они ошибаются. Есть и другие типы – «Я не расист, но…» – которые считают, что признание равенства между расами нам навязано учителями или обществом. Одним из таких людей был ушедший на пенсию профессор, который писал для Quillette (см. ). Они считают, что мы подавляем дискуссии о различиях между расами ради политкорректности.
По сути, место, откуда пришли наши предки, отвечает только за крохотную часть разнообразия наших генов. Более того, гены не полностью определяют нашу личность. Наши ценности и поведение формируются опытом и встреченными людьми. То, кем мы стали, имеет мало общего с биологической расой или нашими предками.
Люди, не достигшие двадцати лет, – как мои воображаемые тинейджеры Джейкоб, Алисса, Мэдисон и Райан, – представляют новое поколение Z, следующее за миллениалами. Для них крайне важно быть личностями. Они явно не желают, чтобы на них смотрели с точки зрения гендера или сексуальной ориентации. Один из опросов 300 представителей поколения Z в США показал, что только 48 % из них идентифицировали себя как абсолютных гетеросексуалов, а треть опрошенных предпочли отвести себе место на шкале бисексуальности. Более трех четвертей согласились с утверждением, что «гендер не определяет человека в той степени, как раньше». Можно слышать, как моя возрастная группа – поколение X – выражает скептицизм по поводу «отказа» поколения Z видеть гендерные различия. Опять же есть мнение, что представители Z пытаются быть политкорректными и при этом отрицают биологические факты.
Существует другой способ увидеть эту смену поколений. У поколения Z гораздо больше информации, чем было в молодости у моего поколения. «Иксы» росли в рамках ограниченного количества типов, предоставленных телевидением и умеренным личным опытом, а «зеты» засыпаны примерами разнообразия и индивидуальности.
Поколение Z считает эту индивидуальность более важной, чем поддержание гендерных стереотипов.
Успех рекламных категорий Facebook, основанный на корреляции наших интересов, предполагает, что взгляд поколения Z на мир статистически правильный. Дуглас Коэн, который работал в рекламной службе Facebook до перехода в Snapchat, рассказал мне, что рекламодатели его бывшего работодателя конкурируют друг с другом за гипертаргетинг своей рекламы по небольшим группам по интересам, определенным в матрице корреляций компании. Цена за охват целевой аудитории может удваиваться или утраиваться, поскольку рекламодатели конкурируют за право общаться непосредственно с любителями рукоделия, боевиков, серферами, игроками в онлайн-покер и многими другими группами. Для рекламодателей идентификация людей стоит больших денег.
Верная категоризация пользователей в соответствии с тем, что они реально любят, и деятельностью, которая им нравится, может быть крайне эффективной и справедливой. Корреляции помогут нам найти группы с общими интересами и целями, так же как ученые используют корреляции между генами, чтобы установить причины заболеваний.
* * *
Парламент может быть страшным местом для молодого специалиста по данным.
– Прошло не так много времени с тех пор, как таблички в Вестминстере называли обычных граждан «посторонними», – сказала мне Николь Нисбетт, когда я встретился с ней в Лидсском университете. – Все меняется, и персонал Вестминстера активно обращается к общественности и исследователям, но эти таблички показывают историческую настороженность по отношению к посторонним.
Николь уже два года работает над диссертацией, проводя половину времени в Лидсе, а половину – в Палате общин. Теперь у нее есть пропуск с «доступом к большинству мест» в Палате. Ее задача – улучшить то, как члены парламента и остальной постоянный персонал прислушиваются к внешнему миру и взаимодействуют с ним. До того как Николь начала свой проект, многие сотрудники, занятые в повседневной работе правительства, ощущали, что все комментарии, оставленные публикой в Facebook или даже на их собственных дискуссионных форумах, были слишком обременительными, чтобы с ними работать.
– Оставалось также ощущение, будто они уже знали, что люди собираются им сказать, – сказала Николь, – и отсеивание всех негативных комментариев и оскорблений было трудной задачей.
Работа с данными дала Николь опыт и, соответственно, другую точку зрения. Она понимала, что количество комментариев в Twitter и Facebook может быть ошеломительным для любого, но также умела находить корреляции. Николь показала мне созданную ею карту, в которой резюмировались споры о запрете изделий из натурального меха. Она заложила в матрицу все слова, употребленные в дискуссии, и посмотрела, как коррелировалось их использование. Связями соединялись слова, которые использовались вместе. «Мех» обнаруживался в одном кластере с «продажей», «торговлей», «промышленностью», которые далее соединялись с терминами «варварский» и «жестокий». Другой кластер объединял слова «страдание», «убийство» и «красивый». Третий связывал «благосостояние», «законы» и «стандарты». В каждом кластере объединялась определенная ветвь аргументации.
В одной области карты Николь рядом стояли слова «смерть от тока» и «анальный». Их соединяла толстая линия. Я уставился на них, пытаясь понять, какой вывод от меня желает услышать Николь.
– Сначала мы думали, что эти слова используют тролли, – сказала она.
В любой дискуссии всегда найдутся люди, которые пытаются накручивать оппонентов, часто с помощью оскорбительной лексики. Однако в спорах с руганью, как правило, наблюдалась меньшая корреляция между словами – оскорбления были буквально случайны, – а эти два слова повторялись широким кругом разных людей. Когда Николь взглянула на фразы, их содержащие, она обнаружила информированную группу людей, обсуждавших реальную проблему: выращенных на ферме лисиц и енотов убивали, вставляя в тела электроды и подавая высокое напряжение. Это добавило новое измерение в обсуждение парламентского персонала, которое они никогда бы не заметили без работы Николь.
– Я избегаю предположений о том, что напишут люди; моя работа – объединить тысячи мнений, чтобы парламент мог быстрее реагировать на такую дискуссию, – говорит Николь.
В ее анализе собраны разные взгляды – не потому, что «политически корректно» выслушивать все стороны в споре, а потому, что статистически верно выделять важные мнения. Взгляды меньшинства получают свое выражение, потому что они реально способствуют разговору. Корреляции дают беспристрастное представление обо всех сторонах дискуссии, нам не нужно занимать какую-то политическую позицию, решать, какие взгляды стоит или не стоит рассматривать.
– Это детские шаги. Нельзя с помощью статистики решить всё, – заметила Николь. И рассмеялась: – Никакой анализ данных не сможет помочь с брекситом!
* * *
Социологи делают всё возможное, чтобы найти статистически верное объяснение данным. Я познакомился с Би Пуранен из Института исследований будущего в Стокгольме, когда мы вместе ехали в Санкт-Петербург на конференцию по политическим переменам. Исследователи в институте, который мы посетили, финансировались непосредственно из средств, выделенных Дмитрием Медведевым, который был президентом России, когда Владимир Путин занимал пост премьер-министра. Однако настроения молодых докторантов были направлены резко против истеблишмента. Они нуждались в демократических переменах и страстно рассказывали, как подавляют их взгляды. Я сам был свидетелем, как тщательно Би разбиралась в конфликтах, симпатизируя собеседникам, но принимая при этом реалии проведения исследовательского проекта в современной России.
Для Би было жизненно важно, чтобы российские исследователи, с которыми она работала, безотносительно к их политическим взглядам вели проект «Всемирный обзор ценностей» точно так же, как и во всех странах-участницах (их почти сто). Задавая людям со всего мира один и тот же набор вопросов, многие из которых относились к таким деликатным темам, как демократия, гомосексуальность, иммиграция и религия, Би и ее коллеги хотели понять, как меняются ценности в разных странах планеты. Даже самый политически мотивированный исследователь быстро понимал: данные нужно собирать как можно более нейтрально.
В обзоре было 282 вопроса, поэтому корреляции давали удобный способ обобщать сходства и различия между ответами. Двое из коллег Би – Рональд Инглхарт и Кристиан Вельцель – обнаружили, что люди, делающие упор на семейные ценности, национальную гордость и религию, чаще имеют моральные возражения против разводов, абортов, эвтаназии и самоубийства. Корреляции в ответах на такие вопросы позволили Инглхарту и Вельцелю классифицировать граждан разных стран по шкале традиционализм – светскость. Такие страны, как Марокко, Пакистан или Нигерия, склонны к традиционализму, а Япония, Швеция и Болгария более светские. Этот результат ни в коем случае не означает, что все люди в какой-то стране придерживаются одинаковых взглядов; однако он дает статистически верную суммарную сводку мнений, доминирующих в этом государстве.
Крис Вельцель нашел еще один вариант корреляции вопросов и ответов. Люди, которых беспокоит свобода слова, тоже склонны ценить воображение, независимость и гендерное равенство в образовании, а также терпимы к гомосексуализму. Ответы на эти вопросы, которые Вельцель отнес к эмансипационным ценностям, коррелировали положительно. К странам с высокими эмансипационными ценностями относятся, например, Великобритания, США и Швеция.
Действительно важным моментом здесь оказалось то, что первая ось (традиционализм – светскость) не коррелировала со второй – эмансипацией. Например, в начале нового тысячелетия русские и болгары отличались высокими светскими ценностями, но не ценили эмансипацию. В США свобода и эмансипация важны почти для всех, но при этом страна остается традиционалистской в том смысле, что многие граждане отдают приоритет религиозным и семейным ценностям. Скандинавские страны – яркие примеры государств и со светскими, и с эмансипационными ценностями, а Зимбабве, Пакистан и Марокко находятся на противоположном конце спектра, где ценят и традиции, и послушание властям.
Разделение ценностей по двум независимым осям натолкнуло Би Пуранен на одну идею. Она захотела узнать, как изменились ценности мигрантов после их появления в Швеции. В 2015 году в стране попросили убежища 150 тысяч человек, в основном из Сирии, Ирака и Афганистана (это примерно 1,5 % населения Швеции); и все они прибыли из трех стран с совершенно иным набором культурных ценностей по сравнению с ценностями их нового дома.
Когда уроженцы западных стран смотрят на этих иммигрантов, то часто замечают проявления, связанные с их традиционными ценностями (хиджабы, новые мечети). Такие наблюдения приводят некоторых к выводам, что, например, мусульмане не могут приспособить свои ценности к новой родине. Внешний вид может демонстрировать, как иммигранты пытаются сохранить свои традиции, однако единственный статистически верный способ понять их внутренние ценности – поговорить с ними и спросить, что они думают. Именно этим занимались Би и ее коллеги. Они опросили 6501 из тех людей, которые приехали в Швецию за последние десять лет, задавая им вопросы об их ценностях.
Результаты были поразительными. Многие иммигранты разделяли типичное европейское стремление к гендерному равенству и терпимость к гомосексуальности, не принимая при этом крайнего шведского секуляризма. Они сохраняли свои традиционные ценности – те, что видны посторонним, – которые касаются важности семьи и религии. По сути, типичная иракская или сомалийская семья, живущая в Стокгольме, имеет очень схожие ценности с обычной американской семьей, проживающей в Техасе.
Мусульмане не единственная группа меньшинств, которую не воспринимают статистически верно. Я часто слышу, как в разговоре об американцах-христианах смешивают противников абортов и гомофобов. Мишель Дилон, профессор социологии из Университета Нью-Гэмпшира, показала, что одни религиозные группы, выступающие против абортов, одобряют однополые браки, а другие против них. В целом аборты и права сексуальных меньшинств внутри религиозных групп рассматриваются как разные вопросы.
* * *
По мере того как наша жизнь все больше перемещается в интернет, доступные данные о нас также расширяются: с кем взаимодействуем в Facebook, что нам нравится, куда ходим, что покупаем – и список можно продолжать. Facebook, Google и Amazon сохраняют все социальные взаимодействия, все запросы и потребительские решения. Это мир больших данных. Нас теперь определяют не возраст, гендер или место рождения, а миллионы наблюдений, фиксирующих все наши действия и мысли.
«Десятка» быстро приступила к проблеме больших данных. Ее участники составили матрицу населения мира. Они объединяли людей по интересам. Им казалось, будто расизм и сексизм ушли в прошлое. Они измеряли, как общество развивается, чтобы стать более толерантным: справедливым и уважающим личность людей. «Десятка» действовала статистически правильно.
Новый порядок во многом финансировался рекламой, адаптированной под конкретного человека. Рекламодатели начали тендерные войны за право показывать свои продукты небольшим целевым группам пользователей Facebook. Чтобы доставлять информацию с хорошей точностью, стали привлекать других статистиков и специалистов по данным. Родилась новая область – реклама с микротаргетированием. Сначала выявляются потенциальные клиенты и им подается только нужная информация в нужное время – чтобы максимизировать их заинтересованность.
Участники «Десятки» снова победили, добавив к списку решенных ими задач рекламу и маркетинг. На этот раз даже кажется, что отчасти мораль на их стороне. Но возникла одна проблема. На числа в этой матрице смотрели не только участники «Десятки». И не все люди, видевшие ее корреляции, правильно понимали наблюдаемые закономерности…
* * *
Исследование Ани Ламбрехт посвящено правильной интерпретации больших данных. В качестве профессора маркетинга в Лондонской школе бизнеса она изучала, как данные используются повсюду – от брендовой одежды до спортивных сайтов. Аня объяснила мне в электронном письме, что, несмотря на очевидные выгоды от использования больших массивов данных в рекламе, важно учитывать и ограничения. «Данные без умения извлекать надлежащие выводы не особо полезны», – сказала она.
В одной из своих научных статей, из которой взят следующий пример, Ламбрехт с коллегой Кэтрин Такер объясняет возникающие проблемы, используя сценарий из торговли в интернете. Представьте себе розничного продавца игрушек, обнаруживающего, что пользователи, которые видят больше его рекламы в Сети, покупают у него активнее. При этом он установил корреляцию между рекламой и приобретением игрушек, в итоге его маркетинговый отдел «больших данных» пришел к выводу, что кампания работает.
А теперь посмотрим на эту рекламу под другим углом. Возьмем Эмму и Джулию: они незнакомы друг с другом, но у них есть семилетние племянницы. Бродя в Сети в последнее воскресенье перед Рождеством, они, независимо друг от друга, видят рекламу компании игрушек. Эмме предстоит напряженная рабочая неделя, у нее нет времени на магазин. Джулия в отпуске и большую часть свободного времени тратит на поиски рождественских подарков. Увидев три-четыре раза рекламу игры «Четыре в ряд», Джулия переходит по ссылке и решает приобрести ее. Эмма же отправляется в какой-то магазин днем 23 декабря, видит модель дома на колесах фирмы Lego и покупает ее.
Джулия видела рекламу гораздо чаще Эммы, но можно ли сказать, что та эффективна? Нет. Мы понятия не имеем, что делала бы Эмма, будь у нее время смотреть рекламу. Те специалисты по «большим данным», которые заключили, что их кампания действует, перепутали корреляцию с причинностью. Мы не знаем, реклама ли заставила Джулию купить игру «Четыре в ряд», и поэтому не можем сделать вывод об ее эффективности.
Разделить корреляцию и причинно-следственную связь сложно. Та корреляционная матрица, которую я заполнил выше для Мэдисон, Райана и их друзей, основана на очень малом числе наблюдений, и мы не можем делать глобальных выводов только из нее (помните уравнение уверенности?). Однако представьте, что такую матрицу построили по очень большому количеству пользователей Snapchat, и мы обнаружили, что Пьюдипай коррелирует с Fortnite. Можно ли сделать вывод, что рост количества подписчиков Пьюдипая увеличит число игроков в Fortnite? Нет. Это снова смешивание корреляции и причинности. Дети не играют в Fortnite из-за того, что смотрят youtube-канал Пьюдипая. Если какая-то кампания по увеличению подписчиков Пьюдипая сработает, то она увеличит количество времени, которое дети будут тратить на его ролики. Она не заставит их играть в Fortnite после просмотра его видео.
А если Fortnite покупает рекламное место на канале Пьюдипая? Это может сработать: например, если некоторые игроки в Fortnite вернулись к Minecraft, Пьюдипай может привлечь их обратно. Но может ничего и не получиться. Не исключено, что интерес к Fortnite среди аудитории Пьюдипая уже находится в точке насыщения и нужно, чтобы этой игрой увлеклась Кайли Дженнер!
Если мы немного подумаем, то увидим разного рода проблемы с потенциальными выводами из наличия в наших данных корреляции Пьюдипай/Fortnite. Но когда началась революция больших данных, многие из них игнорировались. Компаниям рассказывали, что их данные весьма ценные, поскольку теперь они знают о своих пользователях всё. Но это не так.
* * *
Cambridge Analytica – яркий пример компании, которая не сумела разобраться с причинно-следственной связью.
Комитет Сената внимательно слушал то, что я им говорил по скайпу. «Cambridge Analytica собрала массу сведений о пользователях Facebook, в частности о продуктах и сайтах, где те щелкали кнопку “Нравится”. Они намеревались использовать данные для целевого информирования в соответствии с личностью пользователей. Они хотели, чтобы нервным людям показывали сообщения о защите семьи с помощью оружия, а традиционалистам рассказывали о передаче оружия от отца к сыну. Каждое рекламное сообщение должно было быть адаптировано под конкретного избирателя».
Я понимал, что мои собеседники – республиканцы из комитета, – вполне могли вообразить себе выгоды от такого инструмента для следующих выборов. А потому быстро перешел к сути. «Но по нескольким причинам это не могло сработать, – сказал я. – Во-первых, невозможно надежно определить свойства личностей по их лайкам. Таргетирование приводило к ошибкам в определении личностных качеств ненамного реже, чем давало правильные результаты. Во-вторых, тот тип невротизма, который можно найти у пользователей Facebook – любителей группы Nirvana и стиля эмо, – отличается от невротизма, связанного с защитой семьи с помощью оружия».
Я прошелся по проблемам, появляющимся из-за смешивания корреляционной зависимости и причинно-следственной связи. Когда Cambridge Analytica создавала свой алгоритм, выборы еще не состоялись. Как же они могли проверить, работает ли их реклама?
Далее я рассказал о неэффективности фейковых новостей для влияния на избирателей – еще одной теме, которую исследовал в своей предыдущей книге «В меньшинстве». Я также рассказал им, что, вопреки теории эхо-камеры, демократы и республиканцы на выборах 2016 года должны были слышать все стороны. Моя точка зрения противоречила взглядам либеральных СМИ, которые считали победу Трампа манипуляцией с онлайн-избирателями. Его электорат обвиняли в наивности и в том, что эти люди оказались жертвами промывки мозгов. Cambridge Analytica стала олицетворением легкости, с которой соцсети могут влиять на общественное мнение. Я не разделял такую точку зрения.
Координатор звонка сказал: «Сейчас я отключу у вас звук, пока мы обсудим то, что услышали».
Им потребовалось секунд тридцать, чтобы принять решение. «Мы хотели бы, чтобы вы прилетели в Вашингтон для дачи показаний в комитете Сената. Сможете?»
Я не ответил сразу. Я пробормотал что-то о запланированном отпуске и сказал, что мне надо подумать.
В тот момент я действительно не был уверен, стоит ли мне ехать. Но, хорошенько все обдумав, пришел к выводу, что не стоит: мой приезд в США был им нужен не для того, чтобы я объяснял сенаторам причинность и корреляцию. Они не хотели понять используемые мною модели. Они лишь хотели услышать те мои выводы, которые соответствовали их представлениям – что Cambridge Analytica и фейковые новости не сделали Трампа президентом. И я не поехал.
Однако тем летом я оказался в США. Я был в Нью-Йорке и встретился с Алексом Коганом сразу после того, как он давал показания на слушаниях в Сенате. Алекс, исследователь из Кембриджского университета, считался одним из плохих парней в истории Cambridge Analytica. Он собрал данные по 50 миллионам пользователей Facebook и продал их Cambridge Analytica. Не особо мудрый поступок, о котором он потом сожалел.
Мы познакомились с Алексом, когда я начал проверять точность методов Cambridge Analytica. Он интересный собеседник. Возможно, с ним не стоит вести бизнес, но он отлично понимает, как можно и как нельзя использовать данные. Алекс действительно пытался создать то, что Крис Уайли назвал инструментом «психологической войны», для точной фиксации избирателей, но пришел к выводу, что такое оружие невозможно разработать. Данных недостаточно.
Работая в компании, он пришел к тому же выводу о деятельности Cambridge Analytica, что и я: «Эта дрянь не работает». На слушаниях в Сенате он сказал сенаторам то же, но в более вежливой форме.
* * *
Основная «проблема» с алгоритмом компании Cambridge Analytica состояла в том, что он не работал.
В начале эры «больших данных» многие так называемые эксперты предполагали, что корреляционные матрицы могут вести непосредственно к лучшему пониманию пользователей и клиентов. Но все не так просто. Алгоритмы, основанные на корреляциях в данных, использовались не только для политической рекламы, но и при рекомендациях для тюремного заключения, оценке работ школьных учителей и для обнаружения террористов. Название книги Кэти О’Нил «Оружие математического поражения» хорошо отражает возникающие проблемы. Как и ядерные бомбы, алгоритмы не избирательны. Термин «таргетированная реклама» подразумевает жесткий контроль над тем, кому она показывается, но на самом деле эти методы имеют очень ограниченные возможности по надлежащей классификации людей.
Для интернет-рекламы это невелика беда. Жизнь игрока в Fortnite не рухнет, если ему покажут рекламу косметики. Но совсем другое дело – если алгоритм назовет вас преступником, плохим учителем или террористом. Это может изменить карьеру и жизнь. Алгоритмы на базе корреляций изображались объективными, потому что основаны на данных. На деле же, как я обнаружил при написании своей последней книги – «В меньшинстве», – многие алгоритмы делают почти столько же ошибок, сколько и точных прогнозов.
Нашлось и множество других проблем, которые могут возникнуть при конструировании алгоритмов, основанных на корреляционных матрицах. Например, метод представления слов Google в его поисковой системе и сервисе перевода основан на корреляции между использованием слов. Для определения того, когда те или иные группы слов употребляются вместе, применяются также Википедия и базы данных для новостных статей. Когда я посмотрел, как эти алгоритмы рассматривают мое имя Дэвид по сравнению с именем Сьюзен (самым популярным именем для женщин моего возраста в Великобритании), я пришел к нелестным выводам. Там, где я в качестве «Дэвида» был «смышленым», «сообразительным» и «умным», алгоритм давал для Сьюзен определения «изворотливая», «жеманная» и «сексуальная». Основная причина проблемы в том, что эти алгоритмы построены на корреляциях в наших исторических текстах, которые набиты стереотипами.
Алгоритмы, используемые для больших данных, нашли корреляции, но не поняли их причин. В результате они совершали колоссальные ошибки.
* * *
Последствия перехваливания «больших данных» были сложны, но причины просты. Помните, как мы разделили мир на данные, модели и бессмыслицу? Произошло вот что: компаниям и общественности рассказали о данных, но не обсудили модели. Когда моделей нет, верх берет бессмыслица. Александр Никс и Крис Уайли говорили бессмыслицу о таргетировании по личностным качествам и инструментам психологической войны. Компании, прогнозирующие качество работы учителей и создающие программы для вынесения приговоров, говорили бессмыслицу об эффективности их продуктов. Facebook подкреплял ложные стереотипы своей рекламой, ориентированной на этническую принадлежность.
У Ани Ламбрехт есть ответ. Она решает проблему причинности, вводя модель – создавая историю, например, Эммы и Джулии с их способом совершения покупок. Мы можем оценить успех рекламной кампании, если рассмотрим точку зрения потребителей, а не просто взглянем на собранные данные. Ламбрехт разделяет проблему на модель и данные (хотя и не использует таких терминов) – именно эту стратегию мы применяли в данной книге. Сами по себе данные говорят очень мало, но при их объединении с моделью можно получить многое.
Такой базовый подход к определению причинности известен как A/B-тестирование. Я уже описывал этот метод в , а сейчас мы можем применить его на практике. Компания должна попробовать на своих клиентах две разные рекламы: А) оригинальную, эффективность которой нужно проверить, и В) контрольную, например благотворительной организации, где не будет никаких отсылок к компании игрушек. Если компания продает столько же товаров пользователям, которые смотрят благотворительную рекламу, сколько тем, кто видел оригинал, то она будет знать, что ее реклама не оказывает никакого эффекта.
Исследование Ани Ламбрехт описывает множество примеров, как нам стоит подходить к причинности. В одной работе она изучала распространенную в рекламном деле идею, что если на ранней стадии привлечь внимание известных людей в соцсетях, то это может помочь продукту стать вирусным. Если рекламодатель нацелен на людей, которые быстро принимают новые тренды, реклама должна иметь больший эффект. Звучит разумно – не так ли?
Чтобы проверить надлежащим образом эту идею, Ламбрехт и ее коллеги сравнили: а) группу пользователей, которые на ранней стадии делились хештегами свежих трендов, например и , и б) группу пользователей, которые присоединялись к тем же трендам позже. Обеим группам показывали ссылку на рекламу, и исследователи измеряли, как часто люди нажимали на рекламу или делали ретвит (делились ею).
Оказалось, что теория «авторитетов на ранней стадии» неверна. Группа А с меньшей вероятностью щелкала по рекламе или делилась ею по сравнению с группой В. Результаты были одинаковы и для рекламы благотворительной организации для бездомных, и для модного бренда. На самих авторитетных людей трудно повлиять. Они авторитетны, потому что разбираются в том, чем делятся. На них подписываются из-за их независимости и здравомыслия. Тот, кто быстро принимает что-то без применения здравого смысла, – просто спамер, и никто не желает подписываться на таких.
В Snapchat Дуг Коэн со своей командой применяют А/В-тестирование ко всему. Когда я разговаривал с ним, они работали над уведомлениями, проверяя сложный ряд схем и пытаясь выяснить, какая из них побуждает пользователей открывать приложение. Но когда Дуг говорил о том, хорошо ли они понимают своих пользователей, он был осторожен: «Утром вы не тот человек, что в конце дня, поэтому мы можем отнести вас к более широкой категории, но вы меняетесь в течение месяца и года, становясь старше». Он также подчеркнул, что люди не хотят видеть одно и то же все время: «Мы можем классифицировать человека как интересующегося спортом, но это не значит, что он хочет видеть кучу мужских вещей». Пользователи раздражаются, если считают, что алгоритм приписал их к какой-то определенной категории.
Уравнение рекламы говорит нам, что неизбежным следствием организации больших объемов данных становится некоторая степень стереотипизации. Так что не огорчайтесь из-за того, что стали частью корреляционной матрицы. Это верное представление о том, кто вы есть. Ищите корреляцию с интересами ваших друзей и стройте связи. Когда корреляции истинны (а не построены на расовых или гендерных стереотипах), они облегчают поиск общих точек. Если получаются исключения из правила, примите их и скорректируйте свою модель. Ищите закономерности в разговорах, как Николь Нисбетт в политических дискуссиях, и используйте их для упрощения споров. Внимательно ищите небольшие кластеры новых точек зрения и обращайте на них особое внимание. Но не смешивайте корреляцию и причинно-следственную связь. Приглашая на обед друзей, проведите A/B-тестирование меню. Не предлагайте снова пиццу только потому, что в прошлый раз, по словам приятелей, она оказалась вкусной. Стройте статистически правильную модель своего мира.
* * *
В манхэттенском метро после разговора с Алексом Коганом в Нью-Йорке я понял кое-что о себе. Я больше не знал своей политической позиции. Я всегда был левым; прочтя в девятнадцать лет Жермен Грир, стал феминистом. Я всегда был тем, кого сейчас называют термином «воук» («активный, пробудившийся»). Как минимум настолько, насколько это может сделать белый мальчик, выросший в маленьком рабочем поселке в 1980-х. Многие считают, что быть левым, не одобрять Дональда Трампа и обвинять его в манипулировании людьми с помощью соцсетей – части единого пакета. СМИ изображали их коррелированными признаками левого взгляда на мир.
Однако математика заставила меня выбрать другую модель. Я был вынужден принять победу Трампа, поскольку модель говорила: победа заслуженная. Я не одобрял его политических взглядов, но не поддерживал и того, что его избирателей рисовали тупыми и легко управляемыми. Они такими не были.
Вместо того чтобы искать реальные причины роста националистических настроений, которые привели Трампа к власти, спровоцировали брексит, несли ответственность за «Движение пяти звезд» в Италии, Виктора Орбана в Венгрии и Жаира Болсонару в Бразилии, все бросились искать какого-то злодея из бондианы – некую личность, отравившую воды политики. Их Доктор Но явился в образе Александра Никса и компании Cambridge Analytica. Каким-то образом этот человек, обладающий всего лишь базовым пониманием моделей и данных, на их взгляд, должен был манипулировать всей современной демократией.
Самая большая угроза для любого тайного общества – угроза его раскрытия. Компанию Cambridge Analytica разоблачили. Оказалось, что заурядной рекламной фирме Трамп заплатил максимум миллион долларов – и это во время выборов, на которые было потрачено 2,4 миллиарда. Эффект оказался примерно пропорционален размеру вклада: мизерный.
Конспиративной теории с бондовским злодеем не хватило здравого смысла. Данные были слишком скудными, чтобы дать нам хоть какую-то уверенность. А «Десятка» продолжала работать незамеченной. Ее участники управляют банками, финансовыми учреждениями и букмекерскими конторами. Они создают наши технологии и контролируют соцсети. В каждой такой деятельности они получают небольшую долю: 2–3 цента на доллар при азартных играх, цент на доллар в сетевой торговле и даже меньше, когда выдают рекламу в сочетании с результатами поиска в интернете. Со временем эти маленькие доли складываются, и прибыль участников «Десятки» растет. Во всех сферах жизни математики переигрывают тех, кто не знает уравнений.
Сидя в метро по дороге домой, я думал о людях, которые умоляли меня о футбольных советах и о том, как компании, занимающиеся онлайн-ставками, предлагают одиноким мужчинам возможность пообщаться с женщинами во время проигрывания своих денег. Я думал о призме Instagram, через которую мы смотрим на образ жизни, основанный на потребительстве и известности. Я думал о рекламе кредитов на мобильные телефоны с высокими процентами, ориентированной на самые бедные слои общества.
Люди, которые объясняли результаты президентских выборов в США и брексит фейковыми новостями и применением данных, украденных из Facebook компанией Cambridge Analytica, игнорируют базовые противоречия в нашем обществе между богатыми и бедными. Подобные мне люди – математики и другие ученые – тоже сыграли значительную роль в том, что общество стало менее справедливым. Ирония здесь в том, что одна теория заговора верна. Иллюминаты действительно существуют – это «Десятка». И это общество настолько скрыто, что его не видят даже другие участники-конспираторы.
Назад: Глава 6. Уравнение рынка
Дальше: Глава 8. Уравнение вознаграждения

