Книга: Супермышление. Как обходить ментальные ловушки и принимать эффективные решения
Назад: Все относительно
Дальше: Получится ли воспроизвести?
Правильно или нет?
Вы узнали, что не должны основывать свои решения на единичных случаях и что маленькие выборки не могут достоверно показать, что произойдет в большой группе населения. Может быть, вам стало интересно: сколько данных достаточно, чтобы быть уверенными в своих выводах? Установление размера выборки, общего числа собранных точек данных – это уравновешивающее действие. С одной стороны, чем больше информации вы соберете, тем точнее будут ваши подсчеты и тем увереннее вы будете в своих выводах. С другой стороны, на сбор большого количества информации уйдет больше времени и денег и, возможно, риску подвергнется больше участников. Итак, как установить правильный размер выборки?
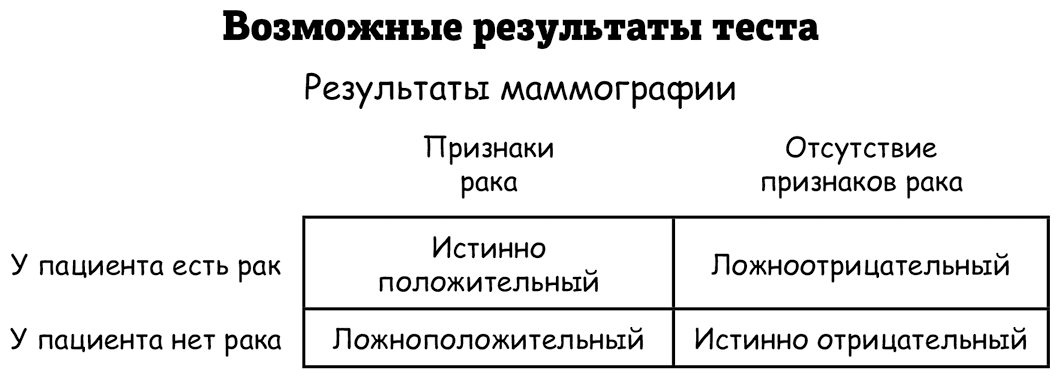
Даже идеально спланированный эксперимент иногда будет давать случайный результат, который заставит сделать неправильные выводы. Больший размер выборки придаст больше уверенности в том, что положительный результат возник не случайно, а также даст больше шансов получить этот положительный результат.Рассмотрим типичную ситуацию с опросом общественной поддержки предстоящего референдума, например по легализации марихуаны. Предположим, что референдум в конечном итоге провалился, но социологи случайным образом выбрали в качестве респондентов людей, которые были благосклоннее к проекту, чем остальное население. Это приведет к ложноположительному результату – положительному результату, который на самом деле оказался ложным (как и ложный результат алкотестера). Или наоборот, референдум в конце концов оказался успешным, но социологи случайно выбрали людей, которые меньше его одобряли по сравнению со всем населением. Получился ложноотрицательный результат – отрицательный результат, который на самом деле был истинным. В качестве другого примера рассмотрим маммографию – медицинский тест для диагностики рака молочной железы. Кажется, что такой тест имеет два возможных результата: положительный и отрицательный. Но на самом деле у маммографии четыре возможных результата, которые отображены в следующей таблице. Два результата, о которых вы сразу подумали: истинно положительный или истинно отрицательный. Другие два результата выдаются при ошибке теста – ложноположительный и ложноотрицательный результат.
Эти ошибочные модели встречаются далеко за пределами статистики в любой системе, где принимаются решения. Отличный пример – ваш спам-фильтр в электронной почте. Недавно спам-фильтры удалили письмо с фотографиями нашей новорожденной племянницы (ложноположительный результат). А настоящий спам до сих пор иногда просачивается в основную почту (ложноотрицательный результат).
Поскольку каждый тип ошибок имеет свои последствия, системы нужно создавать с их учетом. То есть
решения придется принимать на компромиссе между различными типами ошибок, признавая, что некоторые из них неизбежны. Например, правовая система США должна требовать доказательств по обвинительным приговорам, а не основываться на разумных сомнениях в виновности задержанного человека. Это осознанный компромисс в пользу ложноотрицательного (выпустить преступника на волю), а не ложноположительного результата (наказать невиновного человека).В статистике ложноположительный результат известен как ошибка типа I, а ложноотрицательный результат называется ошибкой типа II. При разработке эксперимента ученые оценивают вероятность каждого типа ошибки, которую они готовы терпеть. Допустимый процент ложноположительных результатов обычно равен 5 % (этот показатель также обозначается греческой буквой α – альфа, которая равняется 100 минус уровень доверия. Вот почему обычно уровень доверия составляет 95 %). Это значит, что в среднем, если ваша гипотеза неверна, один из 20 экспериментов (5 %) даст ложноположительный результат.
Независимо от размера выборки в вашем эксперименте всегда можно задать процент ложноположительного результата. Он не обязательно должен быть равен 5 %. Можно выбрать 1 % или даже 0,1 %. Но, ставя такой низкий процент ложноположительного результата для своей выборки, вы увеличиваете частоту ложноположительных ошибок, и тогда вам, возможно, не удастся найти реальный результат. Тут-то речь и заходит о размере выборки.
Определив процент ложноположительных результатов, вы должны выяснить, какого размера вам потребуется выборка, чтобы с достаточно высокой вероятностью найти истинный результат. Эта величина называется мощностью эксперимента и обычно выбирается так, чтобы вероятность обнаружения составляла 80–90 %, а частота ложноположительной ошибки, соответственно, 10–20 % (этот процент также обозначается греческой буквой β – бета, которая равняется 100 минус мощность). Исследователи говорят, что их эксперимент обладает мощностью 80 %.
Давайте рассмотрим один пример, чтобы проиллюстрировать, как все эти модели работают вместе. Предположим, компания хочет доказать, что их новое приложение для засыпания работает. Предварительное исследование показало, что в половине случаев человек засыпает в течение 10 минут. Разработчики думают, что можно улучшить этот показатель с помощью приложения, помогая большему количеству людей заснуть меньше чем за 10 минут.
Разработчики планируют исследование в лаборатории сна, чтобы проверить свою теорию. Тестовая группа будет использовать приложение, а контрольная будет засыпать без него (у настоящего исследования план будет посложнее, но мы объясняем статистические модели).
Статистическая база большинства экспериментов (включая и этот) начинается с гипотезы о том, что между группами нет разницы, – это называется нулевой гипотезой. Если разработчики соберут достаточно доказательств для опровержения этой гипотезы, они сделают вывод, что их приложение действительно помогает людям уснуть быстрее.То есть разработчики приложения наблюдают за обеими группами, а затем рассчитывают процент людей, засыпающих в течение 10 минут в каждой. Если они найдут достаточно большую разницу между этими двумя результатами, они сделают вывод, что результаты несовместимы с нулевой гипотезой, а значит, приложение, вероятно, действительно работает.
Разработчикам также нужно детально изложить альтернативную гипотезу, которая описывает наименьшие значимые показатели, которые, как им кажется, возникнут между двумя группами: например, на 15 % больше людей уснет в течение 10 минут. Это реальный результат, который они хотят подтвердить своим исследованием и имеют 80 % шанс обнаружить (что соответствует ложноотрицательному результату в 20 % случаев).
Эта альтернативная гипотеза необходима для определения размера выборки. Чем меньше разница в альтернативной гипотезе, тем больше людей потребуется для ее обнаружения. Для описанного плана эксперимента размер выборки составляет 268 участников.
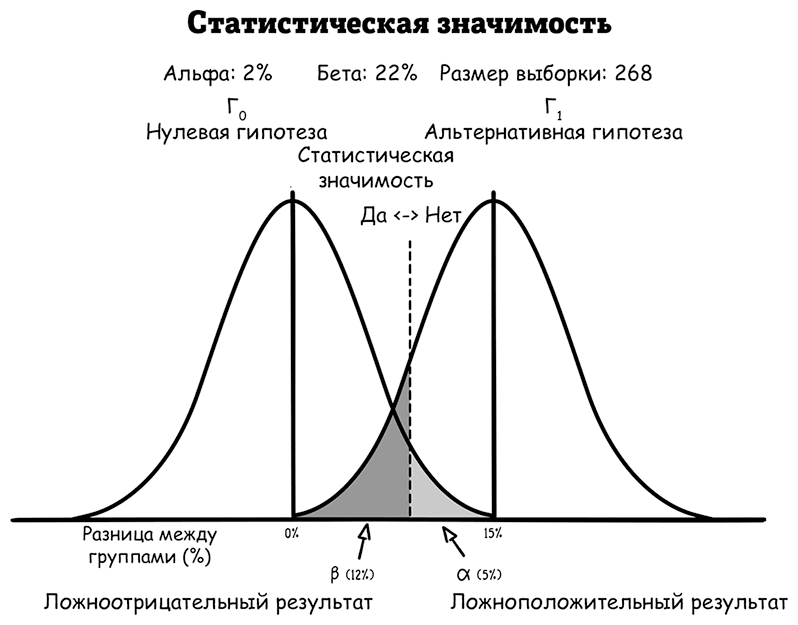
Все эти модели наглядно представлены на рисунке.
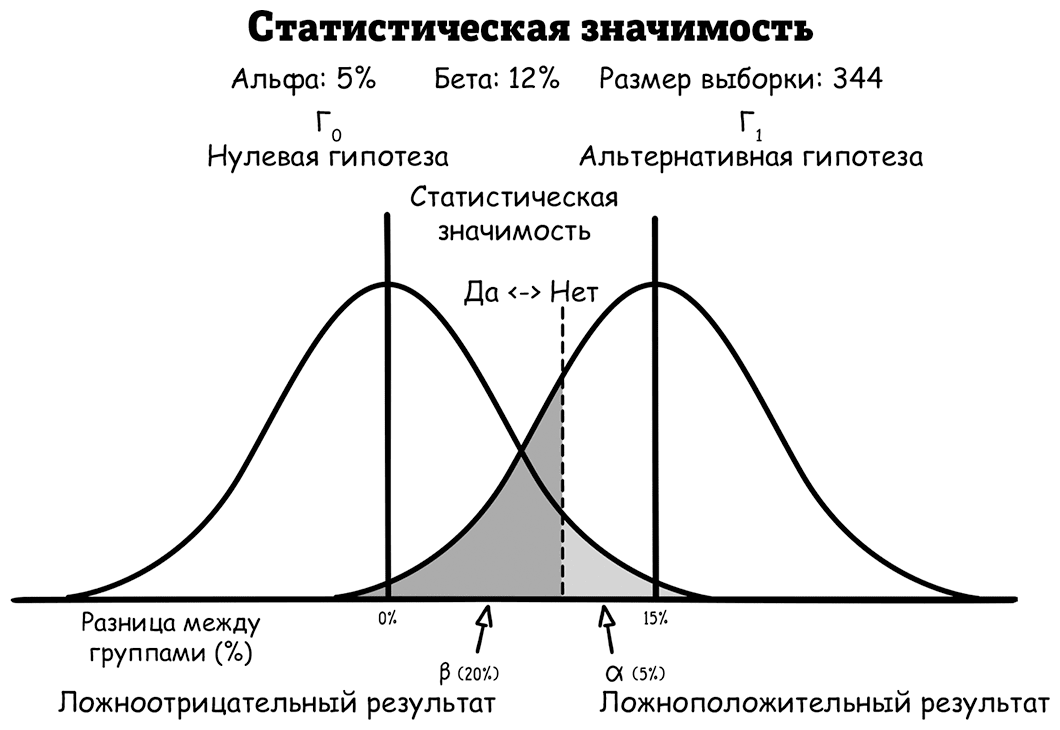
Для начала посмотрим на кривые нормального распределения (по центральной предельной теореме можно предположить, что разницы будут приблизительно нормально распределены). Кривая слева показывает результаты меньше нулевой гипотезы: между двумя группами нет существенной разницы. Вот почему эта левая кривая центрирована на 0 %. Даже в этом случае разница время от времени будет случайно составлять больше или меньше нуля, но чем больше разница, тем менее она вероятна. То есть из-за базовой изменчивости, даже если приложение и не обладает реальным эффектом, разница все равно будет обнаружена между двумя группами, потому что люди засыпают за случайные периоды времени.
Другая кривая нормального распределения (справа) представляет собой альтернативную гипотезу, на правдивость которой надеются разработчики: количество людей, которые засыпают в течение 10 минут при использовании приложения, увеличится на 15 % по сравнению с людьми, которые не пользуются им. Опять же, даже если эта гипотеза верна, из-за изменчивости разница иногда все равно будет меньше 15 %, а иногда больше 15 %. Вот почему правая кривая центрирована на 15 %.
Пунктирная линия представляет собой порог статистической значимости. Все значения, превышающие этот порог (справа), будут опровергать нулевую гипотезу, поскольку такая большая разница вряд ли возникнет, если нулевая гипотеза верна. На самом деле вероятность ее возникновения была бы меньше 5 % – такой процент ложноположительного результата изначально установили разработчики.Последняя мера, к которой часто прибегают, чтобы выявить статистическую значимость результата, называется p-значением, официальное определение которого – вероятность получения результата, равного или превышающего наблюдаемый, если предположить, что нулевая гипотеза верна. По сути своей, если p-значение меньше выбранного уровня ложноположительного результата (5 %), можно сказать, что результат обладает статистической значимостью. P-значения часто используются в отчетах об исследованиях, чтобы сообщить о такой значимости.
Например, p-значение, равное 0,01, значит, что разница, равная или превышающая наблюдаемую, будет иметь место только в 1 % случаев, если приложение окажется неэффективным. Это значение соответствует значению на крайнем хвосте левой кривой нормального распределения и ближе к центру правой кривой нормального распределения. Такое расположение означает, что результат больше соответствует альтернативной гипотезе: данное приложение имеет эффект 15 %.
Теперь обратите внимание, как две кривые накладываются друг на друга, показывая, что некоторая разница между двумя группами согласуется с обеими гипотезами (одновременно под обоими колоколами кривых). Эти серые области показывают, где могут возникнуть два типа ошибки. Светло-серая область – это ложноположительный, а темно-серая – ложноотрицательный результат.
Ложноположительный результат получится, если между двумя группами обнаружится большая разница (как там, где p-значение равно 0,01), но на самом деле приложение не действует. Это произойдет, если кто-то из группы без приложения случайно долго не мог уснуть, а кто-то из группы с приложением случайным образом легко уснул.
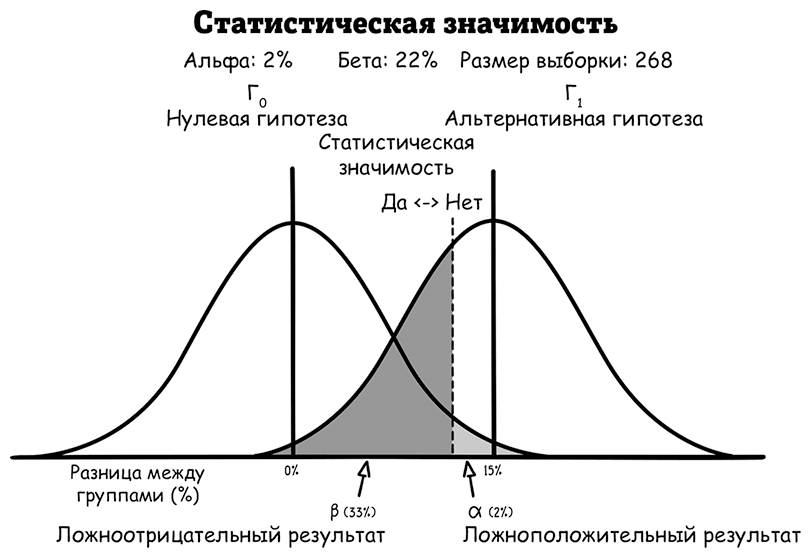
И наоборот, ложноотрицательный результат получится, если приложение на самом деле помогает людям уснуть быстрее, но наблюдаемая разница слишком мала, чтобы обладать статистической значимостью. Если исследование имеет типичную мощность 80 %, этот ложноотрицательный сценарий будет происходить в 20 % случаев.
Предположим, что размер выборки остается фиксированным. Снижение вероятности ложноположительной ошибки эквивалентно переносу пунктирной линии вправо с сокращением светло-серой области. Но при этом шанс сделать ложноотрицательную ошибку возрастает (сравните следующий рисунок с оригиналом).
Если хотите уменьшить процент одной из ошибок, не увеличивая другую, придется увеличить размер выборки. При этом каждая из кривых нормального распределения станет у́же (сравните нижний рисунок также с оригиналом).
Увеличение размера выборки и сужение кривых нормального распределения уменьшают наложение двух кривых, в процессе сокращая общую серую область. Конечно, это привлекательно, потому что уменьшается вероятность совершить ошибку. Но, как мы отметили в начале раздела, есть множество причин, по которым увеличение размера выборки может оказаться нецелесообразным (время, деньги, риск для участников и т. д.).
В таблице показано, как изменяется размер выборки для разных пределов уровня ошибки в исследовании приложения для сна. Вы увидите, что, если процент ошибок понизится, размер выборки придется увеличить.

Все значения размеров выборки в следующей таблице зависят от выбранной альтернативной гипотезы с разницей в 15 %. Размеры выборки увеличивались бы и дальше, если бы разработчики хотели обнаружить еще меньшую разницу, и уменьшились бы, если бы хотели найти только большую разницу.
Исследователям часто приходится брать выборку поменьше, чтобы сэкономить время и деньги, из-за чего выбор большей разницы для альтернативной гипотезы становится привлекательным. Но такой выбор сопряжен с высоким риском. Например, разработчики могли бы сократить размер выборки всего до 62 человек (вместо 268), если бы заменили разницу в альтернативной гипотезе на 30 % между двумя группами (а не 15 %).
Но если в действительности приложение дает разницу всего 15 %, с этим меньшим размером выборки они смогут обнаружить такую меньшую разницу только в 32 % случаев! Это меньше, чем изначальные 80 %, и значит, что в 2/3 случаев будет получен ложноотрицательный результат, который не покажет разницу в 15 %. В идеале любой эксперимент нужно разрабатывать так, чтобы обнаруживать малейшую существенную разницу.
Последнее замечание о p-значениях и статистической значимости: большинство статистиков предостерегают, что нельзя чрезмерно полагаться на p-значения при интерпретации результатов исследования. Неспособность найти значимый результат (достаточно малое p-значение) – это не то же самое, что уверенность в отсутствии эффекта.
Отсутствие доказательств не является доказательством отсутствия. Точно так же, даже несмотря на то, что исследование могло достичь лишь низкого p-значения, этот результат может быть неприменим, что мы рассмотрим в заключительном разделе.Статистическую значимость не следует путать с научной, человеческой или экономической значимостью. Даже самый мизерный заметный эффект будет статистически значимым, если размер выборки достаточно велик. Например, если в исследовании сна примет участие достаточное количество людей, вы потенциально обнаружите разницу в 1 % между двумя группами, но будет ли это значимо для покупателей? Нет.
И наоборот, больше внимания стоит обратить на разницу, измеренную в исследовании, вместе с соответствующим доверительным интервалом. Потребители приложения хотят знать не только то, будут ли они лучше спать с ним, чем без него, но и насколько лучше. Возможно, разработчикам даже захочется увеличить размер выборки, чтобы гарантировать определенную погрешность в своих оценках.
Кроме того, Американская ассоциация статистики в одном из выпусков своего журнала за 2016 год подчеркнула, что «научные выводы и деловые или политические решения не должны опираться только на то, преодолевает ли p-значение определенный порог». Слишком большое внимание к p-значению поощряет черно-белое мышление и сокращает до одного числа весь объем информации, полученной из исследования. Такой исключительный фокус заставит вас упустить из виду возможные неоптимальные варианты в проекте исследования (например, размер выборки) или погрешности, которые могли закрасться в него (например, систематическую ошибку отбора).
Назад: Все относительно
Дальше: Получится ли воспроизвести?

