Книга: Супермышление. Как обходить ментальные ловушки и принимать эффективные решения
Назад: Правильно или нет?
Дальше: Основные идеи
Получится ли воспроизвести?
Вы уже знаете, что результаты некоторых экспериментов – просто счастливая случайность. Чтобы удостовериться в том, что результат исследования не случаен, его необходимо воспроизвести. Интересно, что в некоторых областях, таких как психология, для воспроизведения положительных результатов предпринимались согласованные усилия, но эти усилия показали, что более 50 % положительных результатов невозможно воспроизвести.
Это низкий показатель и такая проблема с исключительно положительными результатами называются кризисом воспроизводимости. В этом последнем разделе мы предлагаем кое-какие модели, которые объясняют, как это происходит и как все равно получить больше доверия в своей области исследований.
Попытки воспроизведения – это попытки отличить ложноположительные результаты от истинно положительных. Подумайте, каковы шансы воспроизведения в каждой из этих двух групп. Предполагается, что ложноположительный результат повторится – то есть ожидается получение второго ложноположительного результата при повторном эксперименте – всего в 5 % случаев. С другой стороны, ожидается, что истинно положительный результат повторится в 80–90 % случаев, в зависимости от мощности повторного исследования. Предположим, что это 80 %, как в предыдущем разделе.
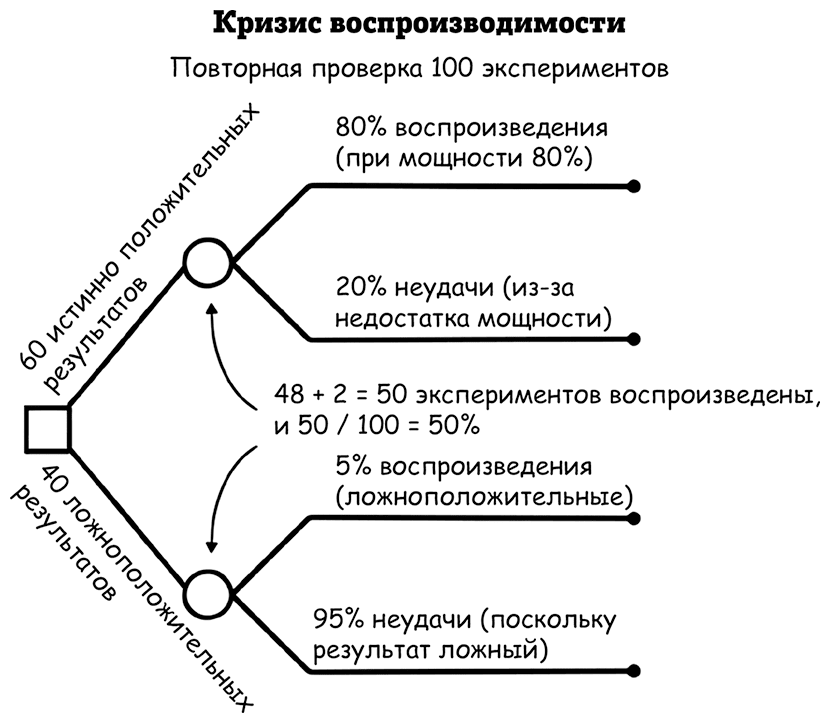
Таким образом, для 50 % воспроизведения требуется, чтобы около 60 % исследований были истинно положительными, а 40 % – ложноположительными. Чтобы было понятнее, представьте 100 экспериментов: если 60 дадут истинно положительный результат, 48 из них должно быть можно воспроизвести (80 % от 60). Из оставшихся 40 ложноположительных результатов будут воспроизведены 2 (5 % от 40), чтобы в общей сложности получилось 50. Тогда уровень воспроизводимости будет 50 на 100 экспериментов, или 50 %.
Получается, в этом сценарии около четверти неудачных воспроизведений (12 из 50) будут объясняться недостатком мощности усилий для воспроизведения. Это реальный результат, который, скорее всего, будет воспроизведен успешно при проведении дополнительного исследования, или получился бы, если бы у первоначального воспроизведения была более крупная выборка.
Остальные результаты, которые не получилось воспроизвести, изначально и не должны были быть положительными. Многие из этих первоначальных исследований, вероятно, недооценили частоту ошибки типа I и повысили шансы получить ложноположительный результат. Это связано с тем, что при планировании исследования с 5 % шансом ложноположительного результата этот шанс применяется только к одной статистической проверке, но крайне редко такая проверка проводится всего один раз.
Проведение дополнительных проверок для поиска статистически значимых результатов имеет много названий, включая прочесывание, выуживание данных или p-взлом (попытка взломать данные в поисках достаточно малых p-значений). Часто это делается из лучших побуждений, потому что наблюдение за данными эксперимента воодушевляет и побуждает исследователя формировать новые гипотезы. Соблазн проверить дополнительные гипотезы велик, так как необходимые для их анализа данные уже собраны. Однако проблема возникает, когда исследователь преувеличивает результаты этих дополнительных испытаний.
Комикс XKCD, приведенный ниже, показывает, чем может обернуться выуживание данных: не найдя никакой статистически значимой связи между карамельками и прыщами, ученые продолжили прочесывать двадцать одну подгруппу, пока не нашли одну с существенно низким p-значением, из-за чего появился заголовок: «Прыщи появляются от зеленых карамелек!»
Каждый раз, когда проводилась очередная статистическая проверка, шанс сделать ошибочный вывод продолжал расти выше 5 %. Чтобы было понятнее, предположим, что у вас есть кубик с 20 гранями. Шансы сделать ошибку при первой проверке будут такими же, как шансы выбросить единицу. Каждый дополнительно проведенный тест будет еще одним броском кубика, каждый с новым шансом 1 к 20 выбросить единицу. После 21 броска (в соответствии с 21 цветной карамелькой в комиксе) будет шанс примерно 2/3, что единица выпала как минимум однажды, то есть был как минимум один ошибочный результат.
Если выуживание данных такого типа проводится достаточно часто, становится понятно, почему так много исследований, подлежащих воспроизведению, изначально бывают ложноположительными. Другими словами, в этом наборе из ста исследований базовый процент ложноположительного результата, скорее всего, был намного больше 5 %, поэтому значительную часть кризиса воспроизводимости можно объяснить ошибкой базового процента.
К сожалению, исследования с большей вероятностью опубликуют, если в них будут статистически значимые результаты, что приводит к искажению публикации. Исследования, которые не смогли показать статистически значимые результаты, все еще имеют научную значимость, но как сами ученые, так и издания предвзято относятся к ним по ряду причин. Например, в журнале ограничено количество страниц, и, выбирая между двумя исследованиями, редактор всегда отдаст предпочтение значимым результатам. Успешные исследования чаще привлекают внимание СМИ и научного сообщества. Вероятнее, что они также сильнее повлияют на карьеру исследователей.

Все эти факторы являются сильным стимулом к получению значительных результатов экспериментов. В комиксе, несмотря на то что первоначальная гипотеза не показала значимого результата, эксперимент был «спасен» и в конечном итоге опубликован, потому что нашлась второстепенная гипотеза, показавшая значимый результат.
Публикация ложноположительных результатов вроде этого напрямую способствует кризису воспроизводимости и задерживает научный прогресс, направляя будущие исследования к этим ложным гипотезам. Так же как и замалчивание отрицательных результатов. Это приводит к тому, что разные люди проверяют одну и ту же ложную гипотезу снова и снова, потому что никто не знает, что ее уже проверили другие.Есть и иные причины, по которым исследование не удается воспроизвести, включая различные ошибки, которые мы обсуждали в предыдущих разделах (например, систематическая ошибка отбора, систематическая ошибка выжившего и т. д.), закрадывающиеся в результаты. Другая причина заключается в том, что по случайности оригинальное исследование могло продемонстрировать впечатляющий эффект, тогда как на самом деле он был куда скромнее (регрессия к норме). Если это так, то воспроизведенное исследование, скорее всего, будет иметь недостаточно большую выборку (недостаточно мощности), чтобы выявить небольшой эффект, и это приведет к неудачному воспроизведению исследования.
Всегда есть способы преодолеть эти проблемы. Например, можно:
• использовать более низкие p-значения, чтобы учесть ложноположительные ошибки в оригинальном исследовании во всех проведенных тестах;
• использовать выборку большего размера при воспроизведении исследования, чтобы иметь возможность обнаружить даже небольшой эффект;
• заранее сделать спецификацию статистических тестов, чтобы избежать p-взлома.
Тем не менее из-за кризиса воспроизводимости и его причин нужно скептически относиться к любым изолированным исследованиям, особенно если вы не знаете, как собирались и анализировались данные.
В более широком смысле, когда вы интерпретируете утверждение, важно критически оценивать любые данные, подтверждающие его: они поступили из изолированного исследования или за ним стоит целый блок исследований? Если это так, то как были разработаны эти исследования? Все ли ошибки были учтены при планировании и анализе? И так далее.Такое исследование – большой труд. Источники в медиа могут делать ложные выводы и редко предоставляют необходимую информацию, которая позволит вам понять весь замысел эксперимента и оценить его качество. Как правило, за подробной информацией вам придется обратиться к оригинальной научной публикации. Почти во всех научных журналах есть целый раздел, описывающий статистический план исследования, но, учитывая ограничение на количество слов в типичной статье, детали иногда опускают. Ищите полные версии или связанные презентации на сайте журнала – можете даже обратиться напрямую к ученым, обычно они охотно отвечают на вопросы о своей работе.
При идеальном раскладе вы найдете блок из большого числа исследований, которые сотрут все сомнения по поводу случайности результата эксперимента. Если повезет, кто-то уже написал систематический обзор вашего вопроса к исследованию. Систематические обзоры – это организованный способ оценки вопроса с использованием всего объема исследований по определенной теме. Они описывают подробный и всесторонний (систематический) план для обзора результатов исследований в определенной области, включая поиск соответствующих исследований, чтобы исключить систематические ошибки в процессе.
Некоторые, но не все систематические обзоры включают в себя метаанализ, где используются статистические методы для объединения данных из нескольких исследований. Хороший пример – сайт FiveThirtyEight, который специализируется на метаанализе данных из опросов, чтобы лучше прогнозировать развитие событий в политике.
Помимо преимуществ, таких как точность и достоверность оценок, у метаанализа есть и недостатки. Например, сложно комбинировать данные из исследований, где слишком сильно отличаются планы или популяция выборок. Они также не могут самостоятельно устранять искажения из оригинальных исследований. Кроме того, и систематические обзоры, и метаанализ подвержены искажению публикации, потому что включают в себя только общедоступные результаты исследований.
Всякий раз, рассматривая обоснованность утверждения, вначале мы проверяем, проводился ли всеобъемлющий систематический обзор, и, если это так, начинаем с него. В конце концов, систематические обзоры и метаанализы часто используются при принятии решений, например при разработке медицинских инструкций.
Если в этой главе и есть одна основная мысль, то это то, что разработать хороший эксперимент сложно! Мы надеемся, что вы также почерпнули отсюда, что вероятность и статистика – это полезные инструменты для понимания проблем, связанных с неопределенностью. Но этот раздел также призван объяснить, что статистика – это не панацея от неопределенности. Как предложил статистик Эндрю Гельман в статье для журнала The American Statistician,
мы должны «стремиться смириться с неопределенностью и отклонениями».В целом имейте в виду, что, хотя
статистика помогает получить уверенные прогнозы в различных обстоятельствах, она не может точно предсказать, что произойдет в отдельно взятом случае. Например, вы знаете, что в среднем летом на вашем любимом пляже тепло и солнечно, но это не гарантирует, что, когда вы пойдете в отпуск, погода не станет дождливой и не по сезону прохладной.Точно так же медицинские исследования утверждают, что риск заработать рак легких возрастает, если вы курите, и хотя вы можете вычислить доверительный интервал, что средний курильщик за свою жизнь столкнется с раком легких, вероятность и статистика не могут сказать, что произойдет с отдельно взятым курильщиком.
Хотя вероятность и статистика – это не магия, они все же помогают лучше описать уверенность в вероятности различных результатов. Конечно, есть много подводных камней, на которые нужно обратить внимание, но мы надеемся, что вы почерпнете отсюда тот факт, что исследования и данные намного полезнее для преодоления неопределенности, чем догадки и предположения.
Назад: Правильно или нет?
Дальше: Основные идеи

