Implementation of FST in Lucene
The algorithm used for implementing an FST in Lucene is based on the paper Direct Construction of Minimal Acyclic Subsequential Transducers published by Stoyan Mihov and Denis Maurel. This algorithm can be used to build a minimal acyclic sub-sequential transducer (a type of FST) that represents a finite relation, given a sorted list of input words and their outputs. As this algorithm constructs the minimal transducer directly, it has better efficiency than other algorithms. It is the perfect fit for a Lucene FST, as all the terms in the Lucene index are stored in a sorted order.
Note
The following paper was referred to for building the algorithm: .
An FST is implemented in Lucene under the following package:
org.apache.lucene.util.fst
Let us see a few of the classes inside the package that can be used to work with an FST:
Builder<T>: Can be used to build a minimal FST from pre-sorted terms with outputsFST<T>: Represents an FSM and uses a compactbyte[]formatOutputs<T>: Represents the outputs for an FST and provides the basic algebra for building and traversing the FSTPositiveIntOutputs: An implementation ofOutputsclass where each output is a non-negative long valueUtil: Contains static helper methods
Note
The complete Java documentation for the Lucene FST implementation can be obtained from the following link: .
Let us understand this with an example:
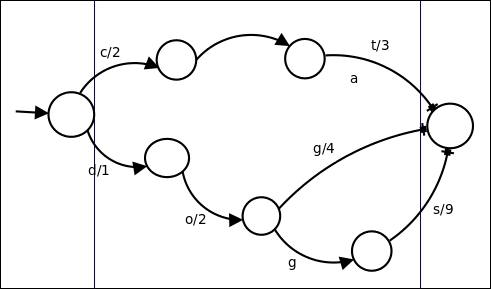
Here is a sample FST that maps three words, cat, dog, and dogs, to their ordinal numbers, which are 5, 7, and 12, respectively. As we traverse the edges of the FST, we sum up the outputs. For example, dog outputs 1 when it hits d, 2 when it hits o, and finally 4 when it hits g. Therefore, the output ordinal will be 7, which is the sum of the outputs corresponding to each hit.
An FST in the Lucene core for the preceding three words would function with reference to the following code:
String inputValues[] = {"cat", "dog", "dogs"}; long outputValues[] = {5, 7, 12}; PositiveIntOutputs outputs = PositiveIntOutputs.getSingleton(); Builder<Long> builder = new Builder<Long>(INPUT_TYPE.BYTE1, outputs); BytesRef scratchBytes = new BytesRef(); IntsRef scratchInts = new IntsRef(); for (int i = 0; i < inputValues.length; i++) { scratchBytes.copyChars(inputValues[i]); builder.add(Util.toIntsRef(scratchBytes, scratchInts), outputValues[i]); } FST<Long> fst = builder.finish();Once this FST has been built, we can use it for FST-related operations. Lucene supports the following FST operations:
- Retrieval by key: The input
dogwould output7 - Retrieval by value: The input
5would outputcat - Scanning: Iteration over key-value pairs in a sorted order
- Deduction: Identification of the n-shortest path by weight
Internally, an FST is stored as a SortedMap class of ByteSequence and Output. If the edges are sorted, it can be represented as:
SortedMap<ByteSequence,SomeOutput>
This implementation of the FST in Lucene requires less RAM but leads to higher CPU utilization during lookup. This is because in Lucene, the FST has been encoded as byte[]. Higher CPU utilization can be attributed to the fact that the amount of processing required for lookup in this implementation of the FST is more. An FST is memory efficient and loads fast from disk, as it is built from pre-sorted inputs in Lucene.

