Chapter 10. Text Tagging with Lucene FST
In the previous chapter, we delved into the setup and working of SolrCloud. We saw the working of distributed indexing and search and how they can be used for handling horizontal scalability and high availability issues in a large-scale Solr deployment. We also discussed the use of SolrCloud as a large-scale NoSQL database.
In this chapter, we will understand what text tagging is and how Lucene and, hence, Solr can be used to implement it in indexing. We will discuss the Finite State Transducer (FST) and the algorithms related to it and learn how it can be integrated with Solr. The topics that we will cover are:
- An overview of FST and text tagging
- Implementation of FST in Lucene
- Text tagging algorithms
- Using Solr for text tagging
- Implementing a text tagger using Solr
An overview of FST and text tagging
FSTs are used for Natural Language Processing (NLP). To understand the function of an FST, let us understand a Finite State Machine (FSM) first. An FSM is an abstract mathematical model of computation that is capable of storing a status or state and changing this state on the basis of the input. FSMs can be applied to various electronic modeling, engineering, and NLP problems. An FSM is represented as a set of nodes containing the various states of a system and labeled edges between these nodes. Here the edges represent transitions from one state to another and the labels represent the conditions on these transitions. A stream of input can be then processed by the FSM causing a number of state transitions.
The following diagram is an example of an FSM that describes some of the states of our day-to-day life:
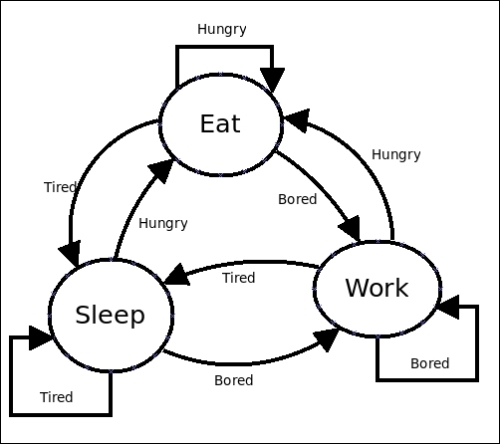
Here Eat, Sleep, and Work are the states in which a person will be. Bored, Tired, and Hungry are the edges showing the conditions under which transitions occur.
An FSM containing a start state and an end state can be used for language processing by generating or recognizing a language defined by all the possible combinations of conditions generated by traversing each of the edges from the start state to the end state.
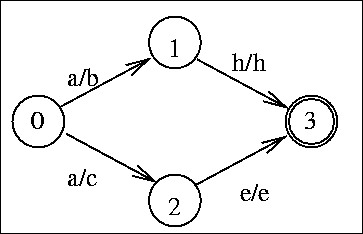
An FST is a special type of FSM. An FST contains an input string and an output string. Therefore, instead of traversing an input string for just accepting or rejecting it, an FST translates the contents of the input string into the output string. That is, an FST accepts an input string and generates an output string. In an FST, each transition has two symbols—one representing the input and the other representing the output. If an FST does not generate an output string, we can assume that the input string has been rejected.
A sample FST is shown in the following figure:
To understand text tagging, let us first look at what geotagging is. Geotagging is a solution for identifying place name references in a natural language. The following text is an example of geotagging:
I live in a house near Delhi.
A geotagger identifies the place Delhi in the previous text. This information can be extended to resolve the place name into a particular latitude and longitude combination.
A text tagger has a broader scope. It can identify names and places from unstructured text. An FST can be used as a mechanism for text tagging. A text tagger consults with a dictionary to extract names or tags. Then, it uses simple NLP to eliminate low-confidence tags. It needs to find names with varying word lengths as well as overlapping names. There is a great deal of theory behind FSMs, FSTs, and text tagging. In any case, let us go ahead and see how an FST functions with the help of Lucene.

