Routing documents to a particular shard
As we have seen, SolrCloud automatically distributes documents to different shards in the index. The queries on the cloud accumulate results from all the different shards and send them back. Why then would we want to route documents to a particular shard?
Suppose that we have a huge cluster of servers as part of SolrCloud—say 100 servers—with 30 shards and 3 replicas for each shard. This gives us ample room to manage a large-scale index expanding to some terabytes of data. A query to get the documents from the index based on a criterion would go to all the 30 shards in the index to get the results. The machine on which the query is executed would accumulate results from all the 30 shards and create the final result set. This would involve huge movement of data between shards and the shard performing the merge operation on the results will have to do some heavy processing, since it would move through 30 different result sets and merge them into a single result set.
It would be better if the query hits fewer shards or probably a single shard and fetches results from that shard without performing any merge operation. This would definitely be faster and less resource and network intensive. Ideally, each query should have an identifier or a set of identifiers pointing to the shards that may contain results from the query. This may not look possible from a broad view. Nevertheless, if the indexing is performed in a fashion that the data is distributed across the shards on the basis of some identifier, it may become possible.
A realistic example is to have documents from different customers indexed in SolrCloud. It would make sense to route the documents on the basis of the customer ID or customer name to the different shards in the cloud. Thus, documents belonging to IBM, Samsung, Apple, and Sony can reside on different shards. While querying, we can specify a prefix in the query so that a query done by IBM hits only the shard on which IBM resides.
Let us create a separate collection in SolrCloud with a routing parameter and then index a few documents into the cloud. We will be indexing the documents in the file docs.csv. We will consider the category as the sharding key. Therefore, Solr will create a hash based on the category and distribute the index on the basis of that hash.
To create the collection (let us call it catcollection), we have to execute the following command. Note the router.field=cat parameter at the end of the CREATE command. This is how we specify a router in a collection:
http://solr1:8080/solr/admin/collections?action=CREATE&name=catcollection&numShards=2&replicationFactor=2&maxShardsPerNode=2&collection.configName=conf1&router.field=cat
We can see that catcollection is created along with the previous collection mycollection. This collection again has two shards—shard1 with solr3 as leader and solr1 as replica, and shard2 with solr4 as leader and solr3 as replica:
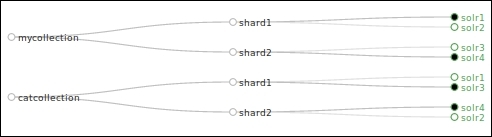
In order to verify whether the routing that we have specified has been successful, we will have to connect to the ZooKeeper server using the zkCli.sh script and look at the clusterstate.json file:
ubuntu@zoo1:~/zookeeper-3.4.6$ ./bin/zkCli.sh -server zoo1,zoo2,zoo3 [zk: zoo1,zoo2,zoo3(CONNECTED) 2] get /clusterstate.json
The output will contain both the collections—mycollection and catcollection—along with all the configuration parameters, as follows:
"catcollection":{ "shards":{ "shard1":{ "range":"80000000-ffffffff", "state":"active", "replicas":{ "core_node2":{ "state":"active", "base_url":"http://solr1:8080/solr", "core":"catcollection_shard1_replica1", "node_name":"solr1:8080_solr"}, "core_node3":{ "state":"active", "base_url":"http://solr3:8080/solr", "core":"catcollection_shard1_replica2", "node_name":"solr3:8080_solr", "leader":"true"}}}, "shard2":{ "range":"0-7fffffff", "state":"active", "replicas":{ "core_node1":{ "state":"active", "base_url":"http://solr4:8080/solr", "core":"catcollection_shard2_replica1", "node_name":"solr4:8080_solr", "leader":"true"}, "core_node4":{ "state":"active", "base_url":"http://solr2:8080/solr", "core":"catcollection_shard2_replica2", "node_name":"solr2:8080_solr"}}}}, "maxShardsPerNode":"2", "router":{ "field":"cat", "name":"compositeId"}, "replicationFactor":"2"}}Here the router parameter has the field cat mentioned in it. Also, the range is specified in the range parameter for each shard. shard1 and shard2 will contain documents with hash IDs in the ranges 80000000-ffffffff and 0-7fffffff, respectively. Therefore, when a document is marked for indexing, the router will calculate the 32 bit hash of the content in the cat field and route the document to the shard whose range includes the hash value of the category value:
Note
The hash values are represented in hexadecimal.
Now let us push the docs.csv file (available with this chapter) to the cloud and see how the documents are distributed across the shards. Execute the following command to push the documents into SolrCloud:
$ java -Dtype=text/csv -Durl=http://solr4:8080/solr/catcollection/update -jar post.jar docs.csv SimplePostTool version 1.5 Posting files to base url http://solr4:8080/solr/catcollection/update using content-type text/csv.. POSTing file docs.csv 1 files indexed. COMMITting Solr index changes to http://solr4:8080/solr/catcollection/update.. Time spent: 0:00:16.608
In order to query a particular shard, we will have to append the shards=shard<no> command at the end of the query. Let us see the documents in shard1 and shard2:
http://solr1:8080/solr/catcollection/select?q=*:*&shards=shard1
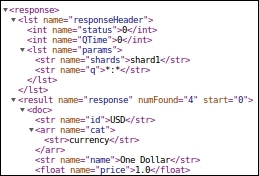
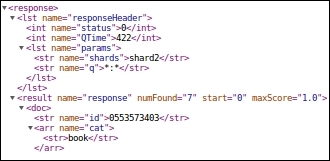
We can see that documents belonging to the category currency are indexed on shard1. Similarly, on executing the query on shard2, we can see that the documents belonging to the categories book and electronics are indexed on shard2:
http://solr1:8080/solr/catcollection/select?q=*:*&shards=shard2
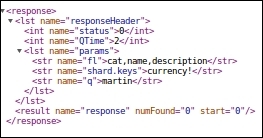
To send a query to a particular shard, we have to use the shard.keys parameter in our query. For example, to send the following query to the shard containing only books, we need to execute the following query:
http://solr1:8080/solr/catcollection/select?q=martin&fl=cat,name,description&shard.keys=book! 
We can see that all the books that have the word martin in their descriptions become a part of the query result. If we try to execute the same query with a different shard key, say currency, we will not be able to get any results:
http://solr1:8080/solr/catcollection/select?q=martin&fl=cat,name,description&shard. keys=currency!