Distributed indexing and search
Now that we have SolrCloud up and running, let us see how indexing and search happen in a distributed environment. Go to the <solr_installation>/example/exampledocs folder where there are some sample XML files. Let us add some documents from the hd.xml file to SolrCloud. We will use the node solr1 for adding documents to the index. Here we are passing the collection name in the update URL instead of the core. The output from the command execution is shown in the following snippet:
$ java -Durl=http://solr1:8080/solr/mycollection/update -jar post.jar hd.xml SimplePostTool version 1.5 Posting files to base url http://solr1:8080/solr/mycollection/update using content-type application/xml.. POSTing file hd.xml 1 files indexed. COMMITting Solr index changes to http://solr1:8080/solr/mycollection/update.. Time spent: 0:00:21.209
Note
Please use localhost instead of the solr1 host if running on a local machine.
The documents are now committed into SolrCloud. To find the documents, perform a search on any node. Let us say we search on the node solr2. Execute the following query:
http://solr2:8080/solr/mycollection/select/?q=*:*
We can see that there are two documents in the result:
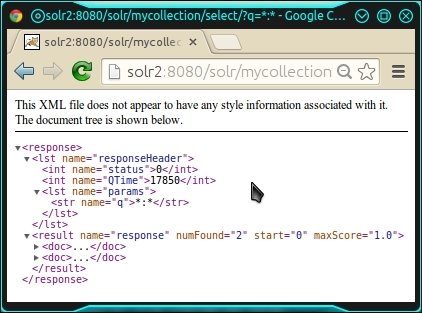
So, we actually indexed the documents via the solr1 server in our SolrCloud and searched via the solr2 server. The documents were indexed somewhere inside SolrCloud. In order to check where the documents went, we will have to go to each server and examine the overview of the collection. In the present case, the documents were indexed on servers solr3 and solr4, which are replicas.
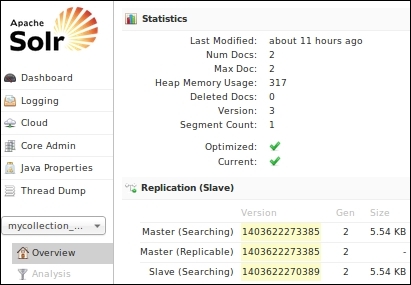
This means that we can index documents from any shard in SolrCloud, and those documents will be routed to a server in the cloud. Similarly, we can search from any shard in the cluster and query the complete index on SolrCloud.
Later in this chapter, we will also look at how and why to send documents to a particular shard.
Let us try indexing via the other machines. Execute the following commands from the exampledocs folder on the remaining machines in SolrCloud:
java -Durl=http://solr2:8080/solr/mycollection/update -jar post.jar mem.xml java -Durl=http://solr3:8080/solr/mycollection/update -jar post.jar vidcard.xml java -Durl=http://solr4:8080/solr/mycollection/update -jar post.jar monitor*.xml
This will index the documents in the mem.xml, vidcard.xml, monitor.xml, and monitor2.xml files into SolrCloud. On searching via, say, the solr3 machine, we can get all the documents. We indexed all nine documents, and all of them were found during a search on SolrCloud:
http://solr3:8080/solr/mycollection/select/?q=*:*

This means that since we have a four-node cluster, we can now index and search via all four nodes. The nodes themselves take care of routing of the documents to their appropriate shards and indexing them. Ideally, this should result in a four-fold increase in the indexing and searching speed. However, in a real-life scenario, the number of queries per second for indexing and search would be a little less than four times. It may also depend on the amount of data in the index, the IO capabilities of the server, and the network bandwidth between the machines in the cloud.

