Working of OR and AND clauses
Let us see how the collector and scorer work together to calculate the results for both OR and AND clauses. Let us first focus on the OR clause. Considering the earlier index, suppose we perform the following search:
orange OR strawberry OR not
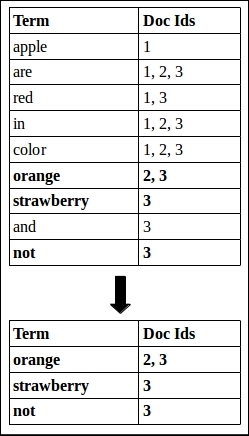
A search for orange OR strawberry OR not
On the basis of the terms in the query, Doc Id 1 was rejected during the Boolean filtering logic. We will need to introduce the concept of accumulator here. The purpose of the accumulator is to loop through each term in the query and pass the documents that contain the term to the collector.
In the present case, when the accumulator looks for documents containing orange, it gets documents 2 and 3. The output of the accumulator in this case is 2x1, 3x1, where 2 and 3 are the document IDs and 1 is the number of times the term orange occurs in both the documents.Next, it will process the term strawberry where it will get document ID 3. Now, the accumulator outputs 3x1 that adds to our previous output 3x1 and forms 3x2, meaning that document ID 3 contains two of our input terms. The term not is processed in a similar fashion.
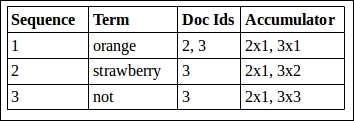
An accumulator at work
Here Sequence denotes the sequence in which the terms are processed.
The Collector will get Doc Id 2 with a score of 1, as it occurs only in one document and Doc Id 3 with a score of 3. Therefore, the output from the collector will be as follows:
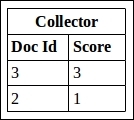
Document scores
In this case, since the score for Doc Id 3 is higher, it will be ranked higher than document 2. This type of search is known as a "term at a time" search, since we are processing documents for a term and we go through the terms in the query one by one to process the result.
The score here is a relative representation of frequency. It is not the actual score as per the equation shown in the following image that can be also found in , Customizing the Solr Scoring Algorithm:

Let us see how the AND clause works in filtering and ranking results. Let us perform an AND search with the following clause:
color AND red AND orange
While searching with the AND clause, first all terms matching the query are selected from the index. The collector then selects the document id corresponding to the first term and matches it against the document ids corresponding to the remaining terms.
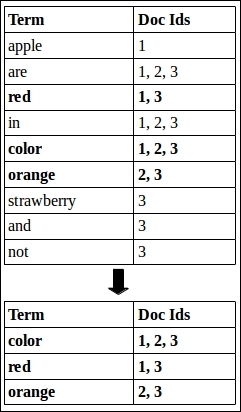
Query: color AND red AND orange
In this case, Doc Id 1 will be selected and matched against IDs corresponding to terms red and orange. Since no match is found with the term orange, the next document (Doc Id 2) corresponding to the term color will be selected, which is again not found in term red. Finally, Doc Id 3 will be selected and it finds a match with the terms red and orange. The accumulator will output only document ID 3 in this case. This concept is known as "doc at a time" search, as we are processing documents instead of terms.
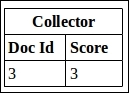
Document scores
In most cases, the query would be a mix of AND and OR clauses. Therefore, the algorithm for finding and ranking the results depends on the query parameters.
The minimum should match parameter, which is a part of the eDisMax query parser and discussed later in this book, is also an important factor in deciding the algorithm to be used for a search. In the case of an OR query, the minimum should match parameter is taken as 1, as only one term out of all the terms in our query should match. As seen in this case, the term at a time algorithm was used for search. The AND query results in a minimum should match parameter that is more than 1, and in this case, the doc at a time search was used.
The complexity of both the algorithms is shown in the following image:

Algorithm complexity
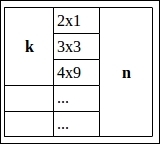
In this case, the following needs to be noted:
q: Number of terms in a query- Example:
orange OR strawberry OR not
- Example:
p: Number of documents in terms matching the query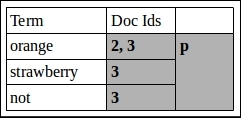
k: Number of documents the accumulator collects for showing the first pagen: Total number of documents that match the query