Chapter 3. Solr Internals and Custom Queries
In this chapter, we will see how the relevance scorer works on the inverted index. We will understand how AND and OR clauses work in a query and look at how query filters and the minimum match parameter work internally. We will understand how the eDisMax query parser works. We will implement our own query language as a Solr plugin using which we will perform a proximity search. This chapter will give us an insight into the customization of the query logic and creation of custom query parsers as plugins in Solr. This chapter will cover the following topics:
- How a scorer works on an inverted index
- How
ORandANDclauses work - How the eDisMax query parser works
- The minimum should match parameter
- How filters work
- Using Bibliographic Retrieval Services (BRS) queries instead of DisMax
- Proximity search using SWAN (Same, With, Adj, Near) queries
- Creating a parboiled parser
- Building a Solr plugin for SWAN queries
- Integrating the SWAN plugin in Solr
Working of a scorer on an inverted index
We have, so far, understood what an inverted index is and how relevance calculation works. Let us now understand how a scorer works on an inverted index. Suppose we have an index with the following three documents:

3 Documents
To index the document, we have applied WhitespaceTokenizer along with the EnglishMinimalStemFilterFactory class. This breaks the sentence into tokens by splitting whitespace, and EnglishMinimalStemFilterFactory converts plural English words to their singular forms. The index thus created would be similar to that shown as follows:
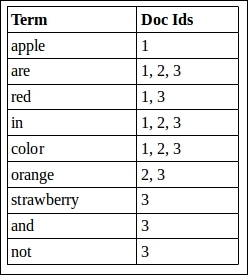
An inverted index
A search for the term orange will give documents 2 and 3 in its result. On running a debug on the query, we can see that the scores for both the documents are different and document 2 is ranked higher than document 3. The term frequency of orange in document 2 is higher than that in document 3.
However, this does not affect the score much as the number of terms in the document is small. What affects the score here is the fieldNorm value, which ranks shorter documents higher than longer documents.
Tip
A debug can be run on a query by appending debugQuery=true to the Solr query.
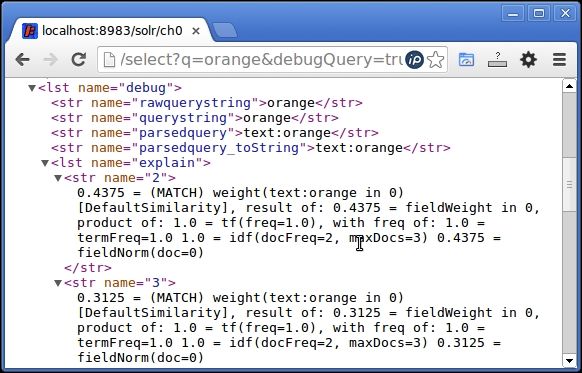
Relevance score
Inside the Lucene API, when a query is presented to the IndexSearcher class for search, IndexReader is opened and the query is passed to it and the result is collected in the Collector object — instance of Collector class. The IndexSearcher class also initializes the scorer and calculates the score for each document in the binary result set. This calculation is fast and it happens within a loop.

