The eDisMax query parser
Let us understand the working of the eDisMax query parser. We will also look at the minimum should match parameter and filters in this section.
Working of the eDisMax query parser
Let us first refresh our memory about the different query modes in Solr. Query modes are ways to call different query parsers to process a query. Solr has different query modes that are specified by the defType parameter in the Solr URL. The defType parameter can also be changed by specifying a different defType parameter for the requestHandler property in the solrconfig.xml file. The popularly used query modes available in Solr are DisMax (disjunction Max) and eDisMax (extended disjunction max) in addition to the default (no defType) query mode. There are many other queryModes available, such as lucene, maxscore, and surround, but these are less used.
The query parser used by DisMax can process simple phrases entered by the user and search for individual terms across different fields using different boosts for different fields on the basis of their significance. The DisMax parser supports an extremely simplified subset of the Lucene query parser syntax. The eDisMax query parser, on the other hand, supports the full Lucene query syntax. It supports queries with AND, OR, NOT, +, and - clauses. It also supports pure negative nested queries such as +foo (-foo) that will match all documents. It lets the end user specify the fields allowed in the input query. We can also use the word shingles in a phrase boost (pf2 and pf3 parameters in Solr query) on the basis of the proximity of words.
Let us create a sample index and understand the working of a sample query in the eDisMax mode.
Index all files in the Solr default installation into the exampledocs folder. In Solr 4.6, execution of the following commands inside the exampledocs folder will result in the indexing of all files:
java -jar post.jar *.xml java -Dtype=text/csv -jar post.jar *.csv java -Dtype=application/json -jar post.jar *.json
This will index all the XML files along with the books.csv and books.json files into the index. The index should contain approximately 46 documents. It can be verified by running the following query on the Solr query interface:
http://localhost:8983/solr/collection1/select?q=*:*
A search for ipod usb charger with a boost of 2 on the name and a default boost on the text, along with a proximity boost on both the fields and a minimum match of 2, will form the following query:
http://localhost:8983/solr/collection1/select?q=ipod usb charger&qf=text name^2&pf=text name&mm=2&defType=dismax&debugQuery=true
The debug output shows how the eDisMax parser parses the query:
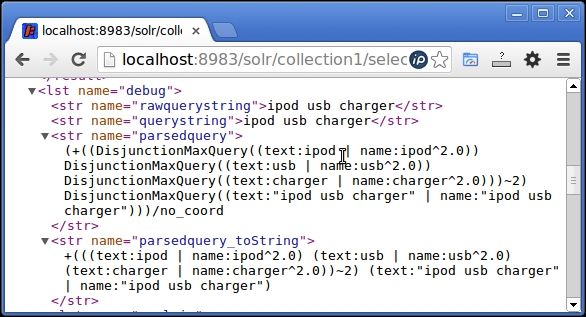
At the outermost level, the query (also known as the Boolean query) has 2 clauses:
- Clause 1:
+( ( DisjunctionMaxQuery((text:ipod | name:ipod^2.0)) DisjunctionMaxQuery((text:usb | name:usb^2.0)) DisjunctionMaxQuery((text:charger | name:charger^2.0)) )~2 )
- Clause 2:
DisjunctionMaxQuery((text:"ipod usb charger" | name:"ipod usb charger"))
The first clause has a + sign preceding it, which means that the first clause must match in every document returned in the result set. The second clause is an OR query that should match within the documents returned. Even if the clause does not find a match in the document, the document will be returned but with a lower score.
The first clause also has 3 sub-clauses. Each one should match with the documents in the result set. Also out of the 3 clauses, at least 2 must match, which we have specified by the mm=2 (minimum should match = 2) parameter in our Solr query. The mm=2 parameter in the Solr query is converted to the clause ~2 in our parsed query.
What does the clause DisjunctionMaxQuery((text:ipod | name:ipod^2.0)) do? Here we search for ipod in the fields text and name and find the score in both the cases, that is the scores for ipod in text and ipod in name, and return the maximum of these two scores as the output of the DisjunctionMaxQuery clause. Why do we return the maximum score? Why not take the sum and return that as the score? Suppose, we are searching for usb charger in two fields, name and description. If we take the sum, then a document that has usb charger in the name and not in the description will have the same score as another document that has usb in both name and description but charger nowhere in these fields.
If still returning the maximum score is not something that makes sense in a particular scenario, we can use the tie parameter to decide how the final score of the query will be influenced by the scores of lower scoring compared to the higher scoring fields. A value of 0.0 means that only the maximum scoring subquery contributes to the final score. On the other hand, a value of 1.0 means that the final score will be a sum of individual subquery scores. In this case, the maximum scoring subquery loses its significance. Ideally, a value of 0.1 is preferred to have a mix of both scenarios.
The clause text:ipod is the smallest piece of the query, which is also known as a term query. This is where the tf-idf scoring we discussed above happens. This is encapsulated by the DisjunctionMaxQuery clause we just saw.
The second clause of the query, DisjunctionMaxQuery((text:"ipod usb charger" | name:"ipod usb charger")), is again composed of two subqueries inside the DisjunctionMaxQuery clause. The query here is text:"ipod usb charger", which has multiple terms against a single field, and is known as a phrase query. It seeks all the documents that contain all the specified terms in the specified field and discards those documents where the terms are adjacent to each other in the specified order. In our case, the subquery will seek documents where the terms ipod, usb, and charger appear and in the field text and then check the order of the terms in the document. If the terms are adjacent to each other, the document is selected and ranked high.
Therefore, the interpretation of the query we saw earlier is as follows:
- Look for the documents that have two of the three terms
ipod, usb, andcharger. Search only thenameandtextfields. A document does not get a high score for matching any one of these terms in both fields. - The
namefield is important, so it is boosted by2. - If the documents from the previous section have the phrase
"ipod usb charger"in thetextor thenamefield, they are given higher scores.
The minimum should match parameter
We saw a brief preview of how the minimum should match parameter works in the earlier section. The default value of mm is 1 and it can be overwritten in solrconfig.xml. It can also be passed as a query parameter as we did in our example in the previous section.
When dealing with optional clauses, the mm parameter is used to decide how many of the optional clauses must match in a document for that document to be selected as a part of the result set. Note that the mm parameter can be a positive integer, a negative integer, or a percentage. Let us see all the options for specifying the mm parameter:
- Positive integer: A positive number
3specifies that at least three clauses mush match irrespective of the total number of clauses in the query. - Negative integer: A negative number
2specifies that, out of the total number of clauses (n) in the query, the minimum number of matching clauses isn-2. Therefore, if the query has five clauses,3is the must match number. - Percentage: A value of
75%specifies that the matching clauses should constitute at least 75 percent of the total number of clauses in the query. A query with four clauses will have a minimum match number of3ifmmis specified as75%. - Negative percentage: A negative value of
-25%indicates that the optional clauses constitute 25 percent of the total number of clauses. Therefore, ifmm=-25%for four clauses, there should be at least three matching clauses. - Positive integer (> or <) percentage: Let's take an example, say,
4<75%. This means that, if the number of optional clauses in the query is less than or equal to4, then all of them must match. However, if the number of optional clauses is greater than4, say8, only 75 percent of the clauses or 6 clauses should match. - Multiple conditions: These are used to define multiple conditions, each being valid for the number before it. For example,
2<-25% 9<-3indicates that, if there are less than or equal to two clauses, all the clauses should match. If there are three to nine clauses, all but 25 percent are required. If there are more than nine clauses, all but three are required.
No matter what condition is specified and what number is derived during calculation, Solr will never use a value greater than the number of optional clauses or a value less than 1. That is, no matter what the calculated value for mm is, the minimum number of required matches would never be less than 1 or greater than the number of optional clauses.
The minimum should match parameter should be properly thought through for each use case. It is also important to have some sample user queries to figure out a particular formula for mm. The value of mm should be such that both precision and recall requirements for most queries are satisfied.
Minimum should match is an expensive algorithm during a search. There was a major bug fix in Lucene version 4.3 that improved the performance of the minimum should match in DisMax queries. The bug fix is shown in the following figure:
The improvement fix can be referred to in the following link: .
Working of filters
Filter queries do not affect the score of the documents in the result set. Filter queries cache the document IDs for inclusion or exclusion in a result set. This makes filter queries in Solr very fast. Since results obtained by using filter queries are not ranked, it is recommended to use filter queries to narrow down the result set rather than for the initial search itself.
Suppose that, in the index we created earlier, we are looking for a hard drive. The query for the same would be as follows:
http://localhost:8983/solr/collection1/select?q=hard drive&qf=name^2 text&pf=name&fl=id,name,score&defType=dismax&debugQuery=true
The result has the following three documents. Note that the scores are also printed.
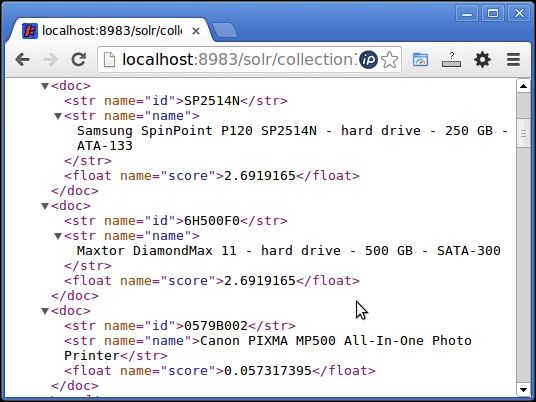
Scores for documents in a query result
I am a brand conscious shopper and prefer the brand Samsung to other brands. Therefore, in this case, I would filter the search results on the basis of the brand field, which in our case is the field manu. The query would be as follows:
http://localhost:8983/solr/collection1/select?q=hard drive&qf=name^2 text&pf=name&fq=manu:samsung&fl=id,name,score&defType=dismax&debugQue ry=true
The output clearly shows that the score of the document remained the same after applying the filter query:
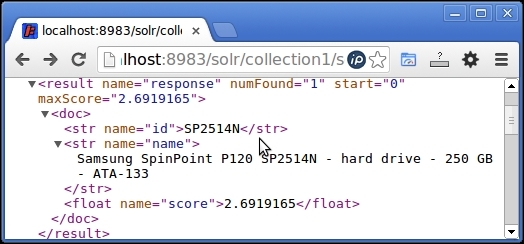
Same score after applying the filter
As discussed earlier, the purpose of a filter query is to narrow down the result set. On an e-commerce site, the filter query should be used to narrow the result set on the basis of the facets. The first query should be an eDisMax query that gives results on the basis of the score of the documents. Once the results are in place, we would like to narrow them down but keep the results in the order that they were ranked. This is where filter queries make sense, as applying filter queries to the existing result set will narrow down the result and also keep the products in their previous order of ranking.
Suppose I am a customer and I am looking for a Levi's jeans in blue color. The query that I will enter would most probably be levis jeans blue. Here the search has to happen across multiple attributes of each product. The attributes that I have mentioned during my search are brand, category, and color. How should the search query be formed in this case? If we use the eDisMax query parser, all the terms will be searched in all the fields in my documents.
If I specify the query fields as brand category color, all the terms levis, jeans, and blue would be searched for all the three fields:
q = levis jeans blue qf = brand category color
The matching documents would be found mostly when the following terms match: brand:"levis", category:"jeans", and color:"blue". We would display the listing with the facets, say, price and size. A selection on the facet size would be treated as a filter query adding the fq parameter to our existing query:
fq = size:32
This will narrow down the result to a list of products that match my preferences. If the result is not too large to confuse me or too small with limited choices, I will most probably select a product and make a purchase. If the result is large enough, I can select more parameters from the facet price to narrow down the results further.

