Building a custom scorer
Now that we know how the default relevance calculation works, let us look at how to create a custom scorer. The default scorer used for relevance calculation is known as DefaultSimilarity. In order to create a custom scorer, we will need to extend DefaultSimilarity and create our own similarity class and eventually use it in our Solr schema. Solr also provides the option of specifying different similarity classes for different fieldTypes configuration directive in the schema. Thus, we can create different similarity classes and then specify different scoring algorithms for different fieldTypes as also a different global Similarity class.
Let us create a custom scorer that disables the IDF factor of the scoring algorithm. Why would we want to disable the IDF? The IDF boosts documents that have query terms that are rare in the index. Therefore, if a query contains a term that occurs in fewer documents, the documents containing the term will be ranked higher. This does not make sense for certain fields, such as name, designation, or age.
The default implementation for idf function can be found in the Lucene source code inside the org.apache.lucene.search.similarities.DefaultSimilarity class:
public float idf(long docFreq, long numDocs) { return (float)(Math.log(numDocs/(double)(docFreq+1)) + 1.0); }In this code snippet, numDocs is the total number of documents in the collection and docFreq is the number of documents that have the specific term from the query. To customize the IDF, we would extend the DefaultSimilarity class and create a NoIDFSimilarity class that returns 1 for idf as indicated by the following code:
public class NoIDFSimilarity extends DefaultSimilarity { @Override public float idf(long docFreq, long numDocs) { return 1.0f; } }The NoIDFSimilarity class can be used where we would like to ignore the commonality of a term across the entire collection. If we do not consider the rareness of a term in the algorithm, both common and rare terms in the entire index will have the same ranking. This makes sense when a search is on a targeted field, such as a name, a category, or an e-mail address, where the rareness of the term does not make much sense.
Let us compile our customized similarity classes and implement them in our schema. For this, we need the lucene-core-4.6.0.jar file, which can be found in the <solr folder>/example/solr-webapp/webapp/WEB-INF/lib/ folder. Run the following command to compile the NoIDFSimilarity.java file:
javac -cp /opt/solr-4.6.0/example/solr-webapp/webapp/WEB-INF/lib/lucene-core-4.6.0.jar:. -d . NoIDFSimilarity.java Note
The commands here are for Linux systems. For Windows systems, use Windows path format while executing the commands.
This will compile the Java file into the com.myscorer folder. Now create a myscorer.jar file for the package com.myscorer by running the jar command on the created folder com:
jar -cvf myscorer.jar com The JAR file needs to be placed with the Lucene JAR file in our Solr library:
cp myscorer.jar /opt/solr-4.6.0/example/solr-webapp/webapp/WEB-INF/lib/ In order to check the scorer, let us index all files in the Solr default installation under the exampledocs folder. In Solr 4.6, execution of the following commands inside the exampledocs folder will result in indexing of all files:
java -jar post.jar *.xml java -Dtype=text/csv -jar post.jar *.csv java -Dtype=application/json -jar post.jar *.json
This step will index all the XML files along with the books.csv and books.json files into the index. The index should contain approximately 46 documents. This can be verified by running the following query on the Solr query interface: http://localhost:8983/solr/collection1/select?q=*:*
Search for ipod in the field text with the DefaultSimilarity class and note the score and order of a few documents that appear on the top.
Also, note that the debugQuery=true parameter in the query gives the name of the similarity class used. [DefaultSimilarity] in this case.
http://localhost:8983/Solr/collection1/select/q=text:ipod&fl=*&debugQuery=true
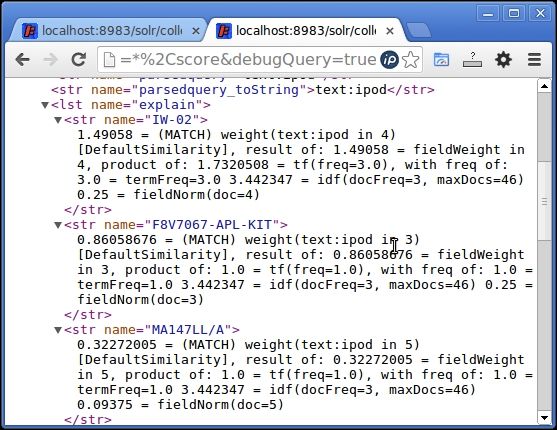
Search for ipod using DefaultSimilarity
Now let’s modify our schema.xml file and put NoIDFSimilarity as the default similarity class to be used and observe how our search behaves. Add the following line to the end of schema.xml file and restart Solr:
<similarity class=”com.myscorer.NoIDFSimilarity”/>
This will change the similarity for all fields in our schema to the NoIDFSimilarity class. On running the same query again, we can see that scores of the documents have changed. Also, the similarity class is now [NoIDFSimilarity].
Note
Solr will need to be restarted whenever schema.xml or solrconfig.xml file is changed. Only then will the changes be visible in Solr.
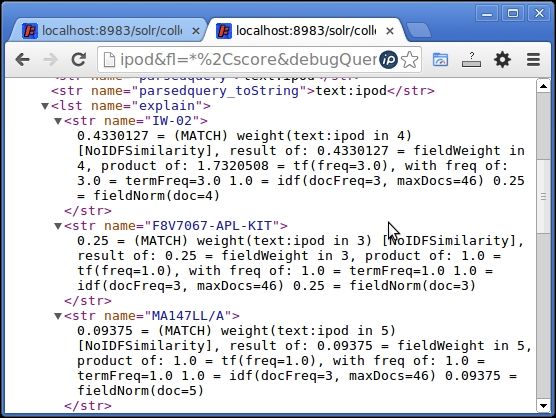
Search for ipod using NoIDFSimilarity
Let us create another custom scorer where length normalization is disabled. The default implementation for the lengthNorm function can be found in the Lucene source code inside the org.apache.lucene.search.similarities.DefaultSimilarity class:
public float lengthNorm(FieldInvertState state) { final int numTerms; if (discountOverlaps) numTerms = state.getLength() - state.getNumOverlap(); else numTerms = state.getLength(); return state.getBoost() * ((float) (1.0 / Math.sqrt(numTerms))); }In a broad sense, this extracts the number of terms in a field and returns Boost * (1/sqrt(number of terms)) so that shorter fields have a higher boost. In order to disable boosting due to shorter field length, either consider the number of terms as 1 for this algorithm or return 1 irrespective of the number of terms and the boost on the field. Let us create our own implementation of DefaultSimilarity known as NoLengthNormSimilarity where we will simply return the boost for the field and discard any calculations with respect to the number of terms in the field. The code will override the lengthNorm function as follows:
public class NoLengthNormSimilarity extends DefaultSimilarity { // return field’s boost irrespective of the length of the field. @Override public float lengthNorm(FieldInvertState state) { return state.getBoost(); } }Note
The purpose of creating a similarity class without length normalization is to treat documents with different number of terms in their field similarly.
Thus, a document with say 5 tokens will be treated as equal to another document with say 50, 500, or 5000 tokens. Now, in a search for WiFi router, two products, say Netgear R6300 WiFi router and D-Link DSL-2750U Wireless N ADSL2 4-Port WiFi router, will have the same boost. Earlier with the default similarity, the Netgear R6300 WiFi router would have had a higher boost as it had a smaller number of terms than that in D-Link DSL-2750U Wireless N ADSL2 4-Port WiFi router. On the negative side, a document with a field having the Netgear R6300 WiFi router will have the same boost as another document with the field having the following text:
Experience blazing speeds upto 300Mbps of wireless speed while you upload and download data within a matter of seconds when you use this WiFi router.
A user searching for a Wi-Fi router is specifically searching for a product rather than a description of the product. Hence, it would make more sense if we use the NoLengthNormSimilarity class in our product names in an e-commerce website.
It is possible to use two different similarity classes for two different fieldTypes in Solr. To implement this, we need a global similarity class that can support the specification of the fieldType level similarity class implementation. This is provided by solr.SchemaSimilarityFactory.
Simply add this similarity class at the global level at the end of schema.xml file as follows, which will replace the earlier similarities we had introduced:
<similarity class=”solr.SchemaSimilarityFactory”/>
Specify the fieldType level similarity classes in the section where fieldType is defined. For example, we can add NoLengthNormSimilarity to fieldType text_general and NoIDFSimilarity to text_ws, as follows:
<fieldType name=”text_ws” class=”solr.TextField” positionIncrementGap=”100”> <analyzer> <tokenizer class=”solr.WhitespaceTokenizerFactory”/> <filter class=”solr.EnglishMinimalStemFilterFactory”/> </analyzer> <similarity class=”com.myscorer.NoIDFSimilarity”/> </fieldType> <fieldType name=”text_general” class=”solr.TextField” positionIncrementGap=”100”> <analyzer type=”index”> <tokenizer class=”solr.StandardTokenizerFactory”/> <filter class=”solr.StopFilterFactory” ignoreCase=”true” words=”stopwords.txt” /> <filter class=”solr.LowerCaseFilterFactory”/> </analyzer> <analyzer type=”query”> <tokenizer class=”solr.StandardTokenizerFactory”/> <filter class=”solr.StopFilterFactory” ignoreCase=”true” words=”stopwords.txt” /> <filter class=”solr.SynonymFilterFactory” synonyms=”synonyms.txt” ignoreCase=”true” expand=”true”/> <filter class=”solr.LowerCaseFilterFactory”/> </analyzer> <similarity class=”com.myscorer.NoLengthNormSimilarity”/> </fieldType>
This can be tested by restarting Solr and running the Solr query again with debugQuery=true, which is similar to what we did before for testing NoIDFSimilarity.
There are a few other similarity algorithms that are available in Solr. The details are available in the following API documents: .
Some of these similarities, such as SweetSpotSimilarity, have an option of specifying additional parameters for different fieldTypes. This can be specified in schema.xml file while defining the similarity class implementation for fieldType by adding additional parameters during definition. A sample implementation is as shown in the following code snippet:
<fieldType name=”text_baseline” class=”solr.TextField” indexed=”true” stored=”false”> <analyzer class=”org.apache.lucene.analysis.standard.StandardAnalyzer”/> <similarity class=”solr.SweetSpotSimilarityFactory”> <!-- TF --> <float name=”baselineTfMin”>6.0</float> <float name=”baselineTfBase”>1.5</float> <!-- plateau norm --> <int name=”lengthNormMin”>3</int> <int name=”lengthNormMax”>5</int> <float name=”lengthNormSteepness”>0.5</float> </similarity> </fieldType>
We will discuss some of these similarity algorithms later in this chapter.

