Chapter 2. Customizing the Solr Scoring Algorithm
In this chapter, we will go through the relevance calculation algorithm used by Solr for ranking results and understand how relevance calculation works with reference to the parameters in the algorithm. In addition to this, we will look at tweaking the algorithm and create our own algorithm for scoring results. Then, we will add it as a plugin to Solr and see how the search results are ranked. We will discuss the problems with the default algorithm used in Solr and define a new algorithm known called the information gain model. This chapter will incorporate the following topics:
- The relevance calculation algorithm
- Building a custom scorer
- Drawback of the TF-IDF model
- The information gain model
- Implementing the information gain model
- Options to TF-IDF similarity
- BM25 similarity
- DFR similarity
Relevance calculation
Now that we are aware of how Solr works in the creation of an inverted index and how a search returns results for a query from an index, the question that comes to our mind is how Solr or Lucene (the underlying API) decides which documents should be at the top and how the results are sorted. Of course, we can have custom sorting, where we can sort results based on a particular field. However, how does sorting occur in the absence of any custom sorting query?
The default sorting mechanism in Solr is known as relevance ranking. During a search, Solr calculates the relevance score of each document in the result set and ranks the documents so that the highest scoring documents move to the top. Scoring is the process of determining how relevant a given document is with respect to the input query. The default scoring mechanism is a mix of the Boolean model and the Vector Space Model (VSM) of information retrieval. The binary model is used to figure out documents that match the query set, and then the VSM is used to calculate the score of each and every document in the result set.
In addition to the VSM, the Lucene scoring mechanism supports a number of pluggable models, such as probabilistic models and language models. However, we will focus on the VSM as it is a default scoring algorithm, and it works pretty well for most of the cases. The VSM requires that the document and queries are represented as weighted vectors in a multidimensional space where each distinct index item is a dimension and weights are TF-IDFvalues. The TF-IDF formula is the core of the relevance calculation in Lucene. The practical scoring formula used in Lucene is shown in the following image:
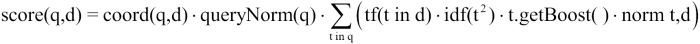
The default implementation of the tf-idf equation for Lucene is known as default similarity (the class is DefaultSimilarity inside Lucene). Let us look at the terms in the equation before understanding how the formula works:
tf(t in d): This is the term frequency, or the number of times termt(in the query) appears in documentd. Documents that have more occurrences for a given term will have a higher score. The default implementation for this part of the equation in theDefaultSimilarityclass is the square root of frequency.idf(t): This is the inverse document frequency, or the inverse of the number of documents in which term t appears, also known as the inverse of DocFreq. This means that a term that occurs in fewer documents is a rare term and results in a higher score. The implementation in theDefaultSimilarityclass is as follows:idf(t) = 1+log(numDocs / (docFreq+1))
t.getBoost(): This is the search time boost of termtin queryqas specified in the query syntax.norms(t,d): This function is a product of index time boosts and the length normalization factor. During indexing, a field can be boosted by calling thefield.setBoost()function before adding the field to the document. This is known as index time boost. Length normalization (lengthNorm) is computed on the basis of the number of tokens in a field for a document. The purpose oflengthNormfactor is to provide a higher score for shorter fields. Once calculated, this cannot be modified during a search.coord(q,d): This function is a score factor that specifies the number of query terms that are found in a document. A document that has more of the query’s terms will have a higher score than that of another document that has fewer query terms.queryNorm(q): This function is used to make the scores between queries comparable. As this is the same factor for all documents, it does not affect the document ranking but just makes the scores from different queries or indexes comparable.
Boosting is used to change the score of documents retrieved from a search. There is index time boosting and search time or query time boosting of documents. Index time boosting is used to boost fields in documents permanently. Once a document is boosted during index time, the boost is stored with the document. Therefore, after the search completes and during relevancy calculation, the stored boost is taken into consideration. Search time or query time boosting is dynamic. Certain fields can be boosted in the query that can result in certain documents getting a higher relevancy score than others. For example, we can boost the score of books by adding the parameter cat:book^4 in the query. This boosting will make the score of books relatively higher than the score of other items in the index.
For details on the scoring algorithm, please go through the following documentation: .

