Handling a multilingual search
Content is produced and consumed in native languages. Sometimes even normal-looking documents may contain more than one language. This makes language an important aspect for search. A user should be able to search in his or her language. Each language has its own set of characters. Some languages use characters to form words, while some use characters to form sentences. Some languages do not even have spaces between the characters forming sentences. Let us look at some examples to understand the complexities that Solr should handle during text analysis for different languages.
Suppose a document contains the following sentence in English:
Incorporating the world's largest display screen on the slimmest of bodies the Xperia Z Ultra is Sony's answer to all your recreational needs.
The question here is whether the words world's and Sony's should be indexed. If yes, then how? Should a search for Sony return this document in the result? What would be the stop words here—the words that do not need to be indexed? Ideally, we would like to ignore stop words such as the, on, of, is, all, or your. How should the document be indexed so that Xperia Z Ultra matches this document? First, we need to ensure that Z is not a stop word. The search should contain the term xperia z ultra. This would break into +xperia OR z OR ultra. Here xperia is the only mandatory term. The results would be sorted in such a fashion that the document (our document) that contains all three terms will be at the top. Also, ideally we would like the search for world or sony to return this document in the result. In this case, we can use the LetterTokenizerFactory class, which will separate the words as follows:
World's => World, s Sony's => Sony, s
Then, we need to pass the tokens through a stop filter to remove stop words. The output from the stop filter passes through a lowercase filter to convert all tokens to lowercase. During the search, we can use a WhiteSpaceTokenizer and a LowerCaseFilter tokenizer to tokenize and process our input text.
In a real-life situation, it is advisable to take multiple examples with different use cases and work around the scenarios to provide the desired solutions for those use cases. Given that the numbers of examples are large, the derived solution should satisfy most of the cases.
If we translate the same sentence into German, here is how it will look:

German
Solr comes with an inbuilt field type for German - text_de, which has a StandardTokenizer class followed by a lowerCaseFilter class and a stopFilter class for German words. In addition, the analyzer has two German-specific filters, GermanNormalizationFilter and GermanLightStemFilter. Though this text analyzer does a pretty good job, there may be cases where it will need improvement.
Let's translate the same sentence into Arabic and see how it looks:

Arabic
Note that Arabic is written from right to left. The default analyzer in the Solr schema configuration is text_ar. Again tokenization is carried out with StandardTokenizer followed by LowerCaseFilter (used for non-Arabic words embedded inside the Arabic text) and the Arabic StopFilter class. This is followed by the Arabic Normalization filter and the Arabic Stemmer. Another aspect used in Arabic is known as a diacritic. A diacritic is a mark (also known as glyph) added to a letter to change the sound value of the letter. Diacritics generally appear either below or above a letter or, in some cases, between two letters or within the letter. Diacritics such as ' in English do not modify the meaning of the word. In contrast, in other languages, the addition of a diacritic modifies the meaning of the word. Arabic is such a language. Thus, it is important to decide whether to normalize diacritics or not.
Let us translate the same sentence into Japanese and see what we get:

Japanese
Now that the complete sentence does not have any whitespace to separate the words, how do we identify words or tokens and index them? The Japanese analyzer available in our Solr schema configuration is text_ja. This analyzer identifies the words in the sentence and creates tokens. A few tokens identified are as follows:
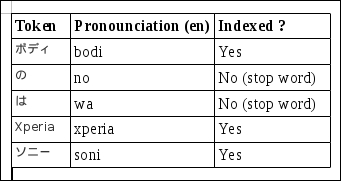
Japanese tokens
It also identifies some of the stop words and removes them from the sentence.
As in English, there are other languages where a word is modified by adding a suffix or prefix to change the tense, grammatical mood, voice, aspect, person, number, or gender of the word. This concept is called inflection and is handled by stemmers during indexing. The purpose of a stemmer is to change words such as indexing, indexed, or indexes into their base form, namely index. The stemmer has to be introduced during both indexing and search so that the stems or roots are compared during both indexing and search.
The point to note is that each language is unique and presents different challenges to the search engine. In order to create a language-aware search, the steps that need to be taken are as follows:
- Identification of the language: Decide whether the search would handle the dominant language in a document or find and handle multiple languages in the document.
- Tokenization: Decide the way tokens should be formed from the language.
- Token processing: Given a token, what processing should happen on the token to make it a part of the index? Should words be broken up or synonyms added? Should diacritics and grammars be normalized? A stop-word dictionary specific to the language needs to be applied.
Token processing can be done within Solr by using an appropriate analyzer, tokenizer, or filter. However, for this, all possibilities have to be thought through and certain rules need to be formed. The default analyzers can also be used, but it may not help in improving the relevance factor of the result set. Another way of handling a multilingual search is to process the document during indexing and before providing the data to Solr for indexing. This ensures more control on the way a document can be indexed.
The strategies used for handling a multilingual search with the same content across multiple languages at the Solr configuration level are:
- Use one Solr field for each language: This is a simple approach that guarantees that the text is processed the same way as it was indexed. As different fields can have separate analyzers, it is easy to handle multiple languages. However, this increases the complexity at query time as the input query language needs to be identified and the related language field needs to be queried. If all fields are queried, the query execution speed goes down. Also, this may require creation of multiple copies of the same text across fields for different languages.
- Use one Solr core per language: Each core has the same field with different analyzers, tokenizers, and filters specific to the language on that core. This does not have much query time performance overhead. However, there is significant complexity involved in managing multiple cores. This approach would prove complex in supporting multilingual documents across different cores.
- All languages in one field: Indexing and search are much easier as there is only a single field handling multiple languages. However, in this case, the analyzer, tokenizer, and filter have to be custom built to support the languages that are expected in the input text. The queries may not be processed in the same fashion as the index. Also, there might be confusion in the scoring calculation. There are cases where particular characters or words may be stop words in one language and meaningful in another language.
Note
Custom analyzers are built as Solr plugins. The following link gives more details regarding the same: .
The final aim of a multilingual search should be to provide better search results to the end users by proper processing of text both during indexing and at query time.

