Working of analyzers, tokenizers, and filters
When a document is indexed, all fields within the document are subject to analysis. An analyzer examines the text within fields and converts them into token streams. It is used to pre-process the input text during indexing or search. Analyzers can be used independently or can consist of one tokenizer and zero or more filters. Tokenizers break the input text into tokens that are used for either indexing or search. Filters examine the token stream and can keep, discard, or convert them on the basis of certain rules. Tokenizers and filters are combined to form a pipeline or chain where the output from one tokenizer or filter acts as an input to another. Ideally, an analyzer is built up of a pipeline of tokenizers and filters and the output from the analyzer is used for indexing or search.
Let us see the example of a simple analyzer without any tokenizers and filters. This analyzer is specified in the schema.xml file in the Solr configuration with the help of the <analyzer> tag inside a <fieldtype> tag. Analyzers are always applied to fields of type solr.TextField. An analyzer must be a fully qualified Java class name derived from the Lucene analyzer org.apache.lucene.analysis.Analyzer. The following example shows a simple whitespace analyzer that breaks the input text by whitespace (space, tab, and new line) and creates tokens, which can then be used for both indexing and search:
<fieldType name="whitespace" class="solr.TextField"> <analyzer class="org.apache.lucene.analysis.WhitespaceAnalyzer"/> </fieldType>
Note
Downloading the example code
You can download the example code files from your account at for all Packt Publishing books that you have purchased. If you purchased this book elsewhere, you can visit and register yourself to have the files e-mailed directly to you.
A custom analyzer is one in which we specify a tokenizer and a pipeline of filters. We also have the option of specifying different analyzers for indexing and search operations on the same field. Ideally, we should use the same analyzer for indexing and search so that we search for the tokens that we created during indexing. However, there might be cases where we want the analysis to be different during indexing and search.
The job of a tokenizer is to break the input text into a stream of characters or strings, or phrases that are usually sub-sequences of the characters in the input text. An analyzer is aware of the field it is configured for, but a tokenizer is not. A tokenizer works on the character stream fed to it by the analyzer and outputs tokens. The tokenizer specified in schema.xml in the Solr configuration is an implementation of the tokenizer factory - org.apache.solr.analysis.TokenizerFactory.
A filter consumes input from a tokenizer or an analyzer and produces output in the form of tokens. The job of a filter is to look at each token passed to it and to pass, replace, or discard the token. The input to a filter is a token stream and the output is also a token stream. Thus, we can chain or pipeline one filter after another. Ideally, generic filtering is done first and then specific filters are applied.
Note
An analyzer can have only one tokenizer. This is because the input to a tokenizer is a character stream and the output is tokens. Therefore, the output of a tokenizer cannot be used by another.
In addition to tokenizers and filters, an analyzer can contain a char filter. A char filter is another component that pre-processes input characters, namely adding, changing, or removing characters from the character stream. It consumes and produces a character stream and can thus be chained or pipelined.
Let us look at an example from the schema.xml file, which is shipped with the default Solr:
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100"> <analyzer type="index"> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" /> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> <analyzer type="query"> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" /> <filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> </fieldType>
The field type specified here is named text_general and it is of type solr.TextField. We have specified a position increment gap of 100. That is, in a multivalued field, there would be a difference of 100 between the last token of one value and first token of the next value. A multivalued field has multiple values for the same field in a document. An example of a multivalued field is tags associated with a document. A document can have multiple tags and each tag is a value associated with the document. A search for any tag should return the documents associated with it. Let us see an example.
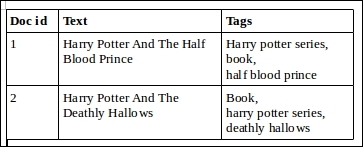
Example of multivalued field – documents with tags
Here each document has three tags. Suppose that the tags associated with a document are tokenized on comma. The tags will be multiple values within the index of each document. In this case, if the position increment gap is specified as 0 or not specified, a search for series book will return the first document. This is because the token series and book occur next to each other in the index. On the other hand, if a positionIncrementGap value of 100 is specified, there will be a difference of 100 positions between series and book and none of the documents will be returned in the result.
In this example, we have multiple analyzers, one for indexing and another for search. The analyzer used for indexing consists of a StandardTokenizer class and two filters, stop and lowercase. The analyzer used for the search (query) consists of three filters, stop, synonym, and lowercase filters.
The standard tokenizer splits the input text into tokens, treating whitespace and punctuation as delimiters that are discarded. Dots not followed by whitespace are retained as part of the token, which in turn helps in retaining domain names. Words are split at hyphens (-) unless there is a number in the word. If there is a number in the word, it is preserved with hyphen. @ is also treated as a delimiter, so e-mail addresses are not preserved.
The output of a standard tokenizer is a list of tokens that are passed to the stop filter and lowercase filter during indexing. The stop filter class contains a list of stop words that are discarded from the tokens received by it. The lowercase filter converts all tokens to lowercase. On the other hand, during a search, an additional filter known as synonym filter is applied. This filter replaces a token with its synonyms. The synonyms are mentioned in the synonyms.txt file specified as an attribute in the filter.
Let us make some modifications to the stopwords.txt and synonyms.txt files in our Solr configuration and see how the input text is analyzed.
Add the following two words, each in a new line in the stopwords.txt file:
and the
Add the following in the synonyms.txt file:
King => Prince
We have now told Solr to treat and and the as stop words, so during analysis they would be dropped. During the search phrase, we map King to Prince, so a search for king will be replaced by a search for prince.
In order to view the results, perform the following steps:
- Open up your Solr interface, select a core (say collection1), and click on the Analysis link on the left-hand side.
- Enter the text of the first document in text box marked field value (index).
- Select the field name and field type value as
text. - Click on Analyze values.
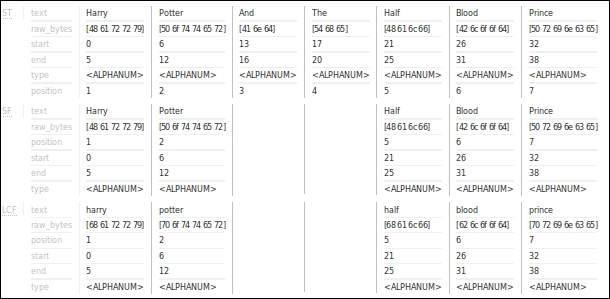
Solr analysis for indexing
We can see the complete analysis phase during indexing. First, a standard tokenizer is applied that breaks the input text into tokens. Note that here Half-Blood was broken into Half and Blood. Next, we saw the stop filter removing the stop words we mentioned previously. The words And and The are discarded from the token stream. Finally, the lowercase filter converts all tokens to lowercase.
During the search, suppose the query entered is Half-Blood and King. To check how it is analyzed, enter the value in Field Value (Query), select the text value in the FieldName / FieldType, and click on Analyze values.
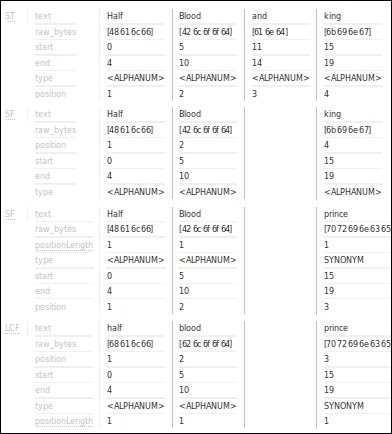
Solr analysis during a search
We can see that during the search, as before, Half-Blood is tokenized as Half and Blood, And and is dropped in the stop filter phase. King is replaced with prince during the synonym filter phase. Finally, the lowercase filter converts all tokens to lowercase.
An important point to note over here is that the lowercase filter appears as the last filter. This is to prevent any mismatch between the text in the index and that in the search due to either of them having a capital letter in the token.
The Solr analysis feature can be used to analyze and check whether the analyzer we have created gives output in the desired format during indexing and search. It can also be used to debug if we find any cases where the results are not as expected.
What is the use of such complex analysis of text? Let us look at an example to understand a scenario where a result is expected from a search but none is found. The following two documents are indexed in Solr with the custom analyzer we just discussed:
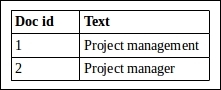
After indexing, the index will have the following terms associated with the respective document ids:
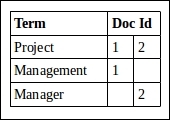
A search for project will return both documents 1 and 2. However, a search for manager will return only document 2. Ideally, manager is equal to management. Therefore, a search for manager should also return both documents. This intelligence has to be built into Solr with the help of analyzers, tokenizers, and filters. In this case, a synonym filter mentioning manager, management, manages as synonyms should do the trick. Another way to handle the same scenario is to use stemmers. Stemmers reduce words into their stem, base, or root form. In this chase, the stem for all the preceding words will be manage. There is a huge list of analyzers, tokenizers, and filters available with Solr by default that should be able to satisfy any scenario we can think of.
For more information on analyzers, tokenizers, and filters, refer to:
AND and OR queries are handled by respectively performing an intersection or union of documents returned from a search on all the terms of the query. Once the documents or hits are returned, a scorer calculates the relevance of each document in the result set on the basis of the inbuilt Term Frequency-Inverse Document Frequency (TF-IDF) scoring formula and returns the ranked results. Thus, a search for Project AND Manager will return only the 2nd document after the intersection of results that are available after searching both terms on the index.
It is important to remember that text processing during indexing and search affects the quality of results. Better results can be obtained by high-quality and well thought of text processing during indexing and search.
Note
TF-IDF is a formula used to calculate the relevancy of search terms in a document against terms in existing documents. In a simple form, it favors a document that contains the term with high frequency and has lower occurrence in all the other documents.
In a simple form, a document with a high TF-IDF score contains the search term with high frequency, and the term itself does not appear as much in other documents.
More details on TF-IDF will be explained in , Customizing a Solr Scoring Algorithm.

