Chapter 1. Solr Indexing Internals
This chapter will walk us through the indexing process in Solr. We will discuss how input text is broken and how an index is created in Solr. Also, we will delve into the concept of analyzers and tokenizers and the part they play in the creation of an index. Second, we will look at multilingual search using Solr and discuss the concepts used for measuring the quality of an index. Third, we will look at the problems faced during indexing while working with large amounts of input data. Finally, we will discuss SolrCloud and the problems it solves. The following topics will be discussed throughout the chapter. We will discuss use cases for Solr in e-commerce and job sites. We will look at the problems faced while providing search in an e-commerce or job site:
- Solr indexing fundamentals
- Working of analyzers, tokenizers, and filters
- Handling a multilingual search
- Measuring the quality of search results
- Challenges faced in large-scale indexing
- Problems SolrCloud intends to solve
- The e-commerce problem statement
The job site problem statement – Solr indexing fundamentals
The index created by Solr is known as an inverted index. An inverted index contains statistics and information on terms in a document. This makes a term-based search very efficient. The index created by Solr can be used to list the documents that contain the searched term. For an example of an inverted index, we can look at the index at the back of any book, as this index is the most accurate example of an inverted index. We can see meaningful terms associated with pages on which they occur within the book. Similarly, in the case of an inverted index, the terms serve to point or refer to documents in which they occur.

Inverted index example
Let us study the Solr index in depth. A Solr index consists of documents, fields, and terms, and a document consists of strings or phrases known as terms. Terms that refer to the context can be grouped together in a field. For example, consider a product on any e-commerce site. Product information can be broadly divided into multiple fields such as product name, product description, product category, and product price. Fields can be either stored or indexed or both. A stored field contains the unanalyzed, original text related to the field. The text in indexed fields can be broken down into terms. The process of breaking text into terms is known as tokenization. The terms created after tokenization are called tokens, which are then used for creating the inverted index. The tokenization process employs a list of token filters that handle various aspects of the tokenization process. For example, the tokenizer breaks a sentence into words, and the filters work on converting all of those words to lowercase. There is a huge list of analyzers and tokenizers that can be used as required.
Let us look at a working example of the indexing process with two documents having only a single field. The following are the documents:

Documents with Document Id and content (Text)
Suppose we tell Solr that the tokenization or breaking of terms should happen on whitespace. Whitespace is defined as one or more spaces or tabs. The tokens formed after the tokenization of the preceding documents are as follows:

Tokens in both documents
The inverted index thus formed will contain the following terms and associations:
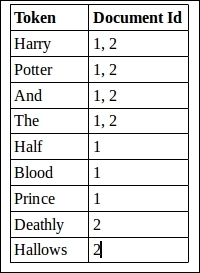
Inverted index
In the index, we can see that the token Harry appears in both documents. If we search for Harry in the index we have created, the result will contain documents 1 and 2. On the other hand, the token Prince has only document 1 associated with it in the index. A search for Prince will return only document 1.
Let us look at how an index is stored in the filesystem. Refer to the following image:
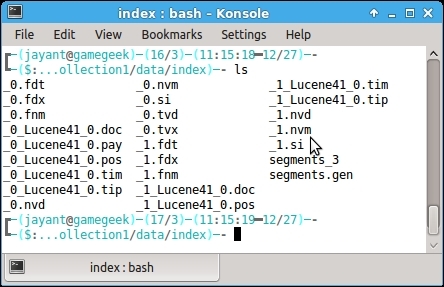
Index files on disk
For the default installation of Solr, the index can be located in the <Solr_directory>/example/solr/collection1/data. We can see that the index consists of files starting with _0 and _1. There are two segments* files and a write.lock file. An index is built up of sub-indexes known as segments. The segments* file contains information about the segments. In the present case, we have two segments namely _0.* and _1.*. Whenever new documents are added to the index, new segments are created or multiple segments are merged in the index. Any search for an index involves all the segments inside the index. Ideally, each segment is a fully independent index and can be searched separately.
Lucene keeps on merging these segments into one to reduce the number of segments it has to go through during a search. The merger is governed by mergeFactor and mergePolicy. The mergeFactor class controls how many segments a Lucene index is allowed to have before it is coalesced into one segment. When an update is made to an index, it is added to the most recently opened segment. When a segment fills up, more segments are created. If creating a new segment would cause the number of lowest-level segments to exceed the mergeFactor value, then all those segments are merged to form a single large segment. Choosing a mergeFactor value involves a trade-off between indexing and search. A low mergeFactor value indicates a small number of segments and a fast search. However, indexing is slow as more and more mergers continue to happen during indexing. On the other hand, maintaining a high value of mergeFactor speeds up indexing but slows down the search, since the number of segments to search increases. Nevertheless, documents can be pushed to newer segments on disk with fewer mergers. The default value of mergeFactor is 10. The mergePolicy class defines how segments are merged together. The default method is TieredMergePolicy, which merges segments of approximately equal sizes subject to an allowed number of segments per tier.
Let us look at the file extensions inside the index and understand their importance. We are working with Solr Version 4.8.1, which uses Lucene 4.8.1 at its core. The segment file names have Lucene41 in them, but this string is not related to the version of Lucene being used.
Tip
The index structure is almost similar for Lucene 4.2 and later.
The file types in the index are as follows:
segments.gen, segments_N: These files contain information about segments within an index. Thesegments_Nfile contains the active segments in an index as well as a generation number. The file with the largest generation number is considered to be active. Thesegments.genfile contains the current generation of the index..si: The segment information file stores metadata about the segments. It contains information such as segment size (number of documents in the segment), whether the segment is a compound file or not, a checksum to check the integrity of the segment, and a list of files referred to by this segment.write.lock: This is a write lock file that is used to prevent multiple indexing processes from writing to the same index..fnm: In our example, we can see the_0.fnmand_1.fnmfiles. These files contain information about fields for a particular segment of the index. The information stored here is represented by FieldsCount, FieldName, FieldNumber, and FieldBits. FieldCount is used to generate and store ordered number of fields in this index. If there are two fields in a document, FieldsCount will be 0 for the first field and 1 for the second field. FieldName is a string specifying the name as we have specified in our configuration. FieldBits are used to store information about the field such as whether the field is indexed or not, or whether term vectors, term positions, and term offsets are stored. We study these concepts in depth later in this chapter..fdx: This file contains pointers that point a document to its field data. It is used for stored fields to find field-related data for a particular document from within the field data file (identified by the.fdtextension)..fdt: The field data file is used to store field-related data for each document. If you have a huge index with lots of stored fields, this will be the biggest file in the index. Thefdtandfdxfiles are respectively used to store and retrieve fields for a particular document from the index.. tim: The term dictionary file contains information related to all terms in an index. For each term, it contains per-term statistics, such as document frequency and pointers to the frequencies, skip data (the.docfile), position (the.posfile), and payload (the.payfile) for each term..tip: The term index file contains indexes to the term dictionary file. The.tipfile is designed to be read entirely into memory to provide fast and random access to the term dictionary file..doc: The frequencies and skip data file consists of the list of documents that contain each term, along with the frequencies of the term in that document. If the length of the document list is greater than the allowed block size, the skip data to the beginning of the next block is also stored here..pos: The positions file contains the list of positions at which each term occurs within documents. In addition to terms and their positions, the file also contains part payloads and offsets for speedy retrieval..pay: The payload file contains payloads and offsets associated with certain term document positions. Payloads are byte arrays (strings or integers) stored with every term on a field. Payloads can be used for boosting certain terms over others..nvdand.nvm: The normalization files contain lengths and boost factors for documents and fields. This stores boost values that are multiplied into the score for hits on that field..dvdand.dvm: The per-document value files store additional scoring factors or other per-document information. This information is indexed by the document number and is intended to be loaded into main memory for fast access..tvx: The term vector index file contains pointers and offsets to the.tvd(term vector document) file..tvd: The term vector data file contains information about each document that has term vectors. It contains terms, frequencies, positions, offsets, and payloads for every document..del: This file will be created only if some documents are deleted from the index. It contains information about what files were deleted from the index..cfsand.cfe: These files are used to create a compound index where all files belonging to a segment of the index are merged into a single.cfsfile with a corresponding.cfefile indexing its subfiles. Compound indexes are used when there is a limitation on the system for the number of file descriptors the system can open during indexing. Since a compound file merges or collapses all segment files into a single file, the number of file descriptors to be used for indexing is small. However, this has a performance impact as additional processing is required to access each file within the compound file.
For more information please refer to: .
Ideally, when an index is created using Solr, the document to be indexed is broken down into tokens and then converted into an index by filling relevant information into the files we discussed earlier. We are now clear with the concept of tokens, fields, and documents. We also discussed payload. Term vectors, frequencies, positions, and offsets form the term vector component in Solr. The term vector component in Solr is used to store and return additional information about terms in a document. It is used for fast vector highlighting and some other features like "more like this" in Solr. Norms are used for calculating the score of a document during a search. It is a part of the scoring formula.
Now, let us look at how analyzers, tokenizers, and filters work in the conversion of the input text into a stream of tokens or terms for both indexing and searching purposes in Solr.

