Локальный исследовательский архив
Локальный исследовательский архив – это архив, который создается в рамках конкретного исследования для хранения полевых данных и вспомогательных материалов. Такой архив является продуктом коллективной работы всей команды исследователей, однако будет нелишним определить ответственного за архивацию данных, т. е. члена исследовательской команды, который выберет удобную платформу для архивирования, создаст базовую структуру разделов в архиве, будет координировать остальных участников, отслеживая полноту и консистентность загружаемых материалов. Поскольку еще со времени диссертационного исследования я интересуюсь вопросами вторичного анализа данных и архивирования, а также информационными технологиями, то роль архивариуса в большинстве наших проектов логичным образом доставалась мне.
Локальный исследовательский архив
Это архив, который создается в рамках конкретного исследования для хранения полевых данных и вспомогательных материалов.
В ходе наших исследований для архивирования данных мы использовали облачное хранилище «Google Диск» (drive.google.com), работа с которым доступна каждому, кто имеет учетную запись электронной почты в домене gmail.com (см. рис. 8.1). «Google Диск» позволяет просматривать большинство загруженных файлов без скачивания (аудио, видео, фото, тексты). Это удобно для получения оперативной информации о состоянии полевых работ в любом месте и с любого гаджета. Альтернативными вариантами платформ для исследовательских архивов могут быть dropbox, icloud и другие виды облачных хранилищ. Отмечу, что хранение данных в облачном хранилище является достаточно надежным с точки зрения рисков утраты материалов, однако мы практиковали также резервное хранение на внешних usb-накопителях.
Наш опыт показал, что важно загружать материалы в архив сразу по мере их поступления, так как это не только существенно облегчает группировку материалов по отдельным кейсам, но и позволяет освободить место на диктофоне, смартфоне, фотоаппарате, видеокамере для новых материалов. У нас случались досадные ситуации, когда видеозапись интервью приходилось прерывать на середине, потому что память гаджета оказывалась переполненной из-за не перенесенных в архив предыдущих записей.

Рис. 8.1. Загрузка материалов в локальный архив на «Google Диске»
Источник: Скриншот, сделанный автором данной главы в ходе создания и ведения исследовательского архива проекта «Социальная мобильность» с использованием сервисов Google.
Локальный архив удобно использовать не только для хранения полевых материалов, но также и для доработки инструментария. Например, в проекте «Межпоколенная социальная мобильность» черновики анкет или гайдов изначально рассылались всем участникам проекта по электронной почте. Однако довольно быстро стали очевидны недостатки этого способа: несколько исследователей одновременно приступали к редактированию одного и того же файла на своих локальных устройствах, попутно оставляя комментарии в общей переписке, что затрудняло дальнейшее сведение всех правок в единый документ. Затем, когда рабочий файл был размещен в локальном архиве для совместного редактирования, правки и комментарии перестали теряться, и обсуждение нашего инструментария и иных полевых материалов стало более эффективным.
Локальный архив удобно использовать не только для хранения полевых материалов, но также и для доработки инструментария.
Структура локального исследовательского архива
Для удобства использования исследовательского архива в каждом новом проекте мы придавали ему структуру в соответствии с логикой полевой работы, т. е. создавали отдельные папки по типам данных: для аудиофайлов, для визуальных материалов, для бланков информированных согласий, для литературы по проекту (см. рис. 8.2). Эта структура могла видоизменяться по мере наполнения архива, однако основные разделы, как правило, сохранялись. Внутри папок по типам данных обычно создавались подпапки по регионам, категориям респондентов, и др.

Рис. 8.2. Структура локального архива: каждому типу данных соответствует определенная папка
Источник: Скриншот, сделанный автором данной главы в ходе создания и ведения исследовательского архива проекта «Социальная мобильность» с использованием сервисов Google.
В зависимости от задач проекта в архиве могут появляться папки с вторичными данными для облегчения дальнейшей работы с ними, папки с публикациями по проекту и другие категории данных. Например, в проекте «Прошлое и настоящее рабочих районов» важными структурными элементами архива стали статистические материалы по изучаемым районам, таблицы упоминаемости районов и заводов, сканы и копии печатных изданий, а также материалы моих сопутствующих подпроектов: «Дом на месте завода» и «Креативное пространство школьного музея».
Как видно из рис. 8.3, загруженные файлы имеют унификацию имен, т. е. использование одного и того же стандарта при наименовании файлов, позволяющего не только быстро найти в архиве нужный файл, но уже из названия понять, к какой категории данных относится конкретный файл. Если пренебречь унификацией и загружать файлы с произвольными именами, то при увеличении количества данных будет все сложнее ориентироваться в них и контролировать, все ли материалы присутствуют в архиве.

Рис. 8.3. Структура локального архива: внутри каждой папки содержатся файлы одного и того же типа данных с унификацией имен файлов
Источник: Cкриншоты, сделанные автором данной главы в ходе создания и ведения исследовательского архива проекта «Социальная мобильность» с использованием сервисов Google.
Каким образом можно сделать унификацию архивных материалов? В наших текущих проектах использовалось два способа. Первый способ: каждому кейсу присваивалось длинное уникальное имя, состоящее из порядкового номера респондента, категории респондента (регион/район/подгруппа (например, бывший заводчанин), фамилии исследователя, ответственного за данный кейс (интервьюер, если речь идет об интервью, или наблюдатель, если речь идет о наблюдении), даты проведения, типа данных (при необходимости). Этот вариант представлен в табл. 8.1. Если используются какие-либо сокращения в именах, присваиваемых кейсам, то будет нелишним пояснить порядок сокращений в отдельном документе.
Второй вариант: присваивать файлам в архиве короткие уникальные имена, но добавлять полную информацию в самом начале каждого файла (по тем же категориям, которые используются в первом варианте). Такой формат мы использовали в публичной версии нашего исследовательского архива в проекте «Межпоколенная социальная мобильность» (см. рис. 8.4).
Таблица 8.1. Первый способ унификации: из каких элементов складывается полное имя файла в архиве
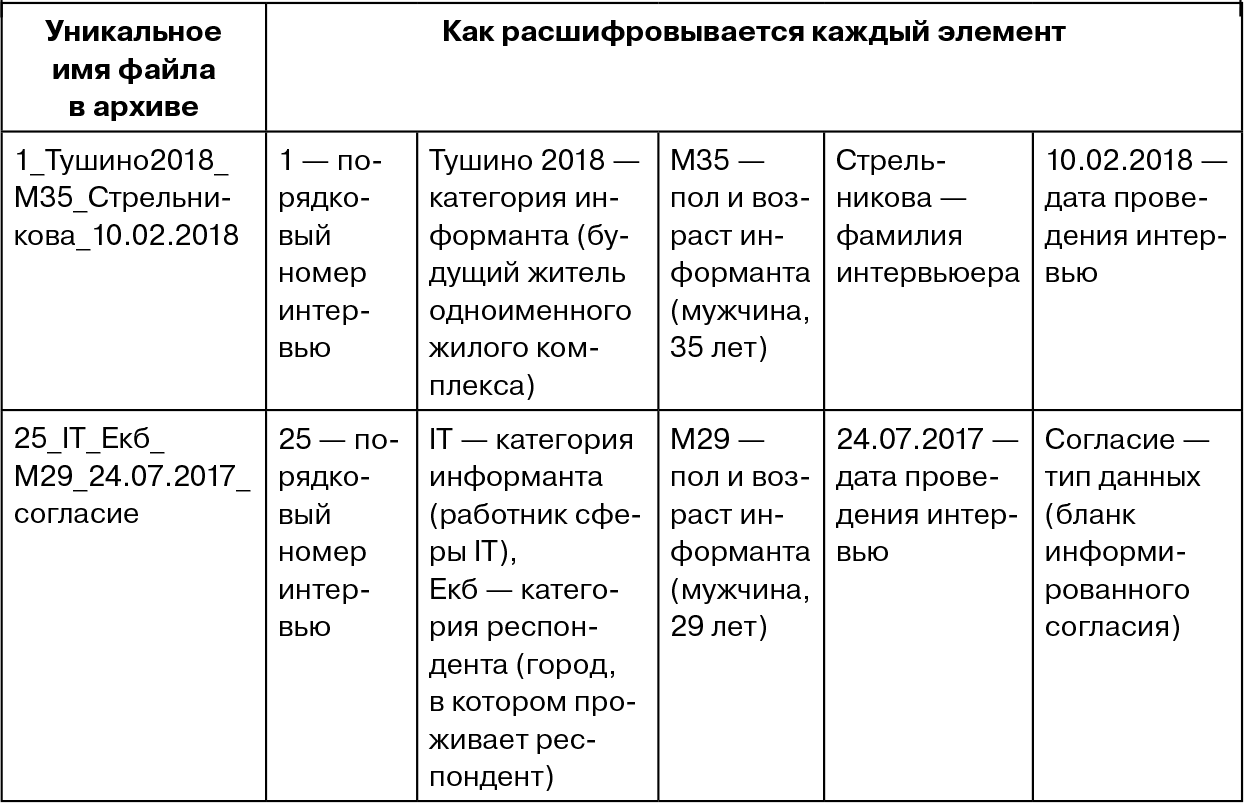

Рис. 8.4. Второй способ унификации: данные с короткими именами, размещенные в публичной версии локального исследовательского архива
Источник: Cкриншоты, сделанные автором данной главы в ходе создания и ведения исследовательского архива проекта «Социальная мобильность» с использованием сервисов Google.
Если один и то же исследовательский коллектив проводит сразу несколько проектов, то задача архивирования усложняется, так как важно не перепутать материалы разных исследований. Для этого можно в уникальное имя кейсов добавлять аббревиатуру названия проекта, а также добавлять название проекта в колонтитул каждого полевого материала.

