ГЛАВА 7
ЛИНЕЙНЫЕ МОДЕЛИ
Да, я вру, потому что ты требуешь от меня однозначных ответов, а однозначные ответы почти всегда ложь.
Элена Ферранте
Нередко модели устанавливают определенную функциональную зависимость между переменными. Она может быть линейной, вогнутой, выпуклой, S-образной или содержать пороговый эффект. Из всех этих вариантов линейные модели самые простые и распространенные — и именно они будут находиться в центре внимания в этой главе. Влияние образования на уровень доходов, увеличение продолжительности жизни благодаря физической активности, а также зависимость явки избирателей от дохода — все это можно количественно измерить с помощью линейных моделей. В начале главы мы освежим ваши знания о линейных функциях с одной переменной. Затем покажем, как регрессия приводит данные в соответствие с линейной функцией, раскрывая знак, величину и значимость эффекта. Кроме того, мы обсудим, почему ошибки, помехи и разнородность означают, что данные не попадают точно на линию регрессии. Затем мы расширим линейную модель, включив в нее несколько переменных, и объясним, как выполнить подгонку моделей со множеством переменных. Для того чтобы выработать интуитивное понимание таких моделей, мы опишем модель успеха как линейную функцию навыков и удачи. В конце главы мы поговорим о том, как использование данных и регрессий в качестве руководства к действию ограничивает количество ошибок, но может также привести к малозначимым, консервативным действиям. Мышление, ориентированное на большие коэффициенты, способно сдерживать инновации. Для выявления более инновационных вариантов мы рассмотрим возможность построения других, более умозрительных моделей.
ЛИНЕЙНЫЕ МОДЕЛИ
В линейной зависимости величина изменения одной переменной в результате изменения другой переменной не зависит от значения второй переменной. Если высота дерева находится в линейной зависимости от его возраста, это дерево ежегодно вырастает на одну и ту же величину. Если стоимость дома возрастает линейно в зависимости от его площади, то ее увеличение на 200 квадратных футов повышает стоимость дома вдвое по сравнению с увеличением на 100 квадратных футов. Увеличение площади дома на 400 квадратных футов повышает стоимость дома в четыре раза.
Линейные модели
В линейной модели изменения независимой переменной x приводят к линейным изменениям зависимой переменной y по следующей формуле:
y = mx + b,
где m — это наклон линии, а b — отрезок, отсекаемый на координатной оси, значение зависимой переменной, когда независимая переменная равна нулю.
Модель линейной регрессии находит линию, которая минимизирует расстояние до точек данных. Линейная регрессия может объяснить колебания уровня преступности, объема продаж стиральных машин и даже цен на вина . Предположим, у нас есть данные о взрослых в возрасте от двадцати до шестидесяти лет, в том числе расстояние, которое они проходят каждую неделю. Мы находим следующее уравнение регрессии:
Проходимое человекомi расстояние в милях = −0,1 · возрастi + 12 + ei
Это уравнение регрессии указывает знак (с возрастом расстояние уменьшается) и величину (каждый год возраста сокращает расстояние на десятую часть мили) эффекта. В данном примере отрезок на координатной оси не имеет отношения к делу, поскольку находится вне нашего диапазона данных, то есть не включает данные о людях в возрасте около нуля лет. Уравнение позволяет предположить, что сорокалетний человек должен проходить восемь миль в неделю, а пятидесятилетний — семь миль. Данные, используемые для построения регрессии, не попадают точно на линию регрессии. На рис. 7.1 показаны гипотетические данные, на основе которых построена наша линия регрессии. Серым кружком обозначена сорокалетняя женщина по имени Бобби, которая проходит одиннадцать миль в неделю — расстояние, превышающее оценочный показатель модели на три мили. Для того чтобы привести эти данные в соответствие с моделью, в уравнение включена погрешность по каждой точке данных, которая обозначена символом e и равна разности между оценкой, полученной с помощью модели, и фактическим значением зависимой переменной. В случае Бобби погрешность e равна +3 мили.
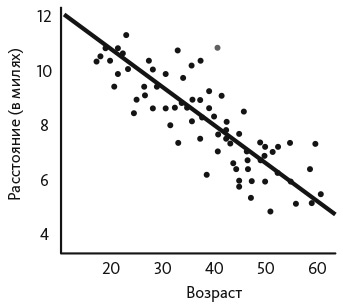
Рис. 7.1. Диаграмма разброса и линия регрессии
В социальном и биологическом контекстах мы не ожидаем идеальных линейных соответствий. Результат зависит от множества переменных, а регрессия с одной переменной по определению содержит только одну переменную. Прогнозируемые значения могут отклоняться от фактических именно из-за этих пропущенных переменных. Бобби может пройти больше, чем ожидается, потому что как профессор ботаники водит своих студентов на прогулки в лес. Модель не учитывает профессию как переменную, что объясняет, почему данные на рис. 7.1 не находятся на линии. Член уравнения e может также быть следствием погрешности измерения. Фитнес-данные, которые собирают смартфоны, содержат ошибки, если люди забывают где-то свои устройства или одалживают их другим. Кроме того, ошибка может возникнуть из-за помех окружающей среды — набрать дополнительное расстояние можно за счет поездки на работу по ухабистой дороге .
Чем ближе линия регрессии к данным, тем больше данных объясняет модель и тем выше значение R в квадрате (доля объясненной вариации). Если все данные находятся точно на линии регрессии, то значение R в квадрате равно 100 процентам. При прочих равных условиях мы предпочитаем модели с более высокими значениями R в квадрате.
Знак, значимость и величина
Линейная регрессия предоставляет нам информацию о коэффициентах независимых переменных.
Знак: корреляция (положительная или отрицательная) между независимой и зависимой переменной, определяется по знаку коэффициента m.
Значимость (p-значение): вероятность того, что коэффициент m отличен от нуля.
Величина: наилучшая оценка коэффициента при независимой переменной.
В регрессии с одной переменной чем ближе данные к линии регрессии и чем больше их объем, тем больше мы можем доверять знаку и величине коэффициентов. Статистики измеряют значимость коэффициента с помощью p-значения, которое равно основанной на регрессии вероятности того, что коэффициент отличен от нуля. P-значение, равное 5%, означает наличие одного шанса из двадцати, что данные были сгенерированы процессом, в котором коэффициент равен нулю. Стандартные пороговые уровни значимости — 5 процентов (обозначается как *) и 1 процент (обозначается как **). Однако значимость — это не все, что нам нужно. Коэффициент может быть значимым, но иметь малую величину (когда это так, мы можем быть уверены в наличии корреляции, но переменная оказывает незначительное воздействие), или может быть большим, но не иметь значимости. Так часто происходит с данными с искажениями или со множеством пропущенных переменных.
Для того чтобы увидеть, как использовать регрессию в качестве руководства к действию, представьте компанию, которая поставляет специи. Компания предлагает более ста видов специй. Клиенты покупают наборы из шести, двенадцати или двадцати четырех специй, которые сотрудники упаковывают и отгружают. Регрессия, оценивающая количество заказов, отгруженных за восьмичасовую смену, как функцию стажа работы сотрудника, дает следующее уравнение:
количество выполненных заказов = 200 + 20** · стаж
Уровень значимости коэффициента 20, который указан перед стажем работы, составляет 1 процент. Мы можем быть уверены, что значение этого коэффициента положительное. Если зависимость носит причинно-следственный характер (см. ниже), модель можно использовать для прогнозирования количества заказов, которые сотрудник может выполнить за одну смену в зависимости от стажа работы. Кроме того, мы можем использовать эту модель для прогнозирования количества заказов, которые эти сотрудники выполнят в следующем году. Здесь мы имеем пример модели, которая позволяет составить прогноз и служит руководством к действию.
КОРРЕЛЯЦИЯ VS КАУЗАЦИЯ
Регрессия выявляет только корреляцию между переменными, но не причинность . Если мы сначала построим модель, а затем используем регрессию, чтобы проверить, подкреплены ли данными результаты, полученные с помощью этой модели, это тоже не поможет доказать наличие причинно-следственной связи (казуальности). Тем не менее описать модель с самого начала — гораздо лучше, чем выполнять регрессионный анализ в поисках значимой корреляции, то есть использовать метод, известный как глубинный анализ данных. В случае глубинного анализа данных существует риск обнаружить переменную, которая коррелирует с другими каузальными переменными. Например, глубинный анализ данных может выявить значимую положительную корреляцию между уровнем витамина D и общим состоянием здоровья. Люди получают витамин D от солнца, а значит, этот факт может быть обусловлен тем, что люди, ведущие активный образ жизни, проводят больше времени на свежем воздухе и имеют более крепкое здоровье. Кроме того, регрессионный анализ может выявить сильную корреляцию между уровнем успеваемости в школе и количеством учеников, входящих в состав школьной команды конного спорта. Скорее всего, команды конного спорта не оказывают прямого причинно-следственного воздействия, но соотносятся с уровнем семейного дохода и объемом финансирования школы — факторами, такое воздействие оказывающими.
Глубинный анализ данных может также приводить к обнаружению ложной корреляции, когда связь между переменными обусловлена случайным стечением обстоятельств. Мы можем обнаружить, что компании с более длинными названиями получают более высокую прибыль, или что у людей, живущих неподалеку от пиццерий, выше риск заболеть гриппом. При пороговом уровне значимости 5 процентов одна из двадцати проверяемых переменных будет значимой. Следовательно, проанализировав достаточное количество переменных, мы обязательно найдем значимую (и ложную) корреляцию.
Избежать ложных корреляций можно путем создания обучающих и проверочных наборов данных. Корреляция, выявленная на обучающем наборе данных и присутствующая в проверочном наборе данных, с гораздо большей вероятностью является истинной. Тем не менее у нас по-прежнему нет никаких гарантий наличия причинно-следственной связи. Для того чтобы доказать каузальность, необходимо провести эксперимент, в ходе которого мы будем манипулировать с независимой переменной и наблюдать, изменится ли зависимая переменная. В качестве альтернативы можно найти естественный эксперимент, то есть когда это произошло совершенно случайно.
ЛИНЕЙНЫЕ МОДЕЛИ СО МНОЖЕСТВОМ ПЕРЕМЕННЫХ
В большинстве явлений задействовано несколько каузальных и корреляционных переменных. Счастье человека можно связать со здоровьем, семейным положением, потомством и религиозной принадлежностью. Стоимость дома зависит от его площади, размера участка, количества ванных комнат и спален, типа строительства и качества местных школ. Все эти переменные можно включить в регрессию, чтобы объяснить стоимость жилья. Однако мы должны помнить, что при добавлении дополнительных переменных нам понадобится больше данных для получения значимых коэффициентов регрессии.
Прежде чем обсуждать множественную регрессию, выработаем интуитивное понимание уравнений со множеством переменных, введя уравнение успеха Майкла Мобуссина . Это уравнение описывает успех, будь то в работе, спорте или играх, как взвешенную линейную функцию мастерства и удачи.
Уравнение успеха
успех = a · мастерство + (1 − a) · удача,
где значение a в диапазоне [0,1] равно относительному весу мастерства.
Присвоение относительного веса мастерству и удаче (возможно, с помощью регрессии при наличии данных) позволило бы нам использовать модель для прогнозирования результатов. Если менеджер команды агентов по продаже рекреационных автомобилей обнаруживает, что успех, выраженный в объеме продаж, содержит большой элемент удачи, он будет ожидать регрессии к среднему значению: продавцы, обеспечившие высокий уровень продаж в этом месяце, скорее всего, покажут средние результаты в следующем месяце. В таком случае менеджер может использовать эту модель как основу для дальнейших действий. Возможно, он не захочет поднимать зарплату агенту по продажам, у которого было два удачных месяца подряд, до уровня оплаты в конкурирующей компании. Однако если бы вместо этого регрессионный анализ показал, что удача не сыграла почти никакой роли, а высокий результат за два месяца был бы хорошим предиктором аналогичной результативности в следующие месяцы, тогда менеджер, возможно, захотел бы заплатить лучшему продавцу столько же, сколько платят в других компаниях.
Аналогичные соображения применимы и к оплате труда СЕО. Совет директоров не должен выплачивать бонусы СЕО, работающим в отраслях, где удача определяет успех. Прибыль нефтедобывающей компании зависит от рыночной цены нефти — переменной, которая находится вне контроля компании. Следовательно, совет директоров нефтедобывающей компании должен воздерживаться от вознаграждения СЕО за хороший год. В рекламном агентстве целесообразно поступать с точностью до наоборот — если компания работает хорошо, выплачивать большие бонусы СЕО. Словом, платите за мастерство, а не за удачу. На самом деле корпорации с более эффективной системой управления платят за удачу меньше .
Даже такие простые модели, как эта, позволяют сделать глубокие выводы. Проанализировав данное уравнение, мы видим, что даже в контексте, почти полностью зависящем от мастерства (как в случае бега, велоспорта, плавания, шахмат или тенниса), при небольших отличиях в его уровне именно удача в значительной мере определяет успех. Можно предположить, что в самых конкурентных средах (таких как Олимпийские игры) различия в навыках несущественные, а значит, значение имеет удача. Мобуссин называет это парадоксом мастерства. Величайший пловец в истории Майкл Фелпс был на его обеих сторонах. Во время Олимпийских игр 2008 года в конце 100-метровой дистанции баттерфляем Фелпс отставал от Милорада Чавича, но по счастливой случайности коснулся стены первым. Во время Олимпийских игр 2012 года Фелпс опережал Чада ле Кло на финише, но первым к стене прикоснулся ле Кло. Да, Фелпс обладает невероятным мастерством, но эта победа и поражение — продукты удачи.
МНОЖЕСТВЕННАЯ РЕГРЕССИЯ
Модели множественной линейной регрессии соответствуют линейным уравнениям со множеством переменных и минимизируют суммарное расстояние до данных. Эти уравнения содержат коэффициенты для каждой независимой переменной. Представленное ниже уравнение описывает конечный результат гипотетической регрессии оценок учащихся по математическим тестам как функцию количества часов обучения (HRS), социально-экономического статуса семьи (SES) и количества курсов ускоренного обучения (AC).
оценка по математике = 21,1 + 9,2** · HRS + 0,8 · SES + 6,9* · AC.
Согласно этой регрессии, оценка учащегося повышается на 9,2 пункта на каждый дополнительный час обучения. У коэффициента две звездочки, а значит, он существенно отличается от нуля на уровне значимости 1 процент. Это подразумевает наличие сильной корреляции, но не причинно-следственной связи.
Уравнение также показывает, что оценка одного учащегося повышается почти на семь пунктов на каждый курс ускоренного обучения. Этот коэффициент тоже имеет значимость, но только на уровне 5 процентов. Социально-экономический статус семьи (переменная, принимающая значения от 1 (низкий статус) до 5 (высокий статус)) имеет положительный коэффициент, который незначительно отличается от нуля, поэтому можно предположить, что он, по всей вероятности, оказывает небольшое причинно-следственное воздействие.
На основании этого или любого другого регрессионного анализа мы можем прогнозировать конечные результаты. Модель прогнозирует, что учащийся, который уделяет учебе семь часов и проходит один курс ускоренного обучения, должен набрать около 90 баллов. Кроме того, модель также можно использовать в качестве руководства к действию, но с осторожностью, поскольку здесь мы не можем вывести причинно-следственную связь. Данные показывают, что учащиеся, которые усердно учатся и проходят ускоренные курсы обучения, получают более высокие оценки. Одна из причин того, что упорная учеба или ускоренные курсы обучения могут не принести пользы — смещение отбора. Возможно, такие учащиеся более сильны в математике.
Хотя регрессия не может доказать, что именно порождает те или иные закономерности в данных, она позволяет исключить некоторые объяснения. Рассмотрим различия в уровне благосостояния разных рас. В 2016 году средний уровень благосостояния белых семей (около 110 000 долларов) более чем в десять раз превышал уровень благосостояния семей афро- и латиноамериканцев. Этот разрыв можно объяснить множеством причин, в том числе институциональными факторами, различиями в доходах, поведением в отношении сбережений или процентом браков. Регрессия поддерживает одни объяснения и исключает другие. Например, регрессионный анализ указывает на отсутствие значимой зависимости между семейным положением и уровнем благосостояния афроамериканцев, а значит, семейное положение не может быть причиной. Различий в доходах, хотя они и достаточно большие, тоже оказалось недостаточно для объяснения данного разрыва .
БОЛЬШОЙ КОЭФФИЦИЕНТ И НОВЫЕ РЕАЛИИ
Как уже говорилось, модели линейной регрессии играют важнейшую роль в области научных исследований, политического анализа и принятия стратегических решений — отчасти потому, что их легко оценить и интерпретировать. По мере повышения доступности данных их применение стало еще шире. Фраза «Мы верим Богу, все остальные должны предоставлять данные» звучит в деловых и правительственных кругах все чаще. Широкое применение данных (которое нередко означает использование моделей линейной регрессии) может подталкивать нас к совершению второстепенных действий — в сторону, противоположную реализации перспективных новых идей. Компании, правительства или фонды, которые собирают данные, а затем используют модель линейной регрессии и находят переменную с самым большим коэффициентом статистической значимости, — практически не в состоянии воздержаться от корректировки этой переменной и получения предельного выигрыша.
При совершении того или иного действия лучше выбрать переменную с большим коэффициентом, чем с малым. Кроме того, мышление с ориентацией на большие коэффициенты опирается на консервативный подход, который фокусируется на определенных незначительных улучшениях и отвлекает внимание от принципиально нового курса действий. Вторая проблема мышления, ориентированного на большие коэффициенты, состоит в том, что их величина соответствует предельному эффекту с учетом имеющихся данных. Нередко, как мы увидим в следующей главе, величина эффекта уменьшается по мере повышения значения переменной. Если это так, большой коэффициент становится меньше, когда мы пытаемся его использовать.
Большой коэффициент и новые реалии
Линейная регрессия указывает на величину корреляции между независимыми переменными и изучаемой переменной. Если такая корреляция каузальна (описывает причинность), изменение переменной с большим коэффициентом будет иметь серьезные последствия. Курс действий, опирающийся на большие коэффициенты, гарантирует улучшения, но исключает новые реалии, которые подразумевают более фундаментальные перемены.
Альтернативой мышлению, ориентированному на большие коэффициенты, является мышление, ориентированное на новые реалии. Мышление с ориентацией на большие коэффициенты расширяет дороги и строит полосы для транспортных средств с пассажирами, чтобы снизить интенсивность дорожного движения. Мышление с ориентацией на новые реалии строит сети железнодорожного и автобусного сообщения. Мышление с ориентацией на большие коэффициенты финансирует покупку компьютеров для студентов с низкими доходами. Мышление с ориентацией на новые реалии предоставляет компьютеры всем без исключения и сокращает сроки доставки почты до трех дней в неделю. Мышление с ориентацией на большие коэффициенты увеличивает ширину сидений в самолетах. Мышление с ориентацией на новые реалии создает такой салон самолета, который можно заполнять взаимозаменяемыми отсеками для людей с разными габаритами. Большие коэффициенты — это хорошо. Предпринимать действия, основанные на фактических данных, — мудро, но мы также должны быть открыты для новых идей. А обнаружив их, должны использовать модели, чтобы выяснить, обеспечат ли они требуемые результаты. Регрессионный анализ дорожно-транспортных происшествий с участием подростков может указывать на то, что возраст имеет самый большой коэффициент, подразумевая, что правительство может захотеть повысить возраст для получения водительских прав. Это действительно может сработать, но такого результата позволяют добиться и принципиально новые меры, такие как запрет на вождение в ночное время, автоматический мониторинг водителей-подростков через их смартфоны или введение ограничений на количество пассажиров в автомобилях подростков. Действия с учетом новых реалий могут дать более масштабный эффект, чем использование большого коэффициента.
РЕЗЮМЕ
Таким образом, линейные модели исходят из постоянной величины эффекта. Линейная регрессия — мощный инструмент предварительного анализа данных, позволяющий определить знак, величину и значимость переменных. Если мы хотим знать о влиянии потребления кофе, алкоголя и газированных напитков на здоровье человека, регрессионный анализ поможет нам в этом. Мы можем обнаружить, что потребление кофе снижает риск сердечно-сосудистых заболеваний, так же как и умеренное потребление алкоголя. Однако нам следует скептически относиться к экстраполяции линейных эффектов слишком далеко за пределы диапазона имеющихся данных. Мы не должны думать, что выпивать за день тридцать чашек кофе, не говоря уже о шести бокалах вина, это хорошо. Не стоит также делать линейные прогнозы на слишком отдаленное будущее. За период с 1880 по 1960 год численность населения Калифорнии росла со скоростью 45 процентов. Применив линейную экстраполяцию, мы получили бы численность населения Калифорнии в 2018 году в размере 100 миллионов человек, что более чем в два раза превышает фактический показатель.
Имейте в виду, что мы только начинаем. Большинство изучаемых явлений носят нелинейный характер. По этой причине многие регрессионные модели содержат нелинейные параметры, такие как квадрат возраста, квадратный корень из возраста и даже логарифм возраста. Для того чтобы объяснить нелинейные характеристики, мы также можем организовать непрерывную последовательность линейных моделей. Эти сопряженные линейные модели могут аппроксимировать кривую во многом подобно тому, как из прямоугольных кирпичей можно выложить извилистую дорожку. Хотя линейность может быть слишком сильным и нереалистичным предположением, это хорошая отправная точка. При наличии данных можно использовать линейные модели для проверки интуитивных выводов, а затем разработать более сложные модели, в которых воздействие переменной слабеет по мере увеличения ее значения (убывающая отдача) или усиливается (положительная отдача). Такие нелинейные модели — тема следующей главы.
Бинарная классификация данных
В эпоху больших данных организации используют для их классификации алгоритмы, основанные на моделях. Политическая партия может захотеть выяснить, кто голосует, авиакомпании может понадобиться информация о характеристиках часто летающих пассажиров, а организатор мероприятий может захотеть узнать о его участниках. В каждом из этих случаев организация распределяет людей на две категории: те, кто покупает, вносит свой вклад или регистрируется на мероприятие, обозначаются как положительные величины (+), а те, кто этого не делает, — как отрицательные величины (–).
Модели классификации используют алгоритмы для разделения людей на категории с учетом таких характеристик, как возраст, доход, уровень образования или количество часов, проведенных в интернете. Разные алгоритмы подразумевают разные базовые модели взаимосвязи между характеристиками и результатами. Применение множества алгоритмов (использование множества моделей) обеспечивает более точную классификацию.
Линейная классификация. На рис. M1 положительные величины (+) представляют участников голосования, а отрицательные величины (–) — тех, кто не голосовал. Линейная функция возраста и уровня образования человека позволяет определить, примет ли он участие в голосовании. Данные указывают на то, что более образованные люди и люди старшего возраста с большей вероятностью голосуют. В данном примере прямая линия почти идеально делит избирателей на категории .
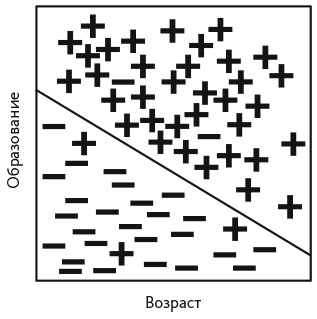
Рис. M1. Использование линейной модели для классификации поведения избирателей
Нелинейная классификация. На рис. M2 положительные величины (+) представляют часто путешествующих пассажиров (которые летают более 10 000 миль в год), а отрицательные величины (–) всех остальных клиентов авиакомпании. Люди среднего возраста и более обеспеченные летают чаще. Для классификации этих данных необходима нелинейная модель, которую можно рассчитать с помощью алгоритмов глубокого обучения, таких как нейронные сети. Нейронные сети содержат больше переменных, поэтому могут построить практически любую кривую.
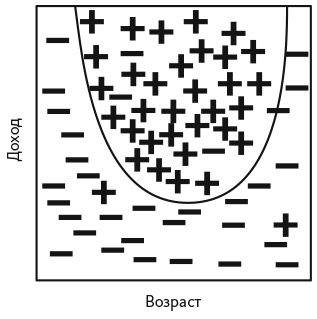
Рис. M2. Использование нелинейной модели для классификации часто путешествующих пассажиров
Лес деревьев принятия решений. На рис. M3 положительные величины (+) представляют людей, которые участвовали в конференции по научной фантастике, с учетом их возраста и количества часов, проведенных в интернете. В этом случае мы классифицируем данные с помощью трех деревьев принятия решений. Деревья принятия решений обеспечивают классификацию на основе наборов условий по характеристикам. На рисунке показаны следующие деревья:
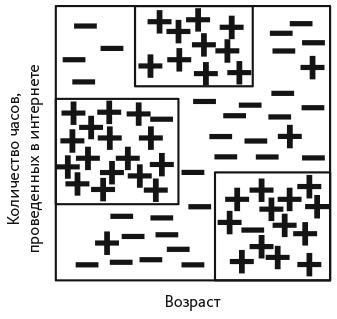
Рис. M3. Лес деревьев принятия решений, классифицирующий участников конференции
Дерево 1: если (возраст < 30) и (количество часов в интернете за неделю в диапазоне [15, 25]).
Дерево 2: если (возраст в диапазоне [20, 45]) и (количество часов в интернете за неделю >30).
Дерево 3: если (возраст >40) и (количество часов в интернете за неделю >20).
Такая совокупность деревьев принятия решений называется лесом. Алгоритмы машинного обучения создают деревья в произвольном порядке на обучающих наборах данных, а затем сохраняют те, которые обеспечивают точную классификацию на проверочном и обучающем наборах.

