Глава 11. Котики счастливые и несчастные или Логистическая регрессия и дискриминантный анализ
Из предыдущей главы вы узнали, как с помощью линейной регрессии понять, насколько сильно те или иные факторы влияют на уровень котикового счастья. Однако, у обычного регрессионного анализа есть одно существенное ограничение – уровень счастья должен быть достаточно точно измерен с помощью какого-нибудь прибора или теста. К сожалению, мы зачастую не располагаем подобным оборудованием. Максимум, что мы можем сделать, это прикинуть, является ли данный конкретный котик счастливым или несчастным.

Можем ли мы при таких условиях найти факторы, предсказывающие котиковое счастье?
Разумеется да. И для этого существуют два очень хороших метода. Первый называется логистической регрессией, а второй – дискриминантным анализом.
Логистическая регрессия во многом похожа на линейную. Однако вместо уровня счастья в левой части уравнения стоит величина, которая позволяет рассчитать вероятность того, что данный котик счастлив. Эта величина называется логарифмом шанса.
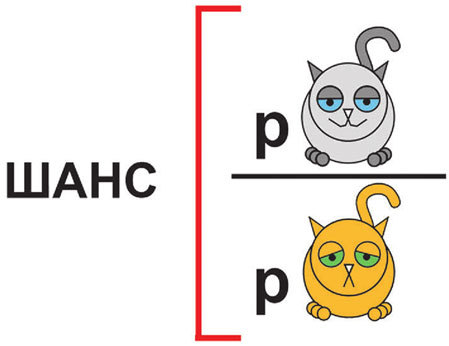
Слово «шанс» достаточно часто встречается в русском языке, как правило, обозначая то, что ни в коем случае нельзя упустить. Но с точки зрения статистики шанс – это вероятность того, что данный котик счастлив, деленная на вероятность того, что он несчастлив.
По некоторым математическим причинам от шанса берут натуральный логарифм и подставляют эту величину в регрессионное уравнение. Если логарифм шанса будет положительным, то данный котик считается счастливым, а если отрицательным – то несчастным.
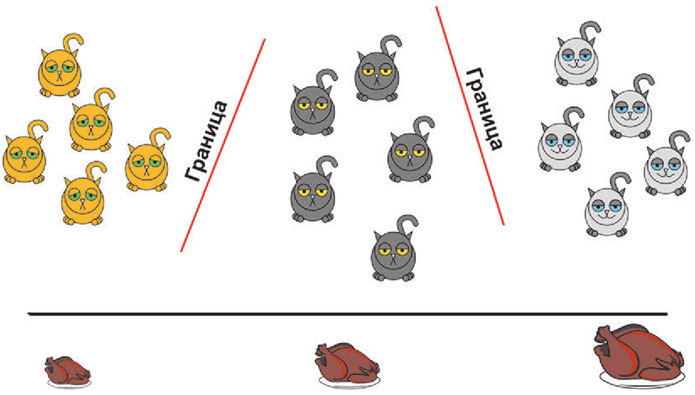
Альтернативным методом является дискриминантный анализ. Чтобы разобраться, что это такое, обратимся к рисунку.
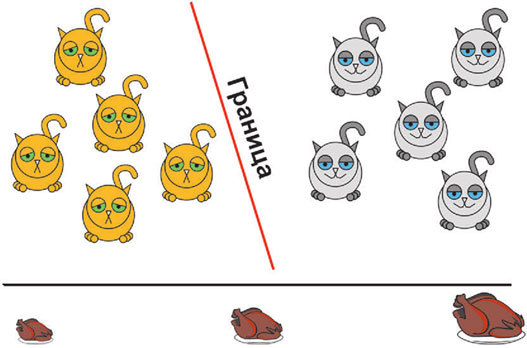
На нем представлены счастливые котики (Барсики) и несчастные (Мурзики), а также информация о том, кто из них сколько ест. Очевидно, что Барсики едят в целом больше, и мы можем провести четкую границу между котиками по этому фактору. И если такая граница возможна, то мы делаем вывод, что фактор связан с уровнем счастья. Иной случай выглядит так.
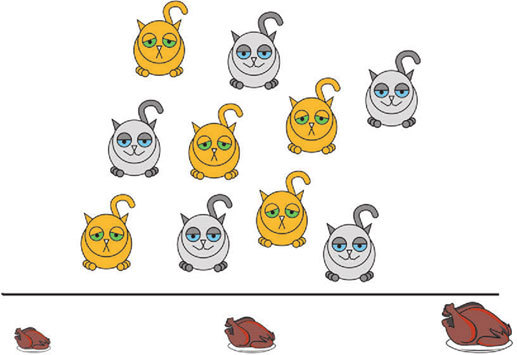
Здесь невозможно построить такую границу, чтобы Барсики оказались по одну ее сторону, а Мурзики – по другую. Соответственно, в этом случае количество еды не связано с уровнем счастья.
Алгоритм нахождения таких границ и называется дискриминантным анализом, а формула, которая задает границы, – дискриминантной функцией. По итогу дискриминантного анализа вы получаете таблицу, в которой обозначается, по каким факторам удалось провести внятные границы, а по каким – нет.
Дискриминантный анализ может работать и с большим количеством групп. Например, если мы добавим к нашим Барсикам и Мурзикам группу философских котиков, дискриминантный анализ сможет найти границы между ними всеми. Число таких границ всегда будет на одну меньше, чем количество групп.
Если же вы являетесь поклонником регрессионного анализа, то при большом количестве групп вы можете вычислить так называемую мультиномиальную регрессию.
НЕМАЛОВАЖНО ЗНАТЬ!
Мультиколлинeарность и переобучение
С методами регрессионного и дискриминантного анализов связаны две проблемы, которые существенным образом могут испортить вам все ваши выводы.
Первая из них – проблема мультиколли-неарности – возникает в случаях, когда некоторые факторы сильно коррелируют между собой, и приводит к неустойчивости получившегося уравнения. Проявляется это в двух формах.
1. При добавлении всего одного-двух котиков в выборку это уравнение может измениться до неузнаваемости.
2. Формулы, построенные на двух сходных выборках котиков, будут различаться.
Как правило, эту проблему преодолевают тремя способами.
1. Исключают одну из коррелирующих переменных из анализа.
2. Предварительно проводят процедуру факторного анализа (о нем будет рассказано далее), заменяющего эти переменные одной искусственной, которая и будет включена в регрессию.
3. Проводят процедуру пошаговой регрессии. Такая регрессия постепенно включает в уравнение по одной переменной и сразу же после этого пересчитывает вклад всех остальных. В итоге если одна из коррелирующих переменных была выбрана в качестве фактора, вторая туда скорее всего не попадет.
Вторая проблема – проблема переобучения – заключается в том, что уравнение, полученное на одних котиках, может не работать на других. Она возникает из-за того, что в вашей выборке котиков могут быть закономерности, которые нехарактерны для котиков в целом. И зачастую они попадают в регрессионную модель.
Для того чтобы предотвратить переобучение, используют критерий, который искусственно ограничивает количество факторов, включенных в уравнение (например критерий Акаике и Байесовский информационный критерий).

