Глава 3
Когда компьютеры исчезнут
Информационные технологии растут экспоненциально, практически удваивая свои показатели ежегодно. То, что раньше размещали в здании, сегодня умещается в кармане, а то, что носят в кармане, через 25 лет поместится в клетке крови.
Рэй Курцвейл
В разгар Второй мировой Алан Тьюринг и команда Блетчли-парка изобрели первый программируемый электронный цифровой компьютер, созданный для конкретной цели: помочь британским дешифровщикам с криптоанализом шифровальной машины Lorenz. Эти роторные машины для поточного шифрования широко использовались немецкой армией во время войны при передаче закодированных сообщений. Colossus Mark I был введен в эксплуатацию 5 февраля 1944 года. Его усовершенствованная версия, Mark II, начала работу 1 июня 1944 года, за считаные дни до начала высадки в Нормандии.

Рисунок 3.1. Звуковой модуль музыкальной открытки, цена 0,10 доллара США (источник: Alibaba)
Первым универсальным программируемым вычислительным устройством стал «Электронный числовой интегратор и вычислитель» (Electronic Numerical Integrator and Computer, ENIAC). Изначально применявшийся в армии США для расчета таблиц артиллерийской стрельбы, он вошел в строй 29 июня 1947 года. К 1950 году на планете существовало лишь несколько таких машин – компьютеров. Однако компьютерные технологии уже появились и пошли в мир.
Давайте сравним то время с сегодняшним днем.
В наши дни простейший гаджет, например звуковой модуль в музыкальной поздравительной открытке, обладает процессором в 1000 раз большей мощности, чем вся вычислительная техника конца Второй мировой войны вместе взятая, и при этом обходится в 10 центов за чип. Закон Мура в очередной раз подтвержден!
Среднего класса устройство, которое вы носите в кармане, производительнее, чем все, что имелось в распоряжении крупнейших мировых банков, корпораций и авиакомпаний в 1980-х годах. Создание чего-либо эквивалентного по вычислительной мощности обычному современному планшету 20–30 лет назад стоило бы от 30 до 40 млн долларов, и в то время это считалось бы суперкомпьютером. Смартфон у вас в кармане мощнее, чем все компьютеры, которыми располагало НАСА в 1970-х годах при работе над проектом «Аполлон». И кстати, почти в три миллиона раз мощнее, чем навигационный компьютер «Аполлона», с помощью которого Нил Армстронг, Базз Олдрин и Майкл Коллинз прокладывали путь к поверхности Луны. Мощнейший суперкомпьютер 1993 года, созданный корпорацией Fujitsu для Космического агентства Японии примерно за 34 млн долларов (в ценах 1993 года), уступил бы в производительности смартфону уровня Samsung Galaxy S6. Этот же смартфон в 30 или 40 раз мощнее, чем все компьютеры, которыми Bank of America располагал в 1985 году. Игровая приставка Xbox 360 примерно в 100 раз производительнее, чем бортовой компьютер первого космического шаттла.
Если у вас на руке умные часы, скорее всего производительность их процессора больше, чем у настольного компьютера 15-летней давности. Процессор компьютера Raspberry Pi Zero, который сейчас в США стоит всего пять долларов, эквивалентен по мощности iPad 2 выпуска 2011 года. На таких автомобилях, как Tesla Model S, установлено множество центральных (CPU) и графических (GPU) процессоров, которые вместе образуют более мощную вычислительную платформу, чем у авиалайнера Boeing 747.
Через 30 лет вы будете носить в кармане или встраивать в одежду, дом и даже в собственное тело устройства, превосходящие по мощности самые производительные сегодняшние суперкомпьютеры и, возможно, даже более мощные, чем все компьютеры, которые были подключены к интернету в 1995 году.
Сети и Всемирная паутина
На заре своих дней интернет начинался как проект ARPANET – от английского Advanced Research Projects Agency Network («Сеть Агентства передовых исследовательских проектов»), возглавляемый Агентством передовых исследовательских проектов (ARPA, позднее – Управление перспективных исследовательских проектов, DARPA) и научным сообществом. Первое соединение с помощью сети ARPANET было установлено между Калифорнийским университетом в Лос-Анджелесе (UCLA) и Стэнфордским исследовательским институтом (SRI) 29 октября 1969 года в 22:30.
Мы установили телефонную связь с ребятами в SRI. Напечатали букву L и спросили по телефону: «Видите L?» – «Да, видим L», – был ответ. Мы напечатали О и спросили: «Видите О?» – «Да, видим О». Тогда мы напечатали G, и система легла…
Профессор Леонард Клейнрок, Калифорнийский университет в Лос-Анджелесе, из интервью о первом тестовом обмене пакетами данных в 1969 году
Параллельно развитию первых компьютерных сетей различные производители компьютеров стремились уменьшить в размере и персонализировать технику, чтобы ее можно было использовать дома или в офисе. Вопреки распространенному мнению, первой компанией, создавшей персональный компьютер (ПК), была не IBM. В начале 1970-х Стив Джобс и Стив Возняк уже интенсивно работали над собственной версией. Их детище – первый Apple, позже известный как Apple I, – фактически опередил модель IBM почти на пять лет, и в нем применялся совершенно другой инженерный подход. Однако событием персональный компьютер стал только после того, как Apple выпустила свой Apple II.
Примерно тогда же, когда Джобс и Возняк создавали первую разновидность ПК, компьютеры на рабочих местах стали резко уменьшаться в размере. Больше не надо было отводить целые комнаты этим гигантам, состоящим из множества блоков: дисков, принтеров, устройств ввода и центрального процессора. Безраздельное доминирование мейнфреймов (больших универсальных серверов) в корпоративном компьютерном ландшафте шло к концу. Они уступали дорогу мини-компьютерам, более известным как midrange – машины средней мощности.

Рисунок 3.2. Оригинальный компьютер Apple I, созданный Джобсом и Возняком и выпущенный в 1976 году (фото: Cynde Moya)
Термин «мини-компьютер» не очень подходил приборам размером с большой холодильник, но все-таки они были и мощнее и меньше, чем стандартный мейнфрейм. Digital Equipment Corporation (DEC) разработала серию мини-компьютеров PDP (Programmed Data Processor, «Программируемый обработчик данных»), начав с PDP-1, и завоевала большую популярность к моменту выпуска PDP-11. В 1980-х на предприятия пришли Sun Microsystems, HP и другие со своими компьютерными платформами для бухгалтерии и простейшими системами управления. Однако персональные компьютеры тоже были уже готовы преобразить рабочие места, прежде всего благодаря тому, что появились сетевые технологии.
В 1979 году на основе работ, которые с начала 1970-х годов велись в исследовательском центре Xerox PARC над технологией Ethernet для локальных и глобальных вычислительных сетей (LAN/WAN), Роберт Меткалф основал компанию 3Com. Сначала программы, способные использовать протоколы LAN, ограничивались простыми задачами вроде совместного доступа к файлам, распечатки файлов и отправки электронной почты. Вскоре эта технология развилась в то, что стало называться многоуровневой архитектурой (n-tier computing), позволяющей связывать много персональных компьютеров и серверов приложений в весьма мощные офисные сети. Такие компании, как Oracle, возникали в ответ на необходимость создавать базы данных и программные системы для этой новой архитектуры.
Закон Меткалфа, названный так в честь основателя 3Com, гласит, что по мере роста числа узлов сети ее полезность для участников растет экспоненциально. Это объясняет стремительный рост Facebook или Twitter за последние годы. Понимать эффект сети очень важно для понимания будущего. Если совместить законы роста сети с ростом компьютеров по закону Мура, то прежде всего мы увидим, что экспоненциальный рост взаимосвязанных компьютеров и других устройств уже нельзя остановить. В 2008 году количество «предметов», подключенных к интернету, превысило число людей на планете, причем развитие глобальной компьютерной сети после этого только ускорилось.
Сегодня мы соединяем в сеть лампочки, домашние термостаты, дверные замки, самолеты, дорожный транспорт, дроны, роботы-пылесосы и еще много приспособлений и гаджетов. Мы на пороге взрывного роста взаимосвязанных интеллектуальных устройств, датчиков и узлов, которые обещают до неузнаваемости изменить мир. К 2020 году к интернету будет подключено 50 млрд «вещей», а к 2030 году, возможно, мы будем говорить уже о 100 трлн датчиков – по 150 датчиков на каждого человека планеты. Эти датчики будут сообщать обо всем, от частоты сердцебиений до уровня зарядки электромобиля, загрязнения воздуха вокруг, содержания сахара в крови и даже параметров повседневных отходов нашей жизнедеятельности. На основе их данных будет строиться информированное и измеряемое будущее с растущей продолжительностью жизни на все более чистой и безопасной планете.
Чтобы революция связи действительно изменила будущее и судьбу Земли, предстоит сделать сети доступными для всех, а не только для развитых наций. Как этого добиться?
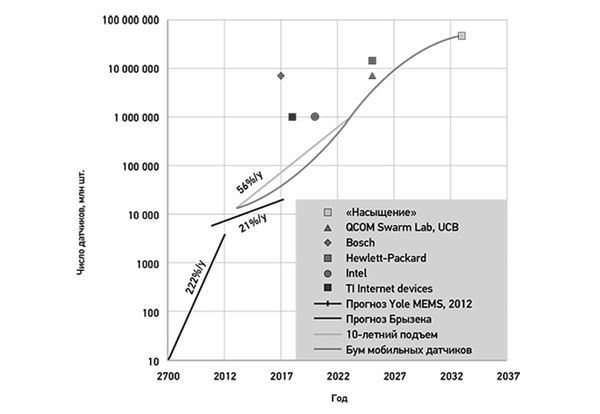
Рисунок 3.3. 50-100 трлн устройств к 2030 году, или 150 датчиков на каждого человека (источник: SBP Global)
В 2014 году во время «революции зонтиков» в Гонконге важную роль сыграло новое (на тот момент) приложение под названием FireChat на основе технологий ячеистой сети. С помощью телефонного Wi-Fi или передатчика Bluetooth оно может связываться с другими телефонами, даже когда ни интернет, ни обычная мобильная связь не работают. Калифорнийская компания Open Garden, создатель FireChat, объявила, что в октябре 2015 года заключила партнерское соглашение с оператором Smart Tahiti Networks (STN), которое позволит жителям Таити общаться друг с другом, не нуждаясь в тарифных планах или в связи с сотовым оператором.
Ячеистая топология обещает стать идеальным решением для соединений внутри сети. Теоретически любое устройство, способное выходить в интернет, может стать узлом распределенной сети, которая позволит не только устройству соединяться с интернетом, но и другим устройствам – связываться, используя соединения друг друга. Сегодня у сети есть разные точки доступа, будь то оборудование интернет-провайдера (ISP) или беспроводные маршрутизаторы Wi-Fi, – устроенные как каналы для связи с более крупной сетью, которой является интернет. Узлы ячеистой сети – это маленькие радиопередатчики, которые связываются не только с пользователями того или иного узла или точки доступа, но и друг с другом. Если один из них теряет соединение с основным каналом интернета, он просто соединяется с ним через любой другой доступный узел. Это настоящая распределенная сетевая топология, которая больше не зависит от связи каждой конкретной точки доступа с основным каналом.
Последствия у технологии ячеистой сети далеко идущие, особенно в сельской местности Африки, Индонезии, Индии и Китая, где связность сети – возможность подключения к ней – ограниченная или вообще нулевая. Теоретически каждое устройство с маленьким встроенным радиопередатчиком может стать средством выхода в интернет даже в изолированных районах. Помимо ячеистой сети, есть и другие технологии, которые доставят беспроводной интернет более чем двум миллиардам людей, не имеющим к нему доступа, – над этим сейчас работают Facebook и Google.
В рамках инициативы Internet.org Facebook создает прототип сети на базе высотных дронов Aquila, которые, используя солнечную энергию и лазеры, передают сигнал на небольшие вышки или тарелки, размещенные на земле. Такие дроны могут не приземляться месяцами и летать выше гражданских самолетов. Google работает над аналогичным проектом под названием Project Loon, используя вместо дронов высотные аэростаты.
В следующие 20 лет самые крупные инновации будут связаны не с ростом сетей, а с новыми применениями интеллектуальных компьютеров, объединенных в сети, в каждой сфере нашей повседневной жизни. Чтобы это произошло, нужна новая парадигма дизайна, новые программы и новые пути взаимодействия человека с устройствами. Внимание к дизайну наглядно проявляет себя в красоте таких устройств, как айфоны, по сравнению с первыми мобильными телефонами; в том, как большие дисплеи применяются в Tesla, или в отсутствии экранов в таких устройствах, как Amazon Echo. Мы ищем и находим все более изощренные способы встраивать технологии в окружающий нас мир.
Эволюция интерфейса и интерактивный дизайн
В 1982 году я пошел в 9-й класс элитной средней школы в Мельбурне, в Австралии. Мельбурнская школа была одним из первых учебных заведений в стране, где преподавали компьютерные науки как один из предметов. Сегодня мы видим, как президент Обама и ему подобные пишут свой первый фрагмент кода на Java, а дети учатся программировать через YouTube и Codecademy, но тогда, в начале 1980-х, подобное изучали в университетах. Когда я начал знакомиться с программированием в школе, мы пользовались компьютером, доставшимся нам от Мельбурнского университета, который давал возможность программировать на Бейсике, Паскале, Коболе и Фортране, но только с помощью перфокарт.

Рисунок 3.4. В 1970-х компьютеры чаще программировали с помощью перфокарт, чем с клавиатуры
В те дни, чтобы программировать, нужно было записать свой код на бумаге, затем, строчка за строчкой, перенести его на перфоркарту. Затем специальный аппарат для чтения пачек карт читал их поштучно и переводил карандашную пометку или отверстие в букву, число или знак, которые затем интерпретировались и компилировались. Классическая программа Hello World требовала четыре разных карты. В школе я был общепризнанным хакером. Прекрасно помню, как взломал систему школьной администрации, чтобы прочитать записи учителей. Меня за это на две недели отлучили от компьютерного класса. За символическую плату я предлагал другим ученикам делать за них задания по программированию. Дело было не в деньгах: я просто проверял, смогу ли получить одни и те же результаты на выходе, пользуясь разными версиями программы.
Примерно в это время мой приятель Дэн Голдберг познакомил меня с моим первым компьютером Apple II, а через некоторое время я завел дома первый микрокомпьютер VIC-20. Несколько лет спустя я уговорил отца потратиться на домашний IBM-совместимый компьютер. От программирования на перфокартах, с которых считывались карандашные пометки, я перешел к клавиатурам и монохромным экранам. Интерфейс, особенно тот, что создавался для игр и графики, был очень примитивным. У моего микрокомпьютера Commodore VIC-20 было около 4 килобайт встроенной оперативной памяти, 16-килобайтное расширение и кассетный накопитель на магнитной ленте для хранения программ. Он был способен показывать изображения с использованием 16 ярких цветов, но я соединил его со старым черно-белым телевизором, который валялся у родителей. Помню, как покупал журналы для тех, кто увлекался VIC-20, и вглядывался в строчки кодов, старательно вводя их, чтобы сыграть в какую-нибудь новую игру.
Так я учился программированию. Меняя параметры, изучал его синтаксис и логику. Заканчивая среднюю школу, я обладал достаточными навыками, чтобы сразу устроиться на работу по этой специальности. Это позволяло мне совмещать учебу в университете с ежедневными занятиями тем, что я любил: писать коды. Когда появились Windows 3 и 3.11, вдруг оказалось, что графический интерфейс делает работу на компьютере еще проще. Вы получали стандартные средства контроля и такие элементы, как окно редактирования, удобные кнопки и другие элементы дизайна, которые давали гораздо больше возможностей по сравнению со старым экраном с зелеными буквами. Компьютеры становились все мощнее, а интерфейсы – все удобнее. Первое поколение компьютерных интерфейсов было знакомо только инженерам. Второе позволяло научить пользователей применять конкретные программы, не становясь программистами.
Но даже в условиях такого прогресса знание одной компьютерной или операционной системы не означало умения работать или ориентироваться в другой, недостаточно знакомой. Скоро стало возможно купить программный продукт в готовом виде. Достаточно было вставить дискету или картридж в консоль или в компьютер, и даже тот, кто никогда не пользовался этой программой прежде, имел все шансы разобраться в ней. Сегодня мы загружаем на телефоны и ноутбуки приложения и программы, освоение которых требует минут, а не недель интенсивной учебы. YouTube и другие онлайн-инструменты позволили моему 12-летнему сыну научиться писать на Java дополнения к экосистеме популярной игры Minecraft за считаные недели.
С развитием этой тенденции мы получим компьютеры колоссальной мощности, встроенные в окружающий мир и не требующие для управления никакого специального интерфейса: реагирующие на сказанное вслух слово или действующие за нас. Чтобы представить это наглядно, подумайте о ношении каких-нибудь фитнес-браслетов Fitbit и тех задачах, которые выполняет их компьютер, чтобы они были эффективными.
Появление многоточечной сенсорной панели (мультитач) стало огромным шагом вперед в дизайне интерфейсов персональных устройств. Она позволяет носить в кармане мощнейшие компьютеры, не требующие лишнего «железа» – мыши или клавиатуры.
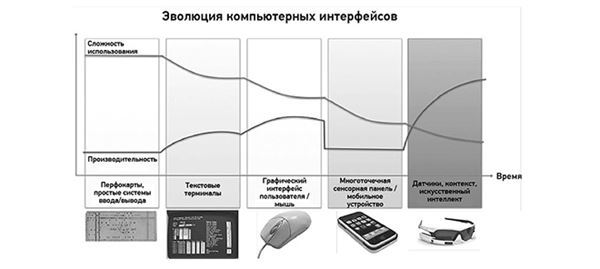
Рисунок 3.5. Эволюция компьютерных интерфейсов
Такие экраны критикуют как издевательство над нашими умственными способностями, но нельзя отрицать, что эти устройства исключительно просты: двухлетний ребенок в состоянии взять айпад и пользоваться им.
В следующей фазе развития компьютера мы увидим радикальное изменение способов с ним обращаться. Помимо непосредственного ввода информации с помощью виртуальной клавиатуры, голоса, прикосновения, жеста, станет возможен ввод с датчиков. Они будут собирать биометрические данные, показатели состояния здоровья, сведения о геолокации, о работе устройства с учетом данных окружающей среды и даже результатов социального, эвристического и поведенческого анализа, предсказывая и сравнивая наше поведение. Ввод данных перестанет быть линейным и больше не будет ограничиваться одним только экраном или интерфейсом.
От экранов к сенсорным датчикам
Если вы носите смартфон, фитнес-устройство или смарт-часы, они уже сейчас ежедневно собирают огромный объем информации о вас и ваших действиях. Встроенный акселерометр вместе с чипом GPS регистрирует перемещения достаточно точно, чтобы посчитать количество шагов и измерить высоту, когда вы поднимаетесь по лестнице. Носимые пульсомеры и фитнес-мониторы регистрируют частоту сердцебиения и работают как шагомеры. Но следующее поколение сенсорных датчиков будет способно на гораздо большее.
В 2014 году Samsung объявила о создании прототипа носимого устройства Simband, объединяющего десятки разных датчиков, которые могут регистрировать и хранить данные о пройденных за день шагах, сердцебиении, кровотоке и давлении, температуре тела, уровне кислорода и количестве выделившегося пота, – всего 12 типов ключевых данных. Дисплей Simband похож на монитор пульса, стоящий в отделениях интенсивной терапии, только его можно носить на запястье.
Подобно тому как GPS и навигационный софт предсказывают влияние плотности движения на длительность поездки, через 10 лет, в союзе с искусственным интеллектом и алгоритмами, сенсорные датчики смогут регистрировать развивающееся сердечно-сосудистое заболевание, угрозу инсульта, проблемы желудочно-кишечного тракта, нарушения функции печени или острую почечную недостаточность и даже рекомендовать или принимать меры, которые предотвратят критическую ситуацию, пока вы ждете врача.

Рисунок 3.6. Разнообразные датчики Simband встроены в ремешок часов (фото: Samsung)
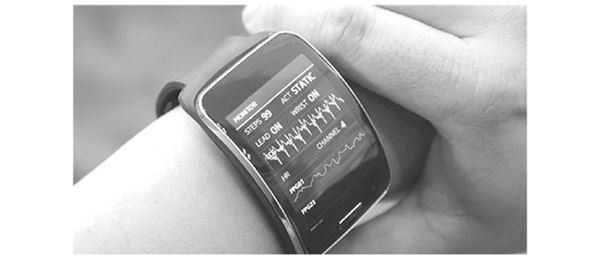
Рисунок 3.7. Дисплей Simband с электрокардиограммой (ECG или EKG) и другими данными (фото: Samsung)
Компании, предлагающие страхование жизни и здоровья, начинают понимать, что такие инструменты принципиально снизят их риски при продаже страховых полисов, а держателям полисов (то есть всем нам) позволят, при участии профессиональных врачей, лучше распоряжаться своим здоровьем. Вместо того чтобы оценивать потенциальный риск развития сердечного заболевания, страхование будет занято мониторингом образа жизни и биометрических данных, который позволяет этим риском управлять. Бумажные анкеты-заявки, которые вы заполняете сейчас, покупая страховку, окажутся практически бесполезными по сравнению с данными, которые страховщик получит от комплекта сенсорных датчиков. Кроме того, анкета не поможет человеку контролировать свое питание, физические нагрузки и т. д., чтобы снизить риск сердечных заболеваний. Вот почему такие организации, как John Hancock, американский страховой гигант, уже делают скидки покупателям полисов, которые носят фитнес-мониторы.
При том, сколько данных загружается в интернет каждый день и каждую секунду, эффективный анализ их во всем их объеме и разнообразии уже находится далеко за пределами возможностей человека и требует использования компьютеров. Это обещает в том числе радикально изменить наш взгляд на диагностику заболеваний. Несколько лет назад IBM создала компьютер, способный сразиться в телеигре Jeopardy! с двумя ее многолетними чемпионами. Watson – так назвали компьютер – убедительно выиграл, превзойдя двух прежде непобедимых соперников-людей, Дженнингса и Раттера. Позже руководство Нью-Йоркского геномного центра одобрило использование IBM Watson в медицинской диагностике. Насколько автору известно, это первый случай, когда конкретный машинный интеллект был профессионально или академически сертифицирован для работы врачом. Но, без сомнения, не последний.
Что стояло за этой медицинской сертификацией? Команде, создавшей IBM Watson, было интересно, сможет ли он научиться строить гипотезы для решения таких задач, как диагностика рака или поиск генетических маркеров наследственных заболеваний, если ему предоставить правильные данные. Чтобы проверить свою теорию, команда из IBM месяцами загружала в банк данных Watson медицинские журналы, описания случаев из реальной практики и диагностические методики за 20 лет.
В статье об этом исследовании, опубликованной Медицинским колледжем Бейлора и IBM в рецензируемом издании, ученые смогли продемонстрировать новый способ генерирования научных вопросов, в долгосрочной перспективе полезных для разработки новых эффективных методов лечения. За считаные недели биологи и специалисты по обработке данных с помощью Watson точно определили, какие белки участвуют в модификации структуры белка р53. В исследовании отмечалось, что, если бы не когнитивные возможности Watson, на такую работу у ученых ушли бы годы. Watson проанализировал 70 000 научных статей о р53, чтобы предсказать белки, которые активируют и деактивируют р53. Этот автоматизированный анализ позволил бейлоровским онкологам выбрать для дальнейшего исследования шесть белков – потенциальных мишеней. Выдающийся результат, если учесть, что за последние 30 лет ученые в среднем выделяли по одному такому белку-мишени в год. Производительность Watson превосходит коллективные усилия исследователей рака в США, с их пятимиллиардным финансированием, на 600 %.
Но самое впечатляющее то, что, когда в Watson вводили данные о симптомах конкретного пациента, он мог точно установить тип рака и самое эффективное лечение более чем в 90 % случаев. Почему это важно? Врачи-люди, специалисты-онкологи с 20-летним опытом, обычно оказываются правы в 50 % случаев. Как у Watson получается систематически опережать по этому показателю людей?
Прежде всего – благодаря его способности за секунды объединять и безошибочно помнить данные всех исследований за последние 20 лет.
Логичный следующий шаг – разрешить врачам использовать Watson для лучшей диагностики пациентов, не так ли? Но есть одна тонкость: врачи могут лечить пациентов только на основании рекомендации лицензированного диагноста. Вот почему Геномный центр Нью-Йорка вынес вопрос на заседание совета директоров и получил согласие на регистрацию Watson в качестве лицензированного диагноста в Нью-Йорке.
Что может Watson? Изучить все ваши медицинские записи. Его загружали и обучали лучшие врачи в мире. Он выдает возможные диагнозы, вероятность в процентах, причины, разумную интерпретацию, возражения, противоречия. Хочу сказать, что сейчас эта программа начала работать для миллионов пациентов в Юго-Восточной Азии. Они никогда не увидят Мемориальный онкологический центр имени Слоуна – Кеттеринга, в отличие от нас с вами, находящихся здесь. [Но] они получат к нему доступ, и мне кажется, это очень важно.
Джинни Рометти, председатель правления и генеральный директор IBM, из выступления в программе Чарли Роуза, апрель 2015 года
Теперь, когда мы знаем, что Watson диагностирует рак точнее, чем врач-человек, спрошу вас: к кому бы вы скорее обратились, если бы ваш доктор заподозрил это заболевание у вас? К «доктору Ватсону» или к человеку? Можно, конечно, возразить, что Watson вряд ли хорошо умеет общаться с больными, и все же, поняв, куда ведут эти технологии, мы сможем взглянуть на будущее здравоохранения совершенно другими глазами. Обратите внимание, что генеральный директор IBM присвоил «Ватсону» мужской род, как человеку. Это так, к слову.
Вполне вероятно, что датчики, которые вы носите на теле или внутри, в будущем смогут точно отслеживать изменения состояния вашего здоровья и диагностировать нарушение задолго до того, как оно станет проблемой. Компьютеры будут автоматически анализировать ваши генетические особенности и сообщать алгоритму или машинному интеллекту, на что обратить внимание. Заметив определенные отклонения, алгоритм или интеллект, подобный Watson, сможет рекомендовать конкретные изменения в питании и повседневной жизни – например, больше спать, увеличить физическую нагрузку, – назначить лекарства или даже персонализированные препараты генной терапии. Подумайте о потенциале машинного интеллекта в роли специалиста по питанию, личного тренера или врача. С развитием носимых и вводимых в организм медицинских устройств лечение начнет происходить автоматически. При диабете уровень инсулина сможет поддерживать имплантат. Если проблема станет серьезной, устройство просигналит о ней лечащему врачу, и он, используя свое непревзойденное умение общаться с больными, сможет пригласить вас для более «человеческого» разговора.
К 2020 году медицинская информация об отдельных пациентах будет удваиваться каждые 73 дня. Нужны технологии, которые свяжут разрозненные части в единую картину, просигналят об отклонениях и посоветуют, что предпринять, как это в прошлом сделали бы врачи. Предотвращение острых ситуаций при заболеваниях, которые можно контролировать, станет нормой, а самые большие расходы будут связаны с подпиской на медицинские услуги и с устройствами, которые вы носите, а не с госпитализацией и не с посещением врача.
Телесериал «Во все тяжкие» заострил проблемы, связанные с финансовой доступностью здравоохранения в США, показав преподавателя старших классов, который начал производить запрещенные препараты, чтобы оплатить лечение диагностированного у него рака. В будущем водораздел в области здравоохранения может пройти не между теми, у кого есть страховка и у кого ее нет, а между имеющими и не имеющими доступ к медицинскому искусственном интеллекту и к носимой медицинской технике. «Умные» общества обеспечат таким доступом всех своих граждан, потому что он резко сократит совокупные расходы на здравоохранение.
При потенциальном количестве датчиков в 2030 году от 50 до 100 триллионов большая часть данных будет генерироваться автоматически, а не через устройства ввода. Они будут поступать через датчики на пульсомерах, акселерометрах в смартфонах, биометрические регистраторы, пассивные камеры или алгоритмы для сбора данных о поведении. Объем данных, поступающих из окружающего нас мира, за 10 лет превысит данные, которые мы вводим с помощью клавиатуры или сенсорного экрана, в 10 000 раз. Иными словами, встроенные в нашу среду обитания компьютеры будут больше реагировать на то, что мы делаем, что говорим и как поступаем, чем на то, что мы набираем на клавиатуре или на что кликаем.
Будущее информационных технологий – объединение датчиков и машинного интеллекта. Датчики станут инструментом ввода данных, а алгоритмы – способом их обобщения. Интерфейсы будут просто предоставлять актуальные для нас заключения. Наше участие в управлении процессами или во вводе данных станет очень незначительным, по крайней мере в привычном смысле слова.
Переход от программ к сплошной компьютеризации пространства
Тенденции в области интерфейса и способов использования компьютерной техники сейчас все больше и больше отличаются от наших традиционных представлений о программном обеспечении и взаимодействии с компьютером. Скоро мы будем наблюдать отказ от программных приложений как таковых. Хотя вывод данных радикально усовершенствовался, ввод не особо изменился.
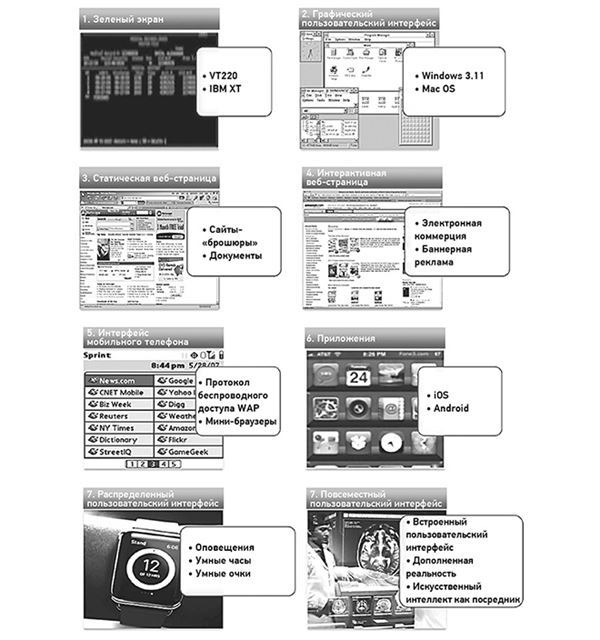
Рисунок 3.8. Эволюция интерактивности
Мы перешли от перфокарт к клавиатуре, потом добавили мышь, камеру и микрофон, а совсем недавно создали мультитач-экраны. Однако большей частью ввод все еще построен на использовании буквенной клавиатуры типа QWERTY, как у пишущей машинки.
От очень простых текстовых интерфейсов мы переходим к все более сложным. Первые компьютерные дисплеи были примитивными, монохромными. Первые браузеры и мобильные телефоны тоже позволяли осуществлять лишь очень примитивные взаимодействия. Вместе с айфонами пришли новые мобильные приложения, уже гораздо более интерактивные, чем простые мобильные веб-страницы. Появление умных часов и очков и подобных устройств породило распределенную архитектуру программного обеспечения. Приложение может быть установлено на телефоне, но связанная с ним картинка и уведомления будут транслироваться на часы или очки. Уже совсем скоро рабочий стол, стена гостиной, приборная панель автомобиля и другие элементы окружающей среды обзаведутся экранами для интерактивного взаимодействия. Мы наполним окружающий мир данными, идеями и контекстом еще и с помощью очков и контактных линз, использующих технологию дополненной реальности.
В эпоху приложений большинство таких предприятий, как банки и авиакомпании, стремятся наращивать функциональность, но, по мере добавления все новых возможностей, растет и предрасположенность к тому, что писатель Джаред Спул назвал «провал сотрудничества» (engagementrot). Проблема заключается в том, что невозможно сохранить «низкозатратное» для пользователя взаимодействие, если возможностей предлагается слишком много. Рано или поздно наступает момент, когда он начинает путаться в них. Что это за момент? Возьмем для примера спецпредложения или скидки в розничной торговле. Если они встроены в банковское приложение, то в какой-то момент возникает вопрос: это банковское приложение или приложение по поиску спецпредложений? Дизайн теряет однозначность, потому что теперь перед нами две конкурирующих области применения, борющиеся друг с другом за внимание клиента.
Более масштабное понимание эволюции интерфейса, встроенных электронных устройств и интерактивности неизбежно приводит к выводу о том, что со временем приложения потеряют свою обычную роль.
Этим летом Google создала восьмифунтовый прототип компьютера для ношения на лице. Для Айва, тогда еще не знавшего о планах Google, «очевидным и правильным местом» для такого прибора было запястье. Позже, увидев Google-очки, Айв, по его словам, понял, что лицо «абсолютно не подходит» для этой цели. [Тим Кук, генеральный директор Apple] сказал: «Мы всегда считали очки плохой идеей, потому что людям на самом деле не очень нравится их носить. Они грубо навязывают себя вместо того, чтобы оставаться фоном, на котором, по нашему мнению, место технологиям».
Иэн Паркер о мнении Джонатана Айва по поводу носимых устройств
По мере того как в пользовательском опыте растет роль контекста, приложения теряют свою функциональность. Будь то умные часы и очки, смартфон или еще какая-то форма интерфейса, встроенная в окружающий мир, лучший способ и лучший инструмент для выстраивания отношений с клиентом и для получения прибыли – это мелкие целевые блоки клиентского опыта. Где сегодня программы или технологии встроены в жизнь потребителя? Великолепный пример – Uber. Команда Uber изучила проблемы перевозок и встроила приложение в жизнь пользователя совершенно не так, как предлагают свои поездки таксомоторные компании. Эта фирма разработала не приложение, а весь клиентский опыт целиком. Чтобы это сделать, она полностью переформатировала способы подбора водителя, распределения автомобилей (без радио), заказа такси, оплаты поездки и многое, многое другое. Она даже позволяет авторизовавшимся водителям взять машину в аренду или открыть банковский счет.
До появления Uber совокупный объем рынка такси в Сан-Франциско составлял 150 млн долларов в год. В начале 2015 года генеральный директор компании Трэвис Каланик объявил о его росте до 650 млн, при этом 500 млн дохода приходилось на Uber. Выстроив не приложение, а клиентский опыт, Uber вовлекла в бизнес огромное количество тех, кто никогда не пошел бы работать таксистом. Она не создала лучшего такси и не обслуживала отдельный маршрут, а с «пустого места» выстроила весь клиентский опыт в целом. Как это сказалось на обычных таксомоторных компаниях? Газета San Francisco Examiner написала 6 января 2016 года, что местная Yellow Cab Со-Ор объявила о своем банкротстве.
Искушение дополнять продукт все новыми возможностями и функциями очень велико. Посмотрите на Facebook и его мессенджер – и на то, как мессенджер недавно отпочковался от Facebook. Шаг для многих неоднозначный, но тем самым было признано, что обмен мгновенными сообщениями и интерактивное чтение ленты – настолько разные действия, что они не должны конкурировать. Интерактив становится отдельным, самостоятельным опытом, встроенным в нашу повседневную жизнь, а не опцией в мобильном приложении. Попробую проиллюстрировать это еще на одном примере.
В XX веке люди смотрели любимые телепрограммы на конкретном канале в определенное время. Чтобы увидеть что-то во второй раз, до появления видеомагнитофонов (VCR) приходилось ждать повторного показа. Наши дети сегодня действуют совершенно иначе. Они выбирают, что смотреть, и тут же смотрят это на YouTube или Netflix. Между каналом PewDiePie на YouTube и сериалом «Карточный домик» на Netflix практически нет разницы. Некоторые исследования даже показывают, что потребление информации в выбранный потребителем момент времени уже опередило телевидение по предпочтительности для пользователей.
Пусть на вашем айфоне еще стоят такие приложения, как игры или книги, которые вы читаете, но частью вашего персонального информационного мира, выстроенного специально для вас, неизбежно станут сведения, привязанные к поведению и контексту. Сегодня это направление ограничивается только контекстуализацией, пропускной способностью канала, возможностями прогнозирования и анализом местоположения пользователя. Совместите эти способности, – и то, что было приложениями, окажется просто откликами на ваши потребности.
От процессора на чипе к компьютерам везде
В 1997 году компания Intel представила публике ASCI Red, первый суперкомпьютер производительностью более 1 терафлопса. Система использовала 9298 чипов Pentium II, размещенных в 72 системных блоках. Недавно Nvidia объявила о выпуске Tegra X1, своего первого терафлопсного процессора для мобильных устройств. Мы говорим о процессоре, который умещается в смартфоне, машине, планшете или умных часах и может выполнять 1 000 000 000 000 инструкций или вычислений в секунду – как и тот суперкомпьютер 1997 года.
Чтобы представить себе, как далеко ушла технология всего за 15 лет, подумайте вот о чем: ASCI Red занимал почти 149 квадратных метров и потреблял 500 000 ватт электроэнергии, причем еще 500 000 ватт уходили на охлаждение помещения, где он находился, чтобы он мог выйти на свою терафлопсную мощность. Tegra X1 размером с ноготь и потребляет 10 ватт. Одна из платформ, возникших недавно для таких вычислительных устройств, – это, разумеется, компьютер автомобиля, которому нужен процессор, достаточно мощный для езды без водителя, усовершенствованный экран и приборная панель с хорошей визуализацией. За ближайшие 10 лет применение встроенных в автомобили компьютеров вырастет экспоненциально. Mercedes F015, продемонстрированный на выставке потребительской электроники CES, – пример того, как преобразится интерьер автомобиля в условиях движения без водителя. Скоро станет нормой машина как развлекающее, рабочее, игровое и социальное пространство. Интерактивный салон, если угодно. В самоуправляемом автомобиле, где больше не нужны прозрачные окна, обеспечивающие водителю обзор по всему периметру, они могут стать интегрированными дисплеями. К этому мы еще вернемся.
Если терафлопсный чип (и более мощные компьютеры) удастся встроить в пространства нашей повседневной жизни, интерактивным экраном может стать все. Это хорошо показано в футурологическом сериале «День, сделанный из стекла» («A Day Made of Glass»), созданном американской компанией Corning, где мы видим зеркала, столешницы, стены и автомобили, ставшие интерактивными устройствами, которые оснащены сенсорными панелями и контекстным интеллектом.

Рисунок 3.9. Mercedes F015 использует пространство внутри совсем не так, как обычный автомобиль (источник: media.daimler.com)

Рисунок 3.10. С дешевыми суперкомпьютерными чипами все что угодно может стать интерактивным дисплеем (источник: Corning, A Day Made of Glass)
По мере встраивания компьютеров во все, что нас окружает в машине, дома, в школе и на работе, понятия экрана и операционной системы, какими мы их знаем, начинают рассыпаться. Для экранов, встроенных в зеркала или столешницы, нельзя будет загружать программы из магазина приложений, как мы привыкли, но наверняка какие-то возможности персонализации будут. Более того, эти экраны будут общаться с централизованным искусственным интеллектом или агентом, собирающим актуальную информацию из нашего личного «облака». На основании собранных данных будут выводиться графики встреч, новостная лента, соответствующая нашим интересам, и различные рекомендации. Эти компьютеры будут не просто выводить нужные сведения на экран. Если в Samsung Simband информацию о вас постоянно собирают шесть разных датчиков, то компьютеры, которые со временем будут встроены повсюду, станут слушать и учиться непрерывно и круглосуточно.
Две недавно созданные компьютерные платформы иллюстрируют начало сдвигов в концепции интерфейса. И Amazon Echo, и поддержанная платформой Indiegogo новинка Jibo вышли на рынок как персональные устройства для дома. Обе технологии встроены в дом, умеют слушать, учиться и откликаться на сигналы окружающего мира в реальном времени. Jibo даже позиционируется как личный помощник семьи. С ними в дом приходят и встраиваются технологии Google Voice, Siri от Apple или Cortana от Microsoft, с доступом к почти бесконечным информационным ресурсам, которые предоставляет интернет.
Начать работать с этими помощниками очень просто. Вы спрашиваете что-нибудь у Echo или Jibo – например, будет ли завтра дождь, купить ли молока, – или просите напомнить на следующей неделе, что надо заказать отель для отпуска. Jibo дает тут большие возможности, потому что он мобилен, а встроенная камера позволяет, например, сделать мгновенное фото вашей семьи. На экране, входящем в интерфейс Jibo, даже появляются разные персонажи, в зависимости от того, с кем из членов семьи он взаимодействует.
Первое поколение домашних помощников еще ограничивается выдачей информации по запросу, но в скором будущем мы начнем использовать эти технологии дома и на работе, чтобы составлять и соблюдать расписания, делать покупки и принимать повседневные решения.

Рисунок 3.11. Семейный робот Jibo – личный помощник и средство коммуникации (фото: Jibo)
За 20 лет эти устройства превратятся в различные версии искусственного интеллекта, достаточно мощные, чтобы обеспечивать те из наших потребностей, которые можно удовлетворить с помощью цифровой техники, соединять нас с нашими личными панелями управления, «облаками», сетями датчиков, давать советы, касающиеся здоровья, финансового благополучия и многих других областей, в которых мы привыкли получать консультации от людей.
Как понять, что говоришь с компьютером?
В декабре 2013 года журнал Time опубликовал статью под названием «Знакомьтесь: робот из телемаркетинга, которая не признается, что она робот», где рассказывалось о рекламном телефонном звонке главе вашингтонского офиса Time Майклу Шереру Шерер, уловив что-то не то, спросил робота, человек она или компьютер. В ответ она эмоционально, с очаровательным смехом сообщила, что настоящая. Но когда Шерер спросил, какой овощ кладут в томатный суп, сказала, что не понимает вопроса. Робот представилась Самантой Вест.
Цель подобных алгоритмов – подготовить адресата звонка прежде, чем переключить его на человека, чтобы завершить продажу. Эти алгоритмы стали возможными благодаря технологиям распознавания голоса. Современные инструменты, такие как Siri и Cortana, неплохо распознают речь без акцента, но было время, когда это казалось научной фантастикой.
Еще в 1932 году ученые из Bell Laboratories работали над проблемой машинного «восприятия речи». К 1952 году они создали систему Audrey для распознавания называемых цифр, правда с очень ограниченными возможностями. Однако в 1969 году Джон Пирс, один из ведущих инженеров компании, обратился к Акустическому обществу Америки с открытым письмом, в котором критиковал распознавание и сравнивал его со «схемами превращения воды в бензин, добычи золота из морской воды, лечения от рака и полета на Луну». По иронии судьбы, через месяц после того, как Пирс опубликовал свое письмо, Нил Армстронг высадился на Луну. Тем не менее вскоре финансирование работ по распознаванию речи в Bell Laboratories прекратилось.
К 1993 году системы, созданные Рэем Курцвейлом, умели распознавать 20 000 слов (произносимых по отдельности), но точность не поднималась выше примерно 10 %. В 1997 году Билл Гейтс довольно дерзко предсказывал: «Я уверен, что через 10 лет для взаимодействия с компьютером мы будем использовать не только клавиатуру и мышь, но и получим системы распознавания речи, достаточно совершенные, чтобы они сделались стандартной частью интерфейса». В 2000 году до этого по-прежнему оставалось 10 лет. Прорыв произошел, когда начали использовать модели Маркова и глубинного обучения нейронных сетей, принципиально выросла компьютерная производительность и увеличились объемы накопленных данных. Однако существующие сегодня системы все еще несовершенны, потому что они до сих пор не умеют обучаться языку. Их алгоритмы усваивают языки не так, как люди: они идентифицируют фразу через распознавание, ищут ее в базе данных и отвечают подходящим образом.
Распознавать речь и уметь поддержать разговор – это совершенно разные вещи. Что нужно сделать компьютеру, чтобы притвориться перед своим собеседником человеком?
Тест Тьюринга: нужен или нет?
В 1950 году Алан Тьюринг опубликовал знаменитую статью под названием «Вычислительные машины и разум». В ней он ставил вопрос не только о том, можно ли считать, что компьютер или машина «думают», но и конкретнее: можно ли вообразить цифровое устройство, которое хорошо справляется с игрой в имитацию? Тьюринг предположил, что такой проверкой машинного интеллекта, которую он называл «игра в имитацию», может быть обмен вопросами и ответами между человеком и машиной. Далее в его статье сказано, что, если не получится за пять минут отличить человека от машины, следует признать машину достаточно «человекоподобной», чтобы пройти тест на основы сознания и мышления.
Автономной машине без водителя не нужно проходить тест Тьюринга, чтобы оставить таксиста без работы.
Исследователи, которые с тех пор дополняли эту работу, рассматривают игру в имитацию как одну из версий, или сценариев, того, что более известно как тест Тьюринга.
Хотя компьютерам пройти такую проверку еще не под силу, мы приближаемся к этому рубежу. Седьмого июня 2014 года, в дни 60-й годовщины смерти Тьюринга, Лондонское королевское общество провело на основе названного его именем теста соревнования. В них участвовал российский бот-собеседник по имени Евгений Густман, который успешно убедил 33 % судей (людей), что он 13-летний украинец, который выучил английский как иностранный язык. И хотя некоторые, например Джошуа Тененбаум, профессор математической психологии в Массачусетском технологическом институте (Massachusetts Institute of Technology, MIT), назвал результаты соревнования «не впечатляющими», оно все же показывает, что мы ближе, чем когда-либо, подошли к тому, чтобы принять компьютер за человека.
Такие задачи, как: забронировать билет на самолет, поменять заказанный отель на другой, решить проблему с банком, заказать машину или узнать результат теста на отцовство, – машина сможет успешно осуществить самостоятельно уже очень скоро. Частично это делается уже сегодня. Наш клиентский опыт не настолько разнороден, чтобы оправдать затраты на «человеческий» колл-центр. Рискну предположить, что в реальности за разговор с «настоящим» человеком скоро придется доплачивать. Многие авиалинии и отели уже берут дополнительную плату, если вы хотите поменять условия резервирования по телефону, а не на сайте бронирования. Совершенно очевидно, что услуги живой консьержки в будущем станут сервисом премиум-уровня, частью отношений с особо ценными клиентами. Для остальных, таких как мы, останутся сервисы на основе искусственного интеллекта. Только надо понимать, что в будущем человек не сможет оказать услугу более качественно, чем машина.
Возможно, мы и заподозрим, что говорим с компьютером, но взаимодействие окажется таким эффективным, что стопроцентной уверенности в этом не будет, да она и не понадобится. Через 15 лет, если отсчитывать от настоящего дня, взаимодействие с машинами распространится повсеместно, и искусственный интеллект будет отличаться только способностью решить некоторые проблемы лучше и быстрее. Например, Uber сможет рекламировать свои самоуправляющиеся автомобили как «самый безопасный в мире транспорт», зная, что статистически уже на старте автономный автомобиль в 20 раз безопаснее управляемого человеком.
Ключом к этому будущему служит способность искусственного интеллекта усваивать язык, учиться общению. В интервью газете Guardian в мае 2015 года профессор Джефф Хинтон, эксперт в области искусственных нейронных сетей, сказал, что Google «остался один шаг до создания алгоритмов, способных к логике, естественному разговору и даже флирту». Сейчас Google работает над тем, чтобы кодировать мысли как векторы, которые можно описать последовательностью чисел. Эти «мыслевекторы» за 10 лет смогут наделить систему искусственного интеллекта «здравым смыслом», подобным человеческому, считает Хинтон.
Некоторые аспекты коммуникации окажутся труднее остальных, предсказал Хинтон. «Трудно будет понимать иронию. Для этого сначала придется хорошо освоить буквальный смысл. Но, с другой стороны, американцы тоже не понимают иронии. Так что компьютер достигнет уровня американца раньше, чем уровня британца…»
Из интервью профессора Джеффа Хинтона газете Guardian 21 мая 2015 года
Типы алгоритмов, которые позволяют машинам сделать скачок в когнитивном развитии, стали возможными благодаря применению больших компьютерных мощностей к обработке крупных массивов данных.
Являются ли тест Тьюринга или машина, способная успешно изображать человека, необходимым условием человеческого взаимодействия с компьютером? Не обязательно. Прежде всего, надо отдавать себе отчет, что машинному интеллекту вовсе не нужно быть полной копией человеческого, чтобы радикально преобразить рынок занятости или наш образ жизни.
Чтобы понять, почему стремиться к созданию компьютерной копии человеческого мозга нет никакой необходимости, надо посмотреть на три четко выделяющиеся фазы в развитии искусственного интеллекта.
● Машинный интеллект – зачаточный машинный интеллект, который заменяет некоторые элементы человеческого мышления при принятии решений или при обработке данных, необходимой для решения конкретных, определенных задач. Нейросети или алгоритмы, способные принимать эквивалентные человеческим решения в ограниченной области и, по принятым параметрам, делающие это лучше человека. Это не исключает способности интеллекта к обучению или когнитивной деятельности: он может учиться решать новые задачи или обрабатывать новую информацию, выходящую за рамки первоначальной программы. Такой способностью обладают уже многие машины. В числе примеров – самоуправляемый автомобиль Google, система IBM Watson, алгоритмы высокочастотного трейдинга, программы распознавания лиц.
● Искусственный интеллект общего характера – эквивалентный человеческому машинный интеллект, который не только проходит тест Тьюринга и отвечает на реплики подобно Homo sapiens, но и умеет принимать решения, эквивалентные человеческим. Вероятно, он будет способен обрабатывать такие внелогические информативные сигналы, как эмоции, тон речи, выражение лица и нюансы, воспринимать которые способно живое существо (понимает ли ваша собака, когда вы сердиты или огорчены?). Главное, что такой искусственный интеллект сможет успешно справляться с любыми задачами, с которыми справляется человек.
● Сверхинтеллект – один или несколько машинных интеллектов (как нам называть их группу?), которые, отдельно или вместе, превосходят человеческий ум настолько, что способны понимать и обрабатывать концепты, которых человек понять не в состоянии.
Чтобы существенно повлиять на механизмы занятости или поставить под угрозу человеческие рабочие места в сфере услуг, искусственному интеллекту не обязательно становиться универсальным. Нам не придется ждать и 10, 15 или 30 лет, чтобы увидеть, как все случится. Как мера способности машин положить конец нашему нынешнему образу жизни и работы тест Тьюринга едва ли применим.
Для того чтобы считаться интеллектуальными, машинам не нужен интеллект как у людей. По тем меркам, которые мы применяем к животным, Watson, возможно, уже сейчас превосходит многие биологические виды, населяющие сегодня планету. Надо ли машине быть такой же умной, как человек, или еще умнее, чтобы ее можно было назвать интеллектуальной? Нет. По сути, от искусственного интеллекта вообще не стоит ожидать, чтобы он думал как люди. Почему он должен формироваться и прогрессировать так, чтобы думать в точности как мы? Совершенно не должен и, скорее всего, не станет.
Приведу два примера. Между 2009 и 2013 годами вооруженный машинным интеллектом высокочастотный трейдинг (HFT) составлял от 49 до 73 % всего объема рынка акций в США, а в Евросоюзе в 2014 году – около 38 %. Шестого мая 2010 года индекс Доу-Джонса рухнул с рекордной скоростью, хотя компенсировал потери за считаные минуты. После пятимесячного расследования Комиссия по ценным бумагам и биржам США и Комиссия по торговле товарным фьючерсами совместно выпустили доклад, в котором пришли к выводу, что HFT внес существенный вклад в волатильность этого мгновенного обвала. Крупная фьючерсная биржа СМЕ Group в своем расследовании заключила, что алгоритмы HFT стабилизировали рынок и ослабили удар от этого падения.
Для индустрии, которая за последние 100 лет довела биржевую торговлю до уровня высокого искусства, алгоритмы HFT знаменуют заметный отход от практики торговых залов Goldman Sachs, UBS и Credit Suisse. Сами эти алгоритмы очень далеко ушли от типичного человеческого поведения. Анализ сценариев HFT продемонстрировал совершенно иное поведение и принятие решений, нежели у людей. Что привело к этому сдвигу? Возможно, тот факт, что у HFT нет ни предвзятости, какая может быть у трейдеров-людей (например, привычки сохранять ставку на какой-нибудь класс активов дольше, чем рекомендуется, просто потому, что конкретному трейдеру нравится эта акция или отрасль), ни этической основы принятия решений. Некоторые возразят, что Уолл-стрит не слишком похожа на твердыню морали, и все же у алгоритма HFT этические основания для принятия решений попросту отсутствуют, если соответствующий навык не запрограммирован.
В 2014 году Audi тестировала на гоночной трассе беспилотные автомобили – две модификации Audi RS7 с мозгом величиной с игровую приставку PS4 в чехле. На данном этапе эти гоночные Audi еще нельзя назвать полностью самоуправляемыми, поскольку инженеры должны сперва проехать на них несколько кругов, чтобы машины выучили границы. Эти две машины известны как Ajay и Bobby, и, что интересно, у них сформировались разные стили вождения, несмотря на идентичное «железо», программы и системы навигации. Инженерная команда Audi, при всей ее гигантской экспертной квалификации, не готова объяснить, откуда эта наглядная разница взялась.
Наверное, машинное сознание продемонстрирует еще много разновидностей «интеллекта», которые не впишутся в стандартную человеческую модель или в наши ожидания и тем не менее позволят одновременно и усовершенствовать принятие решений людьми, и пересмотреть традиционный человеческий подход к критическому мышлению. То, что интеллект, развивающийся у машины, отличается от нашего, не делает его ниже или примитивнее. Те, кого больше всего тревожит, что он захватит мир или поработит людей, вероятно, видят в нем подобия людей со сверхвысоким IQ: с такими же желаниями, этикой, склонностью к эгоизму и насилию, которые присущи нам, людям. Сверхинтеллектуальная версия человека действительно была бы страшноватой. Однако у нас нет причин ожидать, что искусственный интеллект проявит человеческие склонности, предрассудки и субъективность. Гораздо более вероятно обратное.
Те виды искусственного интеллекта, которыми мы располагаем сейчас, через несколько лет сумеют не только распознавать эмоции и чувства, но и определять, когда человек лжет. В какой-то момент мы, вероятно, поручим одному из них выбирать правительство. Представьте, как мог бы выглядеть по-настоящему чистый, честный выборный процесс, особенно если использовать искусственный интеллект для того, чтобы интересы каждого законного избирателя были представлены как можно лучше с помощью оптимальной конфигурации границ избирательных округов.
А как насчет распределения ресурсов и работы над такими проблемами, как, например, изменение климата? Когда искусственный интеллект сумеет с высокой точностью смоделировать климат планеты на протяжении тысячи лет и дать точную, верифицируемую количественную оценку использования ископаемого топлива или, например, влияния коровьих кишечных газов на уровень углекислоты (CO2) в атмосфере, – подумайте, как это скажется на распределении ресурсов и применении возобновляемых источников энергии.
Да, искусственный интеллект угрожает сложившемуся положению вещей, потому что, скорее всего, он окажется чистейшей формой логики и здравого смысла. Все, что сегодня «попахивает», в мире искусственного интеллекта будет разоблачено очень быстро. Добавьте к этому способность машины обучаться и строить гипотезы, и очень скоро нам придется защищать плохие человеческие решения перед лицом непогрешимой машинной логики, вооруженной таким объемом фактов и таким эффективным мышлением, с которыми мы, люди, просто не сможем тягаться. Через 15 лет в некоторых городах людям могут запретить садиться за руль, потому что самоуправляемые автомобили докажут, что они менее опасны. Страховые компании будут брать дороже за страховку автомобиля с водителем-человеком.
Нам предстоит убедиться, что в своих отдельных разновидностях машинный интеллект может очень отличаться от человеческого и наверняка станет революционной технологией задолго до того, как будет создан искусственный эквивалент нашего ума. Тот факт, что до его создания пройдет еще 20–30 лет, не означает, что все сказанное – только теория. Машины уже давно отнимают работу у людей; это началось 200 лет назад, с парового двигателя. Алгоритмы и роботы – всего лишь очередная машина в длинном ряду новейших технологий.

