Эффект ансамбля
Netflix, краудсорсинг и форсирование прогнозной точности
Чтобы передать прогнозную аналитику на краудсорсинг и привлечь лучшие таланты со всего мира, компания должна выставить свою стратегию, данные и исследования на всеобщее обозрение. Как это может повысить конкурентоспособность компании? Какие ключевые инновации в области прогнозной аналитики были разработаны при помощи краудсорсинга? Обязательно ли повышение точности прогнозирования должно достигаться путем головокружительного наращивания сложности? Или же существует некое простое и элегантное решение? Насколько целесообразен негуманоидный краудсорсинг?
Ракетостроители без опыта работы
В следующем году мы с приятелем собираемся построить ракету. Проблема в том, что у нас нет ни нужных знаний, ни опыта. Но кого это волнует? Мы хотим в космос.
Как бы странно это ни звучало, но Мартин Чабберт и Мартин Пиотте сделали именно это в мире прогнозной аналитики. В 2008 году эти двое монреальцев поставили перед собой цель выиграть соревнование Netflix Prize с главным призом $1 млн — самый престижный на тот момент аналитический конкурс. Невероятно, но без всякого опыта в прогнозной аналитике «ракетостроители по совместительству» стали центральными персонажами той истории.
Компания Netflix занимается прокатом фильмов, и основу ее бизнеса составляет уникальная система рекомендаций Cinematch. Эта система настолько хороша, что компания бросила вызов всему миру, предложив попытаться улучшить точность рекомендаций Cinematch на 10%. Netflix предлагает нам наглядный пример ПА в действии, поскольку 70% всех заказываемых фильмов выбирается клиентами на основе онлайн-рекомендаций. Сегодня системы рекомендаций все больше становятся чашей Грааля для розничной торговли в целом. Индивидуальные рекомендации не только служат коммерческой уловкой для увеличения продаж, но и обеспечивают персонализацию и релевантность, которых так жаждут сегодняшние клиенты.
Применение ПА: рекомендации фильмов
- Предмет прогнозирования: какую оценку клиент поставит фильму.
- Цель прогнозирования: рекомендовать клиентам такие фильмы, которые с большой вероятностью им понравятся и получат высокую оценку.
Такие конкурсы, как Netflix Prize, делают ставку на состязательный дух как главный двигатель научного прогресса. Как и на скачках, на игровом поле царит соперничество, и безусловный победитель выявляется в открытой борьбе. За некоторыми ограничениями в конкурсе Netflix мог участвовать любой житель планеты независимо от возраста, пола и т.д.; для этого нужно было просто скачать данные, разработать прогнозную модель и предоставить ее жюри.
Победитель получает все. Чтобы гарантировать объективное сравнение предлагаемых решений, в ПА-конкурсах используется хитрый прием: участники должны представить не прогнозную модель, а прогнозные оценки, сгенерированные для оценочного (квалификационного) набора данных, правильные ответы для которого — искомые значения, которые должна предсказать модель, — удерживаются в секрете. В конкурсе Netflix Prize модели должны были предсказать, какие оценки поставили фильмам клиенты (на основе оценок, поставленных ими другим фильмам). Настоящие оценки фильмов не были указаны в публично доступных квалификационных данных, поэтому на момент отправки своих решений участники не знали, насколько верны их прогнозы. В качестве конкурсного материала Netflix опубликовала обучающий набор данных, содержащий более 100 млн оценок, которые 480 189 клиентов поставили 17 770 фильмам (из соображений конфиденциальности имена клиентов были удалены).
Единственное, что имеет значение, — прогнозная способность модели, а не знания, опыт или прошлые научные заслуги ее разработчиков. Такие конкурсы представляют собой сугубо прагматичные и объективные соревнования «на лучший пирог» — тот, кто сумеет испечь модель, которая лучше других решает поставленную прогнозную задачу, тот получает славу и, как правило, деньги.
Темные лошадки
Именно это и сделали двое наших монреальцев, Мартин и Мартин, которые взяли Netflix Prize штурмом, несмотря на отсутствие опыта, или, быть может, благодаря этому. Никто из них никогда раньше не сталкивался со статистикой или анализом данных, не говоря уже конкретно о рекомендательных системах. На тот момент оба работали в телекоммуникационной отрасли, занимаясь разработкой ПО.
Но, когда Netflix объявила свой конкурс, они решили принять вызов. По вечерам дома эти двое упорно трудились по 10–20 часов в неделю и в конечном итоге сумели вырваться вперед как команда под названием PragmaticTheory. «Прагматичный» подход оказался настолько успешным, что в последние месяцы конкурса команда стабильно находилась в числе лидеров.
На ум приходит поразительная параллель с историей создания первого в мире частного пилотируемого космического корабля SpaceShipOne, разработчики которого получили премию Ansari X Prize в размере $10 млн. По некоторым данным, этот корабль был разработан небольшой командой с бюджетом всего $25 млн, которой удалось посрамить гиганта НАСА с его колоссальными финансовыми и человеческими ресурсами. Конкурсы в области ПА делают для науки о данных то же самое, что премия X Prize сделала для ракетостроения.
Коллективный разум: богатство в разнообразии
Краудсорсинг обладает способностью формировать некую совершенную меритократию. Уходят в небытие такие категории, как происхождение, раса, пол, возраст и квалификация. Остается лишь качество самой работы.
Когда вам требуется решить сложную задачу, кто вам поможет? Если вы в затруднении, у вас остается единственный выход — обратиться за помощью ко всему миру. Конкурсы дают доступ к самому большому трудовому ресурсу — широкой общественности. Наиболее распространенный способ задействовать краудсорсинг — открытый конкурс — позволяет привлечь специалистов из самых разных уголков планеты, дав им возможность бороться за победу и получать удовольствие от сотрудничества. Через краудсорсинг компания фактически нанимает на работу весь мир.
Соревнование Netflix Prize с наградой $1 млн привлекшее к себе всеобщее внимание и давшее новое понимание возможностей краудсорсинга, собрало целую международную армию талантливых специалистов. В общей сложности для участия в конкурсе было сформировано 5169 команд, и за все время его проведения было представлено 44 014 решений.
Главная сила краудсорсинга заключается в том, что он дает доступ к интеллектуальному разнообразию. Крис Волински, член команды BellKor от компании AT&T Research, также одного из лидеров Netflix Prize, сказал об этом так: «Меня с самого начала удивляло, как много в списке лидеров было так называемых “любителей”. Если на то пошло, наша группа тоже не имела опыта работы с рекомендательными системами, когда мы начинали… Но, как я понял впоследствии, чтобы добиться успеха, иногда требуется только одно — свежий взгляд со стороны».
Например, одна таинственная анонимная команда под названием «Простой парень из гаража» оказалась настолько сильной, что мгновенно поднялась на шестое место в конкурсном рейтинге. Как стало известно впоследствии, команда состояла всего из одного человека — бывшего консультанта по вопросам управления, окончившего университет по специальности «психология», а в аспирантуре занимавшегося проблематикой исследования операций (он называет себя безработным и признается, что на самом деле работал не в гараже, а в собственной спальне).
Двум «темным лошадкам» из команды PragmaticTheory, о которых мы ведем разговор, было нетрудно обойти устоявшиеся правила и мыслить вне рамок — в первую очередь потому, что ни о каких правилах и рамках они не имели ни малейшего представления. Не сдерживаемые ничем, они смело могли пойти туда, куда до них не ступала нога человека. Как сказал мне в интервью Мартин Чабберт, они решили, что «наиболее прагматичный и наименее догматичный подход может дать хорошие результаты». Как ни странно, их конкурентное преимущество проистекало не столько из способности к научным инновациям, сколько из практического опыта в разработке программного обеспечения. Мартин рассказывает об этом поразительном уроке:
«Хорошие идеи были у многих, но превратить слова в математические формулы весьма непросто… Наш опыт программирования сыграл ключевую роль. В этом конкурсе существовала очень тонкая грань между плохой идеей и ошибкой в коде. Часто бывало так: люди решали, что их модель плоха, просто потому, что она не приносила ожидаемых результатов, тогда как на самом деле причиной была ошибка в коде. То, что мы умели хорошо писать коды и — прежде чем признавать модель неработоспособной — проверять их на наличие ошибок, оказало нам существенную помощь… Вопреки представлению большинства людей это было скорее состязание в искусстве программирования, чем конкурс на лучшую математическую идею».
Как показало соревнование Netflix Prize и другие конкурсы в области прогнозной аналитики, наилучших результатов добиваются команды, состоящие из специалистов в разных дисциплинах. Так, в конкурсе на разработку лучшего программного средства для оценки школьных сочинений, спонсором которого выступил фонд Hewlett Foundation (созданный основателем компании Hewlett-Packard), победу одержала команда, включавшая физика в области элементарных частиц из Великобритании, аналитика данных из Национальной метеорологической службы в Вашингтоне и аспиранта из Германии; они получили приз в размере $100 000. Разработанная ими компьютерная программа оценивает сочинения так же точно, как и настоящие преподаватели, хотя ни один из трех победителей не имел опыта работы в сфере образования или текстовой аналитики.
Попробуйте угадать, какой специалист преуспел в прогнозировании распределения темной материи во Вселенной? В рамках конкурса, объявленного НАСА и Королевским астрономическим обществом, аспирант из Великобритании Мартин О’Лири, специализирующийся на гляциологии (науке о льде), предложил новый метод, который, по словам Белого дома, «превзошел все передовые алгоритмы, используемые на сегодняшний день в астрономии». Работа О’Лири стала первым крупным открытием в этом конкурсе (хотя он и не стал окончательным победителем). Как объясняет О’Лири, методы, применяемые им в работе для картографирования границ ледников на основе спутниковых фотографий, вполне могут быть использованы и для картографирования галактик.
Краудсорсинг набирает силу
При наличии определенного набора условий толпа практически всегда превзойдет любое число штатных сотрудников.
Большинство организаций, с которыми я работал, рассматривали конкуренцию в бизнесе как состязание, где все выигрывают от совместного участия, а не как войну, где победа одного достигается ценой проигрыша другого. Концепция краудсорсинга отражает эту философию.
Одна маленькая новаторская фирма Kaggle взяла на себя роль организатора и предложила инновационную платформу для проведения соревнований в области прогнозной аналитики. В ее послужном списке насчитывается уже 53 успешных конкурса, в том числе два вышеупомянутых, касавшихся оценки школьных сочинений и распределения темной материи. Сообщество Kaggle состоит из более чем 50 000 специалистов разных областей знаний, которые разбросаны по 100 странам и работают на базе 200 университетов. Предлагаемые призы варьируются от $10 000–20 000 до $3 млн. В общей сложности за время существования этой платформы пользователи Kaggle предложили более 144 000 решений в рамках различных конкурсов.
Чтобы использовать возможности краудсорсинга в сфере ПА, компания вынуждена радикально изменить свой подход к исследованиям и разработке. Вместо того чтобы держать свою стратегию, планы, данные и исследования в строжайшем секрете, она должна выставить их на всеобщее обозрение. И вместо того чтобы тщательно контролировать своих научных сотрудников, организация должна приветствовать всех и каждого, кто желает принять участие в конкурсе ради победы или просто удовольствия. Другими словами, использование краудсорсинга — это самый странный и фантастический способ конкурировать в бизнесе.
Краудсорсинг помогает заключить счастливый брак. Основатель и генеральный директор Kaggle Энтони Голдблум (включенный журналом Forbes в список «30 звезд до 30 лет в сфере технологий») рассказывает об этой истории любви: «С одной стороны, есть компании, у которых имеются горы данных, но нет возможности извлечь из них ту полезную информацию, которую бы они хотели. С другой, есть исследователи и ученые, особенно из университетских кругов, которые крайне нуждаются в доступе к реальным данным, чтобы протестировать и уточнить свои методики».
Учитывая нынешний дефицит высококвалифицированных аналитиков данных, идея поиска талантливых кадров по всему миру представляется весьма разумной. Согласно докладу McKinsey, «к 2018 году одни только Соединенные Штаты могут столкнуться с нехваткой специалистов с глубокими аналитическими навыками в количестве от 140 000 до 190 000 человек, а также 1,5 млн менеджеров и аналитиков, имеющих практические навыки в применении анализа больших данных для принятия эффективных решений». Чтобы не позволять своим данным лежать мертвым грузом, организации вынуждены обращаться за помощью к широким массам. Как подчеркивает Kaggle, «существует, по сути, бесчисленное множество вариантов решения любой задачи прогнозного моделирования, и невозможно знать с самого начала, какой метод и какой аналитик окажутся наиболее эффективными».
Еще несколько лет назад конкурсы в области ПА проводились в основном научно-исследовательскими организациями и конференциями. Компания Kaggle изменила ситуацию. Этот краудсорсинговый ресурс сумел завоевать доверие к себе в мире коммерции тем, что, как он утверждает, ему «всегда удается превзойти уже достигнутые уровни точности, причем с существенным отрывом». Например, из 147 примеров применения ПА, приведенных в таблицах, размещенных в приложении этой книги, 14 примеров относятся к проектам Kaggle:

Ваш соперник — ваш друг
Как ни парадоксально, но соревнование порождает сотрудничество. Лозунг Kaggle гласит «Превратим анализ данных в спорт». Но соперники в лабораторных халатах, кажется, не стремятся вести столь же безжалостную и беспощадную борьбу, что ведут атлеты на спортивных аренах. Несмотря на наличие денежного стимула, участниками часто движет не стремление выиграть, а любовь к науке. Для них характерна готовность к сотрудничеству и обмену знаниями. Это одно из лучших проявлений так называемого конкурентного сотрудничества. Победитель Netflix Prize Мартин Чабберт сказал мне, что публичный форум конкурса «был тем местом, где люди предлагали новые идеи, и эти идеи часто вдохновляли нас на собственные творческие инновации». А журнал Wired написал, что «участники таких конкурсов, даже лидеры, поразительно открыто рассказывают об используемых ими методах, действуя больше как ученые, работающие над интересной научной проблемой, нежели как соперники, сражающиеся за приз $1 млн». Принимая участие в одном из конкурсов, Джон Элдер оказался в замешательстве. «Поразительно, как много людей было открыто для обмена и сотрудничества, — говорит Джон. — Там царила уникальная атмосфера товарищества».
Такое сообщество формируется вокруг каждого конкурса, превращая его в чашку Петри для выращивания отличных идей. Но Джон Элдер признает, что раскрытие информации может стоить вам конкурентного преимущества. Команда из Elder Research участвовала в конкурсе Netflix Prize на ранних этапах, на которых, собственно говоря, и были достигнуты самые значительные успехи. В один из моментов она вышла на третье место, применив один из ключевых аналитических методов раньше остальных участников. Впоследствии именно этот метод стал ключевым компонентом, который был использован в победившем решении конкурса Netflix Prize, а также компанией IBM при разработке суперкомпьютера Watson, занявшего первое место в американском аналоге интеллектуального телешоу «Своя игра». Движимая духом коллегиальности, команда Джона сообщила об избранном ею методе непосредственно в своем названии, тем самым раскрыв свое секретное оружие. Команда называлась «Ансамбль экспертов».
Объединенные нации
На последнем круге в скачках под названием Netflix Prize (которые стартовали еще до того, как была запущена платформа Kaggle) горстка лидеров шла буквально ноздря в ноздрю. Но сама гонка продвигалась с черепашьей скоростью, как будто при просмотре спортивного события в замедленном повторе. Вследствие убывающей отдачи от их усилий и возрастающей сложности прогнозных моделей, чем ближе команды подходили к цели — 10%-ному повышению точности существующей рекомендательной системы, которое Netflix поставила условием получения приза $1 млн, — тем медленнее они продвигались вперед.
Несмотря на это, страсти накалялись. Каждую неделю команды по очереди вырывались вперед, добиваясь незначительного улучшения точности своих моделей. Хотя никто, в том числе Netflix, не знал, было ли вообще возможно преодолеть отметку в 10%, существовало подспудное ожидание того, что в любой момент одна из команд сделает решающий прорыв и преодолеет финишную черту.
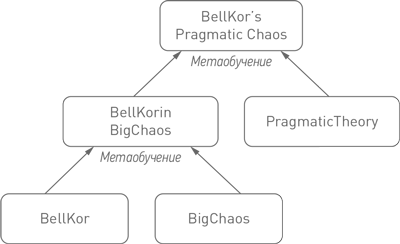
Такой прорыв произошел в сентябре 2008 года, временно оставив позади наших монреальцев. Две группы, BellKor (от AT&T Research) и BigChaos (молодежная команда от небольшого стартапа из Австрии), сформировали альянс. Они объединили свои силы и прогнозные модели и собрали суперкоманду. Учитывая все то тесное сотрудничество, что имело место неофициально, почему бы не сделать его официальным?
Объединение было рискованным шагом. Обмениваясь технологиями, команды теряли конкурентное преимущество по отношению друг к другу. Одержи они победу, им пришлось бы делиться выигрышем. Но, если бы они не объединились достаточно быстро, другие команды могли попробовать такую же тактику для достижения победы.
Это сработало. Созданные командами прогнозные модели значительно отличались друг от друга, и, как и предполагалось, сильные стороны одной модели компенсировали слабые стороны другой. Благодаря интеграции моделей была достигнута точность, превышавшая результаты каждой модели в отдельности. Этот шаг позволил новой суперкоманде BellKor in BigChaos оставить далеко позади других участников и получить ежегодный приз за прогресс в размере $50 000.
Метаобучение
Вот где кроется еще один источник силы ПА. Объединить две и более сложные прогнозные модели не составляет труда: просто примените машинное обучение для разработки еще одной модели, которая будет комбинировать их прогнозы. По сути, этот процесс представляет собой «обучение на знаниях, полученных путем обучения», — или метаобучение.
Таким образом, бывшие соперники, а ныне сотрудники, легко объединили две замысловатые модели, разработанные разными способами. Как рассказал мне Андреас Тошер из команды BigChaos, чтобы не ломать голову над тем, как сопоставить и скомбинировать свои теории и методы, они переложили всю работу по их объединению на плечи машинного обучения. Новая ансамблевая модель выступала в качестве менеджера по отношению к двум существующим базовым моделям. Она рассматривала прогнозы каждой из них для каждого отдельного случая. В одних случаях она больше доверяла прогнозам модели А, в других — модели В. Поступая таким образом, ансамблевая модель учится предсказывать, какие случаи являются слабыми местами в каждой базовой модели. Во многих случаях прогнозы базовых моделей могут совпадать, но там, где есть расхождения в оценках, агрегированная модель позволяет добиться повышения точности прогнозирования.
Успех команды BellKor in BigChaos изменил правила игры в Netflix Prize и повлек за собой волну объединения команд, которые в результате превращались в более крупных и сильных игроков. Это было похоже на волну слияний и поглощений мелких компаний в молодой, быстроразвивающейся отрасли.
Несмотря на все свое мастерство, двум Мартинам из Монреаля было трудно конкурировать с новыми сильными игроками. Но достижения их команды PragmaticTheory привлекли к себе внимание соперников, и приглашение не заставило себя ждать. Им было предложено присоединиться к суперкоманде BellKor in BigChaos и сформировать суперсуперкоманду. Так на свет появилась команда BellKor’s Pragmatic Chaos:
26 июня 2009 года BellKor’s Pragmatic Chaos преодолела заветный 10%-ный барьер, что делало ее главным претендентом на получение премии Netflix.
Крупная рыба и драматичный финиш
Но на этом соревнование не закончилось. В соответствии с правилами конкурса, с момента преодоления 10%-ного барьера участникам отводилось еще 30 дней, в течение которых они могли продолжать отправлять уточненные решения.
У каждого супергероя есть свой супервраг. Для BellKor’s Pragmatic Chaos им стала группа The Ensemble (не путайте с командой Джона Элдера Ensemble Experts, которая использовала метод ансамбля моделей внутри своей группы, а не в результате объединения различных команд). В погоне за призом эта группа жадно поглощала всех соперников, которые были на это согласны, и в конечном итоге превратилась в конгломерат из более чем 20 команд. При присоединении каждой новой команды ее модель включалась в ансамбль, и конечное вознаграждение команды зависело от того, какой вклад внесла ее модель в повышение точности агрегированной модели — разумеется, при условии, что победа достанется объединенной команде. Это было похоже на Борга из «Звездного пути» — внушающую ужас расу киборгов с единым коллективным разумом, способную ассимилировать целые цивилизации. Отдельные команды предпочитали быть поглощенными огромной рыбой, нежели сойти с дистанции. В конце концов, если не можете победить — присоединяйтесь.
Хотя BellKor’s Pragmatic Chaos и объединяла силы всего трех команд, она успешно конкурировала с этой растущей силой. На протяжении последних 30 дней команды шли вплотную друг к другу, в бешеном темпе настраивая и перенастраивая свои модели и представляя все новые решения с уточненными прогнозами даже в последние часы и минуты этого длившегося несколько лет конкурса. По накалу страстей и самоотверженности краудсорсинговые соревнования подчас сравнимы с боевыми действиями, что дает мощный толчок процессу научных инноваций.
Наконец обратный отсчет закончился, и прием решений был прекращен. На несколько недель воцарилась тишина, пока организаторы конкурса оценивали результаты. Для верификации представленных решений и вынесения окончательного приговора использовался нераскрытый тестовый набор данных. Вот как выглядела финальная таблица лидеров:
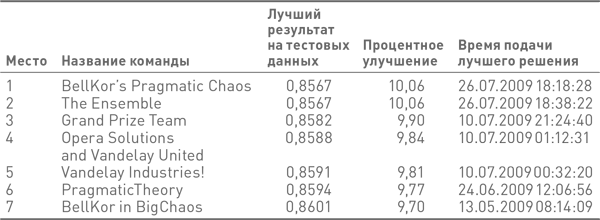
С небольшим перевесом победила команда BellKor’s Pragmatic Chaos. Ее окончательный результат был настолько близок к результату The Ensemble, что по правилам конкурса была признана количественная ничья, но тот факт, что BellKor’s Pragmatic Chaos прислала свои результаты на 20 минут раньше The Ensemble (см. таблицу), стал решающим. Команда-победитель получила деньги, другая — ничего. Как сказал генеральный директор Netflix Рид Хастингс, «эти 20 минут стоили миллион долларов».
Коллективный разум
Принято думать, что среднее — это заурядное. Но в случае коллективного разума среднее часто является наилучшим.
Мудрость толпы дает о себе знать и в решении куда более простых задач, нежели тех, что связаны с анализом данных. Могущество коллективного разума было наглядно продемонстрировано в 2012 году на конференции Predictive Analytics World. Чтобы привлечь внимание к стенду своей компании на выставке, организованной в рамках этого мероприятия, Гари Панчу провел конкурс: участникам предлагалось угадать, какая сумма денег находится в этом контейнере:

Как группа, конкурсанты оказались умнее каждого отдельно взятого участника. При правильном ответе $362 победитель ошибся на $10, тогда как «общая догадка» группы, выведенная на основе 61 индивидуального предположения, составила $365, т.е. группа ошиблась всего на $3.
Как участникам удалось достичь такой точности без координации усилий? Это можно объяснить тем, что завышенные и заниженные оценки разных людей компенсируют друг друга, т.е. усреднение нивелирует ошибки в суждениях. Ни один человек не может преодолеть ограниченность своего знания или мышления: если только вы не супергерой, вы не можете заглянуть внутрь контейнера и быть абсолютно уверены в своем предположении относительно числа купюр. Но как группа вы фактически превращаетесь в такого супергероя.
Как говорится, в единстве — сила. Объединяясь в группу, мы способны преодолеть присущие каждому их нас индивидуальные ограничения. Более того, нам больше не нужно тратить время и силы на выяснение того, кто из нас лучший. Не важно, кто из участников группы умнее, изобретательнее и т.п. Ключ — в многообразии.
Могущество коллективного разума толпы проявляется во многих ситуациях. Вот некоторые из примеров, которые приводит Джеймс Шуровьески в своей книге «Мудрость толпы».
- Рынки предсказаний, где участники прогнозируют буквально все — от результатов скачек до политических и экономических событий — путем размещения ставок (к сожалению, это действенный метод прогнозирования неприменим в сфере ПА, где прогнозная модель обычно генерирует тысячи и миллионы прогнозов).
- Аудитория телевикторины «Кто хочет стать миллионером?»: общий ответ толпы случайных людей, которым нечем заняться, кроме как сидеть в телестудии в будний день, оказывается верным в 91% случаев!
- Технология Google PageRank оценивает популярность сайта и его «важность» в поисковой системе Google на основе количества внешних ссылок, созданных всей совокупностью пользователей.
- Массовые настроения, выражаемые сообществом блогеров, позволяют довольно точно предсказать поведение фондового рынка, о чем мы рассказывали в главе 3 (на самом деле данное исследование было проведено в Центре коллективного интеллекта при Массачусетском технологическом институте).
Но не только человеческий разум выигрывает в могуществе в результате эффективного объединения. Оказывается, эффект коллективного разума распространяется и на негуманоидные «толпы» — а именно на группы прогнозных моделей.
Мудрость толпы… моделей
В основе метода ансамбля моделей лежит концепция «мудрости толпы», которая отражает ключевой принцип: улучшение точности прогнозирования может быть достигнуто путем усреднения множества разных прогнозов.
Подобно толпе, ансамбль прогнозных моделей проявляет тот же благотворный эффект «коллективного разума». У каждой модели есть свои сильные и слабые стороны. Как и суждения отдельных людей, прогнозные оценки отдельных моделей несовершенны. Одна модель может занижать оценки, другая завышать их. Усреднение оценок, сгенерированных разными моделями, может устранить бóльшую часть погрешности. Зачем пытаться нанять одного самого лучшего сотрудника, если вы можете нанять целую команду, члены которой будут компенсировать недостатки друг друга? В конце концов, прогнозные модели работают бесплатно: компьютер потребляет практически одинаковое количество электроэнергии, применяет ли он 100 моделей или всего одну.
Метод формирования ансамблей моделей произвел революцию в индустрии ПА. Его считают одним из наиболее важных достижений в области прогнозного моделирования в первом десятилетии XXI века. И хотя первоначально этот метод громко заявил о себе именно благодаря успешному применению в краудсорсинговых конкурсах, сегодня технология создания ансамблей моделей вышла за пределы этой сферы и широко применяется как в коммерческом, так и в научном мире.
Как ни парадоксально, иногда увеличение сложности может улучшать обучение. Ансамбль моделей, который может включать тысячи компонентов, обладает намного более развитой прогнозной способностью, чем каждая отдельно взятая модель. Здесь не действует принцип «Будь как можно проще, глупышка!» (он же принцип «бритвы Оккама»), позволяющий избежать избыточного обучения, о котором мы говорили в главе 4. Но прежде чем разобраться с этим парадоксом, давайте рассмотрим, как работает ансамбль моделей.
Мешок моделей
Модульная декомпозиция — такова природа вещей, и в этом огромный плюс.
Если в вашей жизни есть иерархический порядок,
Вы легко можете выполнить
Каждую под-под-под-под-подзадачу.
Лев Брейман, один из «великолепной четверки» создателей алгоритма CART (подробности см. в главе 4), разработал один из основных методов формирования ансамбля моделей под названием бэггинг. Как он работает, во многом понятно из названия. Разработайте целый мешок моделей. Затем позвольте каждой модели вырабатывать прогнозы и комбинируйте их путем голосования или в некоторых случаях простого усреднения. Ключевое преимущество таких моделей — разнообразие. Оно достигается путем обучения каждой модели на отдельном подмножестве данных, которое генерируется из обучающих данных как случайная выборка с повторением (это значит, что некоторые примеры повторяются в выборке несколько раз, тем самым оказывая более сильное влияние на процесс обучения модели, тогда как другие вообще не попадают в нее). Вследствие присутствия этого случайного элемента один из вариантов бэггинга, представляющий собой ансамбль деревьев решений CART, называется «случайным лесом». (Вам не кажется, что этот «случайный лес» похож на одно дерево решений «а-ля CART»?)
Идея собрать группу моделей и научить их голосовать проста и элегантна. Другие методы формирования ансамблей, все представляющие собой вариации на одну тему, носят такие же интересные и говорящие названия, в том числе «корзина моделей» (bucket of models), «связки моделей» (bundling), «комитет экспертов», «метаобучение», «многоярусное обобщение» (stacked generalization) и алгоритм TreeNet (не все из перечисленных методов используют голосование; некоторые опираются на метаобучение, как ансамбль моделей, выигравший Netflix Prize).
Концепция сборки простых компонентов в более сложную и мощную структуру является сутью инженерного искусства, будь то строительство зданий и мостов или создание операционной системы для вашего iPhone. Никто не может, да и не должен пытаться, создать сложную массивную конструкцию сразу целиком. Многоуровневая сборка делает структуру управляемой. Каждый уровень объединяет компоненты, которые сами по себе довольно просты, но, будучи интегрированными в единую систему, способными выполнять сложнейшие задачи.
Как правило, ансамбль моделей повышает качество работы отдельных моделей. Посмотрите на попытку одного дерева решений смоделировать круг:
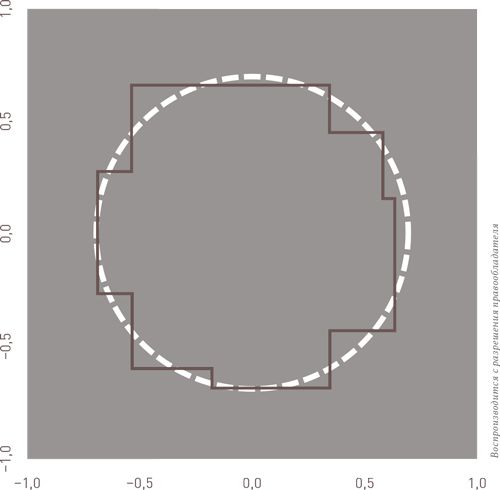
В этом эксперименте дерево решений CART было обучено на наборе данных, включавшем положительные и отрицательные примеры, т.е. точки, попадающие внутрь и за пределы круга соответственно. Так как дерево решений может только сравнивать предикторные переменные (в данном случае, координаты по осям х и у) с фиксированной величиной и не может производить никаких математических действий над ними, граница решений дерева состоит только из горизонтальных и вертикальных линий. Ни диагональные, ни кривые линии здесь невозможны. В результате модель правильно определяет, какие точки находятся внутри и вне круга, но получившийся рисунок совершенно очевидно является грубой, простейшей аппроксимацией.
Ансамбль из 100 деревьев решений CART, сформированный по методу бэггинга, позволяет создать более точный и ровный круг, :
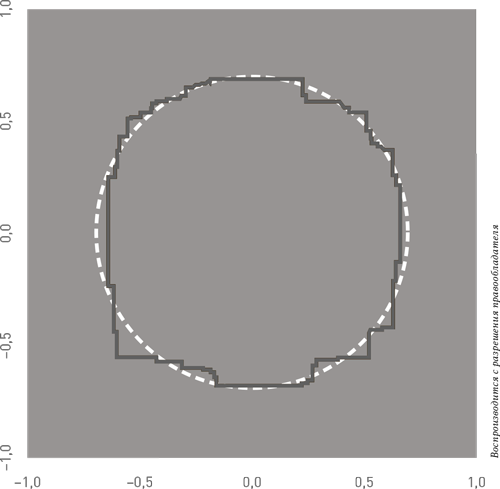
Ансамбль моделей в действии
Конкурсы Kaggle часто выигрывают команды, которые используют ансамбли моделей.
Собираемые автоматически из нескольких тысяч или вручную, как при объединении команд во время соревнования Netflix Prize, ансамбли моделей неизменно одерживают победу. Исследования показывают, что ансамбли повышают эффективность отдельно взятой модели на 5–30%, а интеграция в ансамбль дополнительных моделей ведет к его дальнейшему улучшению. «Группа моделей, как правило, лучше большинства индивидуальных моделей, из которых она состоит, и зачастую лучше, чем все они вместе взятые», — говорит Дин Эбботт.
Расширяется и сфера их коммерческого применения. Среди примеров, приведенных в таблицах в приложении D этой книги, по крайней мере в восьми случаях использовались ансамбли моделей: IBM (суперкомпьютер Watson, играющий в Jeopardy!), Налоговое управление США (налоговое мошенничество), экологическая организация Nature Conservancy (пожертвования), Netflix (рекомендации фильмов), Nokia-Siemens (сброшенные вызовы), Калифорнийский университет в Беркли (изучение активности головного мозга для воссоздания движущегося изображения, которое видит человек), Министерство обороны США (мошеннические счета-фактуры) и Войска специального назначения США (оценка эффективности).
Кажется, это слишком хорошо, чтобы быть правдой. Собирая модели в ансамбли, мы получаем все более точные прогнозные модели без какой-либо новой математики или формальной теории. В чем подвох?
Парадокс генерализации: чем больше, тем меньше
Ансамбли моделей создают видимость увеличения сложности… поэтому улучшение их способности к генерализации, кажется, нарушает требование простоты, выраженное принципом «бритвы Оккама».
В главе 4 мы говорили, что ключевое требование машинного обучения — нахождение границы между обучением и избыточным обучением. Она диктует пределы наращивания сложности прогнозной модели в попытке улучшить ее соответствие обучающим данным. После определенного момента прогнозная эффективность модели, измеряемая на основе независимых тестовых данных, неизменно начинает снижаться.
Однако ансамбли моделей сохраняют устойчивость даже при увеличении сложности. Кажется, они избавлены от дефекта, присущего отдельным моделям, словно пропитаны волшебным зельем против избыточного обучения. Джон Элдер, который в шутку называет ансамбли моделей «секретным оружием», посвятил этой проблеме отдельное исследование, названное им «Ансамбли моделей и парадокс генерализации».
Джон разрешает видимый парадокс через переопределение понятия сложности как характеристики функции, а не формы. Ансамбли моделей выглядят более сложными по своей конструкции — но усложняется ли их поведение? Вместо того чтобы рассматривать структурную сложность модели (насколько она велика или сколько компонентов включает), Элдер измеряет совокупную сложность метода моделирования. Для этого он использует показатель под названием совокупные степени свободы, отражающий, насколько адаптируемым является данный метод моделирования и как сильно меняются генерируемые им прогнозы в результате небольших экспериментальных изменений в обучающих данных. Если небольшое изменение в обучающих данных существенно меняет результат, это говорит о том, что данный метод обучения может быть ненадежным, чрезмерно чувствительным к искажениям и случайным шумам, присущим любому набору данных. Оказывается, что ансамбли моделей имеют более низкий совокупный показатель сложности, чем отдельные модели. Ансамбли меньше подвержены избыточной адаптации. Следовательно, они проявляют менее сложное поведение, и их способность к успешному обучению без избыточного обучения вовсе не является парадоксом.
В этом и состоит эффект ансамбля. Благодаря простому объединению моделей мы получаем возможность наращивать структурную сложность при сохранении критически важной характеристики — устойчивости к избыточному обучению.
| Эффект ансамбля: объединенные в ансамбль прогнозные модели компенсируют недостатки друг друга; следовательно, ансамбль моделей в большинстве случаев обладает бóльшей прогнозной точностью, чем составляющие его модели. |
Для ПА нет пределов
Итак, принимая во внимание обретенное благодаря ансамблям моделей могущество, а также желание испытать свои силы на все более трудных задачах, куда прогнозная аналитика двинется дальше? В следующей главе мы расскажем о том, как ПА взялась за грандиозную задачу — составить конкуренцию людям в интеллектуальной телевикторине Jeopardy!.


