Машина, которая учится
Как крупнейший американский банк прогнозирует ипотечные риски: взгляд изнутри
Какой вид риска использует идеальную маскировку? Как прогнозирование превращает риск в возможность? Чему должны научиться все компании у страховых фирм? Почему машинное обучение требует не только науки, но и искусства? Какая прогностическая модель будет понятна каждому? Можем ли мы полностью доверять машинным прогнозам? Почему прогнозы не смогли предотвратить мировой финансовый кризис?
Эта история повествует о любви между человеком по имени Дэн и банком по имени Chase и о том, как они вместе научились преодолевать все трудности — а точнее, использовать машинное обучение для расширения возможностей прогнозирования и последующего снижения рисков. Вы также узнаете, как же на самом деле работает машинное обучение.
Первое знакомство
Однажды ученому по имени Дэн Стейнберг позвонили из крупнейшего американского банка, который столкнулся с новыми уровнями риска. Банк решил, что только помощь специалиста по машинному обучению позволит ему взять эти риски под контроль.
Решение было правильным, поскольку у Дэна действительно имелись все необходимые средства, чтобы помочь банку. Ученый с духом предпринимателя, он разработал прогнозно-аналитическую систему, ставившую новейшие достижения науки на службу корпоративного мира. В качестве приданого банк предложил электронный скарб: бесконечные ряды единиц и нулей, содержащие информацию о его прошлом опыте.
У банка было топливо, у Дэна — машина. Это был брак, заключенный на небесах. Порой, задумавшись, я рисую на полях:

Более взрослый аналитик выразит свои чувства чуть строже и официальнее, примерно так, как это было сделано в предыдущей главе:
Банк сталкивается с риском
В любой организации финансовый риск нарастает незаметно, пользуясь простой, но идеальной маскировкой: множество небольших и, на первый взгляд, безобидных убытков аккумулируются и превращаются в крупный убыток. Отдельные мелкие потери, банальные и лишенные всякого драматизма, ускользают от корпоративных радаров, но, накапливаясь, способны пустить корабль ко дну.
Вскоре после того, как в 1996 году Chase Bank провел мегаслияние и превратился в крупнейший банк США, группа, занимавшаяся жилищным кредитованием, пришла к выводу, что он столкнулся с новым уровнем риска. Его пул закладных значительно вырос. Теперь ипотечный портфель Chase состоял из портфелей, раньше принадлежавших шести разным банкам, и включал миллионы кредитов. И каждый из них нес небольшой риск — микрориск. За помощью было решено обратиться к Дэну.
Как ни странно, существует два, казалось бы, противоположных вида поведения ипотечных заемщиков, влекущих за собой риск для банка, — либо они не выплачивают кредит, либо выплачивают в полном объеме, но слишком быстро:
Микрориск А: невозврат ипотечного кредита.
Микрориск B: досрочное погашение ипотечного кредита в полном объеме в результате рефинансирования в конкурирующем банке или продажи дома. Досрочное погашение означает убыток для банка, поскольку лишает его запланированных будущих процентных платежей.
Такие риски относят к категории «микро», потому что для банка убытки по одной отдельно взятой закладной не так уж страшны. Опасность в том, что микроубытки могут накапливаться. Кроме того, в финансовом мире под риском чаще всего подразумевается кредитный риск, т.е. микрориск А, означающий невозврат кредита. Но, если вы зарабатываете на процентных платежах, микрориск В тоже нешуточное дело. Проще говоря, банку на руку, чтобы его клиенты не вылезали из долгов.
Прогнозирование борется с риском
Большинство дискуссий на тему принятия решений исходит из того, что решения принимаются только руководителями высшего звена или только решения руководителей высшего звена имеют значение. Это опасное заблуждение.
В общей сложности риски по ипотечному портфелю Chase достигали сотен миллионов долларов. Это было все равно что шагать по зыбучим пескам, где каждая из миллионов песчинок представляет собой микрориск. Когда кредитная заявка признается «низкорискованной» и утверждается, процесс управления рисками на самом деле только начинается. Выданные банком ипотечные кредиты требуют такой же заботы, как коровы на молочной ферме. Почему? Потому что риски скрыты. Миллионы закладных ждут решений о том, какие из них продать другим банкам, какие попытаться удержать на плаву, а какие разрешить рефинансировать по более низкой процентной ставке.
Прогнозная аналитика служит лучшим противоядием от накопления микрорисков. ПА бдительно выявляет возможные микрориски и предупреждает о них организацию, позволяя ей заранее принять надлежащие меры.
В этом нет ничего нового. Эта идея родилась фактически вместе с самой прогнозной аналитикой. Прогнозирование потребительского риска широко известно в форме классической кредитной оценки заемщиков, предоставляемой FICO и кредитными бюро, такими как Experian. Концепция кредитного скоринга была разработана еще в 1941 году и ныне прочно вошла в обиход. Собственного говоря, с нее и началась прогнозная аналитика, а ее успехи выдвинули ПА на передний план. Современные скоринговые системы оценки риска часто опираются на те же самые методы прогнозного моделирования, которые используются в ПА.
Продемонстрировать преимущества борьбы с риском при помощи ПА не составляет труда. Хотя само прогнозирование может быть сложнейшей задачей, чтобы рассчитать выгоду, которую приносит его эффективное использование, достаточно простейших арифметических действий. Представьте, что вы управляете банком, имеющим тысячи выданных кредитов, по 10% из которых ожидается невозврат. Другими словами, каждый десятый из ваших заемщиков окажется неплательщиком, но будущее, как всегда, покрыто завесой тайны: вы не знаете, кто именно из них может оказаться неисправимым должником.
Допустим, вы оцениваете каждый кредит при помощи эффективной прогнозной модели. Одни оцениваются как кредиты с высоким уровнем риска, другие — с низким. Если эти оценки правильны, то среди той половины кредитов, что были признаны наиболее рискованными, будет почти в два раза больше случаев невозврата, чем в среднем по группе, — или, если быть более реалистичным, процент невозврата в ней будет примерно на 70% выше общего показателя. Это музыка для ваших ушей. Таким образом вы делите свой портфель на две половины, для одной из которых невозврат составит 17% (на 70% больше общего показателя по группе, равного 10%), а для другой — всего 3% (17% и 3% в среднем дают 10%).
Высокорискованные кредиты: 17% невозврата.
Низкорискованные кредиты: 3% невозврата.
Вы просто делите свой бизнес на два разных мира — один опасный, другой безопасный. Теперь вы знаете, на чем сосредоточить внимание.
Движимый этой заманчивой перспективой, Chase решил пойти на крупномасштабный, взвешенный макрориск. Он сделал ставку на прогнозирование, доверив ему определять миллионы решений общей стоимостью сотни миллионов долларов. Но о счастливом окончании этой истории можно будет говорить только в том случае, если прогнозная модель докажет свою работоспособность — если выдаваемые ею прогнозы касательно неопределенного будущего принесут реальные результаты.
Прогнозирование ставит нас перед фундаментальной дилеммой. При всех колоссальных объемах информации о прошлом, как убедиться в том, что мы можем доверять предлагаемому нам машинами видению непознаваемого будущего?
Прежде чем мы перейдем к рассмотрению того, как работает прогнозирование, позвольте сказать несколько слов о риске.
Рискованный бизнес
Революционная идея, которая определяет границу между современностью и прошлым, заключается в управлении риском, в представлении о том, что будущее — нечто большее, чем прихоть богов, а мужчины и женщины не пассивны перед природой. Пока люди не обнаружили путь через эту границу, будущее было зеркалом прошлого или мрачным владением оракулов и предсказателей, которые обладали монополией на знание ожидаемых событий.
Нет такого понятия, как риск; есть только плохое ценообразование.
Разумеется, банки не несут на себе все бремя управления рисками общества. Страховые компании также играют центральную роль. На самом деле их основной бизнес заключается в обработке данных с целью количественной оценки риска, чтобы тот мог быть эффективно распределен. Эту идею блестяще выразил Эрик Уэбстер, вице-президент страховой компании State Farm Insurance: «Страхование есть не что иное, как управление информацией. Это объединение рисков, и тот, кто может манипулировать информацией лучше других, получает значительное конкурентное преимущество». Проще говоря, эти компании строят свой бизнес на прогнозировании.
Страховая отрасль выработала целое искусство управления рисками. Однако в книге «Провал риск-менеджмента» Дуглас Хаббард указывает на ключевой пробел, характерный для всех организаций, не связанных со страховым бизнесом, — «за пределами собственно страховой деятельности отсутствует сертифицированная, регулируемая профессия, подобная актуарному делу».
Несмотря на это, любая организация может взять риски под контроль, как это делается в страховании. Как? Путем применения ПА для прогнозирования плохих событий. Для любой организации прогнозная модель выполняет, по сути, ту же функцию, что и актуарная практика для страховой компании: она оценивает людей с точки зрения вероятности негативного результата. И мы можем дать определение ПА именно с этой позиции.
Вот наше первоначальное определение:
Прогнозная аналитика (ПА) — технология обучения на опыте (данных) для прогнозирования будущего поведения людей с целью принятия оптимальных решений.
Чему на самом деле учится организация при помощи ПА, так это тому, как снизить риск через прогнозирование микрорисков. Поэтому альтернативное определение ПА таково:
Прогнозная аналитика (ПА) — технология обучения на опыте (данных) для управления микрорисками.
Оба определения правомерны, поскольку одно подразумевает другое.
Как и авантюрное предприятие, созданное в фильме «Рискованный бизнес» (1983) подростком, героем Тома Круза, любой бизнес является рискованным по определению. Как и страховые компании, все организации выигрывают от измерения и прогнозирования риска плохого поведения, такого как невозврат кредитов, прекращение контактов, уход сотрудников, аварии, мошенничество, преступления и т.д. Таким образом, ПА превращает риск в возможность.
Если брать экономику в целом, где управление рисками может быть важнее, чем в сфере ипотечного кредитования? Ипотечная отрасль, в которой обращаются триллионы долларов, является финансовым краеугольным камнем домовладения, залогом семейного процветания. Но при всей важности ипотеки именно высокорискованные субстандартные ипотечные кредиты считаются главным катализатором недавнего финансового кризиса и Великой рецессии.
Микрориски имеют значение. Оставленные без контроля, они способны нарастать, как снежный ком. Лучший метод борьбы с ними — научиться прогнозировать.
Машинное обучение
Процесс обучения на данных не так сложен, как вы могли подумать.
Начнем с простого вопроса: как проще всего научиться различать ипотечные кредиты с высоким и низким уровнем риска? Какой один-единственный фактор наиболее показателен?
Анализируя предоставленные банком Chase данные, обучающаяся система Дэна сделала следующее открытие: если процентная ставка по ипотечному кредиту ниже 7,94%, риск досрочного погашения составляет 3,8%; если выше — 19,2%.
Схематически это можно представить так:
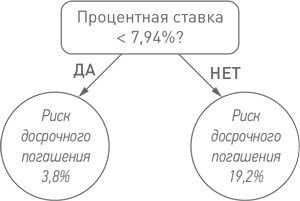
Вот это разница! Опираясь на одну только процентную ставку, мы разделили пул ипотек на две группы, одна из которых в пять раз более рискованна, чем другая, с точки зрения вероятности досрочного погашения (как уже было сказано, непредвиденная выплата клиентом всей суммы долга раньше срока лишает банк будущих доходов в виде процентных платежей).
Ценное открытие, хотя в нем нет ничего удивительного. Домовладельцы, платящие по высоким процентным ставкам, более склонны рефинансировать кредиты и продавать дома, чем платящие по более низким. Если раньше об этом подозревали, то теперь это было подтверждено эмпирически, а эффект точно измерен.
Машинное обучение сделало первый шаг.
Создание самообучающейся модели
Вы уже на полпути. Хотите верьте, хотите нет, но остался всего один шаг, прежде чем вы сможете собственными глазами увидеть суть машинного обучения — способность сгенерировать на основе данных прогнозную модель, которая будет способна учиться на примерах и станет электронным Шерлоком Холмсом, умеющим проницательно оценивать людей и предсказывать их поведение.
Вы стоите в одном шаге от одного из самых крутых достижений в науке, самой смелой человеческой мечты — автоматизации обучения.
Здесь не нужна изощренная математика или сложный компьютерный код; на самом деле остальное я могу объяснить в двух словах. Но сначала давайте воспользуемся моментом, чтобы определить стоящую перед нами научную задачу.
Установленная нами зависимость между процентной ставкой и риском позволяет создать грубую прогнозную модель. Она помещает каждый ипотечный кредит в одну из двух категорий: с высокой степенью риска и с низкой. Поскольку она учитывает только один фактор, или предикторную переменную, такая модель называется одномерной. Все примеры необычных взаимосвязей, приведенные в таблицах в предыдущей главе, относятся к числу одномерных: в каждом случае мы имеем дело с одной переменной, такой как зарплата, адрес электронной почты или кредитный рейтинг.
Но нам нужна многомерность. Почему? Очевидно, что эффективная прогнозная модель должна учитывать не один, а сразу несколько факторов. Вот в чем загвоздка. Позвольте напомнить вам определение:
Прогнозная модель — это механизм, который предсказывает поведение индивида, такое как щелчок мышью, покупка, ложь или смерть (или досрочное погашение ипотеки). Она использует в качестве входных данных характеристики конкретного индивида (переменные) и на выходе выдает прогнозную скоринговую оценку. Чем выше оценка, тем больше вероятность того, что индивид проявит прогнозируемое поведение.
Будучи разработана, прогнозная модель выдает прогнозную оценку для одного человека за один раз:
Рассмотрим ипотечного заемщика со следующими характеристиками.
Заемщик: Салли Смитерс
Ипотека: $174 000
Стоимость недвижимости: $400 000
Тип недвижимости: дом на одну семью
Процентная ставка: 8,92%
Годовой доход заемщика: $86 880
Активы (за вычетом обязательств): $102 334
Кредитная оценка: высокая
Просроченные платежи: 4
Возраст: 38 лет
Семейное положение: замужем
Образование: колледж
Продолжительность проживания по предыдущему адресу: 4 года
Род занятий: менеджер
Частный предприниматель: нет
Трудовой стаж: 3 года
Это индивидуальные характеристики, предиктивные переменные, которые вводятся в прогнозную модель. Ее задача — рассмотреть каждую из этих переменных и свести их в одну прогнозную скоринговую оценку. Назовем эту оценку новой сверхпеременной. Проще говоря, модель анализирует всю известную информацию о человеке и делает о нем один общий вывод.
Такова задача машинного обучения. Ваша же задача — запрограммировать ваш бестолковый компьютер таким образом, чтобы он обработал все имеющиеся наборы данных и автоматически создал многомерную прогнозную модель. Если это удастся, ваш компьютер научится прогнозировать.
Обучение на неудачном опыте
Жизненный опыт — это то, чем многие люди называют свои ошибки.
Моя слава росла с каждой моей неудачей.
Есть еще одно необходимое условие для машинного обучения. Успешная прогнозная модель может быть разработана только на основе горько-сладкой смеси хорошего и плохого опыта, положительных и отрицательных примеров, представленных в выборке данных. Одни ипотечные кредиты в прошлом погашались по графику, другие — досрочно. При обучении модели необходимо использовать обе эти категории данных.
Дело в том, что главный вопрос, на который мы хотим получить ответ путем прогнозирования, следующий: «Как можно заранее провести различие между положительными и отрицательными случаями?» Обучение, основанное только на прошлых положительных примерах, не будет эффективным. Важно учитывать также отрицательный опыт. Ошибки — ваши друзья.
Как работает машинное обучение
А теперь — интуитивный, элегантный ответ на, казалось бы, сложный вопрос, представляющий собой следующий шаг в обучении, совершающий переход от одномерной к многомерной прогнозной модели, учитывающей как положительные, так и отрицательные примеры: продолжайте.
К настоящему времени мы выделили две группы риска. Теперь в группе низкого риска нам необходимо найти еще один фактор, который позволит разделить ее на две подгруппы с разными уровнями риска. И затем сделать то же самое для группы высокого риска. Далее нам нужно повторить это действие в каждой подгруппе. Разделяй и властвуй, а затем властвуй еще больше, разделяя на еще более мелкие группы. Но, как мы дальше узнаем, переусердствовать с этим тоже не стоит.
Этот метод обучения, называемый деревом решений, — не единственный способ создания прогнозной модели, но он неизменно занимает первые места по популярности среди аналитиков-практиков благодаря сочетанию относительной простоты и эффективности. С его помощью не всегда можно разработать самые точные прогнозные модели, но, поскольку эти модели интуитивно понятны, в отличие от непролазных дебрей математических формул, с этого метода хорошо начинать не только знакомство с ПА, но и практически любой проект, где используется ПА.
Давайте начнем выращивать наше дерево решений. Вот что мы имеем на данный момент:

Теперь найдем предикторную переменную, которая позволит разделить представленную слева группу низкого риска на две подгруппы. В имеющемся наборе данных обучающаяся система Дэна выбрала в качестве такой переменной доход заемщика:
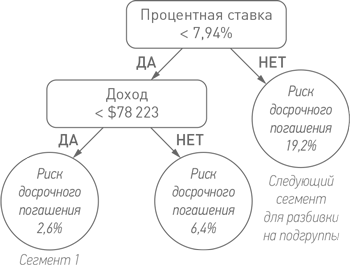
Как видите, дерево растет вниз. Любой ученый, работающий в области компьютерных наук, скажет вам, что деревья растут сверху вниз и корень находится на вершине (разумеется, если хотите, можете перевернуть книгу вверх ногами).
Мы видим, что доход ипотечного заемщика заметно влияет на уровень риска. Левый нижний листок (конечная точка на дереве), названный «Сегмент 1», соответствует подгруппе заемщиков, которые платят по процентной ставке ниже 7,94% и имеют доход ниже $78 223. Пока что среди всех выделенных нами групп это группа самого низкого риска со всего лишь 2,6%-ной вероятностью досрочного погашения.
Данные берут верх над интуитивным чутьем. Кто бы мог подумать, что люди с более низким доходом реже прибегают к досрочному погашению? В конце концов, у них обычно есть более сильный стимул рефинансировать свои ипотечные кредиты. Это трудно объяснить; возможно, причина в том, что люди с низким уровнем дохода склонны придерживаться менее активных финансовых тактик. Как всегда, мы можем только предполагать, какая причинно-следственная связь стоит за этим открытием.
Теперь перейдем к правой части дерева. В качестве основного критерия для разбивки группы высокого риска на подгруппы обучающаяся программа выбрала размер ипотечного кредита:
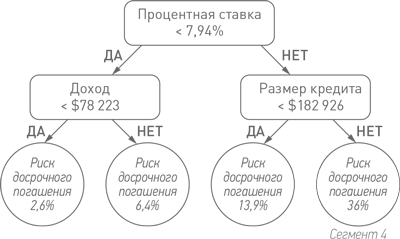
Таким образом, приняв во внимание всего два фактора, мы выделили очень рискованную группу: более крупные по размеру ипотечные кредиты с высокой процентной ставкой, для которых вероятность досрочного погашения составляет целых 36% (Сегмент 4).
Прежде чем эта модель станет еще масштабнее и приобретет еще бóльшую прогнозную силу, давайте поговорим о деревьях.
Деревья решений растут для вас
Они просты, элегантны и точны. И почти не требуют математики. Чтобы спрогнозировать поведение человека при помощи дерева решений, нужно начать с вершины (корня) и, отвечая на вопросы «да/нет», дойти до конечного листка. Этот листок и есть прогноз в отношении данного человека, выданный прогнозной моделью. Например, начните с вершины и, если ваша процентная ставка выше 7,94%, перейдите к правому сегменту. Далее, если размер вашего ипотечного кредита меньше $182 926, поверните налево. Так вы приходите к листку, который говорит, что вероятность досрочного погашения кредита для вас составляет 13,9%.
Вот, например, как вы решаете, что делать, если случайно роняете еду на пол (взято из книги «Правило 30 секунд: Дерево решений» Одри Фукуман и Энди Райта (The 30-Second Rule: A Decision Tree)). Насколько мне известно, это дерево решений не было построено на основе реальных данных:
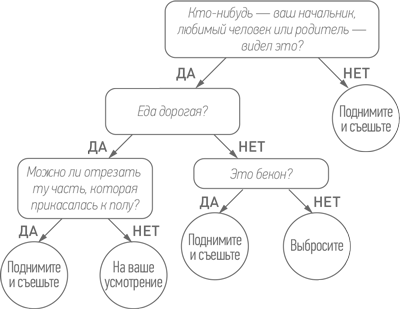
Представьте, что вы уронили на пол недорогой сэндвич в присутствии мамы. Следуя вышеприведенному дереву решений, вы можете поднять его и съесть.
Дерево решений растет на плодородной почве данных и постоянно делит группы индивидов на множество подгрупп. Поскольку данные — это запись ранее произошедших событий, по сути, процедура представляет собой пресловутое обучение на прошлом опыте. Данные определяют, какие предикторные переменные будут использованы в модели и с какими разграничительными (пороговыми) значениями (например, «доход < $78 223» в дереве решений по ипотечным заемщикам). Как и в других видах прогнозного моделирования, дерево генерируется полностью автоматически: вы загружаете данные, нажимаете на кнопку, и дерево решений начинает расти без вашего участия. Этот процесс богат на открытия, позволяя добывать из массивов сырых данных настоящее золото.
Дерево решений может применяться где угодно — в медицине, юриспруденции, астрономии, промышленности, госуправлении, бизнесе и т.д. Этот процесс обучения универсален, поскольку специализация дерева решений зависит исключительно от данных, на которых оно растет. Загрузите данные из новой области знаний, и машина вырастит вам совершенно новое дерево.
Например, одно дерево решений было обучено прогнозировать то, как проголосует по тому или иному постановлению Верховного суда США судья Сандра Дей О’Коннор. Это дерево было разработано в рамках исследовательского проекта, осуществленного четырьмя университетскими профессорами, работающими в таких областях, как политология, государственное управление и право (смотрите работу «Альтернативные подходы к прогнозированию принятия решений Верховным судом США» Андрес Мартин и др.), и основано на нескольких сотнях прошлых постановлений:
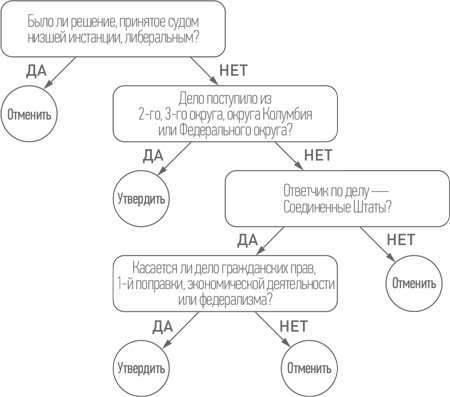
Это просто, но эффективно. Исследование показывает, что группа таких деревьев превосходит в точности прогнозирования живых экспертов. При использовании отдельного дерева решений для каждого судьи и некоторых других средств для прогнозирования того, будет ли постановление единогласным, эта «роща» деревьев предсказывает будущие постановления с точностью 75%, тогда как эксперты-правоведы, которые могут использовать всю доступную информацию по каждому делу, показывают точность не выше 59%. И снова данные одерживают победу над интуицией.
Компьютер программирует сам себя
Если вы найдете ошибку в программе и исправите ее, программа будет работать сегодня. Но если вы научите программу находить и исправлять ошибки, она будет работать вечно.
Логическая схема дерева решений аналогична простой компьютерной программе, поэтому, выращивая его, компьютер в буквальном смысле программирует сам себя. Вам хорошо знакома логическая структура дерева решений, если вы сталкивались с одной из следующих областей.
- Систематика. Иерархическая классификация видов в царстве животных является разновидностью дерева решений.
- Компьютерные программы. Дерево решений является вложенным условным оператором if-then-else (если… то… иначе…). Его также можно рассматривать как график последовательности операций без замкнутых циклов.
- Бизнес-правила. Дерево решений используется как способ кодировки серии бизнес-правил «если… то»; каждый путь от корня к листку соответствует одному правилу (или закономерности; отсюда термин выявление закономерностей в анализе данных).
- Маркетинговая сегментация. Испытанная временем сегментация существующих и потенциальных клиентов в маркетинговых целях может быть реализована в виде дерева решений. Разница в том, что традиционно маркетинговые сегменты выделяются вручную на основе интуитивных предположений маркетолога, тогда как деревья решений, генерируемые автоматически путем машинного обучения, как правило, дробят клиентскую базу на большее число меньших по размеру, но более индивидуализированных подсегментов. Это можно назвать гиперсегментацией.
- Игра «20 вопросов». Чтобы не скучать в длинной автомобильной пробке, вы задумываете какой-нибудь предмет, а ваш собеседник пытается угадать его, сужая круг возможностей наводящими вопросами (не более 20), предполагающими ответ «да/нет». Процесс угадывания слова можно представить в виде дерева решений. На самом деле, когда вы играете с компьютером в игру «Угадай диктатора или телеперсонаж» на сайте www.smalltime.com/Dictator, если после серии вопросов компьютер не может прийти к ответу, он говорит «Я сдаюсь» и просит вас сообщить имя задуманного вами человека или персонажа и указать новый вопрос (новую переменную) для его идентификации, благодаря чему он расширяет свое дерево решений. На моем первом компьютере, купленном в 1980 году, имелась похожая игра («Animal» на Apple II+). Компьютер хранил свое дерево решений на гибкой 5¼-дюймовой дискете.
Ученье — свет
Старые статистики никогда не умирают; они просто разделяются на сегменты по половому и возрастному признаку.
Давайте продолжим выращивать дерево решений для банка Chase. Это самая увлекательная часть — нажать кнопку «Go»; по остроте ощущений это сродни тому, как вдавить в пол педаль газа, впервые сев за руль автомобиля. В вашем распоряжении ощутимый источник силы: данные и возможность добыть из них знания. Этот процесс, когда дерево решений растет вниз, разветвляясь на все более мелкие, но более конкретные и точно определенные подсегменты, похож на работу соковыжималки, которая постепенно выдавливает ценный сок знаний из сырых данных. Если в поведении людей есть какие-либо скрытые закономерности, они не останутся незамеченными и обязательно будут «выдавлены» на поверхность.
Но прежде чем приступать к моделированию, данные необходимо надлежащим образом подготовить, чтобы получить доступ к их прогнозному потенциалу. Как и любое сырье перед обработкой, сырые данные требуют некоторых усилий, чтобы превратить их в обучающие данные (или тренировочные данные). Данные следует организовать таким образом, чтобы два временных интервала были наложены друг на друга: 1) данные, известные нам в прошлом, и 2) результат, который мы хотели бы предсказать и который впоследствии получили. Это все относится к прошлому (прошлый опыт, на котором будет учиться машина), но соотнесение и соединение этих двух различных точек во времени является важнейшим шагом, необходимым условием, делающим обучение прогнозированию возможным. Этот этап подготовки данных может быть довольно утомительным; сопряженный с ним технический процесс часто оказывается более трудоемким, чем предполагалось, но эти усилия будут с лихвой вознаграждены.
Заправленная мощным топливом подготовленных обучающих данных, ПА-машина готова к работе. «Если бы стены могли говорить…» На самом деле они могут. Машинное обучение является универсальным переводчиком, который поможет заговорить любым данным.
Вот как выглядит дерево решений по ипотечным кредитам после нескольких этапов обучения (на этой схеме не указаны ответы «да/нет»; по умолчанию «да» означает переход влево, «нет» — переход вправо):
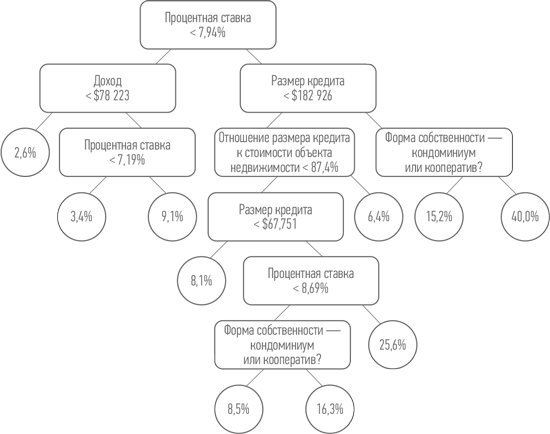
Процесс обучения выделил 10 различных сегментов (листьев дерева) с уровнями риска, варьирующимися от 2,6 до 40%. Столь значительный разрыв означает, что машинное обучение сработало. Были успешно выделены группы, которые в существенной степени отличаются друг от друга по степени вероятности наступления прогнозируемого исхода — досрочного погашения кредита. Таким образом, машина научилась оценивать вероятность будущих событий.
Чтобы предсказать его поведение, индивид должен скатиться по дереву решений сверху вниз, как шарик в патинко, проходя через лабиринт шлюзов и отклоняясь то влево, то вправо. Например, вот какой путь пройдет Салли Смитерс, гипотетический ипотечный заемщик, рассмотренный нами ранее в этой главе:
Вопрос: Процентная ставка < 7,94%?
Ответ: Нет, идите направо.
Вопрос: Размер кредита < $182 926?
Ответ: Да, идите налево.
Вопрос: Отношение размера кредита к стоимости объекта недвижимости < 87,4%?
Ответ: Да, идите налево (размер кредита составляет менее 87,4% от стоимости недвижимости).
Вопрос: Размер кредита < $67 751?
Ответ: Нет, идите направо.
Вопрос: Процентная ставка < 8,69%?
Ответ: Нет, идите направо.
Таким образом, Салли приземляется в сегменте с 25,6%-ной вероятностью. Поскольку средний риск по всему пулу заемщиков составляет 9,4%, эта оценка говорит о том, что вероятность досрочного погашения кредита этим заемщиком относительно высока.
Каждый маршрут от корня дерева к листьям соответствует определенному бизнес-правилу. Например, маршрут, по которому прошла Салли, позволяет вывести правило, которое будет применимо к ней и множеству других домовладельцев с похожими характеристиками (хотя весь маршрут состоит из пяти шагов, само правило можно свести к меньшему количеству строк, поскольку некоторые шаги опираются на одну и ту же переменную):

Чем больше, тем лучше
Если продолжить процесс обучения, мы получим еще более разветвленное дерево решений с 39 сегментами (листьями), которое выглядит следующим образом:
По мере того, как дерево решений становится все больше и сложнее, растет и его прогнозная эффективность, хотя и более медленно, по принципу убывающей отдачи.
Для сравнения эффективности различных прогнозных моделей используется такая общепринятая метрика, как лифт-показатель (lift). Он является своего рода прогнозным коэффициентом. Например, он говорит нам, во сколько раз больше целевых клиентов может быть выявлено при помощи модели, чем без нее.
Подумайте о ценности прогнозирования с точки зрения банка. Каждое досрочное погашение ипотечного кредита означает потерю прибыльного клиента. В более широком смысле это называется уходом или оттоком клиентов. Прогнозирование того, кто из них может уйти, помогает более точно нацелить маркетинговые усилия, направленные на удержание клиентов. Поскольку соответствующие предложения, призванные удержать клиентов, стоят довольно дорого, возможность нацелить их на четко определенную группу риска, вместо того чтобы охватывать ими всю клиентскую базу, дает банку весомое преимущество.
Применение ПА: удержание клиентов через прогнозирование их ухода
- Предмет прогнозирования: какие клиенты могут уйти.
- Цель прогнозирования: нацелить маркетинговые усилия по удержанию клиентов на выявленные группы риска.
Предположим, банк может потерять 10% своих ипотечных заемщиков. Без прогнозной модели единственный способ охватить их всех — это связаться с каждым. Если, что более реалистично, маркетинговый бюджет позволяет направить предложения хотя бы одному из пяти заемщиков, которые при отсутствии модели выбираются произвольно, в этом случае банку удастся в среднем охватить всего лишь каждого пятого клиента из группы риска. Конечно, прогнозная модель — не магический хрустальный шар, который по именам перечислит вам всех готовых уйти клиентов, но при разумном уровне точности она может существенно повысить эффективность маркетинга.
Точнее говоря, она может повысить эффективность маркетинга в три раза. Так, если взять вышеприведенную прогнозную модель на основе полноразмерного дерева решений, то 20% клиентов, получающих самые высокие баллы с точки зрения риска досрочного погашения, включают в себя 60% всех потенциально нелояльных клиентов. Это на 300% больше, чем без модели, поэтому мы говорим, что лифт-показатель данной модели равен трем на отметке 20%. Таким образом, теперь при том же маркетинговом бюджете банк может попытаться удержать в три раза больше клиентов, чем прежде, — т.е. получить в три раза бóльшую отдачу на свои маркетинговые инвестиции.
Каждая из рассмотренных нами выше моделей имеет разный лифт-показатель на 20%-ной отметке:

Если по мере роста дерево решений становится все лучше и лучше, зачем останавливаться на достигнутом? Нужно двигаться дальше!
Не взлетай чересчур высоко, Икар! У меня плохие предчувствия.
Избыточное обучение: не стоит злоупотреблять прогнозированием
Если пытать данные достаточно долго, они обязательно в чем-нибудь признаются.
Есть три вида лжи: ложь, наглая ложь и статистика.
Неограниченные вычислительные ресурсы подобны динамиту: при правильном использовании они могут свернуть горы, при неправильном — пустить по ветру ваш инвестиционный портфель.
Несколько лет назад профессор из Калифорнийского университета в Беркли Дэвид Лейнвебер произвел фурор своим якобы сенсационным открытием, согласно которому значение индекса S&P 500 по итогам года в период с 1983 по 1993 год могло быть спрогнозировано на основе объемов производства сливочного масла в Бангладеш, так как этот экономический показатель математически объясняет 75% колебаний индекса на этом временном интервале. Тут же начали раздаваться скептические возгласы, поскольку, разумеется, трудно было поверить в то, что молочная промышленность этой азиатской страны может быть тесно связана с американским фондовым рынком. Разве можно разумно предположить, что бум или спад в производстве бангладешцами масла в любом отдельно взятом году может привести к аналогичному поведению американских акций? Скептики и противники ПА так энергично выражали свое негодование, что профессор Лейнвебер был вынужден появиться на национальном телевидении.
Сумасшедший ученый или просветитель? Оказывается, это «сенсационное открытие» Лейнвебер сделал в качестве шутливой иллюстрации к главе «К чему может привести глупый анализ данных» в своей книге «Фанаты цифр на Уолл-стрит» (Nerds on Wall Street). Лейнвебер просто хотел продемонстрировать распространенную ошибку путем доведения ее до абсурда. Очень легко найти смешные корреляции, особенно когда вы прогнозируете всего 11 точек данных (годовые значения закрытия индекса с 1983 по 1993 год). Если изучить большое количество всевозможных финансовых показателей по разным странам, среди них непременно отыщутся такие, которые — по чистому совпадению — покажут аналогичную динамику. Например, одно исследование показало, что объемы найденных кладов в Англии и Уэльсе в период с 1992 по 2002 год предсказывали динамику индекса Dow Jones Industrial Average на целый год вперед!
Прогнозное моделирование может усугубить эту проблему. Если вы не увидите, как один фактор затеняет другой, а примените вместо этого динамику машинного обучения для создания модели, которая сочетает все факторы, корреляция может показаться еще более совершенной. Любимый довод скептиков: «Если ваша регрессионная модель становится лучше от добавления всякой посторонней ерунды типа значений дневной температуры — что можно сказать о таком анализе?» Лейнвебер добился 99%-ной точности прогнозирования значений закрытия S&P 500, используя для своей регрессионной модели не только объемы производства сливочного масла, но и поголовье овец в Бангладеш, а также производство масла и сыра в США. Как аналитик, страдающий лактозной недостаточностью, я протестую!
Лейнвебер привлек искомое внимание, но его урок, кажется, прошел даром. «В течение нескольких лет после этого мне продолжали звонить люди и спрашивать по поводу текущей ситуации с производством масла в Бангладеш. И я все время отвечал: “Это была шутка! Просто шутка!” Меня пугает, как мало людей на самом деле поняли суть дела». Как написал Нассим Талеб, автор «Черного лебедя», в своей книге «Одураченные случайностью»: «Нигде проблема индукции так не уместна, как в трейдинге, — и нигде не игнорируется больше всего, как там!» Вот почему время от времени мы можем слышать серьезные заявления не в меру ретивых экспертов о том, что они научились составлять экономические прогнозы на основе таких факторов, как длина женских юбок, ширина мужских галстуков, результаты Суперкубка и снегопад на Рождество в Бостоне.
Виновником подрыва эффективности обучения является избыточное обучение (или сверхподгонка модели). Ловушка избыточного обучения заключается в том, что шум в данных принимается за информацию и из них извлекается слишком много «знаний». Другими словами, в погоне за призрачной точностью вы сбиваетесь с истинного пути.
Деревья решений особенно подвержены этой болезни. Очевидное искушение — продолжить выращивать дерево дальше и дальше до тех пор, пока каждый листок не сузится до одного индивида в обучающей выборке данных. В конце концов любой маршрут от корня до листка, какое бы большое количество переменных он ни включал, может дойти только до уровня индивида, не дальше. Но правило, отражаемое таким маршрутом, не будет общим; оно будет применимо только к этому единичному случаю. В логике такая ошибка рассуждения называется ложным обобщением. По сути, это разветвленное дерево решений в точности запомнит весь массив данных — вы просто запишете их в другой форме.
Однако механическое запоминание есть противоположность настоящему обучению. Предположим, что вы — преподаватель, который дает своим студентам образцы экзаменационных заданий за последние несколько лет, чтобы помочь им подготовиться к выпускным экзаменам.
Если студент просто вызубрит ответ на каждый вопрос из прошлых экзаменационных билетов, фактически он ничему не научится и вряд ли сможет справиться с новыми вопросами, ожидающими его на экзамене в этом году. Наша обучающаяся модель не должна брать пример с такого студента.
Но, даже если не ударяться в крайности, нахождение правильного баланса между достаточным и избыточным обучением — непростая задача. При разработке любой прогнозной модели всегда возникает ключевой вопрос: являются ли выделенные ею закономерности общими для всей совокупности данных или же они верны только для обучающего набора данных? Как мы можем быть уверены в том, что модель будет работать завтра, если она предназначена генерировать прогнозы при уникальных условиях, которые никогда не возникали прежде?
Парадокс индукции
Следует признать, что индуктивные умозаключения характеризуются гораздо более высокой степенью сложности, чем любые дедуктивные операции.
Чтобы понять мысли Бога, мы должны изучать статистику, ибо это есть мера его намерения.
Если это и безумие, то в нем есть система.
Жизнь была бы намного проще, если бы у нас имелся исходный код.
Целью машинного обучения является индукция.
Индукция — процесс логического вывода на основе перехода от частных фактов к общим принципам.
Индукцию не следует путать с дедукцией, которая, по сути, представляет собой прямо противоположный подход:
Дедукция — процесс логического вывода на основе перехода от общего к частному (или от причины к следствию).
Дедукция гораздо проще индукции. Это просто применение известных правил. Если все люди смертны и Сократ человек, то дедукция говорит нам, что Сократ тоже смертен.
Индукция — это своего рода искусство. В нашем распоряжении имеется подробное описание внешних проявлений того, как функционирует этот мир: данные, фиксирующие все происходящее. Опираясь на них, мы стремимся вывести общие правила и закономерности, которые будут оставаться верными даже в тех ситуациях, которые еще не никогда случались. Мы пытаемся посредством обратного инжиниринга воссоздать законы и принципы мироздания. Это поиск системы в безумии.
Хотя индукция и является формой логического вывода, она предполагает некоторый отказ от логики. Дело в том, что индукция опирается на чрезмерно упрощенные предположения. Такие предположения являются ключом к тому индуктивному прыжку, который нам необходимо совершить. Без них разработка методов машинного обучения была бы невозможна. У нас нет достаточных знаний о том, как устроен этот мир, чтобы разработать один идеальный метод обучения. Начать с того, что, если бы у нас были такие знания, нам бы не потребовалось машинное обучение. Например, в основе дерева решений лежит подразумеваемое предположение, что правила, по которым это дерево строится, сколь бы просты они ни были, достаточно эффективны для того, чтобы выявить истинные закономерности.
Профессор Том Митчелл из Университета Карнеги–Меллон, основатель первой в мире кафедры машинного обучения и автор первого учебника по этому предмету, называет этот вид предположений индуктивным смещением (inductive bias). Установление таких фундаментальных предположений, являющееся неотъемлемой частью изобретения новых индукционных методов, и есть искусство, стоящее за машинным обучением. Не существует единственно верного решения, единственного метода обучения, который работал бы лучше других на всем множестве задач. Все зависит от данных.
Между индукцией и рождением есть нечто общее. В обоих случаях на свет появляется что-то новое.
Искусство и наука машинного обучения
Моделирование есть постепенное изменение модели.
Через тонкую настройку хитроумного механизма ты доводишь ее до совершенства.
Каждый твой шаг улучшает точность прогнозирования на обучающих данных.
Один маленький шаг для человека, но гигантский скачок для всего человечества!
Хотя этот рэперский стих и нелогичен, я надеюсь, что он педагогичен.
ПА — моя любовь на всю жизнь, и я буду верен ей до тех пор, пока ты не поцелуешь лягушку, которая превратится в принцессу.
Методы моделирования различаются, но все они сталкиваются с одной ключевой проблемой: научиться как можно бóльшему, но при этом не переучиться. Среди многочисленных подходов к машинному обучению дерево решений часто считается наиболее дружественным к пользователю, поскольку состоит из правил, которые вы можете прочитать как длинное (пусть и громоздкое) предложение, тогда как другие методы являются больше математическими, они берут переменные и встраивают их в уравнения.
Большинство методов обучения нацелены на поиск хорошей прогнозной модели. Они начинают с тривиально простой и часто неумелой модели и путем многократных настроек, своего рода «генетических мутаций», превращают ее в надежный аппарат прогнозирования. В случае дерева решений процесс стартует с небольшого дерева, которое затем выращивается до нужного размера. Большинство математических методов на основе уравнений начинают со стохастической модели со случайно выбранными параметрами, а затем многократно корректируют их, пока уравнение не начинает генерировать точные прогнозы. Во всех методах обучения каждая настройка модели определяется спецификой обучающих данных, поскольку задача модели — прежде всего научиться хорошо прогнозировать в рамках этого набора данных. Среди математических методов моделирования, конкурирующих с деревом решений, можно назвать искусственные нейронные сети, логлинейную регрессию, машину опорных векторов и алгоритм TreeNet.
Способность машинного обучения к непрерывной, ни перед чем не останавливающейся адаптации поражает своей фантастической мощью. Оно выискивает и использует всё — даже уязвимости и лазейки, по неосторожности оставленные аналитиками. В одном проекте мы с моим близким другом Алексом Чаффи (талантливейшим архитектором программного обеспечения) дали компьютеру задание создать совершенного игрока в «Тетрис» через обучение тому, как в процессе игры выбрать наилучшее место для каждой очередной детали. Прогоняя как-то раз систему, мы случайно изменили задачу на обратную (один поставленный по ошибке знак минус вместо знака плюс среди тысяч строк компьютерного кода!), поэтому вместо того, чтобы стараться уложить детали как можно плотнее, компьютер начал укладывать их как можно менее плотно, оставляя большие пустые пространства между ними. Прежде чем мы с Алексом осознали, что причиной была ошибка в программе, мы с недоумением взирали на то, как компьютер прилежно выстраивает детали по диагонали из левого нижнего угла игрового поля в правый верхний, демонстрируя весьма творческий способ играть как можно хуже. На память приходит проницательная фраза ученого Яна Малькольма из фантастического триллера Майкла Крайтона «Парк юрского периода»: «Жизнь пробьется через любые преграды».
Независимо от метода обучения и его математической сложности всегда существует опасность избыточного обучения. В конце концов, приказать компьютеру учиться — все равно что пытаться научить обезьяну с завязанными глазами разрабатывать новые фасоны модных платьев. Компьютер не знает ничего. Он не имеет ни малейшего представления о том, что означают данные, что такое ипотека, зарплата или дом. Цифры — это просто цифры. Даже такие символы, как «$» или «%», ничего не значат для машины. Это слепой, безмозглый автомат, засунутый в коробку, который приходится всегда и всему учить с самых азов.
Любая попытка прогнозного моделирования сталкивается с главной задачей — выделить общие принципы и отсеять шум, признаки, свойственные только имеющемуся набору данных. Такова природа проблемы. Даже если выборка данных, на которых проходит обучение, содержит миллионы или миллиарды примеров, все равно она ограничена по сравнению с тем колоссальным многообразием ситуаций, которые могут возникнуть в будущем. Количество возможных комбинаций, которые могут формировать обучающий пример, увеличивается по экспоненте. Вот почему выстраивание процесса обучения, способного самостоятельно найти золотую середину между недостаточным и избыточным обучением, остается ускользающей и непостижимой задачей даже для самых настойчивых ученых умов.
При решении этой головоломки искусство важнее науки, хотя то и другое играет критически важную роль. Искусство делает возможным, а наука на практике подтверждает, что это работает.
- Искусство в разработке: чтобы предотвратить избыточное обучение, исследователи часто призывают на помощь все свои творческие способности и придумывают поистине блестящие идеи.
- Научное измерение: эффективность прогнозных моделей подвергается объективной оценке.
Но что касается второго пункта, какой метод оценки будет достаточным? Если мы не можем полностью доверять механизму машинного обучения, как мы можем доверять оценке его эффективности? Разумеется, точность любого прогноза можно оценить, просто дождавшись того момента, когда он сбудется или нет. Но, когда вы прогнозируете на несколько месяцев вперед, такой подход непрактичен, так как занимает слишком много времени. Нам нужен почти мгновенный способ оценки работоспособности модели, чтобы в случае избыточного обучения можно было немедленно узнать об этом и скорректировать обучение, вернувшись назад и попробовав еще раз.
Подтверждение: тестовые данные
Все доказательство — в самом пудинге.
Для тестирования прогнозной модели не нужно залезать в математические дебри. Не поймите меня неправильно: некоторые пытаются. Их теоретических трудов хватит на целую библиотеку, и эти фанатичные мыслители недавно провели свою 25-ю ежегодную Конференцию по теории машинного обучения. Но результаты на сегодняшний день весьма ограничены. Все попытки разработать метод машинного обучения, который был бы гарантированно защищен от избыточного обучения, терпят крах. Это действительно сложная научная проблема. Вполне возможно, что неразрешимая.
Что же касается практиков, то для тестирования модели на предмет избыточного обучения они используют на удивление простой, но гениальный способ — разделить случайным образом весь имеющийся массив данных на две части. Одну часть, называемую обучающей выборкой, использовать для создания модели. Другую часть, называемую тестовой выборкой (или валидационной, или контрольной выборкой), отложить в сторону и использовать для тестирования модели. Поскольку тестовая выборка не используется при создании модели, модель никоим образом не может отражать присущих ей специфических странностей или искажений — у нее просто нет возможности о них узнать. Следовательно, то, насколько хорошо модель работает на тестовой выборке, является разумно надежным показателем того, насколько хорошо модель работает в целом, т.е. показателем ее прогнозной эффективности. Используемая для тестирования выборка данных называется независимой.

Никакой математической теории, никакой передовой науки, просто элегантное практическое решение. Именно так это всегда и делается. Это стандартная практика. Все инструментальные программные средства, используемые для прогнозного моделирования, имеют встроенную процедуру выделения тестовой выборки данных и последующего тестирования модели. И все публикуемые отчеты об исследованиях сообщают о работоспособности модели на тестовой выборке данных (разумеется, если только вы не преследуете цель высмеять вопиющие ошибки отраслевых экспертов на примере шуточной корреляции между производством масла в Бангладеш и американским фондовым рынком).
У этого подхода есть один недостаток. Вы жертвуете возможностью использовать для обучения весь имеющийся массив данных, создавая модель на основе обучающей выборки, частично урезанной. Как правило, на тестовую выборку выделяется 20–30% от общего объема данных. Тем не менее обучающая выборка в большинстве случаев остается достаточно большой, и такую жертву можно рассматривать как незначительную плату за возможность проверить работоспособность модели.
Следуя этой практике, давайте посмотрим на результаты тестирования деревьев решений, рассмотренных нами ранее в этой главе. Напомним, что так называемый лифт-показатель (мера эффективности прогнозной модели) для обучающей выборки из 21 816 примеров имел следующие значения:

Как показало тестирование на независимой выборке из 5486 примеров, избыточного обучения не произошло. Все три модели подтвердили свои результаты. Это успех!

Если продолжить разрабатывать это дерево решений, мы рискуем перейти грань. По мере того как дерево становится все больше и больше, разветвляясь на массу все более мелких сегментов, может наступить переобучение. Мы намеренно постарались довести дело до крайности и создали дерево с 638 сегментами (т.е. конечными точками, или листьями). Лифт-показатель на обучающей выборке для этого дерева был самым высоким и составил 3,8. Однако такая оценка прогнозной эффективности модели является смещенной. Тестирование этого огромного дерева решений на тестовой выборке дало лифт-показатель на уровне 2,4, т.е. ниже, чем у самого маленького дерева с четырьмя сегментами.

Тестовые данные руководят обучением, позволяя определить, когда оно сработало успешно, а когда зашло слишком далеко.
Как создается произведение искусства
В каждом куске мрамора я вижу статую так ясно, как будто она стоит передо мной. Мне остается только отсечь грубые края, которые скрывают прекрасное видение, чтобы обнаружить его для других.
Все должно быть сделано настолько просто, насколько возможно, но не проще.
Дерево решений не принесет плодов, если не сдержать его буйный рост. Как это сделать, трудный вопрос. Как добросовестный родитель, мы должны структурировать рост и развитие нашего детища таким образом, чтобы оно не вышло из-под контроля, но в то же время не лишилось творческого потенциала. Где именно провести черту?
Метод дерева решений впервые привлек к себе внимание в начале 1960-х годов, но потерпел громкое фиаско, подвергшись всеобщему осмеянию за свою подверженность избыточному обучению. «Его называли “способом научиться тому, что не работает”, — говорит Дэн Стейнберг. — Это был смертный приговор. С деревьями решений было покончено, как с рестораном, где обнаружили кишечную палочку».
Тем не менее некоторые исследователи не опустили руки и поставили перед собой цель формально определить черту между достаточным и избыточным обучением. Это оказалось невероятно сложной задачей, поскольку, где бы вы ни провели эту черту, казалось, всегда существует риск того, что обучение зашло либо недостаточно далеко, либо слишком далеко. Это была упорная, но безрезультатная борьба. Драматическое напряжение росло.
Как и в театре, ослабить напряжение помогает смех. Наиболее эффективное решение этой проблемы оказалось довольно смешным. Вместо того чтобы стараться сдержать рост дерева в попытке избежать избыточного обучения, не нужно ограничивать его рост вообще. Нужно пройти весь путь до конца — научиться слишком многому… а затем пойти в обратном направлении, шаг за шагом отсекая избыточные ветви знаний до тех пор, пока заветная черта достаточного знания не будет пройдена в обратном направлении. Не бойтесь совершать ошибки! Почему? Потому что ошибки становятся очевидными только после того, как вы их совершили.
Одним словом, вырастите дерево слишком большим и разветвленным, а затем обрежьте его. Хитрость состоит в том, что обрезка дерева производится не на основе обучающих данных, которые обусловили его рост, а на основе тестовых данных, показывающих, где рост сбился с правильного пути. Это невероятно простое и красивое решение позволяет найти тот самый трудноуловимый баланс между недостаточным и избыточным обучением.
Обрезая дерево решений, вы возвращаетесь по собственным следам и отменяете те настройки, сделанные в процессе машинного обучения, которые оказались ошибочными. В результате на свет появляется сбалансированная модель, не боязливо ограниченная, но в то же время и не страдающая чрезмерной самоуверенностью. Подобному тому, как великий Микеланджело создавал статуи, отсекая все лишнее от глыб мрамора, так и мы создаем эффективную прогнозную модель путем отсечения лишних знаний.
При построении прогнозной модели легко пойти в неправильном направлении. Важно, чтобы такие шаги были отменены. На учебном семинаре, который я веду, практиканты разрабатывают прогнозные модели вручную, методом проб и ошибок. Когда они пробуют внести изменение, которое, как оказывается на поверку, больше вредит модели, чем улучшает ее, я слышу, как они восклицают: «Возвращаемся назад! Мы должны вернуться назад!»
Чтобы проиллюстрировать эту идею, ниже представлен график улучшения дерева решений в процессе обучения:
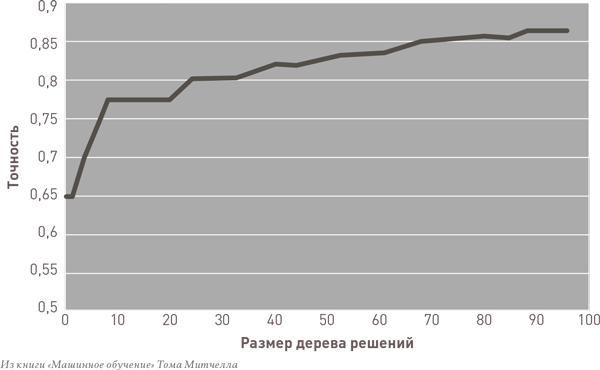
Как видно на графике, вместе с ростом дерева точность — измеряемая на основе обучающих данных, используемых для его построения, — продолжает улучшаться. Но если в процессе роста тестировать модель на независимой тестовой выборке данных, мы видим, что точность модели достигает пика на ранней стадии, после чего дальнейший рост ведет к избыточному обучению, что только вредит ее прогнозной способности:
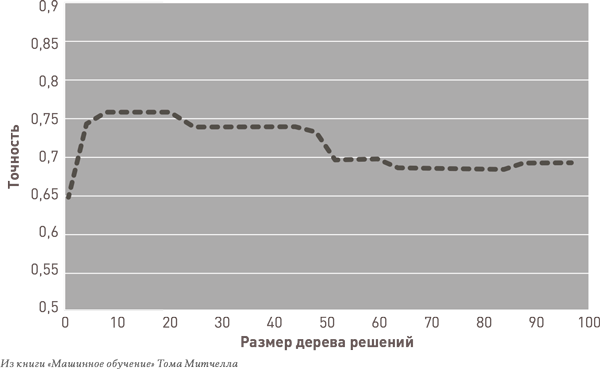
Не давая разрастаться буйной и бесполезной кроне, мы следуем известному методологическому принципу «бритва Оккама», который в кратком виде гласит: «Не следует множить сущее без необходимости». Ищите самое простое объяснение доступных данных. Чем элементарнее модель, тем она лучше. Эта тактика частично определяет индуктивное смещение, намеренно положенное в основу деревьев решений. Это то, что заставляет их работать. Если вы заботитесь о вашей модели, скажите ей: «Будь как можно проще, глупышка!»
Популярный метод построения деревьев решений CART (Classification and Regression Trees) — Деревья классификации и регрессии — использует именно вышеописанный элегантный подход отсечения всего лишнего плюс множество дополнительных наворотов. Метод CART был разработан четырьмя легендарными исследователями из Калифорнийского университета в Беркли и Стэнфордского университета Лео Брейманом, Джеромом Фридманом, Чарльзом Стоуном и Ричардом Олшеном, которых я называю «великолепной четверкой», и был впервые описан в книге с одноименным названием, вышедшей в 1984 году. Как это обычно бывает с другими крупными изобретениями наподобие телевидения и самолета, публикация повлекла за собой поток альтернативных идей, включая алгоритм ID3, предложенный исследователями из Австралии, и алгоритм CHAID, разработанный исследователями из Южной Африки. Между тем метод CART остается наиболее популярным, и программные средства в области ПА от таких производителей, как IBM и StatSoft, включают разновидности этого алгоритма. Компания Дэна Стейнберга Salford Systems продает единственный продукт под названием CART, разработанный совместно с «великолепной четверкой», члены которой также являются ее инвесторами.
Ученый-предприниматель Дэн Стейнберг заслужил доверие «великолепной четверки», которая вверила ему перевод технологии CART из их исследовательской лаборатории в коммерческий мир. Дэн — выходец из Гарварда, получивший докторскую степень по эконометрике. Чтобы не ставить телегу впереди лошади, он основал свою компанию вскоре после изобретения вышеуказанной технологии.
Подтверждение достоверности методов машинного обучения, таких как CART, — главная новость сегодняшнего дня: «Человеческая интуиция достигает поразительных успехов». Тот факт, что машинное обучение работает, свидетельствует, что мы, люди, достаточно умны — наши догадки и интуиция, на которые опирается разработка методов обучения, оправдывают себя. Я называю это «эффектом индукции».
| Эффект индукции: машинным обучением движет искусство. Стратегии, частично являющиеся продуктом неформальной человеческой творческой мысли, будучи оформлены в виде компьютерных программ, дают успешные результаты при разработке эффективных прогностических моделей, хорошо показывающих себя на новых случаях. |
Деревья решений на службе у Chase
Дэн согласился помочь с прогнозированием подразделению ипотечного кредитования банка Chase (в рамках совместных усилий с одной крупной консалтинговой фирмой), и проект стартовал. Он сформировал небольшую группу ученых, которая должна была применить технологию CART к ипотечным данным банка.
Однако Chase намеревался использовать результаты прогнозирования с другой целью, нежели обычно. Обычно компании прогнозируют вероятность ухода клиентов (или, если речь идет об ипотечных заемщиках, вероятность досрочного погашения), чтобы нацелить на них соответствующие маркетинговые усилия и убедить остаться.
Chase же собирался извлечь из прогнозирования ухода клиентов выгоду совершенно иного рода. Банк хотел использовать эти прогнозы для оценки ожидаемой будущей стоимости отдельных ипотечных кредитов, чтобы решить, следует продать их другим банкам или нет. Банки свободно торгуют между собой ипотечными кредитами. Кредит может быть продан в любой момент по текущей рыночной цене, которая определяется его профилем. Но, поскольку рынок в целом не имеет доступа к таким прогнозным моделям, у Chase появлялось весомое преимущество. Он мог оценить будущую стоимость кредита на основе спрогнозированной вероятности досрочного погашения. Другими словами — рассчитать, не заработает ли он больше, если продаст кредит сейчас вместо того, чтобы оставить его на балансе.
Применение ПА: оценка будущей стоимости ипотечных кредитов
- Предмет прогнозирования: кто из держателей ипотечных кредитов может досрочно погасить кредит в течение ближайших 90 дней.
- Цель прогнозирования: оценка будущей стоимости ипотечных кредитов для принятия решений об их удержании или продаже другим банкам.
Использование прогнозов позволяло существенно повысить эффективность таких решений — и отдачу от них, учитывая, что Chase управлял портфелем с миллионами ипотечных кредитов.
Применение ПА обещало Chase огромное конкурентное преимущество на рынке ипотечного кредитования. Тогда как рыночная цена на кредит определяется всего несколькими факторами, модель CART учитывает намного больше переменных и, следовательно, позволяет гораздо точнее предсказать будущую стоимость каждого кредита.
Короче говоря, прогнозирование превращает риск в возможность. Ипотечный кредит с высокой вероятностью досрочного погашения перестает быть плохой новостью, когда об этом риске становится известно. Выставляя такой кредит на продажу, Chase склоняет чащу весов в свою пользу.
Поскольку портфель банка включал миллионы ипотечных кредитов, размер доступных для анализа данных намного превышал ту обучающую выборку из 22 000 примеров, которая была использована для построения иллюстративных деревьев решений в этой главе. Более того, для каждого ипотечного кредита на самом деле были доступны сотни предикторных переменных, характеризующих его в мельчайших подробностях, в том числе полная история платежей, данные о районе, где находится жилье, и масса другой информации о заемщике. В результате проект потребовал 200 гигабайт памяти. Если сегодня такой объем памяти можно купить за 30 баксов и положить его в карман, то в конце 1990-х годов это стоило порядка 250 000 долларов, а сам накопитель был размером с большой холодильник.
Проект Chase потребовал разработки множества моделей, каждая из которых специализировалась на отдельно взятой категории ипотечных кредитов. Команда Дэна вырастила деревья CART отдельно для кредитов с фиксированной и плавающей ставками, а также для кредитов с разными сроками погашения и сроками владения недвижимостью. Поскольку деревья решений обращались к разным ситуациям, они значительно разнились между собой по набору используемых переменных и их трактовке. В конечном итоге весь этот эклектичный набор деревьев решений был передан для интеграции в системы банка.
Деньги растут на деревьях
Предприятие имело ошеломительный успех. Близкие к проекту люди из Chase сообщили, что прогнозные модели принесли банку дополнительные $600 млн прибыли в течение первого года после внедрения (с поправкой на инфляцию сегодня это более $800 млн). Модели правильно выявляли 74% всех кредитов, которые ожидала участь досрочного погашения, и существенно повысили эффективность управления ипотечным портфелем.
Наряду с весомой финансовой отдачей этот успех укрепил репутацию Chase как ведущего банковского института. В целях продвижения бренда банк выпустил серию пресс-релизов, в которых рекламировал свою компетентность в области прогнозной аналитики.
Вскоре после запуска проекта, в 2000 году, Chase предпринял еще один колоссальный шаг на пути к расширению. Он сумел приобрести инвестиционный банк JPMorgan, таким образом сменив название на JPMorgan Chase и став крупнейшим в США банком по размеру активов.
Рецессия в экономике, или Почему микроскопы не могут обнаружить астероиды
Вряд ли стоит говорить, что прогнозная аналитика не сумела предотвратить мировой финансовый кризис, который начался ближе к концу прошлого десятилетия. Но это и не ее задача. Применяемая для предотвращения микрорисков, ПА способна оказать серьезное влияние. Но предсказание макроскопических рисков — игра совершенно иного уровня. ПА предназначена для того, чтобы ранжировать отдельных людей на основе относительного риска, а не чтобы измерять абсолютные риски в условиях грядущих экономических перемен. Прогнозная модель работает на переменных, касающихся конкретного человека, таких как возраст, образование, история платежей и тип недвижимости. Эти факторы не меняются, даже если вокруг этого человека меняется весь мир, поэтому прогнозная скоринговая оценка для него остается прежней.
Прогнозирование макрориска — трудная задача, по сложности намного превосходящая предсказание микрорисков. Здесь действует огромное многообразие факторов, в том числе нематериальных и человеческих. Журналист The New York Times Сол Ханселл метко заметил: «Финансовые компании сознательно программировали свои системы управления рисками, исходя из чрезмерно оптимистичных предположений… У топ-менеджеров банков Уолл-стрит имелись весомые стимулы к тому, чтобы их системы оценки рисков не видели слишком много риска». Профессор Барт Баезенс из Центра исследований риска при Университете Саутгемптона добавляет: «Существует непреодолимое противоречие между консервативными инстинктами и мотивами получить побольше прибыли». Если мы не измеряем и не оцениваем истинное положение дел, никакая аналитика тут не поможет.
Экономическая теория предпринимает попытки прогнозировать макроскопические события, но такая работа обычно осуществляется не в рамках прогнозной аналитики. Хотя, как утверждает Баезенс, «включение в прогнозную модель макроэкономических факторов дает нам возможность выполнить ряд управляемых данными стресс-тестов». Прогнозирование глобальных тенденций в экономике требует совершенно другого набора переменных и совершенно другого аналитического подхода, поскольку у нас нет обучающей выборки данных, содержащей достаточно примеров событий из разряда «черных лебедей», на которых можно было бы обучить модель. Чем реже что-то происходит, тем труднее это предсказать.
Послесловие
Деревья решений выжили и победили, но удовлетворяют ли они в полной мере аналитиков данных? Они просты для восприятия и интуитивно понятны для человеческого разума, поскольку фактически состоят из правил, которые можно прочитать как длинные (пусть и громоздкие) предложения. Безусловно, это большое преимущество, но в некоторых случаях мы с радостью обменяем простоту на эффективность.
В следующей главе мы расскажем об объявленном Netflix открытом конкурсе на лучший алгоритм прогнозирования оценок, которые выставляют клиенты сайта после просмотра рекомендуемых им фильмов. Цель игры — повышение точности прогнозирования. Но как этого добиться? Путем головокружительного наращивания сложности? Или же существует некое простое, но действенное решение?


