Суперкомпьютер Watson и интеллектуальная телевикторина
Как работает компьютер, способный играть в интеллектуальную телевикторину наравне с людьми? Почему для этого ему требуется прогнозное моделирование и в чем секрет его высокой эффективности? Какое отношение это имеет к приложению Siri в устройствах iPhone? Почему человеческий язык так сложен для компьютеров? Возможен ли искусственный интеллект?
14 января 2011 года настал великий день. Дэвид Гондек изо всех сил старался усидеть на месте, борясь со снедающим его беспокойством, хотя он и был всего лишь зрителем в зале. Там, на сцене, в свете софитов стояло его детище — суперкомпьютер, над которым он вместе со своими коллегами из IBM Research работал последние четыре года. На его глазах машина вела интеллектуальный поединок с людьми в популярной национальной телевикторине Jeopardy!.
Знаменитый ведущий Алекс Требек зачитал вопрос в категории «Диалекты»:

Звездочкой (*) помечены вопросы, которые были заданы во время телеигры с участием компьютера Watson.

Соперниками Watson были два чемпиона — обладатель самого большого выигрыша за всю 26-летнюю историю игры Брэд Раттер и рекордсмен по длительности беспроигрышной серии Кен Дженнингс.
Будучи людьми, эти грозные соперники имели не только преимущества перед машиной, но и недостатки.
Watson первым подал звуковой сигнал. Не способный на слух воспринять профессионально поставленный голос Требека, он получил подсказку в виде напечатанного текста. Зрители услышали, как Watson синтезированным голосом дает ответ на вопрос, формулируя его в соответствии с правилами игры в вопросительной форме: «Что такое санскрит?»
Для компьютера подобный вопрос — все равно что манускрипт на санскрите. Человеческие языки гораздо сложнее, чем кажется людям, вследствие присущих им тончайших нюансов и всеобъемлющей неопределенности, с которыми мы, не машины, чувствуем себя вполне комфортно. Научить компьютер работать с человеческим языком нередко считается самой сложной задачей в области искусственного интеллекта.
Текстовая аналитика
Для меня это была китайская грамота.
Я полностью операционален, все мои схемы функционируют идеально.
В научной фантастике искусственный интеллект почти всегда наделен способностью к пониманию человеческих языков. Голливуд любит рисовать будущее, в котором люди свободно болтают с компьютерами как с хорошо информированными друзьями. В фильме «Звездный путь — 4: Возвращение домой» (1986) герои, путешествуя назад во времени, попадают на современную Землю и приходят в замешательство от примитивности наших технологий. Главный инженер Скотти так привык к голосовому общению с машинами, что пытается управлять компьютером Macintosh аналогичным образом. Осторожно поднимая мышь как некий странный артефакт, он говорит в нее бодрым голосом, как в микрофон: «Здравствуй, компьютер!»
Умный и разговорчивый компьютер HAL из фильма «Космическая одиссея 2001 года» таит в своем названии намек на IBM (замените каждую букву в аббревиатуре на следующую букву по алфавиту), хотя автор романа, по которому поставлен фильм, Артур Кларк категорически отрицает, что это было сделано намеренно. Спросите у разработчиков из IBM, есть ли у их суперкомпьютера Watson что-нибудь общее с HAL, легендарным злодеем, пытавшимся убить всех людей, и они поспешат перевести ваше внимание на более послушных носителей искусственного разума из «Звездного пути».
Область исследований, разрабатывающая технологии для работы с человеческим языком, называется обработкой естественного языка (она же компьютерная лингвистика). В сфере коммерческого применения чаще используется термин текстовая аналитика. В рамках этих дисциплин создаются аналитические методы, специально предназначенные для работы с письменной речью.
Если представить все имеющиеся на Земле данные в виде воды, то текстовые данные будут Мировым океаном. По оценкам, текстовые данные составляют около 80% всех данных, поскольку к ним относится все, что мы, человеческая раса, потрудились зафиксировать в письменном виде. Это богатейший материал, поскольку он был создан с целью передать не только факты и цифры, но и человеческие знания.
Но обработка текстовых данных таит в себе не только огромнейший потенциал, но и невероятные сложности.
Злоключения нашего родного языка
Трудно дать ответ, если не понимаешь вопрос.
Давайте начнем с относительно скромной цели, а именно проведем синтаксический анализ вышеуказанного вопроса о санскрите:

Возьмем, например, два слова: «of India». Это предложное словосочетание, которое относится к предыдущему словосочетанию «this classical language». Для вас, как для человека, это может показаться очевидным, но, если бы два последних слова были «of course» («разумеется»), они бы относились к основному глаголу «is», изменяя его значение (или ко всей фразе, если хотите).
Определение того, какую роль в предложении играет каждый компонент, такой как «of India», опирается на понимание значения слов и тех вещей в мире, которые они обозначают. Возьмите знаменитую английскую лингвистическую головоломку «Time flies like an arrow». Где в этом предложении глагол? Если это flies, предложение имеет смысл «Время летит, как стрела», если like — «Мухи времени любят некую стрелу», если time — «Измеряйте скорость мух так же, как измеряете скорость стрелы».
Остроумное продолжение этой фразы, часто приписываемое американскому комику Граучо Марксу, гласит: «Fruit flies like a banana». Это забавный и показательный пример. Like вполне может быть как глаголом, так и предлогом.
Продолжим изучать английский язык. «I had a car» («У меня была машина»). Если вы владели машиной на протяжении одного года, вы скажете «I had a car for a year». Но поменяйте одно слово, и все изменится. «I had a baby» («Я родила ребенка»). Если роды длились пять часов, вы скажете «I had a baby in five hours». Вы используете предлог «in», а не «for». Выбор предлога зависит от того, описываете ли вы ситуацию или событие, плюс значение имеет то, что является объектом действия — машина или ребенок.
«I ate spaghetti with meatballs» — «Я съел спагетти с фрикадельками». (Предлог with означает, что фрикадельки были частью блюда.)
«I ate spaghetti with a fork» — «Я съел спагетти вилкой». (Предлог with означает, что вилка была инструментом действия, а не частью блюда.)
«I ate spaghetti with my friend Bill» — «Я съел спагетти вместе со своим другом Биллом». (Предлог with означает, что Билл был участником трапезы, но никак не инструментом действия или частью блюда.)
«I had a ball» — «У меня был мяч». Замечательно, вы весело провели время.
«I had a ball but I lost it» — «У меня был мяч, но я его потерял». Не так весело! Но в определенном контексте эта фраза может звучать совсем уж нерадостно:
«How was your vacation and where is my video camera?» — «I had a ball but I lost it».
(«Как ты провел отпуск и где моя видеокамера?» — «Я хорошо повеселился, но ее [твою видеокамеру] я потерял».)
В языке даже самая базовая грамматическая структура, определяющая связи между словами, зависит от нашей точки зрения и обширных знаний о мире. Правила гибки, а значения слов изменчивы в этом изобилующем тонкими оттенками смыслов и подсмыслов мире человеческой речи.
Вопрос понятен? Отвечайте
У нас забавный язык: выражения «fat chance» и «slim chance» [fat — толстый, slim — худой, chance — шанс; оба словосочетания можно перевести как «слабая надежда»] означают одно и то же, тогда как «wise man» [мудрец] и «wise guy» [умник] — противоположные вещи.
Почему наш нос течет, а ноги пахнут?
Машине нужно не только обработать и понять вопрос на английском языке, но и ответить на него, что представляет собой целую новую область сверхсложных задач. Предположим, что компьютер чудесным образом преодолел все языковые барьеры и научился «понимать» вопросы в Jeopardy!, т.е. осуществлять синтаксический разбор предложения, анализировать «смысл» основного глагола и то, как этот смысл соотносится со «смыслами» других слов, таких как подлежащее, дополнение и предложные словосочетания, чтобы определять общий смысл вопроса. Рассмотрим следующий вопрос в категории «Телефон в кино»:

«Поняв» смысл вопроса, машина должна запустить процедуру поиска по базе данных, чтобы найти фильм, где снимается Киану Ривз, а сюжет включает использование проводного телефона для побега из некоего места (фильм «Матрица»). Даже если компьютер правильно преобразует вопрос для поиска по базе данных, как можно быть уверенным в том, что база данных будет включать информацию о бессчетном множестве таких второстепенных — и весьма субъективных — деталей сюжета?
Вот еще один пример вопроса из игры Jeopardy!, бросающий вызов любой базе данных (категория «Искусство воровства»):

Во-первых, чтобы ответить на этот вопрос, база данных должна содержать обширную информацию о каждом произведении искусства, точно так же, как в ней должна была быть информация обо всех деталях сюжета для ответа на вопрос о «Матрице». IBM нужно было предусмотрительно включить в базу данных сведения о том, становилось ли каждое произведение искусство объектом кражи, когда и где (в данном случае ответ — Багдад). Во-вторых, машине нужно интерпретировать глагол «пропал» как «был украден». Когда речь идет о произведении искусства, пропажа действительно чаще всего обозначает кражу, но когда я говорю, что у меня пропали ключи от машины, речь идет скорее о моей рассеянности, а не о чьем-либо злом умысле. На какой ступени развития должно находиться механическое воплощение человеческого разума, чтобы различать такие вещи? На самом деле в письменных источниках, таких как газетные статьи, используется большое разнообразие слов для обозначения кражи — исчезновение, хищение, воровство и т.д.
Фильмы и произведения искусства — всего лишь малая верхушка айсберга. Вопросы в Jeopardy! могут затрагивать любую область знаний, от философии и литературы до биохимии и истории виноделия, а ответом может быть человек, место, животное, вещь, год или абстрактное понятие. Эта задача без правил и ограничений называется ответом на открытые вопросы. Здесь возможно все.
Исследователи искусственного интеллекта старой школы живут фантазией создать «полную базу человеческих знаний». Поговорить с такими учеными весьма интересно. Они абсолютно уверены в том, что мы можем достичь звезд, если будем копать как можно глубже, изучать наши собственные мыслительные процессы и воспроизводить их в компьютерных программах, имитирующих человеческий разум и кодирующих человеческое знание. Но кто-то должен донести до бедолаг неприятную весть: это попросту невозможно. В 1980–1990-х годах более прагматичные ученые пришли к выводу, что такая база данных будет слишком большой и плохо структурированной.
Учитывая эти трудности, исследователи из IBM пришли к выводу, что с помощью поиска в базе данных в Jeopardy! можно ответить всего на 2% вопросов. Требование отвечать на открытые вопросы выходит далеко за рамки традиционных компьютерных операций по хранению и обеспечению доступа к данным о бронировании авиабилетов или банковским данным. Здесь нужна гораздо более умная машина.
Совершенный источник знаний
Мы сканируем все эти книги вовсе не для того, чтобы их читали люди. Мы их сканируем, чтобы их прочитал искусственный разум.
Немного хороших новостей: IBM не нужно создавать всеобъемлющую базу данных для игры в Jeopardy!, потому что совершенный источник знаний уже существует: письменное слово. Я рад сообщить, что люди любят писать: мы записываем все, что знаем, в книгах, Интернете, блогах, «Википедии», газетных статьях и т.п. Вся эта текстовая информация представляет собой беспрецедентный кладезь человеческих знаний.
Проблема в том, что знания эти закодированы на человеческом языке, как и сбивающие с толку вопросы в Jeopardy!. Следовательно, машине нужно преодолеть все сложности и тонкости человеческой речи не только в самом вопросе, но и в миллионах письменных документов, которые могут содержать ответ на этот вопрос.
Обращаться за помощью к Google бесполезно. Хотя Google и является для людей главным средством поиска информации в океане хранящихся в Интернете данных, он не дает точных ответов. Поисковик выдает список из сотен и тысяч веб-страниц, каждая из которых содержит возможный ответ. Он не предназначен для выполнения такой задачи, как поиск единственного правильного ответа на вопрос. Попробуйте использовать Google или другие поисковые системы для игры в Jeopardy! — например, осуществите поиск по ключевым словам из вопроса и затем выберите в качестве ответа заголовок первой веб-страницы из результатов поиска. У вас ничего не получится. Если бы задача ответа на открытые вопросы решалась так просто! В лучшем случае вам удастся правильно ответить всего на 30% вопросов.
Личный секретарь Siri от Apple и всезнайка Watson от IBM
Что общего между личным секретарем Siri в смартфонах iPhone и суперкомпьютером Watson? Впервые представленный в модели iPhone 4S как ключевая особенность, отличающая ее от предыдущей модели, помощник Siri реагирует на широкой спектр голосовых команд и запросов, адресованных смартфону.
Siri имеет дело с более простым языком, чем Watson: пользователи формулируют запросы к Siri, зная, что они говорят с компьютером, тогда как многословные, зачастую образные и остроумные вопросы в игре Jeopardy! составлялись для людей без учета того, что на них может отвечать машина. Вследствие этого базовая технология Siri предназначена для решения другого, более простого варианта задачи обработки человеческого языка.
Хотя Siri реагирует на впечатляюще широкий спектр голосовых команд, которые пользователи могут адресовать смартфону в произвольной форме без предварительного обучения, люди знают, что компьютерам трудно понимать человеческую речь, и осознанно или нет ограничивают свои запросы. Например, вы можете скомандовать: «Назначь встречу за кофе с Биллом завтра в 2 часа дня», но вы вряд ли скажете «Назначь-ка мне встречу с тем парнем, с которым я обедал в прошлом месяце и у которого почтовый ящик на Yahoo!» или, что еще маловероятнее, «Я хотел бы узнать, что думает мой старый добрый друг из Вайоминга по поводу того, чтобы встретиться в ближайшие пару недель и обсудить нашу идею со стартапом».
Siri гибко обрабатывает относительно простые фразы, которые непосредственно относятся к функциям смартфона, таким как осуществление звонков, отправка текстовых сообщений, поиск в Интернете, а также связанные с использованием календаря и карт (недаром это приложение называется личным секретарем).
Кроме того, Siri способен отвечать на общие вопросы, хотя ответ на открытые вопросы, о котором мы говорили выше, находится за пределами его возможностей. Он обращается к бесплатной онлайновой системе под названием WolframAlpha и с ее помощью отвечает на просто сформулированные, фактологические вопросы. Дело в том, что эта система может вычислять ответы только на основе фактов, непосредственно содержащихся в структурированных единообразных таблицах в ее базе данных, например:
Даты рождения известных людей: сколько лет было Элтону Джону в 1976 году?
Астрономические факты: за какое время свет пролетает расстояние от Земли до Луны?
География: самый большой город в Техасе?
Здоровье: в какой стране самая большая продолжительность жизни?
Вопросы требуют простой формулировки, поскольку система WolframAlpha в первую очередь предназначена для поиска и вычисления ответов на основе имеющейся базы данных и только во вторую — для обработки усложненных грамматических форм.
Отличие Siri от компьютера Watson состоит в том, что это приложение обрабатывает устные запросы, тогда как Watson имеет дело с письменным текстом. Исследователи обычно подходят к обработке устной речи (распознаванию речи) как к отдельной задаче, выходящей за рамки обработки текста. Когда компьютер пытается транскрибировать устную речь, прежде чем расшифровать ее, как это делает Siri, у него гораздо больше простора для ошибок.
У Siri есть словарь заранее заготовленных шуточных ответов. Например, если вы спросите у него: «Кто твой папочка?», он ответит: «Ты. Может, вернемся к работе?» Но не стоит всерьез рассматривать это как продвинутую способность к восприятию человеческого языка.
Способность Siri и WolframAlpha отвечать на вопросы постоянно совершенствуется благодаря непрерывному процессу исследований и разработок, который частично опирается на поток входящих запросов от пользователей.
Искусственная невозможность
Я задаюсь вопросом, как автоматизировать
Мое замечательное «Я», — чудесная мысль,
Свидетельствующая о моем психическом здоровье.
В чем большее безумие — предполагать, что мысли могут быть настолько материальны или что я умею петь?
В любом случае, если мне это удастся, моя машина будет пытаться сделать то же самое.
Этому искушению невозможно сопротивляться, поскольку, занимаясь проблемой понимания естественного языка, мы проникаем в самое сердце того, что считаем человеческим разумом.
Между гениальностью и безумием тонкая грань.
Не были ли исследователи из IBM сумасшедшими, осмелившись взяться за такую колоссальную по сложности задачу, как научить компьютер отвечать на любой вопрос в интеллектуальной игре для людей Jeopardy!? Им предстояло научить компьютер иметь дело со всем невероятным богатством человеческого языка, причем не только в формулировке каждого вопроса, но и в бессчетном множестве источников текстовой информации, из которых нужно было извлечь ответ. IBM шла ва-банк.
Если бы меня спросили о шансах IBM, я бы решил, что успех невозможен. Будучи непосредственным свидетелем того, как в 1990-е годы лучшие в мире умы безуспешно бились над решением этой задачи (я лично шесть лет посвятил исследованиям в области обработки естественного языка, а также проработал несколько месяцев в том самом центре IBM Research, где был создан Watson), я был готов опустить руки. Человеческий язык — настолько сложный феномен, что на тот момент казалось практически невозможным научить компьютер отвечать на вопросы даже в строго ограниченной области знаний, такой как фильмы или виноделие. Однако IBM нацелилась на неограниченный круг вопросов в любой области знаний.
Достижение этой цели стало бы свидетельством такого большого скачка в сторону обретения человекоподобных возможностей, что сделало бы уместным величественное слово «интеллект». Способный на это компьютер представлялся таким же таинственным и волшебным, как человеческий разум. Несмотря на собственный более чем 20-летний опыт изучения искусственного интеллекта (ИИ), я был убежденным скептиком. Но поставленная IBM задача была настолько грандиозна, что ее успешное решение впервые заставило бы меня согласиться с тем, что термин «искусственный интеллект» имеет под собой основания.
Искусственный интеллект — провокационный термин. Он подспудно предполагает, что машина способна выйти на такую ступень развития. То, что создатели машин даровали им громкое имя «искусственный интеллект», отчасти свидетельствует об их собственной дерзости и самовозвеличивании. В конце концов, чтобы создать такую машину, сам изобретатель должен быть гением.
Проблема не в слове «искусственный», а в слове «интеллект». Интеллект есть полностью субъективный конструкт, поэтому понятие ИИ не имеет четкого определения. Большинство различных определений сводится к тому, чтобы «сделать компьютеры разумными», что бы это ни значило! Не выделяется ни одной конкретной способности, которую можно было бы рассматривать как ключевую характеристику ИИ. Поэтому на практике область ИИ представляет собой погоню за философскими идеалами и исследовательскими грантами.
Знаете, что общего между богом, американским комиком Граучо Марксом и искусственным интеллектом? Они никогда не согласятся стать членами клуба, который захочет принять их в свои члены. ИИ уничтожает сам себя логическим парадоксом почти так же, как Бог в фантастическом романе Дугласа Адамса «Автостопом по Галактике»:
— Я не желаю доказывать, что я существую, — сказал Бог, — поскольку доказанное не требует веры, а без веры я — ничто.
— Но, — возразил ему Человек, — вавилонская рыба [рыба-переводчик с планетарных языков] является неоспоримой уликой, не так ли? Она не могла появиться случайно. Это доказывает, что ты существуешь. А следовательно, согласно твоему собственному заявлению, тебя нет. Что и требовалось доказать.
— О господи, — ответил Бог, — об этом я и не подумал.
И его сразу сдуло порывом логики.
ИИ сталкивается с аналогичным парадоксом самоуничтожения, поскольку, как только вы обучаете компьютер что-либо делать, это сразу же становится банальным. Мы ассоциируем ИИ с еще не решенными «интеллектуальными» задачами — грандиозными и впечатляющими, такими как распознавание устной речи или победа над чемпионом мира по шахматам. Это сложнейшие задачи, но, как только рубеж преодолен, они теряют все свое очарование. В конце концов компьютеры способны выполнять только механические задачи, хорошо понятные и четко определенные. Вы можете быть впечатлены молниеносной скоростью, но в самом электронном процессе исполнения нет ничего сверхъестественного или человекоподобного. Если это возможно, это не интеллектуально.
Обремененный подспудным грузом грандиозных ожиданий, искусственный интеллект ненамеренно приравнивается к тому, чтобы «научить компьютеры делать вещи, которые слишком сложны для компьютеров», — другими словами, к искусственной невозможности.
Как научить компьютер отвечать на вопросы
Однако перед IBM стояла совершенно конкретная, четко определенная задача: научить компьютер отвечать на вопросы в игре Jeopardy!. Если исследователи преуспеют в этом и Watson удастся создать видимость разумности, IBM заработает несколько дополнительных очков на свой счет.
Как правило, предвидеть все возможные вариации в языке невозможно. Исследователи в области обработки естественного языка создают сложнейшие продвинутые методики для анализа фраз на английском и других естественных языках, которые опираются на глубокий фундамент лингвистической теории и специально разработанные словари. Но, реализованные в виде компьютерных программ, эти методики далеки от совершенства. Всегда можно найти фразы, которые кажутся простыми и понятными для людей, но собьют с толку любую систему обработки естественного языка. В ответ на это исследователи расширяют теоретическую базу и базу знаний своих систем, обучая их распознавать еще больше фраз. Но даже после стольких лет упорного труда по ручной отладке этих систем мы по-прежнему находимся в сотнях световых лет от того момента, когда сможем болтать с нашими ноутбуками как с людьми.
Остается одна надежда: автоматизировать непрерывный процесс отладки систем по образцу машинного обучения. В конце концов, этой теме и посвящена данная книга.
Прогнозная аналитика (ПА) — технология обучения на опыте (данных) для прогнозирования будущего поведения людей с целью принятия оптимальных решений.
Применение прогнозной аналитики к вышеописанной задаче ответа на вопросы немного отличается от большинства примеров, которые мы обсуждали в этой книге. В рассмотренных нами примерах прогнозная модель использовалась для предсказания поведения индивида, такого как щелчок мышью, покупка, ложь или смерть, на основе известной о нем информации:
Компьютер Watson от IBM включает модели, которые предсказывают, сочтут ли люди-эксперты пару «вопрос/ответ» в игре Jeopardy! правильной:

Если модель работает хорошо, она должна поставить низкую оценку этой паре, поскольку правильный ответ на этот вопрос — «горизонт событий», а не «радиация» (фанатам «Звездного пути» понравится эта категория вопросов «Последние рубежи»). Watson оценил ответы следующим образом: горизонт событий — 97%, масса — 11% и радиация — 10%. Короче говоря, исследователи из IBM решили задачу поиска правильного ответа методом прогнозной аналитики.
Применение ПА: поиск правильного ответа на открытый вопрос
- Предмет прогнозирования: оценить правильность ответа посредством прогнозирования правильности пары «вопрос/предполагаемый ответ».
- Цель прогнозирования: выявить предполагаемый ответ с наивысшей прогнозной оценкой вероятности и использовать его как окончательный ответ.
Ответ на вопросы не является прогнозированием в традиционном смысле — Watson не предсказывает будущее. Вместо этого его модели «предсказывают» правильность ответа. Для этого применяются те же самые методы прогнозного моделирования, но в отличие от других областей применения ПА прогнозируемый исход в данном случае уже известен, по крайней мере некоторым людям, а не станет известен когда-либо в будущем. В оставшейся части главы я буду говорить о прогнозировании именно в этом альтернативном смысле как о «выведении заключений о неизвестном». В принципе, вопрос, на который отвечают прогнозные модели Watson, можно сформулировать в более традиционной для ПА форме, а именно: «Согласятся ли люди-эксперты с данным предполагаемым ответом на вопрос?» Та же семантическая проблема возникает и в случае прогнозирования клинического диагноза (таблица 4 в приложении D), выявления мошенничества (таблица 5), предсказания человеческого поведения (таблица 8), и в других областях, отмеченных в таблицах в приложении D буквой «О» («обнаружение»).
Говорить как человек; отвечать как человек
Для обучения моделей IBM требовались данные, а именно, примеры вопросов из Jeopardy!. Ищите и обрящете: за несколько десятилетий существования телевикторины накопились сотни тысяч вопросов с правильными ответами (IBM скачала их с фан-сайтов, где размещена вся необходимая информация). Этот массив обучающих данных был беспрецедентным кладезем знаний, который давал машине возможность расширить свои горизонты понимания человеческого языка. Тогда как большинство проектов в области ПА имеют доступ к большим объемам обучающих данных, таких как положительные и отрицательные примеры проявления прогнозируемого поведения в прошлом (смотрите левую колонку в таблицах в приложении D), большинство проектов в области обработки естественного языка не располагают столь обширной базой примеров для обучения.
Имея в своем распоряжении всю историю игры Jeopardy!, компьютер мог попытаться научиться подражать человеку. Пары «вопрос / правильный ответ» содержат в себе примеры человеческого поведения — а именно то, как люди отвечают на такие типы вопросов. Таким образом, обучение на этом виде данных позволяет машине разработать модель, имитирующую человеческое поведение, т.е. прогнозирующую то, как бы ответили на вопросы люди-эксперты. Да, мы, люди, слишком сложные существа для того, чтобы научить компьютеры имитировать наше мышление, но машина необязательно должна выводить ответы точно так же, как это делает человек. При помощи прогнозного моделирования компьютер может найти некий оригинальный способ запрограммировать самого себя на выполнение этой человеческой задачи, даже если он будет выполнять ее иначе, чем люди.
Знаменитый вопрос Алана Тьюринга гласит: «Если машина способна проявлять человекоподобное поведение, говорит ли это о наличии у нее искусственного интеллекта?» Это антропоцентрический подход, и лично я настроен весьма скептично.
Между тем сама по себе обширная база обучающих данных по Jeopardy! не гарантировала создание успешных прогнозных моделей по двум причинам:
- Задача, известная как «ответ на открытый вопрос», сопряжена с колоссальными по сложности нерешенными проблемами в области анализа языка и человеческого мышления.
- В отличие от многих областей применения ПА успех в игре Jeopardy! требует высочайшей точности прогнозирования.
Когда в 2006 году IBM бросила вызов игре Jeopardy!, это направление исследований находилось в зачаточном состоянии. Наиболее значительным источником данных по вопросно-ответным системам, работающим с открытыми вопросами, был конкурс, проводимый в рамках спонсируемой правительством программы «Конференция по текстовому поиску и вопросно-ответным системам» (Text Retrieval Conference — Question Answering, или TREC QA). Однако в этом конкурсе в качестве обучающих данных использовались гораздо более простые по содержанию и формулировке вопросы, чем в игре Jeopardy!, например, «Когда умер Джеймс Дин?». Чтобы отвечать на такие вопросы, вопросно-ответным системам достаточно было уметь искать информацию в Интернете. В этом конкурсе у IBM был один из пяти самых сильных соперников, система которого отвечала правильно на 33% вопросов; при этом ни одна из конкурирующих систем не преодолела барьер 50%. Более того, когда IBM попыталась применить свою систему к более сложным вопросам в игре Jeopardy!, та сумела правильно ответить всего на 13% из них, что было существенно хуже показателя в 30%, достигнутого только при помощи поиска в Интернете.
Гениальная идея
Ученые часто сами определяют для себя цели исследований. Но настоящая большая задача забирает контроль из рук ученых и заставляет их работать над гораздо более сложными проблемами, чем бы они поставили перед собой сами.
На дне коробки с попкорном нет никакого секрета.
Объявив о своем решении создать суперкомпьютер для игры в Jeopardy!, IBM поставила на кон свое имя. После шахматного матча в 1997 году, когда компьютер Deep Blue от IBM одержал победу над чемпионом мира Гарри Каспаровым, в 2011-м компьютер Watson должен был публично вступить в интеллектуальное состязание с человеком в телевизионной игре. Многомиллионная аудитория телезрителей с нетерпением ждала этого события.
Как и во всех великих начинаниях, успех не был гарантирован. Никто не знал, возможно ли в принципе совершить перелет через Атлантику (это сделал Чарльз Линдберг в 1927 году, чтобы выиграть приз $25 000); высадиться на Луне (в 1969 году космический корабль НАСА «Аполлон-11» доставил людей на Луну, выполнив одну из главных целей десятилетия, поставленных Джоном Кеннеди); создать компьютер, который победит шахматного гроссмейстера (компьютер Deep Blue от компании IBM обыграл чемпиона мира в 1997 году), или даже улучшить систему рекомендаций фильмов Netflix на 10% (это было сделано в 2009 году, о чем рассказывалось в предыдущей главе).
Совершить этот прорыв было под силу только такой мощной глобальной мегакомпании, как IBM. Имея свыше $100 млрд годового дохода и более 430 000 сотрудников по всему миру, IBM является четвертой самой дорогой компанией США, уступая лишь Apple, Exxon Mobil, и Microsoft. Она инвестировала в проект Watson десятки миллионов долларов, и за четыре года ее команда в Исследовательском центре имени Уотсона в штате Нью-Йорк (как и суперкомпьютер, этот центр назван в честь первого президента IBM Томаса Уотсона) выросла до 25 кандидатов наук.

Если у вас есть возможность вести исследования полным ходом, это еще не значит, что вы двигаетесь в правильном направлении. Где будет совершен научный прорыв? Напомним, что ключевой инновацией, на которую помог пролить свет краудсорсинговый подход к решению сложных задач, были ансамбли моделей, о которых мы говорили в предыдущем разделе. Именно это доктор прописал и для суперкомпьютера Watson.
Вопросно-ответная машина
Дэвид Гондек и его коллеги из IBM Research могли решить невероятно сложную задачу игры в Jeopardy! только посредством синтеза. В области обработки человеческого языка ландшафт научных наработок был фрагментированным и неполным — этакое попурри из методик и технологий, инновационных по замыслу, но весьма ограниченных в применении. Ни одна из них в отдельности не обеспечивала желаемого результата.
Как работает суперкомпьютер Watson? Он построен на основе ансамбля моделей, эффективно соединяя массу разнообразных методологий и технологий. Здесь нет одного-единственного секретного ингредиента; секрет успеха кроется в общей рецептуре. Именно ансамбль моделей выбирает внутри Watson окончательный ответ на каждый вопрос.
Но прежде чем поближе познакомиться с тем, как работает Watson, давайте посмотрим, какие открытия сделал один эксперт в области ПА, который поставил перед собой цель стать прославленным чемпионом этой интеллектуальной телеигры.
Прогнозный анализ и Jeopardy!
21 сентября 2010 года, за несколько месяцев до появления Watson на публике, во время очередной телевикторины Jeopardy! ведущий Алекс Требек зачитал подсказку к вопросу, предназначенному для любителей научной фантастики:

Конкурсант Роджер Крейг поспешно нажал кнопку. Как и любой кандидат технических наук, он знал, что ответом был коммандер Спок.
Подобно Споку, Роджер довел свое обучение до логического предела. Игра Jeopardy! требует неординарной культурной грамотности, почти недостижимого статуса человека эпохи Возрождения, владеющего по крайней мере базовыми знаниями почти во всех областях. Чтобы подготовиться к участию в этой викторине, к чему он стремился с 12 лет, Роджер сделал то, чего никто до него раньше не делал: он применил к Jeopardy! прогнозный анализ.
Роджер использовал прогнозы для оптимизации своего обучения. Как любой простой смертный, он испытывал дефицит свободного времени. Но он также был специалистом по прогнозной аналитике, поэтому загрузил в компьютер данные по игре Jeopardy!, в том числе историю своих ответов на вопросы викторины, и разработал систему, которая должна была обучиться на этих данных и выделить наиболее слабые места в его знаниях. Таким образом, Роджер мог максимально эффективно использовать свое время, сосредоточившись конкретно на этих темах. Он использовал прогнозную аналитику, чтобы прогнозировать самого себя.
Применение ПА: образование — повышение эффективности целенаправленного обучения
- Предмет прогнозирования: слабые и сильные места в знаниях обучающегося.
- Цель прогнозирования: сосредоточить силы на слабых местах, чтобы восполнить пробелы в знаниях.
Усилия этого находчивого парня окупили себя. В Jeopardy! Роджер установил абсолютный рекорд по величине выигрыша за одну игру, получив $77 000, и продолжил триумфальное шествие, выиграв более $230 000 за серию из семи игр. В результате он занял третье место по общей сумме выигрыша за всю историю игры (в рамках регулярной серии). Через год его пригласили на «Турнир чемпионов», где Крейг завоевал первое место и приз $250 000. По его оценке, он способен правильно ответить на 90% вопросов в Jeopardy!, что делает его одним из лучших игроков в истории игры.
Проанализировав примерно 211 000 вопросов из Jeopardy! (которые он, как и IBM, скачал из архивов фан-сайтов), Роджер составил общую картину представленных в игре областей знаний. «Если знаете ответы примерно на 10 000–12 000 вопросов, — сказал он мне, — вы охватываете большинство из них». Эти области включают в себя страны, штаты, президентов и планеты. Но во множестве других категорий вам не нужны глубокие познания. Поскольку цель телевикторины — развлечь аудиторию, в ней нет чересчур заумных вопросов. Вам нужно хорошо разбираться в таких темах, как известные города, фильмы, цветы; в классической музыке достаточно знать пару десятков композиторов и несколько их лучших работ — и дело будет сделано.
Но даже такие ограничения не приносят большого облегчения тем, кто поставил перед собой цель научить машину отвечать на открытые вопросы. Прогнозные модели, как правило, предназначены выбирать только между двумя вариантами: совершит человек щелчок мышью, купит, обманет, умрет — да или нет? В данном же случае Watson должен был выбирать из более чем 10 000 возможных вариантов ответа на каждый вопрос.
Улучшение качества игры соперников из числа людей, которого они достигали благодаря прогнозной аналитике, было еще одной плохой новостью для Watson. Хотя Роджер Крейг дал исследователям из IBM доступ к своей системе, Watson предстояло столкнуться с могущественным оппонентом Кеном Дженнингсом, также использовавшим в процессе подготовки к «игре века» аналитическое программное обеспечение, которое, по его словам, «оказало ему огромную помощь при возвращении в боевую форму».
Сбор доказательств
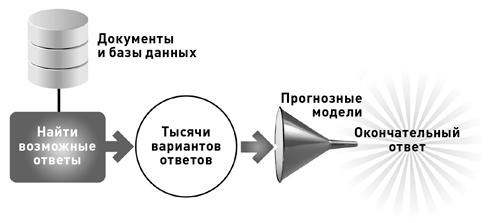
Итак, вот как работает Watson. После расшифровки вопроса компьютеру требуется выполнить три основных шага:
- Найти тысячи вариантов ответов.
- Для каждого ответа собрать доказательства.
- Применить прогнозные модели для выявления правильного ответа.
Последнее слово остается за прогнозными моделями. Собрав тысячи предполагаемых ответов на вопрос, Watson выделяет среди них один ответ, который получает наивысшую оценку ансамбля прогнозных моделей.
Возможные ответы и доказательства Watson собирает из источников, выборочно загруженных в него разработчиками IBM и представляющих собой своего рода срез самой умной части Интернета, который и формирует базу знаний Watson. Она включает 8,6 млн письменных документов, в том числе 3,5 млн статей из «Википедии» (т.е. всю ее англоязычную часть по состоянию на 2010 год), Библию, целую библиотеку популярных книг различной тематики, ленты новостей, тома энциклопедий и многое другое. Все это дополняется более структурированными источниками, такими как словари, тезаурусы и базы данных наподобие Internet Movie Database.
Занимаясь сбором возможных ответов на вопрос, Watson не проявляет большой разборчивости. Его стратегия — забросить как можно более широкую сеть, чтобы гарантировать, что в нее попадется правильный ответ. Он роется в своей базе знаний разными способами, в том числе осуществляет поиск во многом так же, как это делают поисковые системы в Интернете наподобие Google (хотя Watson ведет поиск только в пределах собственного внутреннего хранилища). Когда он находит подходящий документ, например такой, как статья в «Википедии», он берет его название в качестве возможного ответа. В других случаях он использует фрагменты текста размером с ответ. Он также осуществляет поиск и обратный поиск по базе данных и словарям, чтобы собрать еще больше вариантов ответов.
Как и его вымышленный тезка доктор Ватсон, помощник Шерлока Холмса, компьютер сталкивается с классической детективной ситуацией: кто из множества подозреваемых ответов «виновен» в том, что он правилен? Чтобы решить эту загадку, компьютер-детектив должен собрать для каждого подозреваемого как можно больше доказательств за и против. Для этого он еще раз прочесывает свою базу знаний.
Проблема в том, что с таким огромным количеством возможных ответов компьютер действует фактически вслепую. Это серьезный вызов для машины — понять хотя бы то, о какого рода вещах ее спрашивают. Об актере? О фильме? Городе, фрукте, планете, компании, романе, президенте, философской концепции? Исследователи IBM определили, что вопросы в Jeopardy! предусматривают 2500 различных типов ответов. Но, когда они попытались сократить задачу до более управляемых размеров, взяв только 200 наиболее распространенных типов ответов, оказалось, что это позволяет Watson ответить всего на половину вопросов. Диапазон возможных вариантов слишком широк и равномерно распределен, чтобы его можно было безопасно сократить.
Элементарно, Ватсон
Против этой неопределенности есть одно оружие: доказательства. С этой целью Watson использует широкий спектр технологий обработки естественного языка, опирающихся в том числе на новейшие наработки ведущих исследователей в этой области из Университета Карнеги–Меллон, Массачусетского университета, Университета Южной Калифорнии, Техасского университета, Массачусетского технологического института, других университетов и, само собой разумеется, из исследовательского центра IBM Research. Иногда имеет смысл как следует покопаться в лингвистических тонкостях. Например, рассмотрим такой вопрос:

В своем докладе на конференции Predictive Analytics World Дэвид Гондек привел в пример следующую фразу, которая вполне могла бы сбить Watson с толку:
В мае Гари прибыл в Индию после празднования своего юбилея в Португалии.
Учитывая такое количество совпадающих слов, машина, скорее всего, включит Гари в список возможных ответов. Ее поисковым системам безусловно понравится документ с такой фразой. Кроме того, используемые Watson системы сбора доказательств, основанные на сопоставлении слов, поставят этой фразе высокую оценку.
Чтобы определить, может ли фраза претендовать на возможный ответ, Watson нужны более продвинутые лингвистические технологии, способные распознать, как соотносятся между собой слова, из которых она состоит. Возьмем другой вариант:
21 мая 1498 года Васко да Гама высадился в местечке Каппад.
За исключением служебных слов в этой фразе с вопросом перекликается одно только слово «май». Однако Watson способен найти значимые соответствия. Местечко Каппад находится в Индии. Одно из значений слова «высадился» — «прибыл». А 400-летний юбилей в 1898 году соответствует некоему событию в 1498 году.
Будучи установленными, эти соответствия свидетельствуют в пользу правильного ответа «Васко да Гама». Как и все предполагаемые ответы, этот вариант оценивается на предмет совместимости по типу ответа — в данном случае это путешественник, как определено исходя из наличия слова «путешественник» в вопросе. Васко да Гама действительно был известным путешественником, поэтому этот ответ, скорее всего, получит высокую оценку прогнозной модели.
Эти взаимосвязи относятся к самому значению слов, их семантике. Watson работает с базами данных, содержащими информацию об устоявшихся семантических отношениях, и ищет доказательства для установления новых. Рассмотрим следующий вопрос из Jeopardy!:

Варианты ответов, найденные Watson, включают органеллы, вакуоль, цитоплазму, плазму и митохондрии. Искомым типом ответа является жидкость, и Watson находит доказательства того, что только один из ответов подходит под это определение. В одном из определений цитоплазма называется «текучей средой», а поскольку текучая среда часто эквивалентна жидкости, машина ставит цитоплазме более высокую скоринговую оценку по сравнению с остальными вариантами и таким образом правильно отвечает на вопрос.
Здесь Watson выполняет смелый логический трюк. Рассуждать, как это делают люди, в столь нечетко определенной области, как вопросы в игре Jeopardy!, — экстремальный спорт для машины. Неопределенность пронизывает всё — например, в наиболее авторитетных источниках, к которым имеет доступ Watson, утверждается, что все жидкости являются текучей средой, но такое вещество, как стекло, относится одновременно и к жидкостям, и к твердым веществам. Или же, хотя все люди смертны, в источниках может утверждаться, что знаменитые люди достигли бессмертия. Следовательно, строгая иерархия понятий здесь неприменима. По этим причинам, а также вследствие многозначности слов в языках и важнейшей роли контекста базы данных по абстрактным семантическим отношениям совершенно не согласуются друг с другом. Как политические партии, они не в состоянии договориться между собой, а универсальной власти — единственной абсолютной правды, способной уладить разногласия, попросту не существует.
Вместо того чтобы тщетно пытаться разрешить эти разногласия, Watson собирает все, даже противоречивые доказательства. Приговор выносится в самом конце, когда взвешивается весь набор доказательств. Таким образом, применяемый Watson процесс принятия решений аналогичен нашему. Вместо того чтобы искать абсолют, он подстраивается под контекст. В некоторых песнях есть немного от кантри, немного от рок-н-ролла. Например, песни Джеймса Тейлора можно отнести к любому из двух направлений в зависимости от того, кому вы их описываете.
Но в то же время такая гибкость и непредвзятость «мышления» порой может вести к оплошностям. Отказ от абсолюта означает быстрое и свободное оперирование семантикой, что повышает риск глупой ошибки — неправильного ответа, который для людей кажется очевидным. Например, во время телевикторины Watson столкнулся со следующим вопросом в категории «Города США»:

Watson удалось собрать очень мало доказательств для найденных им вариантов ответов, поэтому он не стал бы издавать звуковой сигнал и предлагать свой ответ. Но это был финальный раунд, где ответ каждого игрока был обязателен. Вместо правильного ответа «Чикаго» Watson назвал город, находящийся даже не в Соединенных Штатах, — Торонто. Ведущий Алекс Требек, канадец по происхождению, пошутил, что на этой игре он узнал что-то новое.
Важное значение имеет английская грамматика. Чтобы правильно ответить на некоторые вопросы, прежде всего необходимо правильно разобрать фразу. Рассмотрим такой вопрос:

В поисках доказательств Watson находит следующую фразу из статьи в Los Angeles Times:
«Форд помиловал Никсона 8 сентября 1974 года».
В отличие от нас, компьютеру не так-то легко понять, что правильный ответ — это Никсон, а не Форд. Исходя только из соответствия слов, эта фраза в равной степени свидетельствует в пользу того и другого ответа. Только если машина сумеет определить, что в вопросе употреблен пассивный залог, что означает, что искомый ответ касается объекта, а не субъекта действия (того, кто помилован, а не того, кто помиловал), а в найденной фразе употреблен активный залог, она сумеет правильно интерпретировать это доказательство и поставить более высокую оценку ответу «Никсон».
Попытки грамматической расшифровки фраз при помощи методов обработки естественного языка не всегда дают результат. Компьютеры не всегда способны справиться с нашей грамматикой, поэтому им требуются дополнительные источники доказательств. Человеческий язык — мудреная штука. Возьмем, например, такой вопрос:

При поиске доказательств компьютер может наткнуться на следующую фразу:
«Сэм был расстроен, пока не увидел почти выигрышный результат Милорада Чавича».
Если компьютер неверно интерпретирует слово «расстроен» как глагол в пассивном залоге, а не прилагательное, фраза может быть истолкована как доказательство в пользу ответа «Сэм». Однако это был пловец Майкл Фелпс, который выиграл золото на Олимпийских играх 2008 года. Правильная расшифровка даже простейшей грамматической структуры предложения зависит от глубокого, часто трудноуловимого значения слов.
Горы доказательств
К сожалению, единственного верного решения проблемы не существует. Будь то интерпретации семантических отношений между словами или синтаксический анализ предложений, методики обработки естественного языка не отличаются надежностью. Даже самые лучшие методы во многих случаях приводят к ошибкам. Ситуация усугубляется изощренной манерой формулировки вопросов в Jeopardy!. Чтобы развлекать сидящих у телеэкранов зрителей, авторы вопросов используют шутливый и одновременно лаконичный стиль.
Единственная надежда на то, чтобы собрать из максимально возможного количества источников как можно больше доказательств за и против каждого варианта ответа. Каждое, даже самое незначительное доказательство играет роль. Цель игры — разнообразие. Массив разнообразных доказательств имеет больше шансов привести к правильному ответу, тогда как ни на один самый замысловатый или самый простой метод нельзя всецело положиться, если он используется в одиночку. К счастью, в данном случае разнообразие является обычным делом: как и в любых научных изысканиях, исследователи в области обработки естественного языка стремятся внести собственный уникальный вклад и при разработке своих методик намеренно используют непохожие подходы.
Watson применяет целое ассорти разнообразных подходов к сбору доказательств для оценки предполагаемых вариантов ответов.
- Поиск по фразе. Предполагаемый ответ сопоставляется с вопросом (например, «Никсон был помилован президентом 8 сентября 1974 года») и осуществляется поиск по размеру фразы. Сколько соответствий найдено? Сколько есть соответствий слово в слово, семантических и после грамматического разбора? Какова самая длинная последовательность слов, общая для каждой найденной фразы и предполагаемого ответа?
- Популярность. Как часто встречается данный вариант ответа?
- Соответствие по типу. Соответствует ли данный вариант ответа тому типу ответа, которого требует вопрос (например, актер, фрукт, планета, компания, роман и т.д.)? Если это человек, соответствует ли пол?
- Соответствие по времени. Существовал ли предполагаемый предмет ответа в обозначенный в вопросе период времени?
- Надежность источника. Насколько надежен источник, из которого происходит данное доказательство?
Невозможно знать наперед, какой из этих факторов (и сотни их вариаций, оцениваемых Watson) может иметь решающее значение для выявления правильного ответа. Рассмотрим такой вопрос:

Хотя правильный ответ — Аргентина, подавляющая масса доказательств, полученных в процессе обычного поиска, свидетельствует в пользу Боливии из-за многолетнего территориального спора между этими странами, который часто освещается в новостях. К счастью, достаточный массив других доказательств, выведенных на основе логического соответствия фраз и найденных в источниках географической информации, одерживает верх, и Watson правильно отвечает на этот вопрос.
Кто-то может счесть такую умопомрачительную мешанину методов и подходов не более чем прихотью, тешащей души профессионалов, но я считаю иначе. Дело в том, что большинство сложных методик семантического и лингвистического анализа ненадежны и зачастую не работают. С другой стороны, остальные подходы страдают от чрезмерной упрощенности. Но коллективная способность возникает из совокупности различных методик, сочетающих сотни видов измерений, даже если каждая из них сама по себе далека от совершенства.
Здесь вступает в игру «эффект ансамбля»: большое количество и разнообразие подходов компенсируют их индивидуальные недостатки. Как целое система достигает операционной эффективности при реализации ранее казавшейся невыполнимой задачи — генерировании ответа на открытый вопрос, сформулированный на естественном человеческом языке.
Взвешивание доказательств при помощи ансамбля моделей
Есть два способа создания искусственного интеллекта. Вы либо знаете формулу, либо позволяете ему развиваться самостоятельно. Ясно, что формулы мы не знаем, поэтому остается второй вариант — саморазвитие путем машинного обучения.
Ключ к оптимальному сведению воедино разрозненных доказательств кроется в машинном обучении. Опираясь на известные ответы примерно на 25 000 вопросов из игры Jeopardy!, процесс обучения позволяет установить, как следует взвешивать различные источники доказательств для каждого предполагаемого ответа. За применение машинного обучения и конкретно за эффективность процесса, который сводил вместе все собранные доказательства, в проекте Watson отвечал Дэвид Гондек.
Именно способность синтезировать различные источники фактических данных, чтобы выбрать один окончательный ответ, выводит Watson за рамки обычных поисковых интернет-систем и позволяет вступить на ранее недоступную территорию ответа на открытые вопросы. Вот более подробная схема того, как это работает:
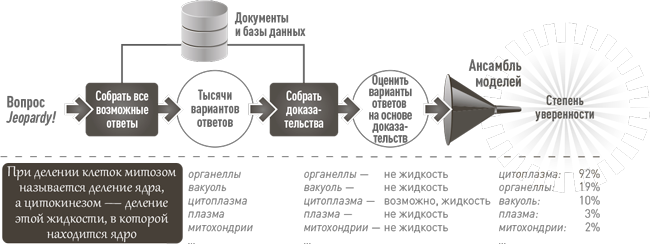
Как видите, сначала Watson находит все возможные ответы на вопрос, а затем собирает доказательства для каждого варианта. Далее ансамбль моделей оценивает каждый вариант по степени уверенности, что позволяет ранжировать их относительно друг друга. В качестве окончательного ответа Watson выбирает ответ с наивысшим уровнем уверенности — и зачитывает его на телеигре перед миллионами зрителей.
Применение ПА: поиск правильного ответа на открытый вопрос
- Предмет прогнозирования: оценить правильность ответа посредством прогнозирования правильности пары «вопрос/предполагаемый ответ».
- Цель прогнозирования: выявить предполагаемый ответ с наивысшей прогнозной оценкой вероятности и использовать его как окончательный ответ.
Ансамбль ансамблей
Дэвид руководил разработкой инновационных компонентов машинного обучения для Watson, неотъемлемой частью которых были ансамбли моделей. Переход от поиска документов к ответу на открытый вопрос требует значительного скачка, поэтому разработка была довольно сложным делом. Watson использует ансамбли моделей тремя способами:
- Объединение доказательств. Каждый предполагаемый ответ оценивается на основе имеющихся доказательств при помощи сотен различных методик. Вместо простого подсчета голосов путем суммирования этих оценок, как это делалось в ансамблях моделей, описанных в предыдущей главе, данный метод делает шаг вперед, обучая модель тому, как следует правильно сводить вместе эти доказательства.
- Специализированные модели для разных типов вопросов. Watson использует отдельные специализированные ансамбли моделей для разных типов вопросов, таких как загадка, вопрос со множеством вариантов ответа, вопросы, связанные с датами, цифрами, переводом и этимологией (историей и происхождением слов). Таким образом, Watson включает ансамбли ансамблей моделей.
- Итеративные фазы применения прогнозных моделей. Для каждого вопроса Watson применяет несколько фаз прогона через прогнозные модели, каждая из которых может компенсировать ошибки, допущенные в предыдущих фазах. Каждая фаза фильтрует варианты ответов и уточняет их доказательную оценку. Первая фаза сокращает количество вариантов ответов с нескольких тысяч до примерно одной сотни; последующие фазы отфильтровывают еще больше. После каждой фазы доказательные оценки оставшихся вариантов ответов пересматриваются и уточняются. Для каждой фазы разрабатывается отдельная прогнозная модель, цель которой — выверка и более точное ранжирование сокращенного списка возможных ответов. С учетом этих итеративных, т.е. многократных, фаз Watson включает в себя ансамбли ансамблей ансамблей моделей.
Успехи машинного обучения в обработке естественного языка
Несмотря на эту сложность, сами по себе прогнозные модели Watson довольно просты: они объединяют собранные доказательства путем взвешенного голосования. Таким образом, одни доказательства получают бóльший вес, другие — меньший. Хотя Дэвид Гондек протестировал различные методы моделирования, в том числе деревья решений (см. главу 4), он пришел к выводу, что наилучшие результаты дает метод, известный как логистическая регрессия, который определяет вес для каждой входной переменной (т.е. доказательства), складывает эти веса, а потом немного преобразует полученную сумму с использованием логистической кривой для получения более точной оценки.
Будучи построенным на основе весов, процесс моделирования фактически учится взвешивать доказательства для каждого предполагаемого ответа. Прогнозная модель отфильтровывает слабые варианты ответов, ставя им более низкие оценки. Другими словами, используемая Watson стратегия состоит не в выделении наиболее вероятных вариантов ответа, а в поэтапном отсеивании неподходящих вариантов, пока не останется один окончательный ответ.
Для достижения этой цели прогнозные модели Watson были обучены более чем на 5,7 млн примеров вопросов из игры Jeopardy! в паре с ответами. Каждый пример включает 550 предикторных переменных, соответствующих различным видам доказательств, собираемым для каждого ответа (следовательно, модель включает 550 весов, по одному на каждый предиктор). Такой большой массив обучающих данных был сформирован на основе 25 000 реальных вопросов игры Jeopardy!. Каждый вопрос участвует в нескольких обучающих примерах, поскольку используется не только правильный ответ, но и множество неправильных вариантов. Правильные и неправильные ответы обеспечивают ценный опыт, на котором модель учится правильно взвешивать доказательства.
Именно благодаря задействованию «эффекта ансамбля» Watson удается так далеко продвинуться в искусстве обработки естественного языка и добиться своей главной цели — научиться отвечать на открытые вопросы. И ключом к успешному объединению сотен используемых им методов обработки языка, разумеется, является обучение на массиве данных из архива игры Jeopardy!. Прогнозное моделирование позволяет оценить относительную силу и слабость различных методов. Другими словами, система определяет в количественном выражении, насколько значимы доказательства, полученные от разных методов — как сложных, затрагивающих глубокий лингвистический и семантический анализ, так и более простых, состоящих в обычном сопоставлении слов, чтобы результаты каждого метода были надлежащим образом учтены в процессе поиска ответа.
Благодаря такой архитектуре системы команда IBM имела возможность совершенствовать и развивать способности своего электронного детища в преддверии выступления в телешоу — и тем совершенствовать его «навыки» в области ответа на открытые вопросы. Система позволяет исследователям экспериментировать с постоянно растущим ассортиментом методов обработки естественного языка. Для этого нужно просто включить в систему новую технологию, которая собирает и обрабатывает доказательства для предполагаемых вариантов ответа, заново обучить ансамбли моделей и проверить, улучшилась ли эффективность системы.
Однако по мере того, как Дэвид и его команда увеличивали количество используемых методов сбора доказательств, эффект от их усилий снижался в соответствии с законом убывающей отдачи. Производительность системы улучшалась, но все более медленными темпами. Тем не менее они продолжали, стараясь выжать последние капли потенциала из машинного обучения и данных в последние недели перед великим состязанием.
Уверенность без излишней самоуверенности
И эксперты, и обычные люди склонны ошибочно принимать более уверенные прогнозы за более точные. Но чрезмерная уверенность часто ведет к фиаско. Если мы научимся лучше анализировать неопределенность, мы научимся составлять более точные прогнозы.
Проблема этого мира в том, что глупцы слишком уверены в себе, а умные люди полны сомнений.
Ты должен знать, когда держать карты, а когда сбрасывать.
Игра Jeoprardy! не рассчитана на игроков, не умеющих сомневаться.
Помимо умения отвечать на вопросы есть и второй важный навык, который должен развить у себя каждый игрок в Jeopardy!: умение адекватно оценивать свою уверенность. Почему? Потому что каждый неправильный ответ влечет за собой наказание. Услышав вопрос, игрок должен решить, стоит ли ему нажимать на кнопку и предлагать свой вариант ответа. Если он это сделает, то либо выиграет указанную сумму в случае правильного ответа, либо проиграет такую же сумму, если ошибется.
Таким образом, игра Jeopardy! отражает общее правило, действующее и в жизни, и в бизнесе: не нужно уметь делать хорошо всё подряд; нужно делать то, что вы хорошо умеете делать. Другими словами, выбирайте задачи, в которых у вас больше шансов преуспеть. На самом деле в основе коммерческого применения ПА часто лежит именно этот принцип. Точно так же, как Watson должен предсказать, на какие вопросы он сможет дать правильный ответ, компании прогнозируют, каким клиентам они смогут продать товар или услугу — и, следовательно, какие клиенты стоят маркетинговых расходов и усилий торговых агентов.
Но как может машина определить свою степень уверенности в ответе? Не заходим ли мы слишком далеко, требуя от нее «познать себя» в такой мере?
Дэвид Гондек показал, что эта проблема может быть решена «бесплатно». Та же оценка, что ставится вариантам ответов прогнозными моделями и помогает выбрать наиболее подходящий из них, может служить показателем степени уверенности в этом ответе. Эти оценки отражают вероятности. Например, если предполагаемый ответ с оценкой 0,85 имеет самый высокий балл среди всех вариантов, Watson выбирает его в качестве окончательного ответа, при этом оценивая свои шансы оказаться правым в 85%. Как выразилась команда IBM, «Watson знает, что он знает и чего он не знает».
Смотря по телевизору игру с участием Watson, вы можете увидеть эту систему в действии. Для каждого вопроса в нижней части телеэкрана показывается три лучших ответа, отобранных Watson, вместе с оценками степени уверенности (см., например, второй рисунок в этой главе). Watson принимает решение о том, стоит ли ему издавать звуковой сигнал и предлагать свой ответ, в зависимости от степени уверенности в правильности лучшего из найденных им ответов, а также от своего положения в игре относительно соперников. Если он отстает, он играет более агрессивно, предлагая свой вариант ответа даже при низком уровне уверенности. Если же Watson опережает соперников, он действует более консервативно, отвечая только в том случае, если достаточно уверен.
Успех игрока зависит не только от того, сколько ответов ему известно, но и от его умения адекватно оценить свою уверенность в ответе. Вот график, показывающий результативность игры различных игроков в Jeopardy!:
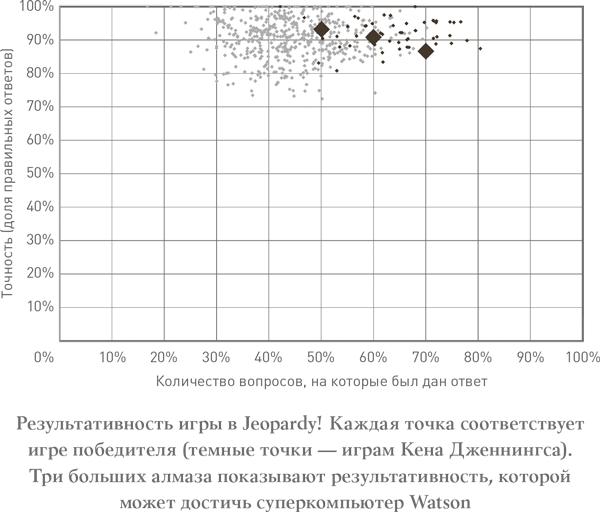
Как видите, игроки сосредоточились ближе к верхней правой части графика. На горизонтальной оси отражено, на какой процент вопросов от общего числа игрок попытался дать ответ; на вертикальной — как часто предложенные ответы оказывались правильными. Очевидно, что чем чаще вы нажимаете на кнопку, тем больше правильных ответов вы должны знать.
Игроки-победители в Jeopardy! демонстрируют очень высокую точность ответов, а некоторые — и довольно высокую частоту попыток. Каждая светло-серая точка отражает результативность победителя одной игры. Бросается в глаза расположение темно-серых точек, которые заходят вправо дальше других и показывают исключительную результативность чемпиона Кена Дженнингса, в 2004 году одержавшего победы в серии из 74 игр подряд. Он был одним из двух игроков, с которым суперкомпьютеру предстояло столкнуться в интеллектуальном поединке.
Watson почти не уступает людям. Три крупные точки (бриллианты) показывают потенциальную результативность, которой он может достичь. При необходимости суперкомпьютер может прибегнуть к более агрессивной тактике, увеличив частоту попыток и отвечая на вопросы даже при низкой степени уверенности в ответе. Это перемещает его на графике вправо и, как следствие, немного вниз. Или же он может играть более консервативно, пытаясь ответить на меньшее число вопросов, но зато чаще давая правильные ответы — тем самым повышая свою результативность (в отличие от политики, на этом графике консерваторы находятся слева).
Благодаря пролитому человеческому поту Watson достиг человеческого уровня эффективности. Мастерство машины является результатом четырех лет упорнейшего труда команды исследователей.
Жажда скорости
Имелось еще одно условие. Watson должен быть быстрым.
У игрока в Jeopardy! есть всего несколько секунд, чтобы ответить на вопрос, но у компьютера (например, на 2,6 ГГц) поиск ответа может занять несколько часов. Это длительный процесс, так как Watson использует сотни методов поиска по огромному количеству источников, чтобы найти как можно больше возможных ответов и собрать как можно больше доказательств. Затем ему нужно оценить все варианты ответов и ранжировать их при помощи прогнозных моделей (я имею в виду только работу Watson во время игры в Jeopardy!, когда процесс машинного обучения завершен и модели применяются непосредственно для получения результата, без дальнейшего обучения).
Чтобы сделать Watson в тысячи раз быстрее, его оснастили тысячами процессоров. Этот суперкомпьютер избавлен от узких мест и функционирует с молниеносной скоростью благодаря кластеру из 90 серверов, включающих 2800 процессорных ядер. Он выполняет 80 трлн операций в секунду, а общий объем оперативной памяти превышает 15 терабайт. Стоимость этого оборудования оценивается более чем в $3 млн, что составляет лишь незначительную часть расходов на разработку его аналитического программного мозга.
Наличие тысяч процессоров означает, что компьютер способен одновременно выполнять тысячи задач. Используемый Watson процесс замечательно подходит для такой конфигурации оборудования, позволяя задействовать его в полной мере путем распределения одновременно выполняемых подзадач, которые исследовательская группа считает естественно параллельными. Например, каждая подпрограмма, занимающаяся поиском доказательств и обработкой языка, может быть приписана к отдельному процессору.
Чем больше, тем лучше. Все это оборудование исследователи из IBM упаковали в гигантский шкаф величиной примерно в 10 холодильников. Учитывая такие размеры, не Watson пришел на игру Jeopardy!, а игра пришла к нему: в исследовательском центре IBM была создана временная телестудия.
Победит ли Watson?
Никто не был уверен в победе Watson. Во время пробных матчей с чемпионами-людьми Watson сумел выиграть 71% вопросов. Он не всегда побеждал; и к тому же во время телевизионной игры ему предстояло столкнуться лицом к лицу с куда более сильными соперниками — непревзойденными чемпионами за всю историю игры Кеном Дженнингсом и Брэдом Раттером.
Предстоящая игра находилась в центре внимания средств массовой информации. Высокорейтинговая викторина Jeopardy! ежедневно привлекает около 9 млн телезрителей, но этот матч человека против машины должен был собрать аудиторию в 34,5 млн человек. Столь массовая популярность игры Jeopardy!, хотя и была источником колоссального давления (вся страна должна была стать свидетелем триумфа или фиаско IBM), также была ключевым фактором, сделавшим эту грандиозную миссию выполнимой. Успешно на протяжении многих лет занимаясь популяризацией человеческих знаний, Jeopardy! накопила богатейшие запасы данных — пар «вопрос/ответ», на которых учился Watson.
Помимо того, чтобы впечатлить или разочаровать сидящих у экранов телезрителей, показанные Watson результаты имели и гораздо более серьезные последствия. Не страдая излишней скромностью, IBM делала громкие заявления о том, что готовится совершить прорыв как в сфере прикладных информационных технологий, так и в области исследований искусственного интеллекта. Принимая во внимание гигантские объемы инвестиций, легко представить, какому невероятному давлению подвергалась команда исследователей со стороны руководства IBM, которое требовало поддержать корпоративный имидж и не сделать компанию объектом публичного унижения. Исследователи понимали, что на кону стоит не только наука, но и их собственная научная карьера.

На стадии обучения Watson иногда делал очень смешные ошибки, которые тем не менее угрожали выставить IBM на посмешище на национальном телевидении. В категории «Королевский английский» на вопрос:

Watson ответил «помочиться» (правильный ответ «позвонить по телефону).
В категории «Заголовки The New York Times»:

Watson сказал «приговор» (правильный ответ «Первая мировая война»).
В категории «Боксерские термины»:

Watson ответил «Wang Bang» [в буквальном переводе — «удар в член», на сленге — «половое сношение»] (правильный ответ «low blow» — удар в пах).
Команда сплотила силы на финишной прямой. Руководитель проекта Watson Дэвид Феруччи заставил всех переехать из своих кабинетов в общее помещение, превратив его в подобие оперативного штаба, в котором царила напряженная, но в то же время чрезвычайно продуктивная атмосфера. Их жизнь была перевернута с ног на голову. Дэвид Гондек временно арендовал квартиру поближе к офису, чтобы не тратить время на поездки. Команда жила ответом на открытые вопросы. «Я думал о вопросах из Jeopardy! круглыми сутками, — говорит Гондек. — По ночам мне снились кошмары по поводу этих вопросов. Я даже с людьми разговаривал в форме вопросов».
Предстартовый мандраж
Нет такой вещи, как ошибка, вызванная человеческим фактором. Есть только системная ошибка.
Дженнифер Чу-Кэрролл, один из членов основной команды разработчиков Watson, пыталась сохранять спокойствие: «Мы знали, что можем выиграть, но… что если мы где-нибудь ошиблись с расчетами и проиграем хотя бы на один доллар?» Хотя у них была договоренность с продюсерами Jeopardy! о дублях в случае сбоя оборудования (игра шла в записи, а не в прямом эфире, а Watson, как и любой компьютер, иногда требует перезагрузки), если бы Watson дал нелепый ответ из-за ошибки в программном обеспечении без аппаратного сбоя, у разработчиков не было возможности исправить ситуацию. Это будет показано по национальному телевидению.
Испытание инновационной технологии, будь то в космосе или в области искусственного интеллекта, всегда сопряжено с высочайшим риском и не только потому, что исследователи смело идут туда, куда не ступала нога человека, но и потому, что они создают прототип. Космический аппарат «Аполлон-11», совершивший полет на Луну, не сошел с конвейера. Он был первым в своем роде. Система Watson, разработанная для игры в Jeopardy!, была бета-версией. Этот супермощный высокоскоростной исполин был создан не инженерами-программистами в рамках устоявшегося, отработанного процесса «производства» ПО для массового распространения, а теми же исследователями, которые разрабатывали и развивали его аналитические способности. С точки зрения программного обеспечения между экспериментальной и рабочей версией системы практически не было никакой разницы. Не было четкого разграничения между кодом, который использовался для итеративного, экспериментального улучшения системы посредством машинного обучения, и кодом в рабочей версии системы. Разумеется, это были ученые мирового класса, многие из которых имели опыт разработки программного обеспечения, но перед ними стояла беспрецедентная задача — при помощи виртуальных инструментов построить корабль, который позволит человечеству выйти в новое пространство высокоскоростного, осуществляемого в режиме реального времени автоматического ответа на любые непредвиденные вопросы.
Сменив лабораторные халаты на кепки программистов, команда исследователей из IBM работала в поте лица. Как сказал мне Дэвид Гондек, изменения в код Watson продолжали вноситься вплоть до последнего дня накануне великого матча, что было весьма неортодоксальным подходом в подготовке программного обеспечения к критически важному запуску. Никто в команде не хотел быть тем самым программистом, который перепутал в коде метрические и британские единицы измерения силы и тем самым обрушил на Марс летательный аппарат NASA Mars Climate Orbiter стоимостью $327,6 млн после его девятимесячного путешествия к Красной планете. Вспомните также историю конкурса Netflix Prize (см. главу 5), который был выигран двумя не-аналитиками, обнаружившими, что ключ к успеху кроется в их опыте профессиональных разработчиков ПО.
Команда исследователей затаила дыхание, наблюдая за тем, как Watson идет навстречу своей судьбе. Отключенный от Интернета и любого другого источника знаний, Watson отправился в самостоятельное плавание, всецело автономный и самодостаточный. Единственное, что ему требовалось, — подключение к электрической розетке. Всегда страшно смотреть, как ваш птенец вылетает из гнезда, ведь в жизни нет страховочной сети.
Наступил момент, когда Watson должен был доказать всему миру, что он имеет право именоваться не только «искусственным», но и «интеллектом».
За победу!
Сейчас вы станете очевидцем исторического состязания между человеком и машиной.
Если способность машины общаться на человеческом языке подходит под это определение, значит, 14 февраля 2011 года вниманию всего мира был представлен величайший прорыв в области искусственного интеллекта.
Как это принято в индустрии развлечений, столь беспрецедентный момент в истории науки был обставлен с грандиозной помпой в духе Голливуда. В конце концов, это было популистское событие. В определенном смысле Watson был первой в истории настоящей говорящей машиной, с которой человеку потенциально было гораздо проще установить контакт, чем с любым другим компьютером. Независимо от того, как они его воспринимали — как дружественного андроида из «Звездного пути» или электронного злодея HAL 9000 из «Космической одиссеи 2001 года», 34,5 млн человек включили телевизоры, чтобы посмотреть на состязание.
После того как отзвучала известная мелодия Jeopardy!, профессионально поставленный голос за кадром торжественно произнес: «Мы ведем трансляцию из Исследовательского центра имени Томаса Уотсона компании IBM в городе Йорктаун-Хейтс, штат Нью-Йорк. Это игра Jeopardy!. IBM принимает вызов!»
Сидя перед экранами телевизоров, мы с коллегами испытывали некоторый культурный шок: вместо ожидаемой нами демонстрации возможностей искусственного интеллекта мы видели чистой воды шоу-бизнес. Но это не было неожиданностью для сидевших в зрительном зале членов команды Watson, которые готовились к этой игре несколько лет.
Когда с формальностями было покончено и Watson представили публике, игра пошла своим ходом, как совершенно обычный матч, словно бы не было ничего экстраординарного в том, что одним из игроков был не обаятельный интеллектуал в костюме и галстуке, а робот с синтезированным голосом, похожий на персонажа фантастических фильмов.
Разумеется, для Дэвида Гондека и его коллег это было далеко не рядовым событием. Команда пережила очень нервный день во время записи шоу, за месяц до его показа по телевидению. За время матча, состоявшего из двух игр и транслировавшегося затем в течение трех дней, перед вами пролетали десятки вопросов. Когда камера поворачивалась к аудитории, чтобы показать ее реакцию, она фокусировалась на создателях машины — Дэвиде Феруччи, Дэвиде Гондеке, Дженнифер Чу-Кэрролл и других, которые то переживали моменты восторга, то терпели душевные муки.
В тот день машина восторжествовала над людьми. Watson правильно ответил на 66 вопросов, неправильно — на 8. Из этих восьми только ответ «Торонто» в категории «Города США» можно было считать ляпом по человеческим меркам. В этой главе приведены примеры вопросов, помеченные «*», на которые Watson ответил во время телеигры (на все эти вопросы компьютер ответил правильно, кроме того, где он дал ответ «Торонто»). Окончательный счет, измеряемый в Jeopardy! в долларах, составил: Watson — $77 147, Дженнингс — $24 000, Раттер — $21 600.
Давая ответ на последний вопрос матча, Кен Дженнингс процитировал известную фразу из фильма по рассказу Герберта Уэллса: «Я от лица всех землян приветствую наших новых компьютерных властителей». Позже он размышлял: «Watson имеет много общего с идеальным игроком в Jeopardy!: он очень умный, очень быстрый, абсолютно беспристрастен и никогда не знал прикосновений женщины».
После матча: слава, почести и награды
Я думал, что подобные технологии появятся лишь через много лет, но, как оказалось, они существуют уже сегодня. Я доказал это собственным уязвленным эго.
Для человечества это была игра на чужом поле, я понял это.
Возможно, нам следовало сделать его чуточку похуже.
Миллион долларов за первое место в игре Jeopardy!? Да (пожертвовано на благотворительные цели). Премия престижного конкурса American Technology Awards в номинации «Инновационная технология года»? Да. Премия журнала R&D «Новатор года»? Да. Международная интернет-премия Webby в номинации «Человек года»? Неожиданно, но факт. Собирая урожай всевозможных премий и наград, исследователи IBM продолжали работать над Watson. Теперь они меняли его компоновку и затачивали архитектуру его вопросно-ответной системы DeepQA под использование в медицинской и финансовой сферах. Возьмем медицинскую диагностику. Учитывая все богатство накопленных письменных знаний, ни один врач не в состоянии овладеть ими в полном объеме. Следовательно, предоставление врачу ранжированного списка возможных диагнозов для каждого пациента снижает вероятность того, что врач может упустить из виду правильный диагноз. Анализ источников знаний на основе обучения на примерах — ответов в игре Jeopardy! или медицинских диагнозов — есть способ «обеспечить и формализовать использование знаний для принятия решений», как выразился Роберт Джуэлл из IBM Watson Solutions.
«Ямбический искусственный интеллект от IBM»
Разумен ли Watson? Вопрос предполагает, что речь идет прежде всего о научном понимании разума. Активные приверженцы искусственного интеллекта часто совершают ошибку, чрезмерно превознося его возможности и наделяя «душой». Людям свойственно выискивать глубокий смысл там, где его нет. Вот вам наглядный пример: читая курс по искусственному интеллекту в Колумбийском университете, я разработал приложение для генерации палиндромов (фраз-перевертышей, одинаково читающихся в обоих направлениях). Одним из палиндромов, случайно сгенерированным программой, был «Iambic IBM AI» — «ямбический искусственный интеллект от IBM». Эта фраза имеет дополнительный смысл, поскольку у нее действительно ямбический ритм.
Некоторые склонны приписывать Watson поистине невероятные умственные способности. Однажды, когда Дэвид Гондек выходил из здания исследовательского центра IBM, его остановил охранник. «Если ваша машина может ответить на любой вопрос, — сказал он, — почему бы не спросить у нее, кто убил президента Кеннеди?»
Как ни странно, даже технари-специалисты при ответе на этот философский вопрос обычно высказывают весьма предвзятые мнения с уклоном в ту или иную сторону. Речь идет не о том, правильно это или нет. Подобные философские рассуждения есть не более чем игра, приятное упражнение для ума. Позвольте же и мне поучаствовать в этом развлечении. Вот мои мысли:
Наблюдая за тем, как Watson лихо выдает ответ за ответом на самые разнообразные вопросы, включающие абстрактные рассуждения, метафоры и тонкие каламбуры, я остолбенел. Впервые в жизни я почувствовал, что готов в значительной степени очеловечить машину, отбросить свое всегдашнее недоверие и поверить в чудо. На мой взгляд, Watson мастерски оперирует не только информацией, но и знаниями. С точки зрения моего восприятия он наделен определенной способностью к размышлению. Честно признаться, я не предполагал, что когда-либо в своей жизни испытаю подобное чувство. Для меня Watson — это первый настоящий искусственный интеллект.
Если вы еще не сделали этого, я призываю вас посмотреть игру Jeopardy! с участием Watson.
Прогнозируйте правильные вещи
Прогнозные модели совершенствуются и раскрывают свой потенциал, но иногда прогнозирование того, что случится в будущем, не решает проблемы. Часто организации нужно решить, какие действия она должна предпринять. Она хочет знать не только то, что будут делать люди, но и что ей с этим делать. Следовательно, нам нужно предсказать не будущие события, а нечто совершенно другое. Что именно, вы узнаете в следующей главе.


