Глава 11. Служба с состоянием
Для распределенных приложений, имеющих хранимое состояние, требуются: неизменность идентификации, постоянные сетевые координаты, хранилище и упорядоченность. Паттерн Stateful Service (Служба с состоянием) описывает примитив StatefulSet, предлагающий все эти строительные блоки с надежными гарантиями, который идеально подходит для управления приложениями с состоянием.
Задача
К настоящему моменту мы познакомились со многими примитивами Kubernetes для создания распределенных приложений: контейнерами с поддержкой проверки работоспособности и ограничения ресурсов, группами контейнеров (подами), механизмом динамического размещения подов в пределах кластера, пакетными заданиями, инструментами планирования заданий, подами-одиночками и многими другими. Все эти примитивы характеризует одна общая черта: они рассматривают управляемое приложение как приложение без сохранения состояния, сконструированное из идентичных взаимозаменяемых контейнеров и соответствующее принципам методологии «Двенадцать факторов».
Наличие платформы, решающей задачи размещения, отказоустойчивости и масштабировании приложений без состояния, дает значительное преимущество, однако не менее важной является поддержка приложений с состоянием, каждый экземпляр которых уникален и имеет свои характеристики.
В реальном мире за каждой масштабируемой службой без состояния стоит служба с состоянием, обычно в форме некоторого хранилища данных. На ранних этапах развития Kubernetes, когда еще отсутствовала поддержка приложений с состоянием, эта проблема решалась путем размещения приложений без состояния в Kubernetes, а компонентов с состоянием — вне кластера, в общедоступном облаке или на локальном аппаратном обеспечении, управляемом с помощью традиционных, не облачных механизмов. Учитывая, что каждое предприятие имеет множество приложений с состоянием (устаревших и современных), отсутствие их поддержки считалось существенным ограничением Kubernetes, известной как универсальная облачная платформа.
Но какие типичные требования предъявляются приложениями с состоянием? Мы можем развернуть приложение с состоянием, такое как Apache ZooKeeper, MongoDB, Redis или MySQL, используя: развертывание Deployment, которое создает набор реплик ReplicaSet с параметром replicas = 1, чтобы обеспечить надежность приложения; службу Service для поддержки обнаружения его конечной точки; и PersistentVolumeClaim с PersistentVolume в роли хранилища для состояния.
В общем и целом это верно для приложения с состоянием, действующего в единственном экземпляре, но не совсем, потому что ReplicaSet не гарантирует семантику «не больше одного экземпляра», и количество реплик может увеличиваться на короткие промежутки времени. Это может иметь катастрофические последствия и приводить к потере данных. Кроме того, серьезные проблемы могут возникать в случае с распределенными службами с состоянием, состоящим из нескольких экземпляров. Приложение с состоянием, включающее несколько кластерных служб, требует от базовой инфраструктуры разносторонних гарантий. Рассмотрим некоторые из наиболее распространенных требований, предъявляемых распределенными приложениями с сохранением состояния.
Хранилище
Мы можем увеличить количество реплик в ReplicaSet и получить распределенное приложение с состоянием. Но как определить требования к хранилищу в таком случае? Обычно для распределенного приложения с состоянием, такого как упомянутое выше, требуется выделенное постоянное хранилище для каждого экземпляра. Набор реплик ReplicaSet с параметром replicas = 3 и определением PersistentVolumeClaim (PVC) приведет к тому, что все три пода будут подключены к одному и тому же постоянному тому PersistentVolume (PV). ReplicaSet и PVC гарантируют лишь запуск требуемого числа экземпляров и подключение хранилища к узлам, где действуют эти экземпляры, но само хранилище не является выделенным, а совместно используется всеми экземплярами пода.
Решить проблему общего хранилища для всех экземпляров можно, реализовав механизм деления хранилища на сегменты и бесконфликтного их использования внутри самого приложения. Однако в этом случае создается единая точка отказа с единственным хранилищем. Кроме того, такой подход подвержен ошибкам из-за изменения количества подов в процессе масштабирования и может вызвать серьезные сложности в реализации предотвращения повреждения или потери данных во время масштабирования.
Другое решение — создание отдельного набора реплик ReplicaSet (с replicas = 1) для каждого экземпляра распределенного приложения с состоянием. В этом сценарии каждый набор ReplicaSet получает свой запрос постоянного тома PVC и выделенное хранилище. Недостаток этого подхода — необходимость большого объема ручного труда: для масштабирования придется создать новый набор определений ReplicaSet, PVC или Service. В этом подходе не хватает всего одной абстракции, управляющей всеми экземплярами приложения с состоянием как единым целым.
Постоянные сетевые координаты
Кроме хранилища, распределенное приложение с состоянием требует постоянной идентификации в Сети. В дополнение к внутренним данным приложение с состоянием хранит такие сведения, как имя хоста и информация о соединениях со своими партнерами. То есть каждый экземпляр должен быть достижим по определенному адресу, который не должен динамически меняться, как IP-адреса подов в ReplicaSet. Это требование можно было бы удовлетворить с помощью обходного решения: создать Service и установить replicas = 1 в ReplicaSet. Однако управление такой комбинацией должно осуществляться вручную, и само приложение не может полагаться на постоянство имени хоста, поскольку оно будет меняться после каждого перезапуска, а также ему будет неизвестно имя службы Service, открывающей доступ к нему.
Идентичность
Как следует из предыдущих требований, кластерные приложения с состоянием сильно зависят от наличия постоянных сетевых координат и выделенного долговременного хранилища для каждого экземпляра, потому что каждый экземпляр приложения с состоянием уникален и имеет свою идентичность, основными компонентами которой являются долговременное хранилище и сетевые координаты. К этому списку также можно добавить идентификатор/имя экземпляра (для некоторых приложений с состоянием требуются уникальные постоянные имена), которое в Kubernetes будет именем пода. Поды, созданные с помощью ReplicaSet, получают произвольные имена и не сохраняют их после перезапуска.
Упорядоченность
Кроме уникальной и долговременной идентификации, экземпляры кластерных приложений с состоянием имеют фиксированное положение в их коллекциях. Обычно это положение влияет на последовательность масштабирования экземпляров вверх и вниз, но также может использоваться для распределения данных, блокировки или выбора ведущего экземпляра.
Другие требования
Постоянное и долговременное хранилище, постоянство сетевых координат и упорядоченность — все это типичные требования, предъявляемые кластерными приложениями с состоянием. Но управление приложениями с состоянием предъявляет также множество других специфических требований, которые меняются от случая к случаю. Например, некоторые приложения поддерживают понятие кворума и требуют постоянного присутствия некоторого минимального количества экземпляров; некоторые из них требуют последовательного развертывания экземпляров, тогда как другие поддерживают параллельное развертывание; некоторые допускают наличие дубликатов экземпляров, а некоторые нет. Предусмотреть все эти уникальные требования и предоставить универсальный механизм просто невозможно, поэтому Kubernetes также позволяет создавать определения нестандартных ресурсов и операторов для управления приложениями с состоянием. Об операторах мы поговорим в главе 23.
Выше были перечислены некоторые типичные проблемы управления распределенными приложениями с состоянием и ряд не самых лучших вариантов их решения. А теперь давайте рассмотрим механизм, имеющийся в Kubernetes, помогающий удовлетворить эти требования, — примитив StatefulSet.
Решение
Чтобы объяснить, что предлагает StatefulSet для управления приложениями с состоянием, мы периодически будем сравнивать его с уже знакомым примитивом ReplicaSet, который в Kubernetes используется для выполнения приложений без состояния. Можно провести такую аналогию: примитив StatefulSet предназначен для управления домашними любимцами, а ReplicaSet — для управления домашним скотом. Домашние любимцы и скот — известная (хотя и неоднозначная) аналогия в мире DevOps: идентичные и взаимозаменяемые серверы называются скотом, а незаменимые уникальные серверы, требующие индивидуального ухода, называются домашними любимцами. Аналогично, примитив StatefulSet (первоначально основанный на этой аналогии и названный набором любимцев PetSet) предназначен для управления уникальными модулями, тогда как ReplicaSet предназначен для управления идентичными взаимозаменяемыми подами.
Давайте рассмотрим, как работают StatefulSet и как они удовлетворяют потребности приложений с состоянием. В листинге 11.1 приводится определение нашей службы генератора случайных чисел в форме StatefulSet.
Листинг 11.1. Служба Service для доступа к StatefulSet
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: rg
spec:
serviceName: random-generator
replicas: 2
selector:
matchLabels:
app: random-generator
template:
metadata:
labels:
app: random-generator
spec:
containers:
- image: k8spatterns/random-generator:1.0
name: random-generator
ports:
- containerPort: 8080
name: http
volumeMounts:
- name: logs
mountPath: /logs
volumeClaimTemplates:
- metadata:
name: logs
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 10Mi
Имя набора StatefulSet используется как префикс при создании имен узлов.
Ссылка на обязательную службу Service, которая определена в листинге 11.2.
Два пода с именами ng-0 и ng-1, являющихся членами набора StatefulSet.
Паттерн создания PVC для каждого пода (подобно паттерну пода).
Мы не будем подробно разбирать листинг 11.1, а исследуем только общее его поведение и гарантии этого определения StatefulSet.
Хранилище
Большинство приложений с состоянием хранят некоторую информацию и поэтому требуют выделенного постоянного хранилища для каждого экземпляра. Настройка и связывание постоянного хранилища с подом в Kubernetes производится посредством PV и PVC. Для создания PVC вместе с подом StatefulSet использует элемент volumeClaimTemplates. Это дополнительное свойство является одним из основных отличий StatefulSet от примитива ReplicaSet, который имеет элемент persistentVolumeClaim.
Вместо ссылки на предопределенный PVC StatefulSet динамически создает PVC с помощью volumeClaimTemplates во время создания пода. Благодаря этому каждый под получает свой выделенный PVC во время создания, а также во время масштабирования вверх, при изменении счетчика replicas в StatefulSet.
Как вы, наверное, заметили, мы говорили, что PVC создаются и связываются с подами, но мы ничего не сказали о PV. Дело в том, что примитив StatefulSet никак не управляет PV. Хранилище для подов должно быть заранее выделено администратором или провайдером PV на основе запрошенного класса хранения и готово для использования подами с состоянием.
Обратите внимание на асимметричное поведение: масштабирование StatefulSet вверх (увеличение счетчика replicas) создает новые поды и связанные с ними PVC. При масштабировании вниз поды удаляются, но PVC (и PV) никуда не исчезают, то есть постоянные тома PV не утилизируются и не удаляются, и Kubernetes не может освободить хранилище. Такое поведение основано на предположении, что хранилища для приложений с состоянием имеют важнейшее значение и периодическое масштабирование вниз не должно приводить к потере данных. Если вы уверены, что приложение с состоянием было остановлено специально и скопировало/передало свои данные другим экземплярам, то можете удалить PVC вручную, что позднее позволит повторно использовать соответствующий постоянный том PV.
Постоянные сетевые координаты
Каждый под, созданный контроллером StatefulSet, имеет постоянные и неизменные сетевые координаты, генерируемые на основе имени набора StatefulSet и порядкового индекса (начиная с 0). Так, предыдущий пример создаст два пода с именами rg-0 и rg-1. Для генерации имен подов используется четко установленный формат, который отличается от формата в ReplicaSet, основанного на добавлении случайного окончания.
Постоянные сетевые координаты являются такой же неотъемлемой чертой приложений с состоянием, как и наличие постоянного хранилища.
В листинге 11.2 определяется автономная (headless) служба Service. Параметр clusterIP: None здесь означает, что мы не хотим, чтобы эта служба обслуживалась маршрутизатором kube-proxy, выделяла IP-адреса из диапазона адресов кластера или балансировала нагрузку. Возникает вопрос: зачем нужна эта служба?
Листинг 11.2. Служба Service для организации доступа к StatefulSet
apiVersion: v1
kind: Service
metadata:
name: random-generator
spec:
clusterIP: None
selector:
app: random-generator
ports:
- name: http
port: 8080
Объявление службы автономной.
Поды без состояния, созданные с помощью ReplicaSet, идентичны, и поэтому для системы безразлично, кому из них передать запрос (балансировка нагрузки выполняется с помощью обычной службы Service). Но поды с состоянием отличаются друг от друга, и иногда важно, чтобы запрос попал в определенный под с определенными координатами.
Автономная служба Service с селекторами (здесь .selector.app == random-generator) позволяет это сделать. Такая служба создает записи конечных точек Endpoint на API Server и записи A (адреса) в DNS, которые указывают непосредственно на поды, поддерживающие службу Service. Проще говоря, для каждого пода создается своя уникальная запись DNS, благодаря чему клиенты получают возможность напрямую связаться с ними. Например, если предположить, что наша служба random-generator принадлежит пространству имен default, мы можем связаться с подом rg-0, используя его полное доменное имя: rg-0.random-generator.default.svc.cluster.local, где имя пода добавляется в начало доменного имени службы. Такой формат позволяет другим компонентам кластерного приложения или другим клиентам напрямую обращаться к определенным подам.
Мы также можем выполнить поиск записей SRV в DNS (например, командой dig SRV random-generator.default.svc.cluster.local) и отыскать все работающие поды, зарегистрированные в управляющей службе Service, в наборе StatefulSet. Этот механизм позволяет любым приложениям динамически обнаруживать члены кластера. Связь между автономной службой Service и StatefulSet определяется не только селектором, но и ссылкой на имя службы в StatefulSet, в данном случае serviceName: "random-generator".
Наличие выделенного хранилища, определяемого параметром volumeClaimTemplates, не является обязательным, но ссылка на службу в поле serviceName должна быть определена всегда. Управляющая служба Service должна существовать до создания набора StatefulSet и отвечает за его сетевую идентификацию. При необходимости вы можете создать другие типы служб, которые дополнительно осуществляют балансировку нагрузки между подами с состоянием.
Как показано на рис. 11.1, наборы StatefulSet предлагает множество строительных блоков и гарантированный порядок управления приложениями с состоянием в распределенной среде, которые можно выбирать и использовать значимым для вас способом.
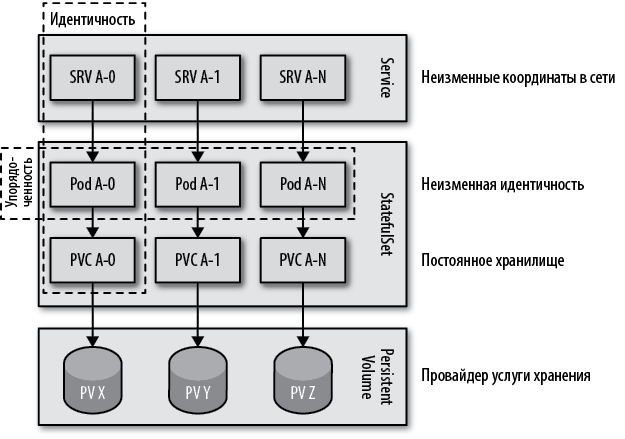
Рис. 11.1. Распределенное приложение с состоянием в Kubernetes
Идентичность
Идентичность — фундамент, на котором основываются все остальные гарантии контроллера StatefulSet. Опираясь на имя StatefulSet, можно получить имя пода и его идентичность. Используя эту идентичность, можно определить имена PVC, обращаться к конкретными подам через автономные службы Service и т.д. Идентичность любого пода известна еще до его создания, и это знание можно использовать в самом приложении.
Упорядоченность
Распределенное приложение с состоянием по определению состоит из нескольких уникальных и невзаимозаменяемых экземпляров. Кроме их уникальности, экземпляры также могут быть связаны друг с другом порядком их создания, в соответствии с требованием упорядоченности.
С точки зрения StatefulSet упорядоченность важна только для масштабирования. Поды имеют имена, включающие порядковый индекс в конце (начиная с 0), и порядок их создания определяет порядок, в котором они масштабируются вверх и вниз (при масштабировании вниз поды останавливаются в обратном порядке следования их индексов, от n — 1 до 0).
Когда определяется ReplicaSet с несколькими репликами, поды планируются и запускаются все вместе, не дожидаясь успешного запуска предыдущих подов (под успешным запуском подразумевается переход в состояние готовности, как описывается в главе 4 «Проверка работоспособности»). Порядок запуска подов и их переход в состояние готовности не гарантируется. То же происходит, когда происходит масштабирование ReplicaSet вниз (изменением счетчика replicas или удалением набора). Все поды, принадлежащие ReplicaSet, начинают останавливаться одновременно без какого-либо порядка. Такое поведение обеспечивает быструю остановку, но может оказаться нежелательным для приложений с состоянием, особенно если имеют место фрагментирование и распределение данных между экземплярами.
Чтобы обеспечить надлежащую синхронизацию данных в процессе масштабирования вверх или вниз, StatefulSet по умолчанию выполняет запуск и остановку подов последовательно. Это означает, что поды запускаются, начиная с первого (с индексом 0), и каждый последующий запускается только после успешного запуска предыдущего. Масштабирование вниз выполняется в обратном порядке: сначала останавливается под с самым большим индексом, и только после успешной остановки начинается остановка пода со следующим индексом в порядке убывания. Так продолжается, пока не остановится под с индексом 0.
Другие особенности
StatefulSet обладает еще целым рядом характеристик, которые можно настраивать в соответствии с потребностями приложений с состоянием. Каждое приложение с состоянием является уникальным и требует внимательного исследования перед попыткой вписать его в модель StatefulSet. Давайте рассмотрим еще несколько возможностей Kubernetes, которые могут пригодиться при работе с приложениями с состоянием.
Раздельное обновление
Мы описали выше гарантии упорядочения при масштабировании подов в StatefulSet. Для обновления запущенных приложений с состоянием (например, изменением параметра .spec.template), StatefulSet поддерживает поэтапное (такое, как канареечное) развертывание и гарантирует выполнение определенного количества экземпляров, пока обновления будут применяться к остальной части экземпляров.
Организовать раздельное обновление экземпляров при использовании стратегии по умолчанию поэтапного обновления можно, указав число в параметре .spec.updateStrategy.rollingUpdate.partition. Этот параметр (со значением по умолчанию 0) определяет порядковый номер, по которому следует разделить StatefulSet для обновления. Если параметр указан, обновятся все поды с индексами большими или равными значению partition, а остальные — нет. Это относится даже к остановленным подам; Kubernetes воссоздаст их в предыдущей версии. Это позволяет обновить сначала одну часть кластерного приложения с состоянием (например, чтобы гарантировать наличие кворума), а затем развернуть изменения в остальной части кластера, записав в параметр partition значение 0.
Параллельное развертывание
Когда параметру .spec.podManagementPolicy присваивается значение Parallel, контроллер StatefulSet запускает или завершает работу всех подов одновременно, не дожидаясь готовности или полной остановки предыдущего пода, прежде чем перейти к следующему. Если приложение не требует последовательной обработки, эта настройка может ускорить запуск или остановку.
Гарантированная семантика «не больше одного»
Уникальность — одно из фундаментальных свойств экземпляров приложений с состоянием, и Kubernetes гарантирует, что никакие два пода в StatefulSet не будут иметь одинаковую идентичность или не будут привязаны к одному постоянному тому PV. Контроллер ReplicaSet, напротив, поддерживает семантику «гарантированного выполнения не менее X экземпляров одновременно». Например, ReplicaSet с двумя репликами стремится постоянно иметь не менее двух действующих экземпляров. Главная цель контроллера — не допустить уменьшения количества подов ниже заданного числа, даже ценой его увеличения в какие-то промежутки времени. При замене старого пода новым одновременно может выполняться большее число реплик, чем указано, когда новый под уже запустился, а старый еще не остановился полностью. Также число реплик может увеличиться, если узел Kubernetes будет классифицирован как недоступный с состоянием NotReady, но на нем все еще будут действовать ранее запущенные поды. В этом случае контроллер ReplicaSet запускает новые поды на исправных узлах, что может привести к увеличению числа работающих подов. Все это приемлемо в семантике не менее X экземпляров.
Контроллер StatefulSet, напротив, делает все возможное, чтобы гарантировать отсутствие дубликатов подов, то есть семантику «не более одного». Он не запустит под, пока не убедится, что старый экземпляр полностью остановлен. Когда узел выходит из строя, он планирует запуск новых подов на другом узле только после того, как Kubernetes подтвердит, что поды (и, возможно, весь узел) остановлены. Семантика не более одного, поддерживаемая контроллером StatefulSet, диктует эти правила.
Контроллер StatefulSet может нарушить эти гарантии и запустить дубликаты подов только при активном вмешательстве человека. Например, эту гарантию может нарушить удаление объекта ресурса недоступного узла из API Server, пока физический узел продолжает работать. Такое действие должно выполняться, только если подтвердится, что узел не работает или выключен и на нем не запущены процессы пода. К нарушению гарантий может также привести принудительное удаление пода командой kubectl delete pods _<pod>_ --grace-period = 0 --force, которая не ждет подтверждения остановки пода от Kubelet. Это действие немедленно удалит информацию о поде из API Server и заставит контроллер StatefulSet запустить заменяющий экземпляр пода, что может привести к дублированию.
Другие подходы для организации выполнения подов в единственном экземпляре обсуждаются в главе 10 «Служба-одиночка».
Пояснение
В этой главе мы рассмотрели некоторые стандартные требования и проблемы управления распределенными приложениями с состоянием. Мы выяснили, что организовать выполнение единственного экземпляра приложения с состоянием относительно просто, но обслуживание распределенного состояния — это сложная и многоплановая задача. Обычно мы связываем понятие «состояние» с понятием «хранилище», однако здесь мы увидели, что состояние может иметь несколько аспектов и разные приложения с состоянием могут требовать разных гарантий. В этом отношении контроллер StatefulSet является отличным средством для реализации распределенных приложений с состоянием. Он учитывает необходимость постоянного хранилища, работы в Сети (через сервисы), поддержки идентичности, упорядоченности и некоторых других аспектов. Он предлагает хороший набор строительных блоков для автоматического управления приложениями с состоянием и превращает их в полноправных граждан облачного мира.
Контроллеры StatefulSet дают хорошее начало, но мир приложений с состоянием уникален и сложен. Кроме приложений с состоянием, разработанных для выполнения в облаке, которые прекрасно вписываются в StatefulSet, существует масса устаревших приложений, разработанных для выполнения в обычном, не облачном, окружении и предъявляющих еще более широкие требования. К счастью, фреймворку Kubernetes есть чем ответить на это. В сообществе Kubernetes давно поняли, что вместо моделирования различных рабочих нагрузок с помощью ресурсов Kubernetes и реализации их поведения с использованием универсальных контроллеров предпочтительнее позволить пользователям реализовать свои контроллеры и даже дать им возможность моделировать ресурсы приложений с помощью своих определений ресурсов и поведения с помощью операторов.
В главах 22 и 23 вы познакомитесь с соответствующими паттернами Controller (контроллер) и Operator (Оператор), которые с успехом можно использовать для управления сложными приложениями с состоянием в облачных окружениях.
Дополнительная информация
• Пример службы с состоянием (http://bit.ly/2Y7SUN2).
• Основы StatefulSet (http://bit.ly/2r0boiA).
• Документация с описанием StatefulSet (http://bit.ly/2HGm6oE).
• Развертывание Cassandra в StatefulSet (http://bit.ly/2HBLNXA).
• Запуск координатора распределенной системы ZooKeeper (http://bit.ly/2JmNPNQ).
• Автономные службы Service (http://bit.ly/2v7Z19P).
• Принудительное удаление подов в StatefulSet (http://bit.ly/2OeuRrh).
• Правильное масштабирование вниз приложений с состоянием в Kubernetes (http://bit.ly/2Fk0mgK).
• Настройка и развертывание приложений с состоянием (http://bit.ly/2UsbkJt).
Предположим, что мы изобрели очень сложный способ получения случайных чисел в распределенном кластере RNG с несколькими экземплярами нашей службы в роли узлов. Конечно, это не так, но для примера это достаточно хорошая предпосылка.

