Глава 12. Обнаружение служб
Паттерн Service Discovery (Обнаружение служб) предлагает постоянную конечную точку, с помощью которой клиенты могут получить доступ к экземпляру требуемой службы. Для этого Kubernetes поддерживает несколько механизмов, которые используются в разных конфигурациях, в зависимости от того, где располагаются службы и их потребители — в кластере или за его пределами.
Задача
Приложения, развернутые в Kubernetes, редко существуют сами по себе и обычно взаимодействуют с другими службами внутри кластера или с системами вне кластера. Взаимодействие может быть инициировано изнутри или извне. Взаимодействия, инициируемые изнутри, обычно выполняются методом опроса: приложение, сразу после запуска или позднее, подключается к другой системе и начинает посылать и получать данные. Типичным примером может служить приложение, запущенное в поде, которое устанавливает соединение с файловым сервером и начинает использовать файлы на нем, или подключается к брокеру сообщений и начинает получать либо отправлять сообщения, или соединяется с реляционной базой данных либо хранилищем пар ключ/значение и начинает читать или писать данные.
Важная отличительная особенность здесь заключается в том, что приложение, запущенное в поде, решает в какой-то момент открыть исходящее соединение с другим подом или внешней системой и начинает обмен данными. В этом сценарии взаимодействия инициируются изнутри, и для приложения не нужны никакие дополнительные настройки в Kubernetes.
Этот подход часто используется для реализации паттернов, описанных в главе 7 «Пакетное задание» или в главе 8 «Периодическое задание». Кроме того, к другим системам иногда активно подключаются поды, действующие под управлением DaemonSet или ReplicaSet. Однако в Kubernetes наиболее распространен вариант, когда в кластере имеются службы, ожидающие соединений, чаще всего в форме входящих HTTP-соединений, от других подов в кластере или внешних систем. В этих случаях потребителям услуг необходим механизм для обнаружения подов, которые динамически размещаются планировщиком на узлах и иногда масштабируются вверх и вниз.
Это было бы серьезной проблемой, если бы нам пришлось самим отслеживать, регистрировать и искать конечные точки динамических подов в Kubernetes. Вот почему Kubernetes реализует паттерн Service Discovery (Обнаружение служб) с помощью различных механизмов, которые мы рассмотрим в этой главе.
Решение
В эпоху до появления Kubernetes наиболее распространенным механизмом обнаружения служб было обнаружение на стороне клиента. Когда потребителю требовалось обратиться к службе, которая может масштабироваться до нескольких экземпляров, потребитель должен был иметь агента обнаружения, способного отыскать в реестре экземпляры службы и выбрать один из них. Это решение может быть реализовано, например, с помощью встроенного агента (такого, как клиент ZooKeeper, клиент Consul или Ribbon) или с помощью другого процесса, такого как Prana, предназначенного для поиска службы в реестре, как показано на рис. 12.1.
В эпоху после появления Kubernetes многие функции распределенных систем, такие как размещение, проверка и восстановление работоспособности, изоляция ресурсов, а также обнаружение служб и балансировка
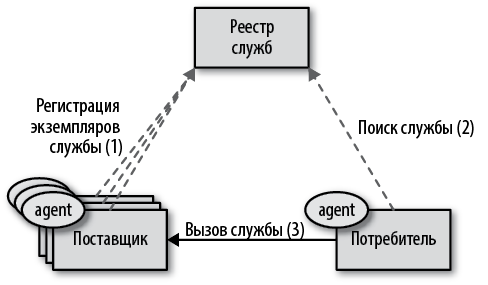
Рис. 12.1. Обнаружение служб на стороне клиента
нагрузки, были переложены на плечи платформы. Если использовать определения из сервис-ориентированной архитектуры (Service-Oriented Architecture, SOA), поставщик должен регистрировать каждый экземпляр в реестре, а потребитель должен обращаться к реестру, чтобы получить доступ к сервису.
В мире Kubernetes все это происходит за кулисами, поэтому потребитель службы вызывает фиксированную конечную точку виртуальной службы Service, которая динамически отыскивает экземпляры службы, реализованные в виде подов. На рис. 12.2 показано, как происходят регистрация и поиск в Kubernetes.
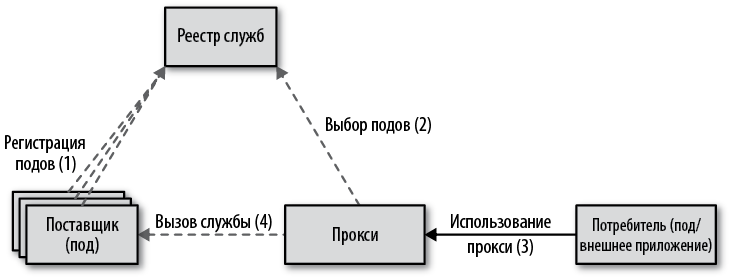
Рис. 12.2. Обнаружение служб на стороне сервера
На первый взгляд паттерн Service Discovery (Обнаружение служб) может показаться простым. Однако для его реализации можно использовать несколько механизмов в зависимости от того, где находится поставщик или потребитель — внутри кластера или за его пределами.
Обнаружение внутренних служб
Предположим, у нас есть веб-приложение и мы хотим запустить его в Kubernetes. Как только мы определим контроллер развертывания Deployment с несколькими репликами, планировщик разместит поды на подходящих узлах, и каждый из них получит IP-адрес кластера, назначенный до запуска. Если другая клиентская служба в другом модуле пожелает обратиться к конечным точкам веб-приложения, у нее не будет простого способа заранее узнать IP-адреса подов с приложением.
В Kubernetes эту проблему решает ресурс Service. Он организует постоянную точку входа для коллекции подов с одинаковой функциональностью. Самый простой способ создать Service — выполнить команду kubectl expose, которая создаст Service для пода или нескольких подов в Deployment или ReplicaSet. Команда создаст виртуальный IP-адрес, который запишет в параметр clusterIP, и извлечет из ресурсов селекторы подов и номера портов, чтобы создать определение службы Service. Однако чтобы получить более полный контроль, лучше создать определение Service вручную, как показано в листинге 12.1.
Листинг 12.1. Простая служба Service
apiVersion: v1
kind: Service
metadata:
name: random-generator
spec:
selector:
app: random-generator
ports:
- port: 80
targetPort: 8080
protocol: TCP
Селектор, описывающий метки соответствующих ему подов.
Порт, через который доступна эта служба Service.
Порт, который прослушивают поды.
Этот пример определяет службу Service с именем random-generator (имя потребуется позже для обнаружения) и типом type: ClusterIP (по умолчанию), которая принимает TCP-соединения через порт 80 и направляет их в порт 8080 всех соответствующих подов с селектором app: random-generator. Неважно, когда и как создаются поды, — любой под, соответствующий селектору, становится целью маршрутизации, как показано на рис. 12.3.
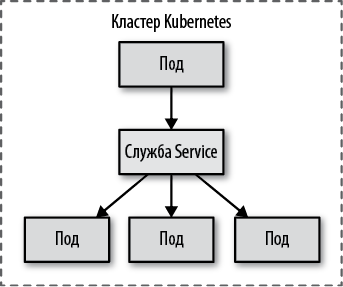
Рис. 12.3. Обнаружение внутренней службы
Важно помнить, что после создания службы Service она получит clusterIP, доступный только внутри кластера Kubernetes (на что указывает имя параметра), и этот IP-адрес остается неизменным, пока существует определение службы. Но как другие приложения в кластере смогут определить этот динамически распределенный clusterIP? В их распоряжении есть два способа:
Через переменные окружения
Запуская поды, Kubernetes заполняет их переменные окружения сведениями обо всех службах Service, действовавших до этого момента. Например, наша служба random-generator, прослушивающая порт 80, будет внедряться во все вновь запускаемые поды через переменные окружения, как показано в листинге 12.2. Приложение, выполняющееся в этом поде, сможет узнать, какое имя службы использовать, обратившись к своим переменным окружения. Этот простой механизм поиска можно использовать в приложениях, написанных на любом языке, а кроме того, его легко сымитировать за пределами кластера Kubernetes для целей разработки и тестирования. Основной проблемой этого механизма является временная зависимость от создания службы Service. Поскольку переменные среды нельзя добавить в уже запущенные поды, координаты службы будут доступны только подам, запущенным после создания службы в Kubernetes. Соответственно, служба Service должна быть определена до запуска подов, зависящих от нее, или, если это невозможно, поды необходимо перезапустить.
Листинг 12.2. Переменные окружения с информацией о службах, автоматически создаваемые в подах
RANDOM_GENERATOR_SERVICE_HOST=10.109.72.32
RANDOM_GENERATOR_SERVICE_PORT=8080
Через поиск в DNS
В Kubernetes действует свой DNS-сервер, и все поды автоматически настраиваются на его использование. Более того, когда создается новая служба Service, для нее автоматически создается новая запись в DNS. Если предположить, что клиент знает имя необходимой ему службы, он сможет обратиться к ней по полному доменному имени (Fully Qualified Domain Name, FQDN), такому как random-generator.default.svc.cluster.local. Здесь random-generator — это имя службы Service, default — имя пространства имен, svc указывает, что это ресурс Service, а cluster.local — окончание, характерное для кластера. При обращении к службе в том же пространстве имен окончание с именем кластера, а также пространство имен можно опустить.
Механизм обнаружения с использованием DNS не имеет недостатков, свойственных переменным окружения, потому что сервер DNS позволяет любым подам отыскивать все службы Service сразу после их определения. Однако вам все равно может понадобиться использовать переменные окружения для определения номера порта, если он нестандартный или неизвестен потребителю службы.
Вот еще несколько основных характеристик служб Service с типом type: ClusterIP, на которых основываются другие типы:
Несколько портов
В одном определении службы можно зарезервировать несколько портов, исходных и целевых. Например, если под поддерживает возможность соединения по протоколу HTTP через порт 8080 и по протоколу HTTPS через порт 8443, нет необходимости определять две службы, потому что одна служба Service может связать оба порта с портами 80 и 443.
Близость сеансов
Когда появляется новый запрос, Service выбирает случайный под. Это поведение можно изменить, определив параметр sessionAffinity: ClientIP, который привяжет все запросы, исходящие с одного и того же IP-адреса, к определенному поду. Не забывайте, что службы Service в Kubernetes выполняют балансировку нагрузки на транспортном уровне L4 и не могут исследовать сетевые пакеты и выполнять балансировку нагрузки на уровне приложений, например на основе cookie.
Проверка готовности
В главе 4 «Проверка работоспособности» вы узнали, как определить параметр readinessProbe для контейнера. Если для пода определены проверки готовности и они терпят неудачу, под удаляется из списка конечных точек службы Service, даже если он соответствует селектору.
Виртуальный IP-адрес
При создании служба Service с типом type: ClusterIP получает постоянный виртуальный IP-адрес. Однако этот IP-адрес не соответствует ни одному сетевому интерфейсу и не существует в реальности. Он обслуживается компонентом kube-proxy, действующим на каждом узле, который получает информацию о новой службе и обновляет настройки iptables на своем узле, добавляя правила, которые перехватывают сетевые пакеты, направляющиеся на этот виртуальный IP-адрес, и заменяют его IP-адресом выбранного пода. В настройки iptables не добавляются правила для ICMP — только для протокола, указанного в определении службы, такого как TCP или UDP. Как следствие, нет возможности использовать ping для проверки IP-адреса службы, потому что эта команда использует протокол ICMP. Зато есть возможность получить доступ к службе через TCP (например, послать HTTP-запрос).
Выбор ClusterIP
В определении службы Service можно явно указать IP-адрес в поле .spec.clusterIP. Это должен быть действительный IP-адрес из предопределенного диапазона. Хотя это и не рекомендуется, но этот параметр может пригодиться при работе с устаревшими приложениями, настроенными на использование определенного IP-адреса, или при наличии существующей записи DNS, которую желательно использовать повторно.
Службы Service с типом type: ClusterIP доступны только внутри кластера Kubernetes, используются для обнаружения подов, соответствующих селекторам, и применяются наиболее часто. Далее мы рассмотрим другие типы служб, которые позволяют обнаруживать конечные точки, указанные вручную.
Ручное обнаружение служб
Когда создается служба Service с параметром selector, Kubernetes создает и поддерживает список подходящих и готовых к использованию подов в списке ресурсов конечных точек. Выполнив команду kubectl get endpoints random-generator, можно убедиться, что были созданы все конечные точки от имени службы в листинге 12.1. Подключения можно перенаправлять не только к подам внутри кластера, но и к внешним IP-адресам и портам. Для этого следует опустить определение selector в Service и вручную создать ресурсы конечных точек, как показано в листинге 12.3.
Листинг 12.3. Service без параметра selector
apiVersion: v1
kind: Service
metadata:
name: external-service
spec:
type: ClusterIP
ports:
- protocol: TCP
port: 80
Далее, в листинге 12.4 определяется ресурс конечных точек с именем, совпадающим с именем службы Service, который определяет целевые IP-адреса и порты.
Листинг 12.4. Конечные точки для внешней службы
apiVersion: v1
kind: Endpoints
metadata:
name: external-service
subsets:
- addresses:
- ip: 1.1.1.1
- ip: 2.2.2.2
ports:
- port: 8080
Имя должно совпадать с именем службы Service, обеспечивающей доступ к этим конечным точкам Endpoints.
Кроме того, эта служба Service доступна только изнутри кластера и может использоваться так же, как предыдущие, через переменные окружения или поиск в DNS. Разница лишь в том, что список конечных точек поддерживается вручную и их IP-адреса обычно находятся вне кластера, как показано на рис. 12.4.
Это не единственный механизм подключения к внешним ресурсам, хотя и используется чаще других. Конечные точки могут содержать IP-адреса подов, но не виртуальные IP-адреса других служб Service. Одной из
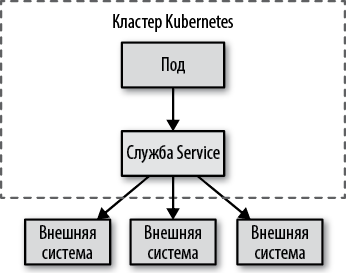
Рис. 12.4. Обнаружение службы вручную
замечательных особенностей служб Service является возможность добавлять и удалять селекторы и ссылаться на внешних или внутренних провайдеров без удаления определения ресурса, что может привести к изменению IP-адреса службы. То есть потребители услуг могут продолжать использовать тот же IP-адрес службы, даже если фактическая реализация поставщика услуг будет перемещаться по локальной сети Kubernetes.
В категории методов ручного обнаружения служб есть еще тип ресурса Service, представленный в листинге 12.5.
Листинг 12.5. Служба Service с внешним адресом назначения
apiVersion: v1
kind: Service
metadata:
name: database-service
spec:
type: ExternalName
externalName: my.database.example.com
ports:
- port: 80
Эта служба Service тоже не имеет параметра selector, но ее тип определен как ExternalName. Это важное отличие с точки зрения реализации. Эта служба ссылается на ресурс с именем, указанным в externalName, адрес которого определяется исключительно с помощью DNS. Это — способ создания псевдонима для внешней конечной точки с использованием DNS CNAME вместо прокси с IP-адресом. Но по сути это еще один способ абстрагирования конечных точек, расположенных за пределами кластера Kubernetes.
Обнаружение служб в кластере извне
Все механизмы обнаружения служб, представленные выше в этой главе, используют виртуальный IP-адрес, указывающий на поды или внешние конечные точки, а сам виртуальный IP-адрес доступен только внутри кластера Kubernetes. Однако всякий кластер Kubernetes работает в реальном мире, и кроме подключения его подов к внешним ресурсам часто требуется обратное — возможность подключения внешних приложений к конечным точкам подов. Давайте посмотрим, как сделать под доступным для клиентов, действующих за пределами кластера.
Первый способ — определить службу Service и экспортировать ее за границы кластера, задав тип type: NodePort.
Определение в листинге 12.6 описывает службу Service, поддерживаемую подами, которые соответствуют селектору app: random-generator. Она принимает соединения через порт 80 по виртуальному IP-адресу и направляет их на порт 8080 выбранного пода. Но дополнительно это определение резервирует порт 30036 на всех узлах и перенаправляет все входящие соединения через этот порт в службу Service. Это резервирование обеспечивает доступность службы и через виртуальный IP-адрес, и извне, через выделенный порт на каждом узле.
Листинг 12.6. Служба Service с типом NodePort
apiVersion: v1
kind: Service
metadata:
name: random-generator
spec:
type: NodePort
selector:
app: random-generator
ports:
- port: 80
targetPort: 8080
nodePort: 30036
protocol: TCP
Открывает порт на всех узлах.
Фиксированный номер порта (который должен быть доступен). Если опустить этот параметр, будет выбран случайный номер порта.
Этот метод экспортирования служб (как показано на рис. 12.5) может показаться неплохим вариантом, но у него есть свои недостатки. Давайте рассмотрим некоторые из его отличительных характеристик:
Номер порта
Вместо выбора конкретного порта в виде параметра nodePort: 30036 можно позволить Kubernetes самостоятельно выбрать порт из его диапазона.
Правила брандмауэра
Так как этот метод основан на открытии порта на всех узлах, в брандмауэр необходимо добавить дополнительные правила, разрешающие внешним клиентам подключаться к этому порту.
Выбор узла
Внешний клиент может открыть соединение с любым узлом в кластере. Но если узел окажется недоступным, клиентское приложение должно само установить соединение с другим работоспособном узлом. С этой целью может быть полезно установить балансировщик нагрузки перед узлами, который выбирает исправные узлы и обрабатывает отказы.
Выбор пода
Когда клиент открывает соединение через порт узла, он перенаправляется к случайно выбранному поду, который может находиться на том же узле, где было открыто соединение, или на другом узле.
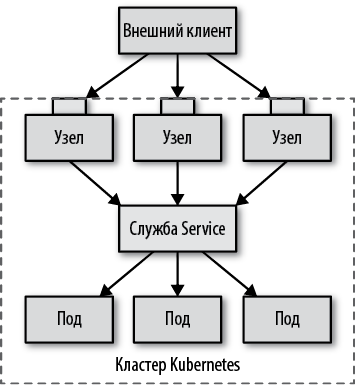
Рис. 12.5. Обнаружение служб по порту узла
Этой дополнительной переадресации можно избежать и заставить Kubernetes всегда выбирать под на узле, где было открыто соединение, если добавить параметр externalTrafficPolicy: Local в определение Service. В этом случае Kubernetes не позволит подключаться к модулям, размещенным на других узлах, что, впрочем, может породить проблемы. Чтобы решить их, нужно гарантировать размещение подов на всех узлах (например, реализовав паттерн Daemon Service (Фоновая служба)) или предоставить клиенту информацию о том, на каких узлах имеются исправные поды.
Исходящие адреса
Существуют еще некоторые особенности, связанные с исходящими адресами пакетов, отправляемых службам Service разных типов. В частности, службы типа NodePort получают пакеты с исходящими адресами клиентов, прошедшими процедуру преобразования сетевых адресов (NAT), то есть исходящие IP-адреса клиентов в сетевых пакетах заменяются внутренними адресами узла. Например, когда клиентское приложение отправляет пакет на узел 1, исходящий адрес в нем меняется на адрес узла, адрес назначения меняется на адрес пода, после чего пакет пересылается на узел 2, где находится сам под. Когда под получает сетевой пакет, исходящий адрес в нем будет отличаться от адреса оригинального клиента и совпадать с адресом узла 1. Чтобы этого не происходило, можно определить параметр externalTrafficPolicy: Local, как описано выше, и передавать трафик только подам, находящимся на узле 1.
Другой способ организовать возможность обнаружения служб для внешних клиентов — настроить балансировку нагрузки. Вы уже видели, как служба Service с типом type: NodePort строится поверх обычной службы с типом type: ClusterIP, дополнительно открывая порт на каждом узле. Ограничением этого подхода является необходимость иметь балансировщик нагрузки для клиентских приложений, выбирающий работоспособный узел. Службы с типом LoadBalancer устраняют это ограничение.
Кроме создания обычных служб Service и открытия портов на каждом узле с помощью служб с типом type: NodePort, можно также экспортировать службу вовне с использованием балансировщика нагрузки облачного провайдера. На рис. 12.6 показана такая конфигурация: собственный балансировщик нагрузки играет роль шлюза в кластер Kubernetes.
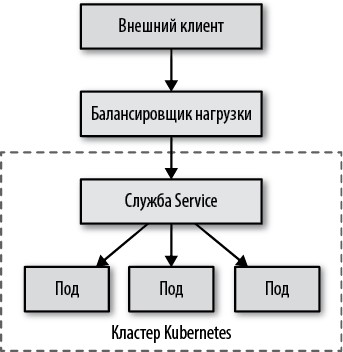
Рис. 12.6. Обнаружение служб посредством балансировщика нагрузки
То есть службы Service этого типа действуют, только когда облачный провайдер настроил в Kubernetes поддержку балансировки нагрузки.
Мы можем создать службу с балансировщиком нагрузки, указав тип LoadBalancer. Встретив такую службу, Kubernetes добавит IP-адреса в поля .spec и .status, как показано в листинге 12.7.
Листинг 12.7. Служба Service типа LoadBalancer
apiVersion: v1
kind: Service
metadata:
name: random-generator
spec:
type: LoadBalancer
clusterIP: 10.0.171.239
loadBalancerIP: 78.11.24.19
selector:
app: random-generator
ports:
- port: 80
targetPort: 8080
protocol: TCP
status:
loadBalancer:
ingress:
- ip: 146.148.47.155
Kubernetes присваивает clusterIP и loadBalancerIP, если они доступны.
Поле status управляется фреймворком Kubernetes и добавляет Ingress IP.
С этим определением службы внешнее клиентское приложение может открыть соединение с балансировщиком нагрузки, который сам выберет узел и найдет под. Способ предоставления доступа к балансировщику нагрузки и обнаружения служб зависит от поставщика облачных услуг. Некоторые облачные провайдеры разрешают определять адрес балансировщика нагрузки, а некоторые — нет. Некоторые поддерживают механизмы сохранения исходящих адресов, а некоторые заменяют их адресом балансировщика. Обязательно проверяйте конкретную реализацию, предлагаемую выбранным вами облачным провайдером.
 Поддерживается еще один тип служб Service: автономные (headless) службы, для которых не требуется выделенный IP-адрес. Автономная служба создается добавлением параметра clusterIP: None в раздел spec:. Поддерживающие поды добавляются в автономную службу внутренним DNS-сервером, и такие службы наиболее полезны для реализации StatefulSet, как подробно описано в главе 11 «Служба с состоянием».
Поддерживается еще один тип служб Service: автономные (headless) службы, для которых не требуется выделенный IP-адрес. Автономная служба создается добавлением параметра clusterIP: None в раздел spec:. Поддерживающие поды добавляются в автономную службу внутренним DNS-сервером, и такие службы наиболее полезны для реализации StatefulSet, как подробно описано в главе 11 «Служба с состоянием».
Обнаружение служб уровня приложения
В отличие от механизмов, обсуждавшихся до сих пор, Ingress — это не тип службы, а самостоятельный ресурс Kubernetes, который располагается перед службами Service и действует подобно интеллектуальному маршрутизатору и точке входа в кластер. Обычно ресурс Ingress используется с целью открыть доступ к службам Service по протоколу HTTP через внешние URL и обеспечить балансировку нагрузки, завершение SSL (SSL termination) и виртуальный хостинг на основе имен, но существуют и другие специализированные реализации Ingress.
Для нормальной работы Ingress необходимо, чтобы в кластере был запущен один или несколько контроллеров Ingress. В листинге 12.8 показан простой ресурс Ingress, экспортирующий единственную службу Service.
Листинг 12.8. Определение простого ресурса Ingress
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: random-generator
spec:
backend:
serviceName: random-generator
servicePort: 8080
В зависимости от инфраструктуры, на которой работает Kubernetes, и реализации контроллера Ingress, это определение выделяет IP-адрес, доступный извне, и открывает доступ к службе random-generator через порт 80. Но эта конфигурация не сильно отличается от службы Service с типом type: LoadBalancer, которая требует внешнего IP-адреса для каждого определения Service. Настоящая сила Ingress заключается в использовании единого внешнего балансировщика нагрузки и IP-адреса для обслуживания нескольких служб и снижения затрат на инфраструктуру.
В листинге 12.9 показана простая конфигурация веерной маршрутизации между несколькими службами с единым IP-адресом, основанная на HTTP URI.
Листинг 12.9. Определение ресурса Ingress с отображением маршрутов
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: random-generator
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
rules:
- http:
paths:
- path: /
backend:
serviceName: random-generator
servicePort: 8080
- path: /cluster-status
backend:
serviceName: cluster-status
servicePort: 80
Специализированные правила маршрутизации запросов на основе пути для контроллера Ingress.
Отправлять в службу random-generator все запросы...
...кроме запросов, в которых указан путь /cluster-status; эти запросы должны передаваться другой службе.
маршруты в OpenShift
Red Hat OpenShift — популярный корпоративный дистрибутив Kubernetes. Помимо полной совместимости с Kubernetes, OpenShift предлагает ряд дополнительных возможностей. Одна из них — маршруты Route, очень похожие на Ingress. Они настолько похожи, что почти неразличимы. Следует отметить, что появление поддержки маршрутов Route предшествовало введению объекта Ingress в Kubernetes, поэтому маршруты Route можно смело считать прямыми предшественниками Ingress.
Тем не менее между объектами Route and Ingress существуют технические отличия:
Маршрут Route автоматически поддерживается балансировщиком нагрузки HAProxy, интегрированным в OpenShift, поэтому нет необходимости устанавливать дополнительный контроллер Ingress. Однако в OpenShift есть возможность заменить встроенный балансировщик нагрузки.
Имеется возможность использовать дополнительные режимы завершения TLS, такие как повторное шифрование и сквозной доступ к службе.
Поддерживается распределение трафика между экземплярами с учетом весовых коэффициентов.
Поддерживаются шаблонные символы в доменных именах.
Наконец, Ingress тоже можно использовать в OpenShift. То есть, используя OpenShift, вы получаете некоторую свободу выбора.
Поскольку все контроллеры Ingress имеют разные реализации, кроме обычного определения ресурса Ingress контроллеру может потребоваться дополнительная информация, которая передается посредством аннотаций. Если предположить, что контроллер Ingress настроен правильно, предыдущее определение обеспечит использование балансировки нагрузки и доступность двух служб с разными путями через один IP-адрес, как показано на рис. 12.7.
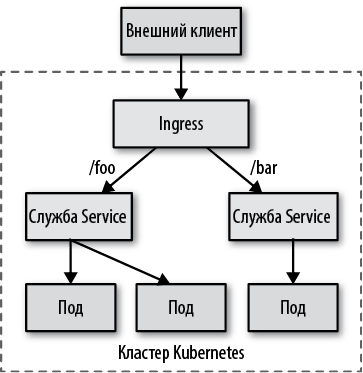
Рис. 12.7. Обнаружение служб уровня приложения
Ingress — это самый мощный и в то же время самый сложный механизм обнаружения служб в Kubernetes. Главное его преимущество — возможность организовать доступ к нескольким службам через один IP-адрес, когда все службы используют один и тот же протокол прикладного уровня L7 (обычно HTTP).
Пояснение
В этой главе мы рассмотрели основные механизмы, используемые при реализации паттерна Service Discovery (Обнаружение служб) в Kubernetes. Обнаружение динамических подов внутри кластера всегда производится через ресурс Service, хотя разные варианты могут приводить к разным реализациям. Абстракция Service — это высокоуровневый облачный способ настройки низкоуровневых деталей, таких как виртуальные IP-адреса, правила iptables, записи DNS или переменные окружения. Обнаружение служб извне кластера основывается на абстракции Service и направлено на предоставление услуг внешнему миру. Тип NodePort позволяет определить простую службу, доступную извне, однако для настройки служб с высокой доступностью требуется интеграция с поставщиком инфраструктуры платформы.
В табл. 12.1 перечислены разные способы реализации паттерна Service Discovery (Обнаружение служб) в Kubernetes. В ней дается краткая информация о различных механизмах обнаружения служб, описанных в этой главе, организованных в порядке возрастания сложности. Мы надеемся, что она поможет вам мысленно построить модель и лучше понять ее.
Таблица 12.1. Механизмы паттерна Service Discovery (Обнаружение служб)
| Название | Конфигурация | Тип клиента | Описание |
| ClusterIP | type: ClusterIP .spec.selector | Внутренний | Наиболее распространенный механизм обнаружения служб изнутри |
| Ручное обнаружение служб по IP | type: ClusterIP kind: Endpoints | Внутренний | Обнаружение по внешнему IP-адресу |
| Обнаружение по полному доменному имени | type: ExternalName .spec.externalName | Внутренний | Обнаружение по внешнему полному доменному имени |
| Автономная служба | type: ClusterIP .spec.clusterIP: None | Внутренний | Обнаружение на основе DNS без виртуального IP-адреса |
| NodePort | type: NodePort | Внешний | Предпочтительный вариант для трафика, отличного от HTTP |
| LoadBalancer | type: LoadBalancer | Внешний | Требует поддержки со стороны облачной инфраструктуры |
| Ingress | kind: Ingress | Внешний | Интеллектуальный механизм маршрутизации на основе L7/HTTP |
В этой главе представлен достаточно полный обзор всех основных механизмов Kubernetes для обнаружения служб и доступа к ним. Однако наше путешествие на этом не заканчивается. В рамках проекта Knative были созданы новые примитивы поверх Kubernetes, которые помогают разработчикам приложений организовать обслуживание и обмен сообщениями.
В контексте паттерна Service Discovery (Обнаружение служб) проект Knative Serving представляет особый интерес, потому что предлагает новый ресурс, напоминающий Service, который был представлен здесь, но с другой группой API. Knative Serving предлагает также поддержку ревизий приложений и очень гибкое масштабирование служб за балансировщиком нагрузки. Мы кратко расскажем о Knative Serving в разделе «Knative Build» главы 25 и во врезке «Knative Serving» главы 24, однако полное обсуждение Knative выходит за рамки этой книги. В разделе «Дополнительная информация» главы 24 вы найдете ссылки, где можно найти более подробную информацию о Knative.
Дополнительная информация
• Пример обнаружения служб (http://bit.ly/2TeXzcr).
• Службы Service в Kubernetes (http://bit.ly/2q7AbUD).
• Использование DNS для обнаружения служб и подов (http://bit.ly/2Y5jUwL).
• Отладка служб Service (http://bit.ly/2r0igMX).
• Использование исходящего IP-адреса (https://kubernetes.io/docs/tutorials/services/).
• Настройка внешнего балансировщика нагрузки (http://bit.ly/2Gs05Wh).
• Выбор между NodePort, LoadBalancer и Ingress в Kubernetes (http://bit.ly/2GrVio2).
• Ingress (https://kubernetes.io/docs/concepts/services-networking/ingress/).
• Выбор между Kubernetes Ingress и OpenShift Route (https://red.ht/2JDDflo).
Название ресурса Ingress так и переводится — вход, точка входа. — Примеч. пер.

