Глава 10. Служба-одиночка
Паттерн Singleton Service (Служба-одиночка) гарантирует, что в каждый конкретный момент времени активным будет только один экземпляр приложения при условии сохранения высокой доступности. Этот паттерн можно реализовать внутри приложения или полностью переложить на плечи Kubernetes.
Задача
Одна из основных возможностей фреймворка Kubernetes — простота и прозрачность масштабирования приложений. Поды могут масштабироваться императивно, командой kubectl scale, или декларативно, путем определения такого контроллера, как ReplicaSet, и даже динамически, основываясь на нагрузке на приложение, как описано в главе 24 «Эластичное масштабирование». Запуская несколько экземпляров одной и той же службы (не контроллера службы Service, а компонента распределенного приложения, представленного подом), система может увеличивать пропускную способность и доступность. Доступность увеличивается, потому что в случае выхода из строя одного экземпляра службы диспетчер сможет переадресовать запросы другим, исправным экземплярам. В Kubernetes множественные экземпляры являются репликами пода, а ресурс Service отвечает за диспетчеризацию запросов.
Однако иногда желательно, чтобы действовал только один экземпляр службы. Например, если служба выполняет некоторую периодическую задачу, тогда при одновременном выполнении нескольких экземпляров каждый будет запускать задачу через запланированные интервалы, что приведет к дублированию, а не к запуску только одной задачи, как ожидалось. Другой пример: служба, которая выполняет опрос определенных ресурсов (файловой системы или базы данных), и требуется, чтобы такой опрос и обработку результатов осуществлял только один экземпляр и, возможно, даже один поток. Третий случай имеет место, когда речь заходит об однопоточном потребителе, извлекающем сообщения из брокера сообщений, который также является службой-одиночкой.
Во всех этих и подобных им ситуациях нужно иметь возможность ограничивать количество активных экземпляров службы в каждый момент времени (обычно требуется только один), независимо от того, сколько экземпляров было запущено и продолжает работать.
Решение
Запуск нескольких реплик одного модуля создает топологию активный-активный, в которой все экземпляры службы активны. Но нам нужна топология активный-пассивный (или ведущий-ведомый), в которой активен только один экземпляр, а все остальные являются пассивными. Блокировку приложения можно организовать на двух уровнях: извне и изнутри.
Блокировка приложения извне
Как следует из названия, этот подход основан на использовании управляющего процесса, который выполняется отдельно от приложения и обеспечивает работу только одного его экземпляра. Сама реализация приложения не знает об этом ограничении и запускается как экземпляр-одиночка. Это напоминает создание единственного экземпляра класса Java управляющей средой выполнения (например, Spring Framework). Реализация класса не знает, что используется только один его экземпляр, и не содержит никакого кода, предотвращающего создание нескольких экземпляров.
На рис. 10.1 показано, как можно реализовать блокировку приложения за его пределами с помощью контроллера StatefulSet или ReplicaSet с единственной репликой.
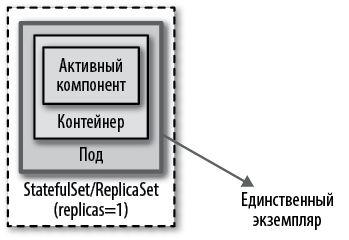
Рис. 10.1. Механизм блокировки приложения извне
В Kubernetes для этого нужно запустить под с единственной репликой. Однако этого недостаточно, чтобы гарантировать высокую доступность пода-одиночки. Дополнительно нужно заключить под в контроллер, такой как ReplicaSet, который обеспечит высокую доступность пода-одиночки. Эта топология не совсем активный-пассивный (в данном случае отсутствует пассивный экземпляр), но имеет тот же эффект, так как Kubernetes гарантирует постоянное присутствие в кластере одного действующего экземпляра пода. Кроме того, благодаря контроллеру, осуществляющему проверку работоспособности и повторный запуск пода в случае сбоя, как описано в главе 4 «Проверка работоспособности», обеспечивается высокая доступность единственного экземпляра пода.
Главное, на что следует обратить внимание при реализации этого подхода, — количество реплик, которое не должно увеличиваться случайно или по ошибке, потому что на уровне платформы отсутствует механизм, предотвращающий изменение количества реплик.
Было бы не совсем верно утверждать, что с этой реализацией в каждый момент времени выполняется только один экземпляр, особенно когда что-то идет не так. Примитивы Kubernetes, такие как ReplicaSet, отдают предпочтение доступности перед согласованностью — осознанное решение для высокодоступных и масштабируемых распределенных систем. Это означает, что ReplicaSet реализует для своих реплик семантику «не менее», а не «не более». Если настроить контроллер ReplicaSet как управляющий одиночным экземпляром, определив параметр replicas: 1, он будет гарантировать выполнение не менее одного экземпляра, но иногда может выполняться больше экземпляров.
Чаще других встречается проблема, когда узел с подом, управляемым контроллером, выходит из строя и отключается от кластера Kubernetes. В этом случае контроллер ReplicaSet запускает другой экземпляр пода на исправном узле (при наличии достаточного объема ресурсов), но не гарантирует остановку пода на отключенном узле. Аналогично, при изменении количества реплик или перемещении подов на другие узлы их фактическое количество может временно превысить желаемое. Это временное увеличение производится с целью обеспечить высокую доступность и предотвратить сбои, что необходимо для масштабируемых приложений и приложений без состояния.
Поды-одиночки могут быть отказоустойчивыми и восстанавливаться автоматически, но они не являются высокодоступными по определению. Для одиночек обычно важнее согласованность, а не высокая доступность. В Kubernetes имеется ресурс StatefulSet, который обеспечивает согласованность в ущерб доступности и дает желаемую гарантию присутствия единственного экземпляра. Если ReplicaSet не предоставляет гарантий, необходимых вашему приложению, и у вас есть строгое ограничение, требующее, чтобы одновременно выполнялось не более одного экземпляра пода, возможно, вам подойдет StatefulSet. Контроллеры StatefulSet предназначены для приложений с состоянием и предлагают много новых возможностей, в том числе более строгие гарантии для одиночек, но они также сложнее в обращении. Мы обсудим проблемы, связанные с одиночками, и поближе познакомимся с контроллерами StatefulSet в главе 11 «Служба с состоянием».
Как правило, приложения-одиночки, выполняющиеся в подах Kubernetes, открывают исходящие соединения с брокерами сообщений, реляционными базами данных, файловыми серверами или другими системами, работающими в других подах или внешних системах. Однако иногда поду-одиночке может потребоваться принимать входящие соединения, и Kubernetes предлагает такую возможность в виде ресурса службы Service.
Подробно службы Service будут рассматриваться в главе 12 «Обнаружение служб», а здесь мы лишь кратко коснемся той их части, которая относится к одиночкам. Обычная служба Service (с параметром type: ClusterIP) создает виртуальный IP-адрес и балансирует нагрузку между всеми экземплярами, соответствующими селектору службы. Но под-одиночка, управляемый посредством StatefulSet, имеет единственный экземпляр и постоянную сетевую идентификацию. В таком случае лучше создать автономную службу Service (с параметрами type: ClusterIP и clusterIP: None). Она называется автономной, потому что не имеет виртуального IP-адреса, kube-proxy не обслуживает такие службы и платформа не осуществляет их проксирование.
Однако такая служба все еще имеет практическую ценность, потому что автономная служба Service с селекторами создает конечные точки в API Server и генерирует записи A в DNS для соответствующих подов. Соответственно, поиск службы Service в DNS возвращает не ее виртуальный IP-адрес, а IP-адреса входящих в нее подов. Это обеспечивает прямой доступ к поду-одиночке через запись службы в DNS, минуя виртуальный IP-адрес службы. Например, если создать автономную службу Service с именем my-singleton, можно использовать ее как my-singleton.default.svc.cluster.local для прямого доступа к IP-адресу модуля.
Подводя итог, можно сказать, что когда требование к единственности экземпляра не является строгим, достаточно использовать контроллер ReplicaSet с одной репликой и обычную службу Service. Для строгого соблюдения требования и более эффективного обнаружения службы предпочтительнее использовать контроллер StatefulSet и автономную службу Service. Законченный пример этой конфигурации вы найдете в главе 11 «Служба с состоянием», где вам останется лишь уменьшить число реплик на одну, чтобы обеспечить выполнение единственного экземпляра.
Блокировка приложения изнутри
В распределенном окружении для управления количеством экземпляров службы часто используется распределенная блокировка, как показано на рис. 10.2. Всякий раз, когда активируется экземпляр службы или компонент в экземпляре, он может попытаться получить блокировку и в случае успеха перейти к активным действиям. Любой другой экземпляр службы, не сумевший получить блокировку, переходит в состояние ожидания и постоянно повторяет попытки получить блокировку на случай, если текущая активная служба освободит ее.
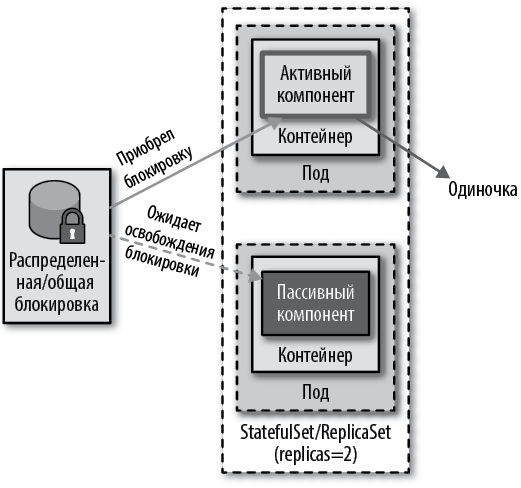
Рис. 10.2. Механизм блокировки приложения изнутри
Многие существующие распределенные платформы используют этот механизм для достижения высокой доступности и отказоустойчивости. Например, брокер сообщений Apache ActiveMQ может работать в высокодоступной топологии активный-пассивный, где общую блокировку обеспечивает источник данных. Экземпляр брокера, запустившийся первым, получает блокировку и становится активным, а другие экземпляры, запущенные после, становятся пассивными и ожидают снятия блокировки. Эта стратегия обеспечивает наличие единственного активного экземпляра брокера, а также устойчивость к сбоям.
Эту стратегию можно сравнить с классической реализацией паттерна Singleton (Одиночка) в объектно-ориентированном мире: одиночка — это экземпляр объекта, хранящийся в статической переменной класса. В этом случае класс знает, что может существовать только один его экземпляр, и написан так, что не позволяет создавать несколько экземпляров в одном и том же процессе. В распределенных системах это означает, что само контейнерное приложение должно быть написано так, чтобы не было возможности иметь более одного активного экземпляра, независимо от количества запущенных экземпляров. Для этого в распределенном окружении должна иметься поддержка распределенных блокировок, например такая, как в Apache ZooKeeper, HashiCorp Consul, Redis или Etcd.
Типичная реализация в ZooKeeper использует эфемерные узлы, которые запускаются с началом сеанса клиента и удаляются по завершении сеанса. Первый запущенный экземпляр службы инициирует сеанс на сервере ZooKeeper и создает эфемерный узел, чтобы стать активным. Все остальные экземпляры в том же кластере становятся пассивными и должны ждать освобождения эфемерного узла. Именно так реализация на основе ZooKeeper обеспечивает наличие только одного активного экземпляра службы во всем кластере, обеспечивая поведение активный-пассивный для защиты от сбоев.
В мире Kubernetes вместо создания кластера ZooKeeper только ради поддержки блокировок лучше использовать механизм Etcd, доступный через Kubernetes API и выполняющийся на ведущих узлах. Etcd — это распределенное хранилище пар ключ/значение, которое использует протокол Raft для поддержания своего реплицированного состояния. Особенно важно, что это хранилище предлагает необходимые строительные блоки для реализации выбора лидера, и уже имеется несколько клиентских библиотек, реализовавших эту возможность. Например, Apache Camel имеет компонент интеграции с Kubernetes, который реализует алгоритм выбора лидера и позволяет организовать выполнение единственного экземпляра. Кроме того, этот компонент вместо прямого доступа к Etcd API использует Kubernetes API и организует распределенную блокировку на основе карт конфигураций ConfigMap. Он полагается на гарантии оптимистичной блокировки в Kubernetes для правки таких ресурсов, как ConfigMap, позволяющей только одному поду обновлять конфигурацию в ConfigMap.
Реализация Camel использует эту гарантию, чтобы обеспечить активное выполнение только одного экземпляра маршрута Camel, а все остальные заставить ждать освобождения блокировки перед активацией. Это нестандартная реализация блокировки, но она позволяет достичь желаемого: при наличии нескольких подов с одним и тем же приложением Camel только один из них действует активно, а остальные ждут в пассивном режиме.
Реализация с использованием ZooKeeper, Etcd или любого другого механизма распределенной блокировки действует аналогично описанной: только один экземпляр приложения становится лидером и активирует себя, а другие экземпляры находятся в пассивном ожидании освобождения блокировки. Это гарантирует, что даже если будет запущено несколько реплик пода и все выполняются исправно, только одна реплика будет активна и будет выполнять свои бизнес-функции, а другие будут ждать приобретения блокировки, что может произойти в случае сбоя или выхода из строя ведущего узла.
Бюджет неработоспособности пода
В отличие от паттерна Singleton Service (Служба-одиночка) и механизма выбора лидера, которые пытаются ограничить максимальное количество экземпляров, действующих одновременно, ресурс бюджета неработоспособности пода PodDisruptionBudget в Kubernetes предлагает дополнительную и даже в чем-то противоположную возможность — возможность ограничить количество экземпляров, останавливаемых одновременно для обслуживания.
По своей сути PodDisruptionBudget гарантирует, что заданное количество или процент подов не будет добровольно вытеснено с узла. Под добровольным в данном случае понимается вытеснение, которое можно отложить на определенное время, — например, когда оно инициируется истощением ресурсов узла для обслуживания или обновления (kubectl drain) или уменьшением кластера, а не выходом узла из строя, что нельзя ни прогнозировать, ни контролировать.
В листинге 10.1 приводится определение ресурса PodDisruptionBudget, который применяется к подам, соответствующим селектору, и гарантирует доступность не менее двух подов в каждый момент времени.
Листинг 10.1. PodDisruptionBudget
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: random-generator-pdb
spec:
selector:
matchLabels:
app: random-generator
minAvailable: 2
Селектор для подсчета числа доступных подов.
Не меньше двух подов должно быть доступно. В этом параметре также можно определить процент, например 80%, чтобы указать, что может быть вытеснено только 20% подов, соответствующих селектору.
Кроме .spec.minAvailable имеется также параметр .spec.maxUnavailable, определяющий максимальное количество подов, которые могут быть вытеснены. Но указать можно только какой-то один из параметров, а кроме того, PodDisruptionBudget обычно применяется только к подам, управляемым контроллером. Для подов, не управляемых контроллером (их также называют простыми, или голыми, подами), следует учитывать другие ограничения, связанные с PodDisruptionBudget.
Эта возможность может пригодиться в приложениях, работа которых основана на кворуме и для обеспечения кворума требуется одновременное выполнение некоторого минимального количества реплик. Или когда приложение обслуживает критический трафик и количество действующих экземпляров никогда не должно опускаться ниже определенного процента. Это еще один примитив Kubernetes, влияющий на управление экземплярами во время выполнения, и о нем стоило упомянуть в этой главе.
Пояснение
Когда требуются строгие гарантии единственности экземпляра, их нельзя получить, полагаясь на ReplicaSet и механизмы блокировки вне приложения. Назначение контроллера ReplicaSet в Kubernetes — гарантировать доступность подов, а не поддерживать семантику «не более одного». Как следствие, существует много сценариев нарушения требования единственности (например, когда узел, на котором запущен под-одиночка, отключается от остальной части кластера и отключенный экземпляр пода заменяется новым), когда в течение короткого периода времени одновременно действуют два пода. Если это неприемлемо, используйте контроллеры StatefulSet или рассмотрите варианты приобретения блокировок в приложении, которые предоставляют больший контроль над процессом выбора лидера с более строгими гарантиями. Подход на основе блокировок также поможет предотвратить случайное масштабирование подов при изменении значения параметра replicas.
Иногда требуется, чтобы только один компонент контейнерного приложения действовал в одиночку. Например, контейнерное приложение, реализующее конечную точку HTTP, можно безопасно масштабировать до нескольких экземпляров, но в нем имеется компонент опроса, который должен выполняться в одиночку. Использование подхода с блокировкой вне приложения не может использоваться в такой ситуации, так как помешает масштабированию всей службы. Мы должны либо выделить компонент-одиночку в отдельную единицу развертывания (что хорошо в теории, но не всегда практично из-за больших накладных расходов), либо использовать механизм блокировки внутри приложения и блокировать только этот компонент. Это позволит прозрачно масштабировать все приложение и конечные точки HTTP, а для других частей использовать поведение активный-пассивный.
Дополнительная информация
• Пример службы-одиночки (http://bit.ly/2TKp5nm).
• Упрощенная реализация выборов лидера с использованием Kubernetes и Docker (http://bit.ly/2FwUS1a).
• Выборы лидера в клиенте на Go (http://bit.ly/2UatejW).
• Настройка бюджета неработоспособности пода (http://bit.ly/2HDKcR3).
• Создание служб-одиночек в кластере Kubernetes (http://bit.ly/2TKm1HR).
• Компонент интеграции Apache Camel с Kubernetes (http://bit.ly/2JoL6mT).

