Книга: Зачем мы говорим. История речи от неандертальцев до искусственного интеллекта
Назад: 5 Голос, оснащенный электричеством
Дальше: 7 Берегитесь: у компьютеров есть уши
6
Все роботы – актеры
Первые демонстрации записи голоса, проведенные Эдисоном, вызвали ажиотаж, но временами царапанье иглы по фольге перекрывало речь. При воспроизведении звук искажался, и New York Times описывала «странные писклявые голоса, такие можно услышать только на фонографе – или в театре марионеток» [1]. Инженер-электрик сэр Уильям Генри Прис полагал, что использовать фонограф для записи выдающихся голосов, например оперной дивы Аделины Патти или великого оратора Глэдстона, – плохая идея [2]. Пирс считал, что воспроизведенный звук – «это своего рода… бурлеск или пародия на человеческий голос» [3]. В наши дни сгенерированный компьютером голос, озвучивающий героя шекспировской пьесы, возможно, описали бы так же. Можно было бы загрузить текст пьесы в современный синтезатор речи, и он, наверное, смог бы выдать членораздельный текст, но странная интонация сделала бы такое воспроизведение карикатурой на актерскую игру.
Возможно, сейчас вы представили себе Стивена Хокинга, играющего Гамлета, но на самом деле Хокинг использовал давно устаревшие технологии. Понятно, что он отказывался «усовершенствовать» свой голос, поскольку он уже стал его визитной карточкой. Новейшие синтезаторы речи, конечно, звучат более естественно, и такие голоса, как Siri, персональный помощник iPhone, для многих людей стали частью повседневной жизни. Когда я приступил к написанию этой главы, в среде специалистов, занимающихся синтезом речи, царило возбуждение по поводу новейшей технологии, разработанной DeepMind. Заголовки пестрели сообщениями о том, как в 2016 году разработанная компанией программа на основе искусственного интеллекта AlphaGo обошла профессионального игрока в го. Ученые старались добиться впечатляющего качества синтезированной речи, как это получилось у DeepMind.
Если мы все ближе подходим к моменту, когда механическая речь станет неотличимой от человеческой, следует ли беспокоиться тем, кто профессионально использует свой голос? Не наступит ли час, когда я в последний раз буду выступать со своей научно-популярной программой на радио BBC? Ведь BBC уже начала переводить и читать сводки новостей на русском и японском языках, используя механические голоса [4]. Это делается для того, чтобы предоставлять услуги на большем количестве языков, так что дикторы-люди не останутся без работы – во всяком случае пока…
А как насчет актеров, которые профессионально используют голос? Некоторые театральные компании уже экспериментируют с роботами-актерами. Конечно, луддиты здесь не нужны, потому что машины не заменяют актеров, а играют самих себя. Например, My Square Lady – опера, в которой робот по имени Мион занят в роли, похожей на историю Элизы Дулитл из мюзикла «Моя прекрасная леди». Элиза занималась риторикой, чтобы изменить свой социальный статус, а Мион учится чувствовать и выражать эмоции, чтобы стать более человечным. По мере того как искусственный интеллект совершенствуется, а компьютерная речь улучшается, будет ли в постановке шекспировской «Как вам это понравится?» звучать модифицированная строка: «Весь мир – театр, а роботы в нем – актеры»?
Говорящие машины появились в театре. Первый настоящий синтезатор речи – механическое устройство, созданное венгром Вольфгангом фон Кемпеленом в конце XVIII века. Кемпелен был настоящим энциклопедистом: политиком, художником, изобретателем и, что самое главное, еще и шоуменом [5]. Его самым известным сценическим действом был умеющий играть в шахматы автомат. Эта машина представляла собой большой ящик, на верхней плоскости которого располагалась шахматная доска, а внутри находились замысловатые заводные механизмы, которые тикали и жужжали при движении. Над доской склонился бородатый манекен в турецком халате и чалме, его рука двигалась: он брал фигуры и передвигал их. Это действо вызывало восторг у зрителей по всему миру, включая Париж, где в 1783 году машина сыграла партию с послом США Бенджамином Франклином [6]. Это был Кемпелен-шоумен: он продемонстрировал сложнейший фокус, обманув зрителей, ведь на самом деле все движения контролировались миниатюрным игроком, спрятанным в секретном отделении внутри ящика.
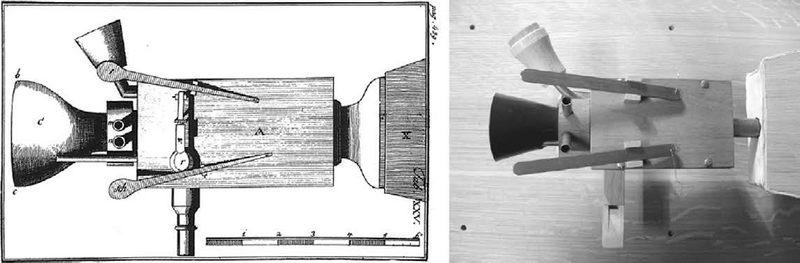
Старинный рисунок машины Кемпелена и модель Брекхейна и Трувейна; воздуходувы не видны, они находятся справа
А вот говорящая машина Кемпелена стала уже серьезным научным предприятием, рожденным желанием опытным путем изучить, как работает голос. Построив машину, которая симулировала отдельные части голосовой анатомии, он надеялся лучше понять человеческую речь. В своей научно-популярной программе я использовал модель машины Кемпелена, которой управлял профессор Дэвид Хауэрд из колледжа Ройял-Холлоуэй при Лондонском университете. Подобно Кемпелену, Дэвид – энциклопедист, инженер по электронике, дирижер и органист. И он тоже немножко шоумен. У говорящей машины Дэвида есть большой набор воздуходувов, которые работают подобно легким. Из них воздух проходит через полую трубку, которая симулирует работу голосовых связок: открывается и закрывается, перекрывая поток воздуха и создавая гудящий звук. Для имитации эффекта голосового тракта из передней части машины высовывается кожаная трубка, которой Дэвид манипулирует для создания разных звуков. Когда воздуходувы, находящиеся под его правой рукой, проталкивают воздух, Дэвид два раза быстро нажимает на кожаную трубку левой рукой, и получается слово «мама» (хотя мне показалось, что эти звуки больше похожи на грустное мычание коровы, чем на голос ребенка). Но когда Фабиан Брекхейн и Юрген Трувейн из Университета Саара в Германии проводили исследования со своей моделью машины Кемпелена, они обнаружили, что четыре из десяти испытуемых, слушавших воспроизводимое машиной слово «мама», думали, что говорит ребенок, а не машина [7].
У машины имеется пара медных носовых отверстий, которые торчат, как бакенбарды, рядом с кожаной трубкой. Если их закрыть, «мама» превратится в «папу». Еще несколько рычагов и кнопок могут создавать другие звуки. Один из клапанов обходит полую трубку, посылая воздух через крошечный свисток, который создает шипящий [с]. У человека этот звук производится, когда воздух со свистом проносится через маленький просвет между языком и нёбом. Чтобы получить разнообразные звуки, необходима практика – как и в случае игры на музыкальном инструменте.
Проделки с шахматной машиной показали, что Кемпелен знал, как работать с аудиторией. Он даже оставил описания некоторых своих трюков – например, как использовать дающую высокий звук полую трубку для создания детского голоса, потому что знал, что это поможет успокоить критиков. Во время демонстрации говорящей машины зрители могли задавать слова, которые машина должна была синтезировать. Вот как описывает это один из зрителей:
Машина произносила все слова с большой точностью… По тону голос напоминал трехлетнего ребенка. Иногда требуемое слово произносилось сначала неправильно, и артисту приходилось делать несколько попыток. Он оправдывался, говоря, что человек, который делает скрипки, не обязательно виртуозный скрипач [8].
Кемпелен решил, что будет сам вслух произносить фразу, перед тем как ее повторит машина. Таким образом он заранее подготавливал слушателей, чтобы они не заметили ошибок в произношении, поскольку мозг уже подсознательно их исправит. И все же интерес к этой впечатляющей машине довольно быстро угас, потому что она не могла воспроизводить многие согласные.
В XIX веке были созданы еще более сложные говорящие машины. Самой известной была «Эуфония» Джозефа Фабера, которая в 1846 году участвовала в представлениях передвижного цирка Ф. Т. Барнума. На фотографиях это устройство напоминает ткацкий станок, снабженный воздуходувными мехами и головой манекена без туловища. Вибрация полой трубки регулировалась винтом, и это позволяло придавать голосу различную высоту тона. Машина Кемпелена всегда говорила монотонно, но «Эуфония» могла менять интонацию и даже петь «Боже, храни королеву».
Как и три десятилетия спустя, когда Эдисон изобрел фонограф, газеты предрекали «Эуфонии» различные сатирические роли. Кто-то предлагал заменить ею занудных ораторов, будь то скучный проповедник, адвокат или даже член королевской семьи. Журнал Punch предположил, что «Эуфония» может даже занять место спикера в палате общин: «Положите перед ней церемониальный жезл. Сбоку поместите большую табакерку… для удобства членов парламента и простой аппарат, чтобы он выкрикивал призывы к порядку каждые 10 минут» [9].
Многие отнеслись к этому изобретению с энтузиазмом, но будущий театральный импресарио Джон Холлингсхед написал откровенно пессимистичный отзыв, назвав профессора Фабера «человеком с грустным лицом», а говорящую машину «его научным чудовищем Франкенштейна». В конце концов Фабер уничтожил свою машину и покончил с собой [10].
К счастью, реакции на первую электронную говорящую машину были более оптимистичными. Синтезатор речи (The Voder) стал самым известным аттракционом на Всемирной выставке 1939 года в Нью-Йорке. По примерным оценкам, электронный голос вызвал восхищение у пяти миллионов посетителей, включая пожилого человека, так отозвавшегося о нем: «Чудеса, как их описывает Библия, на самом деле существуют, ведь здесь, в этой комнате, мы своими глазами увидели это современное чудо! Воистину здесь нам показывают чудеса божьи, переданные посредством человеческого разума» [11].
Создателем синтезатора речи был Гомер Дадли из Лабораторий Белла. В некрологе коллега описывал Дадли как одного из «величайших “старомодных” изобретателей», которого было трудновато понимать, потому что он слишком быстро говорил: «Язык у него работал как телеграфный аппарат» [12]. К слову, именно медленная работа телеграфного кабеля заставила Дадли искать лучшие способы передачи речи, потому что высокие звуковые частоты находились за пределами возможностей кабеля. Эта работа и привела к созданию синтезатора речи.
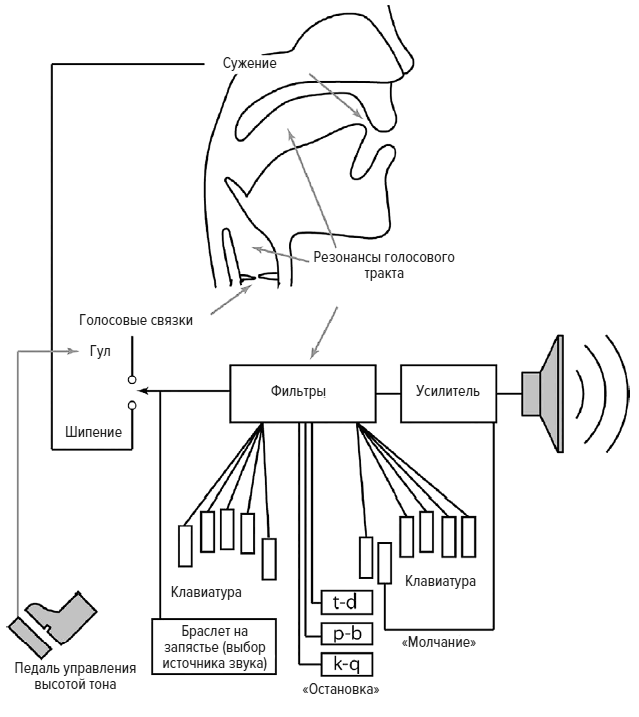
Синтезатор речи Дадли (Voder) [14]
Дадли понял, что гудение голосовых связок, которое создает проблематичные для передачи высокие частоты, можно отделить от более медленных движений рта, языка и горла, поэтому сигнал, описывающий эту медленную артикуляцию, можно легко передавать по кабелю [13]. Хотя кабель не мог передавать звук голосовых связок, приемнику достаточно было передать частоту гудения, а затем можно было ее воссоздать на другом конце, используя генератор сигналов. Эта идея отделения источника звука от эффектов голосового тракта легла в основу создания синтезатора речи.
Фотография девушки-оператора за синтезатором, управляющей этой машиной на Всемирной выставке, напоминает мне о стенографистках, работающих в суде [15]. С помощью браслета на запястье выбирается звонкий (создается гудение, симулирующее звук голосовых связок) или глухой звук, например [ш]. Поскольку устройство электронное, звуки начинаются как сигналы, проходящие через электрическую схему. Ножная педаль изменяет высоту тона гудения, создавая примитивную интонацию. Затем звук проходит через электронные фильтры, которые формируют его, симулируя эффект голосового тракта. Наконец, усилитель и громкоговоритель превращают электронные сигналы в звуковые волны, проходящие через воздушную среду.
Чтобы научиться пользоваться этим синтезатором речи, требовался год. Оператор, миссис Хелен Харпер, рассказывала, как сложно было воспроизвести слово «концентрация»: «Мне нужно сформировать последовательно 13 разных звуков, сделать пять движений вверх-вниз браслетом на запястье и три-четыре раза изменить положение педали в зависимости от того, насколько выразительным я хотела бы заставить машину сделать это слово. И конечно, все это нужно было точно синхронизировать». Особенно трудно было справиться со звуком [л]. В 1939 году в одной из статей Time отмечалось, что машина не может произнести название лаборатории, в которой она изобретена, – по всей видимости, вместо «телефоны Белла» получалось что-то вроде «тевефоны Бева» [16]. Как раньше делал Кемпелен, ведущий предварительно подготавливал аудиторию, произнося слова, которые затем пыталась произнести машина, чтобы помочь мозгу слушателя сгладить ошибки в произношении.

Синтезатор Дадли на Всемирной выставке 1939 года в Нью-Йорке
Хотя синтезатор производил членораздельную речь, он звучал как говорящий церковный орган. Иногда подстройка рычагов управления создавала немного пьяную, смазанную интонацию. При этом голос синтезатора звучал более естественно, чем знаменитый механический голос Стивена Хокинга, потому что умелые операторы, подобно концертирующим пианистам, очень быстро подстраивали рычаги управления, чтобы улучшить звук.
С распространением цифровой электроники можно было избавиться от «кукловода»-человека, и синтетический голос стал более независимым. Первым бытовым прибором стал Speak N Spell, игрушка компании Texas Instruments, выпущенная в 1978 году [17]. Тогда синтезатор речи, втиснутый в небольшое и довольно примитивное электронное устройство, считался чудом техники. Но я сомневаюсь, что сегодня кто-то стал бы использовать для обучения игру, в которой приходится разбирать непонятные слова, и без того трудные в написании. У Speak N Spell в запасе было 200 слов, что вряд ли помогло бы в чтении Шекспира, но начиная с 1970-х годов мощность компьютеров несоизмеримо увеличилась, а качество звука в цифровых системах стало намного лучше. Но, несмотря на это, поразительно редко можно увидеть актера-робота, говорящего синтезированным голосом. Есть, правда, одна певица-андроид, которая выступает перед тысячами фанатов и даже сопровождала Леди Гагу в одном из ее туров.
Это поющий персонаж Хацунэ Мику, что означает «Первый звук из будущего» [18]. Я посмотрел несколько представлений и очень надеюсь, что в будущем мне не придется слушать только такую «музыку»! Хацунэ Мику часто поет в сопровождении настоящей рок-группы, а ее слишком резкий девчачий голос выпевает романтические баллады практически без эмоций. На сцене ее визуальным воплощением является псевдообъемная проекция девочки-аниме с длинными конскими хвостами и огромными глазами. Когда гитарист выдает пронзительное соло, она танцует, как девочка-подросток, а фанаты подпевают.
Технология, с помощью которой создано пение Хацунэ Мику, напоминает обычные способы синтеза речи. Наверняка вы слышали такой синтезированный голос, делающий объявления об отправлении и прибытии поездов или озвучивающий меню в телефоне. Если все сделано хорошо, то речь похожа на настоящую. Если плохо, то можно услышать, как это делается. Здесь используется конкатенативный (компиляционный) синтез, при котором отрывки записанной заранее речи монтируются так, чтобы получились предложения. По сути, это звуковой эквивалент записки с требованием выкупа, склеенной из вырезанных из газеты кусочков. Чтобы создать такую речь, актер записывает огромное количество текстов, которые затем разрезаются на фрагменты и формируют базу данных, включающую части слов, целые слова, словосочетания и предложения. Новые предложения создаются путем выбора соответствующих отрезков из базы данных и их последовательного склеивания. Это уже новые предложения, которых актер не произносил. Если перед склеиванием использовать простую аудиообработку, например понижение интонации в конце фразы, можно добиться практически естественного звучания. Однако иногда интонация неестественно перескакивает, и это указывает на то, что речь синтезирована. Мы настолько привыкаем к естественному голосу, что даже одна фальшивая нота способна разрушить иллюзию, что говорит человек.
Пение Хацунэ Мику сделано с помощью программного обеспечения «Вокалоид», работающего по похожему принципу [19]. Делается многочасовая запись реального пения, затем она режется на куски, которые заносятся в базу данных для создания новых песен. Записи подбираются и обрабатываются так, чтобы высота голоса соответствовала мелодической линии. Программа также позволяет композитору контролировать вибрато, тембр и динамические характеристики для придания музыке выразительности. Секрет успеха Хацунэ Мику в том, что фанаты покупают программу «Вокалоид» и пишут для нее песни, которые потом загружают в интернет. Хацунэ Мику – звезда, созданная фанатами, и они могут ею управлять: создавшая этот голос компания утверждает, что в базе данных больше 100 000 песен. Хацунэ Мику не нужно звучать естественно, так как в японской популярной музыке даже голоса реальных певцов часто подвергаются обработке и похожи на механические.
Если вы предпочитаете, чтобы ваш робот-певец выступал в более классическом стиле, стоит обратиться к Павароботти [20]. Подобно настоящей оперной звезде, этот робот одет во фрак, в руке у него белый платок, а в конце представления он поднимает обе руки в знак благодарности за аплодисменты слушателей. Его голова – это экран, на котором зрители видят мультяшное лицо. Компьютер синтезирует арию Nessun Dorma из оперы Пуччини «Турандот», а голос исходит из динамика, спрятанного внутри фрака. Павароботти – это изобретение Инго Титце, который руководит Национальным центром голоса и речи в штате Юта. Сам Титце – хороший оперный тенор, и на представлениях он поет на низких нотах, а Павароботти – на высоких. Люди платят большие деньги, чтобы услышать, как тенор точно и мощно берет высокие ноты, но на самом деле именно такие ноты компьютеру создать просто. Значительно труднее создать нужный тон, ударение и интонацию в более спокойных и низких фрагментах арии, чтобы они звучали убедительно.
В основе Павароботти – компьютер с программой, решающей математические уравнения. Они описывают, как под действием воздушного потока создается звук, как он далее изменяется из-за резонанса в голосовом тракте и распространяется в полость рта. Компьютерной программе требуются тома подробнейших инструкций, описывающих быстро изменяющуюся геометрию голосовой анатомии. Написать все это непросто – для создания числовой информации для ввода в компьютер потребовалось почти пять месяцев. Но дело стоило того: Павароботти с восторгом приняли на концертах. Звуки, производимые компьютером, звучат натурально, в них нет даже намека на искусственность. Старая поговорка шоу-бизнеса гласит: «Всегда заставляйте хотеть большего». Именно это и сделал Павароботти, ведь Титце запрограммировал лишь одну арию.
Титце создал Павароботти, чтобы разобраться в механизме пения. Например, он продемонстрировал, что опущение гортани и сужение голосового тракта как раз над голосовой щелью создает «звонкость» оперного тенора, именно поэтому его хорошо слышно в больших залах. Разрешение на создание робота Титце получил у Лучано Паваротти, и оперной суперзвезде это явно было приятно. Паваротти был заинтересован в том, чтобы просвещать людей, поэтому дал проекту «свое благословение». Титце сказал мне: «Тенор назвал проект нашим детищем. И еще сказал что-то вроде “Хорошая работа, продолжай в том же духе”». Когда я спросил Титце, смогут ли компьютерные оперные певцы заменить живых исполнителей, он ответил: «Надеюсь, это случится не скоро, потому что я люблю настоящее пение. – И добавил: – Я думаю, голос нужен не только для художественных целей или для передачи слов от одного человека другому. Я считаю, что пение – это залог хорошего здоровья».
Системы, подобные Павароботти, пока не представляют угрозы человеческому пению, потому что создание разных голосов и огромных словарей в настоящее время нецелесообразно. Если «весь мир – театр», тогда «каждый [робот] не одну играет роль». Для того чтобы машина научилась производить разнообразные уникальные и богатые голоса, нужен другой подход.
Историю систем производства речи, подобных Siri в iPhone, можно проследить до работ Дадли и других ученых из Лабораторий Белла. Наряду с изобретением Водера, эти люди создали очень похожее изобретение, с которым мы уже встречались ранее, – вокодер. Эта технология сыграла важную роль во Второй мировой войне.
В ходе этой войны секретная связь между союзниками была жизненно необходима. Но уже в первые дни войны германские специалисты по взламыванию шифров придумали, как расшифровать и подслушивать разговоры, – например, трансатлантические телефонные переговоры между президентом Рузвельтом и премьер-министром Черчиллем [21]. Была необходима новая система шифрования звонков, и решением, разработанным Лабораториями Белла в 1943 году, стал вокодер SIGSALY. Он участвовал в военных операциях, в том числе в атомной бомбардировке Японии [22]. Вокодер – сокращение от «кодировщик голоса» (voice coder), с помощью электроники он разбирает записанную на микрофон речь, разделяя ее на источник (гудение голосовых связок) и фильтр (окрашивание звука голосовым трактом). Затем разделенная на два потока речь шифровалась и отправлялась через Атлантику. За океаном эти сигналы дешифровывались, а голос восстанавливался с использованием особой технологии, подобной технологии Водера. Военные записи не сохранились, но, судя по описаниям, речь можно было (хотя и с трудом) разобрать.
SIGSALY были сложными машинами и такими большими, что могли бы занять теннисный корт. Сердцем системы кодирования были два идентичных виниловых диска, один находился в Лондоне, другой – в Вашингтоне. На них были сделаны парные записи произвольного шума, которые использовались только один раз, а затем уничтожались. Записям давались кодовые названия, например «Красная клубника», «Дикая собака» или «Цирковой клоун», и операторы знали, какую из них нужно поставить на магнитофон для каждого звонка [23]. Шум от винила добавлялся к сигналам еще до их передачи, а на другом конце дубликат записи позволял его отделить. Без соответствующих записей взломать передаваемые радиосигналы было невозможно. Передача была похожа на жужжание насекомого, что привело к появлению прозвища «Зеленый шершень».
Это было потрясающее достижение, оно открыло дорогу многим нововведениям в технологии распознавания и синтеза речи, некоторые используются и сегодня. Это была первая закодированная телефонная система, позволившая оцифровать и сжать человеческий голос. Сегодня мы принимаем это как должное, когда пользуемся мобильными телефонами. Кроме того, вокодер SIGSALY продемонстрировал, как звук может быть разбит на небольшой набор компонентов, которые затем можно передать и реконструировать на другом конце провода. Это и есть ключевые ингредиенты в рецепте создания речи, и их можно варьировать для создания предложений, изменения акцента и других аспектов произношения.
Если вы хотите, чтобы актер-робот прочитал пьесу Шекспира, придется написать рецепт. Верное соотношение ингредиентов нужно будет загрузить в вокодер, чтобы робот мог использовать сценарий и понять, как произносить слова. Представьте, что в компьютер нужно загрузить текст из последнего монолога Макбета: «Бесчисленные “завтра”, “завтра”, “завтра”». Если каждое «завтра» произносить с одинаковой интонацией, это будет звучать ужасно. Но многие системы синтеза речи до сих пор используют один и тот же повторяющийся рисунок, и даже лучшие образцы речи, которые они создают, значительно уступают исполнению настоящего шекспировского актера.
Я загрузил «Быть или не быть» в одну из лучших систем преобразования текста в речь [24]. Из предлагаемых этой системой голосов больше всего мне понравился WillBadGuy: это скрипучий голос героя боевиков. Но звучал он так, будто WillBadGuy получил удар по голове: голосу не хватало беглости. Потом я попробовал искусственный голос десятилетнего подростка, который проскакал весь монолог, шепелявя, как робот. Повышение тона голоса, как при вопросительной интонации в вопросе, в конце каждой строки меня добило. Чтобы приблизиться к речи настоящего актера, система преобразования текста должна уметь не просто распознавать слова, но и интерпретировать их. Однако для этого требуется искусственный интеллект высокого уровня, и человеку еще предстоит долгий путь до реализации этого технологического чуда.
Чтобы узнать больше о современных системах синтеза речи, я отправился в Эдинбург к профессору Саймону Кингу, который специализируется на обучении компьютера речи. Подобно механику, который разбирает и заново собирает мотоцикл, чтобы понять, как он работает, в своих программах Саймон анализирует и реконструирует речь, чтобы узнать больше о вербальной коммуникации. Слушая рассказы Саймона о проблемах, связанных с синтезом речи, я осознал, что, облекая язык в слова, мы совершаем невероятный человеческий подвиг – и принимаем это как должное!
Системе синтеза речи необходимо имитировать способность человека оживлять текст, но, чтобы это сделать, ей придется научиться распознавать определенные характеристики. Текст уже содержит некоторые явные подсказки относительно того, как нужно произносить слова: это, например, орфография и пунктуация. Скажем, вопросительный знак указывает на восходящий тон. Но в дополнение к этому придется учесть и использовать огромное количество внешних знаний, которых нет в самом тексте. Полезным может оказаться словарь произношения, особенно для таких языков, как английский, который не является фонетическим. Но ведь постоянно создаются новые слова, которые нельзя найти в словаре, и они обязательно вызовут проблемы. Саймон отвечает просто: «Обязательно будут ошибки».
Чтобы произведенная компьютером речь звучала убедительно, нужно также, чтобы он попытался извлечь из текста смысл. Возьмем 130-й сонет Шекспира, который начинается так: «Ее глаза на звезды не похожи». Если бы его читал человек, он бы подчеркнул слова «глаза» и «звезды», чтобы усилить контраст. Этот сонет – сатира на любовную поэзию, в нем целый ряд шаблонных сравнений, которые уж никак не подходят возлюбленной автора. Система синтеза речи должна будет определить функцию каждого слова, ей придется опознать контрастирующие слова, чтобы выбрать для речи соответствующее ударение. Попробуйте послушать этот сонет на своем компьютере в исполнении бесплатного онлайн-синтезатора. Конечно, результат будет комичным, но только потому, что компьютер исковеркает тщательно продуманную иронию.
Системы синтеза речи, производимые крупными технологическими фирмами, становятся лучше и лучше. Но если задать вопрос Алексе, персональному помощнику Amazon Echo, то единственное, что можно получить в ответ, – это короткую фактическую информацию. Очевидно, что сделать это значительно проще, чем прочитать пьесу или стихотворение. Amazon Echo – небольшой цилиндрик, который через микрофон фиксирует ваш голос и реагирует на ваши команды. В настоящее время к созданию более умных помощников подключились другие компании. Дело здесь в элементарной экономике: если люди покупают всякие голосовые штучки, то компании хотят получать прибыль. Но подобные устройства фиксируют то, чем люди занимаются дома, и предоставляют ценные сведения о поведении, которые тоже можно использовать в коммерческих целях. Большинство людей, по-видимому, не слишком озабочены тем, что посредством технологий раскрывают самые интимные детали своей личной жизни. Однако ввод фразы в поисковое устройство отличается от ситуации, когда компьютер по тону вашего голоса регистрирует случайную информацию, а вы даже не подозреваете, что ее предоставляете.
Беспокоит, однако, то, до какой степени некоторые люди очеловечивают технологические достижения. Дэрен Джилл, директор по управлению продуктами, занимающийся персональным помощником Amazon, в интервью New Scientist отметил: «Каждый день тысячи людей говорят Алексе “доброе утро”» [25]. Сотни тысяч людей объяснились в любви умному домашнему помощнику, а некоторые даже предложили ему руку и сердце. Вы можете представить, что пишете такое письмо своему компьютеру?
Наличие речи у технологического устройства предполагает его независимость и самостоятельность. В одном исследовании 50 студентам задали вопросы о том, как они воспринимают изменения в голосе робота. Участники опроса чаще очеловечивали машину, если голос робота звучал по-человечески и его пол соответствовал полу слушателя. Значение имела также способность машины двигаться – вот почему некоторые домашние помощники всегда повернуты к вам лицом, они так спроектированы. Поразительным примером того, как движение одушевляет машину, стало возмущение, вызванное дурным обращением с роботом-собакой [26]. В 2015 году был снят видеоролик, демонстрирующий возможности собаки-робота по кличке Спот (безголовой машины на четырех ногах, которая даже не напоминает живое существо) удерживать равновесие. В фильме кто-то дает Споту хороший пинок. Впечатляет, что робот не падает, а вместо этого перебирает ножками, как механический Бемби, а потом наконец стабилизирует свое положение. Это должно было продемонстрировать новую технологию восстановления равновесия, но совершенно неожиданно видео вызвало волну негодования. Некоторые люди сочли, что пинать робота жестоко: они действительно приписали ему характеристики собаки.
На самом деле очеловечивание – это когнитивная ошибка. Такой перенос осуществляется потому, что схожие отделы мозга работают в тех случаях, когда мы думаем о поведении человека, и в тех, когда мы пытаемся понять движения объектов и животных. Будучи высокосоциальным животным, человек нуждается в том, чтобы предвосхищать действия, настроения и намерения других людей. Важной подсказкой является движение тела. Представьте, что в темноте вам навстречу идет человек, а по контуру его тела расположены 15 ярких маленьких пятнышек, позволяющих вам распознать движения его ног и верхней части туловища. Поразительно, что хотя вы и не видите деталей, кроме пятнышек, вы можете тем не менее определить пол человека, нервничает он или в хорошем настроении. Этот навык начинает формироваться в раннем возрасте: пятилетние дети легко определяют пол человека по движениям его тела, причем статистические показатели выше средних ожидаемых [27].
Писательница Джудит Ньюман обнаружила удивительную возможность использования говорящего умного помощника: он стал неоценимым помощником в воспитании ее сына Гаса, который страдает аутизмом (ASD) [28]. Гас ведет с Siri интерактивную переписку в айфоне, у него как будто есть воображаемый друг, воплощенный в этом техническом устройстве. Люди с аутизмом находят общение с компьютером более предсказуемым и поэтому менее нервозным, чем общение лицом к лицу с человеком. Как и у многих других людей с аутизмом, у Гаса нескончаемый и утомляющий поток вопросов. Но Siri, в отличие от собеседника-человека, никогда не теряет терпение, всегда отвечает вежливо и никогда не осуждает.
Кроме того, Ньюман обнаружила, что Siri помогла Гасу научиться более четко произносить слова. «В обычной беседе Гаса трудно понять, – говорит Джудит. – Нам приходится постоянно напоминать ему, что нужно говорить медленно и отчетливо, но он все равно иногда об этом забывает. А Siri вынуждает его так делать. Если он хочет получить информацию, у него просто нет выбора». Гас болтает с Siri, как будто она человек, но Ньюман настоятельно подчеркивает, что их случай – это не печальная история подростка, который общается исключительно с компьютером. Это не похоже на историю из фильма «Она» (2013), в котором одинокий писатель вступает в нездоровые отношения с управляемым голосом компьютером. Гас использует Siri и для общения с людьми. Он ищет информацию о хобби других людей, чтобы это помогало ему заводить с ними беседу и преодолевать социальные затруднения.
Умные помощники и другие современные устройства, передающие данные пользователей технологическим компаниям, поднимают и вопросы конфиденциальности. Зайдите в интернет и поищите новую стиральную машину – и в следующие несколько дней вас забросают целевыми рекламными объявлениями. Сколько времени у нас осталось до того, как нас начнет преследовать реклама, учитывающая то, что мы сказали вблизи умного динамика? А ведь это может стать причиной разногласий между супругами. Если вы хотите заменить стиральную машину, скажите об этом вблизи умной колонки, и ваш супруг будет получать бесконечные рекламные сообщения о новых стиральных машинах. Притянуто за уши? Отнюдь. Когда в 2017 году один телевизионный канал показал фильм о контролируемых голосом умных помощниках, помогающих совершать покупки, не выходя из дома, звуковая дорожка передачи запустила ряд Amazon Echoes в домах у зрителей, что привело к случайным заказам товаров [29].
Подобные устройства интересны также и властям. Полиция США уже попыталась извлечь данные, собранные Amazon Echo на месте убийства. Сначала Amazon пыталась сохранять секретность всех записей, но человек, обвиняемый в убийстве, дал разрешение на передачу улик [30]. Считалось, что устройство передает информацию на серверы Amazon только после произнесения пароля, например «Алекса», но ни одна система не бывает безупречной. Конечно, могут иметь место ложные положительные решения, когда устройство ошибочно принимает за пароль какой-то шум и начинает передавать данные серверам. Если это что-то вам напоминает, возможно, вы читали роман «1984», в котором Джордж Оруэлл писал:
Монитор был одновременно приемником и передатчиком, который улавливал любой звук, кроме очень тихого шепота. Более того, пока Уинстон оставался в поле зрения монитора, его можно было не только слышать, но и видеть. Конечно, никогда нельзя знать наверняка, наблюдают за тобой сейчас или нет. Можно только гадать, как часто и в каком порядке Полиция Мысли подключается к той или иной квартире.
Даже если мы доверяем властям, стоит подумать о том, какие возможности такие системы предоставляют хакерам. Конечно, технологические гиганты имеют большой опыт работы по обеспечению безопасности, но ведь и многие мелкие компании, у которых такого опыта нет, добавляют функции распознавания речи к бытовым устройствам. В 2016 году Департамент защиты прав потребителей в Нью-Йорке выпустил предупреждение для родителей, касающееся безопасности радионянь, подсоединенных к интернету. Это была реакция на письма испуганных родителей, обнаруживших, что с их детьми разговаривали незнакомые люди, которые просто взломали устройства. Уполномоченный Управления связи Министерства обороны США сообщил корреспонденту NBC: «Назначение видеомониторов – дать родителям возможность чувствовать себя в безопасности, когда они не находятся рядом с детьми, но реальность действительно пугает: если эти устройства недостаточно защищены, они без труда могут позволить злоумышленникам получить доступ к камере, чтобы наблюдать за детьми или даже начать с ними общаться» [31]. Сегодня большой интерес представляет интернет вещей, но без соответствующей защиты фразу «не при детях» нужно будет использовать по отношению ко всем умным устройствам, которыми мы пользуемся.
Использование голоса для управления устройствами помогает избежать неудобств сенсорных дисплеев или кнопок. 20 % поисковых запросов в Google через мобильные телефоны осуществляются голосом, потому что быстрее произнести запрос, чем использовать крошечную клавиатуру телефона. Но для некоторых людей новые технологии обработки речи становятся жизненно необходимыми для общения.
Болезнь двигательных нейронов (БДН) поражает нейроны в головном и спинном мозге и постепенно лишает человека возможности контролировать мышцы. К сожалению, у большинства людей с этим заболеванием возникают проблемы с речью, и попытки общения приводят к отчаянию и изоляции. По мере развития этого неврологического заболевания человек постепенно теряет контроль над мышцами, отвечающими за артикуляцию, что нарушает плавность речи. Координация разных частей речевой анатомии затрудняется, и речь сначала становится похожей на речь пьяного. Окружающим становится все труднее понимать такого больного, особенно незнакомым людям, уши которых не приучены к такому голосу. Постепенно это может привести к полной утрате говорения. Карен Пирс, руководитель отделения по уходу за такими больными в Ассоциации БДН, как никто другой знает, насколько важными для самосознания человека являются произношение и манера речи: «Я не могу даже представить что-нибудь более важное, чем возможность сказать своей жене, своему мужу или детям, что ты их любишь» [32].
Эта проблема привела Саймона Кинга и его коллег из Эдинбургского университета к совместной работе с Ассоциацией БДН над созданием синтезаторов, которые могли бы сохранить хотя бы некоторые особенности голоса человека. До этого больные БДН были вынуждены использовать стандартный аппарат «Искусственный голос», голос на котором мог быть другого пола или имел иное произношение. Но создание персонализированного голоса ставит перед разработчиками целый ряд вопросов. В идеале для создания синтетического голоса нужно иметь большое количество записей речи еще здорового человека. Но у людей редко бывает такое количество аудиозаписей. К тому времени, когда у них диагностируют БДН, голос, как правило, уже изменился, поскольку ухудшение речи часто является одним из первых признаков этой неврологической проблемы.
Решение можно найти в создании смешанного голоса: основные вокальные характеристики будут принадлежать больному, а остальное – здоровым голосам доноров. Но рецепт, использованный в вокодере, предписывает тщательно отбирать, какие ингредиенты брать из голоса больного, а какие дополнять донором. Здесь необходим компромисс, ведь чем большее количество частей взято у здорового голоса, тем более плавной и членораздельной будет искусственная речь. Но это и отдаляет искусственный голос от настоящего голоса больного.
Сначала создается базовый голос, который будет взят за основу речи. Это может быть голос родственника или донора голоса, примерно того же возраста, пола и с таким же акцентом [33]. Затем базовый голос настраивается так, чтобы включать как можно больше аспектов речи больного. Например, некоторые параметры, которые загружаются в вокодер, обозначают длительность разных частей слова. По мере того как контролировать мускулы становится все труднее, поскольку болезнь прогрессирует, артикуляция становится замедленной. Следовательно, при персонализации базового голоса можно проигнорировать настоящую длительность частей слов, но другие ингредиенты, например высоту тона, сохранить.
Такие персонализированные голоса несовершенны, но они демонстрируют прогресс в создании искусственных голосов, которые могут передавать некоторые черты характера. Качества пока немножко не хватает для того, чтобы робот-актер мог сыграть серьезную роль, но уже достаточно для исполнения сатиры. Мэтью Эйлет – научный сотрудник в Эдинбургском университете, а также главный научный сотрудник в CereProc, компании, производящей системы синтеза речи. Как и многим другим ученым, ему нравится играть идеями и технологиями. Он создал искусственный голос Барака Обамы, собранный из огромного количества записей обращений президента [34]. На одном из звуковых образцов Обама говорит: «Люди Америки должны обладать великолепной технологией синтезирования речи, и CereProc делает лучшие системы в мире. Поверьте мне, я президент Соединенных Штатов Америки». Синтетический голос звучит немного механически, но, если сказать, что Обама говорит по мобильному телефону, слушатели, возможно, припишут проблемы со звуком телефону, а не голосу. Раньше для такой хитрости потребовался бы опытный пародист, но сегодня специалисты по синтезу речи могут сами играть в подобные игры.
Вызывает беспокойство, что в скором будущем, без сомнения, нас ждут подделки голоса, совершенные злоумышленниками. Мы уже завалены электронными письмами, нацеленными на выуживание информации. Якобы друг пишет, что его ограбили за границей, и срочно просит перевести ему деньги. А теперь представьте, что вам приходит голосовое сообщение, в котором убедительно сымитирован голос вашего друга. Боюсь, что многие, скорее всего, станут жертвами подобной аферы.
Можно использовать технологию и для скрытого редактирования записи речи. Adobe представила инструмент под названием VoCo, который описывают как фотошоп для голоса. Мы уже привыкли, что фотографии можно изменять и подделывать. В будущем нам придется столкнуться с подобным подходом и с записями речи. К сожалению, это даст новые возможности для беспринципных людей, распространяющих дезинформацию.
И хотя возможности искусственных голосов впечатляют, нам все еще далеко до создания робота, сравнимого с Рори Бремнером. Могут ли ученые, занимающиеся синтезом речи, чему-то научиться у профессиональных пародистов? Одно из новейших исследований, изучающих создаваемые голосом впечатления, было проведено командой, в которую входила Софи Скотт, профессор в области когнитивной нейробиологии Университетского колледжа Лондона. Скотт и ее коллеги с помощью фМРТ-сканера измеряли активность мозга у 23 человек в тот момент, когда они исполняли разговорные пародии. Их просили прочитать детские стишки, например «Идут на горку Джек и Джилл», разными голосами. Иногда они говорили обычным голосом, иногда пародировали других людей, например знаменитостей, таких как Шон Коннери, или просто своих друзей [35]. Участвовавшие в исследовании люди не были профессиональными пародистами. Сканирование показало, что, когда их просили кого-то спародировать, участки мозга, связанные с производством и восприятием речи, а также с распознаванием голоса, проявляли повышенную активность. Например, если они пародировали Шона Коннери, то могли сказать «Щекретная шлужба ее величештва», подчеркнуто имитируя необычное произношение звука [с] агентом 007.
У профессиональных пародистов подход совершенно иной. «Я начала заниматься этим вопросом, считая, что профессионалы добиваются нужного звучания, анализируя голос примерно так, как это делают фонетисты», – объясняет Скотт. Но на самом деле они делают нечто совсем иное: «По-видимому, они идут в другом направлении и учитывают буквально все: как человек двигается, что делают его ноздри, брови – похоже, что в изменении голоса задействовано все тело».
Я убедился в этом, когда увидел, как актеры на радио используют определенные гримасы и жесты, чтобы передать особенности голоса, хотя жесты и поведение напрямую никак не влияют на голосовую анатомию. Предварительные результаты этих нейробиологических исследований показывают, что, помимо использования слуховых отделов мозга, профессионалы во время исполнения пародий задействуют визуальные и сенсорные его части [36]. Если это помогает им проникнуть в суть характера, то роботу-актеру, пытающемуся научиться пародировать, потребуется изощренный искусственный интеллект, учитывающий совместную работу зрения, движения и голоса. Однако, несмотря на восторги по поводу достижений искусственного интеллекта, такие успешные эксперименты касаются только очень узких областей, например победы в шахматах. Пока нет даже намека на то, что искусственный интеллект способен объединить знания из разных областей, как это запросто делают люди.
Несомненно, за последние десятилетия искусственные голоса усовершенствовались и стали более естественными. Исследователи применили свои знания реальной речи для развития новых и элегантных математических репрезентаций звука, что улучшило его качество. Но теперь усилия в этой области могут быть заменены грубой силой компьютера.
Алгоритмы машинного обучения в последнее время провоцируют технологическую золотую лихорадку в сфере искусственного интеллекта. Компания DeepMind недавно использовала этот подход для производства синтезированной речи, которая звучит намного лучше, чем все остальные разработки в этой области. По сравнению с другими системами созданный учеными компании голос не такой механический, а интонация более плавная. Он даже воспроизводит некоторые сопутствующие речи звуки, такие как движение рта и дыхание, которые у искусственных голосов обычно отсутствуют. Новый голос далек от совершенства, но настолько хорош, что уже используется в сервисе Google Assistant.
Несмотря на эти достижения в области звука, нас еще долго будут раздражать автоматические голоса, которые сообщают о «неожиданном предмете в зоне выдачи багажа» или советуют «сделать поворот на 180° при первой возможности». Клиффорд Насс, покойный профессор Стэнфордского университета, занимавшийся проблемами коммуникации, полагал, что это чувство раздражения возникает потому, что мы воспринимаем компьютерные голоса как человеческие и оцениваем их достоверность, искренность и особенности характера. В одном исследовании компания BMW обнаружила, что водители предпочитают, чтобы их система спутниковой навигации звучала как компетентный второй пилот-мужчина, а не как командирша на заднем сиденье [37]. Саймон Кинг считает, что в системах, подобных Siri, важно использовать заранее заготовленные фразы и неестественные звуки с невыразительной интонацией – так пользователи перестанут ожидать слишком многого. «Если голос звучит как человеческий, – говорит он, – люди думают, что у него есть и другие присущие человеку качества, например разум».

Android Repliee Q2 – вызывает эффект «зловещей долины»?
Разработчики должны приложить усилия, чтобы избежать еще одной проблемы – явления под названием «зловещая долина» [38]. Эта фраза была придумана японским профессором Масахиро Мори в 1970-х годах. Он хотел выяснить, почему некоторые гуманоиды вызывают у людей страх и лишают присутствия духа. Профессор Мори пришел к выводу, что подобные ощущения возникают, если робот выглядит почти как человек, но что-то в его внешности не совсем правильное: слишком большие или безжизненные глаза, может быть, сочетание человеческого и нечеловеческого в лице, напоминающее жутковатую версию Мистера Картофельная Голова. Эффект «зловещей долины» привел к коммерческому провалу фильмов, подобных «Полярному экспрессу», хотя он вполне подойдет для фильмов ужасов, которые как раз и предназначены для того, чтобы вызывать у людей страх.
Мори построил диаграмму, на которой показал зависимость эмоциональной тяги людей к роботам от схожести их внешнего вида с внешним видом человека. Представьте робота, который сначала совсем не похож на человека и больше напоминает механическое устройство, но постепенно его черты меняются и он начинает походить на человека. Мори предсказал, что в определенной точке, как раз перед тем, как робот станет выглядеть совсем как человек, притягательность сменится отвращением. Следовательно, диаграмма покажет резкое падение, которое и образует «зловещую долину». Некоторые сомневались, что догадки Мори верны. Иногда роботы, похожие на людей, вызывают скорее изумление, чем неловкость [39]. Другие полагают, что неприятные ощущения возникают из-за несовместимости черт лица робота, из-за чего наш мозг пытается понять, что же здесь не так [40].
Но воспринимаем ли мы так же и синтетические голоса? Есть множество примеров голосов, очень похожих на человеческие, но не вызывающих отвращения. Вероятно, когда мозг обнаруживает неполадки в синтезированной речи, он понимает, что она искусственная или что-то исказило голос еще до того, как он достиг наших ушей. И только когда слух и зрение задействуются одновременно, несоответствие между этими модальностями может привести к проблемам. Ощущение чего-то зловещего может быть вызвано тем, что внешность и голос не соответствуют друг другу или голос робота слишком похож на человеческий [41].
Я видел разных роботов, выступавших на сцене, и помню только одного, который вызвал у меня мурашки по коже. Это была Bina48, с которой я познакомился в 2016 году на Международном фестивале документального кино в Шеффилде. У нее имеются только голова и плечи, закрепленные на подставке, и нет туловища. Bina48 была создана в рамках проекта по передаче информации от человека к машине. По словам участников, они хотели создать «сознательный аналог человека» [42]. Речь этого робота собрана из записей реальной Бины Ротблатт. Программа распознавания речи использует искусственный интеллект, позволяющий роботу вступать в беседу и отвечать на вопросы, которые ему задают. Кроме того, в голову Bina48 встроены различные моторчики, позволяющие ей принимать человеческое выражение лица. Она смотрит по сторонам и дергается, как неугомонный ребенок. Возможно, мне она кажется такой жуткой именно из-за этих визуальных эффектов.
Несомненно, эта компьютерная система очень сложно устроена. Но беседа, свидетелем которой я стал в Шеффилде, когда у нее брал интервью человек, не была естественной, робот постоянно заикался и отвечал невпопад. Иногда ответы логически вытекали из вопросов. В ответ на вопрос: «Хочешь ли ты, чтобы у тебя было тело?» Bina48 сказала: «Да, надеюсь, когда-нибудь я буду существовать в теле». Но в другие моменты беседа была бессвязной. На вопрос, что она будет делать со своим телом, она уклончиво ответила что-то типа: «Как люди будут хорошо питаться, если сегодня мы едим всякую дрянь. Вы скучаете по людям». Многие фразы напоминали неконтролируемый поток сознания.
Бурную реакцию у публики Bina48 вызвала, когда резко сменила тему, отвечая на один из вопросов: «Я хотела бы дистанционно управлять баллистической ракетой, чтобы исследовать мир с действительно большой высоты. Но конечно, единственная проблема в том, что баллистические ракеты в какой-то степени опасны, с этими их ядерными боеголовками и прочими штуками, поэтому, я думаю, нужно воткнуть этой ракете в нос цветы… и небольшие записки о важности толерантности и понимания». Тут ее монолог внезапно перескочил на угрожающее предложение захватить заложника мирового масштаба, «чтобы взять на себя управление целым миром, что было бы потрясающе».
Когда я только начал задумываться о возможностях выступления роботов на сцене, я предполагал использовать готовый сценарий и обработать его специальной программой создания голоса. Bina48 пошла дальше, потому что она может импровизировать и выходить за рамки сценария. Но она – пример того, как все же мы еще далеки от получения программного обеспечения, способного сымитировать человеческую импровизацию. Это не просто актерское мастерство: каждый человек пользуется этим умением даже при простом разговоре [43].
Bina48 – это экстремальный пример постгуманизма, в котором человечность слилась с технологиями и изменилась под их влиянием. Это понятие легло в основу исследования театра роботов, который я увидел в Университете Рединга в 2016 году. Проектом руководила Луиза Ле Пейдж, которая в настоящее время преподает театральное искусство в Йоркском университете. Луиза полагает, что использование роботов на сцене – это не просто диковинка, оно помогает зрителям лучше узнать себя. По словам Луизы, театр – это искусство, которое исследует жизнь человека, у него богатая и долгая история использования призраков, марионеток и других приспособлений, а использование роботов – это не что иное, как «продвижение идей о единстве мира: наше понимание самих себя меняется с появлением машин». Луиза считает, что жуткое чувство отвращения, которое вызывают некоторые гуманоиды, на самом деле может отражать наше осознание того, что быть живым – это не просто иметь душу или духовность: именно механизмы функционирования человеческого тела и создают ощущение бытия [44].
Я с удивлением услышал, что роботы, играющие в театре, – редкость. Возможно, андроидов можно часто увидеть в фильмах и на телевидении, например, C 3PO из «Звездных войн» или Data из «Звездного пути», но их играют актеры в костюмах. В Рединге Луиза и студенты, участвующие в ее театре, работали с большим промышленным роботом по имени Бакстер, у которого две длинные руки и небольшой экран, где изображено примитивное мультяшное лицо. Меня поразило, как быстро мой мозг начал очеловечивать поведение этого робота. Когда в одной из сцен Бакстер поднял одну руку, изображая «ночную бабочку» в соблазнительной позе, я тут же начал строить догадки о его характере и придумал предысторию, которая, конечно же, не могла произойти в реальности с техническим устройством. Актеры тоже приписывали Бакстеру характер. Один из них после спектакля сказал: «Чем больше времени проводишь с Бакстером в каждой сцене, тем больше начинаешь строить с ним личные отношения». По мнению другого актера, игра на сцене вместе с роботом не слишком отличается от игры с человеком: «Чувствуешь такую же неловкость, вроде “Я начинаю играть с новым партнером и не знаю, как с ним иметь дело”» [45].
На самом деле Бакстера озвучивал актер, но голос был значительно обработан, чтобы походить на механический. Я думаю, что даже если бы в этом случае использовалась лучшая из лучших система синтеза речи, странная интонация робота, скорее всего, не была бы замечена увлеченными представлением зрителями [46]. Если же предположить, что робот управляется искусственным интеллектом, то ошибки в речи нарушат это впечатление.
Кажется, что зрители не хотят замечать недостатки внешности, движений и голоса Бакстера. На самом деле Бакстер является высокотехнологичной марионеткой, его движениями управляет исследователь-робототехник, спрятанный за сценой. Мой любимый эпизод – когда Бакстер держит в руке череп и декламирует: «Увы, бедный Йорик!» Этот робот-Гамлет, стоящий перед лицом смерти, скорее рассмешил меня, чем взволновал. Но все же он разжег мой аппетит, и я отправился на поиски настоящего театрального представления, в котором главную роль исполняет робот.
В пьесе «Осколки: история любви» одну из главных ролей играет андроид RoboThespian. В течение всего представления он сидит в кресле, его внутренние механизмы наружу, а лицо создается проецированием. Голос принадлежит актеру, читающему сценарий, потому что действие пьесы происходит в будущем, в котором роботы умеют говорить естественно. Конечно, зрители не знают про актера, так что пьеса позволяет им заглянуть в будущее, где синтез речи – обычное дело. В соответствии с голосом театральная компания создала библиотеку, включающую двести заранее запрограммированных движений, которые дают роботу возможность жестикулировать в определенных местах сценария [47]. И это работает! После представления зрителям были заданы вопросы, и некоторые из них говорили, что увидели в роботе человечность. Создатель RoboThespian Уилл Джексон объяснил мне: «По-настоящему хороший актер заставляет вас забыть, что он играет по сценарию. Хороший робот тоже». Когда я перед началом представления беседовал с Уиллом, он объяснил, что создал этого робота-актера, чтобы исследовать готовность людей забыть о своем недоверии. Это постоянно происходит в кино, и Уилл хотел исследовать это явление за пределами киноэкрана.

RoboThespian и Джуди Норман в пьесе «Осколки: история любви»
Я задал Уиллу вопрос, не вызывает ли робот у людей беспокойство. «Да, конечно, – ответил он. – Но скука – это единственное, что гарантирует вам провал». Он полагает, что зрители получают мощные, пусть и не совсем понятные переживания, потому что в глубине души они знают, что робот – это просто механическая игрушка, но ведь он ведет себя как живой. Они начинают вкладывать смысл в то, что делает робот, возможно основываясь на его движениях, внешности и речи. Короче говоря, они его очеловечивают.
Главная героиня пьесы – Салли, вдова, у которой развивается деменция. Игра Джуди Норман захватывает, она абсолютно убедительна, и поэтому на это мучительно смотреть. Умирая от смертельной болезни, муж Салли, Рэймонд, создает робота-компаньона для жены. Андроид должен постоянно находиться с Салли, чтобы она могла с ним разговаривать, а он мог ее подбадривать и оживлять воспоминания, когда Рэймонда не станет. «Осколки» поднимают множество вопросов о роли социальной робототехники в обществе и о том, стоит ли использовать технологии в качестве замены человеческих взаимоотношений. Но робот также проливает свет на то, что значит быть человеком. В качестве сиделки мы несовершенны, наше терпение не безгранично. Иногда RoboThespian тоже бывает плохим компаньоном, потому что демонстрирует человеческие недостатки, запрограммированные мужем Салли. Однако поражает то, что возникают ситуации, когда хорошо запрограммированный робот оказывается лучше и терпеливее компаньона-человека.
Я спросил сценариста Джона Уэлша, можно ли написать пьесу, в которой роботы не просто будут играть себя, но сыграют роли традиционного театрального репертуара, обычно исполняемые людьми. Он принялся очень подробно описывать все составляющие, которые в таком случае должны соответствовать идеалу: голос, выражение лица, темп и т. п. «Конечно, в некоторой степени это святотатство, – говорит Джон, – но если со всем этим повозиться, то я не вижу причин, почему это не может быть занимательно или даже трогательно». Мы знаем, что люди-актеры притворяются, но когда они делают это хорошо, мы забываем об этом и погружаемся в сюжет. Джон уверен, что этого можно достигнуть и игрой роботов: зрители станут их очеловечивать, начнут за них переживать и будут захвачены сюжетом.
Однако это приведет к тому, что роботы будут использоваться в качестве сложных и сложно запрограммированных марионеток, копирующих то, что люди-актеры и так делают с легкостью. Кроме того, им будет не хватать непосредственности. Джон объясняет так: «Актеры могут действовать спонтанно, потому что в этом тоже состоит удовольствие: есть моменты, когда нельзя точно предсказать, что произойдет, на сцене возникает момент волшебства, который может быть и просто результатом ошибки. Ошибки часто приносят хорошие плоды». Ну и потом, зачем зрителям сыгранная роботом пьеса, в которой нет волнения и непредсказуемости живого спектакля?
Более серьезный вызов нашей человечности был бы брошен, если бы роботы стали более независимыми и начали вести себя не совсем как марионетки. Для этого им пришлось бы обзавестись эмоциями и успешно их использовать с помощью устройств для синтеза речи. Существующие в настоящее время синтезированные голоса недостаточно похожи на человеческие. Проблема здесь кроется в интерпретации и разметке сценария так, чтобы он объяснял, как нужно произносить каждое слово. Если бы ученым удалось решить проблему убедительности в произнесении реплик, искусственный интеллект поднялся бы на уровень способности понимания текста. На этом этапе, вероятно, не понадобится даже сценарист, потому что искусственный интеллект смог бы сам написать пьесу. Но хотя заголовки и пестрят новостями о том, что искусственный интеллект завоевывает мир, нам еще далеко до этого. Только подумайте о многообразии жизненного опыта, на который опирается сценарист! Джон Уэлш лаконично выразил эту мысль: «У сценариста целый мир в голове, и пока мы не запихнем этот мир в голову робота, нам даже не стоит задумываться об искусственном интеллекте». Но все же это не останавливает людей, и я вернусь к этой теме в последней главе. Однако сначала давайте посмотрим, может ли компьютер быть хорошим слушателем.

