Книга: Зачем мы говорим. История речи от неандертальцев до искусственного интеллекта
Назад: 4 Харизма голоса
Дальше: 6 Все роботы – актеры
5
Голос, оснащенный электричеством
Четыре десятилетия спустя после первой записи «У Мэри был маленький барашек» Эдисон счел, что фонограф готов к проведению серии аудиотестов для демонстрации точности воспроизведения голоса [1]. В ходе этих тестов певец стоял около фонографа, время от времени пел, а в промежутках просто артикулировал слова: звук на самом деле исходил от воскового цилиндра. Слушателям предлагалось определить разницу между живым голосом и записью на фонографе. Перед восторженными аудиториями состоялись тысячи представлений, но, скорее всего, не обошлось без надувательства. Конечно, поверхностный шум от вращающегося цилиндра должен был выдать «подставной» голос. Кроме того, разве звук не изменяется, проходя через большую воронку, необходимую для усиления записи? Оказалось, сами певцы жульничали и подражали несовершенному звуку, воспроизводимому фонографом. По иронии судьбы тесты, предназначенные для демонстрации точности воспроизведения голоса машиной, впервые показали, как техника записи влияет на пение людей.
Чтобы понять, как менялся голос в первые годы звукозаписи, я послушал дуэт Эла Джонсона и Бинга Кросби в Alexander’s Ragtime Band[2]. Бинг Кросби знаменит своим проникновенным пением. Можно ощутить чарующую легкость тона, которая создается его техникой владения микрофоном, особенно во второй части записи. Эл Джонсон, наоборот, так никогда и не приспособился к микрофону, и стиль его пения остался таким же, каким был до появления этой технологической новинки. Джонсон усиливает голос, как будто хочет быть услышанным на последних рядах зала. Так делали странствующие актеры (менестрели) и актеры водевилей. У Джонсона богатый продолжительный резонанс и специфическое звучание. Его агент, несколько преувеличив, охарактеризовал его так: «У этого человека самый звучный голос из всех людей, которых я когда-либо знал. Я встал у задней стены театрального зала, положил руки на стену и почувствовал, как вибрируют кирпичи» [3].
Усиление голоса было необходимо на заре звукозаписи, потому что фонографу не хватало чувствительности. Приходилось петь или громко кричать в большую воронку, иначе запись получалась слишком тихой. Но через некоторое время появился микрофон. Певцам, подобным Кросби, больше не нужна была старая вокальная техника, выработанная для пения в больших театральных залах, и они могли использовать стиль, который наилучшим образом подходил к тексту песни. Микрофон стал катализатором, ускорившим появление огромного разнообразия голосов, которые мы слышим в музыке сегодня. Но было бы неправильно считать, что современные певцы просто заново открыли давно утраченный естественный певческий голос – использовавшийся до того, как возникла необходимость усиливать его перед большими аудиториями, поскольку технологии изменили все. Послушайте Шер в Believe или металлические голоса Daft Punk, чтобы понять, насколько запись может изменить голос. Технология не просто обрабатывает голос певца в микрофоне: она его преобразует [4]. И это касается не только пения: актеры тоже изменили приемы выступления на сцене, на экране или на радио.
Первой драмой, написанной специально для радио, стала «Опасность» (Danger). Чтобы ее заказать, написать сценарий и исполнить на радио, в 1924 году потребовалось чуть меньше 24 часов. Ее автор, Ричард Хьюз, три десятилетия спустя рассказал: «Это было время немого кино, а наша “пьеса для слушания” (как я ее прозвал) должна была стать недостающей половинкой немого фильма, так сказать, представить всю историю с помощью одного только звука» [5]. В наши дни, при доступности аудиокниг и подкастов, легко не заметить, насколько радикальной была идея Хьюза.
Драматург опасался, что вводит слушателей в «мир слепых», и хотел «облегчить им эту задачу, хотя бы в этот раз». Для этого он выбрал историю, в которой по сценарию действие происходит в полной темноте. Хьюз перебрал множество вариантов, но отказался от сцены в постели, поскольку его беспокоила возможная реакция руководства BBC – «нужно было считаться с лордом Рейсом». Он остановился на истории, действие которой происходит после несчастного случая в угольной шахте. Но Хьюз решил, что если все роли будут исполняться актерами, изображающими шахтеров, то слушатели запутаются, так как голоса персонажей будут звучать практически одинаково. Таким образом, пьеса превратилась в историю с участием группы посетителей, состоящей из двух мужчин и девушки.
Хьюз включил в пьесу звуковые эффекты, но, когда наступило утро, столкнулся с проблемой: как их реализовать? Сначала он обратился за помощью к лучшим специалистам в области кино, потому что мастера шумового оформления уже умели добавлять звук к немым фильмам. Они бросали на барабан горох, чтобы изобразить дождь, включали ветряные машины, ритмично постукивали по кокосовым орехам, когда в кадре были ковбои. Хьюз заручился поддержкой звукорежиссера, но дальше встала проблема, как изобразить взрыв, лежащий в основе сюжета [6]. Громкий удар мог создать перегрузку на примитивных микрофонах и студийном оборудовании. К счастью, продюсером пьесы был изобретательный Найджел Плэйфэр. Хьюз описывал его как «своего рода гения, причем совершенно беспринципного». Для прослушивания пьесы критики собрались в комнате для прессы, что позволило Плэйфэру схитрить. Критики не поняли, что взрыв, который они услышали, на самом деле прозвучал в соседней комнате: звук прошел через стену, а не через динамики радиоприемника. Те, кто слушал передачу дома, услышали не такой впечатляющий звук, но ведь они и не писали рецензии!
Еще одной проблемой стали голоса главных героев. Актеры работали в студии, где акустические условия исключали эхо и отзвуки угольной шахты. Хьюз опасался, что, если голоса не будут звучать как надо, слушателям придется прикладывать усилия, чтобы поверить в происходящее. На помощь опять пришел Плэйфэр, он заставил актеров «засунуть свои прелестные головки в ведра». Это должно было изменить голос. Возможно, что голоса при этом звучали как при телефонном разговоре – не очень похоже на звук голоса в шахте, но, я думаю, все сошло им с рук из-за новизны предприятия. Конечно, в наши дни сделать все это гораздо проще: примитивная компьютерная программа может добавить акустику угольной шахты голосам, записанным в безэховой студии.
Для этого нужно получить звуковой отпечаток шахты или другого пространства, например пещеры, который будет выступать в качестве аудиодвойника. Это явление называется «импульсная характеристика пространства», и именно его улавливает микрофон, когда в помещении производится короткий резкий звук [7]. Импульсная характеристика пространства и чистая запись голосов, сделанная в безэховой студии, затем соединяются при помощи математической операции свертки, что делает звучание голосов актеров таким, как будто они находились в шахте. Без подобной звуковой телепортации не обходится ни одна компьютерная игра или виртуальная реальность. Такое моделирование звука повсеместно используется архитекторами при акустическом проектировании, поскольку позволяет им услышать, как будут «звучать» здания после окончания строительства.
В радиопостановках моделирование звука позволяет звукорежиссерам, используя программы обработки и синтеза звуков, изменять голоса персонажей. Но как микрофоны и электронные чудеса изменили актерское мастерство? Чтобы получить ответ на этот вопрос, я обратился к Элоиз Уитмор, дизайнеру звуков, получившей награду за лучший звуковой дизайн. Элоиз сыграла решающую роль в одном из моих собственных исследовательских проектов, для которого она создала поразительное звуковое сопровождение для систем трехмерного звука (мы еще к ним вернемся). Дизайнеры звука – безымянные герои радиопостановок: невидимые художники, стоящие за миром звуков, в который погружены слушатели. «Если звук действительно хорош, никто его не заметит, никто не скажет о нем ни слова, но если он плох, вы сразу же об этом узнаете, – объясняет Элоиз. – Звуковое сопровождение должно заменить картинку, но не завладевать происходящим, оно не должно быть более значительным, чем само представление». Умелое использование звука может помочь в представлении истории, освободив актеров от необходимости подробно говорить о том, что происходит. В качестве примера Элоиз приводит сцену из «Царя Эдипа», в которой герой обнаруживает, что его жена повесилась. Историю рассказывают старцы, и можно различить звуковые фрагменты происходящего за сценой: «Вы слышите, как Эдип заходит в комнату, как закручивается веревка, на которой висит тело. Вы слышите, как Эдип вынимает тело из петли». Современные цифровые технологии позволяют точно воспроизвести звук и сделать звуковое сопровождение намного богаче, чем это было возможно раньше. Разве можно представить подобное в радиопостановке «Опасность», когда актеры стояли перед микрофонами, а звукорежиссер извлекал звуки из разных предметов?
Для того чтобы голоса в радиопостановке звучали качественно, недостаточно нанять хорошего актера, который озвучит роль с правильным произношением. Слушатели полагаются исключительно на то, что они слышат, поэтому в свой голос актер должен вложить все. Элоиз объясняет это так: «Я подробно объясняю актерам, как голосом показать улыбку». Эмоции должны передаваться звуками, поэтому незначительный вздох или смешок помогает слушателям понять, какие чувства испытывает персонаж. Актерам также приходится преувеличенно дышать, чтобы ненавязчиво напоминать слушателям о своем присутствии. Конечно, эти незначительные звуки можно уловить только благодаря чувствительности современных микрофонов. Интересно, что звуки дыхания можно использовать даже для того, чтобы рассказать историю. Элоиз работала над криминальным радиосериалом, в котором Максин Пик исполняла роль детектива Сью Крейвен. В этой драме Крейвен постоянно носится по полицейскому участку или выезжает на место преступления. В рассказе дыхание Максин сообщает нам, что́ она в данный момент чувствует: спокойна ли она, возбуждена или в панике. Для выступлений на радио актерам необходимо овладеть еще одним трюком: они должны научиться создавать слышимое движение, то есть ходить и говорить так, чтобы звуком создавать впечатление движения. Качество такого звука для фильма будет неприемлемо, но на радио оно оживит голос.
Микрофоны и технологии позволяют подслушивать интимные беседы и даже проникать в сознание героев. В театральном представлении есть монологи, но актер будет усиливать голос, чтобы его было слышно со сцены, и в этом случае потеряются тонкие оттенки речи. В радиопостановке внутренний голос более личный. Элоиз предложила мне послушать постановку «Дзен и искусство ухода за мотоциклом», над которой она работала. В пьесе слушатели следуют за отцом, который берет сына в поездку на мотоцикле, и вы слышите, как мужчина пытается примириться со своим прошлым, а для этого приходится разбираться в глубоких философских вопросах. Бо́льшую часть пьесы в качестве рассказчика выступает внутренний голос отца, и нужно, чтобы он звучал иначе, чем его же голос, когда он вслух разговаривает с мальчиком. Разница этих голосов частично создается за счет того, как актер произносит роль, но Элоиз все же приходится ему помогать, манипулируя записью. Она придает внутреннему голосу больше басов, чтобы он контрастировал с более высоким тоном внешней речи [8]. Такой внутренний голос очень похож на тот, который слышит каждый из нас: в нем больше басов, чем в том, что слышат окружающие.
Музыкальные продюсеры манипулируют звуком и для того, чтобы добиться ощущения внутреннего голоса. «Охотник» – первый трек в третьем альбоме Бьорк Homogenic (1997). Музыкальное сопровождение представляет собой звук синтезатора на фоне электронного ударника. Большую часть времени голос Бьорк вторит этой технологической эстетике, к нему добавляется эхо и другие аудиоэффекты. Исключением является повторяемая строка «Я – охотник», где ее голос звучит естественно, как чистая трансляция того, что схвачено микрофоном в студии. Подобно мазкам кисти великого художника (хотя большинство людей, возможно, не отдают себе отчета в таких деталях), тонкие эффекты звукозаписи в этом произведении очень важны. Простая акустика в строчке «Я – охотник» приближает певицу к слушателю. И внезапно начинает казаться, что Бьорк как будто признается в чем-то личном напрямую слушателю [9].
Таким образом, продюсеры играют на стереотипах восприятия даже в записях с множеством электронных эффектов. Когда Элоиз создала голос для Слоноверблюда, монстра из первого фильма-сказки в формате виртуальной реальности «Вращающийся лес», она просила актера озвучивать разные эмоции – восходящий тон для обозначения счастья, нисходящий тон – для печали и так далее. (Эти интонационные рисунки практически универсальны и имеют музыкальные эквиваленты – например, нисходящие мелодии передают печаль.) Настоящие слова не использовались, достаточно было простых «ммм» или «ха!». Чтобы показать движение Слоноверблюда, актер изобразил ритмичные тяжелые вздохи, за которыми следовали медленные тяжелые шаги. После этого Элоиз применила широкую палитру цифровых хитростей, чтобы создать звучание монстра, – например, понизила тон, чтобы получился глубокий голос, подходящий крупному животному. Если вы решите прослушать финальную запись, то не поверите, что все началось с голоса актера. Тем не менее использование человеческого голоса в качестве первого ингредиента для создания звука наделило монстра индивидуальностью. Это еще один пример того, как технология влияет на ремесло актера.
Слоноверблюд – добрый монстр, но для опасных животных понадобится более сильное искажение звуковой волны. Стандартный прием – обрезка звуковой волны. Представьте гладкую форму волны (синусоиду), состоящую из округлых возвышений и мягко выгнутых впадин. При самой радикальной форме обрезки верхушки возвышений срезаются и дно впадин уплощается (см. диаграмму). Волна на верхнем рисунке имеет только одну частоту, скажем 100 Гц. Обрезанная форма приобретает дополнительные обертоны или гармоники, кратные начальной частоте: 200, 300, 400 Гц и т. д. Поскольку голос начинается с гармоник, искажение делает их громче и изменяет тембр звука.
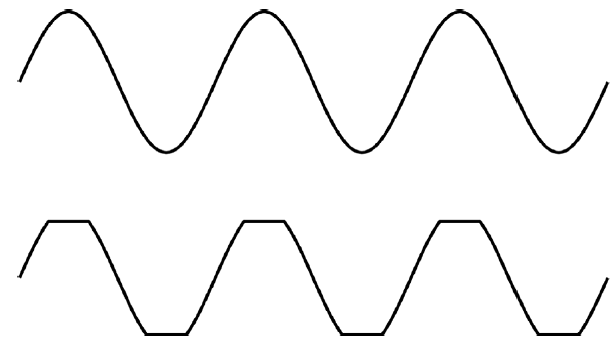
Простая звуковая волна и ее вариант, искаженный обрезкой вручную
Сильно искаженный вокал стал повальным увлечением в 1990-х годах. Хорошим примером является хит группы U 2 «The Fly» 1991 года. В нем голос Боно приобретает скрипучий тон, подражая Роду Стюарту и Бонни Тайлер, у которых это получается естественным образом. Группы, подобные Eels, используют это и сейчас, но уже не так явно: гармоники делают звучание голоса более мощным, но не создают скрипучести. Голос звучит более мощно потому, что дополнительные гармоники добавляют звук в тех частотах, к которым ухо особенно чувствительно. Резонанс ушного канала означает, что наши уши особенно чувствительны к частотам в районе 3000 Гц. Добавьте еще немного искажения, как сделали U 2 в «The Fly», и получите скрипучесть, или, на языке ученых, – «шершавость» (roughness).
Во внутреннем ухе звук расщепляется базилярной мембраной в соответствии с частотой. Эта мембрана продолжается по всей длине улитки; если ее развернуть, она будет напоминать пианино, у которого частоты выстроены по длине. Высокие частоты возбуждают базилярную мембрану ближе к овальному окошечку внутреннего уха, а низкие вызывают движение на противоположном конце. Когда человек слышит ноту, базилярная мембрана одновременно вибрирует в нескольких точках, давая сигнал мозгу о том, какие частоты составляют звук. Для низкочастотных гармоник вибрирующие части базилярной мембраны находятся на большом расстоянии друг от друга. Наоборот, для высоких частот гармоники настолько близко расположены друг к другу, что созданные ими вибрации базилярной мембраны взаимодействуют и движение становится трудно распознать. Если это происходит, мозг слышит скрипучий, хриплый звук.
Такая резкость и скрипучесть возникают естественным образом, когда человек визжит. Попробуйте начать со звука [ааа] и постепенно увеличивайте давление воздуха, идущего из легких. С увеличением давления под голосовой щелью, вызывающего вибрацию голосовых связок, они начнут двигаться все больше и больше, что создаст более громкий звук. Но если резко увеличить давление воздуха, то вы достигнете предела физических возможностей гортани, голосовые связки больше не смогут раскрываться и закрываться в обычном ритме. В результате голос исказится, и визгливое высокое [ааа] приобретет пронзительную хрипоту.
В 2009 году я провел онлайн-эксперимент для Манчестерского фестиваля науки. Я просил людей оценить 19 разных воплей и сказать, какой из них самый жуткий. Отобрать звуки для эксперимента было очень непросто, потому что казалось, будто вопящий человек сильно страдает, особенно в самых ярких примерах. Именно хрипота делала звуки настолько ужасными (а это всегда происходит, когда человек вопит, никак себя не сдерживая и с максимальной силой). Анализ 20 000 результатов показал, что самыми жуткими чаще всего были женские вопли, а от самых длинных и высоких воплей просто кровь стыла в жилах. Естественно, женские вопли более высокие, чем мужские, поэтому они ближе к тем частотам, к которым уши человека более чувствительны, так что звуки воспринимаются громче [10].
В основе самых грубых звуков лежит быстрая флуктуация звуковой волны при частоте примерно 170 Гц. Интересно, что эта ниша не используется в обычной речи. Она находится между уровнем, при котором активные органы речи движутся для формирования звука, и частотами в пределах гудения, производимого голосовыми связками. Крик отчаяния часто требует незамедлительных действий, чтобы предотвратить опасность, так что в его резкости имеется преимущество: именно она выделяет такие крики из обычной речи. Люк Арнал из Женевского университета и его команда занимались исследованием этого феномена [11]. Они показали, что добавление голосу резкости не только усиливает воспринимаемый страх, но и заставляет участников реагировать быстрее. Наблюдая испытуемых с помощью фМРТ-сканера, ученые могли проследить за реакциями мозга. Неприятные звуки в значительной степени влияли на миндалевидное тело и первичную слуховую кору. Миндалевидное тело – это скопление нейронов, имеющее миндалевидную форму. Оно расположено в глубине мозга, как известно, играет важную роль в обнаружении и устранении опасностей [12]. Резкий звук, который может быть произведен сильно искаженными голосами, по-видимому, воздействует на когнитивные функции, которые развились у человека для быстрого распознавания сигналов отчаяния и реагирования на них. Неудивительно, что такое искажение голоса очень популярно у певцов тяжелого металла – и очень полезно для создания голосов злобных монстров.
«Вращающийся лес», фильм в формате виртуальной реальности, в котором фигурирует Слоноверблюд Элоиз, появился на свет необычно: саундтрек был написан еще до того, как были созданы персонажи, обычно бывает наоборот, и звуковое сопровождение опирается на видеоряд. Этот саундтрек на самом деле был написан для крупного исследовательского проекта (я принимаю в нем участие), в рамках которого мы разрабатываем новые способы прослушивания записей в домашних условиях [13]. Чтобы изучить ограничения уже существующих технологий, мы заказали серию драматических эпизодов. Техническое задание для сценариста было очень необычным: оно содержало таблицу технических требований, которые практически не имели отношения к созданию хорошей истории! Повествование должно было вестись от первого лица, источники звука должны были перемещаться, приближаться с разных направлений и восприниматься на разных расстояниях. Мы поставили задачу таким образом специально, поскольку знали, что современные аудиосистемы изо всех сил стараются создать подобное разнообразие звуков. Из этого странного технического задания драматург Шелли Сайлас ухитрилась создать волшебную сказку, в которой мальчик общается со Слоноверблюдом, топающим через лес. И только позднее BBC заказала видео, превратившее «Вращающийся лес» в фильм.
Будем надеяться, что результаты этого исследовательского проекта позволят улучшить разборчивость звукового ряда фильмов, демонстрируемых на телеэкранах. За последние годы от многих зрителей поступали жалобы, что диалоги в телешоу трудно разобрать. (Такая проблема не стоит в радиопостановках, ведь если слова будет трудно понять, передача утратит смысл.) Костюмная драма «Трактир “Ямайка”» была прозвана «Невнятная “Ямайка”» после того, как на нее посыпались тысячи жалоб. Более свежим примером является телешоу «Британские СС» в жанре альтернативной реальности. Действие происходит в Британии после победы нацистов во Второй мировой войне. Главную роль исполняет актер Сэм Райли, но временами его голос похож на едва различимый хрип. Возможно, некоторые сцены нужно было бы предварять словами: «Слушайте очень внимательно, я пробурчу это лишь один раз» [14]. Звукооператоры справедливо негодовали, когда их обвинили в том, что они некачественно выполнили свою работу. На самом деле голос был записан правильно, с использованием высокочувствительных микрофонов. Проблема в том, что такие микрофоны позволяют актерам играть естественно, без усиления голоса: таким образом, шепот – это стилистика, выбранная актерами и режиссерами, которые ценят натурализм выше, чем хорошую дикцию.
В этом проекте мы исследовали и другие проблемы разборчивости речи в звукозаписи, например случаи, когда музыка оказывается слишком громкой и затрудняет восприятие диалога. Решение этой проблемы может лежать в области объектно ориентированного аудио. Когда вы смотрите телевизор, то обычно получаете два аудиопотока из транслятора, которые затем передаются на левый и правый динамики телевизора. Если музыка слишком громкая, ее трудно приглушить, поскольку речь и музыка уже смикшированы. В случае объектно ориентированного аудио музыка, звуковые эффекты и диалоги посылаются по отдельным каналам. Дома нужное микширование осуществляет телевизор, что позволяет при желании приглушить музыку. В настоящее время мои коллеги разрабатывают компьютерные алгоритмы, которые будут отслеживать, насколько членораздельными являются слова в конкретном эпизоде. Это позволит телевизору автоматически настраивать громкость фоновых звуков, чтобы слова стали разборчивыми.
Технологии привели к неразборчивости слов и в сценической речи: на эстетику драматургии, актерского мастерства и постановки тоже влияют теле- и киноиндустрия. Одна из проблем – желание отказаться от усиления голоса, когда актер громко проговаривает роль с хорошо поставленным произношением, и заменить его более естественной речью. Но если театральный режиссер принимает решение использовать аутентичный акцент, который сложнее понимать, как же люди на галерке будут смотреть постановку? Решение кажется очевидным: наденьте на актера микрофон, поставьте усилители, направленные в зал, и добавьте громкости. Так и делают на Бродвее. Там зрители ждут, что речь актеров будет усилена в любой постановке. Но в Соединенном Королевстве использование электроники является предметом споров.
Недовольство по поводу использования электроники вылилось в шумные протесты, когда в 1999 году открылось, что Королевский национальный театр использовал электронное усиление в постановке Шекспира. Грэм Шеффилд, в то время художественный директор Барбикана, заметил: «Одно дело – использовать микрофоны для создания звуковых спецэффектов, но совсем другое, если микрофоны становятся привычным вспомогательным средством для ленивых актеров». Шеффилд пояснил: «Это уничтожает близость и естественность в отношениях между актерами и залом. Как бы хорошо это ни было исполнено, звук всегда будет казаться искусственным» [15]. Интересно, что жалобы посыпались только через несколько месяцев после премьеры «Троила и Крессиды». К этому времени критики и тысячи зрителей уже посмотрели пьесу с электронным усилением голосов, но никто ничего не заметил. Постановка даже получила хорошие отзывы, причем Майкл Биллингтон из Guardian назвал ее «великолепным новым спектаклем» [16]. В заголовки СМИ электроника попала лишь тогда, когда кто-то из сотрудников Королевского театра передал эту информацию прессе.
Впервые я услышал об этом споре, когда присутствовал на выступлении театрального звукорежиссера Гарета Фрая на конференции по звуку в 2010 году. Находящиеся «за кулисами» волшебники, такие как Гарет, обычно неизвестны широкой публике, но в числе его заслуг звуковое сопровождение церемонии открытия Олимпийских игр 2012 года в Лондоне (по сценарию Дэнни Бойла) [17]. Совсем недавно я встретился с Гаретом в Манчестере, в центре искусств HOME, во время перерыва в работе над шоу. Когда я попросил объяснить, в чем заключается его работа, он ответил: «Я несу ответственность за все, что слышат зрители».
Гарет объяснил, что в Королевском национальном театре инцидент со звуком произошел в результате случайного побочного эффекта, связанного с модными тенденциями в сценических постановках. Когда театр был только построен, в большинстве постановок использовались громоздкие тяжелые декорации. В пьесе Ноэла Коварда «Относительные ценности» декорации библиотеки в интерьере великолепного особняка выглядели бы очень натуралистично и были бы проработаны до мельчайшей детали. Передвинуть такие декорации нелегко, а это означает, что все повороты сюжета должны происходить в одной комнате. Автору нужно придумать, почему герои приходят только в эту комнату, а зрители должны поверить, что маловероятные встречи действительно могут случиться только в одном этом пространстве. Такое оформление сцены, возможно, доставляет массу проблем драматургам, но у него есть значительное акустическое преимущество: звук отражается от тяжелых декораций в направлении слушателей и, таким образом, усиливает голос актера.
Однако к концу XX века мода на декорации изменилась. Следуя эстетике телевизионных программ и кинофильмов, авторы пьес захотели менять место действия. Это означало, что декорации должны были стать более простыми, легкими и абстрактными. Перемещение на новое место действия часто осуществляется только за счет смены освещения и звукового окружения. Но эффективное отражение звука от постоянных тяжелых декораций исчезло, а без них часть аудитории плохо слышала происходящее на сцене. Электронные средства усиления звука необходимы именно для сглаживания недостатков акустики, а не потому, что современные актеры не способны усиливать голос, как считают некоторые журналисты. В наши дни эти средства приобрели еще большее значение, потому что в пьесе присутствует музыка и различные звуковые эффекты, а это означает, что голосам актеров приходится соперничать со множеством «шумов». Но усиление должно производиться очень тонко, чтобы зрители этого не осознавали. Гарет описывает этот способ как «располовинивание расстояния: усилить звук настолько, чтобы казалось, что актер в два раза ближе, чем на самом деле». Но использование технологий может пойти еще дальше и помочь сюжету. Гарет рассказал, что электроника может использоваться как слуховая маска, «отделяя голос от актера». Простая обработка звука, например смена высоты тона, может изменить пол персонажа, а реверберация – местонахождение актера, например перенести его из ванной комнаты в церковь [18].
В музыке реверберация широко используется для улучшения голоса. Это своего рода слуховой кетчуп, потому что добавление незначительной реверберации к звукозаписи обычно ее улучшает [19]. Когда музыкальные продюсеры используют реверберацию, они играют на ожиданиях и стереотипах слушателей. Запись диска Confess Патти Пейдж была революционной, потому что это был первый хит, в котором при записи поп-звезды использовалось наложение звука: Патти сама себе подпевает. Это песня-диалог, в которой ко второму голосу добавлена реверберация. Это было сделано с помощью динамика, воспроизводящего пение Пейдж в мужском туалете с отличной акустикой. Звук был записан через микрофон. Добавление реверберации помогло различить строки «разных» участников диалога, которые в ином случае слились бы, потому что и те и другие были спеты Пейдж. У реверберации имеется и религиозный подтекст, потому что такой эффект естественным образом возникает в акустическом пространстве церквей и соборов – и очень подходит для песни Confess [20].
Я разговаривал с Гаретом о пьесе «Встреча» (Encounter), имевшей успех во всем мире и поставленной на Бродвее в 2016 году. Она необычна тем, что звук доминирует и в постановке, и в самом сюжете. Пьеса рассказывает историю Лорена Макинтайра, фотографа, в 1960-х годах потерявшегося в лесах Амазонки и нашедшего приют у индейцев племени майоруна. Можно было поставить пьесу в традиционном стиле, но, как указал Гарет, представить тропический лес с помощью декораций или проецированием изображения было непросто. Гарет объяснил, что пьеса была бы «обречена на провал, потому что неизбежно стала бы уменьшенной копией реальности». Лучше было бы с помощью звука подключить фантазию зрителей, чтобы создать в их воображении картинки. Однако это не просто воспроизведение звуков тропического леса через динамики: каждый зритель получал наушники, которые помогали лучше представить сюжет.
В пьесе «Встреча» пересекаются несколько временных пластов и нарративов, в том числе есть сказки, которые отец рассказывает дочке на ночь. В обычной театральной постановке было бы трудно до конца прочувствовать такой интимный момент из-за физической удаленности от сцены. Но у каждого зрителя были наушники, соединенные с особым микрофоном на сцене, поэтому актер Саймон Макберни мог нашептывать зрителям прямо в уши. Перед началом представления Макберни дует в микрофон, и зрители взвизгивают, потому что у них складывается ощущение, что их ушам становится тепло от дыхания актера. Таким образом воссоздается интимная атмосфера чтения сказок на ночь. Звук переносит зрителей на сцену и в тропический лес.

Голова манекена
Особенный микрофон – это голова манекена, в уши которой вставлены микрофоны. Гарет использовал этот микрофон и для записи звуков в тропических лесах Амазонки. Это была очень непростая экспедиция. Всему виной были «чертовы москиты: я не мог их прихлопнуть, потому что из-за этого запись была бы испорчена» [21]. Темно-серая голова без туловища записывала звук бинаурально (стереофонически), этот метод является основой акустических исследований.
Закройте глаза и прислушайтесь к окружающим звукам. Возможно, с одной стороны вы услышите проезжающую по улице машину, с другой стороны раздастся пение птицы, а чуть дальше – звуки радио. Ориентиры, которые подсказывают вам источник звука, накладываются на звуковые волны, проходящие по слуховым каналам [22]. Причина, по которой микрофоны размещены в ушах манекена, как раз и состоит в необходимости поймать все звуки вместе с этими пространственными ориентирами. Если затем воспроизвести запись через наушники прямо в уши, зрители перенесутся в звуковую атмосферу того места, где была сделана запись. Хорошая бинауральная запись на самом деле создает ощущение, что звуки вас окружают. И этим она отличается от обычной записи: прослушайте любую композицию в наушниках, и вам покажется, что музыканты играют у вас в голове. Это происходит из-за отсутствия акустических ориентиров, которые разместили бы исполнителей снаружи. Мозг не может решить, где источник звука, и приходит к заключению, что он находится внутри. Гарет обыграл этот феномен, когда занимался постановкой «Встречи». Внутренний монолог заблудившегося в тропическом лесу фотожурналиста передается с помощью стерео, поэтому слушателям кажется, что он исходит изнутри, как бы из их головы, но голоса индейцев-майорана звучат бинаурально, поэтому создается ощущение, что они находятся снаружи.
До недавнего времени использование бинауральной записи ограничивалось в основном лабораториями. Но эта технология переживает второе рождение, поскольку слушание в наушниках стало очень популярным. BBC передавала один из эпизодов «Доктора Кто» с бинауральным саундтреком, 360 видео в интернете используют эту технологию, и именно так звук воспроизводится гарнитурой виртуальной реальности. Если сюжет приспосабливается к виртуальной и дополненной реальности, насколько технология может изменить голос актера?
До появления звукозаписывающих технологий актерам и певцам, принимавшим участие в крупных постановках, приходилось решать задачи, требующие значительных физических усилий: как «докричаться» до зрителей на задних рядах, чтобы они услышали не просто неразборчивый шепот? Отчасти это объясняет, почему некоторые стили пения, например оперное, сегодня многим кажутся странными [23]. Потрясающий контраст старого и нового можно услышать в «Барселоне», дуэте рок-солиста Queen Фредди Меркьюри и оперной певицы-сопрано Монсеррат Кабалье. Самое интересное в песне начинается в тот момент, когда после напыщенного и затянутого вступления начинает звучать смесь рока и классической музыки с помпезными аккордами, громыханием литавр и колоколов. У Меркьюри очень выразительный голос: многие согласятся, что он был одним из величайших певцов XX века. Местами у него приятный мелодичный голос, а когда словам нужна энергия, он почти кричит. Именно микрофоны и усиление звука позволяли Меркьюри выражать такое многообразие эмоций, даже когда он выступал перед огромными аудиториями. Голос Кабалье, напротив, весь пропитан вибрато, он всегда очень мелодичен, звучит почти как музыкальный инструмент. Но если в оперных традициях качество тембра голоса Кабалье имеет первостепенное значение, артикуляция слов не так важна [24]. Временами трудно понять, на каком языке поет Кабалье: испанском, каталанском или английском [25].
Используемая Кабалье вокальная гимнастика, конечно, впечатляет, однако за нее приходится платить не только неразборчивостью слов: у певицы ограниченная голосовая палитра для передачи эмоций. Как любой другой инструменталист, она может играть ритмом, гармонией и динамикой, но у нее остается мало возможностей для того, чтобы пропеть отдельные фрагменты вполголоса или внести еще какие-то стилистические изменения. Кабалье не может сделать того, что может Меркьюри, – например, резко сместить акценты и изменить интонацию и проявить свою индивидуальность. Поэтому для нетренированного уха все оперные сопрано звучат одинаково. Лучшие поп-певцы, наоборот, чаще всего выделяются именно голосами. Например, Боб Дилан. Во время его турне в середине 1960-х годов использование электронного аккомпанемента вызвало бурю недовольства среди фанатов. Во время печально известного концерта в Manchester Free Trade Hall зрители вяло хлопали в ладоши и кто-то выкрикнул: «Иуда!» И все же обвинять Дилана в том, что он продал настоящий фолк, было бы странно: без микрофона и усиления он со своим характерным скрипучим голосом никогда не смог бы петь перед большими аудиториями [26].
Не так давно я слушал в первом ряду оперу в концертном исполнении и почувствовал всю мощь оперного голоса. Пианисту приходилось бить по клавишам, чтобы аккомпанемент был слышен на фоне громких голосов. Сила звучания голоса крайне важна для постановок больших опер, потому что певцам обычно приходится состязаться с оркестром, который иногда бывает очень большим – например, в опере Вагнера «Кольцо нибелунга» участвуют 90 музыкантов. То, что оркестр играет в оркестровой яме, помогает певцам быть услышанными на фоне звучания оркестра. В таком театре, как, например, Фестивальный театр в Байройте, где ставятся оперы Вагнера, половина оркестра располагается под козырьком сцены. Если прямой путь от музыканта к слушателю блокируется, звук можно услышать только в отраженном виде или когда он огибает барьер оркестровой ямы благодаря дифракции. Дифракция низких частот происходит с большей легкостью, чем дифракция высоких частот, и это приглушает звучание оркестра. Поэтому в диапазоне высоких частот певцу приходится меньше соперничать с оркестром. Но даже с таким помощником, как оркестровая яма, нужна особая техника пения.
Оперные певцы стремятся добиться такого диапазона частот, к которому особенно чувствительно ухо. Слуховой канал между ушной раковиной и барабанной перепонкой имеет такую частоту резонанса, при которой воздух в канале вибрирует эффективно. Этот резонанс означает, что все ноты, которые певец производит в диапазоне около 3000 Гц, будут звучать громче благодаря анатомии уха. Но для достижения такого диапазона певцы должны использовать различные техники, потому что мелодии, которые они исполняют, имеют разные частоты.
Например, мужской баритон берет низкую ноту на частоте 100 Гц, что значительно ниже наиболее эффективного диапазона. У такой ноты будут также гармоники, которые являются производными от частоты ноты – 200, 300, 400 Гц и т. д. Чтобы усилить голос, баритон настраивает резонансы своего голосового тракта на одну из более высоких гармоник в том диапазоне, к которому наиболее чувствительно ухо слушателя. Это создает форманту певца. Баритон добивается этого, опуская гортань и сужая голосовой тракт как раз над голосовой щелью. Похожим образом усиливают голос и актеры [27].
Певицам-сопрано приходится прибегать к другому способу, потому что они поют на более высоких частотах (300–1000 Гц). Они настраивают свой голосовой тракт так, чтобы он придерживался основной высоты тона голосовых связок. Делается это за счет широкого раскрытия рта – так голосовой тракт постепенно расширяется, подобно рупору. Но когда голос поднимается к самым высоким нотам, возникают проблемы, потому что в этом случае невозможно точно воспроизвести некоторые гласные звуки [28]. Это объясняет, почему в пении Кабалье иногда трудно разобрать слова. В поп-музыке используется усилитель, и, когда певец выступает перед большой аудиторией, можно понять слова. Поэтому лирическое богатство песен, которым отличаются многие знаменитые баллады, возможно лишь благодаря микрофону.
Современное пение прошло через множество итераций, вызванных влиянием как культуры, так и технологического прогресса, давшего разнообразие голосов, которые мы слышим сегодня. Возможно, первым и самым важным шагом стало возвращение к более естественному пению. Появление микрофона привело к тому, что певцы начали исполнять свои песни в разговорной манере. Этот новый стиль пения, который называют crooning (тихое, проникновенное пение, «мурлыканье»), ассоциируется с американскими певцами, такими как Бинг Кросби, но считается, что первым в этом жанре запел Эл Боулли, который родился и вырос в Африке [29]. Боулли приехал в Британию в 1920-е годы и большую часть творческой карьеры провел в этой стране вплоть до трагической гибели во время бомбежки в годы Второй мировой войны. Отрывок старого фильма, в котором он исполняет Melancholy Baby в британском отделении киностудии Pathe, показывает, как он поет перед большим микрофоном, закрепленным на штативе. Со стороны это выглядит так, как будто он обращается к своей печальной подружке, сидящей перед ним на стуле. Боулли наклоняется вперед и практически шепчет самые задушевные строки в микрофон, а потом отклоняется назад и поет в обычной манере строки, приходящиеся на сильные доли такта: Every cloud must have a silver lining. Его легкий тенор очень точен, так что даже малейшие вариации подчеркивают значение текста.
Проникновенное звучание кажется нам сегодня очень старомодным, но когда эта манера исполнения только появилась, такое публичное проявление близости и личных чувств было принято неоднозначно. «Стоит мне включить приемник, и я обязательно услышу, как они завывают и блеют, только портят воздух и выкрикивают бессодержательные слова, выпевая их под ужасные мелодии, – жаловался в 1932 году архиепископ Бостона О’Коннелл. – Это – дегенеративная форма пения, истинный американец не будет заниматься таким низкопробным делом». В Британии Сесил Грейвз, контролировавший выпуск программ на BBC, издал инструкции, в которых предписывалось не пускать «конкретно эту мерзкую форму пения» на радио [30]. Критики считали такое пение женственным и эмоционально неполноценным, но они проиграли.
Одним из величайших певцов, выступавших в этой манере, был Бинг Кросби. Он начал карьеру как актер варьете, но быстро приспособил свои сценические навыки к новым возможностям, которые давал микрофон. Тем не менее важнейший вклад в музыку Кросби сделал не своим пением: он финансировал развитие магнитной звукозаписи. Появление магнитной ленты улучшило качество записываемого звука и, что еще важнее, позволило с легкостью редактировать записи с помощью ножниц и клейкой ленты. Ошибки во время выступления больше не впечатывались навеки в воск или резину, их можно было удалить.
Кросби терпеть не мог, когда ему приходилось повторять живые выступления на радио, чтобы их можно было передавать в разные часовые пояса Соединенных Штатов Америки, поскольку это сокращало время, которое он мог провести на поле для гольфа. В 1946 году недавно созданная ABC Radio Network постаралась облегчить мегазвезде жизнь и записала его шоу Philco Radio Time на диск. Но качество звука было ужасным, и слушатели быстро поняли, что Кросби не поет вживую, в результате чего пострадал рейтинг компании. Решение нашлось в поверженной нацистской Германии. Запись на магнитную ленту уже была изобретена и использовалась в германских радиопередачах во время Второй мировой войны. Первый случай, продемонстрировавший возможность передачи звука, произошел посреди ночи – союзники услышали оркестровую музыку, но в это время музыканты уже должны были спать. Союзники знали, что немцы использовали что-то получше цилиндров и дисков, потому что в записях отсутствовали характерные поверхностные скрежет и треск. После войны были обнаружены катушечные записывающие устройства, называвшиеся магнитофонами, их перевезли в Америку, где новую технологию проанализировали, скопировали и усовершенствовали. Кросби понял, что магнитная лента может облегчить ему жизнь, поэтому решил вложиться в это предприятие [31]. Как только для шоу Кросби начали использовать магнитную ленту, он стал практически шептать в микрофон, поскольку тихие звуки больше не поглощались поверхностными шумами, как при записи на диск. Слушатели думали, что он опять выступает вживую, и рейтинги радиошоу Кросби выросли до прежнего уровня [32].
Другие увидели потенциал электроники в том, что она способствовала выражению сильных эмоций в песнях о происходящих в мире катаклизмах. Билли Холидей была одной из величайших джазовых певиц начала XX века. У нее было трудное детство, она драила полы и была девочкой на побегушках в борделе, прежде чем начала зарабатывать пением. В некрологе New York Times говорилось следующее: «Мисс Холидей стала певицей скорее от отчаяния, чем по желанию» [33]. Послушайте ее исполнение Strange Fruit, это душераздирающее описание чернокожих мужчин и женщин, жертв суда Линча, повешенных на тополях, и вы почувствуете, что она передает и трагизм собственной жизни. Она постоянно меняет тон и поет очень печально, но так спеть было бы невозможно, если бы она выступала без микрофона и пела громко.
Сегодняшние певцы и авторы песен тоже заставляют слушателей почувствовать, будто они проникают во внутренний мир исполнителя. Как написала музыкальный обозреватель Китти Эмпайр, «поклонников музыки захватывают внутренние переживания и муки автора и исполнителя. Мы думаем, что песни напрямую связаны с самыми уязвимыми местами артиста. Нас восхищает надтреснутый голос, блеснувшая слеза» [34]. Профессор Никола Диббен из Шеффилдского университета исследует эмоции в музыке, она не только написала о личных переживаниях в записях Эми Уайнхаус и Адели, но и лично работала с Бьорк. Она рассказала мне, что развитие технологии звукозаписи и особенно использование микрофона позволило создать «переход к очень индивидуалистическим и почти нездоровым отношениям [слушателей] с конкретными звездами». Крупные планы в фильмах породили культ кинозвезд, «крупные планы» голоса, которые улавливает микрофон, приводят к появлению поп-звезд.
Никола находит материал для исследования в самых неожиданных местах. Однажды она была в парикмахерской и была поражена реакцией своего стилиста на песню Адели. Обычно на музыку, которая звучит в общественном месте, обращают мало внимания, но, когда заиграла песня Адели, мастер сказала что-то вроде «боже, как мне нравится эта вещь, она рассказывает о моих переживаниях, она как будто рассказывает о моей жизни».
Чтобы узнать, как музыкальные продюсеры усиливают чувство интимности в поп-музыке, Никола исследовала хит Адели Someone Like You [35]. Эта песня в 2011 году стала самым продаваемым синглом в Великобритании и получила премию «Грэмми» за лучшее сольное исполнение поп-музыки. Слова песни очень эмоциональные, они передают автобиографическую историю о женщине, которая смирилась с расставанием. Адель поет под простой аккомпанемент фортепиано, который постепенно становится все более интенсивным. Но секрет проникновенного звучания кроется в том, чтобы заставить слушателя почувствовать, будто Адель физически находится рядом. Естественно, когда кто-то находится близко, эмоциональные реакции человека усиливаются. Чтобы этого достигнуть, музыкальный продюсер располагает микрофон очень близко к певцу, а затем применяет эффект звуковой компрессии. Это усиливает самые тихие места в песни таким образом, что можно услышать даже незаметные звуки, например дыхание певца [36]. Здесь требуются художественные ухищрения, потому что подвергшееся компрессии пение – это не совсем то, что мы услышали бы, если бы Адель пела без микрофона. Если в начале эпохи звукозаписи делались попытки точно отобразить голос певца, то в последние 50 лет продюсеры, наоборот, стараются его улучшить. И даже то, что воспринимается как берущее за душу пение, как в Someone Like You, на самом деле представляет собой гиперреальную постановку. Однако, как и в случае с другими аспектами современного звукового дизайна, это работает, только если слушатель не осознает акустического мошенничества.
Голос Адели в балладе, подобной Someone Like You, нуждается в компрессии, чтобы она могла полностью использовать свои вокальные способности. Если противопоставить начало и конец этой записи, становится очевидным резкий контраст в пении между задумчивым началом и тем, как Адель резко усиливает звучание в конце. И все же финальная часть записи звучит ненамного громче начала из-за использования компрессии.
Получившиеся в результате близость и интимность могут внезапно бросить в дрожь. Никола Диббен объясняет, что если произвести беспристрастный анализ невероятного вокала Джарвиса Кокера, то окажется, что он «как ни странно, отвратителен». Альбомы в стиле брит-поп, которые Кокер записал с группой Pulp в 1990-е годы, рассказывают о запретной любви, вуайеризме и сексе. Когда Кокер поет о любовной связи в песне Pencil Skirt, его пение полно утрированных звуков, производимых губами, языком и дыханием. Такой акустический «крупный план» помещает слушателя вплотную к певцу, когда он говорит: «Давай ложись у стены и смотри, детка, как исчезает моя совесть». Так голос превращает слушателя в извращенного участника процесса.
Джарвис Кокер и Адель очень умело играют на чувстве близости, которое им дает микрофон, но есть и те, кто, возможно, идет еще дальше. Таких звезд, как Мэрайя Кэри и Уитни Хьюстон, а также многих конкурсантов программ, подобных Pop Idol, обвиняли в том, что они «перестарались с душевностью» – использовали слишком много словесной гимнастики и чрезмерных эмоций. В некоторых случаях результат оказывался комическим. Например, интерпретацию национального гимна США в исполнении Кристины Агилеры на Супербоул в 2011 году стоит посмотреть онлайн. Как написал на сайте Huffington Post Джон Эскоу, «певцы, подобные Агилере, которые, несомненно, обладают замечательным вокальным инструментом, похоже, просто не знают, когда остановиться, и превращают каждую песню в олимпийское состязание, потому что они высасывают из нее душу. Как будто для того, чтобы доказать свою искренность, им нужно в каждом отдельном слове проявить все возможные его качества». Желание победить на телешоу талантов и стремление к тому, чтобы песня удерживала внимание слушателей в этом полном отвлекающих моментов мире, привели к чересчур утрированному исполнению, от которого, по моему мнению, просто устаешь. Но может быть, сейчас я напоминаю тех, кто жаловался на первых популярных певцов, и это знак, что я отстал от моды [37].
Когда мы говорим о том, как технологии изменили голос, важно не упустить из виду один аспект, меньше связанный с технологическими нововведениями, – влияние подражания. Появление огромных музыкальных библиотек, таких как Spotify, вынуждает начинающих певцов тоже изменять голос. Фанаты слушают кумиров снова и снова, чтобы подстроить собственные голоса под голос своего музыкального героя или героини.
Елена Дафферн из Йоркского университета, профессиональная певица и исследователь, проводит в своей лаборатории эксперименты с голосом. Когда мы беседовали о подражании, Елена отметила, что сегодня люди стараются скопировать записи, в которых на голоса уже наложены аудиоэффекты. «Как это повлияло на пение? – задает она риторический вопрос. – Когда ты молод и подпеваешь Бейонсе, то не ожидаешь, что сейчас продюсер наложит все эти эффекты, ты стараешься воспроизвести их сам». Но дело не только в эффектах: слушатель пытается воспроизвести пение, которое уже улучшено с помощью редактирования. Маловероятно, что певцы (если, конечно, они не прошли интенсивную подготовку) сразу же попадут в нужные частоты каждой ноты. Когда звукозапись выполнялась на воске, такие «недостатки» оставались в нем навеки, но цифровые технологии позволяют легко их устранить. Скорее всего, певец запишет вокал несколько раз, а потом звукорежиссер вырежет и склеит лучшие куски.
С помощью программного обеспечения сегодня можно исправить фальшивые ноты. Auto-Tune – это акустический аналог цифрового фоторедактора, позволяющего удалять изъяны и несовершенства со снимков. Эта программа используется популярными певцами любого статуса и способностей. Когда журналист прямо спросил об этом Робби Уильямса, тот ответил: «Сейчас все используют Auto-Tune. На вашем компьютере ведь есть программа для проверки орфографии? Вы ее используете? А почему? Разве вы не умеете писать правильно?» [38] Если прибегать к такому сравнению, можно подумать, что Auto-Tune – простой инструмент, который нужно использовать всем. Но как и в случае с улучшением фотографий, которое привело к неправильному восприятию собственного тела, Auto-Tune создает такие ожидания относительно точности тона, каких никогда раньше не было. Как сказал один хорошо осведомленный представитель музыкальной индустрии: «Все поют так, будто используют Auto-Tune, даже если они этого не делают» [39].
Музыкальная мимикрия распространяется далеко за пределы копирования обработанного человеческого голоса. Есть одна популярная вокальная техника, которая возникла исключительно из имитации машины. Битбоксинг появился как пародирование буханья, треска и грохота электронной драм-машины. Подобные выступления завораживают, так как артисты с поразительной точностью воссоздают звучание барабанов и тарелок. Некоторые даже добавляют песенную вокальную линию или другие инструменты. Возможно, битбоксинг имеет свое начало в хип-хопе, но он уже проник и в массовую культуру. Некоторые рассматривают битбоксинг как своего рода голосовой атлетизм, но лучшие мастера этого стиля, такие как SK Shlomo (Саймон Шломо Кан) и Bellatrix придают ему настоящую музыкальность.
Просматривая научную литературу по битбоксингу, я с удивлением обнаружил знакомое имя. Я знаю Дэна Стауэлла как специалиста, разрабатывающего компьютерные программы для идентификации пения птиц, но я и подумать не мог, что его докторская диссертация была посвящена битбоксингу. Когда я навестил Дэна в лондонском Университете королевы Марии, он продемонстрировал мне свое умение. Еще подростком он занимался экспериментальной музыкой и считал битбоксинг одним из способов создания необычных акустических тембров и текстур. Дэн объяснил возросшую за последние 10 лет популярность этого стиля: в интернете можно найти огромное количество видеоклипов, которые подробно объясняют, как добиться подобного эффекта. Когда в 1990-х сам Дэн учился этим приемам, он мог только копировать звукозаписи, и было непросто догадаться, как можно вокально воспроизвести некоторые эффекты.
Битбоксер использует голосовые техники, которые в норме не используются, когда человек, допустим, разговаривает по-английски. Но многие звуки битбоксинга можно обнаружить в речи за пределами западной культуры, например щелчки, которые встречаются в койсанских языках Африки. Сначала Дэн показал мне, как создать звук малого барабана. Для этого нужно скривить рот набок и втянуть воздух через зубы, что создаст звук, похожий на приглушенное чихание. Удивительно, но этот звук производится на вдохе. Я не могу назвать ни одного звука, который делается на вдохе, пожалуй, так происходит, только когда человек задыхается или глотает. Но есть языки, в которых такие звуки встречаются повсеместно, – например, исландцы часто говорят ja («да»), втягивая воздух в легкие.
В битбоксинге звук малого барабана – это взрывной звук. Обычный, произносимый с помощью голоса взрывной звук, например [п], начинается с нагнетания давления из легких при сомкнутых губах. Когда губы размыкаются, происходит быстрое освобождение воздуха, создающее толчок давления, в результате которого и появляется звук. Для копирования звука барабана Дэн делает нечто подобное, но в обратном порядке. Он использует язык, чтобы «запечатать» рот, и ослабляет диафрагму, чтобы уменьшить давление в легких. Когда он резко сдвигает язык вниз в задней части и по бокам рта, воздух быстро втягивается через получившееся маленькое отверстие сбоку и создает звук. Умение производить звуки на вдохе очень полезно, потому что в противном случае битбоксеру пришлось бы останавливаться, чтобы перехватить дыхание. Конечно, это уничтожило бы иллюзию звучания драм-машины [40].
Битбоксеры играют на том, как мозг воспринимает звуки, чтобы создать впечатление одновременной игры множества музыкальных инструментов. Музыканты называют это полифонией. Этот музыкальный трюк известен уже многие столетия, и в качестве примера обычно приводят произведения Баха для скрипки соло. В этих сочинениях скрипач время от времени перескакивает вперед и назад между высокими и низкими нотами. Если он играет хорошо, то слушатель не улавливает эти скачки, а слышит две мелодии, одну на высоких нотах, а другую на низких. Битбоксеры делают нечто похожее: они перескакивают между разными звуками барабана, а мозг слышит разные ритмические линии. Особенно сильное впечатление создается, когда битбоксер одновременно ведет барабаны и вокал. Известный пример – Rahzel, американский битбоксер, чей коронный номер – интерпретация песни If Your Mother Only Knew. В начале своего выступления он сообщает слушателям, что исполнит пять партий одновременно: «Я буду отбивать ритм, да, вести хор, басовую линию, петь и подпевать» [41].
Битбоксеры используют и то, как мозг воспринимает и соединяет поступающие в уши фрагменты звука. Рассмотрим рисунок. Линия 1 в верхней части показывает прерывистую линию, а что показывает линия 2? Она прерывистая или непрерывная? Похоже, что непрерывная, хотя линии 1 и 2 абсолютно одинаковые. Мозг предполагает, что во втором случае он имеет дело с непрерывной линией, которая частично спрятана за заштрихованными прямоугольниками. Он ищет самое простое решение, складывая все компоненты. То же самое происходит со звуком. Представьте, что вы слышите прерывистый звуковой сигнал, например грузовика, когда он начинает двигаться задним ходом. А потом добавьте шипящий звук в промежутках между звуками. Шипение выступает в той же роли, что и заштрихованные прямоугольники, и вы вдруг обнаруживаете, что сигнал больше не воспринимается как прерывистый, вам кажется теперь, что он звучит непрерывно? Мозгу кажется, что это постоянный тон, хотя на самом деле это не так. Это стремление превратить прерывистый звук в нечто более гармоничное является жизненно важным навыком, который дает возможность соединять фрагменты речи в единое целое, даже в том случае, если то, что слышится, прерывается помехами.
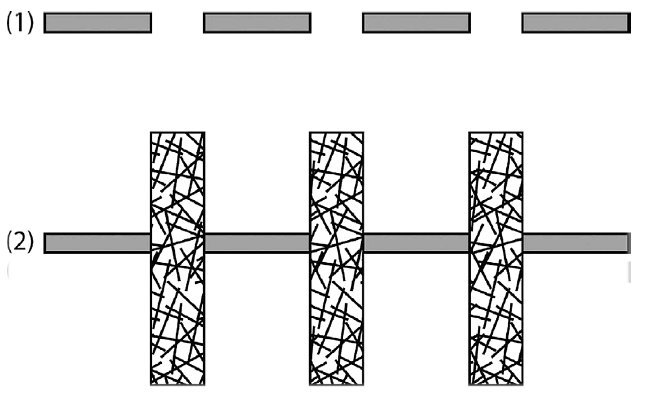
Иллюзия непрерывности

Иллюстрация скачущего ритма
Скачущий ритм – это еще один акустический прием, которым можно объяснить полифонию битбоксинга. Это иллюстрирует простой рисунок (см. с. 209). Вы повторяете ноту, перепрыгивая то на высокую частоту, то возвращаясь на исходную позицию. На верхней схеме прыжок от низкой ноты к высокой – маленький, и вы слышите веселую мелодию, напоминающую ритм скачущей лошади. Но если расстояние между низкой и высокой нотами увеличивается, как на нижней схеме, вы слышите уже две серии звуковых сигналов: высокие и низкие. И они явно отделены друг от друга. В акустике такие два звука, как на верхней схеме, называются соединенными из одного источника, а на нижней схеме, где скачки больше, они сформированы двумя «акустическими потоками»: один – для высокой, а другой – для низкой ноты.
Битбоксер должен убедить мозг слушателя, что воспроизводимые звуки, имитирующие звуки разных частей ударной установки, исходят из разных акустических потоков. Битбоксер должен уметь быстро перескакивать между разными звуками, не искажая эти потоки. Здесь помогает разница в высоте тона, как показано на примере выше, а также разница в тембре. Ожидания слушателя, сформированные синкопированным ритмом барабана, когда басовые ноты приходятся на синкопу, помогают поддерживать эту иллюзию. Если битбоксинг исполняется качественно, мозг слушателя воспринимает басовый барабан, малый барабан и тарелки как разные акустические потоки, поэтому создается иллюзия, что битбоксер играет на множестве инструментов. Но, по словам Дэна, если исполнение некачественное, то акустические потоки разрушаются и создается впечатление, что человек «производит какие-то нелепые звуки».
Простые характеристики звука помогают мозгу формировать акустические потоки. Например, возьмем эффект засурдиненной трубы, который битбоксер создает на фоне ритма. Этот звук обладает набором гармоник, которые представляют собой производные от базовых частот. Такие гармоники передаются от внутреннего уха в мозг разными нейронами, потому что у них разная частота, и поэтому они разделяются на базальной мембране внутреннего уха. Однако мозг воспринимает эти различные гармоники как исходящие из одного источника, а не как набор несвязанных звуков. Делает он это так: отмечает, что все гармоники начинаются и заканчиваются одновременно. Нейробиологи называют это восходящей преаттентивной обработкой. Но на эти потоки влияет и нисходящая когнитивная обработка, когда мозг подключает память и ожидания, чтобы понять, что происходит. Когда Rahzel исполняет If Your Mother Only Knew, он использует именно этот прием. Прежде чем исполнить свой коронный трюк, изображая барабаны и вокал одновременно, он довольно долго поет только вокал. Это знакомит слушателей со словами и мелодией, поэтому, когда Rahzel добавляет звуки барабана, слушатели сами «устраняют» исковерканные слова, если они возникают. Некоторые слова становятся непонятными, потому что они точно совпадают с ударами барабана. В этом случае Rahzel создает композитный звук и полагается на то, что мозг слушателя будет воспринимать его как два отдельных звука из двух разных акустических потоков.
Дэн продемонстрировал мне этот эффект, спев песню, которую исполняет Rahzel, аккомпанируя себе на малом и басовом барабанах. Если он не поет вокал, то удары бас-барабана могут быть созданы втягиванием воздуха в легкие при закрытой голосовой щели. Тогда звук воспринимается как вибрации, исходящие из боковой части горла [42]. Но когда if в начале песни совпало с бас-барабаном, Дэн создал сложный звук, в котором слова и бас-барабан слились. По отдельности это звучало как bif, но если слушатели знают слова и ритм песни, то искаженное слово остается незамеченным и бас-барабан не пропускает удар [43].
Мы увидели, как в битбоксинге человеческий голос сливается с ударной установкой. Но технология открывает и другие возможности, например слияние голоса с музыкальными нотами. В 1940-х годах в Capitol Records придумали детскую историю о говорящем дожде. На первый взгляд она кажется веселой, но на самом деле эта история совсем не веселая. «Спарки и Говорящий Поезд» (Sparky and the Talking Train) рассказывает о мальчике, который очень любил локомотивы. Однажды он сказал маме, что слышал говорящий с помощью свистка поезд. И получил снисходительный ответ: «Ну что ты, дорогой, поезда не разговаривают». А когда Спарки отказался поверить, что ему просто показалось, мама добавила: «Ну все, хватит, мы поговорим с папой, когда он вернется, может быть, он сможет заставить тебя поверить» [44]. Спарки продолжал настаивать, что поезд действительно разговаривал, и это привело к тому, что он стал изгоем в семье и среди друзей. Но, поскольку эта история для детей, в конце все заканчивается хорошо. Спарки становится героем, когда предотвращает несчастный случай, после того как поезд говорит ему о плохо закрепленном колесе.
В записи сиплый, свистящий голос поезда был создан с использованием соновокса. К горлу крепился репродуктор, и актер беззвучно артикулировал слова. Свистковые тоны, проигрываемые репродуктором, заставляли горло вибрировать и проходили в голосовой тракт. Эти вибрации заменяли нормальное гудение голосовых связок [45]. Подобная техника может помочь человеку, который утратил голосовые связки из-за болезни. Искусственная гортань закрепляется на горле и действует подобно репродуктору соновокс. В этом случае устройство производит не свист, а гудение, ведь здесь идея состоит не в создании мультяшного голоса, а в замене речи.
В XX веке были разработаны еще более сложные способы создания вокальных карикатур и «механических» голосов. Самым замечательным был вокодер, устройство, первоначально разработанное, чтобы кодировать речь для телефонных линий. Во многом вокодер имитировал работу соновокса: замещал создаваемую голосовыми связками звуковую волну нотами синтезатора. Группа Kraftwerk первой использовала вокодер в альбоме 1974 года Autobahn. Главная песня начинается с того, что машина заводится, трогается с места и гудит. Затем вокодер создает медленную электронную распевку слова Autobahn [46]. Механический голос постепенно нарастает, начиная с тоники, а затем добавляются еще ноты, чтобы получился аккорд. Такое электронное обесчеловечивание голоса точно соответствовало отстраненной эстетике группы (мы вернемся к вокодеру в следующей главе).
Когда компьютеры появились в каждой звукозаписывающей студии, обработка музыки стала цифровой, что дало еще большую свободу для манипулирования голосом. Возможно, самым известным и эффективным преобразованием голоса был хит Шер Believe, который принес ей премию «Грэмми» в 1999 году. Пение Шер было обработано программой Auto-Tune с максимальным использованием звуковых эффектов, чтобы придать ее голосу модуляции. Auto-Tune постоянно оценивает частоту пения, используя математическую операцию «автокорреляция». Если программа обнаруживает частоту, которая не подходит к одной из нот музыкальной гаммы, аудио обрабатывается так, чтобы гармония улучшилась. Скажем, нота, изображенная на верхней схеме рисунка на с. 215, бемольная, тогда четыре цикла звука сжимаются и в конце добавляется еще один цикл. Это означает, что нота изменяется быстрее: другими словами, частота увеличилась, чтобы скорректировать гармонию [47]. Если корректировка производится осторожно и постепенно, будет трудно обнаружить использование Auto-Tune, часто его просто не слышно. Но если программа настроена так, что производит коррекцию моментально, получается модулированный звук, такой как в Believe Шер. На самом деле мы слышим, как программа прыгает между разными нотами, так как тон корректируется слишком часто. Эта запись – замечательный пример того, как артисты используют технологии и злоупотребляют ими для создания неожиданных творческих эффектов.
Популярная музыка прибегает к созданию коротких, легко запоминающихся мелодий, которые делают песню притягательной. Этот прием известен как «музыкальный хук». Believe Шер – пример того, что это может относиться не только к мелодии или словам: искаженный голос сам по себе становится эффектным хуком. С учетом того, как акустические потоки формируются в сознании, качание частоты помогает отличить голос от музыкального сопровождения и выделить его.
Повышение тона в Auto-Tune
Злоупотребление Auto-Tune приводило и к удивительным мистификациям. Одна из самых известных – это ремейк речи Ника Клегга, в которой он приносит извинения за повышение платы за обучение. Эта запись даже попала в топ-40. Звуки, производимые с вибрацией голосовых связок, например гласные, по своей природе обладают тоном [48]. Если использовать Auto-Tune, можно повысить или понизить частоты разговорной речи так, чтобы она стала похожей на мелодию. Программа не сможет обработать звуки речи, которые обладают нечеткими частотами, например [с], поэтому после наложения Auto-Tune мистификация Клегга переключается с механического голоса на пение и обратно.
Голос с едва различимым механическим оттенком – это обычное явление в современном поп-вокале. Такие записи лучше продаются, хотя некоторым не нравится подобное звучание. Музыкальный критик Telegraph Нил Маккормик так прокомментировал использование Auto-Tune: «Преимущественно в музыке эта штука используется плохо, из рук вон плохо». Он вспоминает свой разговор с Леди Гагой: «Когда я впервые брал у нее интервью, она то и дело начинала петь, а я ей вроде: ух ты, петь-то умеешь по-настоящему; но у нее ведь была эта пластинка, на которой она звучала как робот, играющий в Just Dance». Маккормик спросил Леди Гагу, зачем она использует обработанный в Auto-Tune голос, ведь она фантастическая певица. «И она, по сути, ответила, что этого хочет молодежь».
Но так ли уж сильно электронные ухищрения для манипуляций с современным поп-голосом отличаются от техник пения, которые изобретали оперные певцы для создания звука, достаточного, чтобы заполнить весь зрительный зал? Как мы увидели на примере «Барселоны», оперные певцы жертвуют произношением, концентрируя внимание на мелодической линии. Таким образом, обучение студентов пению в классическом стиле воспитывает певцов, у которых почти нет индивидуальности. Так и голос современного певца, прошедший цифровую обработку, может звучать не как голос человека, а как музыкальный инструмент. Оперные певцы используют очень широкое вибрато, модуляцию частоты, которая помогает им выделяться на фоне оркестра. Подобно этому, механическое качание частоты, которые звукооператор добавляет к голосу поп-певца, помогает выделить его на фоне музыкального сопровождения. При качественном исполнении музыкальная обработка – это просто расширение того, что люди делали на протяжении веков [49].
Технология дает возможность создавать подобные эффекты на кончиках пальцев звукооператоров, позволяя записи выйти за пределы того, чего можно достигнуть естественным путем. Это касается всех видов искусства: как только инструменты становятся широкодоступными, художественные достоинства результата начинают меняться. Каким бы ни было эстетическое качество конечного продукта, речь идет об изменении голоса, потому что человек все равно будет копировать звуки, полученные в студии, даже если в итоге они будут звучать искусственно, как у робота. Но плохо ли это? Певческий голос развивался тысячелетиями, и то, что мы наблюдаем сегодня, – лишь технология, ускоряющая эту тенденцию.
А что, если вообще избавиться от человека-певца и человека-оратора и использовать синтетические голоса? Пойдут ли люди в театр, чтобы смотреть, как играют роботы-актеры?
Назад: 4 Харизма голоса
Дальше: 6 Все роботы – актеры

