Книга: Зачем мы говорим. История речи от неандертальцев до искусственного интеллекта
Назад: 6 Все роботы – актеры
Дальше: 8 Компьютеры пишут любовные послания
7
Берегитесь: у компьютеров есть уши
Сколько еще потребуется времени, чтобы мы перестали отдавать компьютерам ненужные приказы и начали вести с ними осмысленные беседы? Чтобы это произошло, компьютеры должны стать хорошими слушателями. Им придется выйти за рамки алгоритмического декодирования речи и настроиться на тон нашего голоса. Каждый испытывал ужасное чувство, когда любимый человек обижался не на то, что мы сказали, а на то, как мы это сказали. Хорошо это или плохо, но тонкие оттенки голоса могут сказать очень многое: будь то возбуждение, с которым мы рассказываем смешной анекдот, скука от надоевшей беседы или ужас, если мы сообщаем подробности трагедии. Человек, умеющий вести разговор, улавливает эти тонкости независимо от того, чей голос он слышит – человека или микросхемы. Может ли компьютер стать хорошим слушателем?
Самая спорная из всех технологий, позволяющих компьютеру воспринимать речь, связана с распознаванием лжи. Многие из нас почувствуют себя не в своей тарелке при мысли о том, что их разоблачит мощь аналитики, принадлежащая холодной бездушной машине. И все же надежда на то, что технологии помогут отличить правду от лжи, делает технологии исключительно привлекательными для полицейских и политиков, которые стремятся защитить людей от убийц, сексуальных маньяков, финансовых мошенников и других преступников. Детектор лжи стал звездой бульварных телешоу и авторитетным судьей супружеской верности. И все это несмотря на множество примеров, указывающих на несостоятельность данного устройства.
Убийца с Грин-Ривер получил свое прозвище по названию реки к югу от Сиэтла, на берегу которой он в 1980-х и 1990-х годах оставлял тела своих жертв. Одним из инструментов, которым пользовалась полиция во время охоты на серийных убийц, был полиграф. Эта машина проверяет, говорит ли человек правду, опираясь на физиологические признаки, такие как скорость биения сердца, потоотделение и дыхание. В 1984 году Гэри Риджуэй, женатый человек, работавший в окрасочном цехе, добровольно вызвался пройти испытание на полиграфе и успешно его прошел. Девятнадцать лет спустя Риджуэя посадили за решетку за 48 жестоких убийств первой степени, после того как результаты теста ДНК неопровержимо доказали его связь с жертвами этих убийств [1]. Понятно, что полиграф не смог идентифицировать убийцу с Грин-Ривер.

Проверка на детекторе лжи на Клинтонском инженерном заводе, 1944
Научное исследование полиграфа, предпринятое Британским психологическим обществом, показало, что в уголовных делах правильность результатов теста составляет от 83 до 89 %, если он проверяет действительно виновных людей. Но если тест проходит невиновный человек, то правильность результатов составляет от 53 до 78 % от общего числа тестов [2]. Несмотря на это, в 2014 году британское правительство ввело обязательную проверку на полиграфе опасных преступников, совершивших сексуальные преступления. Судебные разбирательства показали, что проверка на полиграфе заставляла таких преступников с большей вероятностью признаваться в рискованном поведении, например рассматривании порнографических изображений или знакомстве с детьми. Но на самом деле эти признания не были получены на полиграфе: преступники признавались сами, потому что верили в возможности аппарата разоблачать ложь.
Но если полиграф недостаточно надежен, возможно, мы сможем научить компьютер анализировать речь? Анализ стресса по голосу – это сомнительный метод, используемый страховыми фирмами, полицией и правительственными департаментами для выявления у людей признаков лжи. ABC News утверждает, что этот метод использовался в заливе Гуантанамо и в Ираке, после чего был запрещен Пентагоном [3]. Компании, которые продают такие системы, не раскрывают секретов их работы, но научные исследования подвергли сомнению их эффективность. Напротив, существуют стандартные способы использования компьютера для восприятия голоса и его последующей интерпретации, и эти способы подробно описаны. Основные подходы уже используются в различных ситуациях – например, автомобиль по затрудненной речи определяет, что водитель пьян, или мобильное приложение предупреждает людей с биполярным расстройством об изменении настроения.
Научить компьютер слушать и понимать речь можно с помощью машинного обучения, когда компьютерную программу учат анализировать запись и извлекать из нее полезную информацию. Некоторые важные вычисления в науке о речи основаны на простых математических формулировках. Если вы хотите узнать, с какой частотой открываются и закрываются голосовые связки, существуют специальные уравнения для получения этой информации по форме звуковой волны. Но если вы хотите узнать о чем-то менее определенном, например не тревожится ли человек о чем-то, то маловероятно, что математические рассуждения принесут результат. В таких случаях компьютерная программа должна на собственном опыте «научиться» опознавать явные признаки тревоги.
Машинное обучение в случае с аудиозаписями может использоваться не только для распознавания речи. Оно применяется при анализе музыки, например для определения жанра – является ли произведение классическим, джазовым, представляет рок-музыку и т. д. В корпорации BBC R&D я занимался исследованием эмоций, которые вызывают музыкальные заставки теле- и радиопрограмм. В архивах BBC хранятся миллионы записей, и корпорация хотела, чтобы каждой из них была присвоена метка с указанием настроения (веселая ли запись, печальная или, наоборот, заряжает энергией), чтобы можно было легко сориентироваться в архиве, отыскивая записи с определенным настроением. Может ли в этом помочь анализ музыкальной заставки? Когда звучат первые радостные аккорды музыкальной заставки к американскому ситкому «Друзья», вы можете догадаться, что это оптимистическая комедия, даже если никогда не смотрели этот сериал. Многие новостные сводки начинаются торжественно, чтобы настроить на серьезный лад. Мы хотели узнать, сможет ли компьютер определять характер музыкальной темы: радостная она или грустная, забавная или серьезная?
Люди научаются соотносить определенные музыкальные характеристики с конкретными настроениями. Темп веселых мелодий, скорее всего, будет более быстрым, и в западной музыке в них часто используется мажорная тональность. Печальная музыка обычно бывает в миноре, в ней музыкальные фразы «стекают вниз», повторяя нисходящую интонацию, которую мы используем, когда сообщаем печальные новости [4]. Мы накапливаем подобные ассоциации в течение всей своей жизни, когда слушаем музыку. Алгоритм машинного обучения тоже должен прийти к такому «пониманию», прослушивая огромное количество аудиопримеров. В настоящее время второе рождение переживает один из методов машинного обучения, известный как искусственные нейронные сети. Принцип действия этого метода в общих чертах имитирует структуры мозга.
Человеческий мозг – это идеальная обучающаяся машина. Мозг младенца состоит примерно из 100 миллиардов нейронов, и каждый нейрон связан приблизительно с 10 000 других. Перед каждым нейроном стоит относительно простая задача. Информация проходит через него в форме электрических импульсов, которые принимаются дендритами – отростками клетки с короткими ответвлениями. Импульсы сочетаются путем сложения или вычитания, в зависимости от того, возбуждающей или тормозящей является связь. Если сложный сигнал превышает определенный порог, нейрон срабатывает и посылает еще один электрический импульс, который стремительно пробегает по нервному волокну, или аксону. Затем этот импульс передается другим нейронам. Именно слаженная работа этих простых нейронов в обширной и сложной сети и делает мозг поразительно мощным.
Ребенок вырабатывает новый навык посредством обучения. Когда отец сидит рядом с дочерью и читает ей книгу, мозг девочки пытается связать звуки, которые она слышит, со словами, которые она видит на странице. Когда малышка начинает читать книгу сама, отец обеспечивает обратную связь, сообщая ей, как она справляется, хвалит ее, если слово прочитано правильно, и деликатно исправляет в случае ошибки. Такое научение вызывает изменение силы, скорости и числа связей между нейронами в мозге девочки. Ребенок учится на успехах и ошибках, так что, когда он будет читать книгу в следующий раз, у него будет больше шансов сделать это правильно.
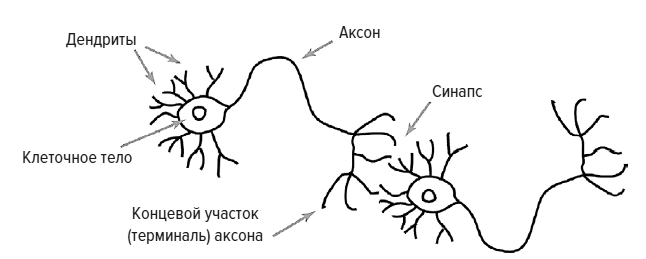
Два нейрона
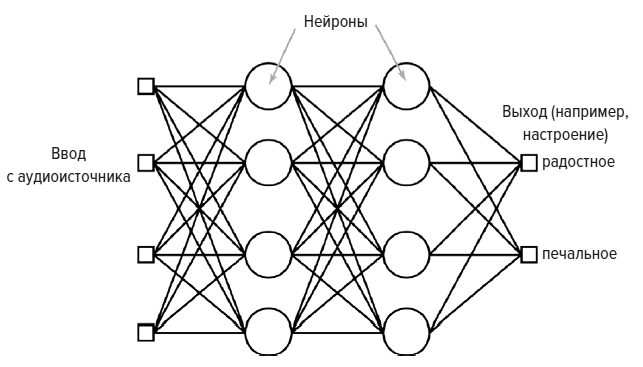
Искусственная нейронная сеть
Искусственные нейронные сети пытаются скопировать этот тип поведения. Они тоже сконструированы из большого количества «нейронов», которые способны выполнять простые математические операции. Каждый искусственный нейрон представляет собой несколько строк компьютерного кода, который, подобно своему биологическому эквиваленту, суммирует и обрабатывает входящие сигналы, перед тем как послать результаты другим нейронам сети. Однако эти нейроны не являются точными репликами нейронов мозга, и количество их связей значительно меньше.
Как и ребенок, искусственная нейронная сеть нуждается в обучении. Ученый-компьютерщик выступает в роли суррогатного родителя, снабжая сеть примерами и обеспечивая обратную связь относительно правильности или неправильности принятия решения алгоритмом. Для того чтобы обучить сеть определять настроение в мелодии музыкальной заставки, можно загружать в нее записи, уже четко отмеченные в зависимости от того, какие чувства, радостные или печальные, эта мелодия вызвала у среднего слушателя. Можно догадаться, что пометить вручную тысячи записей – это утомительное занятие. Поэтому мы обратились за помощью к людям и провели онлайн-эксперимент, в котором 15 000 человек прослушивали 144 музыкальные заставки за 60 лет и сообщали нам, какое настроение создавало у них каждое произведение. В процессе обучения компьютер использует обратную связь и оценивает, насколько верно было определено настроение, чтобы изменить силу связей между нейронами. Таким образом, компьютер постепенно улучшает свои расчеты. Обработав достаточное количество примеров, он постепенно научается более точно определять эмоцию, передаваемую музыкальной записью [5].
Поскольку искусственная нейронная сеть несравнима по мощности с человеческим мозгом, то загрузка сырого аудиоматериала может ее переполнить. У человека миллиарды нейронов, но даже у самых крупных искусственных сетей их только тысячи. Следовательно, способность компьютера к самообучению тоже ограничена, и поэтому ему лучше упростить задачу. В нашем случае мы загрузили несколько тщательно отобранных характеристик, извлеченных из звуков, а не сырой аудиоматериал [6]. Зная, что веселая музыка будет, скорее всего, более быстрой, вы можете применить математические формулы для вычисления темпа и ввести эти данные в искусственную нейронную сеть. Еще одним приемом может стать определение аккордов, которые выделяются в произведении, что поможет понять, мажор это или минор, и таким образом, предугадать, будет оно радостным или печальным.
Алгоритм машинного обучения становится таким мощным, потому что, научившись один раз, он приобретает способность делать разумные предположения о музыкальных заставках, которые никогда раньше не слышал. Конечно, система несовершенна и может быть хороша ровно настолько, насколько хороши были загруженные в нее данные. Когда мы расширили поле деятельности и попытались по музыкальным заставкам определить жанр телепрограмм, это вызвало затруднения. Одна из таких проблемных ситуаций – нестройные аккорды грустной заставки к детской программе Noggin the Nog [7]. Поскольку такая музыка не соответствует оптимистичному сценарию этого жанра, она привела алгоритм машинного обучения в замешательство. Возможно, однако, что она обманула бы и человека!
Таким образом, успех в машинном обучении обычно зависит от определения характерных особенностей, присущих необходимой информации. Чтобы использовать машинное обучение в распознавании лжи, нужно знать, какие характеристики речи могут на нее указывать, и тогда искусственная нейросеть сможет обнаружить обман. Итак, что же выяснили психологи по результатам экспериментов с людьми? Существуют ли явные признаки, указывающие на лжеца?
В январе 1998 года президент Билл Клинтон сделал знаменитое заявление: «У меня не было сексуальных отношений с этой женщиной, мисс Левински». Его речь была натянутой и выдержанной, а каждое слово сопровождалось ритмичным постукиванием указательным пальцем по пюпитру. Семь месяцев спустя президент выступил по национальному телевидению и объявил, что солгал. Контраст между этими двумя выступлениями Клинтона поражает. Его признание вины страстное и беглое, произнесено в знакомом всем стиле, который помог ему стать успешным политиком. Самый резкий контраст между этими речами наблюдается в изменении ритма: второе выступление уже не размеренное, паузы между словами естественным образом варьируются.
Когда родители спрашивают подростка, где он был вчера вечером, или представитель власти допрашивает подозреваемого, или кто-то слушает политика, словам которого не верит, – все исходят из предположения, что обязательно обнаружатся какие-то явные признаки, которые укажут на неправду. Когда человек неискренен, он обычно напряжен. И мы предполагаем, что волнение или страх оставят свой отпечаток и в речи [8]. Стресс увеличивает возбуждение, и это затрудняет точный контроль над голосом. У некоторых людей это сказывается на громкости речи, появляется грубость в голосе, изменяется частота колебаний голосовых связок. У других происходит избыточная компенсация эффектов повышенного возбуждения, поэтому речь становится чрезмерно точной. Это могло бы правдоподобно объяснить вымученность первого выступления Клинтона.
Проблема состоит в том, что многие люди полагают, что им лучше удается обнаружить ложь, чем солгать самим. Но на самом деле все как раз наоборот: мы лучше обманываем, чем разоблачаем ложь. Это может быть связано с ранними воспоминаниями о крупном обмане, который не удался. «Безобидная» ложь, где ставки не так высоки («Прости, твое письмо, похоже, попало в спам»), обычно не так запоминается и не имеет большого значения. Мы забываем, что на самом деле у нас хорошо получается обманывать. Мы обычно пытаемся отыскать конкретные признаки, которые, как нам кажется, укажут на то, что собеседник лжет, например, он отводит взгляд в сторону, улыбается или дергается. Но научные исследования показывают, что это неточные признаки. В действительности представление о том, что когда люди лгут, они больше суетятся, прямо противоположно тому, как на самом деле ведут себя лжецы.
Эйтан Элаад из Национальной полиции Израиля исследовал этот вопрос в проекте с участием 60 полицейских, которым показывали видеозаписи подростков и просили их определить, когда те лгут [9]. На видео были записаны восемь подростков, описывающих людей, которые им нравятся или не нравятся. Иногда они говорили правду, но иногда и обманывали. Правильная интерпретация таких видеозаписей – это настоящая проблема в расследовании лжи. Когда подростки лгали, они должны были бы проявлять признаки стресса, в противном случае следователи не смогли бы найти зацепок, с которыми можно было бы работать. Однако очевидно, что в случае раскрытия обмана речь не шла о реальной угрозе тюремного заключения или других жестких санкциях. Можно было сыграть на самооценке подростков, сказав им, что только те, кто обладает мощным интеллектом, сильной волей и отличным умением контролировать себя, смогут преуспеть в обмане [10].
Две трети израильских полицейских думали, что они показали очень хорошие результаты в определении лжи. На самом деле их ответы были даже хуже, чем ожидалось: ложь была обнаружена только в 46 % случаев. С тем же успехом они могли бы просто бросить монетку. В среднем по данным исследований, в которых принимали участие судьи, психиатры и специалисты по работе с полиграфом, успешность была чуть выше простой догадки [11].
В 1994 году Ричард Уайзман, профессор Хертфордширского университета и специалист по общественному пониманию психологии, провел большой эксперимент по изучению лжи. Ход эксперимента контролировался в меньшей степени, чем лабораторные исследования, но Уайзман протестировал огромное количество людей, которые должны были обнаружить ложь. В эксперименте использовались два интервью с известным британским политическим обозревателем сэром Робертом Деем. В одном интервью он солгал, в другом сказал правду. Публика должна была это определить. Более 40 000 человек слушали Дея по радио, читали его интервью в газетах или смотрели выступления по телевизору. Радиослушатели, у которых для обнаружения лжи были лишь вербальные и голосовые подсказки, опознали ее правильно в 73 % случаев. Читатели газеты, у которых был только текст, правильно ответили в 64 % случаев. Удивительно, но те, кто смотрел интервью по телевизору и мог не только слышать, но и видеть Дея, показали худшие результаты и оказались правы в 52 %, что ненамного выше ожидаемой вероятности. По-видимому, добавление визуальных подсказок на самом деле снижает способность обнаружения лжи [12].
По результатам всемирного обзора, самым распространенным признаком обмана, по мнению большинства людей, является то, что если человек лжет, он отводит взгляд [13]. Если человек смотрит в сторону, даже маленькие дети 5–6 лет связывают это с враньем. Но любопытно, почему мы полагаемся на этот ложный знак? Человек очень хорошо определяет чувства окружающих, и, по-видимому, здесь существует какая-то иллюзорная взаимосвязь. Мы отводим взгляд, когда нам стыдно, а если нас поймали на лжи – это стыдно. Возможно, именно поэтому мы ошибочно полагаем, что если человек говорит правду, он будет смотреть прямо в глаза, а лжец отведет взгляд.
Низкие показатели успешности в исследованиях обмана частично объясняются тем, что люди полагаются на стереотипные, но ошибочные признаки, как раз такие, как взгляд в сторону. Еще одним фактором является презумпция правды: мы естественным образом убеждены, что истинных утверждений больше, чем ложных. Как и в большинстве жизненных ситуаций, в попытках обнаружить ложь мы для вынесения суждений используем эвристику, или произвольные решения, а она часто основана на предубеждениях. Майкл Шермер в книге «Верующий мозг» (The Believing Brain) приводит следующий пример [14]. Представьте, что вы – первобытный человек, находитесь в саванне и вдруг слышите звук. Это шум ветра в траве? Или это к вам подбирается хищник? Предположим, что это хищник, и он готовится к нападению, тогда самое правильное решение – быстро смыться. Если есть вероятность, что это хищник, то очень опасно успокаивать себя тем, что это ветер. Так, себе во благо вы усваиваете практическое правило, основанное на предубеждении, что любой звук в саванне означает приближение хищника.
Когда надо обнаружить ложь, презумпция истинности означает, что мы верим: правдивых утверждений больше, чем ложных (за исключением некоторых особых обстоятельств, например когда мы слушаем презентацию продаж). Причина такого предубеждения может заключаться в том, что в повседневной жизни мы сталкиваемся с большим количеством истинных, а не ложных утверждений. Кроме того, часто легче подтвердить сказанное, когда говоришь правду. Ложь встречается гораздо реже, а когда это происходит, ее труднее обнаружить. Иногда можно даже подсознательно вступить с собой в сговор, чтобы сохранить обман в тайне. Действительно ли подруга хочет получить честный ответ, когда спрашивает, не слишком ли она толстая в своем любимом платье? (Этот феномен получил название «эффект страуса».) Короче говоря, обычно мы полагаем, что можем отличить и правду, и ложь, хотя большая часть подтверждений исходит от правды. В большинстве случаев мы не склонны распознавать обман в том, что нам говорят [15].
Есть подсказки, которые могут повысить шансы раскрыть обман, но они плохо различаются и трудно обнаруживаются. Лжецы склонны делать больше речевых ошибок, при ответах на вопросы могут казаться вялыми, медленнее говорить. Для того чтобы спланировать и осуществить обман, необходимо дополнительное время на обдумывание. Обычно честно ответить легче, такой ответ подразумевает, что описываемое произошло на самом деле. Существуют, однако, и другие варианты маскировки обмана, и тогда, если вас допрашивают, мозг начинает работать интенсивнее, чтобы последующие ответы совпадали с предыдущей ложью [16]. Олдерт Фрай из Портсмутского университета полагает, что это можно использовать для повышения успешности допросов. Вы можете заставить подозреваемого рассказать свою историю в обратном порядке, добавить когнитивные установки, и тогда с большей вероятностью можно будет распознать признаки лжи.
Одним из самых знаменитых лжецов современности является бывший профессиональный велогонщик Лэнс Армстронг. Он единственный в мире семь раз финишировал первым в гонке «Тур де Франс», но на протяжении всей карьеры и после ее завершения его обвиняли в использовании допинга. Стоя на Елисейских Полях на фоне Триумфальной арки и произнося свою последнюю речь победителя в 2005 году, Армстронг заявил: «Всем, кто с пренебрежением относится к велоспорту, я хочу сказать одно: вы циники и скептики, мне жаль вас. Мне жаль вас потому, что разум ваш закрыт. И мне жаль вас потому, что вы не способны поверить в чудо… это спорт, и победить здесь можно лишь тяжелой работой». В 2013 году Армстронга лишили всех титулов, когда он, в конце концов, признал, что принимал запрещенные стимуляторы и анаболики. В старых телевизионных интервью, в которых спортсмен отрицал использование допинга, поражает то, насколько свободно и уверенно он отвечал на вопросы. Этот прием подтверждался в исследовании, которое показало, что, если хочется соврать, сохраняйте свободу и плавность речи, и тогда вас не поймают [17]. Армстронг – это показательный пример еще одного открытия в исследовании обмана: люди, которые хорошо умеют врать, когда лгут, держатся естественно.
Но есть ли еще какие-то вокальные подсказки? Эксперименты показали, что тон речи лжеца часто повышается, частота увеличивается примерно на 6–7 Гц. Можно обнаружить несколько вероятных причин этого явления. Например, стресс из-за необходимости лгать изменяет скорость биения сердца, что в свою очередь изменяет давление в нижней части голосовой щели, вызывая ускорение вибрации голосовых связок. К сожалению, это происходит не всегда. Короче говоря, ученые не дали нам никаких универсальных признаков лжи.
С учетом вышесказанного можно только удивляться нашей склонности верить в то, что мы легко распознаем лжецов. А разве это не противоречит нашему собственному опыту, когда мы врали, а нас никто не разоблачал? (Ну, сам-то я, конечно, никогда не вру!) Опрос тысячи взрослых американцев показал, что люди лгут в среднем 1,65 раза в день, хотя значительная часть этой лжи производится скромным количеством продуктивных врунов [18]. Учитывая, что даже самые заслуживающие доверия люди говорят неправду, чтобы избежать неловких ситуаций, почему же мы никак не научимся лучше распознавать ложь других, даже на собственном опыте? Противоречивая и тонкая природа вокальных и вербальных признаков лжи делает это невозможным.
Исследование Линн тен Бринке и ее коллег из Калифорнийского университета в Беркли, проведенное в 2014 году, дает основания полагать, что, в то время как нашим сознательным попыткам разоблачить лжеца мешает поиск бесполезных стереотипных подсказок, нашему бессознательному это удается чуть-чуть лучше [19]. В этом исследовании ученые просили испытуемых просмотреть видеозаписи с участием людей, которые либо врали, либо говорили правду. На видео были записаны интервью фиктивного преступления – кражи 100 долларов. Испытуемые должны были сказать, лгут ли люди на видео. Кроме того, с целью выявить подсознательные мысли испытуемых Линн тен Бринке провела тест на неявные ассоциации [20]. Испытуемых просили сказать, соответствуют ли слова (такие как «лживый» и «правдивый») картинкам, на которых были изображены лжецы и люди, говорящие правду, и затем измерялась скорость, с которой подбирались словесные ассоциации. Тен Бринке обнаружила, что, когда слово не совпадало с картинкой, – например, когда слово «лживый» предъявлялось вместе с изображением человека, говорящего правду, – испытуемому требовалось больше времени на ответ. Таким образом, хотя испытуемые с трудом определяли лжецов, когда их просто просили сказать, кто лжет, они подсознательно находили подсказки относительно правдивости говорящих. Если предрассудки нашего сознательного ума мешают нам обнаружить ложь, возможно, бесстрастный компьютер в этом преуспеет.
Несколько коммерческих систем заявляют, что могут распознать обман, используя тест на наличие стресса в голосе (VSA). В 2003 году BBC News сообщила: «Компания по страхованию автомобилей, которая установила телефонные детекторы лжи, объявила, что четверть всех заявлений о краже машин была отозвана с момента введения новинки» [21]. Год спустя New York Times опубликовала заявление одного из производителей, что их технологию используют «1400 органов правопорядка на всей территории Соединенных Штатов, а также местные и федеральные организации, включая Министерство обороны» [22]. За последние годы Министерство труда и пенсионного обеспечения Соединенного Королевства потратило 2,4 миллиона фунтов стерлингов на оценку этой технологии, включая проверку почти 3000 претендентов на выплаты [23].
Как утверждают, действие подобных систем основывается на отслеживании микротреморов. Стресс изменяет приток крови к мышцам, включая и мышцы, контролирующие гортань, в результате чего, предположительно, меняются микротреморы голоса [24]. Однако, хотя исследования и обнаружили небольшие треморы в крупных мышцах, например в бицепсах, нет никаких доказательств того, что они возникают и в мышцах гортани. Управление голосом – это невероятно сложный процесс, в котором задействованы самые маленькие и самые быстрые мышцы тела, которые обеспечивают артикуляцию. Даже если бы здесь присутствовали микротреморы, их влияние было бы невозможно обнаружить.
С научной точки зрения недостатки тестов на наличие стресса в голосе были детально описаны в статье, опубликованной в журнале International Journal of Speech, Language and the Law двумя специалистами в области лингвистики и фонетики из Швеции – Франсиско Ласердой из Стокгольмского университета и Андерсом Эриксоном из Гетеборгского университета [25]. Авторы статьи не скрывали, что относятся к этой технологии с презрением. «В любой области найдутся шарлатаны, – такими словами начинается введение к статье, – особенно там, где можно сделать деньги, и лингвокриминалистика – не исключение». Статья была удалена с сайта журнала, после того как одна из компаний, технологию которой высмеяли ученые, пригрозила подать в суд на издателя. Этот случай послужил причиной того, что в 2013 году в Великобритании были изменены законы о распространении клеветы с целью защиты ученых, которые публикуют прошедший независимое рецензирование материал в научных журналах [26].
В центре внимания статьи находился один конкретный патент на технологию, который подтверждал опасения авторов по поводу используемого метода. «Текст патента был похож на студенческое эссе. Причем эссе такого студента, который совершенно не понимал, о чем идет речь, а просто использовал красивые слова», – говорит Франсиско. В патенте содержалось 500 строк компьютерного кода, что позволило Франсиско реконструировать процесс распознавания лжи. Программа выбирает из записи голоса изгибы звуковой волны, обрабатывает их, а затем вычисляет количество пиков, низших точек и плоских участков. Плоские участки могут быть вызваны паузами, хмыканьем (заполняющим речевую паузу) и поэтому, возможно, имеют некую слабую корреляцию с плавностью речи. Но число пиков и низших точек в профиле волны очень сильно зависит от настроек звукозаписывающего устройства.
Франсиско объясняет: «Это примерно то же самое, как если бы вы взяли текст, подсчитали количество случаев употребления гласной между двумя согласными, а потом оценили полученное число и длину последовательностей символов, которые находятся на расстоянии, скажем, пяти или десяти шагов в алфавите. И на основе этих данных сделали вывод, в каком состоянии находится автор текста!» Франсиско охарактеризовал эту программу как «управляемый голосом квази-случайный генератор чисел». Основываясь на количестве пиков, низших точек и плоских участков, программа выдает ряд меток, например: «обманчивость; низкий уровень стресса; мышление меньше, чем в рамках классификации; нормальное возбуждение». Как замечают в статье Ласерда и Эриксон, «результат анализа структурирован по тем же принципам, что и гороскопы», и представляет собой модель, которую практически каждый оператор может интерпретировать по-своему.
Подобные системы подвергались и научной проверке, которая показала, что они дают результаты, сравнимые с ожидаемой вероятностью. Келли Демхаус и ее коллеги из Университета Оклахомы опросили 319 заключенных из окружной тюрьмы, использовали ли те наркотики. Затем их ответы протестировали на наличие стресса в голосе [27]. После окончания интервью у опрошенных были взяты образцы мочи для анализа, и таким образом была установлена истина. «Ложные утвердительные ответы», вычисленные программой, на самом деле очень важны. Представьте, что, поддавшись на уговоры компании, вы согласились тестировать всех пассажиров в Хитроу на голосовой стресс. Вы будете каждый день отсеивать 8000 невинных людей, которых программа ложно идентифицировала как представляющих опасность.
В другом исследовании, тоже проведенном в тюрьме, количество арестантов-обманщиков сократилось на две трети после того, как им сообщили, что их речь анализировалась [28]. Таким образом, по-видимому, тест на наличие стресса в голосе работает благодаря блефу: люди, скорее всего, не станут лгать, если будут знать, что их могут разоблачить. Психологи называют это явление «эффектом фиктивного полиграфа». Оно было обнаружено Эдвардом Джоунзом и Гарольдом Сигалом, которые использовали поддельный детектор лжи, чтобы заставить испытуемых «открыть канал связи с собственной душой» и обнаружить их настоящие помыслы [29]. Полиция, страховые фирмы и правительственные учреждения могли бы сэкономить кучу денег, просто притворившись, что они купили детекторы лжи! Однако все это заставляет меня задуматься о том, сколько времени может продолжаться такой блеф.
Достаточно немного покопаться в интернете, чтобы без труда обнаружить свидетельства бесполезности подобных систем. Но тест на наличие стресса в голосе – это технология-зомби. Сколько бы ни разоблачали ее с помощью научных доказательств, она так или иначе возрождается снова. Не обращая внимания на результаты научных исследований, Министерство труда и пенсионного обеспечения Великобритании потратило 2,4 миллиона фунтов стерлингов с мая 2007 по июль 2008 года, проверяя возможность использования этой технологии для сокращения случаев мошенничества с пособиями. Идея была такая: когда заявитель звонит в правительственное учреждение, анализ стресса в голосе поможет сотрудникам определить, на кого следует обратить особое внимание. В четырех из семи случаев, что составило 80 % всех телефонных звонков, система сработала так же, как если бы сотрудник просто подбросил монетку [30]. «Жаль, что они потратили такую огромную сумму денег, чтобы получить такой результат, можно было бы для начала просто задать нужные вопросы», – сказал мне Франсиско Ласерда.
Сложности с обнаружением обмана в голосе заключаются в том, что и лжец, и говорящий правду могут находиться в стрессе. Исследователи лжи называют это «ошибкой Отелло» [31]. В пьесе Шекспира Отелло обвиняет жену, Дездемону, в любовной связи с Кассио, своим лейтенантом. У Кассио видели платок, который Отелло подарил Дездемоне. Отелло думает, что Кассио убили, исполнив его приказ, и сообщает Дездемоне, что Кассио мертв. Она решает, что у нее не осталось возможности доказать свою невиновность. Отелло принимает ее страдания за доказательство вины и убивает ее.
Если бы Отелло жил в наши дни, мог бы компьютер помочь ему определить, виновна Дездемона или нет? Как человек, много лет занимающийся машинным обучением, могу поспорить, что исследование только интонации и ритма речи Дездемоны вряд ли указало бы ему на правду. Если ни одному научному исследованию не удалось найти каких-либо определенных моделей, которые люди используют, когда лгут, и если стресс может изменять голос даже у тех, кто не лжет, тогда даже самый лучший алгоритм машинного самообучения ждет неудача.
А как насчет более простой на первый взгляд задачи: может ли компьютер, «слушая», определить, насколько человек пьян? Когда мы «под градусом», речь может резко изменяться. Говорение требует исключительно сложной координации мелких моторных движений. После принятия определенного количества алкоголя мышечный контроль теряется, речь становится неуклюжей и неразборчивой, потому что нам трудно справиться со своей голосовой анатомией. Из-за проблем с артикуляцией и притупленного восприятия мы, возможно, будем говорить медленнее.
Анализ голоса оказался в центре внимания в судебном процессе против Джозефа Хейзелвуда, капитана нефтяного танкера «Эксон Вальдес». Его обвинили в том, что он был пьян, когда командовал судном. В 1989 году танкер налетел на риф у побережья Аляски, в результате в океан вылилось 41,8 миллиона литров нефти и погибло 250 000 птиц, 3000 морских выдр, 300 тюленей, 250 белоголовых орланов и 22 косатки [32]. Записи разговоров Хейзелвуда во время катастрофы показали, что его голос был изменен. Он говорил медленнее, чем обычно, несколько изменилась и грубость голоса.
Мог бы компьютер обнаружить такие изменения в голосе капитана и автоматически передать командование кораблем первому помощнику? В 2011 году ученые приняли участие в соревновании, чтобы понять, насколько хорошо компьютер может определять опьянение по записи голоса [33]. Первым этапом стала подготовка образцов, с которыми далее должны были работать исследователи. Образцы были получены следующим образом: исследователи напоили добровольцев (154 человека) и попросили их проговорить некоторые фразы. Затем перед исследователями встала задача разработать компьютерные алгоритмы, которые могли бы определить, есть ли в аудиозаписях признаки, указывающие на трезвость или опьянение говорящего. Лучшая программа добилась точности 71 % [34]. Это соответствует результату, который может показать человек: в среднем люди могут опознать речь пьяного в трех четвертях случаев [35]. К сожалению, показатель успешности для компьютера слишком низкий, чтобы машину можно было считать надежным инструментом для проверки капитанов.
В деле «Эксона Вальдеса», хотя Хейзелвуд и признал, что пил водку перед тем, как подняться на борт, его оправдали. Одна из причин – анализ голоса не мог однозначно доказать его опьянение. Изменения в речи могли быть вызваны тем, что ему приходилось повышать голос, чтобы его могли услышать члены команды, ведь на корабле шумно [36]. Хотя, как и человек, «слушающий» компьютер может считывать голосовую информацию, выводы могут оказаться ошибочными, поскольку алгоритм несовершенен или голосовые подсказки недостаточно однозначны.
До настоящего времени алгоритмы поиска лжи не учитывали слова. Возможно, компьютер с большей вероятностью смог бы обнаружить опьянение, если бы искал особые фразы, например: «А знаешь, ты ведь мой лучший друг», или обращал внимание на то, как пьяные «слов неправильный порядок часто делают»? Джонатан Айткен был высокопоставленным британским политиком, которому прочили пост будущего консервативного премьер-министра. В 1985 году, будучи главным секретарем Министерства финансов, Айткен ушел в отставку с поста члена кабинета министров, чтобы противостоять обвинениям, выдвинутым против него газетой Guardian и Granada TV. Они заявили, что он получал взятки от бизнесменов из Саудовской Аравии в связи с продажей оружия. Он, не колеблясь, выступил с речью, в которой заявил, что подаст в суд по обвинению в клевете: «Если мне придется начать борьбу, чтобы удалить раковую опухоль нашей бесчестной и извращенной журналистики с помощью меча чистой правды и надежного щита честной игры, пусть будет так. Я готов к бою». Четыре года спустя Айткен был приговорен к тюремному заключению сроком 14 месяцев за лжесвидетельство и препятствие отправлению правосудия. В ходе дела по обвинению в клевете он заявил, что часть счета из отеля Ritz в Париже оплатила его жена деньгами, которые он ей ранее выдал. Но Guardian удалось получить копию этого счета, и обман был разоблачен. Карьера Айткена закончилась. Если прослушать архивную запись его речи, в которой он говорил о «мече правды», можно услышать, что манера его речи удивительно невыразительна и резко контрастирует с саркастическими словами.
Но чтобы у компьютера появилась возможность обнаружить ложь, ему придется научиться понимать слова. Это позволит системе ориентироваться на другие признаки обмана, обнаруженные в научных исследованиях, например, на тот факт, что когда человек врет, он приводит меньше деталей и устанавливает меньше связей с внешними событиями [37]. Но чтобы использовать эти данные, компьютеру нужно уметь распознавать речь и понимать ее семантику.
Одна из первых электронных систем распознавания речи, которая называлась «Одри», была создана в 1952 году К. Дэйвисом и его коллегами из Лабораторий Белла в США. Она могла распознавать отдельные цифры, а при тщательной настройке на конкретного говорящего правильно идентифицировала практически каждое слово. Как и другие первые системы, «Одри», по существу, работала по принципу подбора моделей. На рисунке выше показана запись голоса человека, который считает от одного до пяти. В верхней части – обычный способ представления звука, «виляющий» след, показывающий, как изменяется давление, создаваемое голосом, по мере произнесения пяти цифр. Второе слово, two, показывает два отдельных отрывка, [t] и [oo]. Оно начинается с взрывного [t], при котором воздух сначала блокируется языком, прижатым кверху, к нёбу, а когда язык отрывается, резкий выдох создает звук. За этим быстро следует гласный [oo], который почти пропевается. В нижней части – спектрограмма, показывающая изменение частотной характеристики речи. Для слова two темная линия опускается вниз слева направо, а для слова three видна диагональная темная линия, идущая в обратном направлении. Когда говорящий произносит вторую часть слова three, его интонация создает увеличение частоты, отсюда и идущая вверх линия на спектрограмме.
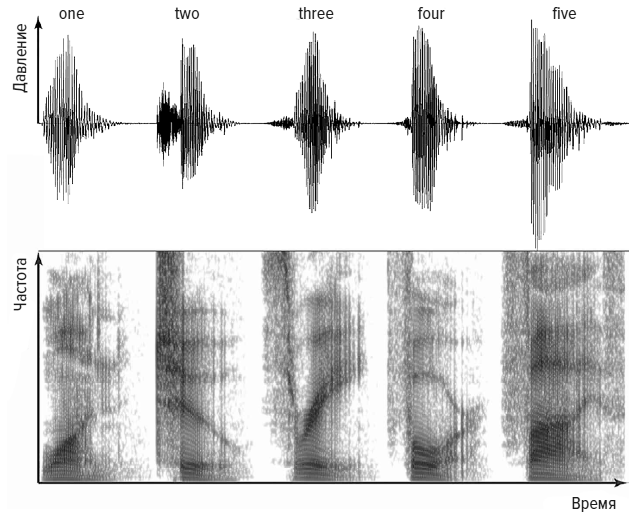
Мужской голос, считающий «one, two, three, four, five»
Спектрограммы подобны отпечаткам пальцев и показывают, что у каждой цифры уникальный рисунок. Задачей «Одри» было подобрать к образцу из произнесенного в микрофон звука пару из ожидаемых рисунков звука для каждой цифры. В 1950-е годы это было сложно реализовать, потому что для создания спектрограмм просто не было компьютеров. Более того, «Одри» была не слишком практичной системой. Джеймс Флэнаган из Лабораторий Белла вспоминал: «Она занимала релейную стойку шести футов (более 1,8 м) высотой, была ужасно дорогой, поглощала солидное количество энергии и создавала мириад проблем обслуживания, связанных со сложной ламповой схемой» [38].
Еще одна проблема, связанная с подобным типом анализа, состоит в том, что человек не всегда одинаково произносит слова. Например, слово, которое обычно произносится с понижающейся частотой, в конце вопросительного предложения может произноситься с повышающейся интонацией. Кроме того, у разных людей произношение может сильно отличаться, так что ваша спектрограмма счета от одного до пяти будет отличаться от моей. Даже лучшие современные системы, которые используют значительно более изощренные технологии, чем «Одри», не срабатывают. Когда в 2011 году iPhone 4S появился на рынке Великобритании, голосовой помощник Siri с трудом понимал сильный шотландский акцент [39].
В последние годы появление мощных компьютеров и использование машинного обучения вполовину снизили количество ошибок при распознавании речи. Современные системы еще далеки от того, чтобы распознавать речь так же, как это делает человек, но им больше не требуется, чтобы вы говорили медленно и делали паузы между словами. Более того, в эпоху больших объемов данных эти системы обучаются на огромном количестве примеров. Именно так Apple решила проблемы с Siri: компьютер прослушал огромное количество записей шотландского произношения, чтобы его запомнить. Кроме того, большие объемы данных означают, что системы распознавания речи обладают огромным словарем – например, голосовой помощник Google претендует на знание примерно трех миллионов слов. Это значительно превышает возможности человека. Поэтому система распознавания речи будет работать, даже если вы прибегаете к очень узкой теме со своим специализированным набором слов.
В наши дни каждый человек создает огромные массивы цифровых данных, совершая покупки, используя социальные сети или осуществляя поиск в интернете. При этом мы передаем компаниям огромное количество информации о себе – в обмен на бесплатные услуги. То, что мы позволяем компьютерам подслушивать наши голоса, делает эти сведения еще более ценными, потому что, помимо слов, это дает возможность узнать и о наших чувствах.
Однако применение машинного самообучения в больших объемах данных может привести к неожиданным негативным последствиям. Можно подумать, что, поскольку эти системы разработаны на языке математики и алгоритмов, они будут столь же объективны, как доктор Спок из «Звездного пути». Но программное обеспечение усваивает и социальные предрассудки, которые содержатся в используемых им данных. В 2017 году Айлин Калискан и ее коллеги из Принстонского университета проанализировали ассоциации между словами в популярной базе данных, которая использовалась для обучения алгоритмов машинного самобучения [40]. В этой базе данных содержались миллиарды слов, закачанных из интернета. В одном из тестов Калискан исследовала, какие имена собственные появлялись в предложениях с приятными словами, например «любовь», а какие – в предложениях с неприятными словами, например «уродливый». Результаты показали наличие расовых предрассудков: имена европейцев и белых американцев чаще связывались с приятными словами, чем имена афроамериканцев. Еще в одном тесте проявился гендерный предрассудок: мужские имена чаще ассоциировались со словами, относящимися к работе, например «профессионал» и «зарплата», а женские имена оказались ближе к словам, описывающим семью, например «родители» и «свадьба». Пополняйте алгоритм машинного самообучения примерами из такой базы – и вы рискуете создать сексистское и расистское программное обеспечение.
Подобная предвзятость уже наблюдается в таких популярных инструментах, как переводчик Google. Например, используем его для перевода с турецкого на английский двух фраз: o bir doktor и o bir hemşire. Результат будет такой: he is a doctor («он – врач») и she is a nurse («она – медсестра») [41]. Но o в турецком языке – это местоимение третьего лица, не указывающее на пол. Представление о том, что врач мужчина, а медсестра – женщина, отражает культурные предрассудки и асимметричное распределение пола в сфере медицины: мы получили сексистский алгоритм. Использование такого алгоритма для просмотра заявлений о приеме на работу усилит существующие культурные предубеждения. Хотя дискуссии вокруг искусственного интеллекта нередко фокусируются на алгоритмах, часто именно данные определяют его работу и могут привести к нежелательным и опасным результатам. В 2015 году компания Flickr выпустила систему распознавания образов, в которой черные люди были неверно обозначены как «обезьяны», а фотографии концентрационных лагерей в Дахау и Аушвице как «конструкция для лазания» и «спорт». Если не соблюдать осторожность, подобные ошибки могут возникать, когда компьютеры будут идентифицировать характеристики людей по их речи. И это будет связано с тем, что в нашем голосе содержится тонкая, но часто противоречивая информация о расе, сексуальности и гендере.
Такие компании, как Google, Apple и Microsoft, сегодня владеют огромными массивами звукозаписей, которые они используют для создания систем распознавания речи. В одном из экспериментов Microsoft использовала данные продолжительностью 24 часа из своего голосового приложения, содержащего 30 000 высказываний. Люди искали конкретные фирмы, поэтому часто встречались слова Walmart, McDonald’s или 7-Eleven. Закончив самообучение, искусственная нейронная сеть достигла точности 70 % в распознавании предложений при голосовых запросах, которые она раньше никогда не слышала [42]. Такой результат впечатляет, если учесть, что у авторов записей были разные акценты, в сообщениях содержались ошибки в произношении и фоновый шум. Однако это все равно означает, что многие слова, предложенные алгоритмом, были выбраны неправильно. Но это проблема не только компьютеров. Как мы уже видели, когда люди слушают речь, в ней часто могут отсутствовать куски или присутствовать ошибки, но мозг заполняет пропуски или вносит исправления. То же самое можно сказать и о чтении. Не так уж трудно понять следующее предложение: «По реузльтатам иселдовасния… не имеет занчения, в каокм поярдке сотят бувкы в солвах, евидстенная ванжая вещщ – тошбы певрая и оплсендяя букав была в нжуонм метсе» [43]. Испорченный текст можно исправить при условии, что достаточное количество букв – правильные. Это же относится и к речи.
Когда вы набираете поисковый запрос в браузере, появляются варианты окончания искомого текста. Когда я набираю в поисковике «Тревор Кокс», первое предложение будет «Тревор Кокс WHL», потому что мое имя совпадает с именем канадского игрока в хоккей на льду, играющего за Medicine Hat Tigers. Такие предположения возможны, поскольку для создания моделей языка используются обширные данные, и в приведенном примере слова, скорее всего, встречаются рядом при поисковом запросе. Подобное моделирование языка жизненно важно для распознавания речи, так как позволяет исправлять неверно понятые слова [44].
Голосовой поиск удивительно эффективен, но может ли он помочь в распознавании лжи? Только не сегодня, поскольку модель языка фокусируется на вероятных маркерах поиска, и у Google для этого имеются огромные массивы информации. Компания начала анализировать ложные факты на веб-страницах, таким образом, рейтинги результатов исследования могут основываться на надежности сайта [45]. Но это имеет свои ограничения в плане обнаружения лжи, потому что письменный и устный язык работают по-разному. Давайте рассмотрим богатство игры слов, например, в спунеризме, и проблему создания модели языка, которая могла бы с этим работать. У богослова Уильяма Спунера, который родился в 1844 году, были проблемы: язык не успевал за мозгом. Говорят, что однажды на бракосочетании он сказал: «А теперь поцелуйно обругайте невесту» (It is kisstomary to cuss the bride). А однажды он случайно предложил тост за «нашего чудаковатого старика-декана» (our queer old dean) вместо «за нашу добрую старушку королеву» (our dear old queen) [46].
Ученые уже пытались использовать машинное самообучение для обнаружения шуток, включая двусмысленности [47]. Они обучают компьютер искать слова с неприличными намеками, например «банан» (banana). Кроме того, для эротических предложений характерны определенные структуры, которые встречаются и в двусмысленных фразах, например: «[субъект] мог бы есть [объект] весь день напролет». После завершения обучения компьютер обнаружил двусмысленные предложения в 70 % случаев. (Это предложение вызывает двусмысленность в сложных проблемах машинного обучения.)
Возможно, если компьютер услышит характерные звуки смеха, он сможет легко обнаруживать шутки. Когда я встретился с нейробиологом Софи Скотт из Университетского колледжа Лондона, чтобы задать ей несколько вопросов об импрессионистах, мы обсуждали и ее исследование, в котором она пыталась определить, как человек выражает эмоции. Работа Софи началась с изучения вызванных испугом криков и выражений недовольства, и только позже она переключилась на более приятное занятие: начала исследовать смех. Но ей пришлось убеждать скептиков, что это серьезный предмет для изучения. Однажды кто-то из коллег Софи прикрепил к пачке отпечатанных на принтере бланков согласия на участие в исследовании следующую записку:
Эта кипа бумажек – просто макулатура, судя по содержанию, и если ее не заберут, она будет ликвидирована.
Но смех – это серьезный предмет, потому что для человека он является обычным состоянием. «При прочих равных условиях вы чувствуете себя комфортно и хорошо с окружающими вас людьми. Вы смеетесь в их присутствии», – объясняет Скотт. Если смех отсутствует, значит, что-то не в порядке. Крайний случай такой ситуации – это люди, страдающие гелотофобией: они боятся смеха, потому что думают, что смеются над ними. Этот случай Софи описывает следующим образом: «На сто процентов данное явление связано с тем, что человек находится в безнадежном психотическом состоянии». Исследование смеха помогает добраться до сути социальных взаимодействий, потому что смех облегчает разговор. Пары, которые снимают неизбежный стресс от постоянного нахождения в обществе друг друга с помощью смеха, в большей степени удовлетворены своими отношениями и дольше остаются вместе.
Прежде чем перейти к обсуждению акустического отпечатка, оставляемого смехом, Софи демонстрирует модель мозга, чтобы показать области, задействованные в процессе слушания. В случае речи левое полушарие задействовано в обработке фонетической, семантической, лексической и синтаксической информации. Это означает, что правое полушарие концентрируется на всех остальных свойствах голоса, таких как интонация или идентификация говорящего. Следовательно, когда Софи исследует человека на фМРТ-сканере и проигрывает ему запись смеха, правое полушарие демонстрирует бо́льшую активность.
Но до того как начать сканирование мозга, Софи нужно было подобрать хорошие записи смеха. Первые попытки, сделанные вместе с коллегами, были успешными, фактически, вспоминает Софи, «мы просто потрясающе провели время, смеша друг друга». Но, когда они попытались записать смех с группой волонтеров, ничего не получилось. «Мне даже не пришло в голову, в чем причина, пока я не увидела, как один бедняга из группы одиноко сидит в безэховой камере и не смеется: конечно, они ведь не знали друг друга [хорошо], они не были друзьями», – сказала Софи. Необходимо, чтобы донор смеха находился один в безэховой камере, чтобы Софи могла получать чистую запись голоса, но смех – это социальная активность. Поэтому Софи и ее коллегам пришлось придумать новую процедуру. «Все начиналось за пределами безэховой камеры, волонтеры проводили много времени вместе, смотрели видеозаписи, вместе смеялись, создавая теплую дружескую атмосферу, – объясняет Софи. – А потом в конце концов кто-то раскочегаривается, и его уже можно запихивать в эту камеру».
Когда Софи воспроизводила эти записи волонтерам, которых она исследовала в сканере, обнаружились два типа смеха со специфическими неврологическими реакциями. Смех – это естественная реакция на забавную ситуацию, но чаще всего встречается вежливый социальный смех, который «смягчает» беседы и в большинстве случаев не имеет ничего общего с юмором. Такой нарочитый смех свидетельствует о том, что человек участвует в разговоре и наслаждается им, и за 10 минут беседы обычно такой смех возникает пять раз [48]. Когда люди слышат такой нарочитый смех, Софи отмечает повышение активности в медиальных префронтальных зонах мозга, которые обычно используются для формирования намерений человека. По-видимому, логично, что в случае такого социального сигнала, как смех, в декодировании звука задействованы сети моделей психического состояния.
Другой вид смеха возникает, когда вы сильно заводитесь и смеетесь бесконтрольно. «Ха-ха-ха» – это очень простая вокализация. Каждое «ха» создается спазмами диафрагмы и межреберных мышц, выталкивающими из легких порции воздуха, которые затем приводят в движение голосовые связки. При настоящем смехе возникает более высокое давление, и это создает более высокий тон, чем при нарочитом смехе. Кроме того, получается еще и хриплый, и свистящий звук, являющийся результатом неконтролируемого использования голосовой анатомии [49]. Неконтролируемый смех может оказаться очень странным звуком. Комик Джимми Карр – особый случай, он описывает свой смех как звуки, производимые счастливым дельфином – он смеется нетипично, на вдохе [50]. Когда человек слышит такой неконтролируемый смех, мозг реагирует повышением активности в левой и правой слуховых зонах коры, расположенных как раз над ушами. Поскольку настоящий смех отличается от речи, пения и других привычных звуков, его необычность приводит к большей активности в слуховой зоне коры [51].
Поскольку смех имеет специфический акустический след, компьютеры, использующие машинное самообучение, могут отличать его с большой долей вероятности [52]. К сожалению, это не означает, что компьютер способен обнаруживать юмор. Если учесть, что в большинстве случаев смех возникает не как реакция на реальную шутку, а как социальная «смазка», компьютер будет очень часто ошибаться. Чтобы компьютер стал хорошим слушателем, способным идентифицировать шутки и ложь, он должен знать о языке гораздо больше. В настоящее время компьютеры механически освоили огромное количество простой информации, но они не имеют представления о том, как реально обстоят дела.
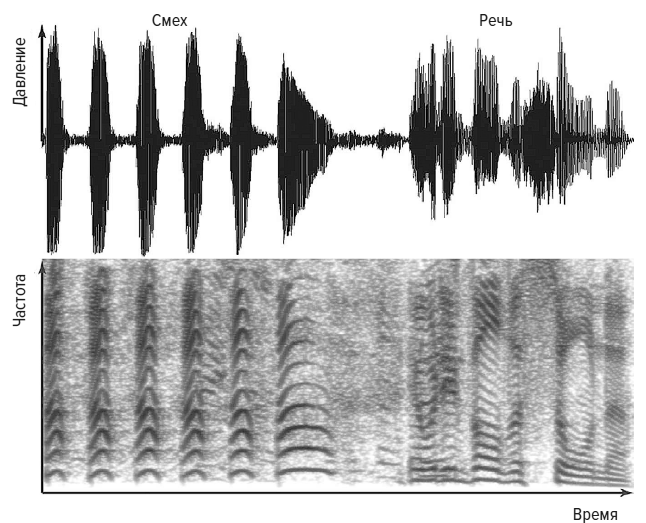
Смех («ха-ха-ха-ха-ха-ха-ха»), а затем речь («а для этого потребуется сауна») Джимми Карра
Герой двух сериалов BBC («Да, господин министр» и «Да, господин премьер-министр»), вымышленный государственный служащий сэр Хамфри Эплби, сказал однажды: «Хорошая речь не та, в которой мы можем доказать, что говорим правду, а та, в которой никто не может доказать, что мы лжем» [53]. Можно сделать так, чтобы ложь было трудно обнаружить, и одна из уловок – включить ее в правдивый текст. Преступник может слегка исказить правдивую историю, например изменить время, когда произошло событие, что позволяет ему говорить в основном правду и обеспечить себе вводящее следствие в заблуждение алиби. Еще одна тактика – умолчание. Партнер, у которого спросили мнение о костюме, частью которого является вызывающая сорочка, может высказать свое мнение о покрое и ничего не сказать об отвратительном рисунке под пиджаком.
Если учесть, что нам приходится иметь дело с многочисленными способами обмана, то неудивительно наше стремление стать надежным детектором лжи. Люди уже разработали разнообразные подходы ко лжи, ведь обман – это очень важный навык, возникший вместе с эволюционными преимуществами, что видно на примере приматов, которые утаивают пищу и совокупляются тайком. Все мы когда-нибудь приукрашивали свои рассказы, чтобы сделать их более интересными и запоминающимися. А белая ложь – это важная часть взаимодействия в социальной группе.
У людей овладение умением обманывать является признаком развития. Около 25 % детей к двум годам уже умеют обманывать, к четырем этой способностью обладают уже примерно 90 %; а к восьми годам – практически каждый ребенок [54]. Это очень важный показатель развития мозга. Дети, которые начинают обманывать раньше, демонстрируют более быстрое когнитивное развитие, и родители, которые обнаруживают, что их малыш лжет, находят это обнадеживающим фактором. Ведь для того чтобы обмануть, ребенку нужно осмыслить, как окружающие воспринимают информацию.
Компьютерное моделирование общения людей показывает, что в обществах, основанных на сотрудничестве и честности, отдельный человек может получить некоторые преимущества, если он иногда кого-то обманывает или лжет, конечно, при условии, что у него высокие цели, а риск разоблачения невелик [55]. Модели показывают также, что обманщиков иногда надо разоблачать – это обеспечивает доминирующую роль сотрудничества. Поэтому ущербная способность обнаруживать ложь не является недостатком, это важная составляющая развития общества.
Исследования продемонстрировали, что те виды приматов, у которых хорошо развито сотрудничество, одновременно демонстрируют и более частые случаи лживого поведения. Люди доминируют в мире именно благодаря сотрудничеству. Голосовые сигналы лжи очень тонкие, сложные и противоречивые именно потому, что, если мы будем время от времени обманывать, и нам это будет сходить с рук, мы обеспечим себе эволюционное преимущество. Давление эволюции заставит и Пиноккио научиться контролировать свой нос. Учитывая, что мы не можем безошибочно обнаруживать ложь, но обладаем гораздо более совершенными навыками слушания, чем самый умный современный компьютер, не стоит удивляться, что анализ голосового стресса не дает результатов. Для создания надежного детектора лжи необходимо, чтобы искусственный интеллект умел анализировать речь и голос даже лучше, чем человек.
Назад: 6 Все роботы – актеры
Дальше: 8 Компьютеры пишут любовные послания

