Нельзя копать колодец иголкой
«Все – яд, все – лекарство. И только доза определяет разницу». Эта знаменитая фраза Парацельса применима не только к веществу, но и к инструментам. Нельзя копать колодец иголкой, и не потому, что она плоха сама по себе, но потому, что предназначена она совсем для других дел. Так во всем. В том числе и в статистических законах. Есть области, где закон нормального распределения можно и нужно применять, и области, где он неэффективен или даже губителен. Одна из таких областей – финансовые рынки.
Давайте рассмотрим распределение такой случайной величины, как колебания курса доллара к рублю (вспоминаю свою первую профессию биржевого трейдера). Предположим, что курс доллара равен 50 рублям, а среднее значение колебаний доллара за последний год равняется 50 копеек в день со стандартным отклонением от среднего 5 копеек. Вопрос: может ли доллар в следующий вторник взлететь (или упасть) не более чем на 55 копеек (среднее значение плюс одно стандартное отклонение)? Может, с вероятностью 68,2 %. А могут ли его колебания уложиться в диапазоне 60 копеек (среднедневные колебания плюс-минус две сигмы)? Могут – с вероятностью 95,4 %. А в диапазон 65 копеек (уже три сигмы)? Конечно – в 99,7 % случаях из 100 курс доллара будет колебаться в столь широком диапазоне. Он даже может вырасти или упасть на 75 копеек, правда, вероятность этого события невелика, лишь один случай на миллион.
А может ли доллар за один день вырасти сразу на 50 рублей (то есть в два раза)? «Ну-у, не-е-ет, это нереально», – отвечаем мы (нам поддакивают начинающий трейдер и профессор кафедры статистики). Если опираться на вышеописанный закон нормального распределения случайных величин, это кажется невозможным. Ибо колебания в 50 рублей соответствуют отклонению от среднего значения (50 копеек) аж на 990 стандартных отклонений! А ведь мы помним, что нормальный закон распределения отрицает отклонение даже на 10 сигм, не то что на 990!
Какая же практическая польза от всех этих рассуждений? Представьте, что вы валютный спекулянт и внимательно отслеживаете котировки доллара к рублю. Вы будто хищный зверь, подстерегающий свою добычу в засаде, терпеливо выжидаете благоприятного момента, когда совершить бросок и накинуться на «жертву». Вот доллар подешевел на 30 копеек. Это нормальная, типичная ситуация для валютного рынка, на этом нельзя заработать, ибо шансы на возврат курса невелики. Вот если бы падение было глубже, тогда другое дело. Так что 30 копеек мало, вы выжидаете.
Вот падение составило уже 50 копеек. Такое на валютном рынке бывает не часто, но и не достаточно редко, чтобы ожидать отскока, то есть падение может продолжиться. Поэтому опять не покупаем, ждем.
И вот ваше терпение вознаграждено – доллар рухнул сразу на 75 копеек. «Такое бывает лишь раз в миллион торговых сессий», – быстренько подсчитали вы в уме. Ну конечно, ведь вы уже прочитали и освоили предыдущий материал и ваши расчеты верны – столь сильные колебания курса соответствуют среднедневному колебанию плюс 5 сигм! Надо брать (то есть покупать). Много. Очень много. Не только на свои, но и на заемные деньги. Если вероятность того, что доллар подешевеет сразу на 75 копеек, равна один на миллион, это означает, что вы дождались самого дна, ниже он уже не упадет. Ведь не могут же два события с такой малой вероятностью следовать друг за другом. В этом случае действует закон перемножения вероятностей, что дает в итоге почти нулевую вероятность такого события. Поэтому ниже быть не может. Два снаряда в одну и ту же воронку не падают! Куй железо, пока горячо! Лови момент! Не упусти свой шанс! Схвати за хвост птицу-удачу. Ну и еще масса подобных поговорок.
Чем обычно заканчиваются такие истории, надеюсь, вы уже догадались. Полным разорением. На следующий день после вашей покупки доллар обрушивается на величину своего среднедневного колебания плюс 100 или 300 стандартных отклонений. Или 500. А может, и вся 1000 сигм!
А-а-а-а-а-а…
Не верите? Вот факты. В 1987 году только за один день американские акции подешевели почти на четверть. Представьте, вся корпоративная Америка только за один день 19 октября 1987 года без видимых причин стала дешевле на 22,6 %! Столь сильный обвал котировок не вписывался ни в одну систему риск-менеджмента, ибо падение на 22,6 % превышает 20 (!!!) стандартных отклонений. А нормальный закон распределения запрещает даже 10 отклонений. С точки зрения теории вероятностей такое событие происходит крайне редко, ну просто крайне редко – не чаще чем один раз за несколько миллиардов жизней Вселенной. Поэтому-то его возможность и была проигнорирована участниками торгов. И тем не менее это произошло.
Как вы думаете, может ли курс доллара за выходные вырасти в четыре раза? Нет, это невозможно, ответит подавляющее большинство. В сложных системах чудеса случаются – ответ системно мыслящего трейдера. Уйдя в пятницу с работы, когда курс доллара был 60 рублей, вы можете в понедельник увидеть отметку 240! Более того, подобное уже случалось, просто мало кто об этом помнит. 17 августа 1998 года Россия объявила дефолт по внешним и внутренним обязательствам, а курса доллара за выходные вырос почти в четыре раза! Вот график.
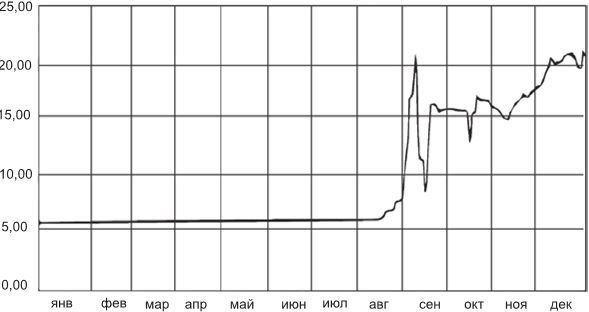
В сложных самоорганизующихся системах чудеса случаются. Курс доллара может вырасти за выходные в четыре раза. Однажды такое уже было
Как же так? Ведь закон нормального распределения запрещает отклонение от среднего даже на 10 стандартных отклонений, как же возможно такое, что рубль обвалился на 1000 сигм? Может быть, закон вовсе и не закон? Или в нем есть исключения, о которых нам неизвестно? И как тогда объяснить четырехкратный рост курса доллара 17 августа 1998 года? А ослабление рубля на несколько десятков процентов 16 декабря 2014 года – это тоже исключение?
Нет-нет, с законом нормального распределения все в порядке, он прекрасно работает (правда, нашему горе-трейдеру это уже не поможет). Проблема в том, что мы упустили одну важнейшую деталь. Вчитайтесь еще раз, более внимательно – закон распределения случайных величин. Случайных!!! Попадания в цель при выстрелах из пушки действительно случайны, то есть каждый выстрел не оказывает никакого влияния на последующий и никак не зависит от предыдущего. Поэтому правило трех сигм работает здесь без исключений. Случайны и выпадения орла или решки при подбрасывании монеты. Результат каждого последующего броска не зависит от предыдущего.
Но вот колебания цен на финансовых рынках не являются независимыми! Они не случайны, хотя на первый взгляд (чего уж скрывать, и на сотый тоже) это не очевидно. На биржах балом правят паника, страх и эйфория. А эти чувства очень и очень заразны. Они мгновенно распространяются среди участников торгов, заражая их и не позволяя принимать независимые, то есть спланированные заранее, на холодную голову решения.
Не ищите случайность там, где ее нет
Дело не в низкой эффективности используемого нами закона, а в том, что мы пытались выкопать колодец с помощью иголки. Мы пытались использовать данный закон совсем не в той области, где он работает, а именно не для тех событий. Закон нормального распределения применим к описанию вероятностей действительно независимых событий или же тех, между которыми наблюдается едва заметная связь. Таких, как выстрелы из пушки, распределение веса и роста людей, продолжительность жизни, различных тестовых шкал и пр. А динамика цен на финансовых рынках, распределение голосов в результате политических выборов, рассадка зрителей в концертном зале, возраст вступления в брак и многие-многие другие, на первый взгляд, случайные события на самом деле вовсе не случайны. Они представляют собой цепь или каскад событий, где каждое конкретное событие испытывает влияние предыдущего и оказывает влияние на последующее. Динамика цен на финансовых рынках, землетрясения, поведение социальных групп, веяние моды, число погибших при террористических атаках, количество самоубийств на тысячу жителей и даже количество представителей сексуальных меньшинств – все это специфические группы. События в таких группах непредсказуемы, однако между ними наблюдается тесная взаимосвязь. Покупка долларов одним трейдером оказывает влияние на решение другого трейдера. То, как вы сели в концертном зале, оказывает влияние на выбор места остальными зрителями. Внезапное землетрясение вызывает цепь природных катаклизмов. Одно отдельно взятое самоубийство приводит к росту количества самоубийств в обществе, а выбранный способ свести счеты с жизнью может повлиять на то, какой способ предпочтет следующий несчастный. И даже ваша прическа оказывает влияние на те пожелания, которые озвучит ваш коллега по работе во время ближайшего посещения парикмахерской. Вот так-то!
Итак, мы пришли к выводу, что распределение событий, которые не могут быть отнесены к независимым, должно быть описано другим законом, отличным от закона нормального распределения. И такой закон есть – он называется степенной (профессиональные статистики иногда говорят про экспоненциальный, но не будем на этом заострять внимание). Вот как он выглядит.
Пример графика степенного распределения величин, которые нельзя назвать случайными
По оси Х здесь отложены разные виды событий, в порядке возрастания их количественных характеристик. Именно виды, а не отдельные события. Это значит, что предварительно была проведена калибровка событий – сначала, ближе к точке 0, идут совсем незначительные, потом просто маленькие, затем средние, крупные и, наконец, с крайней правой стороны оси Х – гигантские. Например, если рассматривать распределение землетрясений в зависимости от магнитуды по шкале Рихтера, то на оси Х будут лежать землетрясения с магнитудой 1, 2, 3 и так далее баллов.
По оси Y отложена частота, с которой эти группы событий встречаются (тоже по возрастанию).
Для примера рассмотрим распределение такой величины, как население городов. По оси Х расположим виды населенных пунктов (в зависимости от количества жителей). Сначала деревушки на грани вымирания, потом небольшие населенные пункты, дальше малые и средние города, крупные, а в конце – крупнейшие мегаполисы мира. По оси Y – доля в процентах, которая отвечает на вопрос, как часто встречается такой тип населенного пункта. Вот что у нас получилось:
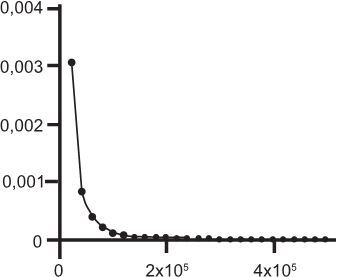
Распределение видов населенных пунктов в зависимости от их доли в общем количестве населенных пунктов
На графике мы видим, что диаграмма явно скошена влево. И это легко объяснимо: ведь на нашей планете гораздо больше маленьких населенных пунктов, чем крупных многомилионных мегаполисов. И чем крупнее город, тем реже он встречается. Поэтому на графике доля населенных пунктов с числом жителей 4 × 105 едва отлична от нуля.
Да, уважаемый читатель, ты прав – анализировать и использовать график в такой форме невозможно. И поэтому наши друзья математики решили представлять подобные графики в другой, более наглядной форме. Она называется логарифмическая. И по оси Х, и по оси Y данные берутся не в абсолютных значениях, а в логарифмических. Тогда график приобретает другой вид:
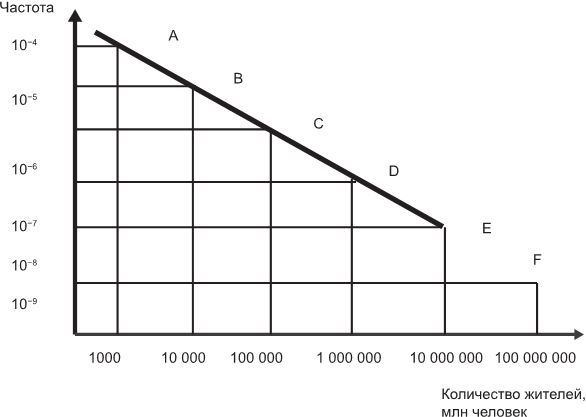
Логарифмическая шкала делает предыдущий график намного более удобным и понятным
Согласитесь, стало намного удобнее. Но главное даже не в большей наглядности.
Посмотрите внимательно на график. Что важного, необычного вы здесь видите? Во-первых, линия, отражающая частоту распределения, стала прямой. Теперь анализировать искомую зависимость намного проще. Обратите также внимание, я выделил на линии пять точек: А, В, С, D, E. Они соответствуют населенным пунктам с количеством жителей в 1 тысячу, 10 тысяч, 100 тысяч, 1 миллион и 10 миллионов человек. Несложно догадаться, что каждый последующий населенный пункт крупнее предыдущего в 10 раз.
По оси Y отложена частота, с которой встречаются данные населенные пункты (шкала логарифмическая). 10-4 соответствует 0,01 %, 10-5 – 0,001 % и т. д.
Что мы видим? Населенные пункты, в которых проживает 1000 человек, встречаются в 0,01 % всех случаев. Городки с населением 10 000 человек – в 0,001 % случаев. Города с населением 100 000 человек – в 0,0001 % случаев и т. д.
Итак, судя по графику, существует обратная зависимость между такими показателями, как число жителей населенного пункта и частота, с которой такой населенный пункт встречается. То есть чем крупнее город, тем реже он встречается. И не просто «реже» – мы можем точно подсчитать, насколько реже. Города, соответствующие точке С, встречаются в 10 раз реже, чем те, что соответствуют точке В; в 100 раз реже, чем города, соответствующие точке А, и т. д. Города с населением 10 миллионов человек встречаются в 10 000 раз реже, чем поселки, в которых проживает тысяча жителей.
И эта обратная зависимость постоянна. Коэффициент 10 (он так и называется – коэффициент зависимости) не меняется на протяжении всей линии. Он один и тот же и для мегаполисов с населением более 10 миллионов человек, и для деревни, в которой проживает менее 10 жителей!
0,01 % всех городов – 1000 человек
0,001 % всех городов – 10 000 человек
0,0001 % всех городов – 100 000 человек
0,00001 % всех городов – 1 000 000 человек
0,000001 % всех городов – 10 000 000 человек
Итак, на каждую 1000 населенных пунктов с населением до 1000 человек приходится 100 городов с населением 10 тысяч, 10 городов с населением 100 тысяч, 1 город с населением 1 миллион и 0,1 города с населением 10 миллионов человек.
Математики при этом говорят, что распределение городов в зависимости от количества приживающих в них жителей отвечает степенному закону с неким постоянным показателем (в нашем случае он равен 10).
Постоянство этого показателя поистине удивительно! Откуда города знают, как им распределяться в зависимости от количества жителей? Откуда они знают, с какой частотой они должны встречаться в природе? И как они узнают, что при увеличении общего количества городов на планете показатель их распределения (10) должен оставаться постоянным? То есть если общее число городов на нашей планете вдруг увеличится в два раза, то соотношение миллионников и десятитысячников должно сохраниться на уровне 100 к 1!
Поразительные закономерности. Но самое удивительное, что точно такой же график можно нарисовать не только для городов. Вот как можно проинтерпретировать степенную зависимость в распределении землетрясений:
в течение периода, когда происходит 1000 землетрясений с магнитудой 5 баллов, случается 100 землетрясений с магнитудой 6 баллов, 10 – с магнитудой 7 баллов и т. д.
Оказывается, степенное распределение очень распространено в живой и неживой природе. Вот, например, как выглядит график распределения богатства людей.
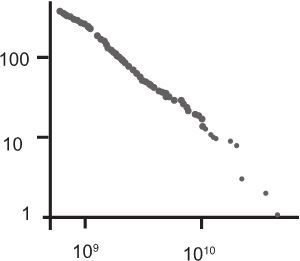
Степенной характер распределения людей в зависимости от накопленного богатства
Обратите внимание – правая часть графика размыта, что объясняется незначительным количеством сверхбогатых людей.
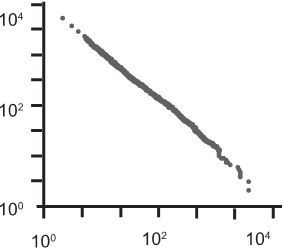
Степенной характер распределения слов в англоязычных текстах
Или вот график, описывающий частоту, с которой встречаются слова в англоязычных произведениях. В данном случае речь идет о тексте романа «Моби Дик» Германа Мелвилла. Самые часто встречающиеся слова – «the», «of», «and» и «to». Исследования других англоязычных текстов выявили точно такое же распределение частоты слов. Разные авторы, разные эпохи, разные тексты, а распределение слов не меняется. Что интересно, и устная речь подвластна степенному распределению, только наиболее часто встречающиеся слова там другие: «I», «and», «the», «to» и «that».
О чем это говорит? О том, что чем чаще я буду употреблять некоторое слово, тем чаще его будете употреблять вы. Вы, в свою очередь, окажете влияние на речь вон того парня, живущего в тысяче километров от вас и от меня. Великая сила взаимозависимости!
А вот распределение частоты телефонных звонков. Казалось бы, разве может быть какая-то зависимость между звонками на те или иные номера телефонов. Очевидно, что это случайные события. Однако график упорно твердит о наличии зависимости.
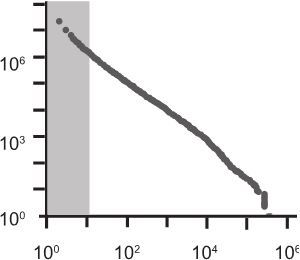
Степенной характер распределения телефонных звонков
На этом графике представлено распределение числа звонков, полученных в течение одного дня 51 миллионом абонентов американской телефонной компании AT&T. Как это ни покажется странным, но максимальное число звонков, полученных одним абонентом, составило 375 746!!! То есть 260 звонков в минуту.
Аналогичный график можно построить и для распределения полученных и отправленных электронных писем.
Ну и последний пример. На графике, расположенном на следующей странице, представлено распределение интенсивности 119 военных конфликтов, которые произошли в период между 1816 и 1980 годами. Интенсивность здесь означает долю погибших от всего населения соответствующей страны. Самой интенсивной войной за рассматриваемый период оказалась (опять контринтуитивный тезис) малоизвестная, но крайне жестокая война между Парагваем и Боливией (1932–1935). Интенсивность этого военного конфликта в два с лишним раза превысила интенсивность Первой мировой войны и почти в четыре раза – войны 1939–1945 годов. О чем говорит этот график?
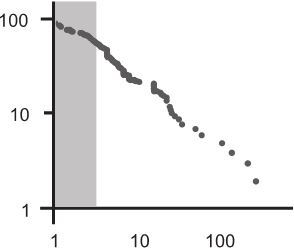
Степенной характер распределения войн
Все та же взаимозависимость. Чем интенсивнее военный конфликт, тем реже он встречается. И не просто реже, а с постоянным коэффициентом, справедливым и для малых стычек, и для мировых войн. Каждая война испытывает влияние предыдущей и оказывает влияние на последующую!
«Слава притягивает славу», «деньги к деньгам» – вот яркие примеры проявления степенного закона. Вспомните, сколько ваших знакомых прочитали «Пятьдесят оттенков серого» только потому, что эту книгу прочитали другие? Знали, что разочаруются, но все равное прочитали. Слава сама по себе, не важно, дурная она или хорошая, притягивает к себе все новых и новых поклонников. Это касается популярных книг и фильмов, бурно дорожающих (или бурно дешевеющих) криптовалют, научных статей, блогов светских львиц и пр.

