7. Визуализация данных в Kibana
Kibana — это веб-инструмент для аналитики и визуализации, созданный на базе открытого исходного кода. Он позволяет визуализировать данные, которые хранятся в Elasticsearch в различном виде: в таблицах, картах, графиках. Благодаря простому интерфейсу этого компонента вы сможете легко исследовать большие объемы данных и выполнять продвинутую аналитику данных в реальном времени.
В книге мы рассмотрим различные компоненты Kibana и поговорим о том, как использовать их для анализа данных.
В этой главе мы разберем следующие темы.
• Скачивание и установка Kibana.
• Исследование данных с помощью Kibana.
• Визуализации в Kibana.
• Анализ временных данных в Kibana.
• Настройка и разработка известных плагинов в Kibana.
Скачивание и установка Kibana
Как и другие компоненты Elastic Stack, Kibana довольно просто скачать и установить.
Перейдите по ссылке https://www.elastic.co/downloads/kibana#ga-release и в зависимости от вашей операционной системы скачайте файл ZIP/TAR, как показано на рис. 7.1.

Сообщество разработчиков Elastic довольно активно, и релизы новых версий с обновленным функционалом и исправлениями выходят довольно часто. За время, которое вы уделили чтению этой книги, последняя версия Kibana могла измениться. Инструкции в книге актуальны для версии Kibana 6.0.0. Вы можете перейти по ссылке past releases (прошлые релизы) и скачать версию 6.0.0. Информация, приведенная в книге, будет действительна для любого релиза версии 6.х.
Рис. 7.1
Kibana — это инструмент визуализации, который опирается на Elasticsearch при выполнении запросов данных, используемых для создания визуализаций. Следовательно, прежде, чем продолжать, убедитесь, что у вас установлена и работает Elasticsearch.
Установка в Windows
Распакуйте скачанный файл. После распаковки перейдите в созданную папку, как показано в следующем фрагменте кода:
D:\>cd D:\packt\kibana-6.0.0-windows-x86_64
Для запуска Kibana перейдите в папку bin, наберите kibana.bat и нажмите клавишу Enter.
Установка в Linux
Распакуйте пакет tar.gz и перейдите в созданный каталог, как показано ниже:
$> tar -xzf kibana-6.0.0-darwin-x86_64.tar.gz
$> cd kibana/
Для запуска Kibana перейдите в папку bin, наберите ./kibana и нажмите клавишу Enter.
Вы должны получить логи следующего вида:
log [04:52:06.749] [info][optimize] Optimizing and caching bundles for kibana, stateSessionStorageRedirect, timelion and status_page. This may take a few minutes
log [04:55:20.118] [info][optimize] Optimization of bundles for kibana, stateSessionStorageRedirect, timelion and status_page complete in 193.36 seconds
log [04:55:20.241] [info][status][plugin:[email protected]] Status changed from uninitialized to green - Ready
log [04:55:20.402] [info][status][plugin:[email protected]] Status changed from uninitialized to yellow - Waiting for Elasticsearch
log [04:55:20.426] [info][status][plugin:[email protected]] Status changed from uninitialized to green - Ready
log [04:55:20.454] [info][status][plugin:[email protected]] Status changed from uninitialized to green - Ready
log [04:55:21.987] [info][status][plugin:[email protected]] Status changed from uninitialized to green - Ready
log [04:55:22.001] [info][listening] Server running at http://localhost:5601
log [04:55:22.008] [info][status][ui settings] Status changed from uninitialized to yellow - Elasticsearch plugin is yellow
log [04:55:22.270] [info][status][plugin:[email protected]] Status changed from yellow to green - Kibana index ready
log [04:55:22.273] [info][status][ui settings] Status changed from yellow to green - Ready
Kibana является веб-приложением и работает на платформе Node.js, в отличие от Elasticsearch и Logstash, которые работают на JVM. Во время запуска Kibana пытается подключиться к Elasticsearch по адресу http://localhost:9200. Kibana запускается с портом 5601 по умолчанию. Вы можете использовать браузер для входа в Kibana по ссылке http://localhost:5601, а также увидеть статус сервера по ссылке http://localhost:5601/status.
Страница статуса показывает информацию об использовании ресурсов сервера и перечень установленных плагинов (рис. 7.2).
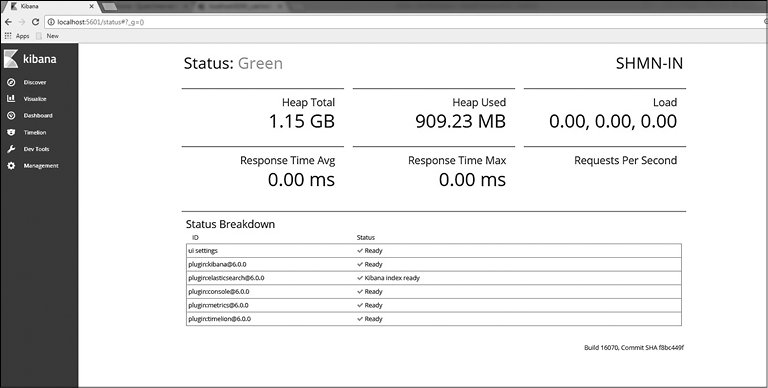
Рис. 7.2

Следует настраивать Kibana таким образом, чтобы она работала с узлом Elasticsearch той же версии. Совместная работа разных патч-версий Kibana и Elasticsearch (например, Kibana 6.0.0 и Elasticsearch 6.0.1) в целом поддерживается, но не рекомендуется.
Запуск разных крупных версий (например, Kibana 5.х и Elasticsearch 2.х) не поддерживается, равно как и запуск мелких версий Kibana, которые являются новее версии Elasticsearch (например, Kibana 6.1 и Elasticsearch 6.0).
Настройка Kibana
После запуска Kibana работает, используя порт 5601, и пытается подключиться к Elasticsearch на порте 9200. Что, если мы захотим изменить эти настройки? Вся конфигурация Kibana находится в файле с названием kibana.yml, который расположен в папке config внутри папки $KIBANA_HOME. Если открыть этот файл в текстовом редакторе, можно увидеть, что его содержимое представляет собой большое количество настроек (пары «ключ — значение»), которые рекомендованы по умолчанию. Это значит, что, пока значение не было изменено, оно считается значением по умолчанию. Чтобы убрать комментарий с параметра, удалите символ # в начале строки параметра и сохраните файл.
В табл. 7.1 приведены ключевые настройки, которые пригодятся вам в начале работы с Kibana.
Таблица 7.1
| server.port | Эта настройка указывает порт, с помощью которого Kibana будет выполнять запросы. Значение по умолчанию — 5601 |
| server.host | Определяет адрес, с которым Kibana будет связываться. Корректными значениями являются и IP-адреса, и имена хостов. Значение по умолчанию — localhost |
| elasticsearch.url | URL-ссылка, используемая для всех запросов Elasticsearch. Значение по умолчанию — http://localhost:9200. Если вы настроили работу Elasticsearch на другой хост/порт, убедитесь, что изменили этот параметр соответствующим образом |
| elasticsearch.username elasticsearch.password | Если настроена авторизация в Elasticsearch, укажите в этом параметре имя пользователя и пароль для доступа. Более детально о безопасности Elasticsearch мы поговорим в следующей главе (X-Pack) |
| server.name | Легко читаемое имя отображения для идентификации процесса Kibana. Значение по умолчанию соответствует названию хоста |
| kibana.index | Kibana использует индекс в Elasticsearch для хранения выполненных поисков, визуализаций и панелей управления. Если индекс не существует, Kibana создаст его. Значение по умолчанию — .kibana |

Файл .yml чувствителен к пробелам и отступам. Убедитесь, что все некомментированные параметры имеют равный отступ, в противном случае во время запуска Kibana произойдет ошибка, делающая невозможной дальнейшую работу.
Подготовка данных
Поскольку вся суть работы Kibana состоит в детальном рассмотрении данных, загрузим образец данных, которые мы будем использовать в процессе обучения. Один из самых распространенных примеров использования — анализ логов. Для этого примера мы загрузим логи сервера Apache в Elasticsearch через Logstash и далее будем использовать Kibana для анализа и создания визуализаций.
По ссылке https://github.com/elastic/elk-index-size-tests находится набор логов сервера Apache, которые были собраны с сайта www.logstash.net за период с мая по июнь 2014 года. Он содержит 300 000 лог-событий.
Перейдите по ссылке https://github.com/elastic/elk-index-size-tests/blob/master/logs.gz и нажмите кнопку Download (Скачать). Распакуйте файл logs.gz.
Убедитесь, что у вас установлена версия Logstash 5.6 или выше. Создайте в папке $LOGSTASH_HOME\bin конфигурационный файл apache.conf, как показано во фрагменте кода ниже:
input
{
file {
path => "D:\Learnings\data\logs\logs"
type => "logs"
start_position => "beginning"
}
}
filter
{
grok {
match => {
"message" => "%{COMBINEDAPACHELOG}"
}
}
mutate {
convert => { "bytes" => "integer" }
}
date {
match => [ "timestamp", "dd/MMM/YYYY:HH:mm:ss Z" ]
locale => en
remove_field => "timestamp"
}
geoip {
source => "clientip"
}
useragent {
source => "agent"
target => "useragent"
}
}
output
{
stdout {
codec => dots
}
elasticsearch { }
}
Запустите Logstash, как показано ниже, чтобы программа приступила к обработке логов и их индексированию в Elasticsearch. Для запуска Logstash потребуется некоторое время, и в результате вы увидите серию точек (по точке на каждую обработанную строку логов):
$LOGSTASH_HOME\bin>logstash –f apache.conf
Проверим общее количество документов (лог-событий), индексированных в Elasticsearch:
curl -X GET http://localhost:9200/logstash-*/_count
В качестве ответа вы должны увидеть значение 300000.
Пользовательский интерфейс Kibana
Откройте Kibana в браузере по ссылке http://localhost:5601. Стартовая страница будет выглядеть следующим образом (рис. 7.3).
Рис. 7.3
Взаимодействие с пользователем
Прежде чем углубляться в ключевые компоненты Kibana, разберемся во взаимодействии с пользователем. Типичный процесс пользовательского взаимодействия изображен на рис. 7.4.
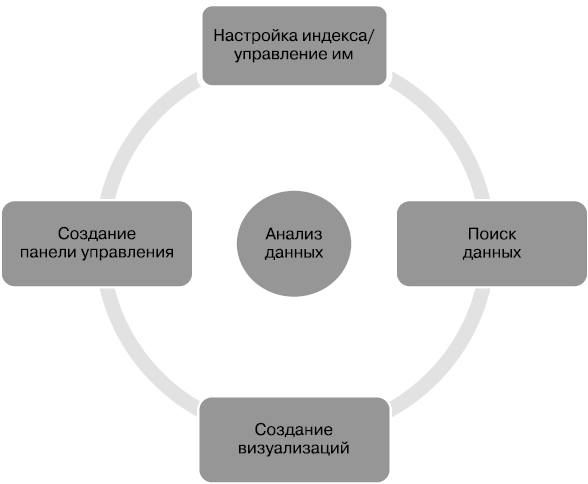
Рис. 7.4
По следующим пунктам вы сможете четко проследить процесс взаимодействия в Kibana.
1. До того как приступать к анализу данных в Kibana, пользователь загрузил данные в Elasticsearch.
2. Чтобы анализировать данные в Kibana, пользователю необходимо предоставить программе сведения о данных, которые хранятся в индексах ES. Он выбирает индексы, по которым необходимо провести анализ.
3. После настройки пользователю следует узнать структуру данных: поля документа, типы полей. Это требуется, чтобы принять решение о том, как именно необходимо визуализировать данные, какие ставить вопросы и какие нужны ответы.
4. Далее, когда есть четкое понимание имеющихся данных, вопросов и желаемых ответов, пользователь создает необходимые визуализации, которые облегчат поиск ответов в огромном объеме данных.
5. Пользователь создает панель управления из набора визуализаций, сформированных ранее.
6. Этот процесс может повторяться на различных стадиях, пока пользователь не получит ответы на все свои вопросы касательно данных. В процессе он может увидеть более детальную картину по данным и сразу получить ответы на только что сформулированные вопросы, которые, возможно, изначально и не были поставлены.
Теперь, когда мы понимаем, как пользователь будет работать в Kibana, рассмотрим, из чего же состоит этот компонент. Как видно в левой части окна на рис. 7.3, пользовательский интерфейс Kibana состоит из следующих компонентов.
• Discover (Исследование). Эта страница помогает в исследовании данных, имеющихся в индексах ES. Она позволяет запрашивать данные, фильтровать их и анализировать структуру документов.
• Visualize (Визуализация). Страница предназначена для создания визуализаций. Вы можете найти различные варианты оформления: гистограммы, линейные диаграммы, карты, облака тегов и пр. Пользователь может подобрать необходимые визуализации для облегчения анализа данных.
• Dashboard (Панель управления). Здесь вы можете собрать несколько визуализаций на единую страницу.
• Timelion (Компонент Timelion). На этой странице можно визуализировать данные в виде временного ряда с помощью простого языка выражений. Кроме того, пользователь может комбинировать независимые источники данных (из разных индексов) в одной визуализации.
• Dev Tools (Инструменты разработчика). Содержит набор плагинов, каждый из которых имеет определенный функционал. По умолчанию эта страница включает только один плагин — Console (Консоль), который предоставляет пользовательский интерфейс для взаимодействия с REST API в Elasticsearch.
• Management (Управление). На этой странице выполняется настройка индексов и управление ими. Здесь также можно управлять уже существующими визуализациями, панелями управления, поисковыми запросами (удалять, экспортировать, импортировать).
Настройка шаблона индекса
Прежде чем вы сможете работать с данными и создавать визуализации для их анализа, требуется настроить шаблон индекса в Kibana. Такие шаблоны используются для идентификации индексов Elasticsearch, которые будут применяться для поиска и аналитики. Они также предназначены для настройки полей. Шаблон индекса представляет собой строку с возможными подстановочными символами, которые могут соответствовать различным индексам. Обычно в Elasticsearch существует два типа индексов.
• Временной индекс. Если между данными и меткой времени есть взаимосвязь, то такие данные называются данными временного ряда. Для них характерно наличие поля с меткой времени. Примером таких данных могут служить логи, метрики, данные твитов. В Elasticsearch эти сведения хранятся в различных индексах, названия которых обычно присваиваются по метке времени, например unixlogs-2017.10.10, tweets-2017.05, logstash-2017.08.10.
• Постоянные индексы. Если данные не имеют меток времени или не связаны с временем, они называются постоянными. Обычно такие данные хранятся в одном индексе, например данные отдела или каталога продуктов.
Рассмотрим экран Configure an Index Pattern (Настройки шаблона индекса). Если в индексе есть поле даты/времени (то есть это временной индекс), то будет виден пункт Time Filter field name (Название поля фильтра времени). Этот пункт позволяет выбрать корректное поле даты/времени. В ином случае поле невидимо.
Поскольку в предыдущем разделе мы уже загрузили данные, настроим их, чтобы иметь возможность использовать во всех примерах этой главы. В поле Index Name or Pattern (Название или шаблон индекса) введите logstash-*. Для Time Filter field name (Название поля фильтра) введите @timestamp и нажмите кнопку Create (Создать).
Вы должны увидеть следующую страницу (рис. 7.5).
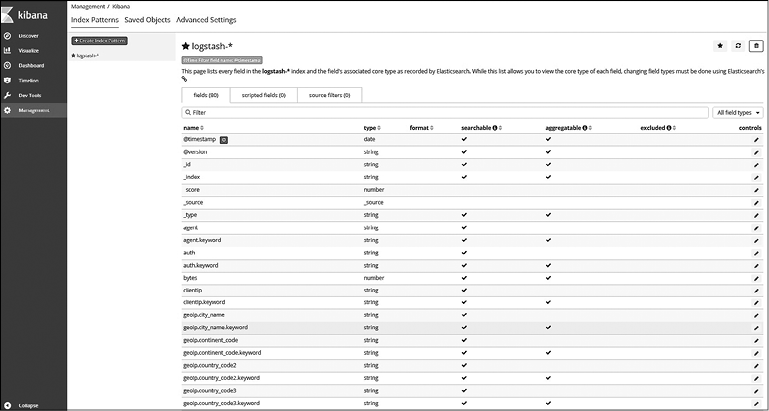
Рис. 7.5
Исследование
Страница Discover (Исследование) предназначена для интерактивного анализа данных. Вы можете выполнять запросы поиска, фильтрации, просматривать данные документов. Можно также сохранять поиск или критерии фильтрации для повторного использования или создания визуализаций на базе отфильтрованных результатов.
По умолчанию страница Discover (Исследование) показывает события за последние 15 мин. Укажите корректный диапазон даты в фильтре времени, так как мы загрузили данные за период с мая по июнь 2014 года. Перейдите на вкладку Time Filter—>Absolute Time Range (Фильтр времени—>Абсолютный диапазон времени) и установите следующие значения: в поле From (От) — 2014-05-28 00:00:00.000 и в поле To (До) — 2014-07-01 00:00:00.000 (рис. 7.6). Нажмите кнопку Go (Начать).
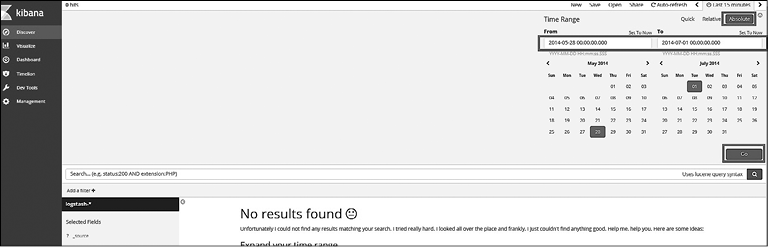
Рис. 7.6
Разделы страницы Discover (Исследование) вы можете увидеть на рис. 7.7.
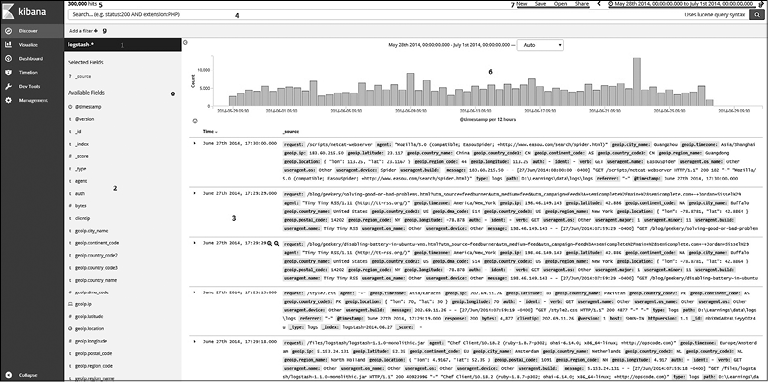
Рис. 7.7
Шаблон индекса (1), список полей (2), таблица документов (3), панель запросов (4), совпадения (5), гистограмма (6), панель инструментов (7), выбор времени (8) и фильтры (9).

Рис. 7.8
Рассмотрим каждый из них.
• Шаблон индекса. Здесь вы можете найти все настроенные шаблоны индекса, шаблон по умолчанию выбирается автоматически. Пользователю разрешается выбрать подходящий шаблон индекса для исследования данных.
• Список полей. Показаны все поля, которые являются частью документа. Если щелкнуть на поле Quick Count (Быстрый подсчет), вы получите общее количество документов в таблице документов, которые содержат определенное поле, топ-5 значений, а также процент документов, содержащих каждое значение (рис. 7.8).
• Таблица документов. Показаны актуальные данные документов. Таблица показывает последние 500 документов, соответствующих пользовательскому запросу/фильтрам, с сортировкой по метке времени (если поле существует). При нажатии кнопки Expand (Расширить) слева вы получаете возможность визуализации данных в формате таблицы или в формате JSON (рис. 7.9).
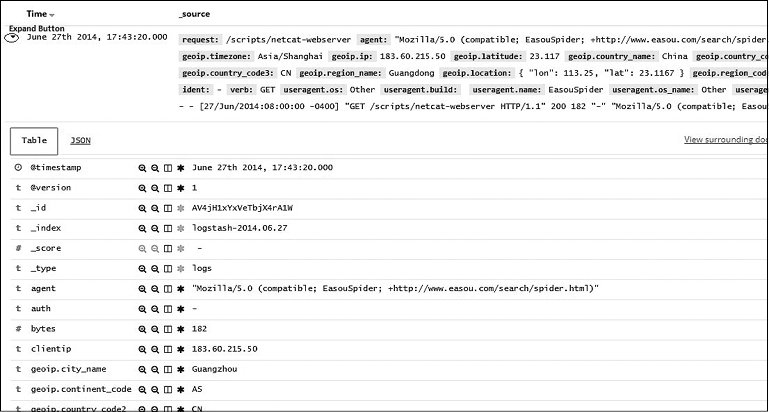
Рис. 7.9
В процессе исследования данных мы нередко больше заинтересованы в определенном наборе полей, чем в документе целиком. Чтобы добавить поля в таблицу документов, вам необходимо навести указатель мыши на поле или список полей, после чего нажать кнопку Add (Добавить). Или разверните документ и нажмите кнопку Toggle column in table (Настроить столбец в таблице) (рис. 7.10).
Рис. 7.10
Добавленное поле заменяет столбец _source в таблице документов. Вы можете изменять порядок для столбцов полей в таблице, нажимая стрелки влево или вправо, которые отображаются при наведении указателя мыши на название столбца. Аналогичным образом при нажатии кнопки удаления x вы можете удалять столбцы из таблицы (рис. 7.11).

Рис. 7.11
• Панель запросов. Используя панель запросов/панель поиска, пользователь может вводить запросы для фильтрации результатов. Запрос результатов поиска приводит к обновлению гистограммы (если для текущего шаблона индекса настроено поле времени), а также к обновлению таблицы документов, списков полей и совпадений, чтобы они соответствовали результатам поиска. Соответствующий поиску текст будет выделен в таблице документов. Для поиска по вашим данным введите поисковый запрос в поле запроса и нажмите Enter или щелкните на значке поиска.
Панель запросов принимает два вида запросов.
• Строковый запрос в Elasticsearch, который создается на базе синтаксиса запроса Lucene: https://lucene.apache.org/core/2_9_4/queryparsersyntax.html.
• Полный запрос DSL JSON в Elasticsearch: https://www.elastic.co/guide/en/elasticsearch/reference/5.5/query-dsl.html.
Детально рассмотрим оба варианта.
Строковый запрос в Elasticsearch
Предоставляет возможность выполнять разные типы поиска: от простого до сложного запросов, придерживающихся синтаксиса запроса Lucene. Рассмотрим несколько примеров.
Общий текстовый поиск. Для поиска текста по любому из полей попросту введите текстовую строку в поле запроса (рис. 7.12).
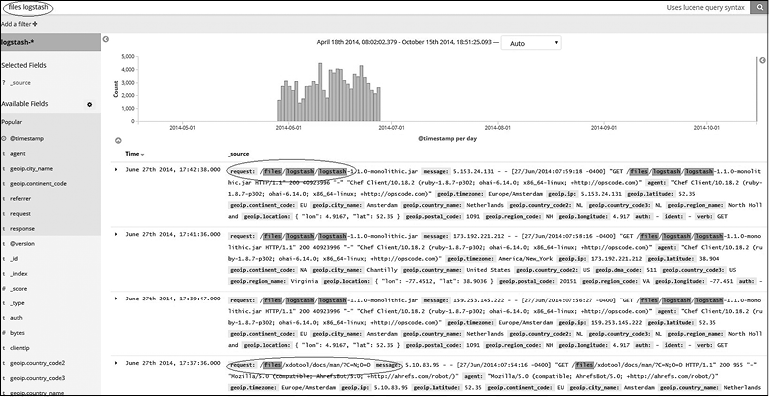
Рис. 7.12
Когда вы вводите несколько слов для поиска, в результаты включаются все документы, которые содержат хотя бы одно слово из искомых, или все слова в любом порядке.
Если вы хотите найти конкретную фразу, то есть найденные документы должны содержать все указанные слова в указанном порядке, то введите фразу в кавычках, например "file logstash" или "files logstash".
Поиск по полю. Для поиска по значениям в определенных полях используйте поле syntax: value (рис. 7.13).
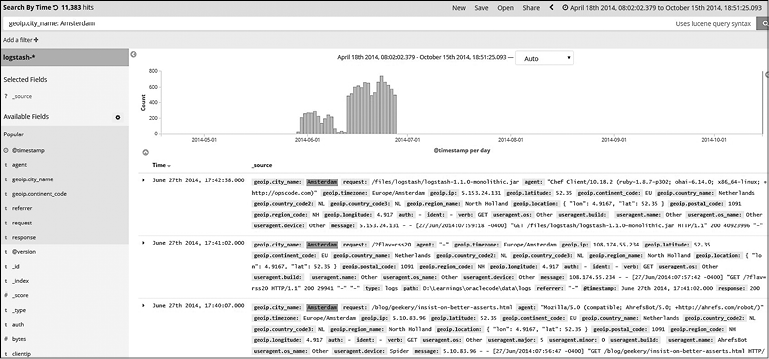
Рис. 7.13
Булев поиск. Возможно применять булевы операторы, такие как AND, OR и - (Must Not Match) для создания сложных запросов. Используя булевы операторы, можно комбинировать поля: value и обычный текст (рис. 7.14).

Имейте в виду, что операторы AND и OR чувствительны к регистру.
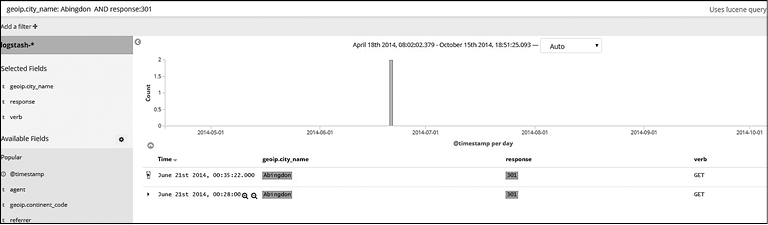
Рис. 7.14
Соответствие Must Not. Далее вы можете увидеть пример применения оператора Must Not с полем (рис. 7.15).
Далее вы можете увидеть пример использования оператора Must Not с обычным текстом (рис. 7.16).

Между оператором - и поисковым текстом/полем не должно быть пробела.
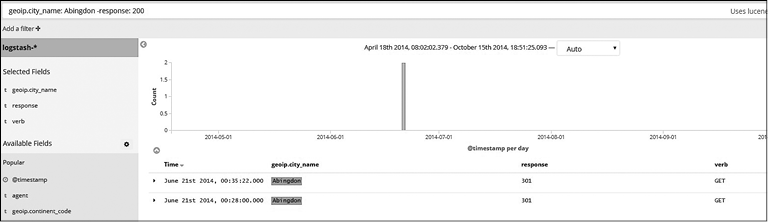
Рис. 7.15
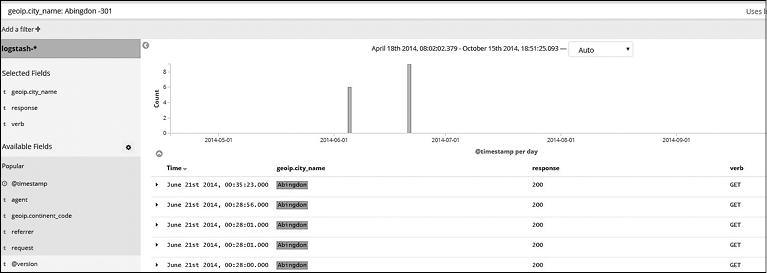
Рис. 7.16
Групповой поиск. Когда мы хотим создать сложный запрос, зачастую приходится группировать критерии поиска. Поддерживается группирование и по полю, и по значению, как можно увидеть на примере ниже (рис. 7.17).
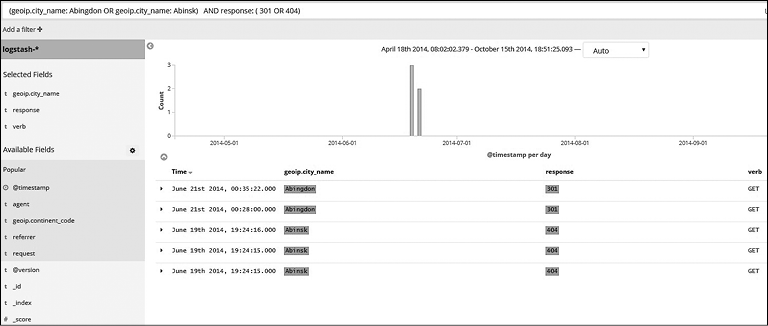
Рис. 7.17
Поиск диапазона. Позволяет искать среди диапазона значений. Включающие диапазоны указываются в квадратных скобках, например [START_VALUE TO END_VALUE], а исключающие диапазоны — в фигурных, например { START _VALUE TO END_VALUE }. Вы можете указать диапазоны для дат, числовых или строковых полей (рис. 7.18).
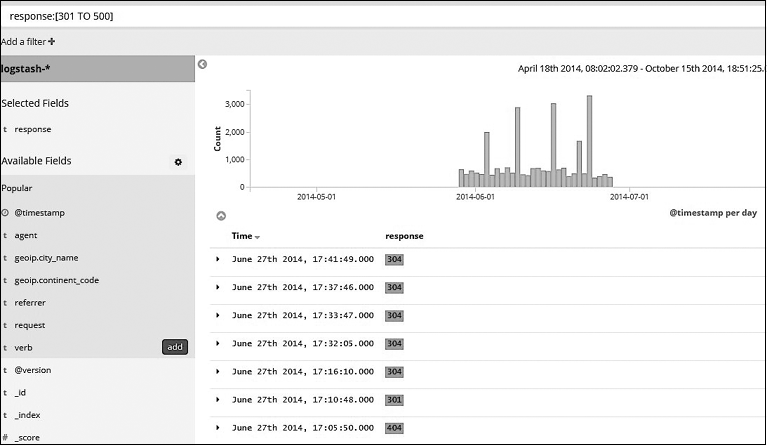
Рис. 7.18

Оператор TO чувствителен к регистру; его значения диапазона должны быть числовыми.
Поиск подстановочного символа и регулярного выражения. Вы можете выполнять запросы, используя символы * и ? с поисковым текстом. Символ * определяет «ни одного соответствия или несколько», а ? задает «ни одного соответствия или одно» (рис. 7.19).

Поиск с подстановочным символом может быть требователен к ресурсам. Всегда рекомендуется добавлять подстановочный символ как суффикс, а не как префикс к поисковому тексту.
По аналогии поддерживаются и regex-запросы. Вы можете указывать шаблоны regex, используя слеш (/) и квадратные скобки ([]). Имейте в виду, что regex-запросы также крайне требовательны к вычислительной мощности.
Например, найдем любые города, которые начинаются с букв g, b или а (рис. 7.20).
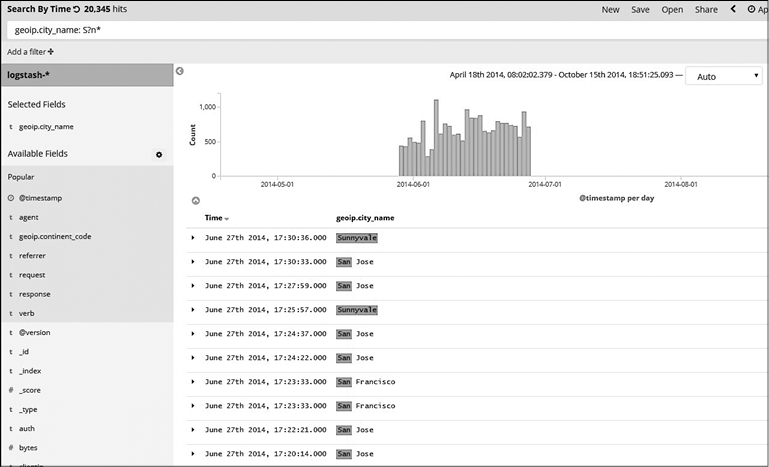
Рис. 7.19
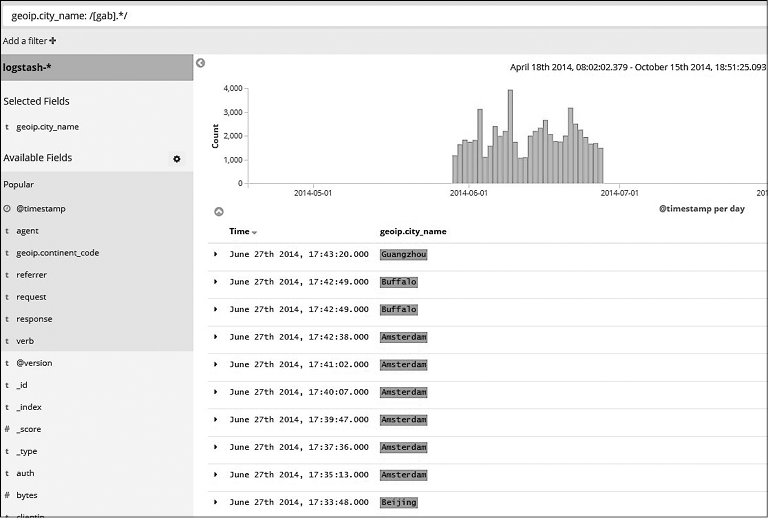
Рис. 7.20
Запрос DSL в Elasticsearch
С помощью запроса DSL можно выполнять запросы напрямую c панели запросов. Его также можно применять для поиска.
На рис. 7.21 вы можете увидеть пример поиска документов, которые имеют значение IE в useragent.name и значение Washington в поле geoip.region_name.
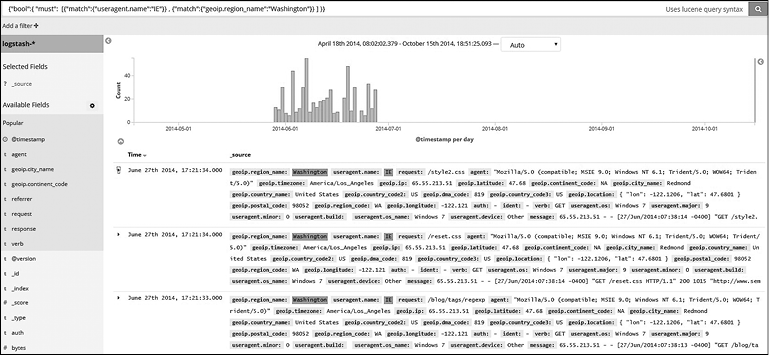
Рис. 7.21
Совпадения. Обозначает общее количество документов, которые соответствуют запросу/критерию, введенному пользователем.
Гистограмма. Этот раздел доступен только при настроенном поле времени для выбранного шаблона индекса. Вы можете увидеть распределение документов по времени с помощью гистограммы. По умолчанию лучший интервал времени для создания гистограммы рассчитывается на основе данных, установленных в фильтре времени. Но вы можете определить другое значение интервала в соответствующем раскрывающемся меню (рис. 7.22).

Рис. 7.22
Во время исследования данных пользователь может «разрезать» гистограмму на секторы и фильтровать результаты поиска. При наведении указателя мыши на гистограмму он меняет изображение на +. Нажав и удерживая кнопку мыши, пользователь может нарисовать прямоугольную область для исследования/фильтрации документов, которые попадают в выбранные интервалы.

После «нарезки» гистограммы интервал/период времени меняется. Для возврата нажмите в браузере кнопку Back (Назад).
Панель инструментов. Введенные пользователем поисковые запросы и примененные фильтры можно сохранить для повторного использования в дальнейшем или для создания визуализаций на базе отфильтрованных результатов поиска. Панель инструментов предоставляет такие функции, как сохранение, повторное использование и распределение поисковых запросов. Пользователь может вернуться к сохраненному поисковому запросу и изменить его, после чего перезаписать существующий поиск или сохранить результат в виде нового поиска (установив флажок Save as new search (Сохранить как новый поиск) в окне Save (Сохранить)).
Создадим новый поиск, базируясь на существующем сохраненном поиске (рис. 7.23).

Рис. 7.23
После нажатия кнопки Open (Открыть) мы видим Saved Searches (Сохраненные поиски) (рис. 7.24).

Рис. 7.24
В Kibana состояние текущей страницы/пользовательского интерфейса сохраняется в самой ссылке URL — так ею проще делиться. Нажатие кнопки Share (Поделиться) позволяет вам поделиться сохраненным поиском (рис. 7.25).

Рис. 7.25
Выбор времени. Этот раздел доступен только при настроенном поле времени для выбранного шаблона индекса. Фильтр времени ограничивает результаты поиска по определенному периоду времени, тем самым помогая анализировать данные, которые принадлежат к интересующему вас периоду времени. Если открыта страница Discover (Исследование), фильтр времени по умолчанию настроен на последние 15 мин.
Для выбора периодов времени фильтр времени предоставляет следующие параметры (отображаются при щелчке на Time Filter (Фильтр времени)).
• Быстрый фильтр времени. Задает быструю фильтрацию с использованием предустановленных диапазонов времени (рис. 7.26).
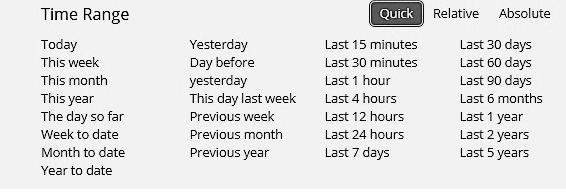
Рис. 7.26
• Относительный фильтр времени. Помогает выполнять фильтрацию на базе относительного времени, то есть относительно текущего времени. Относительное время может быть в прошлом или будущем. Для округления времени предусмотрен соответствующий флажок (рис. 7.27).
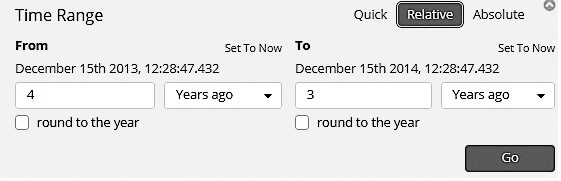
Рис. 7.27
• Абсолютный фильтр времени. Позволяет вам фильтровать данные с ориентацией на введенное начальное и конечное время (рис. 7.28).
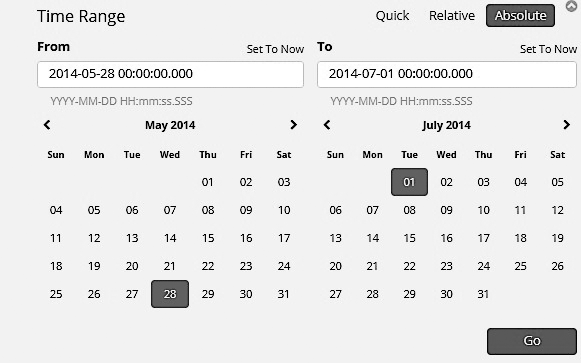
Рис. 7.28
• Автоматическое обновление. Во время анализа в реальном режиме времени данные генерируются постоянно. Потому пригодится возможность автоматически считывать актуальные данные. Именно для этого служит автоматическое обновление. По умолчанию интервал обновления не определен. Вы можете самостоятельно выбрать необходимый для вашего анализа интервал (рис. 7.29).

Рис. 7.29

Фильтр времени доступен на страницах Discover (Исследование), Visualize (Визуализация) и Dashboard (Панель управления). Диапазон времени, который выбирается/устанавливается на этих страницах, может быть перенесен и на другие страницы.
Фильтр времени есть даже на странице Timelion (Компонент Timelion), однако он не зависит от настроек времени на других страницах.
• Фильтры. Используя положительные (positive) фильтры, можно оптимизировать результаты поиска так, чтобы отображались только те документы, которые содержат в поле определенное значение. Допускается также создавать отрицательные (negative) фильтры, которые будут исключать документы, содержащие определенное значение поля.
Вы можете добавлять фильтры на страницах Fields List (Список полей) или Documents Table (Таблица документов), в том числе вручную. На странице Documents Table (Таблица документов) можно также фильтровать документы по наличию или отсутствию поля.
Для добавления положительного или отрицательного фильтра перейдите на страницу Fields List (Список полей) или Documents Table (Таблица документов) и щелкните на значке + или – соответственно. Аналогичным образом для фильтрации по наличию или отсутствию поля щелкните на значке * (фильтр наличия) (рис. 7.30).
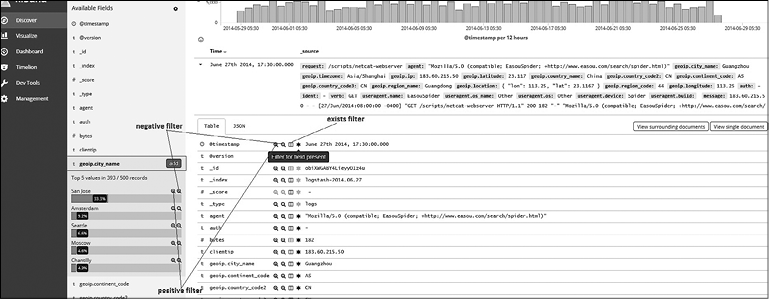
Рис. 7.30
Для добавления фильтров вручную нажмите кнопку Add a Filter (Добавить фильтр), которая расположена ниже на панели запроса. Это приведет к появлению всплывающего окна, в котором вы можете выбрать и применить фильтры, нажав кнопку Save (Сохранить) (рис. 7.31).
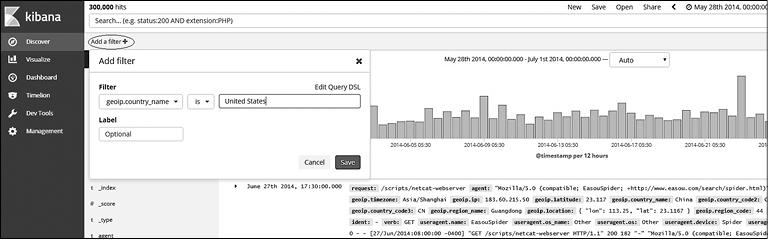
Рис. 7.31
Примененные фильтры показаны на панели запроса на рис. 7.32. Отрицательные фильтры будут выделены красным. Вы можете добавить несколько фильтров и применить к ним следующие действия.
• Enable/Disable Filter (Включение/выключение фильтра). Эта кнопка позволяет активизировать или деактивизировать фильтр без его удаления. Диагональные линии указывают на то, что фильтр выключен.
• Pin Filter (Закрепить фильтр). Закрепляет фильтр. Такие фильтры сохраняются при изменении контекстов в Kibana. Например, вы можете закрепить фильтр на странице Discovery (Исследование), и он останется на том же месте, когда вы переключитесь на страницу Visualize (Визуализация) или Dashboard (Панель управления).
• Toggle Filter (Настроить фильтр). Позволяет переключаться между положительным и отрицательным фильтром и наоборот.
• Remove Filter (Удалить фильтр). Дает возможность удалить примененный фильтр.
• Edit Filter (Редактировать фильтр). Позволяет редактировать примененный фильтр.
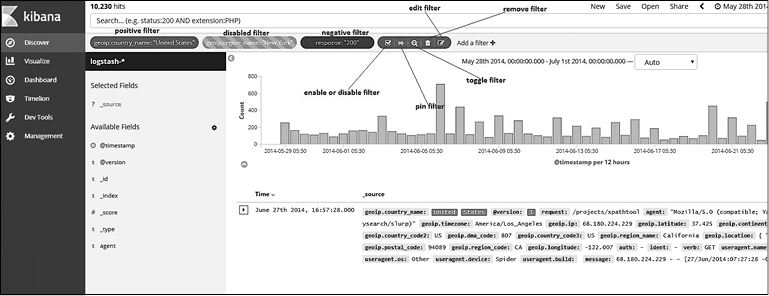
Рис. 7.32
Визуализация
Страница Visualize (Визуализация) служит для создания визуализаций в виде графиков, таблиц и диаграмм, благодаря чему можно легко визуализировать все данные, которые хранятся в Elasticsearch. Создавая визуализации, пользователь легко может увидеть свои данные со стороны, а также получить ответы на вопросы, которые могут возникнуть в процессе исследования. Уже созданные визуализации допускается сохранять и применять для создания панелей управления.
В случае с логами Apache пользователь сможет легко найти ответы на некоторые типичные вопросы, связанные с анализом логов.
• Как различается трафик в разных регионах мира?
• Какие ссылки запрашивают чаще всего?
• С каких IP-адресов чаще всего запрашивают ссылки?
• Как различается нагрузка сети в разное время?
• Есть ли подозрительные или мошеннические действия с каких-либо IP-адресов или регионов?
Все визуализации в Kibana основаны на запросах агрегации в Elasticsearch. Агрегации предоставляют группирование многомерных результатов. Например, можно найти самые распространенные браузеры по устройствам и по странам. В Kibana представлен широкий ассортимент визуализаций (рис. 7.33).
Рис. 7.33
Агрегации Kibana
Kibana поддерживает два типа агрегаций:
• сегментарные;
• метрические.
Поскольку для понимания принципа создания визуализаций важно разбираться в агрегациях, рассмотрим их до того, как приступать к визуализациям.
Сегментарные агрегации. Сегментированием называется группирование документов согласно общим критериям. Сегментирование работает аналогично запросу GROUP BY в SQL. В зависимости от типа агрегации каждый сегмент ассоциирован с критериями, которые определяют, соответствует ли данный документ выбранному сегменту. Для каждого сегмента доступна информация об общем количестве документов в нем.
Сегментарные агрегации могут применяться для следующих целей.
• Учет документов сотрудников в рамках соответствующего индекса.
• Поиск среди сотрудников в зависимости от их возраста или места работы.
• Поиск в индексах логов Apache вхождений ответов 404 в зависимости от страны.
Сегментарные агрегации поддерживают субагрегации, то есть при наличии сегмента все документы в нем могут и далее сегментироваться (группироваться по критериям). Пример: найти вхождения ответов 404 в зависимости от страны или штата.
В зависимости от типа сегментарной агрегации одни указывают единый сегмент, другие — фиксированное количество сегментов, третьи динамически создают сегменты в процессе агрегации.
Сегментарные агрегации могут быть совмещены с метрическими, например для поиска среднего возраста сотрудников в каждой возрастной группе.
Kibana поддерживает следующие типы сегментарных агрегаций.
• Гистограмма. Это тип агрегации гистограммы, который работает только с числовыми полями. Имея значение числового поля и интервал, агрегация разделяет их на сегменты фиксированного размера. Например, гистограмма может быть использована для поиска продуктов в определенном диапазоне цен с интервалом 100.
• Гистограмма даты. Это тип агрегации гистограммы, который работает только с полями даты. Принцип работы заключается в разделении их на сегменты фиксированного размера. Поддерживаются интервалы, основанные на дате или времени: два часа, два дня, две недели и т.д. Kibana предоставляет различные удобные интервалы, включая автоматический выбор, миллисекунды, секунды, минуты, часы, дни, недели, месяцы, годы и пользовательские настройки. Используя опцию Custom (Пользовательский), можно устанавливать ориентированные на дату/время интервалы. Данная гистограмма идеально подходит для анализирования данных временного ряда, например, когда нужно найти общее количество входящих веб-запросов за неделю/день.
• Диапазон. Работает по аналогии с агрегациями гистограммы, однако вместо фиксированных интервалов указываются диапазоны. Возможна работа не только с числами, но и с датами и IP-адресами. Вы можете указывать несколько диапазонов, используя значения from и to. Например, агрегацию можно использовать для поиска количества сотрудников, которые попадают под возрастные диапазоны 0–25, 25–35, 35–50 и 50 лет и старше.
• Условия. Эта агрегация группирует документы, базируясь на каждом уникальном условии в поле. Она идеальна для поиска n значений, например поиска топ-5 стран на основе количества входящих веб-запросов.

Эта агрегация работает только с полями keyword.
• Фильтры. Агрегация используется для создания сегментов на основе условия фильтра. Она позволяет сравнивать определенные значения. Пример: поиск среднего количества веб-запросов в Индии по сравнению с США.
• Сетка GeoHash. Эта агрегация работает с полями, содержащими значения geo_point. В процессе работы поля geo_point группируются в сегменты и отображаются на карте. Пример: визуализация трафика веб-запросов по разным регионам.
• Метрика. Используется для вычисления метрик на основе значений, извлеченных из полей документов. Метрики применяются в связке с сегментами. Доступны следующие метрики.
• Подсчет. Метрика по умолчанию в визуализациях Kibana, показывает количество документов.
• Среднее число. Используется для подсчета среднего значения (для поля) для всех документов в сегменте.
• Сумма. Применяется для подсчета суммы значений (для поля) для всех документов в сегменте.
• Медиана. Предназначена для подсчета медианы значений (для поля) для всех документов в сегменте.
• Минимум. Используется для подсчета минимального значения (для поля) для всех документов в сегменте.
• Максимум. Применяется для подсчета максимального значения (для поля) для всех документов в сегменте.
• Стандартное отклонение. Предназначена для подсчета стандартного отклонения значений (для поля) для всех документов в сегменте.
• Процентиль. Используется для подсчета процентиля значений (для поля) для всех документов в сегменте.
• Ранг процентиля. Используется в отношении набора процентилей для вычисления подобных значений.
Создание визуализации
Выполните следующие шаги для создания визуализаций.
1. Перейдите на страницу Visualize (Визуализировать) и нажмите кнопку Create a new Visualization (Создать новую визуализацию) или кнопку +.
2. Выберите тип визуализации.
3. Выберите источник данных.
4. Создайте визуализацию.
Интерфейс визуализации выглядит следующим образом (рис. 7.34).
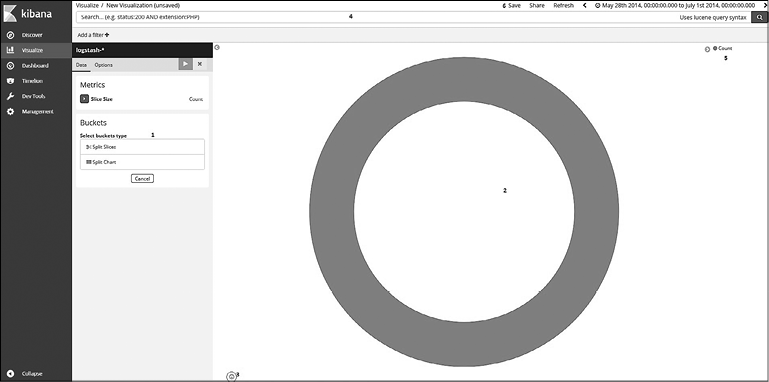
Рис. 7.34
Ниже перечислены компоненты интерфейса визуализации, которые показаны на рис. 7.34.
• Дизайн визуализаций. Используется для выбора подходящих метрик и сегментов для создания визуализаций.
• Предпросмотр визуализаций. В зависимости от выбранных метрик, сегментов, запросов, фильтров и времени визуализация динамически меняется.
• Панель шпиона. Позволяет исследовать необработанные запросы Elasticsearch, ответы, табличные данные и статистику запросов HTTP.
• Панель запроса/Фильтры полей. Применяется для фильтрации результатов поиска.
• Метка. Показывает тип метрики и ключи сегментов как метки. Цвета визуализации можно изменить; для этого нажмите кнопку Label (Метка) и выберите цвет на палитре.
• Панель инструментов/Фильтр времени. Предоставляет возможность сохранять визуализации и делиться ими. Кроме того, с помощью фильтра времени пользователь может ограничить время для фильтрации результатов поиска.

Фильтры времени, панель запросов и фильтры полей рассматривались в разделе «Исследование» ранее.
Типы визуализаций
Рассмотрим каждый тип визуализаций детально.
Линейные диаграммы, гистограммы, диаграммы областей
Эти диаграммы используются для визуализации распределенных данных путем сопоставления их осям Х/Y. Их также можно задействовать для визуализации данных временного ряда и анализа полей. Гистограммы и диаграммы областей полезны для визуализации суммированных данных (когда используются субагрегации).
В версии Kibana 5.5 и новее предоставляется возможность динамически менять тип диаграммы. Иначе говоря, можно начать с диаграммы, но в процессе изменить тип на гистограмму или область. Тем самым достигается гибкость при выборе подходящего для анализа типа визуализации.
Таблица данных
Используется для отображения агрегированных данных в формате таблицы. Полезна для анализа данных с высоким уровнем расхождения, которые будет трудно анализировать с помощью диаграмм. Например, таблицу данных удобно применять для нахождения топ-20 ссылок или топ-20 IP-адресов. Кроме того, она помогает идентифицировать топ-n агрегаций.
Виджет MarkDown
Эта визуализация используется для создания форматированного текста, содержащего общую информацию, комментарии и инструкции, имеющие отношение к панели управления. Данный виджет принимает текст GitHub Markdown (более детально описан по ссылке https://help.github.com/categories/writing-on-github/).
Метрика
Метрические агрегации работают только с числовыми полями и отображают единое числовое значение для выбранных агрегаций.
Цель
Цель — метрическая агрегация, предоставляющая визуализации, демонстрирующие, как метрика достигает указанной цели. Это новый тип визуализации, представленный в Kibana 5.5.
Шкала
Шкала — метрическая агрегация, предоставляющая визуализации для отображения того, как метрические значения относятся к предустановленному порогу/диапазону. Например, такая визуализация может использоваться для демонстрации того, находится ли нагрузка на сервер в допустимом диапазоне, или же она достигла критического значения. Это новый тип визуализации, представленный в Kibana 5.5.
Круговые диаграммы
Эта визуализация применяется для отображения части относительно целого. В визуализации части показаны как сегменты.
Карты координат
Визуализация предназначена для отображения географических данных на карте в зависимости от сегментов/агрегаций. Чтобы можно было использовать эту агрегацию, документы должны иметь поля типа geo_point. Будет использована агрегация сетки GeoHash, точки будут сгруппированы в сегменты, которые представляют клетки на карте. Ранее эта визуализация называлась плиточной картой (tile map).
Карты регионов
Карты регионов — это тематические карты, в которых векторы границ подсвечены градиентом; более интенсивные цвета показывают высокие значения, а менее интенсивные — низкие. Известны под названием картограмм или хороплетов (https://ru.wikipedia.org/wiki/Фоновая_картограмма). По умолчанию Kibana предлагает два векторных слоя: один для стран мира и один — для США. Это новый тип визуализации, представленный в Kibana 5.5.
Облако тегов
Облако тегов — визуальное отображение текстовых данных, которое обычно используется для визуализации текста свободной формы. Теги — это чаще всего единичные слова; важность каждого слова определяется размером или цветом шрифта. Размер шрифта задается метрической агрегацией. Например, если применяется метрика подсчета, то самое популярное слово имеет наибольший размер шрифта, а самое редкое — наименьший.
Визуализации в деле
Рассмотрим, как различные визуализации могут помочь решить следующие задачи.
• Анализ кодов ответов по времени.
• Поиск топ-10 запрошенных ссылок.
• Анализ использования сетевого трафика для каждой из топ-5 стран по времени.
• Поиск наиболее распространенного пользовательского агента.
• Анализ веб-трафика из различных стран.

Поскольку у нас в наличии лог-события за период с мая по июнь 2014 года, установите соответствующий диапазон дат в фильтре времени. Перейдите в меню Time Filter—>Absolute Time Range (Фильтр времени—>Абсолютный диапазон времени) и укажите в поле From (От) значение 2014-05-28 00:00:00.000 и в поле To (До) — 2014-07-01 00:00:00.000. Нажмите кнопку Go (Начать).
Анализ кодов ответов по времени
Данная визуализация может быть создана в виде гистограммы.
Создайте новую визуализацию.
1. Нажмите кнопку New (Создать) и выберите Vertical Bar (Гистограмма).
2. Выберите Logstash-* в поле From a New Search, Select Index (Из нового поиска, выбрать индекс).
3. На оси Х выберите Date Histogram (Гистограмма даты) и значение @timestamp.
4. Нажмите кнопку Add sub-buckets (Добавить субсегменты) и выберите Split Series (Раздельная серия).
5. Выберите Terms (Термы) в поле Sub Aggregation (Субагрегация).
6. Выберите response.keyword в Field (Поле).
7. Нажмите кнопку Play (Воспроизвести) (применив изменения).
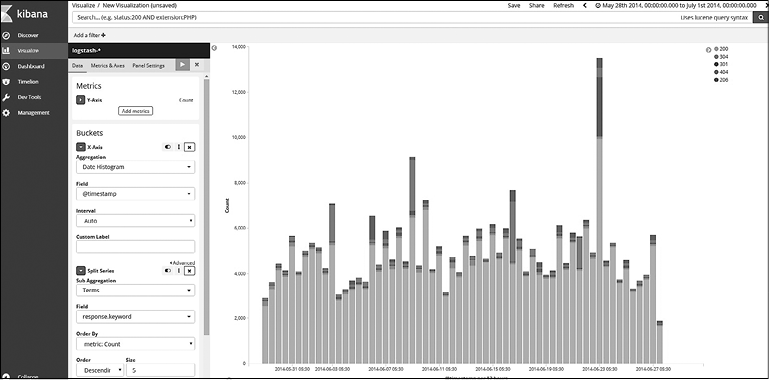
Рис. 7.35
Сохраните визуализацию под названием «Анализ кодов ответов по времени».
Как можно видеть на рис. 7.35, в некоторые дни, например 9, 16 июня и т.д., часто выдается ошибка 404. Теперь для анализа событий 404 щелкните на значении 404 на панели меток/ключей и далее выберите positive filter (положительный фильтр) (рис. 7.36).

Рис. 7.36
В результате вы получите диаграмму следующего вида (рис. 7.37).
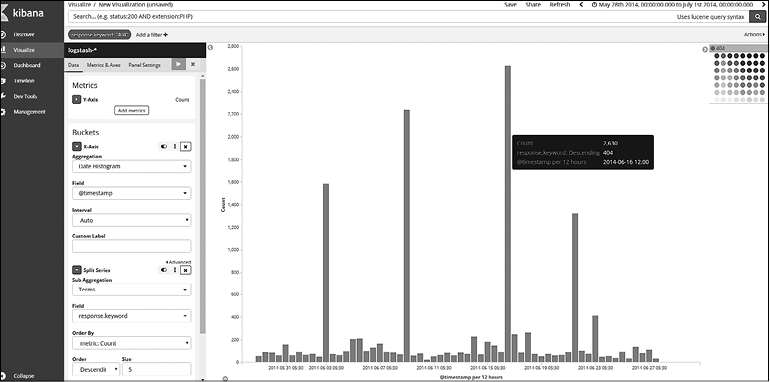
Рис. 7.37

Вы можете развернуть метки/ключи и выбрать цвета на палитре, тем самым изменив цветовое оформление визуализации. Закрепите фильтр и перейдите на страницу Discover (Исследование), чтобы увидеть запросы, которые приводят к ошибке 404.
Поиск топ-10 запрошенных ссылок
Для этого удобно использовать визуализацию в виде таблицы данных (рис. 7.38).
Выполните следующие шаги.
1. Создайте новую визуализацию.
2. Нажмите кнопку New (Создать) и выберите Data Table (Таблица данных).
3. Выберите Logstash-* в поле From a New Search, Select Index (Из нового поиска, выбрать индекс).
4. Выберите тип сегментов Split Rows (Разделенные строки).
5. Выберите в поле Aggregation (Агрегация) значение Terms (Термы).
6. Выберите response.keyword в Field (Поле).
7. Установите размер 10.
8. Нажмите кнопку Play (Воспроизвести) (применив изменения).
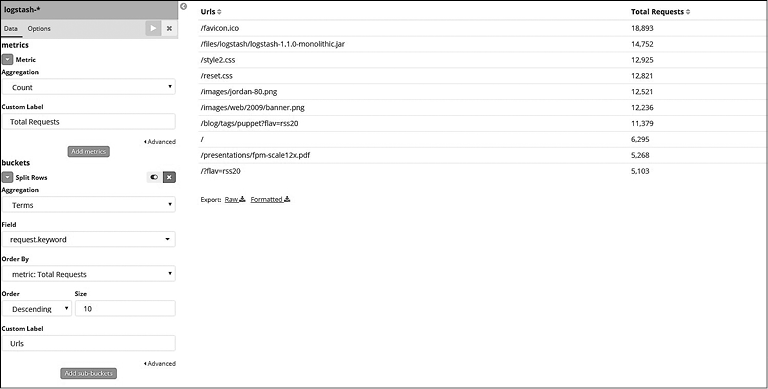
Рис. 7.38
Сохраните визуализацию под названием «Поиск топ-10 запрошенных ссылок».

Для получения осмысленных названий в результатах агрегации можно использовать поля Custom Label (Пользовательские метки). Большинство визуализаций поддерживают такие поля. Визуализацию в виде таблицы данных можно экспортировать как файл .csv, щелкнув на ссылках Raw (Необработанный) или Formatted (Форматированный), которые находятся под визуализацией.
Анализ использования сетевого трафика для каждой из топ-5 стран по времени
Выполните следующие шаги.
1. Создайте новую визуализацию (рис. 7.39).
2. Нажмите кнопку New (Создать) и выберите Area Chart (Диаграмма области).
3. Выберите Logstash-* в поле From a New Search, Select Index (Из нового поиска, выбрать индекс).
4. На оси Y (Y axis) выберите Sum (Сумма) в качестве типа агрегации и bytes (байты) как поле.
5. На оси Х (X axis) выберите Date Histogram (Гистограмма даты) и @timestamp в Field (Поле).
6. Нажмите кнопку Add sub-buckets (Добавить субсегменты) и выберите Split Series (Раздельная серия).
7. Выберите Terms (Термы) в поле Sub Aggregation (Субагрегация).
8. Выберите geoip.country_name.keyword в Field (Поле).
9. Нажмите кнопку Play (Воспроизвести) (применив изменения).
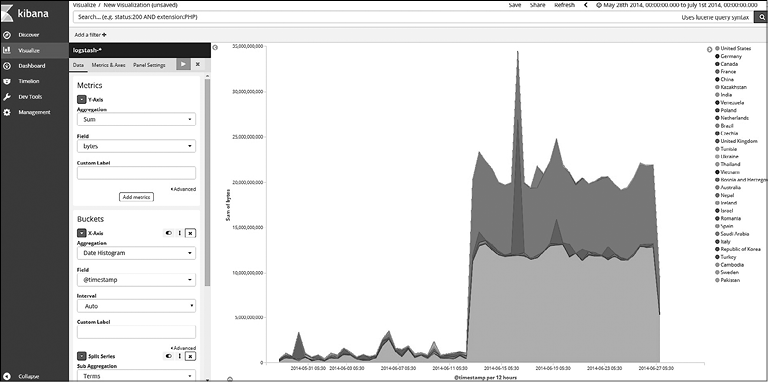
Рис. 7.39
Сохраните визуализацию под названием «Анализ использования сетевого трафика для каждой из топ-5 стран».
Что, если нужно найти не только первую пятерку стран? Перестройте порядок агрегаций и нажмите Play (Воспроизвести) (рис. 7.40).
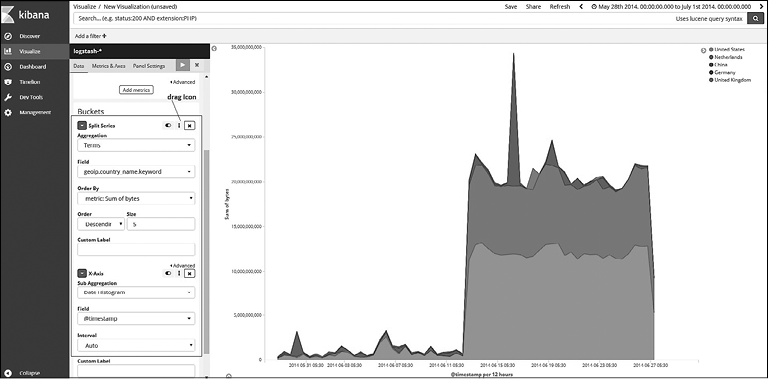
Рис. 7.40

Порядок агрегаций имеет значение.
Анализ веб-трафика из различных стран
Нужные данные можно легко визуализировать с помощью карты координат.
Выполните следующие шаги.
1. Создайте новую визуализацию (рис. 7.41).
2. Нажмите кнопку New (Создать) и выберите Coordinate Map (Карта координат).
3. Выберите Logstash-* в поле From a New Search, Select Index (Из нового поиска, выбрать индекс).
4. Выберите тип сегментов Geo Coordinates (Геокоординаты).
5. Выберите агрегацию Geohash.
6. Выберите поле geoip.location.
7. На вкладке параметров выберите в поле Map Type (Тип карты) значение Heatmap (Карта температур).
8. Нажмите кнопку Play (Воспроизвести) (применив изменения).
Сохраните визуализацию как «Анализ веб-трафика из различных стран». Согласно этой визуализации, наибольшая часть трафика происходит из Калифорнии.
Для той же визуализации при измерении в байтах результат изменится следующим образом (рис. 7.42).
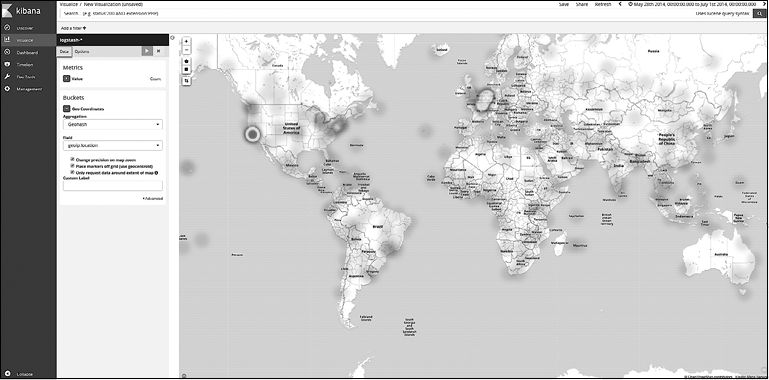
Рис. 7.41
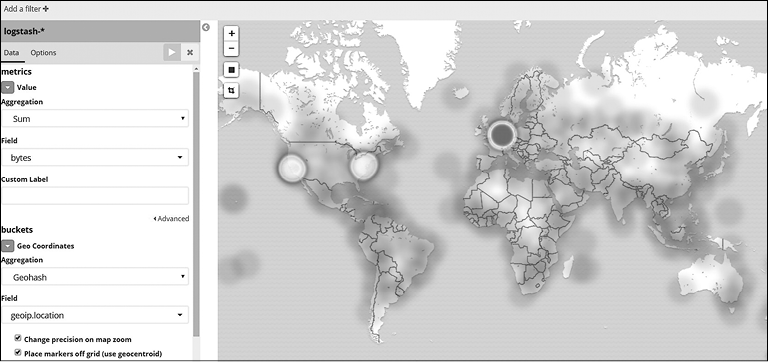
Рис. 7.42

Для изменения масштаба карты вы можете нажимать кнопки +/–, расположенные слева вверху от карты.
Для выбора области фильтрации документов можно нажать кнопку Draw Rectangle (Начертить прямоугольник), которая находится слева вверху, под кнопками изменения масштаба карты. После этого вы можете закрепить фильтр и перейти на страницу Discover (Исследование) для рассмотрения документов, принадлежащих выбранной области.
Поиск наиболее популярного пользовательского агента
Нужные данные можно легко визуализировать с помощью разных диаграмм. Выберем облако тегов.
Выполните следующие шаги.
1. Создайте новую визуализацию (рис. 7.43).
2. Нажмите кнопку New (Создать) и выберите Tag Cloud (Облако тегов).
3. Выберите Logstash-* в поле From a New Search, Select Index (Из нового поиска, выбрать индекс).
4. Выберите тип сегментов Tags (Теги).
5. Выберите Terms (Термы) в поле Aggregation (Агрегация).
6. Выберите поле useragent.name.keyword.
7. Установите размер 10 и нажмите кнопку Play (Воспроизвести) (применив изменения).
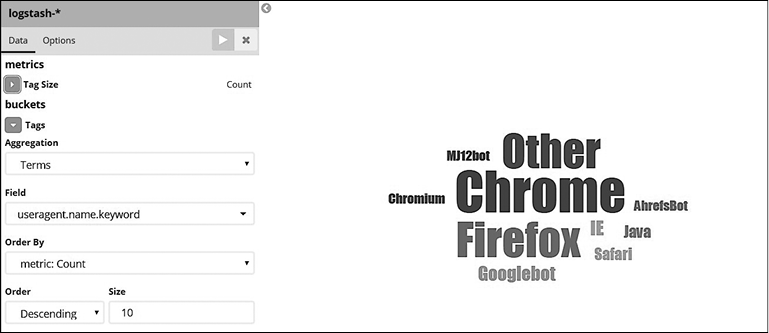
Рис. 7.43
Сохраните визуализацию под названием «Поиск наиболее популярного пользовательского агента». В списке пользовательских агентов для наших данных трафика самым популярным является Chrome, после него — Firefox.
Панели управления
Панели управления помогают собирать разные визуализации на одной странице. Вы можете настроить панель управления, используя ранее сохраненные визуализации и запросы.
Простая панель управления будет выглядеть следующим образом (рис. 7.44).
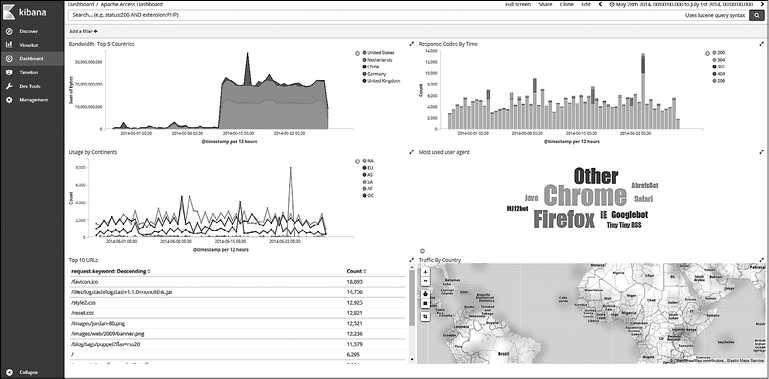
Рис. 7.44
Рассмотрим, как создать панель управления для нашего примера с анализом лог-данных.
Создание панели управления
Для создания новой панели управления перейдите на страницу Dashboard (Панель управления) и нажмите кнопку Create a dashboard (Создать панель управления) или + (рис. 7.45).
Рис. 7.45
На следующей странице вы можете нажать кнопку Add (Добавить) (рис. 7.46), после чего получите список доступных сохраненных визуализаций и результатов поиска, которые доступны для добавления. Щелчок на сохраненных результатах/визуализациях приведет к добавлению их на страницу (рис. 7.47).
Рис. 7.46
Рис. 7.47

Рис. 7.48
Есть возможность разворачивать, редактировать визуализации, менять их порядок или удалять, используя кнопки, размещенные в верхнем углу каждой визуализации (рис. 7.48).

Используя панель запросов, фильтры полей и времени, вы можете фильтровать результаты поиска. Панель управления будет реагировать на эти изменения, если они касаются встроенных в нее визуализаций.
К примеру, возможно, вам необходимо знать только первые несколько значений пользовательских агентов и устройств по стране при условии, что код ответа — 404.
Более детально панель запросов, фильтры полей и времени рассматривались в разделе «Исследование» выше.
Сохранение панели управления
Как только все необходимые визуализации добавлены на панель управления, убедитесь в том, что вы ее сохранили. Для этого нажмите кнопку Save (Сохранить) на панели инструментов и введите название. При сохранении панели управления также сохраняются все критерии запроса и фильтры. Если вы хотите сохранить и фильтры времени, установите флажок Store time with dashboard (Сохранить время на панели управления). Это может быть полезным, если вы планируете в будущем вернуться к панели управления в ее текущем состоянии (рис. 7.49).
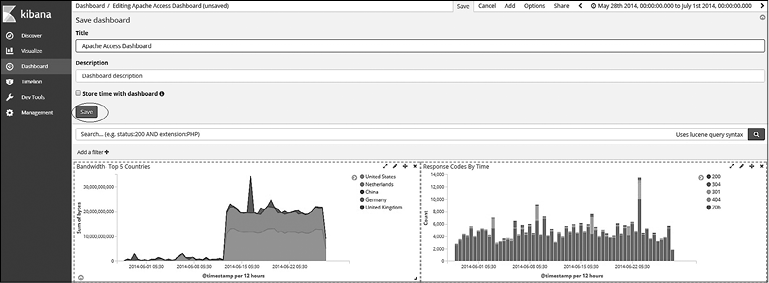
Рис. 7.49
Клонирование панели управления
Используя функцию клонирования, вы можете скопировать текущую панель управления вместе с ее запросами и фильтрами и создать новую. Например, вы можете создать новые панели управления для стран или континентов (рис. 7.50).
Рис. 7.50

Фоновое оформление панели управления может быть изменено со светлого на темное. При нажатии кнопки Edit (Редактировать) на панели инструментов вы увидите кнопку Options (Опции), которая и позволяет добавить эту возможность.
Общий доступ к панели управления
Используя функцию Share (Поделиться), вы можете отправить прямую ссылку на панель управления Kibana другому пользователю или встроить панель в веб-страницу в виде Iframe (рис. 7.51).
Рис. 7.51
Timelion
Timelion — инструмент визуализации для анализа временного ряда в Kibana. Он позволяет комбинировать абсолютно независимые визуализации в пределах одной. Используя простой язык выражений, вы можете выполнять сложные математические вычисления, такие как деление и вычитание метрик, расчет производных и скользящего среднего, а также визуализировать эти вычисления.
Пользовательский интерфейс Timelion
Timelion находится на левой панели пользовательского интерфейса Kibana, между значками разделов Dashboard (Панель управления) и Dev Tools (Инструменты разработчика) (рис. 7.52).
Рис. 7.52
Основной компонент пользовательского интерфейса Timelion — Timelion query bar (Панель запросов Timelion), которая позволяет определять выражения, влияющие на генерирование диаграмм. Вы можете задать несколько выражений, разделяя их запятыми, а также объединять функции в цепочку.
Пользовательский интерфейс Timelion также предлагает следующие функции.
• New (Создать). Используется с целью создания нового листа Timelion для формирования диаграмм.
• Add (Добавить). С помощью этой функции вы можете создать несколько диаграмм на одном листе Timelion.
• Save (Сохранить). Используется для сохранения страницы Timelion. Есть два варианта: сохранить как лист Timelion или сохранить текущее выражение как панель управления Kibana.
• Open (Открыть). Применяется для открытия существующего листа Timelion.
• Options (Опции). Здесь вы можете указать количество строк и столбцов в листе Timelion.
• Docs (Документы). Документация для начала работы с Timelion, а также документация обо всех поддерживаемых функциях выражений Timelion.
• Time Filter (Фильтр времени). Параметры фильтра времени для фильтрации данных.
Выражения Timelion
Простейшее выражение Timelion для создания диаграмм выглядит следующим образом:
.es(*)
Выражения Timelion всегда начинаются с точки, далее идет название функции, которая принимает один или несколько параметров. Выражение .es(*) запрашивает данные из всех индексов в Elasticsearch. По умолчанию количество документов будет подсчитано и показано на диаграмме с обзором по времени.
Если вы хотите ограничить работу Timelion с данными из определенного индекса (например, logstash-*), то можете указать индекс внутри функции следующим образом:
.es(index=logstash-*)
Поскольку Timelion является визуализатором временного ряда, он использует поле @timestamp, находящееся в индексе, как время для размещения данных на оси Х. Вы можете изменить это, подставив необходимое поле времени как значение параметра timefield.
В Timelion присутствует полезная функция автозавершения, которая поможет вам быстрее формировать выражения (рис. 7.53).

Рис. 7.53
Рассмотрим еще несколько примеров использования Timelion на практике.

Поскольку у нас в наличии лог-события за период с мая по июнь 2014 года, установите соответствующий диапазон дат в фильтре времени. Перейдите в меню Time Filter—>Absolute Time Range (Фильтр времени—>Абсолютный диапазон времени) и укажите в поле From (От) значение 2014-05-28 00:00:00.000 и в поле To (До) — 2014-07-01 00:00:00.000. Нажмите кнопку Go (Начать).
Найдем средний расход байтов в США по времени (рис. 7.54). Выражение будет выглядеть следующим образом:
.es(q='geoip.country_code3:US',metric='avg:bytes')
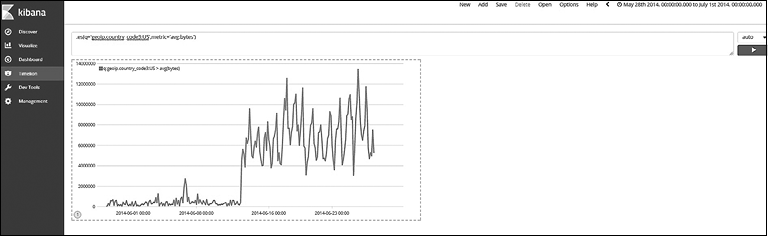
Рис. 7.54
Timelion позволяет размещать несколько диаграмм на одной странице. Для этого нужно разделить выражения запятыми.
Найдем средний расход байтов в США и Китае по времени (рис. 7.55). Выражение будет выглядеть следующим образом:
.es(q='geoip.country_code3:US',metric='avg:bytes'),
.es(q='geoip.country_code3:CN',metric='avg:bytes')
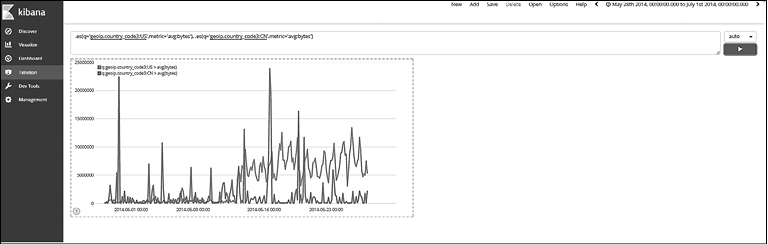
Рис. 7.55
Timelion также позволяет изменять функции. Изменим метку и цвет предыдущих диаграмм (рис. 7.56). Выражение будет выглядеть следующим образом:
.es(q='geoip.country_code3:US',metric='avg:bytes').label('United States').color('yellow'),
.es(q='geoip.country_code3:CN',metric='avg:bytes').label('China').color('red')
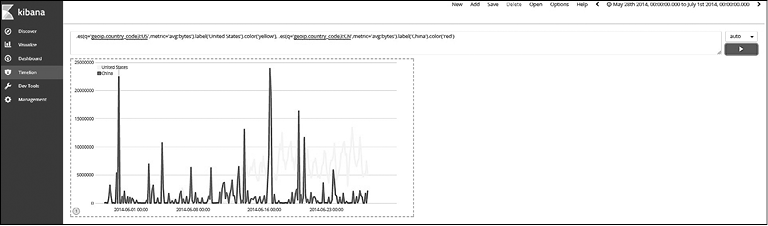
Рис. 7.56
Еще одной полезной функцией является использование смещений при анализе старых данных. Это полезно при сравнении текущих значений с более ранними для анализа динамики. Сравним сумму использования байтов с показателями за предыдущую неделю для США (рис. 7.57). Выражение будет выглядеть следующим образом:
.es(q='geoip.country_code3:US',metric='sum:bytes').label('Current Week'),
.es(q='geoip.country_code3:US',metric='sum:bytes',offset=-1w).label('Previous Week')

Предыдущий скриншот показывает возможность добавления нескольких диаграмм на один лист Timelion. Для этого необходимо нажать кнопку Add (Добавить). Выбор диаграмм изменяет ассоциированное выражение на панели запросов Timelion (Timelion Query Bar).
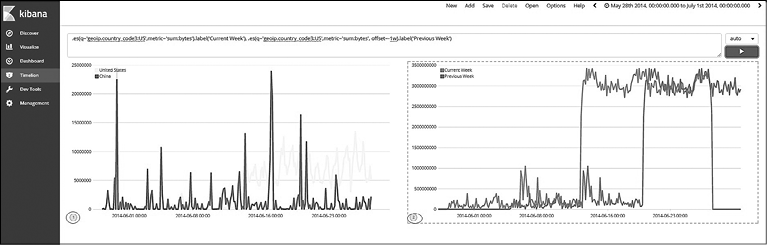
Рис. 7.57
В Timelion также поддерживается использование данных из внешних источников с помощью публичного API. В комплекте вы найдете родной API для получения данных Всемирного банка, Quandl и Graphite.

Выражения Timelion поддерживают более 50 различных функций, которые вы можете использовать для создания выражений (более детально читайте по ссылке https://github.com/elastic/timelion/blob/master/FUNCTIONS.md).
Использование плагинов
Плагины предоставляют отличную возможность расширить функционал Kibana. Все установленные плагины сохраняются в папке $KIBANA_HOME/plugins. Компания — производитель Kibana — Elastic — предоставляет множество плагинов, также доступны сторонние плагины, которыми вы можете воспользоваться.
Установка плагинов
Перейдите в папку KIBANA_HOME и выполните команду install, как показано в следующем фрагменте кода. Таким образом устанавливаются любые плагины. Во время установки необходимо указать либо название плагина (если он от компании Elastic), либо URL-ссылку, по которой размещен плагин:
$ KIBANA_HOME>bin/kibana-plugin install <имя пакета или URL>
Например, для установки x-pack, плагина от компании Elastic, выполните следующую команду:
$ KIBANA_HOME>bin/kibana-plugin install x-pack
Для установки общедоступного плагина, например LogTrail (https://github.com/sivasamyk/logtrail), выполните такую команду:
$ KIBANA_HOME>bin/kibana-plugin install
https://github.com/sivasamyk/logtrail/releases/download/v0.1.23/logtrail-6.0.0-0.1.23.zip

LogTrail — это плагин для просмотра, анализа, поиска и отслеживания лог-событий из различных источников в реальном времени с удобным для разработчиков интерфейсом. Создан компанией Papertrail (https://papertrailapp.com/).

Список общедоступных плагинов Kibana вы найдете по ссылке https://www.elastic.co/guide/en/kibana/6.0/known-plugins.html.
Удаление плагинов
Для удаления плагина перейдите в папку KIBANA_HOME и выполните команду remove, указав название плагина:
$ KIBANA_HOME>bin/kibana-plugin remove x-pack
Резюме
В этой главе вы узнали, как эффективно использовать Kibana для создания красивых панелей управления, которые помогают в исследовании данных.
Вы научились настраивать Kibana для визуализации данных из Elasticsearch. Кроме того, разобрались, как добавлять плагины.
В следующей главе мы поговорим об Elasticsearch и ее ключевых компонентах, позволяющих создавать контейнеры данных. Вы также узнаете о визуализации данных и расширениях, которые необходимы для отдельных сценариев использования.

