8. Elastic X-Pack
X-Pack — расширение для Elastic Stack, которое предоставляет настройки безопасности, уведомлений, мониторинга, отчетности, машинного обучения, а также возможности построения графиков в одном, легко устанавливаемом пакете. X-Pack добавляет важные функции, необходимые для подготовки Elastic Stack к эксплуатации. В отличие от других компонентов Elastic Stack с открытым исходным кодом, X-Pack является коммерческим предложением от Elastic.co, для его работы требуется платная лицензия. При первой установке вы получаете версию на пробный период 30 дней. Базовая, или бесплатная, версия предоставляет только возможность мониторинга и инструменты разработчика, такие как профайлер поиска (Search Profiler) или отладчик Grok (Grok Debugger). Несмотря на то что X-Pack поставляется как пакет, вы можете легко добавлять/исключать те функции, которые хотите/не хотите использовать.
В этой главе мы рассмотрим следующие темы.
• Установка X-Pack в Elasticsearch или Kibana.
• Настройка безопасности в Elasticsearch или Kibana.
• Мониторинг Elasticsearch.
• Работа с уведомлениями.
Установка X-Pack
Поскольку X-Pack является расширением Elasticsearch, до его установки необходимо инсталлировать Elasticsearch и Kibana. Следует запускать версию X-Pack, которая совпадает с версией Elasticsearch и Kibana.
Установка X-Pack в Elasticsearch
X-Pack устанавливается так же, как и любой другой плагин Elasticsearch.
Ниже перечислены шаги для установки X-Pack в Elasticsearch.
1. Перейдите в папку ES_HOME.
2. Установите X-Pack, используя следующую команду:
$ ES_HOME> bin/elasticsearch-plugin install x-pack
Во время установки вам будет задан вопрос о предоставлении X-Pack дополнительных разрешений, которые необходимы для отправки уведомлений по почте, а также для запуска аналитического движка машинного обучения Elasticsearch. Для продолжения введите Y, для отмены установки — N.
В процессе установки вы получите следующие логи/подсказки:
-> Downloading x-pack from elastic
[=================================================] 100%
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@ WARNING: plugin requires additional permissions @
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
* java.io.FilePermission \\.\pipe\* read,write
* java.lang.RuntimePermission
accessClassInPackage.com.sun.activation.registries
* java.lang.RuntimePermission getClassLoader
* java.lang.RuntimePermission setContextClassLoader
* java.lang.RuntimePermission setFactory
* java.net.SocketPermission * connect,accept,resolve
* java.security.SecurityPermission createPolicy.JavaPolicy
* java.security.SecurityPermission getPolicy
* java.security.SecurityPermission putProviderProperty.BC
* java.security.SecurityPermission setPolicy
* java.util.PropertyPermission * read,write
* java.util.PropertyPermission sun.nio.ch.bugLevel write
See
http://docs.oracle.com/javase/8/docs/technotes/guides/security/
permissions.html for descriptions of what these permissions allow and the associated risks.
Continue with installation? [y/N]y
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@ WARNING: plugin forks a native controller @
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
This plugin launches a native controller that is not subject to the Java security manager nor to system call filters.
Continue with installation? [y/N]y
Elasticsearch keystore is required by plugin [x-pack], creating...
-> Installed x-pack
3. Перезапустите Elasticsearch:
$ ES_HOME> bin/elasticsearch
4. Установите пароли для пользователя по умолчанию и резервного: elastic, kibana и logstash_system, выполнив команду:
$ ES_HOME>bin/x-pack/setup-passwords interactive
Вы должны получить следующие логи для ввода пароля резервного/основного пользователя:
Initiating the setup of reserved user
elastic,kibana,logstash_system passwords.
You will be prompted to enter passwords as the process progresses.
Please confirm that you would like to continue [y/N]y
Enter password for [elastic]: elastic
Reenter password for [elastic]: elastic
Enter password for [kibana]: kibana
Reenter password for [kibana]: kibana
Enter password for [logstash_system]: logstash
Reenter password for [logstash_system]: logstash
Changed password for user [kibana]
Changed password for user [logstash_system]
Changed password for user [elastic]

Обратите внимание на установленные пароли. Вы можете выбрать любой пароль по своему желанию. Мы установили следующие пароли: elastic, kibana и logstash — для пользователей elastic, kibana и logstash_system и будем применять их на протяжении этой главы.
Для проверки установки X-Pack и безопасности откройте в своем браузере Elasticsearch по адресу http://localhost:9200/. Вы должны увидеть поле авторизации Elasticsearch. Можете указать здесь встроенного пользователя elastic и пароль elastic. После успешной регистрации вы увидите следующий ответ:
{
name: "fwDdHSI",
cluster_name: "elasticsearch",
cluster_uuid: "08wSPsjSQCmeRaxF4iHizw",
version: {
number: "6.0.0",
build_hash: "8f0685b",
build_date: "2017-11-10T18:41:22.859Z",
build_snapshot: false,
lucene_version: "7.0.1",
minimum_wire_compatibility_version: "5.6.0",
minimum_index_compatibility_version: "5.0.0"
},
tagline: "You Know, for Search"
}
Типичный кластер Elasticsearch состоит из нескольких узлов, следовательно, X-Pack необходимо установить на каждом узле кластера.

Для пропуска подсказок установки используйте параметр -batch: $ES_HOME>bin/elasticsearch-plugin install x-pack --batch.

При установке X-Pack были созданы следующие папки: x-pack в bin, config и plugins в ES_HOME. Мы рассмотрим их в следующих разделах этой главы.
Установка X-Pack в Kibana
X-Pack устанавливается аналогично любому другому плагину расширения Kibana.
Далее перечислены шаги для установки X-Pack в Kibana.
1. Перейдите в папку KIBANA_HOME.
2. Установите X-Pack, используя следующую команду:
$KIBANA_HOME>bin/kibana-plugin install x-pack
В процессе установки вы получите следующие логи/подсказки:
Attempting to transfer from x-pack
Attempting to transfer from
https://artifacts.elastic.co/downloads/kibana-plugins/x-pack/x-pack
-6.0.0.zip
Transferring 120307264 bytes....................
Transfer complete
Retrieving metadata from plugin archive
Extracting plugin archive
Extraction complete
Optimizing and caching browser bundles...
Plugin installation complete
3. Добавьте следующую информацию авторизации в файл kibana.yml, который находится в папке $KIBANA_HOME/config, и сохраните его:
elasticsearch.username: "kibana"
elasticsearch.password: "kibana"

Если во время настройки паролей вы выбрали другой пароль для пользователя kibana, указывайте это значение для elasticsearch.password.
4. Запустите Kibana.
$KIBANA_HOME>bin/kibana
Для проверки установки X-Pack перейдите по ссылке http://localhost:5601/ для открытия Kibana. Вы должны перейти на страницу регистрации (рис. 8.1). Для авторизации можете указать встроенного пользователя elastic и пароль elastic.
Рис. 8.1

При установке X-Pack была создана папка с названием x-pack, расположенная в каталоге с плагинами KIBANA_HOME.
Можете установить X-Pack и в Logstash. Однако в данный момент X-Pack поддерживает только мониторинг Logstash.
Удаление X-Pack
Для удаления X-Pack выполните следующие шаги.
1. Остановите работу Elasticsearch.
2. Удалите X-Pack из Elasticsearch:
$ES_HOME>bin/elasticsearch-plugin remove x-pack
3. Перезапустите Elasticsearch и остановите работу Kibana. Удалите X-Pack из Kibana:
$KIBANA_HOME>bin/kibana-plugin remove x-pack
4. Перезапустите Kibana.
Настройка X-Pack
Сразу после установки можно использовать встроенные возможности X-Pack, относящиеся к безопасности, уведомлениям, мониторингу, отчетности, машинному обучению, а также к построению графиков. Возможно, вам не потребуется весь возможный функционал этого расширения, поэтому вы можете выбирать необходимые инструменты, включать или выключать их в конфигурационных файлах elasticsearch.yml и kibana.yml.
Elasticsearch поддерживает следующие функции и настройки в файле elasticsearch.yml.
| Функция | Настройка | Описание |
| Машинное обучение | xpack.ml.enabled | Установите отрицательное значение для отключения функционала машинного обучения X-Pack |
| Мониторинг | xpack.monitoring.enabled | Установите отрицательное значение для отключения функционала мониторинга Elasticsearch |
| Безопасность | xpack.security.enabled | Установите отрицательное значение для отключения функционала безопасности X-Pack |
| Наблюдатель | xpack.watcher.enabled | Установите отрицательное значение для отключения функционала наблюдателя |
Kibana поддерживает следующие функции и настройки в файле kibana.yml.
| Функция | Настройка | Описание |
| Машинное обучение | xpack.ml.enabled | Установите отрицательное значение для отключения функционала машинного обучения X-Pack |
| Мониторинг | xpack.monitoring.enabled | Установите отрицательное значение для отключения функционала мониторинга Kibana |
| Безопасность | xpack.security.enabled | Установите отрицательное значение для отключения функционала безопасности X-Pack |
| Построение диаграмм | xpack.graph.enabled | Установите отрицательное значение для отключения функционала диаграмм X-Pack |
| Отчетность | xpack.reporting.enabled | Установите отрицательное значение для отключения функционала отчетности X-Pack |

Если X-Pack установлен в Logstash, можете отключить мониторинг, присвоив параметру xpack.monitoring.enabled значение false в конфигурационном файле logstash.yml.
Безопасность
Компоненты Elastic Stack не имеют встроенных механизмов защиты — кто угодно может получить к ним доступ. Это представляет угрозу безопасности при внедрении Elastic Stack в эксплуатацию. Для предотвращения несанкционированного доступа применяются разные механизмы обеспечения безопасности, такие как запуск Elastic Stack вместе с системой сетевой защиты (файерволлом) и использование обратных прокси (nginx, HAProxy и пр.). Компания Elastic.co предлагает коммерческий продукт для защиты Elastic Stack. Он поставляется как часть пакета X-Pack и называется Security.
Модуль безопасности X-Pack обеспечивает следующие способы защиты Elastic Stack:
• пользовательскую аутентификацию и авторизация;
• аутентификацию узла/клиента и шифрование канала;
• аудит.
Пользовательская аутентификация
Пользовательская аутентификация — процесс предотвращения несанкционированного доступа к кластеру Elastic Stack путем проверки данных пользователя. В модуле безопасности X-Pack за процесс аутентификации отвечают один или несколько сервисов, которые называются областями (realms). Модуль безопасности предоставляет два типа областей: внутренние и внешние.
Два типа встроенных областей безопасности называются native и file. Область native является областью по умолчанию, данные аутентификации пользователя хранятся в особом индексе .security-6 в Elasticsearch. Управление пользователями осуществляется с помощью соответствующего API (User Management API) или на странице Management (Управление) в пользовательском интерфейсе Kibana. Мы рассмотрим это детальнее в следующих разделах главы.
Если тип области file, тогда данные аутентификации пользователей хранятся в файле в каждом узле. Управление пользователями осуществляется с помощью специальных инструментов, которые предоставляются во время установки X-Pack. Вы можете найти их в папке $ES_HOME\bin\x-pack. Там же хранятся и пользовательские файлы. Поскольку сведения о пользователях хранятся в файле, в ответственность администратора входит создание пользователей с одинаковыми данными в каждом узле.
Встроенные внешние области безопасности — это ldap, active_directory и pki, которые используют внешний сервер LDAP, внешний сервер Active Directory и инфраструктуру открытого ключа.
В зависимости от настроенных областей данные аутентификации пользователей необходимо добавлять к запросам в Elasticsearch. Порядок областей, приведенный в файле elasticsearch.yml, определяет порядок, в котором области учитываются в процессе аутентификации. Каждая область опрашивается одна за другой в установленном порядке до той поры, пока аутентификация не будет признана успешной. Процесс аутентификации считается успешным при достижении удачной аутентификации запроса одной из областей. Если ни одна из областей не смогла аутентифицировать пользователя, попытка считается неуспешной и клиент получает ошибку аутентификации (HTTP 401).
Если в файле elasticsearch.yml не указано никаких областей, тогда по умолчанию используется область типа native. Для задействования областей типа file или внешних областей их необходимо указать в файле elasticsearch.yml.
Например, в следующем фрагменте кода показана конфигурация цепочки областей, содержащей native, file и ldap:
xpack.security.authc:
realms:
native:
type: native
order: 0
file:
type: file
order: 1
ldap_server:
type: ldap
order: 2
url: 'url_to_ldap_server'

Для отключения определенного типа областей безопасности используйте параметр enabled:false, как показано в примере ниже:
ldap_server:
type: ldap
order: 2
enabled: false
url: 'url_to_ldap_server'
Авторизация пользователя
После того как пользователь успешно аутентифицирован, включается процесс авторизации. Авторизация определяет, имеет ли пользователь, задающий запрос, достаточно разрешений для выполнения конкретного запроса.
В модуле безопасности X-Pack пользовательская безопасность обеспечивается защищенными ресурсами (secured resources). Защищенный ресурс — это ресурс, которому нужен доступ к индексам, документам, полям или доступ на выполнение операций кластеров Elasticsearch. Модуль безопасности X-Pack производит авторизацию, назначая разрешения ролям, которые приписаны пользователям. Разрешение — это одна или несколько привилегий относительно защищенного ресурса. Привилегией называется группа из одного или нескольких действий, которые пользователь может выполнить по отношению к защищенному ресурсу. Пользователь может иметь одну или несколько ролей, а общий набор разрешений пользователя определяется как сумма всех разрешений во всех ролях (рис. 8.2).
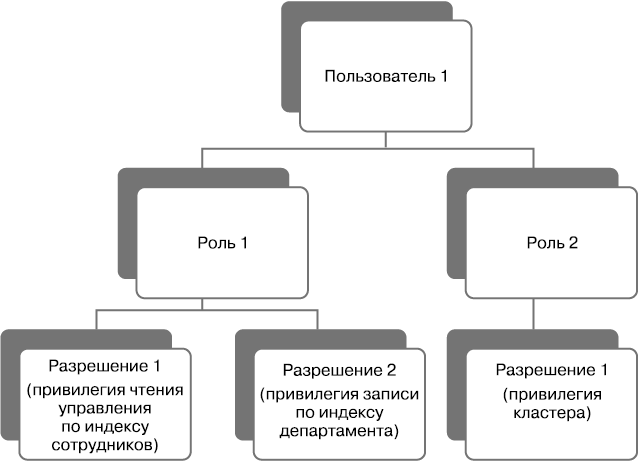
Рис. 8.2
В модуле безопасности X-Pack предоставляются следующие типы привилегий.
• Привилегии кластера. Предоставляет доступ к выполнению различных операций в кластере. Возможны такие настройки:
• all — разрешает выполнять все операции администратора кластера: настройку, обновление, переадресацию или управление пользователями и ролями;
• monitor — позволяет выполнять операции только чтения кластера: запрос работоспособности кластера, состояния кластера, узлов и пр., для проведения мониторинга;
• manage — разрешает выполнять операции для обновления кластера, такие как переадресация и обновление настроек кластера.
• Привилегии индекса. Предоставляет доступ к выполнению различных операций в индексе:
• all — разрешает выполнять любую операцию в индексе;
• read — позволяет выполнять операции только чтения в индексе;
• create_index — разрешает создать новый индекс;
• create — разрешает индексировать новые документы в индексе;
• Привилегия выполнения от имени. Предоставляет возможность действовать от имени пользователя; то есть позволяет аутентифицированному пользователю тестировать права доступа другого пользователя, не зная данных авторизации.

С полным списком привилегий вы можете ознакомиться по ссылке https://www.elastic.co/guide/en/x-pack/master/security-privileges.html.
• Аутентификация узла/клиента и шифрование канала. Модуль безопасности X-Pack предотвращает сетевые атаки путем шифрования связи. Вы можете шифровать трафик между кластером Elasticsearch и внешними приложениями, а также связь между узлами кластера. Для предотвращения незапланированного подключения узлов к кластеру можно настроить подключение узлов к кластеру только с помощью сертификатов SSL. Доступна также IP-фильтрация для предотвращения незапланированного подключения клиентов приложений, узлов или доставки к кластеру.
• Аудит. Аудит позволяет обнаруживать подозрительные действия в кластере. Вы можете использовать его для отслеживания событий, связанных с безопасностью, таких как ошибки аутентификации и отклоненные соединения. Логирование таких событий позволит вам мониторить кластер на предмет подозрительных действий и получать доказательства в случае атаки.
Безопасность на деле
В этом разделе мы рассмотрим создание новых пользователей, новых ролей и ассоциирование ролей с пользователями. Импортируем данные из нашего примера и используем их для того, чтобы разобраться в работе модуля безопасности.
Сохраните следующие данные в файл с названием data.json:
{"index" : {"_index":"employee","_type":"employee"}}
{ "name":"user1", "email":"[email protected]","salary":5000, "gender":"M",
"address1":"312 Main St", "address2":"Walthill", "state":"NE"}
{"index" : {"_index":"employee","_type":"employee"}}
{ "name":"user2", "email":"[email protected]","salary":10000, "gender":"F",
"address1":"5658 N Denver Ave", "address2":"Portland", "state":"OR"}
{"index" : {"_index":"employee","_type":"employee"}}
{ "name":"user3", "email":"[email protected]","salary":7000, "gender":"F",
"address1":"300 Quinterra Ln", "address2":"Danville", "state":"CA"}
{"index" : {"_index":"department","_type":"department"}}
{ "name":"IT", "employees":50 }
{"index" : {"_index":"department","_type":"department"}}
{ "name":"SALES", "employees":500 }
{"index" : {"_index":"department","_type":"department"}}
{ "name":"SUPPORT", "employees":100 }

API _bulk позволяет сохранять последнюю строку файла с символом новой строки, \n. При сохранении файла убедитесь, что символ новой строки расположен в последней строке файла.
Перейдите в папку с этим файлом и выполните следующую команду для импортирования данных в Elasticsearch:
$ directoy_of_data_file> curl -s -H "Content-Type: application/json" -u
elastic:elastic -XPOST http://localhost:9200/_bulk --data-binary @data.json
Для проверки успешности импорта выполните следующую команду и уточните, правильно ли указано количество документов:
D:\packt\book>curl -s -H "Content-Type: application/json" -u
elastic:elastic -XGET http://localhost:9200/employee,department/_count
{"count":6,"_shards":{"total":10,"successful":10,"skipped":0,"failed":0}}
Создание нового пользователя
В первую очередь зайдите в Kibana как пользователь elastic (http://locahost:5601).
1. Для создания нового пользователя перейдите в раздел пользовательского интерфейса Management (Управление) и выберите Users (Пользователи) в разделе Security (Безопасность) (рис. 8.3).
Рис. 8.3
2. На странице Users (Пользователи) перечислены все доступные пользователи и их роли. По умолчанию показаны стандартные/резервные пользователи, которые являются частью области безопасности native X-Pack (рис. 8.4).
Рис. 8.4
3. Для создания нового пользователя нажмите кнопку Create User (Создать пользователя) и добавьте нужную информацию, как показано на рис. 8.5.
4. Нажмите кнопку Save (Сохранить).
Теперь, когда пользователь создан, попробуем получить доступ к некоторым REST API Elasticsearch с данными авторизации нового пользователя и посмотрим, что произойдет. Выполните следующую команду и проверьте полученный ответ. Несмотря на успешную аутентификацию, у пользователя нет назначенных ролей. Он получает HTTP-статус 403, говорящий о том, что пользователь не авторизован для выполнения операции:
D:\packt\book>curl -s -H "Content-Type: application/json" -u
user1:password -XGET http://localhost:9200
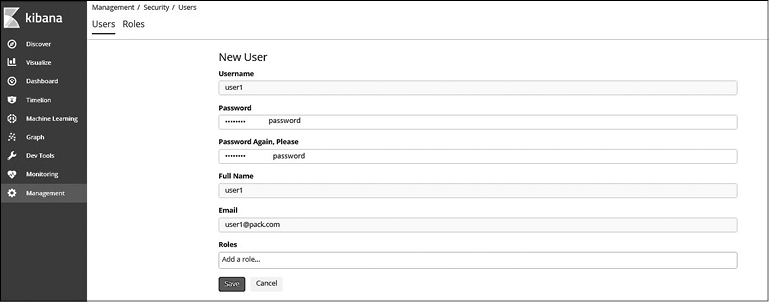
Рис. 8.5
Ответ:
{"error":{"root_cause":[{"type":"security_exception","reason":"action [cluster:monitor/main] is unauthorized for user
[user1]"}],"type":"security_exception","reason":"action
[cluster:monitor/main] is unauthorized for user
[user1]"},"status":403}
Аналогичным образом создайте еще одного пользователя с названием user2, как показано на рис. 8.6.
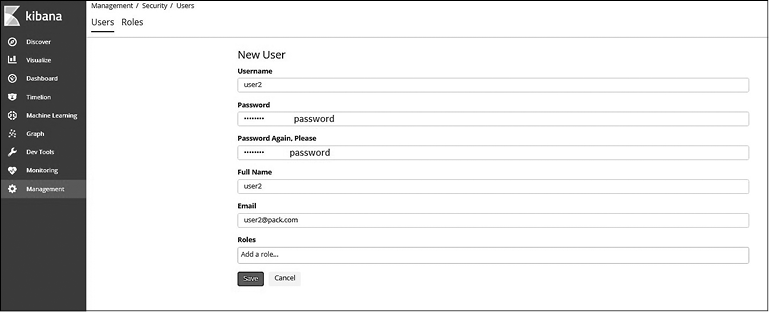
Рис. 8.6
Удаление пользователя
Для удаления роли перейдите в раздел пользовательского интерфейса Users (Пользователи), выберите созданных пользователей и нажмите кнопку Delete (Удалить). Встроенных пользователей удалить невозможно (рис. 8.7).
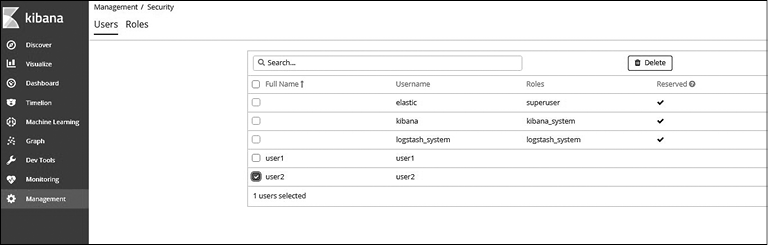
Рис. 8.7
Изменение пароля
Перейдите в раздел пользовательского интерфейса Users (Пользователи) и выберите пользователя, для которого необходимо изменить пароль. Вы попадете на страницу User Details (Сведения о пользователе). Здесь можно отредактировать информацию о пользователе, изменить пароль или удалить пользователя из раздела. Для изменения пароля щелкните на ссылке Change Password (Изменить пароль) и введите новый пароль (рис. 8.8). Нажмите кнопку Save (Сохранить).
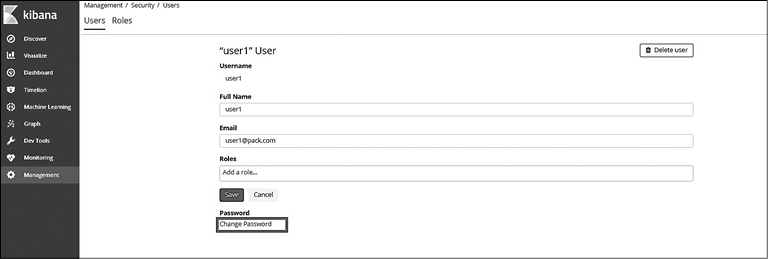
Рис. 8.8

Пароль должен состоять из не менее чем шести символов.
Создание новой роли
Для создания новой роли пользователя перейдите в раздел пользовательского интерфейса Management (Управление) и выберите Roles (Роли) в разделе Security (Безопасность). Если вы находитесь на странице Users (Пользователи), перейдите на вкладку Roles (Роли). На ней будут перечислены все доступные роли (рис. 8.9). По умолчанию будут показаны встроенные/резервные роли, которые являются частью области безопасности native в X-Pack.
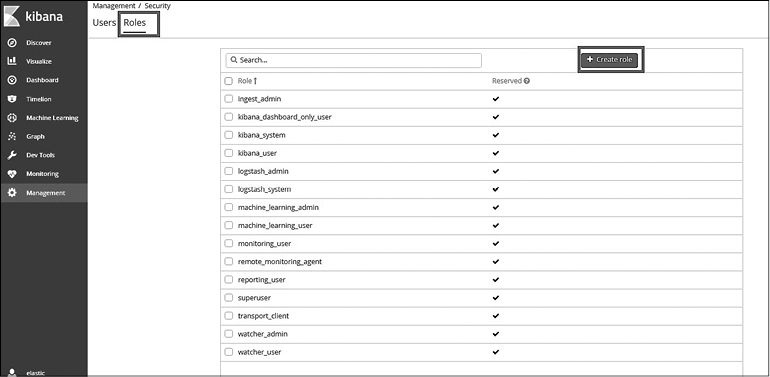
Рис. 8.9
Модуль безопасности X-Pack также предоставляет набор встроенных ролей, которые можно назначить пользователям. Эти роли зарезервированы, и ассоциированные с ними привилегии невозможно обновить. Рассмотрим некоторые из встроенных ролей.
• kibana_system — разрешает необходимый доступ для чтения и записи в индексы Kibana, управления шаблонами индексов и проверки доступности кластера Elasticsearch. Эта роль также предоставляет доступ к индексам мониторинга (.monitoring-*) и доступ чтения/записи к отчетности (.reporting-*). Эти привилегии по умолчанию есть у пользователя kibana.
• superuser — предоставляет доступ для выполнения всех операций над кластерами, индексами и данными. Эта роль также позволяет создавать/редактировать пользователей и роли. Эти привилегии по умолчанию есть у пользователя elastic.
• ingest_admin — предоставляет разрешения на управление всеми конфигурациями контейнеров и шаблонами индексов.

Полный список всех встроенных ролей и их описание доступны по ссылке https://www.elastic.co/guide/en/x-pack/master/built-inroles.html.
Пользователь с ролью superuser может создавать другие роли и назначать их другим пользователям в пользовательском интерфейсе Kibana.
Создадим новую роль с привилегией кластера monitor и назначим ее пользователю user1, чтобы он мог выполнять операции только чтения, такие как запрос сведений о работоспособности кластера, состоянии кластера, информации об узлах, статистики узлов и пр.
Нажмите кнопку Create Role (Создать роль) на странице/вкладке Roles (Роли) и задайте настройки, как показано на рис. 8.10.
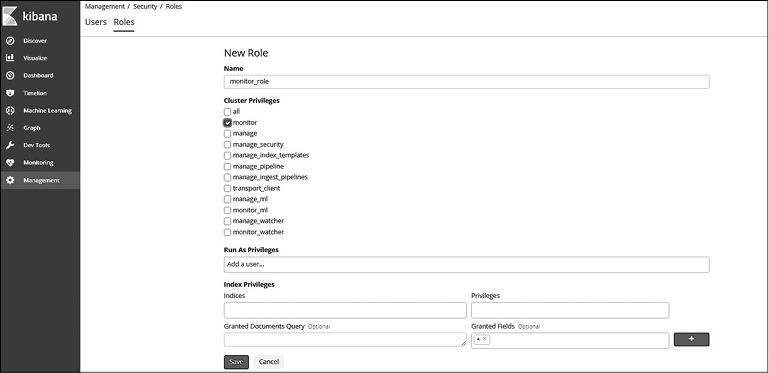
Рис. 8.10
Для назначения только что созданной роли пользователю user1 перейдите на вкладку Users (Пользователи) и выберите user1. На странице User Details (Сведения о пользователе) в раскрывающемся списке выберите роль monitor_role и нажмите кнопку Save (Сохранить) (рис. 8.11).

Одному пользователю можно назначить несколько ролей.
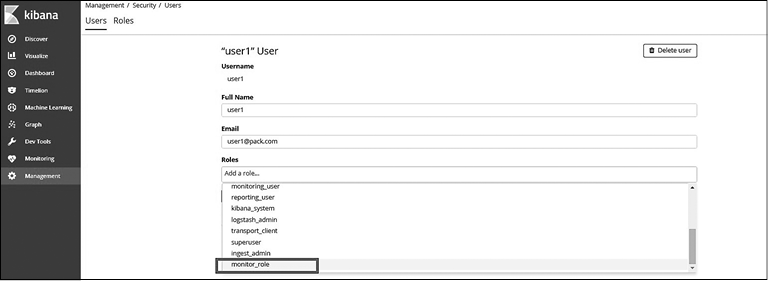
Рис. 8.11
Теперь проверим, действительно ли user1 может получить доступ к некоторым API кластера/узла:
curl -u user1:password "http://localhost:9200/_cluster/health?pretty"
{
"cluster_name" : "elasticsearch",
"status" : "yellow",
"timed_out" : false,
"number_of_nodes" : 1,
"number_of_data_nodes" : 1,
"active_primary_shards" : 53,
"active_shards" : 53,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 52,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 50.476190476190474
}
Выполним ту же команду, как и при создании user1, но без назначения ему каких-либо ролей, и посмотрим на разницу:
curl -u user1:password "http://localhost:9200"
{
"name" : "fwDdHSI",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "08wSPsjSQCmeRaxF4iHizw",
"version" : {
"number" : "6.0.0",
"build_hash" : "8f0685b",
"build_date" : "2017-11-10T18:41:22.859Z",
"build_snapshot" : false,
"lucene_version" : "7.0.1",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}
Как удалить/редактировать роль. Для удаления роли перейдите на страницу/вкладку Roles (Роли), выберите созданные вами роли и нажмите кнопку Delete (Удалить). Встроенные роли удалить невозможно (рис. 8.12).
Для редактирования роли перейдите на страницу/вкладку Roles (Роли), выберите созданные вами роли, которые нуждаются в редактировании. Пользователь направляется на страницу Roles Details (Сведения о роли). Внесите необходимые изменения в разделе привилегий и нажмите кнопку Save (Сохранить). На этой странице также можно удалить роль (рис. 8.13).
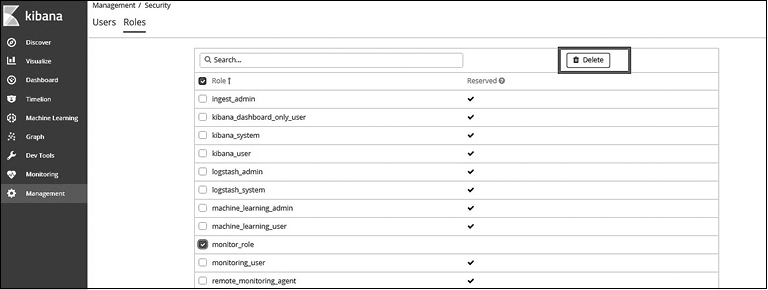
Рис. 8.12
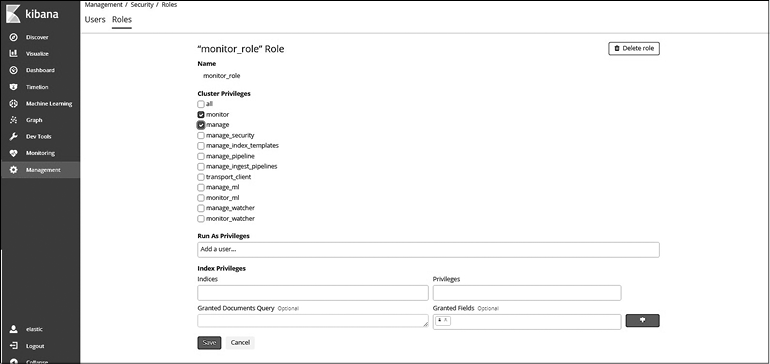
Рис. 8.13
Безопасность уровня документов или уровня полей
Теперь, когда вы знаете, как создавать новых пользователей, роли и назначать роли пользователям, рассмотрим возможности безопасности для документов и полей в определенных индексах/документах.
В примере данных, который мы импортировали в начале главы, есть два индекса: сотрудников (employee) и отделов (department).
Пример 1. Когда пользователь ищет информацию о сотруднике, он не должен получать в результатах поиска сведения о зарплате и адресе из документов в индексе employee.
В этом случае поможет безопасность уровня поля. Создадим новую роль (employee_read) с привилегией read для индекса employee. Для ограничения полей в разделе Granted Fields (Разрешенные поля) выберите те поля, к которым можно разрешить доступ пользователю, как показано на рис. 8.14.
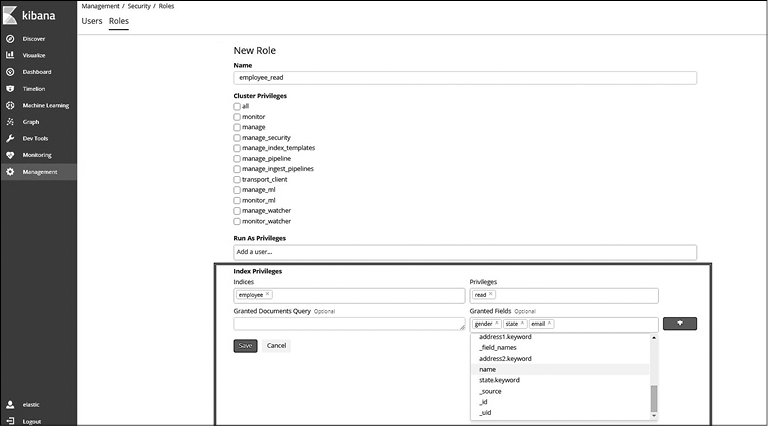
Рис. 8.14

При создании роли можно указать один набор привилегий для нескольких индексов. Для этого необходимо добавить один или несколько индексов в поле Indices (Индексы) или же указать разные привилегии для разных индексов, нажав кнопку + в разделе Index Privileges (Привилегии индексов).
Назначьте пользователю user2 новую роль (рис. 8.15).
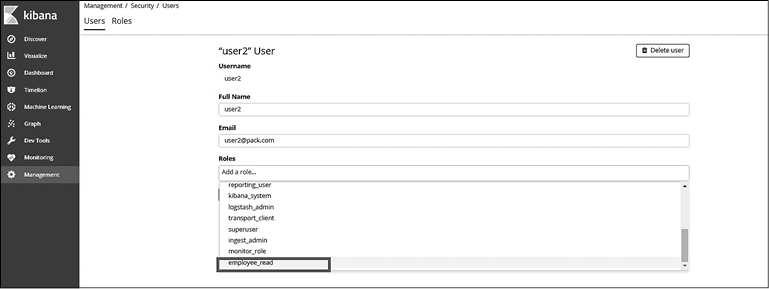
Рис. 8.15
Теперь запустите поиск по индексу сотрудников и посмотрите, какие поля будут в ответе. Как видно в ответе ниже, мы успешно ограничили пользователей в получении доступа к информации о зарплате и адресе:
curl -u user2:password "http://localhost:9200/employee/_search?pretty"
{
"took" : 20,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 3,
"max_score" : 1.0,
"hits" : [
{
"_index" : "employee",
"_type" : "employee",
"_id" : "3QuULGABsx353N7xt4k6",
"_score" : 1.0,
"_source" : {
"gender" : "F",
"name" : "user2",
"state" : "OR",
"email" : "[email protected]"
}
},
{
"_index" : "employee",
"_type" : "employee",
"_id" : "3guULGABsx353N7xt4k6",
"_score" : 1.0,
"_source" : {
"gender" : "F",
"name" : "user3",
"state" : "CA",
"email" : "[email protected]"
}
},
{
"_index" : "employee",
"_type" : "employee",
"_id" : "3AuULGABsx353N7xt4k6",
"_score" : 1.0,
"_source" : {
"gender" : "M",
"name" : "user1",
"state" : "NE",
"email" : "[email protected]"
}
}
]
}
}
Пример 2. Требуется создать многопользовательский индекс и ограничить доступ определенных пользователей к отдельным документам. Например, сделать так, чтобы пользователь user1 мог искать по индексу отдела и получать только те документы, которые относятся к IT-отделу.
Создайте роль department_IT_role и предоставьте привилегию read для индекса department. Для ограничения документов укажите запрос в разделе Granted Documents Query (Разрешенные запросы документов). Запрос должен быть в формате Elatsicsearch Query DSL (рис. 8.16).
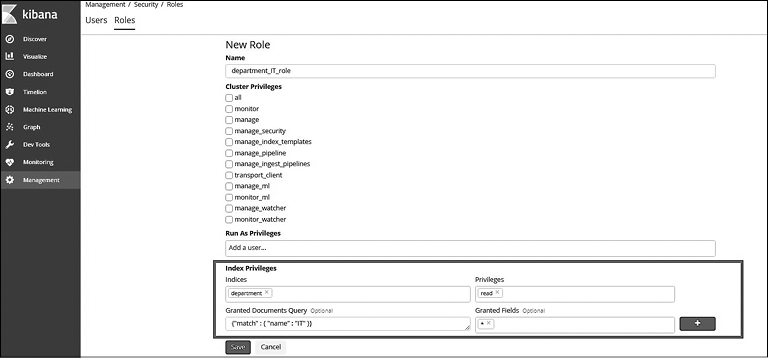
Рис. 8.16
Свяжите созданную роль с пользователем user1 (рис. 8.17).
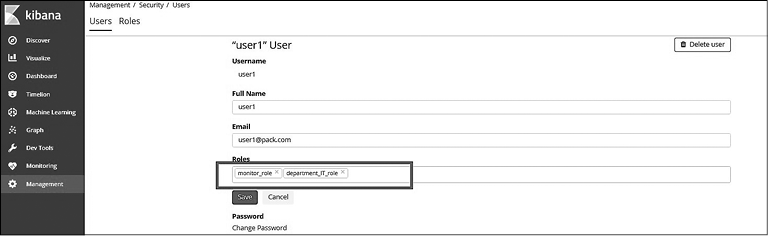
Рис. 8.17
Теперь нужно проверить работоспособность этих настроек, выполнив поиск по индексу department с данными аутентификации пользователя user1:
curl -u user1:password "http://localhost:9200/department/_search?pretty"
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 1.0,
"hits" : [
{
"_index" : "department",
"_type" : "department",
"_id" : "3wuULGABsx353N7xt4k6",
"_score" : 1.0,
"_source" : {
"name" : "IT",
"employees" : 50
}
}
]
}
}
API безопасности X-Pack
В предыдущем разделе вы узнали, как управлять пользователями и ролями в пользовательском интерфейсе Kibana. Однако при многократном выполнении этих операций хотелось бы делать это программно из приложений. Вот где могут пригодиться API безопасности X-Pack. Они состоят из REST API, которые можно применять для управления пользователями/ролями, назначения ролей пользователям, проведения аутентификаций и проверки наличия необходимых привилегий у аутентифицированного пользователя. Эти API проводят операции в области безопасности native. Пользовательский интерфейс Kibana задействует эти API на внутреннем уровне для управления пользователями/ролями. Для выполнения этих API пользователь должен иметь привилегии superuser или manage_security.
API управления пользователями
Предоставляет набор API для создания, редактирования или удаления пользователей из области безопасности native.
Список доступных API:

Параметр username в указанном пути определяет пользователя для выполняемой операции. Тело запроса принимает такие параметры, как email, full_name и password в качестве строки, а roles — в качестве списка.
Пример 1. Создадим нового пользователя user3 с назначенной ему ролью monitor_role:
curl -u elastic:elastic -X POST
http://localhost:9200/_xpack/security/user/user3 -H 'content-type:
application/json' -d '
{
"password" : "randompassword",
"roles" : [ "monitor_role"],
"full_name" : "user3",
"email" : "[email protected]"
}'
Ответ:
user":{"created":true}}
Пример 2. Получим список всех пользователей:
curl -u elastic:elastic -XGET
http://localhost:9200/_xpack/security/user?pretty
Пример 3. Удалим пользователя user3:
curl -u elastic:elastic -XDELETE
http://localhost:9200/_xpack/security/user/user3
Ответ:
{"found":true}
Пример 4. Изменим пароль:
curl -u elastic:elastic -XPUT
http://localhost:9200/_xpack/security/user/user2/_password -H "contenttype:
application/json" -d "{ \"password\": \"newpassword\"}"

Обратите внимание, что при использовании команд curl на устройствах c Windows они не будут срабатывать при наличии одинарных кавычек в тексте (‘). В предыдущем примере показано применение команды curl на устройстве под управлением Windows. Убедитесь также, что вы не используете двойные кавычки в теле команды, как это показано в предыдущем примере.
API управления ролями
Предоставляет набор API для создания, редактирования, удаления и получения ролей из области безопасности native.
Список доступных API:

Параметр rolename в указанном пути определяет роль для выполняемой операции. Тело запроса содержит следующие параметры: cluster, который принимает список привилегий кластера; indices принимает список объектов, указывающих привилегии индекса; run_as содержит список пользователей, от имени которых могут действовать обладатели этой роли.
Параметр indices содержит объект с такими параметрами, как names, принимающий список названий индексов; field_security, принимающий список полей, для которых необходимо предоставить доступ чтения; privileges, принимающий список привилегий индекса; query, принимающий запрос для фильтрации документов.
Пример 1. Создадим новую роль с безопасностью на уровне поля для работы от имени индекса сотрудников:
curl -u elastic:elastic -X POST
http://localhost:9200/_xpack/security/role/employee_read_new –H
'contenttype: application/json' -d '{
"indices": [
{
"names": [ "employee" ],
"privileges": [ "read" ],
"field_security" : {
"grant" : [ "*" ],
"except": [ "address*","salary" ]
}
}
]
}'
Ответ:
role":{"created":true}}

В отличие от пользовательского интерфейса Kibana, в котором не предусмотрено возможностей для исключения полей из пользовательского доступа, вы легко можете включать или исключать поля с помощью API безопасности в рамках безопасности на уровне поля. В предыдущем примере мы ограничили доступ к полю salary и любым полям, которые начинаются с текста/строки address.
Пример 2. Получим сведения об определенной роли:
curl -u elastic:elastic -XGET
http://localhost:9200/_xpack/security/role/employee_read_new?pretty
Ответ:
{
"employee_read" : {
"cluster" : [ ],
"indices" : [
{
"names" : [
"employee"
],
"privileges" : [
"read"
],
"field_security" : {
"grant" : [
"*"
],
"except" : [
"address*",
"salary"
]
}
}
],
"run_as" : [ ],
"metadata" : { },
"transient_metadata" : {
"enabled" : true
}
}
}
Пример 3. Удалим роль:
curl -u elastic:elastic -XDELETE
http://localhost:9200/_xpack/security/role/employee_read
Ответ:
{"found":true}

По аналогии с API управления пользователем и ролями вы можете применять API назначения пользователей для присвоения ролей пользователям. Более детально об этом API вы можете узнать по ссылке https://www.elastic.co/guide/en/elasticsearch/reference/master/security-api-role-mapping.html.
Мониторинг Elasticsearch
Для мониторинга на уровнях кластера, узла или индекса в Elasticsearch предусмотрен широкий набор API, известных как API статистики. Некоторые из этих API: _cluster/stats, _nodes/stats, myindex/stats. Они предоставляют информацию о состоянии и мониторинге в реальном времени, а статистика выдается в форматах point-in-time и .json. Если вы администратор или разработчик, возможно, вы будете заинтересованы в статистике в реальном режиме времени и в накопленной статистике о работе в Elasticsearch. Такие инструменты помогают понимать и анализировать поведение (состояние или производительность) кластера. Именно на этом этапе пригодится функционал мониторинга X-Pack.
Компоненты мониторинга X-Pack позволяют вам легко отслеживать работу составляющих Elastic Stack (Elasticsearch, Kibana и Logstash) из Kibana. X-Pack состоит из агентов мониторинга, которые работают в каждом процессе (Elasticsearch, Kibana и Logstash) и периодически собирают и индексируют метрики о состоянии и производительности. Далее вы можете выполнить визуализацию этих данных в разделе Monitoring (Мониторинг) UI Kibana. Вы можете выбрать необходимые панели управления среди предустановленных в Kibana и с их помощью легко визуализировать и анализировать свои данные в реальном времени.
По умолчанию все собранные в X-Pack метрики индексируются в пределах того же кластера, который вы мониторите. Однако в работе крайне рекомендуется иметь отдельный кластер для хранения этих метрик (рис. 8.18). Такое решение имеет следующие преимущества.
• Возможность мониторинга нескольких кластеров из централизированного места.
• Уменьшение нагрузки и экономия дискового пространства рабочих кластеров, поскольку метрики хранятся в отдельном кластере.
• Доступ к данным мониторинга есть всегда, даже при выходе из строя отдельных кластеров.
• Вы можете установить разные меры безопасности для кластера мониторинга и рабочих кластеров.
Как уже говорилось ранее, все собранные в X-Pack метрики индексируются в пределах того же кластера, который вы мониторите. Если выбран отдельный кластер для мониторинга, необходимо настроить доставку метрик соответствующим образом. Это можно сделать в файле elasticsearch.yml каждого узла, как показано в коде ниже:
xpack.monitoring.exporters:
id1:
type: http
host: ["http://dedicated_monitoring_cluster:port"]
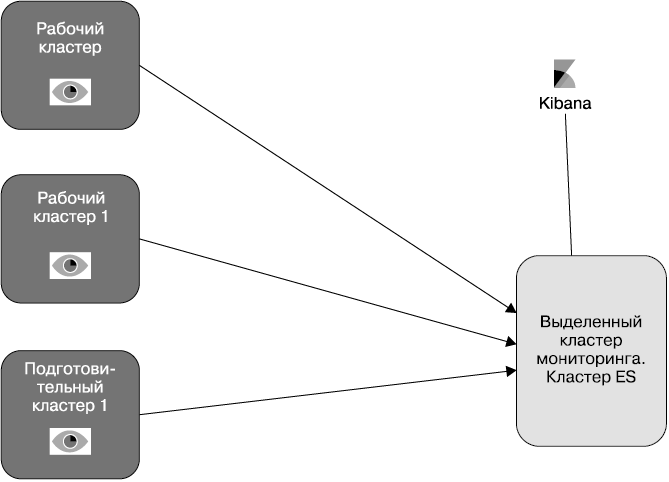
Рис. 8.18

Не обязательно устанавливать X-Pack на выделенный кластер мониторинга, однако рекомендуется установить его и там. Если вы выберете такой вариант конфигурации, убедитесь, что во время настройки указали данные авторизации пользователя (auth.username и auth.password). Метрики сохраняются в индексе на уровне системы; он имеет шаблон индекса .monitoring-*.
Раздел Monitoring (Мониторинг) пользовательского интерфейса
Для доступа к настройкам мониторинга зайдите в Kibana и перейдите в раздел Monitoring (Мониторинг) на боковой панели навигации (рис. 8.19).
На этой странице вы можете увидеть все метрики, доступные для Elasticsearch и Kibana. Более подробную информацию вы можете получить, нажимая кнопки Overview (Обзор), Nodes (Узлы), Indices (Индексы) или Instances (Процессы). Все метрики, которые вы видите на этой странице, автоматически обновляются каждые 10 с, и по умолчанию разрешено посмотреть данные за 1 ч. Эти настройки можно изменить в разделе Time Filter (Фильтр времени), который находится слева вверху страницы. Отображается также название кластера, в данном случае — elasticsearch.
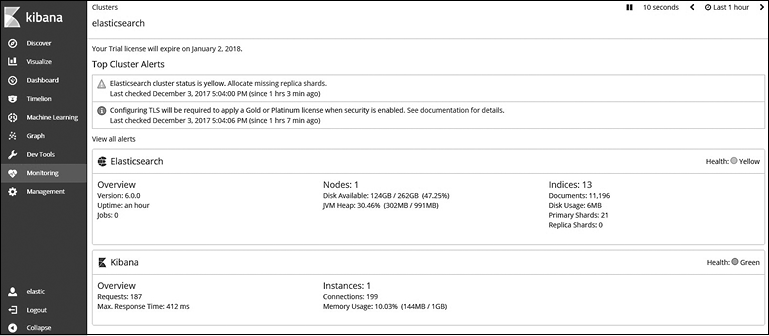
Рис. 8.19

По умолчанию агент отправляет данные о наблюдаемых процессах каждые 10 с. Вы можете изменить эту настройку в файле (elasticsearch.yml), отредактировав параметр pack.monitoring.collection.interval соответствующим образом.
Метрики Elasticsearch
Вы можете мониторить данные производительности Elasticsearch на уровне кластера, узла и индекса. Страница Monitoring (Мониторинг) Elasticsearch содержит три вкладки, каждая отображает метрики на уровне кластера, узла и индекса. Эти вкладки называются Overview (Обзор), Nodes (Узлы), Indices (Индексы) соответственно. Для перехода к пользовательскому интерфейсу мониторинга Elasticsearch щелкните на одноименной ссылке.
Вкладка Overview (Обзор)
Метрики на уровне кластера предоставляют информацию, собранную из всех узлов. Это первое место, с которого начинается мониторинг кластера Elasticsearch. Просмотреть метрики на уровне кластера можно, перейдя на вкладку Overview (Обзор) или щелкнув на ссылке Overview (Обзор). На вкладке выводятся все ключевые метрики, по которым можно судить об общем состоянии кластера Elasticsearch (рис. 8.20).
В состав ключевых метрик входят статус кластера, количество узлов и индексов, использованная память, количество шардов, количество неназначенных шардов, количество документов в индексе, дисковое пространство, использованное для хранения документов, время работы и версия Elasticsearch. На вкладке Overview (Обзор) также отображаются диаграммы, которые показывают производительность по поиску и индексированию, а таблица внизу содержит информацию о каких-либо шардах, проходящих восстановление.
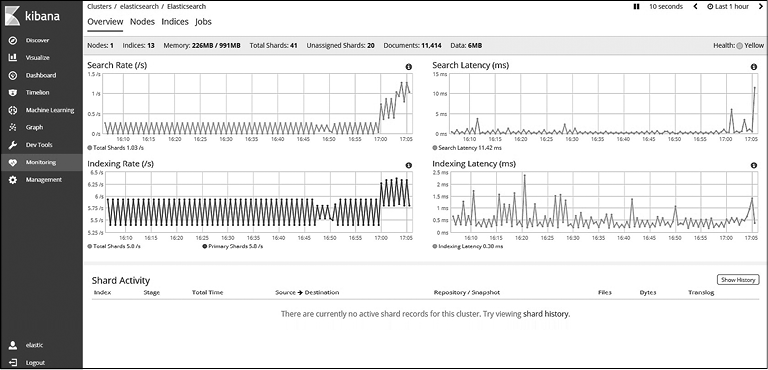
Рис. 8.20

При щелчке на информационном значке в верхнем правом углу каждой диаграммы можно получить описание метрики.
На данной вкладке метрики собираются только на уровне кластера; следовательно, при мониторинге работы Elasticsearch вы можете упустить важные параметры, которые влияют на общее состояние кластера. Например, метрика Memory Used (Использованная память) показывает средний расход памяти, использованной во всех узлах. Однако один из узлов может использовать всю память, а другие — почти не использовать ее. Следовательно, с точки зрения администрирования необходимо производить мониторинг и на уровне узла.
Вкладка Nodes (Узлы)
Перейдя на вкладку Nodes (Узлы), вы увидите общую информацию о каждом узле кластера (рис. 8.21).

Рис. 8.21
Для каждого узла доступна следующая информация: название узла, статус, нагрузка ЦП (среднее, минимальное, максимальное значения), средняя нагрузка (среднее, минимальное, максимальное значения), память JVM (среднее, минимальное, максимальное значения), свободное дисковое пространство (среднее, минимальное, максимальное значения) и количество назначенных шардов. Вы также можете узнать, является ли узел главным (обозначен звездочкой), и получить информацию о хосте доставки и порте.
Щелкнув на названии узла, вы увидите информацию об узле. Подробные сведения об узле разделены на две вкладки: Overview (Обзор) и Advanced (Дополнительно). Обзор узла выглядит следующим образом (рис. 8.22).
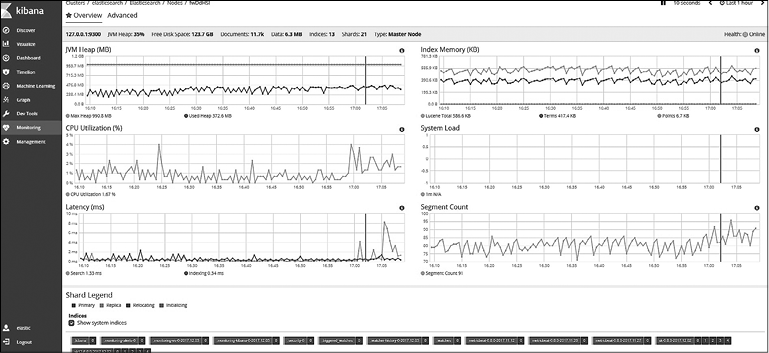
Рис. 8.22
В верхней области вкладки Overview (Обзор) узла представлена следующая информация: статус узла, транспортный IP-адрес узла, процентное использование кучи JVM, доступное свободное дисковое пространство, общее количество документов в узле (включая документы в основных шардах и их репликах), общий объем использованного дискового пространства, количество индексов в узле, количество шардов и тип узла (главный узел, узел данных, узел поглощения и узел координации).
Здесь вы также наглядно увидите, в каком объеме используются куча JVM, память индекса, сведения о коэффициенте загрузки ЦП средней нагрузки на систему, задержке (в миллисекундах) и количестве сегментов. В разделе Shard Legend (Легенда шардов) вы можете просмотреть статусы шардов различных индексов.

Вы можете увидеть статус шардов всех индексов, созданных X-Pack, если установите флажок Show system indices (Показывать системные индексы).
На вкладке Advanced (Дополнительно) узла вы найдете визуализации других метрик, таких как подсчет и длительность сборки мусора (GC), подробный расход памяти на уровнях Lucene и Elasticsearch, время индексирования (в миллисекундах), скорость запросов, индексирования, ветки чтения и статистика Cgroup (рис. 8.23).
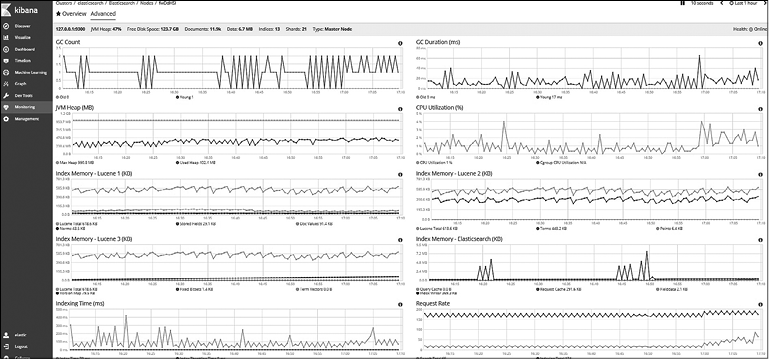
Рис. 8.23
Вкладка Indices (Индексы)
Перейдя на вкладку Indices (Индексы), вы увидите подробности о каждом индексе кластера (рис. 8.24).
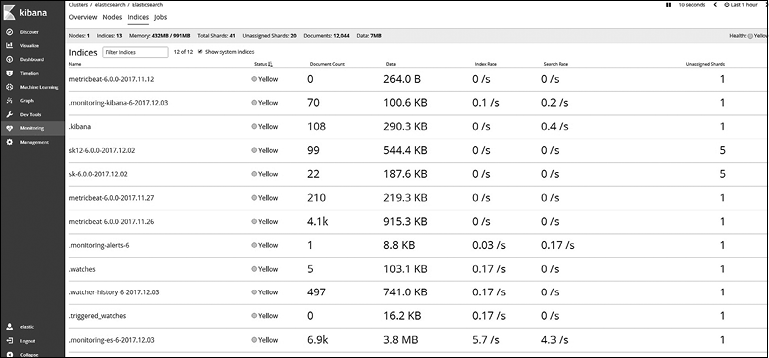
Рис. 8.24

Вы можете увидеть статус шардов всех индексов, созданных X-Pack, если установите флажок Show system indices (Показывать системные индексы).
Для каждого индекса доступна следующая информация: название индекса, статус индекса, общее количество документов, использованное дисковое пространство, скорость индексирования в секунду, скорость поиска в секунду и количество неназначенных шардов.
Информацию об индексе можно получить, щелкнув на его названии. Подробные сведения об индексе разделены на две вкладки: Overview (Обзор) и Advanced (Дополнительно). Пример вкладки Overview (Обзор) приведен на рис. 8.25.
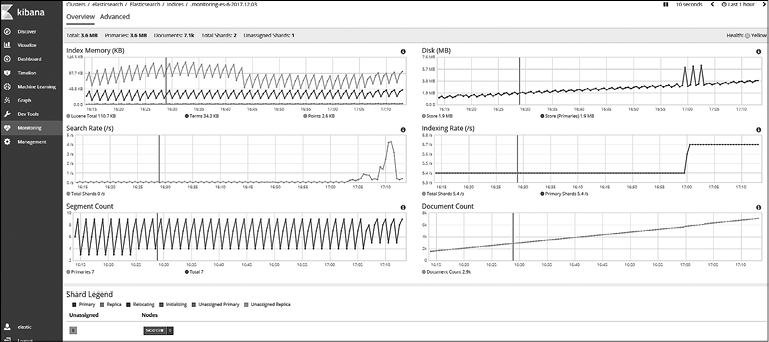
Рис. 8.25
В верхней области вкладки представлена следующая информация: статус индекса, общее количество документов, использованное дисковое пространство, количество шардов (основные + реплики) и неназначенные шарды.
Кроме того, здесь вы можете наглядно увидеть, каков процент использования памяти индекса (в килобайтах), размер индекса (в мегабайтах), скорость поисков в секунду, скорость индексирования в секунду, количество сегментов и количество документов. В области Shard Legend (Легенда шардов) вы можете просмотреть статусы шардов, принадлежащих индексу, и информацию об узлах, которым назначены шарды.
На вкладке Advanced (Дополнительно) визуализированы другие метрики, такие как расход памяти индекса на уровнях Lucene и Elasticsearch, время индексирования (в миллисекундах), скорость и время запросов, время обновления (в миллисекундах), используемое дисковое пространство и количество сегментов (рис. 8.26).

На стартовой странице пользовательского интерфейса Monitoring (Мониторинг) вы можете аналогичным способом мониторить/визуализировать метрики Kibana. Для этого нужно нажать кнопку Overview (Обзор) или Instances (События) в разделе Kibana.
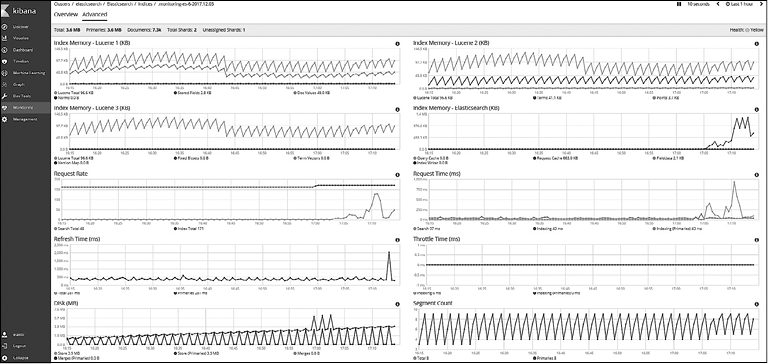
Рис. 8.26
Уведомления
Пользовательский интерфейс Kibana предоставляет красивые визуализации, которые помогают анализировать ваши данные и обнаруживать аномалии в режиме реального времени. Однако администратор или аналитик не могут часами сидеть перед панелями управления в попытке обнаружить аномалию, чтобы оперативно предпринять соответствующие действия. Было бы отлично, если бы администратор получал уведомления, когда происходят определенные события.
• Выходит из строя один из серверов под наблюдением.
• Кластер Elasticsearch переходит в красное/желтое состояние из-за того, что некоторые узлы покидают кластер.
• Использование ресурсов диска или ЦП превышает определенное значение.
• Обнаружено вторжение по сети.
• В логах найдены ошибки.
В таких случаях на помощь приходит компонент уведомления X-Pack. Он называется Watcher (Наблюдатель) и предоставляет такой функционал, как автоматическое наблюдение за изменениями или аномалиями в данных, хранящихся в Elasticsearch, а также позволяет предпринимать необходимые действия. Уведомления X-Pack включены по умолчанию как часть стандартной установки.
Наблюдатель предоставляет набор REST API для создания и тестирования наблюдателей, а также управления ими. Эти действия можно выполнять и на странице Watcher (Наблюдатель) в пользовательском интерфейсе Kibana. На внутреннем уровне будут применяться REST API наблюдателей для управления ими.
Структура наблюдателя
Наблюдатель состоит из следующих компонентов (рис. 8.27).
• schedule — используется для указания интервала времени для расписания работы наблюдателя.
• query — применяется для указания запроса с целью получения данных из Elasticsearch и запуска в качестве источника ввода. Для уточнения запросов возможно использование Elasticsearch-запросов DSL/Lucene.
• condition — используется для указания условий касательно вводных данных, полученных из запроса, при которых следует или не следует предпринимать действия.
• action — применяется для указания типа действий, таких как отправка сообщения по электронной почте, отправка уведомления Slack, запись события в определенный лог и др.
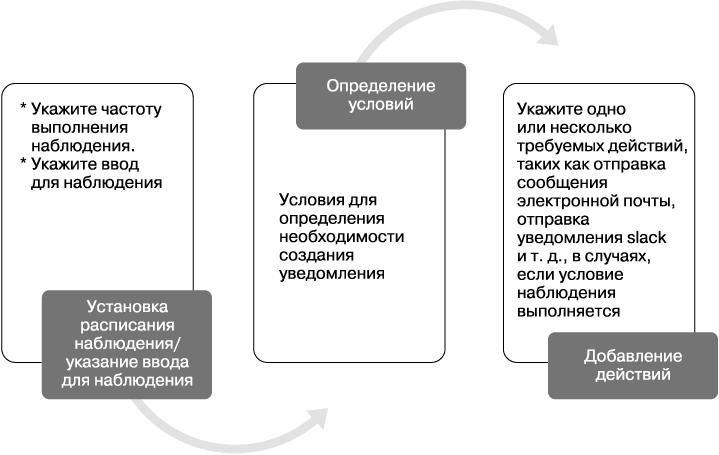
Рис. 8.27
Рассмотрим пример наблюдателя и узнаем принцип его действия в деталях. Следующий фрагмент кода создает наблюдателя:
curl -u elastic:elastic -X POST
http://localhost:9200/_xpack/watcher/watch/logstash_error_watch -H
'content-type: application/json' -d '{
"trigger" : { "schedule" : { "interval" : "30s" }},
"input" : {
"search" : {
"request" : {
"indices" : [ "logstash*" ],
"body" : {
"query" : {
"match" : { "message": "error" }
}
}
}
}
},
"condition" : {
"compare" : { "ctx.payload.hits.total" : { "gt" : 0 }}
},
"actions" : {
"log_error" : {
"logging" : {
"text" : "The number of errors in logs is
{{ctx.payload.hits.total}}"
}
}
}
}'

Чтобы можно было создать наблюдателя, у пользователя должна быть привилегия watcher_admin.
• trigger — используется для указания расписания, а именно — как часто должно выполняться наблюдение. Как только наблюдатель создан, его триггер регистрируется движком scheduler для корректного запуска наблюдателя.
Можно настроить несколько типов триггеров расписания для указания, когда наблюдатель должен начинать работу. Доступны следующие триггеры расписания: интервал, каждый час, каждый день, каждую неделю, каждый месяц, каждый год и cron.
В предыдущем фрагменте кода триггер был настроен с расписанием 30 с, что означает запуск наблюдателя каждые 30 с.
Пример установки ежечасного триггера. Следующий фрагмент кода показывает, как установить ежечасный триггер, который запускает наблюдатель каждую 45-ю минуту часа:
{
"trigger" : {
"schedule" : {
"hourly" : { "minute" : 45 }
}
}
}
Можно также указать массив минут. Следующий фрагмент кода показывает, как указать ежечасный триггер, который запускает наблюдателя каждую 15-ю и 45-ю минуту часа:
{
"trigger" : {
"schedule" : {
"hourly" : { "minute" : [ 15, 45 ] }
}
}
}
Пример для настройки наблюдателя, срабатывающего ежедневно в 8 ч вечера:
{
"trigger" : {
"schedule" : {
"daily" : { "at" : "20:00" }
}
}
}
Пример для настройки наблюдателя, срабатывающего каждую неделю в 10 ч утра по понедельникам и в 8 ч вечера по пятницам:
{
"trigger" : {
"schedule" : {
"weekly" : [
{ "on" : "monday", "at" : "10:00" },
{ "on" : "friday", "at" : "10:00" }
]
}
}
}
Пример настройки расписания с применением синтаксиса cron. Следующий фрагмент кода дает указание наблюдателю срабатывать ежечасно, каждую 45-ю минуту:
{
"trigger" : {
"schedule" : {
"cron" : "0 45 * * * ?"
}
}
}
• input — применяется для указания источника ввода для загрузки данных в контекст выполнения наблюдателя. Данные фигурируют как нагрузка наблюдателя (watcher payload) и будут доступны на последующих стадиях работы наблюдателя. Их можно будет использовать для создания условий или выполнения над ними действий. Вы можете получить доступ к нагрузке, используя переменную ctx.payload.*:
"input" : {
"search" : {
"request" : {
"indices" : [ "logstash*" ],
"body" : {
"query" : {
"match" : { "message": "error" }
}
}
}
}
}
Как видно из предыдущего фрагмента кода, ввод типа search используется для указания запроса, который должен быть выполнен в Elasticsearch для присвоения данным статуса нагрузки наблюдателя. Запрос выбирает все документы в индексах шаблона logstash*, которые содержат error в поле message.

Вы также можете указывать в разделе input следующие типы ввода: simple для загрузки статичных данных, http для загрузки ответов http и chain для предоставления серии вводов.
• condition — применяется для указания, условия в зависимости от нагрузки, для определения того, необходимо выполнять действие или нет:
"condition" : {
"compare" : { "ctx.payload.hits.total" : { "gt" : 0 }}
}
Как видно в предыдущем фрагменте кода, используется тип compare для определения наличия документов в нагрузке; если они есть, тогда будет выполнено действие.
Условие типа compare применяется для указания простых сравнений типа eq, noteq, gt, gte, lt и lte к значению в нагрузке наблюдателя.

Поддерживаются также следующие условия: always, которое всегда устанавливает условие наблюдателя в true; never, которое всегда устанавливает условие в false; array_compare выполняет сравнение с массивом значений, чтобы определить условия наблюдателя; script создает сценарий для определения условия наблюдателя.
• actions — применяется для указания одного или нескольких действий, которые необходимо предпринять, если условие наблюдателя становится равным true:
"actions" : {
"log_error" : {
"logging" : {
"text" : "The number of errors in logs is
{{ctx.payload.hits.total}}"
}
}
}
Как видно в предыдущем фрагменте кода, используется действие записи определенного текста в лог при выбранном состоянии наблюдателя. Запись выполняется в логи Elasticsearch. Количество ошибок вычисляется динамически с помощью поля (hits.total) в нагрузке. Для доступа к нагрузке предназначена переменная ctx.payload.*.

Наблюдатель поддерживает следующие типы действий: email, webhook, index, logging, hipchat, Slack и pagerduty.
Во время работы наблюдателя, как только условие соответствует требованиям, выполняется решение по настроенному действию: следует прервать или продолжить его. Основное назначение прерывания действия состоит в предотвращении слишком частого выполнения одного и того же действия для одного наблюдателя.
Наблюдатель поддерживает два типа прерывания.
• Прерывание на основе времени. Вы можете указать период прерывания с помощью параметра throttle_period как часть конфигурации действий или ограничить на уровне наблюдателя (касательно всех действий) частоту выполнения действия. Глобальный период прерывания по умолчанию — 5 с.
• Прерывание на основе ACK. Используя ACK Watch API, можно предотвращать повторное выполнение действия наблюдателя, пока условием наблюдения является true.
Наблюдатели хранятся в специальном индексе с названием .watches. Каждый раз, когда выполняется работа наблюдателя, в индексе истории наблюдателя (под названием .watches-history-6-*) сохраняется запись watch_record, которая содержит следующие сведения: описание наблюдателя, время работы, нагрузку, результат условия наблюдателя.

Пользователь с привилегией watcher_user может просматривать наблюдатели и историю их работы.
Уведомления в деле
Теперь, когда вы знаете, из чего состоит наблюдатель, поговорим о том, как создавать и удалять наблюдатели, а также управлять ими. Для этих действий можно использовать следующее:
• пользовательский интерфейс наблюдателей в Kibana;
• REST API наблюдателей в X-Pack.
Пользовательский интерфейс наблюдателей использует REST API наблюдателей для управления ими. В этом разделе мы рассмотрим процесс создания и удаления наблюдателей, а также управления ими с помощью соответствующего интерфейса Kibana.
Создание нового уведомления
Для создания наблюдателя зайдите в Kibana (http://localhost:5601) как пользователь elastic и перейдите на страницу Management (Управление); щелкните на ссылке Watcher (Наблюдатель) в разделе Elasticsearch (рис. 8.28).
Рис. 8.28
При нажатии кнопки Create New Watch (Создать новый наблюдатель) вы увидите два варианта создания уведомлений (рис. 8.29):
• Threshold Alert (Пороговое уведомление);
• Advanced Watch (Продвинутое наблюдение).
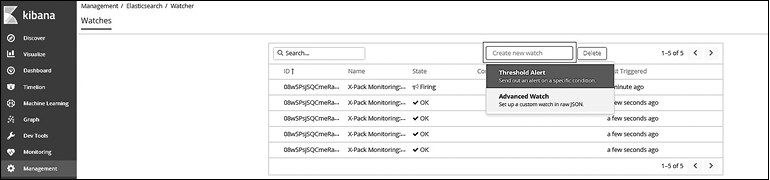
Рис. 8.29
Используя вариант Threshold Alert (Пороговое уведомление), можно создать уведомление, которое основано на определенном пороге для получения уведомлений, когда метрика выходит за пределы установленного порогового значения. На этой странице пользователи могут легко создавать уведомления порогового типа, не беспокоясь о необходимости работать напрямую с сырыми запросами JSON. Данный пользовательский интерфейс позволяет создавать уведомления только для индексов на базе времени (то есть индексов с меткой времени).
С помощью варианта Advanced Watch (Продвинутое наблюдение) можно создавать наблюдатели, работая напрямую с .json для API наблюдателей.

Для работы с пользовательским интерфейсом наблюдателей, а именно для создания, редактирования, удаления и деактивизации наблюдателей, необходим пользователь с привилегиями kibana_user и watcher_admin.
Пороговое уведомление
Нажмите кнопку Create New Watch (Создать новый наблюдатель) и выберите вариант Threshold Alert (Пороговое уведомление). Вы попадете на страницу пороговых уведомлений.
Укажите название уведомления; выберите индекс, который будет запрашиваться, поле времени и частоту триггера в пользовательском интерфейсе порогового уведомления (рис. 8.30).
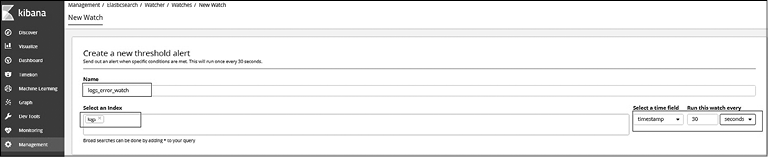
Рис. 8.30
Далее необходимо указать условие, которое приведет к срабатыванию уведомления. Во время изменения выражений/условий визуализация обновляется автоматически и пороговое значение и данные демонстрируются в виде красной и синей линии соответственно (рис. 8.31).
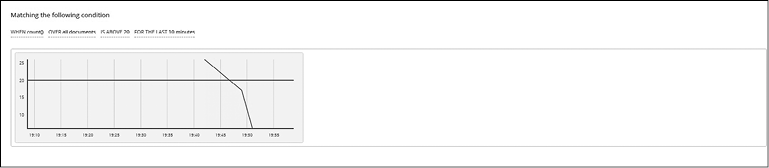
Рис. 8.31
Теперь укажите действие, которое будет выполнено при совпадении условия. Для этого нажмите кнопку Add new action (Добавить новое действие). Вы можете создать одно из трех действий: уведомление по электронной почте, по Slack и запись событий в лог. Можно выбрать одно или несколько действий (рис. 8.32).

Рис. 8.32
В конце нажмите кнопку Save (Сохранить) для создания наблюдателя. Наблюдатель будет сохранен в индексе watches, как показано на рис. 8.33.

Рис. 8.33
Продвинутое наблюдение
Нажмите кнопку Create New Watch (Создать нового наблюдателя) и выберите вариант Advanced Watch (Продвинутое наблюдение). Вы попадете на страницу настройки продвинутого наблюдения.
Укажите идентификатор и название наблюдателя и вставьте JSON для создания наблюдателя в области Watch JSON (Наблюдатель JSON), затем нажмите кнопку Save (Сохранить). Идентификатор наблюдателя присваивается в Elasticsearch при создании, тогда как для пользователя при работе с наблюдателями более удобным является название (рис. 8.34).
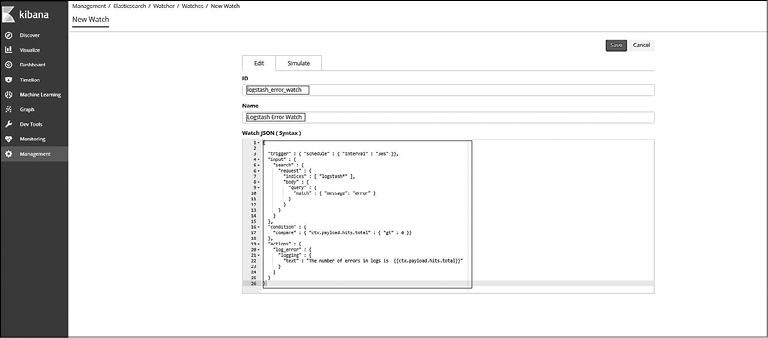
Рис. 8.34
Вкладка Simulate (Симуляция) предоставляет интерфейс для изменения частей наблюдателя с последующей проверкой их воспроизведения (рис. 8.35).
Рис. 8.35

Название наблюдателя будет сохранено в разделе метаданных тела наблюдателя. Можно использовать этот раздел при создании наблюдателя для хранения метаданных, тегов или иной информации.
После нажатия кнопки Save (Сохранить) наблюдатель будет сохранен в индексе watches, как показано на рис. 8.36.
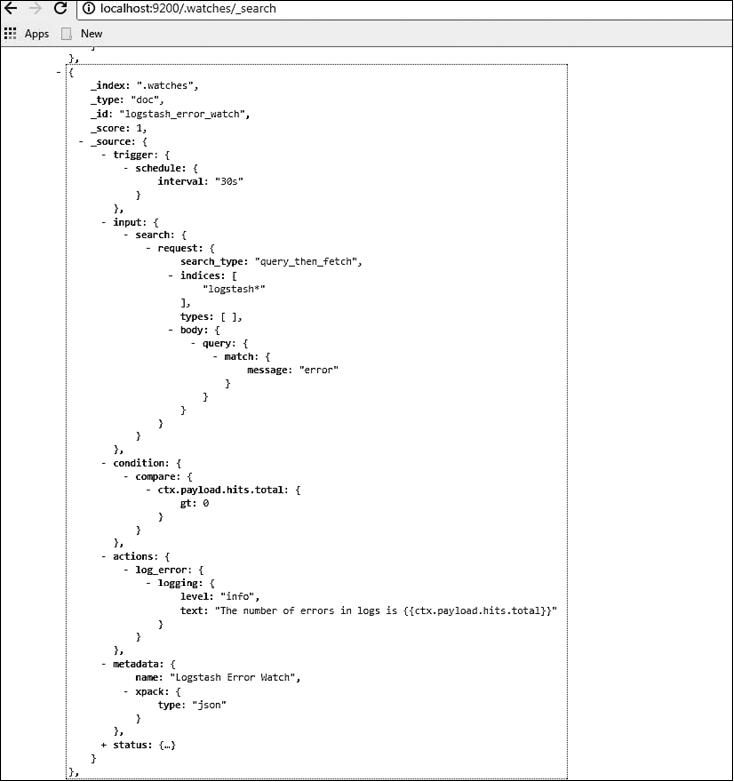
Рис. 8.36
Как удалить/деактивизировать/редактировать наблюдатель
Для удаления наблюдателя перейдите в интерфейс Management (Управление) и выберите Watches (Наблюдатели) в разделе Elasticsearch. В списке наблюдателей выберите один или несколько объектов, которые следует удалить, и нажмите кнопку Delete (Удалить) (рис. 8.37).
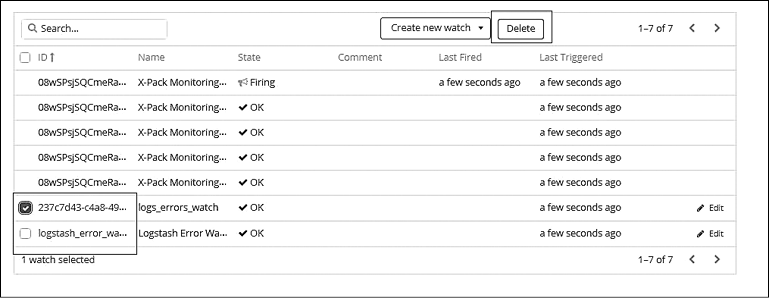
Рис. 8.37
Для деактивизации наблюдателя (то есть временного отключения его работы) перейдите в интерфейс Management (Управление) и выберите Watches (Наблюдатели) в разделе Elasticsearch. В списке наблюдателей выберите необходимый объект. При этом вы увидите историю наблюдения. Нажмите кнопку Deactivate (Деактивизировать). На этой странице, как говорилось выше, также можно удалить наблюдатель.
Щелчок на времени выполнения (ссылке) в истории наблюдателя покажет детали конкретной записи watch_record (рис. 8.38).
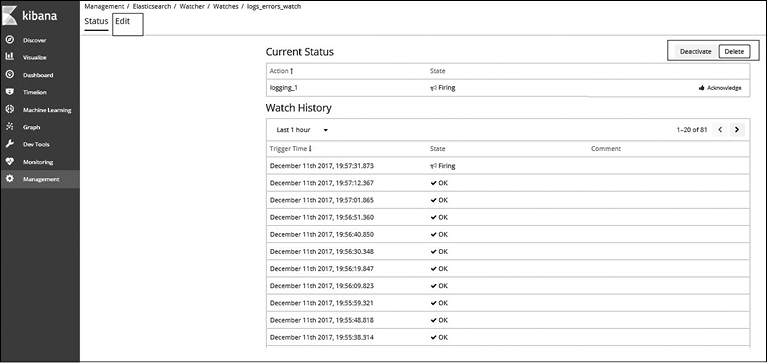
Рис. 8.38
Для редактирования наблюдателя перейдите на вкладку Edit (Редактирование) и внесите изменения. Для сохранения нажмите кнопку Save (Сохранить).
Резюме
Из этой главы вы узнали, как установить и сконфигурировать компоненты X-Pack в Elastic Stack и как настроить безопасность кластера путем создания пользователей и ролей. Вы также научились мониторить сервер Elasticsearch и получать уведомления, если данные изменяются или в них появляются ошибки.
В следующей главе мы соберем целое приложение, используя Elastic Stack для анализа данных и опираясь на все концепции, которые уже рассмотрели на данный момент.

