9. Запуск Elastic Stack в работу
В процессе изучения Elastic Stack вы разобрали много тем и получили подробное представление обо всех его компонентах. Вы уже должны хорошо разбираться в ядре Elasticsearch и его возможностях поиска и аналитики, а также знаете, как эффективно применять Logstash и Kibana для создания мощной платформы аналитики больших данных. Помимо этого, вы видели, как легко настроить безопасность и мониторинг больших данных, а также получать уведомления, анализировать диаграммы и внедрять машинное обучение с помощью X-Pack.
Для включения Elastic Stack в рабочий процесс необходимо быть в курсе распространенных подводных камней и знать некоторые шаблоны и стратегии, которые помогут без проблем запустить решение. В этой главе мы дадим советы по запуску Elasticsearch, Logstash, Kibana и других компонентов в работу.
Мы начнем с Elasticsearch, а затем перейдем к другим составляющим. Есть несколько способов запуска Elasticsearch в эксплуатацию. Различные факторы могут влиять на то, какой именно способ выберете вы. Чтобы вам было проще запустить проект на базе Elastic Stack, мы рассмотрим следующие темы.
• Размещение Elastic Stack в управляемом облаке.
• Размещение Elastic Stack на своем хостинге.
• Создание и восстановление резервных копий.
• Настройка названий индексов.
• Настройка шаблонов индексов.
• Моделирование данных временного ряда.
Для начала разберемся, как запустить Elastic Stack, разместив его в одном из поставщиков управляемого облачного хостинга. Такое решение не потребует дополнительных действий для настройки готового к работе кластера.
Размещение Elastic Stack в управляемом облаке
Облачные поставщики позволяют многократно упростить процесс настройки готового к работе кластера. Как пользователю, вам не потребуется выполнять низкоуровневую настройку или выбирать аппаратную часть и управлять ею, операционной системой и многими другими параметрами конфигурации Elasticsearch и Kibana.
Существует несколько поставщиков облачных сервисов, которые предоставляют управляемые кластеры Elastic Stack: Elastic Cloud, QBox.io, Bonsai и многие другие. В этом разделе мы рассмотрим, как начать работу с Elastic Cloud. Elastic Cloud — это официальное предложение от компании Elastic.co — основного участника в развитии разработки Elasticsearch и других компонентов Elastic Stack. При работе с Elastic Cloud мы изучим следующие темы.
• Настройка и запуск Elastic Cloud.
• Использование Kibana.
• Изменение настроек.
• Восстановление.
Настройка и запуск Elastic Cloud
Зарегистрируйтесь в Elastic Cloud по ссылке https://www.elastic.co/cloud/as-a-service/signup; для этого понадобится адрес электронной почты и его подтверждение. Вам будет предложено установить исходный пароль.
После установки пароля вы можете зайти в консоль Elastic Cloud по ссылке https://cloud.elastic.co. Консоль Elastic Cloud предлагает простой пользовательский интерфейс для управления вашими кластерами. Поскольку вы зарегистрировались с учетной записью для пробного периода, вы получаете 4 Гбайт ОЗУ и 96 Гбайт дискового пространства на ограниченное время.
При запуске кластера мы можем выбрать AWS (веб-сервисы Amazon) или GCE (движок вычислений Google). При входе вы можете создать кластер Elastic Cloud (рис. 9.1).
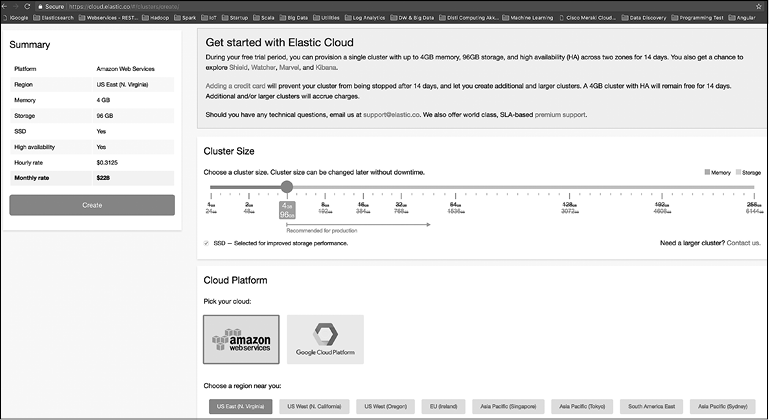
Рис. 9.1
Вы можете выбрать ОЗУ и дисковое пространство и решить, будете ли дублировать кластер в разных зонах доступности. Предоставляется также возможность настроить дополнительные плагины, которые могут понадобиться вам в кластере Elasticsearch. Рекомендуется выбрать последнюю доступную версию 6.х. На момент написания этой книги версия 6.0.0 была новейшей доступной в Elastic Cloud.
Введите название кластера и нажмите кнопку Create (Создать); ваш кластер будет создан и запущен с рабочей конфигурацией, в том числе безопасности. В базовую комплектацию также входит доступ Kibana. На данный момент вам будет предложено получить имя пользователя и пароль для входа в узлы Elasticsearch и Kibana. Запишите их. Вы также получите идентификатор облака, который пригодится вам при подключении облачного кластера к агентам beats и серверам Logstash.
При обзоре кластера вы должны увидеть следующую страницу (рис. 9.2).
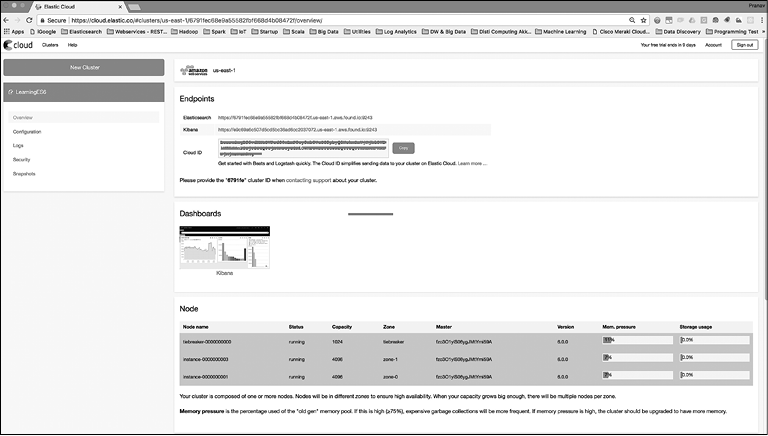
Рис. 9.2
Как видите, кластер запущен и работает. Вместе с ним запущен компонент Kibana, доступ к которому возможен по предоставленной URL-ссылке. Кластер Elasticsearch доступен по предоставленной безопасной ссылке HTTPS.
У этого кластера есть два узла: один в каждой зоне доступности AWS и один — разрешающий узел. Разрешающий узел необходим для выбора главного узла. Это особые узлы в Elastic Cloud, которые помогают в выборе нового главного узла в том случае, если отдельные узлы кластера становятся недоступными.
Теперь, когда все готово, приступим к работе!
Использование Kibana
Мы уже получили ссылку, по которой настроен доступ в Kibana, на странице обзора кластера в Elastic Cloud. Вы можете щелкнуть на ней для входа в интерфейс Kibana. В отличие от локального процесса Kibana, который мы создавали ранее, этот обладает защитой X-Pack. Для входа в систему вам необходимо указать имя и пароль, полученные ранее при создании кластера в Elastic Cloud, как описано в предыдущем разделе.
После входа в Elastic Cloud вы увидите интерфейс Kibana (рис. 9.3).
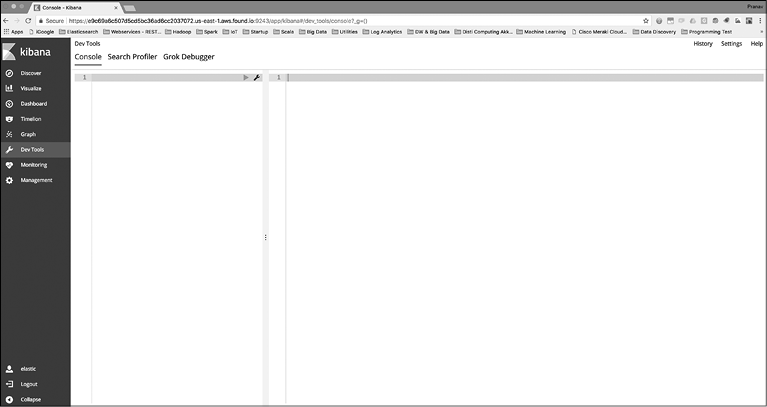
Рис. 9.3
На этой странице вы можете просматривать все индексы, анализировать данные вашего кластера Elasticsearch, а также выполнять их мониторинг.
Изменение настроек
Вы можете указать свои настройки для узлов Elasticsearch на вкладке Configuration (Конфигурация) в Elastic Cloud. Нельзя напрямую редактировать файл elasticsearch.yml в Elastic Cloud. Тем не менее можно использовать раздел под названием User Settings (Пользовательские настройки), с помощью которого разрешается редактировать набор настроек конфигурации.
Полный список параметров конфигурации, которые могут быть изменены при использовании Elastic Cloud, вы найдете в документации по ссылке https://www.elastic.co/guide/en/cloud/current/cluster-config.html#user-settings.
Восстановление
Elastic Cloud автоматически создает точку восстановления всех индексов вашего кластера с определенной периодичностью (каждые 30 мин). При необходимости можете восстановить свои данные. Процесс автоматизирован и не нуждается в дополнительных настройках или написании кода. Перейдите на вкладку Snapshots (Снепшоты), чтобы увидеть список доступных точек восстановления (снепшотов) (рис. 9.4).
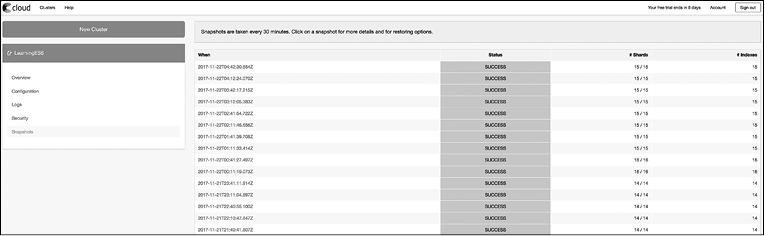
Рис. 9.4
Вы можете выбрать снепшот для восстановления и перейти на следующую страницу (рис. 9.5).
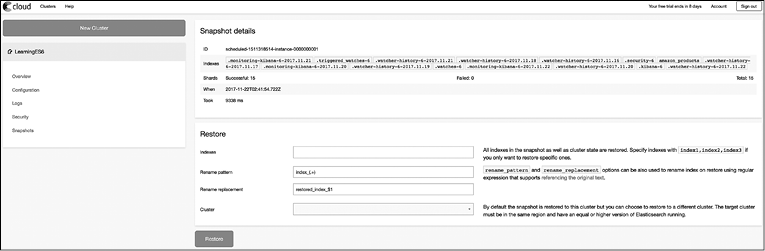
Рис. 9.5
Снепшот восстановления содержит сохраненное состояние для всех индексов кластера. Вы можете выбрать несколько индексов для восстановления, а также переименовать их в процессе. Восстановлению подлежат и некоторые кластеры.
Далее мы рассмотрим, как начать работу с Elastic Cloud, если вы планируете управлять компонентами Elastic Stack самостоятельно. Это называется самостоятельным хостингом в контексте того, что вы будете сами размещать систему и управлять ею.
Размещение Elastic Stack на своем хостинге
При самостоятельном хостинге Elastic Stack вы должны будете лично установить, настроить Elasticsearch и другие компоненты Elastic Stack и управлять ими. Это можно сделать двумя способами:
• используя внутренний хостинг;
• облачный хостинг.
Независимо от вашего выбора, то есть размещения Elastic Stack на внутреннем хостинге (ваш собственный датацентр) или в одном из облачных сервисов, таких как AWS, Azure или GCE, есть некоторые общие особенности, которые необходимо принимать во внимание. При самостоятельном хостинге вы столкнетесь со следующими задачами.
• Выбор аппаратной части.
• Выбор операционной системы.
• Настройка узлов Elasticsearch.
• Управление узлами Elasticsearch и их мониторинг.
• Особенности самостоятельного размещения в облаке.
Все вопросы, кроме последнего, имеют одинаковое решение, независимо от выбора облачного и собственного хостинга.
Выбор аппаратной части
Обычно Elasticsearch выполняет задачи обратного индекса, зависящие от памяти. Чем больше данных поместится в ОЗУ, тем выше будет производительность. Но это утверждение не работает для всех до единого случаев. Все зависит от типа ваших данных, операций над ними и объемов работы.
Не следует считать, что Elasticsearch выполняет все операции в памяти. Данные на диске также достаточно эффективно используются, особенно в случае агрегаций.

Все типы данных (кроме анализируемых строк) поддерживают особую структуру данных под названием doc_values — она организовывает данные на диске по принципу столбцов. Это полезно для операций сортировки и агрегации. Значение doc_values включено по умолчанию для всех типов данных, кроме анализируемых строк, следовательно, операции с ними работают по большей части с диска. Нет необходимости загружать эти поля в память для сортировки или агрегации.
Поскольку Elasticsearch может масштабироваться горизонтально, не так сложно сделать правильный выбор. Для начала лучше выбрать узлы с объемом ОЗУ от 16 до 32 Гбайт и около восьми ядер ЦП. Как вы увидите в следующих разделах, размер кучи JVM в Elasticsearch не может превышать 32 Гбайт; следовательно, нет смысла применять конфигурации с более чем 64 Гбайт ОЗУ. Рекомендуется использовать твердотельные SSD-диски, если вы планируете выполнять сложные агрегации.
Важным моментом является запуск сравнительных тестов (бенчмарков) для проверки производительности на текущем оборудовании, а добавлять или совершенствовать узлы можно по необходимости.
Выбор операционной системы
Предпочтительной операционной системой для запуска Elasticsearch и других компонентов Elastic Stack является Linux. Ваш выбор ОС будет зависеть в основном от технологий, используемых в вашей компании. Если организация использует ПО от Microsoft, вы можете запустить Elastic Stack и на Windows.
Настройка узлов Elasticsearch
Elasticsearch, который является сердцем Elastic Stack, нуждается в предварительной настройке. Большинство настроек можно оставить со стандартными значениями, но есть показатели, которые необходимо подобрать на уровне ОС или JVM.
Размер кучи JVM
Установите одинаковое значение параметров -Xms и -Xmx. Больший размер кучи позволит Elasticsearch держать в памяти больше данных для быстрого доступа к ним. Но есть и обратная сторона: когда куча JVM будет близка к заполнению, сборщик мусора JVM начнет полную сборку мусора. В этот момент все остальные процессы в Elasticsearch будут приостановлены. Чем больше размер кучи, тем длительнее будет эта пауза. Максимальный возможный размер кучи составляет около 32 Гбайт.
Не забывайте также, что следует распределить не более чем 50 % доступного ОЗУ для Elasticsearch JVM. Это делается для того, чтобы система имела в распоряжении достаточно памяти для работы кэша файловой системы Apache Lucene. Все данные, хранящиеся в узле Elasticsearch, рассматриваются как индексы Apache Lucene, которому необходима ОЗУ для быстрого доступа к файлам.
Таким образом, если вы планируете хранить огромные объемы данных в Elasticsearch, нет смысла иметь один узел с более чем 64 Гбайт ОЗУ (50 % от которой — 32 Гбайт — максимальный размер кучи). Рекомендуется добавлять больше узлов, если вы заинтересованы в масштабировании.
Отключение файла подкачки
При включенном файле подкачки ОС нередко имеет свойство выгружать память, использованную приложением, на диск, чтобы другие программы могли задействовать больше ОЗУ.
В узле Elasticsearch это может привести к тому, что ОС начнет выгружать память кучи Elasticsearch. Такой процесс записи содержимого ОЗУ на диск с последующей обратной записью с диска в ОЗУ может замедлить работу. По этой причине следует отключать файл подкачки в узле Elasticsearch.
Дескрипторы файлов
В операционных системах Linux и macOS ограничено количество дескрипторов открытых файлов, которые может хранить процесс. Зачастую необходимо увеличивать это ограничение, так как значение по умолчанию слишком мало для работы Elasticsearch.
Пулы потоков и сборщик мусора
В Elasticsearch предусмотрено много видов операций, таких как индексирование, поиск, сортировка и агрегации. Кроме того, система использует пул потоков JVM для выполнения своих задач. Рекомендуется не менять настройки, связанные с пулами потоков в Elasticsearch, так как обычно это приводит скорее к негативным последствиям, нежели к улучшению производительности. Еще один компонент в Elasticsearch, настройки которого не стоит менять, — сборщик мусора.
Управление Elasticsearch и ее мониторинг
Когда вы используете самостоятельный хостинг Elasticsearch, все вопросы мониторинга и управления кластером ложатся на вас. Приходится мониторить статус процесса Elasticsearch, память и дисковое пространство в узле. Если узел по любой причине выходит из строя или становится недоступным, его необходимо запустить повторно.
Для регулярного резервного копирования необходимо делать снепшоты — точки восстановления индексов Elasticsearch. Мы еще обсудим функционал снепшотов для резервного копирования. Большую часть мониторинга можно выполнять средствами X-Pack и Kibana, но управление должно происходить вручную.
Запуск в контейнерах Docker
Docker — программное обеспечение для автоматизации развертывания и управления приложениями в средах с поддержкой контейнеризации. Его преимущество состоит в том, что программное обеспечение упаковано внутри легковесного контейнера, который имеет минимум накладных расходов по сравнению с виртуальной машиной. В сочетании с этим и большим пулом общедоступных образов Docker является отличным способом запускать программное обеспечение в работу без особых настроек.
Официальные образы Elasticsearch в формате Docker доступны для скачивания в различных видах.
• Elasticsearch с базовой лицензией X-Pack.
• Elasticsearch с полной лицензией X-Pack и 30-дневным пробным периодом.
• Версия Elasticsearch с открытым исходным кодом без X-Pack.
Запуск Elasticsearch внутри контейнера Docker так же прост, как и установка Docker и выполнение команды docker pull с образом Elasticsearch на ваш выбор. Следующие простые команды запустят Elasticsearch 6.0.0 в одном узле, если в вашей системе установлен Docker.
docker pull docker.elastic.co/elasticsearch/elasticsearch:6.0.0
docker run -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node"
docker.elastic.co/elasticsearch/elasticsearch:6.0.0
Подробнее узнать о запуске Elasticsearch в рабочей среде Docker вы можете в документации по следующей ссылке: https://www.elastic.co/guide/en/elasticsearch/reference/6.0/docker.html.
Особенности запуска в облаке
Для самостоятельного размещения Elastic Stack в облачном сервисе вы можете выбрать таких поставщиков, как AWS, Microsoft Azure, GCE и пр. Они предоставляют вычислительные и сетевые ресурсы, виртуальные частные облака и многое другое, что понадобится для контроля ваших серверов. В сравнении с запуском на собственных аппаратных ресурсах использование облачного поставщика имеет следующие преимущества.
• Нет необходимости инвестировать в аппаратное обеспечение.
• Можно повышать или понижать мощность серверов.
• Допускается при необходимости добавлять или удалять серверы.
При первом запуске обычно сложно понять, сколько именно ресурсов ЦП, ОЗУ необходимо. Облачный хостинг предоставляет вам гибкость, которая позволяет начать работу на одном типе конфигурации оборудования, а при необходимости — повысить или понизить вычислительную мощность или добавить/удалить узлы без дополнительных капиталовложений. В качестве примера мы рассмотрим ЕС2 и постараемся разобраться, что же стоит учитывать при выборе. В целом рекомендации будут одинаковыми независимо от облачного поставщика. Далее приведен список вопросов, которые следует рассмотреть при выборе AWS EC2.
• Выбор типа реализации.
• Изменение портов. Не оставляйте порты открытыми!
• Запросы прокси.
• Связка HTTP с локальным адресом.
• Установка плагина исследования EC2.
• Установка плагина репозитория S3.
• Настройка периодического резервного копирования.
Рассмотрим эти вопросы по порядку.
Выбор типа реализации
ЕС2 предлагает разные типы реализаций для различных требований. Стандартным стартовым выбором для Elasticsearch считается реализация m3.2xlarge; она имеет восемь ядер ЦП, 30 Гбайт ОЗУ и два твердотельных диска на 80 Гбайт. Рекомендуется запускать бенчмарки и мониторить нагрузку на ресурсы ваших узлов. В зависимости от результатов вы можете сужать или расширять ресурсную базу.
Изменение портов по умолчанию. Не оставляйте порты открытыми!
Запуск любого сервиса в облаке сопряжен с определенными рисками. Важно учесть, что ни один из портов, используемых Elasticsearch, не должен быть доступен из Интернета. В ЕС2 вы можете детально контролировать, какие порты доступны и с каких IP-адресов или подсетей. В целом нет необходимости открывать какие-либо порты для доступа извне, кроме порта 22 для удаленного доступа.
По умолчанию Elasticsearch использует порт 9200 для трафика HTTP и 9300 — для сообщения между узлами. Рекомендуется заменить эти порты по умолчанию другими, отредактировав файл elasticsearch.yml во всех ваших узлах.
Запросы прокси
Используйте обратные прокси, такие как nginx или Apache, для своих запросов к Elasticsearch/Kibana.
Связка HTTP с локальным адресом
Вам следует запускать узлы Elasticsearch в VPC (Virtual Private Cloud). С недавних пор AWS создает все узлы в VPC. Узлы, которые не нуждаются в клиентском интерфейсе, принимают запросы от клиентов через HTTP. Это может быть определено параметром http.host в файле elasticsearch.yml. Вы можете больше узнать о связках хоста/порта HTTP в документации по ссылке https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-http.html.
Установка плагина исследования EC2
Когда узлы Elasticsearch расположены в одной сети, они находят свои пиры через мультикаст. Это хорошо работает в обычной локальной сети. В случае с ЕС2 сеть является общей и автоматическое распознавание при связи узлов между собой не будет работать. Для этого необходимо установить плагин исследования ЕС2 во всех узлах, что позволит анализировать новые узлы.
Для установки плагина исследования ЕС2 во все узлы выполните действия согласно инструкции по следующей ссылке: https://www.elastic.co/guide/en/elasticsearch/plugins/current/discovery-ec2.html.
Установка плагина репозитория S3
При работе с Elasticsearch важно регулярно делать резервные копии, чтобы быстро восстановить данные в случае фатального сбоя или если требуется откатить систему до последнего исправного состояния. Более детально о сохранении и восстановлении резервных копий с помощью API снепшотов/восстановления Elasticsearch мы поговорим в следующем разделе. Чтобы резервные копии создавались регулярно и хранились в надежном централизованном месте, необходимо настроить механизм снепшотов. Если вы запускаете Elasticsearch на ЕС2, имеет смысл хранить снепшоты в сегменте AWS S3.

S3 расшифровывается как Simple Storage Service (простой сервис хранения). Он может масштабироваться и является надежным местом для хранения больших объемов данных. Предоставляет защиту для ваших данных и доступ с многих различных платформ. S3 соответствует самым строгим требованиям благодаря широким возможностям обеспечения безопасности. Нередко этот сервис является самым предпочтительным решением для долгосрочного хранения данных, особенно когда системы, которые производят эти данные, размещены на AWS.
Плагин репозитория S3 может быть установлен с помощью следующей команды; его необходимо установить в каждый узел вашего кластера Elasticsearch:
sudo bin/elasticsearch-plugin install repository-s3
Настройка периодического резервного копирования
Как только ваш репозиторий S3 настроен, важно убедиться, что периодически создаются резервные копии (снепшоты). Это значит, что нам необходимо запланированное задание, которое будет создавать точки восстановления с регулярными интервалами. Интервал может составлять 15, 30 мин, 1 ч и т.д. в зависимости от чувствительности данных. Мы рассмотрим процесс настройки резервного копирования и восстановления далее в этой главе.
На данном этапе мы разобрались, как запустить Elasticsearch в управляемом облаке или в условиях самостоятельного хостинга. Если вы выбрали последний вариант, придется настроить процесс резервного копирования и восстановления во избежание потерь данных. Информация из следующего раздела применима только в том случае, если вы используете собственный хостинг для кластера Elasticsearch.
Резервное копирование и восстановление
Наличие резервных копий очень важно, если понадобится восстановить данные в случае фатального сбоя. Настоятельно рекомендуется сохранять все ваши данные с фиксированным интервалом времени и хранить достаточное количество резервных копий. Это обычная стратегия. Ваш кластер может быть расположен на внутреннем хостинге, в собственном датацентре либо на облачном хостинге наподобие AWS с возможностью управлять кластером собственноручно.
В этом разделе мы рассмотрим следующие темы.
• Настройка репозитория для снепшотов.
• Создание снепшотов.
• Восстановление данных из выбранного снепшота.
Настройка репозитория для снепшотов
Первый шаг в создании регулярного резервного копирования данных — настройка репозитория для хранения снепшотов (точек восстановления). Их можно хранить в разных местах:
• в общей файловой системе;
• в облаке распределенных файловых систем (S3, Azure, GCS или HDFS).
Выбор способа хранения снепшотов зависит от того, где размещен ваш кластер Elasticsearch и какие параметры хранения доступны.
Сначала рассмотрим самый простой способ с использованием общей файловой системы.
Общая файловая система. Когда у вашего кластера есть общая файловая система, которая доступна со всех узлов кластера, вам нужно убедиться, что она доступна по общему пути. Следует примонтировать выбранную общую папку во всех узлах и добавить путь к этой папке. Общий путь к монтированной файловой системе необходимо добавить в файл elasticsearch.yml в каждом узле следующим образом:
path.repo: ["/mount/es_backups"]

Если ваш кластер содержит единственный узел и вы не запустили полноценный распределенный кластер, нет необходимости настраивать общий диск. Параметр path.repo может быть указан и для локальной папки вашего узла. Запускать рабочий сервер в кластере из одного узла не рекомендуется.
Как только указанная строка добавлена в файл config/elasticsearch.yml во всех ваших узлах, их необходимо перезапустить.
Следующий шаг — регистрация названного репозитория под зарегистрированной папкой. Для этого выполняется команда curl, с помощью которой мы регистрируем названный репозиторий с названием backups:
curl -XPUT 'http://localhost:9200/_snapshot/backups' -H
'Content-Type: application/json' -d '{
"type": "fs",
"settings": {
"location": "/mount/es_backups/backups",
"compress": true
}
}'
Вам потребуется заменить параметр localhost именем хоста или IP-адресом одного из узлов вашего кластера. Параметр type указан fs для общей файловой системы. Тело параметра settings зависит от значения параметра type.
Поскольку в данный момент мы ищем репозиторий общей файловой системы, тело параметра settings должно быть настроено особым образом. Параметр location указан в виде абсолютного пути, он должен вести к одной из папок, которые зарегистрированы с параметром path.repo в файле elasticsearch.yml. Если location не является абсолютным, Elasticsearch посчитает его относительным путем из параметра path.repo. Параметр compress сохраняет снепшоты в сжатом виде.
Облако распределенных файловых систем
Если вы запустили кластер Elasticsearch в сервисе AWS, Azure или Google Cloud, имеет смысл хранить точки восстановления (снепшоты) в альтернативном месте, предоставляемом облачной платформой. Такое хранилище будет более надежным и устойчивым к сбоям, чем общий диск.
Elasticsearch имеет официальные плагины, которые позволяют вам хранить снепшоты в S3. Все, что вам необходимо сделать, — установить плагин репозитория S3 во все узлы вашего кластера и настроить репозиторий по аналогии с тем, как мы настраивали репозиторий общей файловой системы:
curl -XPUT 'http://localhost:9200/_snapshot/backups' -H 'Content-Type:
application/json' -d '{
"type": "s3",
"settings": {
"bucket": "bucket_name",
"region": "us-west",
...
}
}'
В качестве type должен быть указан s3, а параметр settings должен иметь соответствующие значения для s3.
Создание снепшотов
Как только репозиторий настроен, мы можем создавать снепшоты с названиями на основе определенных репозиториев:
curl -XPUT
'http://localhost:9200/_snapshot/backups/backup_201710101930?pretty' -H
'Content-Type: application/json' -d'
{
"indices": "bigginsight,logstash-*",
"ignore_unavailable": true,
"include_global_state": false
}'
В этой команде мы указали, что хотим создать снепшот в репозитории backups с именем backup_201710101900. Имя снепшота может быть любым, но оптимально его сделать таким, чтобы оно в дальнейшем помогало в идентификации. Одна из типичных стратегий — настройка создания снепшота каждые 30 минут с именем, содержащим префиксы вида backup_yyyyMMddHHmm. При неполадках вы сможете легко идентифицировать необходимый файл для восстановления.
При настройках по умолчанию снепшоты действуют по нарастанию. Лишние данные в них не хранятся.
Не исключено, что при периодической записи снепшотов вам понадобится просмотреть список всех имеющихся точек восстановления. Для этого выполните следующую команду:
curl -XGET 'http://localhost:9200/_snapshot/backups/_all?pretty'
Восстановление из определенного снепшота
При необходимости вы можете выбрать определенную точку восстановления с помощью следующей команды:
curl –XPOST 'http://localhost:9200/_snapshot/backups/backup_201710101930/_restore'
Таким образом мы восстановим систему из снепшота backup_201710101930 из репозитория резервного копирования.
Настроив периодичность создания снепшотов, мы обеспечили безопасность на случай возникновения любых неполадок. У нас есть кластер, который можно восстановить в любой критической ситуации. Помните, что вывод снепшотов должен находиться в надежном хранилище. Как минимум не стоит хранить их в том же кластере Elasticsearch; необходимо выбрать другое хранилище, лучше всего надежную файловую систему с высоким уровнем доступности, такую как S3, HDFS и пр.
На данный момент в этой главе мы запустили кластер высокого уровня надежности с регулярным резервным копированием. В следующих разделах мы рассмотрим, как действовать в некоторых распространенных ситуациях моделирования данных. Мы разберем несколько базовых стратегий для настройки псевдонимов индексов, шаблонов индексов, моделирования данных временного ряда и пр.
Присвоение псевдонимов индексам
Псевдонимы индексов позволяют создавать псевдоним для одного или нескольких индексов или шаблонов названий индексов. Чтобы узнать принцип работы псевдонимов, мы рассмотрим следующие темы.
• Что такое псевдонимы индексов.
• Чем могут помочь псевдонимы индексов.
Что такое псевдонимы индексов
Псевдоним индекса предоставляет дополнительное название для индекса; его можно указать следующим образом:
POST /_aliases
{
"actions" : [
{ "add" : { "index" : "index1", "alias" : "current_index" } }
]
}
В данном случае index1 можно найти по псевдониму current_index. Аналогичным образом допускается удалить псевдоним индекса, используя действие _aliases в REST API:
POST /_aliases
{
"actions" : [
{ "remove" : { "index" : "index1", "alias" : "current_index" } }
]
}
Выше вы видите, как удалить псевдоним current_index. В одном вызове в API _aliases можно скомбинировать два действия. При комбинировании операции выполняются автоматически. Например, следующий вызов будет абсолютно прозрачным для клиента:
POST /_aliases
{
"actions" : [
{ "remove" : { "index" : "index1", "alias" : "current_index" } },
{ "add" : { "index" : "index2", "alias" : "current_index" } }
]
}
До вызова псевдоним current_index ссылался на индекс index1, а после вызова будет ссылаться на index2.
Чем могут помочь псевдонимы индексов
После запуска сервера в работу возможна ситуация, когда необходимо переиндексировать данные из одного индекса в другой. Возможно, у нас есть программы, разработанные на Java, Python, .NET или в определенных программных средах, а в них — ссылки на эти индексы. Если индексы изменятся с index1 на index2, потребуется вносить соответствующие изменения во всех клиентских приложениях.
В таких ситуациях пригодятся псевдонимы. Благодаря им достигается дополнительная гибкость, которую рекомендуется использовать в работе. Ключевым фактором является назначение вашему рабочему индексу псевдонима, который будет использован в настройках ваших приложений вместо фактического названия индекса.
Если требуется изменить текущий рабочий индекс, мы просто обновим настройки псевдонима так, чтобы он ссылался на новый индекс вместо старого. Используя эту функцию, мы можем избежать потерь времени при миграции данных или переиндексировании. Псевдонимы работают по известному в компьютерной науке принципу: дополнительный уровень косвенности может решить большинство проблем (более детально — по ссылке https://en.wikipedia.org/wiki/Indirection).
Здесь описаны не все функции, предоставляемые псевдонимами; среди них есть такие, как возможность использования шаблонов индекса, маршрутизация, возможность указывать фильтры и многое другое. Мы рассмотрим псевдонимы индексов и создание временных индексов далее в этой главе.
Настройка шаблонов индексов
Важным шагом в настройке вашего индекса является определение разметки типов, количества шардов, реплик и другие настройки. В зависимости от сложности типов в вашем индексе этот шаг может потребовать существенного количества настроек.
Шаблоны позволяют вам создавать индексы по уже выбранному образцу, избавляя от необходимости создавать каждый индекс вручную. С помощью шаблонов индексов вы можете указать настройки и разметку для создаваемого индекса. Для понимания процесса выполним следующие шаги.
1. Определение шаблона индекса.
2. Создание индексов на ходу.
Предположим, что нам нужно хранить данные датчиков различных устройств и требуется каждый день создавать новый индекс. В начале каждого дня должен создаваться индекс — каждый раз, когда индексируется первая запись показаний датчика. Далее мы рассмотрим подробнее этот пример, а также причину использования временных индексов.
Определение шаблона индекса
Начнем с определения шаблона индекса:
PUT _template/readings_template 1
{
"index_patterns": ["readings*"], 2
"settings": { 3
"number_of_shards": 1
},
"mappings": { 4
"reading": {
"properties": {
"sensorId": {
"type": "keyword"
},
"timestamp": {
"type": "date"
},
"reading": {
"type": "double"
}
}
}
}
}
В этом вызове _template мы определили следующие настройки.
1. Шаблон с названием readings_template.
2. Шаблоны названий индекса, которые соответствуют этому шаблону. Мы создали readings* как единственный шаблон индекса. При любой попытке записи в индекс, которого не существует, но который соответствует такому шаблону, будет использован данный шаблон.
3. Настройки, которые будут применяться к созданному индексу из этого шаблона.
4. Разметка, которая будет применяться к созданному индексу из шаблона.
Попробуем занести данные в этот новый индекс.
Создание индекса на ходу
Если любой клиент пытается индексировать данные для определенного датчика устройства, должно использоваться название индекса с добавлением к нему значения текущего дня в формате yyyy-mm-dd (указывается после параметра readings). Вызов данных индекса для 2017-01-01 будет выглядеть следующим образом:
POST /readings-2017-01-01/reading
{
"sensorId": "a11111",
"timestamp": 1483228800000,
"reading": 1.02
}
Когда вставляется первая запись для даты 2017-01-01, клиент должен использовать название индекса readings-2017-01-01. Поскольку этот индекс еще не существует, а мы создали соответствующий шаблон, Elasticsearch создает новый индекс с помощью указанного шаблона. В результате разметка и настройки, которые мы определили, применяются к этому индексу.
Таким образом создаются индексы на базе шаблонов. В следующем разделе мы рассмотрим, почему эти типы временных индексов полезны и как их использовать в работе с данными временного ряда.
Моделирование данных временного ряда
Нередко приходится хранить в Elasticsearch данные временного ряда. Обычно создается один индекс для всех документов. Ситуация, когда один огромный индекс содержит все документы, является типичным примером, который имеет свои ограничения, особенно учитывая следующие причины.
• Масштабирование индекса с непредсказуемым объемом через некоторое время.
• Изменение разметки со временем.
• Автоматическое удаление более старых документов.
Рассмотрим проявление каждой проблемы при выборе одного монолитного индекса.
Масштабирование индекса с непредсказуемым объемом через некоторое время
Одно из самых сложных решений при создании кластера Elasticsearch и его индексов — выбор количества основных шардов и количества его реплик.
Разберемся, когда количество шардов становится важным.
Единица параллельности в Elasticsearch
Во время создания индекса требуется определить количество шардов. После создания индекса это значение изменить невозможно. Единого золотого правила для определения верного количества шардов на момент создания индекса не существует. Фактически количество шардов влияет на уровень параллельности в индексе. Разберемся в этом на примере того, как может быть выполнен поисковый запрос.
Когда клиент отправляет запрос поиска или агрегации, сначала его получает один из узлов кластера. Этот узел работает как координатор запроса. Координирующий узел отправляет запросы на все шарды кластера и ждет ответа от каждого из них. Как только ответы получены, координирующий узел собирает их в единый файл и отсылает изначальному клиенту.
Это означает, что чем больше у вас шардов, тем меньше работы придется выполнять каждому из них и уровень параллельности может быть увеличен.
Но можно ли выбрать произвольно большое количество шардов? Рассмотрим это в следующих подразделах.
Как количество шардов влияет на оценку релевантности
Выбор большого количества малых шардов не всегда является хорошим решением, поскольку может повлиять на релевантность в результатах поиска. В контексте поисковых запросов оценка релевантности рассчитывается внутри контекста шарда. Относительный процент встречаемости документов считается в пределах контекста каждого шарда, а не по всем шардам. Поэтому количество шардов может влиять на общую оценку в рамках запроса. В частности, не стоит использовать слишком много шардов для решения проблемы масштабирования в будущем.
Как количество шардов влияет на точность агрегаций
По аналогии с поисковым запросом запрос агрегации также управляется с помощью узла координации. Предположим, клиент запросил агрегацию терминов для поля, которое может содержать большое количество уникальных значений. По умолчанию агрегация терминов возвращает клиенту десять наиболее подходящих (топ) терминов.
Для координирования выполнения терм-запроса узел координации не запрашивает все сегменты из всех шардов. Шарды опрашиваются для получения лучших n сегментов. По умолчанию значение n равно параметру size агрегации терминов, то есть количеству лучших сегментов, которые запросил клиент. Таким образом, если клиент запросил топ-10 терминов, координирующий узел вернет топ-10 сегментов из каждого шарда.
Поскольку данные могут быть распределены по шардам особым образом, некоторые из шардов могут не иметь определенных сегментов, даже несмотря на то, что эти сегменты могут входить в топ в некоторых шардах. Если определенный сегмент входит в топ-n сегментов в одном из шардов и не входит в топ-n в другом, он не будет учитываться в общем счете агрегации в координирующем узле. Большое количество шардов используется для масштабирования в будущем, но не увеличивает точность агрегаций.
Теперь вы понимаете, почему важно правильно выбрать количество шардов и почему это сложное решение. Далее мы рассмотрим, как изменение разметки индексов усложняется со временем.
Изменение разметки со временем
Как только индекс создан и в нем начинают сохраняться документы, требования к нему могут меняться.
Если схема меняется, с данными может происходить следующее.
• Добавление новых полей.
• Удаление существующих полей.
Добавление новых полей
Когда первый документ с новым полем индексируется, разметка нового поля создается автоматически, если она еще не существует. Для создания разметки Elasticsearch определяет тип данных для поля, основываясь на значении этого поля в первом документе. Разметка для одного конкретного типа документов со временем может увеличиваться.
Как только документ с новым полем проиндексирован, разметка для этого нового поля создается и сохраняется.
Удаление существующих полей
С течением времени требования к проекту могут меняться. Некоторые поля могут перестать иметь значение и не использоваться. В случае с индексами Elasticsearch не используемые более поля не удаляются автоматически; разметка продолжает находиться в индексе для всех полей, которые когда-либо были проиндексированы. Каждое дополнительное поле в Elasticsearch потребляет ресурсы; это особенно актуально, если у вас сотни или тысячи файлов. Если у вас очень большое количество неиспользуемых полей, это может привести к увеличению нагрузки на кластер.
Автоматическое удаление более старых документов
Ни в одном кластере нет бесконечного ресурса для вечного хранения данных. Если объемы ваших данных растут, вы можете захотеть хранить в Elasticsearch только необходимые данные. Обычно в Elasticsearch предпочтительно хранить данные за последние несколько недель, месяцев или лет, в зависимости от случая.
До версии Elasticsearch 2.х это достигалось благодаря указанию в отдельных документах времени жизни (time to live, TTL). Предоставлялась возможность настроить время нахождения каждого документа в индексе. Но функция TTL была удалена из версии 2.х и далее по причине того, что накладно настраивать TTL для каждого документа.
Мы обсудили проблемы, с которыми можно столкнуться при работе с данными временного ряда. Теперь рассмотрим, как использовать временные индексы для разрешения этих проблем. Временные индексы также называются индексом «в период времени».
Как временный индекс решает эти проблемы
Вместо того чтобы работать с одним монолитным индексом, теперь мы можем создать один индекс на период времени. Периодом может быть один день, неделя, месяц или произвольный отрезок времени. Например, в нашем случае в разделе Index Template (Шаблоны индексов) мы выбрали индекс «в день». Названия индексов будут выглядеть соответственно — у нас были индексы с названиями readings-2017-01-01, readings-2017-01-02 и т.д. Если бы мы выбрали индекс «в месяц», названия выглядели бы следующим образом: readings-2017-01, readings-2017-02, readings-2017-03 и т.д.
Посмотрим, как эта схема решает проблемы, перечисленные ранее.
Масштабирование с временным индексом
Поскольку мы более не используем монолитный индекс, который хранит все-все данные, упрощается масштабирование вверх/вниз. Количество шардов не выбирается заранее и навсегда. Начните с предполагаемого начального количества шардов для выбранного периода времени. Это количество можно задать в шаблоне индекса.
С каждым периодом времени вы имеете шанс подкорректировать шаблон индекса: увеличить или уменьшить количество шардов при создания следующего индекса.
Изменение разметки со временем
Изменять разметку становится проще, поскольку мы можем просто обновить шаблон индекса, который используется для создания новых индексов. Когда шаблон индекса обновлен, новый индекс создается для нового периода времени и, следовательно, применяется новая разметка.
С каждым новым периодом времени есть возможность внести изменения.
Автоматическое удаление старых документов
При использовании временных индексов удаление старых документов становится проще. Мы можем просто отсечь старые индексы вместо того, чтобы удалять отдельные документы. Если бы мы использовали месячные индексы и хотели сохранять данные на протяжении шести месяцев, то могли бы удалить все индексы старше шести месяцев. Поиск и удаление старых индексов можно настроить по расписанию.
Как вы уже видели в этом разделе, настройка индекса «в период времени» имеет очевидные преимущества при работе с данными временного ряда.
Резюме
В этой главе мы обсудили важные техники, которые пригодятся при запуске в работу вашего следующего приложения на базе Elastic Stack. Мы рассмотрели различные варианты размещения, включая собственный и облачный хостинг. Мы разобрались в использовании управляемого облачного сервиса, такого как Elastic Cloud, а также в размещении Elastic Stack на самостоятельном хостинге. Разобрали некоторые распространенные проблемы и их решения, имеющие отношение к обоим типам размещения вашего кластера.
Дополнительно мы рассмотрели различные методы, которые могут быть полезными при запуске Elastic Stack в эксплуатацию. Среди них использование псевдонимов индексов, шаблонов индексов, моделирование данных временного ряда. Разумеется, это не всеобъемлющее руководство, которое могло бы охватить все нюансы внедрения Elastic Stack. Но в книге приведено достаточно информации, чтобы вы могли успешно запустить проект на базе Elastic Stack в работу.
В следующей главе на базе полученных знаний мы построим приложение для аналитики данных датчиков.

