10. Создание приложения для анализа данных с датчиков
Из предыдущей главы вы узнали, как можно запустить в работу приложение на базе Elastic Stack. Теперь попробуем применить эти концепции на практике, при работе с реальным приложением. В этой главе вы собственноручно создадите такое приложение на базе Elastic Stack, которое способно обрабатывать большие объемы данных. И примените в процессе все знания, полученные ранее.
В этой главе мы рассмотрим следующие темы.
• Введение в приложение.
• Моделирование данных в Elasticsearch.
• Настройка базы метаданных.
• Создание контейнера данных Logstash.
• Отправка данных в Logstash через HTTP.
• Визуализация данных в Kibana.
Введение в приложение
IoT (Internet of Things — «Интернет вещей») стал причиной появления широкого спектра приложений. Он может быть определен следующим образом:
Интернет вещей (ИВ) является коллективной сетью соединенных между собой смарт-устройств, которые могут общаться между собой, передавая данные и обмениваясь информацией через Интернет.
Устройства ИВ подключены к Интернету, снабжены различными типами датчиков, которые собирают данные и передают их по Cети. Эти данные можно хранить, анализировать и изменять в режиме реального времени. Количество подключенных устройств будет стремительно расти; согласно данным «Википедии», к 2020 году ожидается 30 миллиардов подключенных устройств. Поскольку каждое устройство может получать текущее значение метрики и транслировать его через Интернет, результатом будут большие объемы данных.
В последнее время появилось большое количество типов датчиков, которые служат для измерения температуры воздуха, влажности, света, движения; они могут использоваться в различных приложениях. Каждый датчик может быть запрограммирован для считывания текущих показателей и отправки их по Cети.
Рассмотрим рис. 10.1, на котором показано, как подключенные устройства и датчики отправляют данные в Elastic Stack.
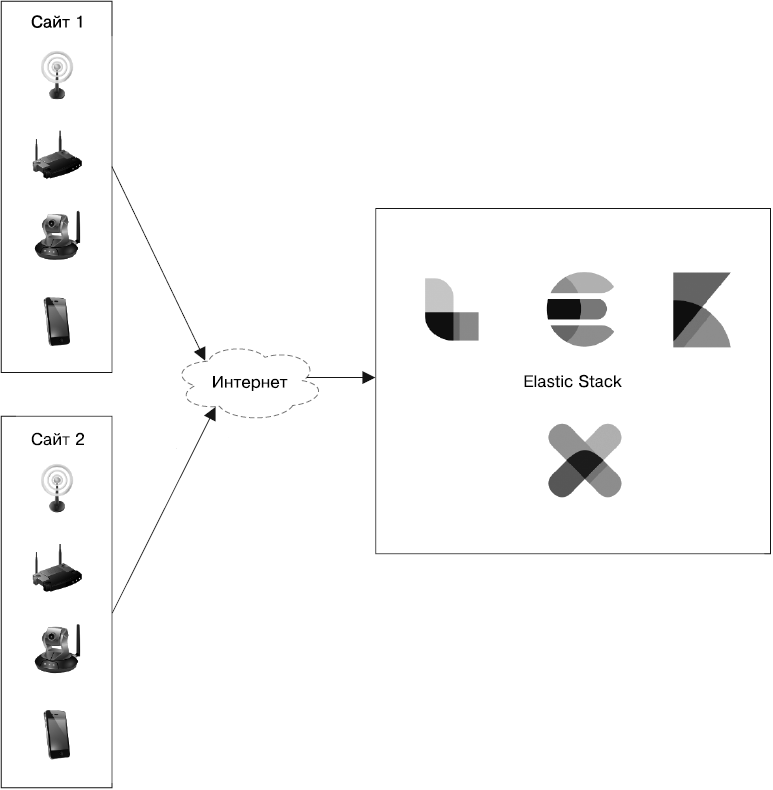
Рис. 10.1
Вы можете увидеть, как выглядит высокоуровневая архитектура системы, которую мы будем обсуждать в этой главе. В левой части рисунка представлены различные типы устройств, оснащенных датчиками. Эти устройства могут получать разные метрики и отправлять их через Интернет для долгосрочного хранения и анализа. Справа вы видите компоненты серверной части. В основном они принадлежат Elastic Stack.
В этой главе мы рассмотрим приложение для хранения и анализа данных, поступающих с двух типов датчиков: температуры и влажности.
Датчики размещены в различных местах или на площадках, каждое место имеет подключение к Интернету (см. рис. 10.1). Наш пример демонстрирует работу с двумя типами датчиков, но приложение может быть расширено для поддержки датчиков любых типов.
В этом разделе мы рассмотрим следующие темы.
• Создаваемые датчиками данные.
• Метаданные с датчиков.
• Окончательно сохраняемые данные.
Создаваемые датчиками данные
Как выглядят данные, которые создаются датчиками? Датчик отправляет данные в формате JSON через Интернет, и каждая запись выглядит следующим образом:
{
"sensor_id": 1,
"time": 1511935948000,
"value": 21.89
}
На примере мы видим следующее.
• Поле sensor_id является уникальным идентификатором датчика, который выполнил запись.
• Поле time является временем считывания показаний в миллисекундах, начиная с времени эпохи, то есть 00:00:00 1 января 1970 года.
• Поле value представляет собой фактическое метрическое значение, считанное датчиком.
Полезные данные JSON такого типа создаются каждую минуту всеми датчиками в системе. Поскольку все из них зарегистрированы в системе, со стороны сервера система имеет соответствующие для каждого датчика метаданные. Взглянем на метаданные, которые относятся к датчикам и доступны для нас из базы данных на стороне сервера.
Метаданные с датчиков
Метаданные, относящиеся ко всем датчикам на всех площадках, доступны для нас в реляционной базе данных. В нашем примере мы сохранили их в MySQL. Метаданные такого типа можно хранить в любой другой реляционной базе. Вы также можете добавить их в индекс Elasticsearch.
В большинстве случаев метаданные с датчиков содержат следующую информацию.
• Тип датчика. Что именно считывает датчик? Это может быть датчик температуры, влажности и т.д.
• Метаданные о местонахождении. Где физически находится датчик с выбранным идентификатором? С каким клиентом он связан?
Информация хранится в следующих трех таблицах MySQL.
• sensor_type — указывает различные типы датчиков и их sensor_type_id.
| sensor_type_id | sensor_type |
| 1 | Температура |
| 2 | Влажность |
• location — указано местонахождение с шириной/долготой и физическим адресом здания.
| location_id | customer | department | building_name | room | floor | location_on_floor | latitude | longitude |
| 1 | Abc Labs | R & D | 222 Broadway | 101 | 1 | C-101 | 40.710936 | –74.008500 |
• sensors — связывает sensor_id с типом датчика и его местонахождением.
| sensor_id | sensor_type_id | location_id |
| 1 | 1 | 1 |
| 2 | 2 | 1 |
Имея представление о структуре базы данных, можно искать все метаданные, связанные с выбранным sensor_id, используя следующий запрос SQL:
select
st.sensor_type as sensorType,
l.customer as customer,
l.department as department,
l.building_name as buildingName,
l.room as room,
l.floor as floor,
l.location_on_floor as locationOnFloor,
l.latitude,
l.longitude
from
sensors s
inner join
sensor_type st ON s.sensor_type_id = st.sensor_type_id
inner join
location l ON s.location_id = l.location_id
where
s.sensor_id = 1;
Результат предыдущего запроса будет выглядеть так.
| sensorType | customer | department | buildingName | room | floor | locationOnFloor | latitude | longitude |
| Temperature | Abc Labs | R & D | 222 Broadway | 101 | Floor1 | C-101 | 40.710936 | –74.0085 |
На данном этапе мы разобрались с форматом входящих данных датчиков с клиентской стороны. Кроме того, мы установили механизм получения связанных метаданных для выбранного датчика.
Далее мы рассмотрим, как должна выглядеть окончательная дополненная запись.
Окончательно сохраняемые данные
Комбинируя данные, поступающие с клиентской стороны и содержащие метрические значения с датчиков, мы можем создать дополненную запись из следующих полей.
1. sensorId.
2. sensorType.
3. customer.
4. department.
5. buildingName.
6. room.
7. floor.
8. locationOnFloor.
9. latitude.
10. longitude.
11. time.
12. reading.
Поля под номерами 1, 11 и 12 содержатся в данных, отправленных датчиком в наше приложение. Остальные поля созданы для дополнения, для этого используется запрос SQL, который мы видели в предыдущем разделе: sensorId. Таким образом мы можем создавать денормализованную запись для каждого датчика каждую минуту.
Итак, мы разобрались, в чем суть приложения и что собой представляют данные. Приступив к разработке приложения, мы начнем с самого центра. В случае с Elastic Stack в центре стека находится Elasticsearch, потому начнем разработку нашего решения с формирования модели данных. Этим мы и займемся в следующем разделе.
Моделирование данных в Elasticsearch
Для моделирования данных в Elasticsearch воспользуемся структурой финальной записи из предыдущего раздела. Учитывая, что у нас данные временного ряда, мы можем применить некоторые техники из главы 9.
• Определение шаблона индекса.
• Понимание разметки.
Взглянем на шаблон индекса, который будем определять.
Определение шаблона индекса. Поскольку мы будем хранить неизменяемые данные временного ряда, нет необходимости создавать один большой монолитный индекс. Мы будем использовать техники из раздела «Моделирование данных временного ряда» предыдущей главы.
Исходный код приложения, рассматриваемого в этой главе, находится в репозитории GitHub по следующей ссылке: https://github.com/pranav-shukla/learningelasticstack/tree/master/chapter-10. На протяжении этой главы мы выполним шаги, перечисленные в файле README.md, который размещен по этому пути.
Создайте шаблон индекса, который упоминается в шаге 1 файла README.md, или запустите следующий скрипт в консоли Kibana (вкладка Dev Tools (Инструменты разработчика)):
POST _template/sensor_data_template
{
"index_patterns": ["sensor_data*"],
"settings": {
"number_of_replicas": "1",
"number_of_shards": "5"
},
"mappings": {
"doc": {
"properties": {
"sensorId": {
"type": "integer"
},
"sensorType": {
"type": "keyword",
"fields": {
"analyzed": {
"type": "text"
}
}
},
"customer": {
"type": "keyword",
"fields": {
"analyzed": {
"type": "text"
}
}
},
"department": {
"type": "keyword",
"fields": {
"analyzed": {
"type": "text"
}
}
},
"buildingName": {
"type": "keyword",
"fields": {
"analyzed": {
"type": "text"
}
}
},
"room": {
"type": "keyword",
"fields": {
"analyzed": {
"type": "text"
}
}
},
"floor": {
"type": "keyword",
"fields": {
"analyzed": {
"type": "text"
}
}
},
"locationOnFloor": {
"type": "keyword",
"fields": {
"analyzed": {
"type": "text"
}
}
},
"location": {
"type": "geo_point"
},
"time": {
"type": "date"
},
"reading": {
"type": "double"
}
}
}
}
}
Каждый раз, когда клиент пытается проиндексировать первую запись в этом индексе, шаблон индекса создаст новый индекс с названием по типу sensor_data-YYYY.MM.dd. Далее в разделе «Создание контейнера данных Logstash» мы рассмотрим, как можно сделать то же самое из Logstash.
Разбираемся с разметкой. Разметка, определенная в шаблоне индекса, содержит все поля, которые будут присутствовать в денормализованной записи после поиска. Обратите внимание на следующие особенности разметки шаблона индекса.
• Все поля, содержащие данные текстового типа, сохранены с типом keyword; дополнительно они сохраняются как text в анализируемом поле. Например, взгляните на поле customer.
• Поля широты и долготы, которые присутствовали в дополненных данных, теперь размечены как тип поля geo_point, название поля — location.
На данном этапе мы определили шаблон индекса, который будет запускать создание индексов с той разметкой, которую мы указали в шаблоне.
Настройка базы метаданных
Нам понадобится база данных, которая хранит метаданные с датчиков. В ней будут находиться таблицы, которые мы рассматривали в предыдущем разделе.
Мы храним данные в реляционной базе данных MySQL, но можно использовать любую другую реляционную базу данных. Исходя из нашего выбора, для подключения к базе данных мы возьмем драйвер MySQL JDBC. Убедитесь, что в вашей системе присутствуют следующие компоненты.
1. База данных MySQL, версия от сообщества 5.5, 5.6 или 5.7. Вы можете использовать существующую базу данных, если уже настроили ее в системе.
2. Установите скачанную базу данных и зайдите в систему с пользователем root. Выполните сценарий, который находится по адресу https://github.com/pranav-shukla/learningelasticstack/tree/master/chapter-10/files/create_sensor_metadata.sql.
3. Зайдите в только что созданную базу данных sensor_metadata и убедитесь, что в ней есть следующие три таблицы: sensor_type, locations и sensors.
Вы можете проверить правильность создания базы данных следующим запросом:
select
st.sensor_type as sensorType,
l.customer as customer,
l.department as department,
l.building_name as buildingName,
l.room as room,
l.floor as floor,
l.location_on_floor as locationOnFloor,
l.latitude,
l.longitude
from
sensors s
inner join
sensor_type st ON s.sensor_type_id = st.sensor_type_id
inner join
location l ON s.location_id = l.location_id
where
s.sensor_id = 1;
Результат выполненного запроса должен выглядеть таким образом.
| sensorType | customer | department | buildingName | room | floor | locationOnFloor | latitude | longitude |
| Temperature | Abc Labs | R & D | 222 Broadway | 101 | Floor1 | C-101 | 40.710936 | –74.0085 |
Наша база данных sensor_metadata готова для поиска необходимых метаданных датчиков. В следующем разделе мы приступим к созданию контейнера данных в Logstash.
Создание контейнера данных Logstash
Теперь, когда у нас настроен механизм автоматического создания индексов Elasticsearch и базы метаданных, мы можем сфокусироваться на создании контейнера данных в Logstash. Для чего нужен наш контейнер данных? Он должен выполнять следующие действия.
1. Принимать запросы JSON по сети (через HTTP).
2. Дополнять JSON метаданными, которые есть в нашей базе данных MySQL.
3. Сохранять в Elasticsearch полученные в результате документы.
Эти три основные функции, которые нам необходимы, согласовываются с плагинами ввода данных контейнера Logstash, фильтрации и вывода соответственно. Полную конфигурацию Logstash для этого контейнера данных вы можете найти по следующей ссылке: https://github.com/pranav-shukla/learningelasticstack/tree/master/chapter-10/files/logstash_sensor_data_http.conf.
Теперь мы пошагово рассмотрим, как достичь финальной цели нашего контейнера данных. Начнем с приема запросов JSON по сети (через HTTP).
Прием запросов JSON по сети
Для этой задачи нам понадобится плагин ввода. Logstash поддерживает плагин ввода http, который выполняет необходимые действия, а именно создание HTTP-интерфейса, с помощью которого различные типы данных могут попасть в Logstash.
Часть файла logstash_sensor_data_http.conf, которая содержит фильтр ввода, выглядит следующим образом:
input {
http {
id => "sensor_data_http_input"
}
}
В поле id находится строка с уникальным идентификатором этого фильтра ввода. Нам не нужно ссылаться на это название в файле; мы просто выберем название sensor_data_http_input.
Документация по плагину ввода HTTP доступна по следующей ссылке: https://www.elastic.co/guide/en/logstash/current/plugins-inputs-http.html. Поскольку мы используем конфигурацию плагина по умолчанию, то просто указали идентификатор (id). Нам необходимо настроить безопасность для этой части HTTP, так как она будет открыта в Интернете для того, чтобы датчики могли отправлять данные откуда угодно. Мы можем задать имя и пароль (параметры user и password) для защиты, как показано в коде ниже:
input {
http {
id => "sensor_data_http_input"
user => "sensor_data"
password => "sensor_data"
}
}
Когда мы запускаем Logstash с этим плагином ввода, он запускает HTTP, используя порт 8080. Безопасность обеспечивается базовой аутентификацией с указанием имени пользователя и пароля. Мы можем отправить запрос этому контейнеру в Logstash, воспользовавшись командой curl, как показано ниже:
curl -XPOST -u sensor_data:sensor_data --header "Content-Type:
application/json" "http://localhost:8080/" -d
'{"sensor_id":1,"time":1512102540000,"reading":16.24}'
Рассмотрим, как дополнить данные JSON, используя метаданные, которые у нас есть в MySQL.
Дополнение JSON метаданными из нашей базы данных MySQL
Дополнение и другая обработка данных внутри контейнера может выполняться с помощью плагинов фильтрации. Мы создали реляционную базу данных, которая содержит таблицы и позволяет искать данные для дополнения входящих запросов JSON.
В Logstash доступен плагин фильтрации, который можно использовать для поиска по любой реляционной базе данных и дополнения входящих документов JSON. Рассмотрим раздел плагинов в нашем конфигурационном файле Logstash:
filter {
jdbc_streaming {
jdbc_driver_library => "/path/to/mysql-connector-java-5.1.45-bin.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://localhost:3306/sensor_metadata"
jdbc_user => "root"
jdbc_password => "<password>"
statement => "select st.sensor_type as sensorType, l.customer as
customer, l.department as department, l.building_name as buildingName,
l.room as room, l.floor as floor, l.location_on_floor as locationOnFloor,
l.latitude, l.longitude from sensors s inner join sensor_type st on
s.sensor_type_id=st.sensor_type_id inner join location l on
s.location_id=l.location_id where s.sensor_id= :sensor_identifier"
parameters => { "sensor_identifier" => "sensor_id"}
target => lookupResult
}
mutate {
rename => {"[lookupResult][0][sensorType]" => "sensorType"}
rename => {"[lookupResult][0][customer]" => "customer"}
rename => {"[lookupResult][0][department]" => "department"}
rename => {"[lookupResult][0][buildingName]" => "buildingName"}
rename => {"[lookupResult][0][room]" => "room"}
rename => {"[lookupResult][0][floor]" => "floor"}
rename => {"[lookupResult][0][locationOnFloor]" => "locationOnFloor"}
add_field => {
"location" =>
"%{lookupResult[0]latitude},%{lookupResult[0]longitude}"
}
remove_field => ["lookupResult", "headers", "host"]
}
}
Как вы можете увидеть, в файле используются два плагина фильтрации:
• jdbc_streaming;
• mutate.
Рассмотрим, для чего они нужны.
Плагин jdbc_streaming
Мы явно указали расположение базы данных, к которой хотим подключиться, имя пользователя и пароль, файл .jar драйвера JDBC и класс.
Скачайте последнюю версию драйвера MySQL JDBC, также известного под названием Connector/J, по следующей ссылке: https://dev.mysql.com/downloads/connector/j/. На момент написания книги последней была версия 5.1.45, которая работает с версиями MySQL 5.5, 5.6 и 5.7. Скачайте файл .tar/.zip, содержащий драйвер, и распакуйте его в вашей системе. Путь к этому извлеченному файлу .jar должен быть указан в параметре jdbc_driver_library.
В общем счете вам необходимо проверить и обновить следующие параметры в конфигурации Logstash для указания вашей базы данных и файла драйвера .jar:
• jdbc_connection_string;
• jdbc_password;
• jdbc_driver_library.
Парамер statement имеет тот же запрос SQL, который мы видели ранее. Он ищет метаданные для выбранного sensor_id. Успешный запрос извлечет все дополнительные поля для этого sensor_id. Результат запроса поиска сохраняется в новом поле — lookupResult, как указано в параметре target.
В результате мы должны получить документ следующего вида:
{
"sensor_id": 1,
"time": 1512102540000,
"reading": 16.24,
"lookupResult": [
{
"buildingName": "222 Broadway",
"sensorType": "Temperature",
"latitude": 40.710936,
"locationOnFloor": "Desk 102",
"department": "Engineering",
"floor": "Floor 1",
"room": "101",
"customer": "Linkedin",
"longitude": -74.0085
}
],
"@timestamp": "2017-12-07T12:12:37.477Z",
"@version": "1",
"host": "0:0:0:0:0:0:0:1",
"headers": {
"remote_user": "sensor_data",
"http_accept": "*\/*",
...
}
}
Как видите, плагин фильтрации jdbc_streaming добавил несколько полей, помимо lookupResult. Эти поля были добавлены Logstash, а поле headers — плагином ввода HTTP.
Далее мы воспользуемся плагином фильтрации mutate для модификации этого документа JSON в желаемый конечный результат в Elasticsearch.
Плагин mutate
Как вы видели в предыдущем разделе, вывод плагина фильтрации jdbc_streaming имеет некоторые нежелательные последствия. Для наших данных JSON необходимы такие изменения:
• перенос найденных полей под lookupResult напрямую в JSON;
• комбинирование полей широты и долготы под lookupResult в виде поля местоположения;
• удаление ненужных полей.
mutate {
rename => {"[lookupResult][0][sensorType]" => "sensorType"}
rename => {"[lookupResult][0][customer]" => "customer"}
rename => {"[lookupResult][0][department]" => "department"}
rename => {"[lookupResult][0][buildingName]" => "buildingName"}
rename => {"[lookupResult][0][room]" => "room"}
rename => {"[lookupResult][0][floor]" => "floor"}
rename => {"[lookupResult][0][locationOnFloor]" => "locationOnFloor"}
add_field => {
"location" => "%{lookupResult[0]latitude},%{lookupResult[0]longitude}"
}
remove_field => ["lookupResult", "headers", "host"]
}
Посмотрим, как плагин mutate выполнит эти задачи.
Перенос найденных полей под lookupResult напрямую в JSON
Как вы уже видели, lookupResult находится в массиве с единственным элементом (под индексом 0 в массиве). Нам необходимо перенести все поля в этот элемент массива непосредственно под данные JSON. Для этого выполним операцию rename для каждого поля.
Например, следующая операция переименует существующее поле sensorType непосредственно под данными JSON:
rename => {"[lookupResult][0][sensorType]" => "sensorType"}
Мы выполним такую операцию для всех найденных полей, которые были возвращены запросом SQL.
Комбинирование полей широты и долготы под lookupResult в виде поля местоположения
Помните, как мы определяли разметку шаблона нашего индекса? Мы указали, что поле location должно иметь тип geo_point. Тип geo_point принимает значение в строковом формате, а именно объединенные данные широты и долготы, разделенные запятой.
Для получения такого результата предназначена операция add_field, создающая поле location, как видно в следующем примере:
add_field => {
"location" => "%{lookupResult[0]latitude},%{lookupResult[0]longitude}"
}
На данном этапе у вас должно быть новое поле с названием location, добавленное в данные JSON именно так, как требовалось. Далее мы приступим к удалению ненужных полей.
Удаление ненужных полей
После переноса всех элементов из поля lookupResult напрямую в JSON это поле нам больше не нужно. Аналогичным образом мы не хотим хранить поля headers и host в индексе Elasticsearch. Мы удалим их все, используя следующую операцию:
remove_field => ["lookupResult", "headers", "host"]
Наконец у нас есть данные JSON в той структуре, которую мы ходим видеть в индексе Elasticsearch. Далее узнаем, как отправить эти данные в Elasticsearch.
Сохранение в Elasticsearch полученных в результате документов
Для отправки данных мы задействуем плагин вывода Elasticsearch, который поставляется в комплекте с Logstash. Он крайне прост в использовании; нам нужно только указать elasticsearch в тегах вывода:
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "sensor_data-%{+YYYY.MM.dd}"
}
}
Мы указали параметры hosts и index для отправки данных в правильный индекс в правильном кластере. Обратите внимание, что название индекса имеет вид %{YYYY.MM.dd}. Название используемого индекса задается согласно текущему времени события и форматируется соответствующим образом.
Помните, что мы определили шаблон индекса sensor_data*. При отправке первого события 1 декабря 2017 года указанный плагин вывода отправит событие в индекс sensor_data-2017.12.01.
Если вы хотите отправлять события в защищенный кластер Elasticsearch, настройку которого с помощью X-Pack мы рассматривали в главе 8, можете изменить имя пользователя и пароль, как указано ниже:
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "sensor_data-%{+YYYY.MM.dd}"
user => "elastic"
password => "elastic"
}
}
Таким образом, у вас будет один индекс на каждый день, в пределах которого будут храниться данные этого дня.
Теперь, когда контейнер данных Logstash готов, отправим данные.
Отправка данных в Logstash через HTTP
На данном этапе датчики уже могут начинать отправлять свои показания в контейнер данных Logstash, который мы создали в предыдущем разделе. Им нужно отправлять данные следующим образом:
curl -XPOST -u sensor_data:sensor_data --header "Content-Type:
application/json" "http://localhost:8080/" -d
'{"sensor_id":1,"time":1512102540000,"reading":16.24}'
Поскольку у нас нет настоящих датчиков, мы будем симулировать данные путем отправки запросов подобного типа. Данные симуляции и скрипт для их отправки в виде кода доступны по следующей ссылке: https://github.com/pranav-shukla/learningelasticstack/tree/master/chapter-10/data.
Если вы используете ОС Linux или macOS, откройте терминал и измените папку на ваше рабочее пространство Elastic Stack, которое получили с GitHub.

Если вы используете Windows, вам понадобится Linux-подобная оболочка, которая поддерживает команду curl и базовые команды BASH (Bourne Again SHell). Если у вас уже есть рабочее пространство GitHub, вы можете использовать Git for Windows, в котором есть Git BASH. Его вы можете задействовать для выполнения скрипта, который загружает данные. При отсутствии этого компонента скачайте и установите Git for Windows по следующей ссылке: https://git-scm.com/download/win. После чего запустите Git BASH для выполнения команд, приведенных в этой главе.
Теперь перейдем в каталог chapter-10/data и выполним load_sensor_data.sh:
$ pwd
/Users/pranavshukla/workspace/learningelasticstack
$ cd chapter-10/data
$ ls
load_sensor_data.sh sensor_data.json
$ ./load_sensor_data.sh
Скрипт load_sensor_data.sh читает документ sensor_data.json строка за строкой и передает данные в Logstash, используя команду curl.
Мы только что воспроизвели в Logstash показания датчиков за один день — они считывались каждую минуту из различных географических мест. Контейнер данных Logstash, который мы создали ранее, должен дополнить данные и отправить их в Elasticsearch.
Теперь наступило время перейти в Kibana и получить детальные отчеты по данным.
Визуализация данных в Kibana
Мы успешно настроили контейнер данных Logstash, а также загрузили с его помощью данные в Elasticsearch. Теперь перейдем к исследованию данных и созданию панели управления, которая поможет нам получить детальную картину.
Начнем с проверки корректности загрузки данных. Для этого перейдем на страницу Dev Tools (Инструменты разработчика) в Kibana и выполним следующий запрос:
GET /sensor_data-*/_search?size=0
{
"query": {"match_all": {}}
}
Запрос запустит поиск данных по всем индексам, которые совпадают с шаблоном sensor_data-*. Мы должны получить большое количество записей в индексе, если данные корректно проиндексированы.
Мы рассмотрим следующие темы.
• Настройка шаблона индекса в Kibana.
• Создание визуализаций.
• Создание панели управления с помощью визуализаций.
Настройка шаблона индекса в Kibana
Прежде чем мы сможем приступить к созданию визуализаций, необходимо настроить шаблон индекса для всех индексов, которые будут потенциально использоваться приложением аналитики данных датчиков. Мы это делаем потому, что наши названия индексов меняются динамически. Каждый день у нас будет появляться новый индекс, нам необходимо иметь возможность создавать визуализации и панели управления, которые смогут работать с несколькими индексами данных датчиков. Для этого перейдите на вкладку Management (Управление) в Kibana и щелкните на ссылке Index Patterns (Шаблоны индексов) (рис. 10.2).
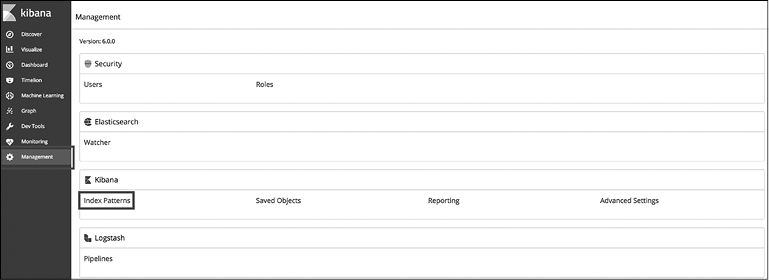
Рис. 10.2
Нажмите кнопку Create Index Pattern (Создать шаблон индекса) и добавьте sensor_data*, как показано на рис. 10.3. В поле Time Filter field name (Название поля фильтра времени) укажите нужное поле и нажмите кнопку Create (Создать).
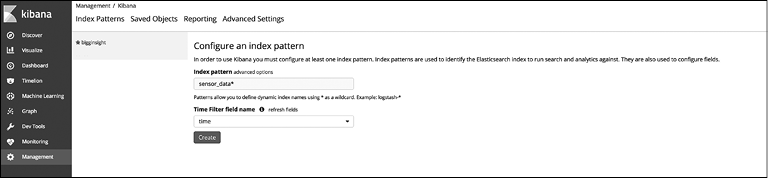
Рис. 10.3
Мы успешно создали шаблон индекса для наших данных с датчиков. Далее приступим к созданию визуализаций.
Создание визуализаций
Наверняка на текущий момент у вас уже накопились вопросы о данных, ответы на которые можно быстро получить с помощью визуализаций. Кроме того, можно сохранить эти визуализации на панели управления для последующего использования при необходимости. Начнем со списка вопросов и постараемся создать визуализации, которые предоставят ответы на них.
Попробуем найти ответы на следующие вопросы.
• Как меняется средняя температура со временем?
• Как меняется средняя влажность со временем?
• Как меняется температура и влажность в каждом месте со временем?
• Могу ли я визуализировать температуру и влажность на карте?
• Как датчики распределены по отделам?
Для получения ответов создадим визуализации и начнем с первого вопроса.
Как меняется средняя температура со временем?
В данном случае нам потребуется агрегация статистики. Нам необходимо знать среднюю температуру по всем датчикам температуры, независимо от их местонахождения или других критериев. Как вы видели в главе 7, следует перейти на вкладку Visualize (Визуализации), после чего создать новую визуализацию нажатием кнопки +.
Выберите Basic Charts (Базовые диаграммы), далее укажите Line (Линейная). На следующей странице для настройки линейной диаграммы выполните шаги 1–5 (рис. 10.4).
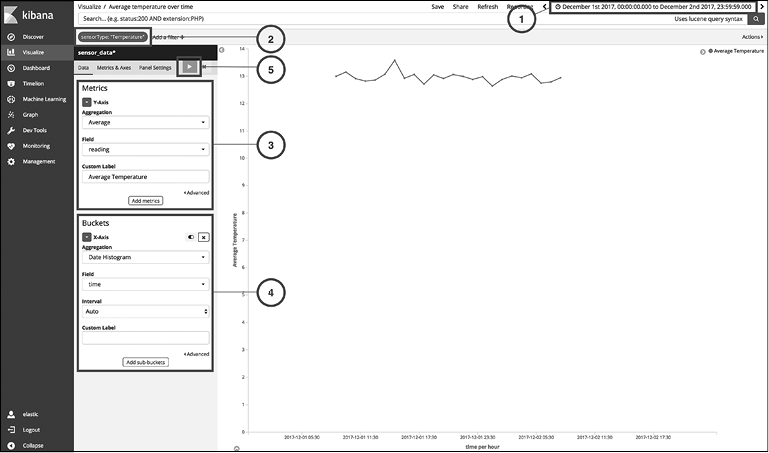
Рис. 10.4
1. Щелкните на маленьком значке с часами в верхнем правом углу, выберите Absolute (Абсолютный) и укажите диапазон с 1 по 2 декабря 2017 года. Это необходимо сделать, так как наши симулированные данные датируются 1 декабря 2017 года.
2. Щелкните на ссылке Add a filter (Добавить фильтр); выберите фильтр следующим образом: sensorType is Temperature. Нажмите кнопку Save (Сохранить). У нас есть два типа датчиков, температуры и влажности. Для текущей визуализации нам нужны только показания температуры. Поэтому мы выбрали этот фильтр.
3. Из раздела Metrics (Метрики) выберите нужные значения. Нас интересует среднее значение показаний. Мы также изменили метку на Average Temperature (Средняя температура).
4. Из раздела Buckets (Сегменты) выберите агрегацию Date Histogram (Гистограмма даты) и поле времени, остальные настройки оставьте как есть.
5. Нажмите треугольную кнопку Apply changes (Применить изменения).
Как меняется средняя влажность со временем?
Этот вопрос очень похож на предыдущий. Для ответа на него мы можем повторно использовать предыдущую визуализацию, слегка модифицировав ее, и создать еще одну копию. Начнем с открытия первой визуализации, которую мы сохранили под названием Average temperature over time (Средняя температура по времени).
Для обновления визуализации выполните следующие шаги (рис. 10.5).
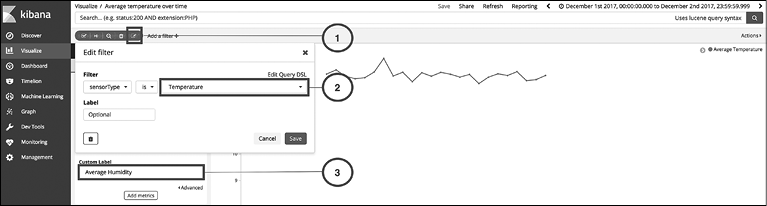
Рис. 10.5
1. Наведите указатель мыши на фильтр с меткой sensorType: "Temperature" и щелкните на значке Edit (Редактировать).
2. Измените значение фильтра с Temperature (Температура) на Humidity (Влажность) и нажмите кнопку Save (Сохранить).
3. Измените Custom Label (Метка) со значения Average Temperature (Средняя температура) на Average Humidity (Средняя влажность) и нажмите кнопку Apply changes (Применить изменения).
Как вы увидите, диаграмма обновится для датчиков влажности. Щелкните на ссылке Save (Сохранить) вверху навигационной панели, запишите новое название визуализации как Average humidity over time (Средняя влажность по времени), установите флажок Save as a new visualization (Сохранить как новую визуализацию) и нажмите кнопку Save (Сохранить). Так вы создадите вторую визуализацию и получите ответ на второй вопрос.
Как меняется температура и влажность в каждом месте со временем?
На этот раз нам нужно больше деталей, чем в первых двух вопросах. Мы хотим узнать, как меняются температура и влажность в каждом месте со временем. Создадим решение для температуры.
Перейдите на вкладку Visualizations (Визуализации) в Kibana и создайте новую линейную диаграмму точно так же, как делали ранее (рис. 10.6).
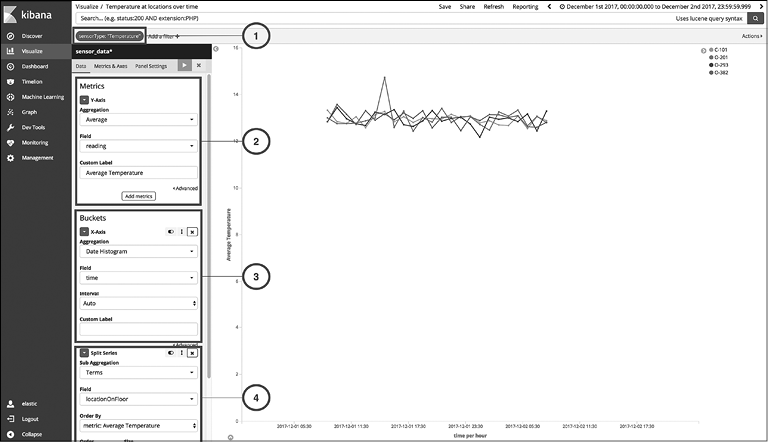
Рис. 10.6
1. Добавьте фильтр для sensorType: "Temperature".
2. Как показано на рис. 10.6, задайте в разделе Metrics (Метрики) выполнение агрегации среднего числа для поля reading.
3. Поскольку мы выполняем агрегацию данных по полю time, необходимо выбрать агрегацию Date Histogram (Гистограмма даты) в разделе Buckets (Сегменты). Здесь следует выбрать поле и оставить Interval (Интервал) в положении Auto (Автоматически).
4. На этот момент новая визуализация аналогична предыдущей: Average temperature over time (Средняя температура по времени). Но нам недостаточно видеть только среднюю температуру, нам надо видеть ее по значению locationOnFloor, которое является нашей единицей идентификации местонахождения. Поэтому в этом шаге мы разбиваем ряд с помощью агрегации условий по полю locationOnFloor. Мы хотим выполнить сортировку по metric: Average Temperature и установить в качестве размера сортировки значение 5, чтобы видеть только топ-5 местонахождений.
Теперь мы создали визуализацию, которая показывает изменение температуры для каждого значения locationOnFloor в наших данных. Вы можете отчетливо видеть перепад О-201 1 декабря 2017 года в 15:00 IST. Из-за этого перепада мы получили перепад средней температуры в это же время в нашей первой визуализации. Это важная информация, которая появилась благодаря графику.
Визуализация для влажности может быть создана путем повторения всех шагов, только с заменой температуры влажностью.
Могу ли я визуализировать температуру и влажность на карте?
Мы можем визуализировать температуру и влажность на карте, используя визуализацию в виде карты координат. Создайте новую визуализацию типа Coordinate Map (Карта координат) и выполните следующие шаги (рис. 10.7).
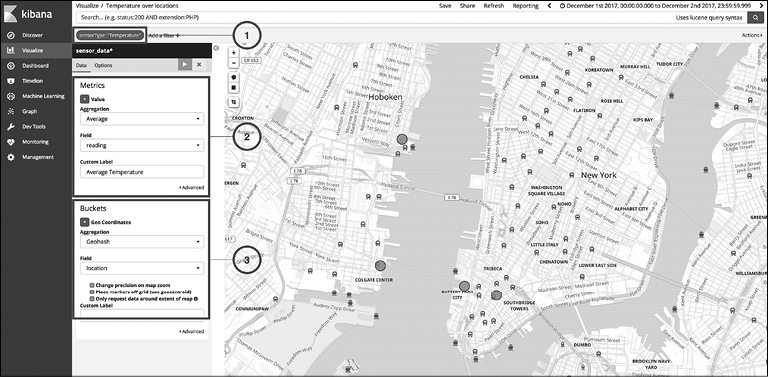
Рис. 10.7
1. Как и в предыдущих визуализациях, добавьте фильтр для sensorType: "Temperature".
2. В разделе Metrics (Метрики) выберите агрегацию среднего числа (Average) для поля reading, как уже было сделано ранее.
3. Поскольку мы используем карту координат, необходимо выбрать агрегацию сетки GeoHash и указать поле geo_point, которое присутствует в наших данных; поле для агрегации — location.
Как видите, теперь наши данные графически отображаются на карте. Мы можем мгновенно узнать среднюю температуру на каждой площадке при наведении указателя мыши на каждую точку. Сфокусируйте внимание на необходимой части карты и сохраните визуализацию с названием Temperature over locations (Температура по местам).
Аналогичным образом можно создать визуализацию в виде карты координат для датчиков влажности.
Как датчики распределены по отделам?
Что, если мы хотим увидеть, как датчики распределены по разным отделам? Помните, что в наших данных есть поле department, которое мы получили после дополнения данных на основе sensor_id. Для визуализации распределения данных по различным значениям полей типа keyword, таким как department, идеально подойдут круговые диаграммы. Создадим новую визуализацию типа Pie (Круговая диаграмма).
Проследуйте по шагам, отмеченным на рис. 10.8.
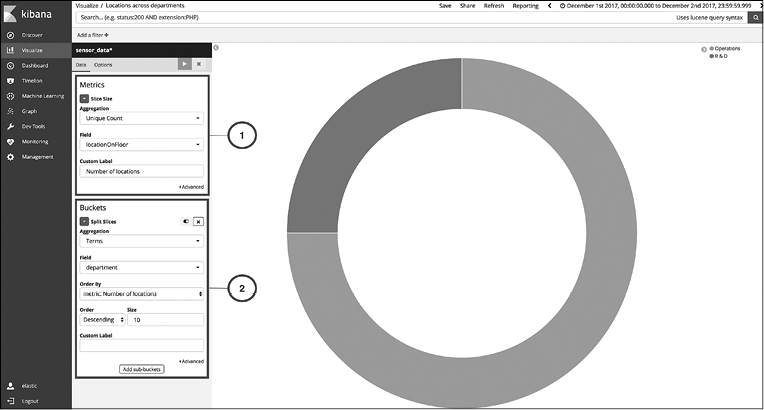
Рис. 10.8
1. В разделе Metrics (Метрики) выберите агрегацию Unique Count (Уникальный подсчет) и поле locationOnFloor. Вы можете отредактировать значение Custom Label (Пользовательская метка) согласно количеству мест.
2. В разделе Buckets (Сегменты) необходимо выбрать агрегацию терминов по полю department, если хотим собрать данные по разным отделам.
Нажмите кнопку Apply changes (Применить изменения) и сохраните визуализацию как Locations across departments (Места по отделам). Аналогичным образом вы можете создать визуализацию для демонстрации мест по разным зданиям. Ее можно назвать Locations across buildings (Места по зданиям). Это поможет нам узнать, в каких местах установлено наблюдение в каждом здании.
Далее мы создадим панель управления для сбора всех визуализаций вместе.
Создание панели управления
Панель управления позволяет организовать несколько визуализаций воедино, сохранять их, а также делиться ими с другими людьми. В возможности наблюдать за несколькими визуализациями одновременно есть свои преимущества. Вы можете фильтровать данные по различным критериям и увидеть отфильтрованный результат на всех визуализациях. Благодаря такому функционалу вы можете собрать больше сведений о своих данных либо получить ответы на самые сложные вопросы.
Создадим панель управления из уже созданых визуализаций. Щелкните на вкладке Dashboard (Панель управления) на навигационной панели слева в Kibana. Нажмите кнопку + для создания новой панели управления.
Нажмите кнопку Add (Добавить) в меню вверху для добавления визуализаций на вашу новую панель управления. Так вы получите полный список уже созданных визуализаций в раскрывающемся меню. Вы можете добавить визуализации одну за другой, а также менять их местами и редактировать размер для создания панели управления, которая идеально соответствует вашим требованиям.
Взглянем на то, какой может быть панель управления для приложения, которое мы создаем (рис. 10.9).
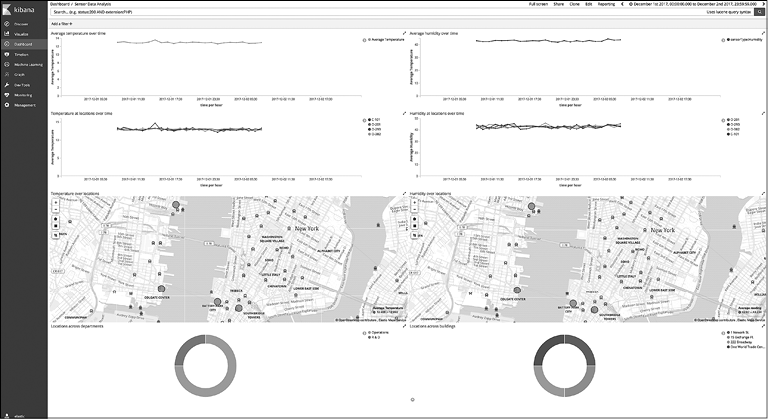
Рис. 10.9
На панель управления можно добавить фильтры — для этого щелкните на ссылке Add a filter (Добавить фильтр) в верхнем левом углу панели управления. Выбранный фильтр будет применен ко всем диаграммам.
Визуализации интерактивны; например, щелкнув на одной из частей круговой диаграммы, вы можете применить этот фильтр глобально. Рассмотрим, в каких случаях это может пригодиться.
Если вы щелкнете на сегменте диаграммы для здания 222 Бродвея в нижнем правом углу, то увидите, что в фильтры был добавлен buildingName: "222 Broadway". Таким образом, вы можете видеть все данные из перспективы всех датчиков этого здания (рис. 10.10).
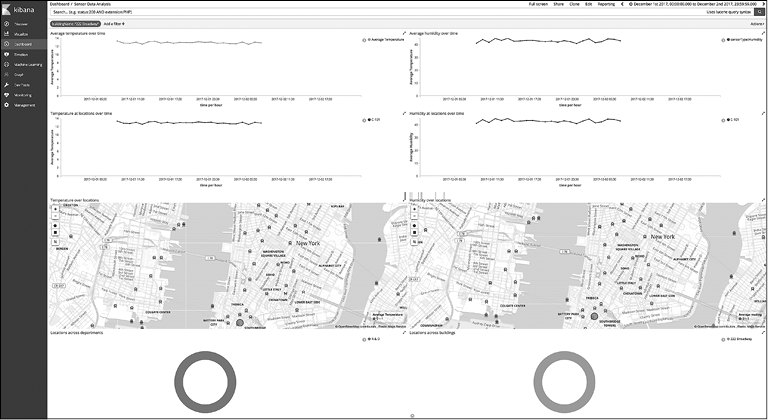
Рис. 10.10
Удалим этот фильтр. Для этого наведите указатель мыши на фильтр buildingName: "222 Broadway" и щелкните на значке с урной. Далее мы попробуем поработать с одной из линейных диаграмм, то есть с визуализацией Temperature at locations over time (Температура по местам во времени).
Как мы уже наблюдали, 1 декабря 2017 года был перепад показателей. Вы можете увеличить детализацию по определенному периоду времени, если нарисуете мышью прямоугольник на той части диаграммы, которую хотите увеличить. Иными словами, обведите перепад прямоугольником, удерживая нажатой левую кнопку мыши. В результате изменится фильтр времени, который изначально был применен ко всей панели управления (отображается в правом верхнем углу).
Посмотрим, удастся ли нам тщательнее исследовать данные после этой операции фокусировки на периоде времени (рис. 10.11).
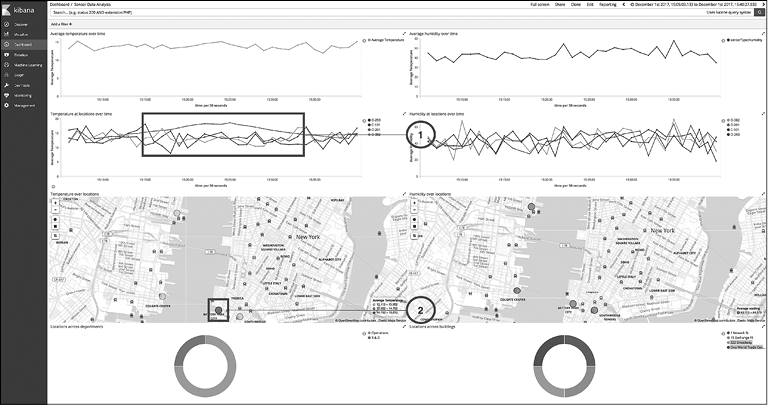
Рис. 10.11
Мы получили следующие факты.
• Температура, согласно датчику на площадке О-201, стабильно поднимается на протяжении этого времени.
• На карте координат вы можете увидеть, что выделенный круг темнее, по сравнению с другими местами, которые выделены более светлым оттенком (в оригинале красный и желтый цвета соответственно. — Примеч. ред.). Это указывает на то, что данная площадка имеет ненормально высокую температуру на фоне других.
Как видите, интерактивное использование диаграмм и выбор различных фильтров дают возможность получить необходимые сведения о ваших данных.
Таким образом, мы продемонстрировали возможности созданного приложения, используя компоненты Elatic Stack.
Резюме
В этой главе мы создали приложение аналитики данных с датчиков, которое имеет широкий спектр применения и относится к развивающейся отрасли Интернета вещей. Мы создали приложение для аналитики, используя только компоненты Elastic Stack, не прибегая к каким-либо другим инструментам или языкам программирования, и получили мощный инструмент, который позволяет обрабатывать большие объемы данных.
Мы начали с самых азов, а именно — с моделирования данных для Elasticsearch. Далее мы разработали контейнер данных, который имеет защиту и может получать данные из Интернета посредством HTTP. Мы дополнили входящие данные с помощью метаданных, которые расположены в реляционной БД и хранятся в Elasticsearch. Мы отправили тестовые данные по HTTP точно так же, как настоящие датчики отправляют данные через Интернет. Мы создали визуализации, которые могут дать ответы на некоторые типичные вопросы о данных. После чего мы собрали все визуализации на одной мощной интерактивной панели управления.
В главе 11 мы создадим еще одно приложение для решения реальных задач с помощью Elastic Stack.

