6. Разработка контейнеров данных с помощью Logstash
Прочитав предыдущую главу, вы наверняка поняли важность Logstash в процессе анализа логов. Вы также узнали о способах применения этого компонента и его высокоуровневой архитектуры, а также прошлись по нескольким наиболее распространенным плагинам. Один из важных процессов в Logstash — это структуризация лог-данных, не имеющих четкой структуры. Она облегчает поиск релевантной информации, а также улучшает возможности анализа. Помимо обработки и структуризации лог-данных, полезным будет и их дополнение для улучшения понимания логов. Logstash выполняет и эту работу. В предыдущей главе вы узнали, что Logstash может читать данные из широкого спектра источников ввода и что это тяжелый процесс. Установка Logstash на граничных узлах доставки логов не всегда возможна. Есть ли альтернативный легковесный агент, который может использоваться для этой цели? Вы узнаете это в текущей главе.
Мы рассмотрим следующие темы.
• Обработка и дополнение логов с помощью Logstash.
• Платформа Elastic Beats.
• Установка и настройка Filebeats для доставки логов.
Обработка и дополнение логов с помощью Logstash
Структурированные данные проще анализировать по сравнению с неструктурированными: можно сделать это более осмысленно/глубоко. Большинство инструментов анализа зависят от структуры данных. Для анализа и визуализации мы будем использовать Kibana, но этот компонент будет работать эффективно, только если данные в Elasticsearch имеют корректный вид (информация лог-данных загружена в соответствующие поля, а тип данных в полях подходящий).
Обычно лог-данные состоят из двух частей:
logdata = timestamp + data
timestamp — это время, когда произошло событие, а data — информация о событии. data может содержать один фрагмент информации или более. Например, если мы возьмем логи apache-access, фрагмент данных будет содержать код ответа, URL запроса, IP-адрес и т.д. Нам понадобится механизм для извлечения этой информации из данных и конвертирования неструктурированных данных/событий в структурированные. Именно здесь пригодится функционал Logstash в виде контейнеров фильтрации. Фильтрационная часть состоит из одного или нескольких плагинов фильтрации, которые помогают обрабатывать и дополнять лог-данные.
Плагины фильтрации
Плагин фильтрации предназначен для преобразования данных. Возможно комбинировать один или несколько плагинов, а порядок их использования определяет порядок, в котором будут преобразованы данные. Пример секции фильтрации в контейнере Logstash будет выглядеть так, как показано на рис. 6.1.
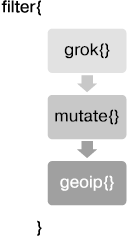
Рис. 6.1
Полученные от плагина ввода события передаются через каждый из плагинов, указанных в секции фильтров, в процессе чего происходит преобразование событий в зависимости от определенных плагинов. В конце выполняется отправка в плагин вывода с целью передачи события в выбранное место.
В следующих разделах мы рассмотрим несколько наиболее популярных плагинов фильтрации, используемых для преобразования данных.
Фильтр CSV
Этот фильтр полезен для обработки файлов .csv. Плагин берет данные CSV, содержащие события, обрабатывает их и сохраняет как отдельные поля.
Взглянем на работу фильтра CSV на примере данных. Сохраните следующие данные в файле с названием users.csv:
FName,LName,Age,Salary,EmailId,Gender
John,Thomas,25,50000,John.Thomas,m
Raj, Kumar,30,5000,Raj.Kumar,f
Rita,Tony,27,60000,Rita.Tony,m
Следующий фрагмент кода показывает работу плагина фильтрации CSV. У него нет обязательных параметров. Он сканирует каждую строку данных и применяет стандартные названия столбцов, такие как column1, column2 для размещения данных. По умолчанию данный плагин использует , (запятую) как разделитель полей. Разделитель по умолчанию может быть изменен в параметре separator. Вы можете указать список названий столбцов либо с помощью параметра columns, который принимает массив названий столбцов, либо включив параметр autodetect_column_names. Таким образом плагин будет знать, что ему необходимо автоматически определять названия столбцов:
#csv_file.conf
input {
file{
path => "D:\es\logs\users.csv"
start_position => "beginning"
}
}
filter {
csv{
autodetect_column_names => true
}
}
output {
stdout {
codec => rubydebug
}
}
Фильтр Mutate
Этот фильтр позволяет выполнять различные изменения данных в полях. Вы можете переименовать, конвертировать, извлекать и модифицировать поля в событиях.
Улучшим кофигурацию csv_file.conf из предыдущего раздела с фильтром mutate и разберемся, как его применять. На примере следующего кода показано использование фильтра Mutate:
#csv_file_mutuate.conf
input {
file{
path => "D:\es\logs\users.csv"
start_position => "beginning"
sincedb_path => "NULL"
}
}
filter {
csv{
autodetect_column_names => true
}
mutate {
convert => {
"Age" => "integer"
"Salary" => "float"
}
rename => { "FName" => "Firstname"
"LName" => "Lastname" }
gsub => [
"EmailId", "\.", "_"
]
strip => ["Firstname", "Lastname"]
uppercase => [ "Gender" ]
}
}
output {
stdout {
codec => rubydebug
}
}
Как видно из примера, настройка convert внутри фильтра помогает изменять тип данных поля. Возможные итоговые конверсии — целое число, строка, число с плавающей точкой и булево значение.

Если тип конверсии — булев, допустимы лишь следующие значения.
Правда: true, t, yes, y и 1.
Ложь: false, f, no, n и 0.
Параметр rename внутри фильтра используется для переименования одного или нескольких полей. Предыдущий пример переименовывает поле FName в Firstname и LName в Lastname.
Параметр gsub используется для сопоставления регулярного выражения и значения поля, а также для замены всех соответствий замещающей строкой. Поскольку регулярные выражения работают только со строками, это поле может содержать лишь строки или массивы строк. Берется массив, хранящий три элемента на одно подстановочное значение (иными словами, берется название поля, регулярное выражение и заменяемая строка). В предыдущем примере символ . в поле EmailId заменен на _.

Убедитесь, что при компоновке регулярного выражения вы не используете специальные символы, такие как \, +, . и ?.
Параметр strip используется для извлечения пробелов.

Порядок параметров внутри фильтра mutate имеет значение. Поля будут редактироваться в том порядке, в котором указаны параметры. Например, если поля FName и LName во входящем событии были переименованы в Firstname и Lastname с помощью параметра rename, другие настройки более не могут ссылаться на FName и LName. Для этого им придется использовать новые, переименованные поля.
Параметр uppercase предназначен для преобразования строки в верхний регистр. В предыдущем примере в верхний регистр преобразовано значение в поле Gender.
Аналогичным образом, используя различные параметры фильтра Mutate, такие как lowercase, update, replace, join и merge, вы можете перевести строку в нижний регистр, обновить существующее поле, заменить значение поля, присоединить массив значений или произвести слияние полей.
Фильтр Grok
Это мощный и популярный плагин для преобразования неструктурированных данных в структурированные, для упрощения запросов и фильтрации этих данных. В общих чертах Grok позволяет сопоставить строку и шаблон (который основан на регулярном выражении) и отобразить определенные части строки на свои поля. Общий синтаксис шаблона Grok выглядит следующим образом:
%{PATTERN:FIELDNAME}
PATTERN — имя шаблона, который соответствует тексту. FIELDNAME — идентификатор для соответствующего фрагмента текста.
По умолчанию поля Grok строкового типа. Для выбора значений float или int необходимо использовать следующий формат:
%{PATTERN:FIELDNAME:type}
Около 120 шаблонов по умолчанию поставляются с Logstash. Они являются гибкими и расширяемыми. На базе существующих вы можете создать свой шаблон. Все шаблоны построены на основе библиотеки регулярных выражений Oniguruma.
Шаблоны содержат название и регулярное выражение, например:
USERNAME [a-zA-Z0-9._-]+
Шаблоны могут включать в себя другие шаблоны. Например:
HTTPDATE %{MONTHDAY}/%{MONTH}/%{YEAR}:%{TIME} %{INT}
С полным списком шаблонов вы можете ознакомиться по следующей ссылке: https://github.com/logstash-plugins/logstash-patterns-core/blob/master/patterns/grok-patterns.
Если шаблон недоступен, можно указать регулярное выражение, используя следующий формат:
(?<field_name>regex)
Например, regex (?<phone>\d\d\d-\d\d\d-\d\d\d\d) будет соответствовать телефонным номерам, таким как 123-123-1234, и вставлять обработанные значения в поле phone.
Взглянем на примеры, чтобы лучше понять работу фильтра Grok:
#grok1.conf
input {
file{
path => "D:\es\logs\msg.log"
start_position => "beginning"
sincedb_path => "NULL"
}
}
filter {
grok{
match => {"message" => "%{TIMESTAMP_ISO8601:eventtime}
%{USERNAME:userid}%{GREEDYDATA:data}" }
}
}
output {
stdout {
codec => rubydebug
}
}
Если строка ввода имеет формат "2017-10-11T21:50:10.000+00:00 tmi_19 001 this is a random message", то вывод будет выглядеть следующим образом:
{
"path" => "D:\\es\\logs\\msg.log",
"@timestamp" => 2017-11-24T12:30:54.039Z,
"data" => "this is a random message\r",
"@version" => "1",
"host" => "SHMN-IN",
"messageId" => 1,
"eventtime" => "2017-10-11T21:50:10.000+00:00",
"message" => "2017-10-11T21:50:10.000+00:00 tmi_19 001 this is
a random message\r",
"userid" => "tmi_19"
}

Если шаблон не соответствует тексту, он добавит тег _grokparsefailure в поле tags.
По ссылке http://grokdebug.herokuapp.com вы можете найти инструмент, который помогает строить шаблоны, соответствующие логам.

X-Pack, начиная с версии 5.5, содержит компонент Grok Debugger, который автоматически включается, когда вы устанавливаете X-Pack в Kibana. Он находится на вкладке DevTools (Инструменты разработчика) программы Kibana.
Фильтр даты
Этот плагин используется для обработки даты в полях. Он очень удобен и полезен при работе с временными рядами событий. По умолчанию Logstash добавляет поле @timestamp для каждого события, оно содержит время обработки события. Но пользователю может быть интересно не время обработки, а фактическое время, когда произошло событие. Таким образом, с помощью данного фильтра мы можем обрабатывать метку даты/времени из полей и далее применять ее как метку времени самого события.
Возможно использовать плагин следующим образом:
filter {
date {
match => [ "timestamp", "dd/MMM/YYYY:HH:mm:ss Z" ]
}
}
По умолчанию фильтр даты перезаписывает поле @timestamp, но вы можете это изменить, явно указав целевое поле, как показано во фрагменте кода ниже. Пользователь также может оставить время, обработанное Logstash:
filter {
date {
match => [ "timestamp", "dd/MMM/YYYY:HH:mm:ss Z" ]
target => "event_timestamp"
}
}

Часовой пояс по умолчанию будет соответствовать местному времени сервера, если не указано иное. Чтобы вручную выбрать часовой пояс, используйте в плагине параметр timezone. Вы можете найти корректные значения часовых поясов по следующей ссылке: http://joda-time.sourceforge.net/timezones.html.
Если поле времени имеет несколько возможных форматов времени, их можно указать как массив значений в параметре match:
match => [ "eventdate", "dd/MMM/YYYY:HH:mm:ss Z", "MMM dd yyyy
HH:mm:ss","MMM d yyyy HH:mm:ss", "ISO8601" ]
Фильтр Geoip
Этот плагин предназначен для пополнения логов информацией. При наличии IP-адреса будет добавлено его географическое местоположение. Географическая информация будет найдена с помощью поиска корректного IP-адреса по базе данных GeoLite2 City, и результаты будут добавлены в поля. База данных GeoLite2 City является продуктом организации Maxmind и доступна по лицензии CCA-ShareAlike 4.0. Logtash поставляется в комплекте с этой базой данных, следовательно, при поиске не придется писать какие-либо сетевые запросы, что позволяет ускорить поиск.
Единственным обязательным параметром этого плагина является source, который принимает IP-адреса в строковом формате. Этот плагин создает поле geoip с географическими данными: названием страны, области, города, почтовым кодом и др. Поле [geoip][location] создается в случае, если поиск GeoIP возвращает широту и долготу и размечен к типу geopoint при индексировании Elasticsearch. Поля geopoint могут использоваться для запроса геоформы в Elasticsearch, функций фильтрации, а также для создания визуализации на карте в Kibana (рис. 6.2).

Рис. 6.2

Фильтр Geoip поддерживает поиск по обоим форматам IPv4 и IPv6.
Фильтр Useragent
Этот фильтр преобразует (parses) строки пользовательского агента (user agent) в структурированные данные, базируясь на данных BrowserScope (http://www.browserscope.org/). Он добавляет следующую информацию о пользовательском агенте: семейство, операционная система, устройство и т.д. Для извлечения деталей этот фильтр использует базу данных regexes.yaml, которая поставляется в комплекте с Logstash. Единственным обязательным параметром для этого плагина является source, который принимает строки, содержащие детали о пользовательском агенте (рис. 6.3).

Рис. 6.3
Введение в Beats
Фреймворк Beats представляет собой легковесные компоненты для доставки данных, которые устанавливаются как агенты на пограничные серверы для передачи операционных данных в Elasticsearch. Как и Elasticsearch, Logstash и Kibana, Beats является продуктом с открытым исходным кодом. В зависимости от условий применения вы можете настроить Beats для доставки данных в Elasticsearch и для преобразования событий до их передачи в Elasticsearch.
Фреймворк Beats создан на основе библиотеки Libbeat, которая предоставляет инфраструктуру для упрощения процесса доставки операционных данных в Elasticsearch. Она предлагает API, которые могут быть использованы всеми компонентами Beats для отправки данных в источник вывода (такие как Elasticsearch, Logstash, Redis, Kafka и пр.), настроек параметров ввода/вывода, обработки событий, внедрения сбора данных и пр. Библиотека Libbeat создана на основе языка программирования Go. Он был выбран по причине простоты обучения, нетребовательности к ресурсам, статичной компиляции и легкого развертывания.
Компания Elastic.co разработала и поддерживает несколько компонентов Beats, таких как Filebeat, Packetbeat, Metricbeat, Heartbeat и Winlogbeat. Есть также несколько компонентов, созданных сообществом, в том числе amazonbeat, mongobeat, httpbeat и nginxbeat, которые были встроены в фреймворк Beats. Некоторые из компонентов расширены для соответствия нуждам бизнеса или имеют точки расширения. Если вы не нашли компонент Beats для своих целей, можете создать собственный с помощью библиотеки Libbeat (рис. 6.4).

Рис. 6.4
Beats от Elastic.co
В следующих разделах мы рассмотрим некоторые из широко распространенных компонентов Beats от Elastic.co.
Filebeat
Это легковесный агент доставки логов из локальных файлов, работает с открытым исходным кодом. Filebeat выступает как бинарный компонент, для запуска не нужна среда выполнения наподобие JVM, следовательно, он очень легковесный, исполняемый и потребляет меньше ресурсов. Filebeat устанавливается как агент на пограничных серверах, с которых необходимо доставлять логи. Он мониторит папки с логами или конкретные лог-файлы и направляет их в Elasticsearch, Logstash, Redis или Kafka. Агент легко масштабируется и предоставляет возможность доставлять логи из нескольких систем в централизованную систему/на сервер, из которых логи могут быть обработаны.
Metricbeat
Metricbeat — это легковесный поставщик для периодического сбора метрик из операционных систем и сервисов, запущенных на ваших серверах. Он помогает мониторить систему путем сбора метрик из нее, а также таких сервисов, как Apache, MondoDB, Redis и пр., запущенных на выбранном сервере. Metricbeat может передавать собранные метрики напрямую в Elasticsearch или отправлять в Logstash, Redis или Kafka. Для мониторинга сервисов Metricbeat может быть установлен на пограничный сервер, на котором запущены сервисы; также есть возможность сбора метрик и с удаленного сервера. Тем не менее рекомендуется устанавливать Metricbeat на тех серверах, на которых запущены сервисы.
Packetbeat
Packetbeat представляет собой анализатор сетевых пакетов в реальном времени, который работает путем захвата сетевого трафика между серверами приложений, декодируя протоколы уровня приложений (HTTP, MySQL, Redis, Memcache и др.), корректируя запросы ответами и записывая конкретные поля для каждой транзакции. Packetbeat отслеживает трафик между серверами, обрабатывает протоколы уровня приложения на лету и преобразует сообщения в транзакции. С его помощью можно легко диагностировать проблемы с приложением, например баги или проблемы производительности, и облегчить устранение неполадок. Packetbeat может быть запущен на том же сервере, где запущено приложение, или на отдельном. Собранная информация о транзакциях отправляется в настроенный вывод, а именно в Elasticsearch, Logstash, Redis или Kafka.
Heartbeat
Heartbeat — это новое дополнение в экосистеме Beats, которое используется для проверки того, работает ли сервис и доступен ли он. Heartbeat является легковесным демоном, который устанавливается на удаленном сервере для периодических проверок статуса работы сервисов, запущенных на сервере. Heartbeat поддерживает мониторинг ICMP, TCP и HTTP для проверки хостов/сервисов.
Winlogbeat
Winlogbeat специализируется на платформе Windows. Он устанавливается в виде службы Windows в операционной системе Windows XP или новее для чтения из одного или нескольких журналов событий с использованием API Windows. Он фильтрует события согласно настроенным пользователем параметрам, после чего отправляет данные событий на выбранный вывод, например в Elasticsearch или Logstash.
Winglobeat может захватывать такие данные, как события приложений, события оборудования, события безопасности и события системы.
Auditbeat
Auditbeat — это новое дополнение к семье компонентов Beats; впервые появился в версии Elastic Stack 6.0. Это легковесный компонент доставки данных, который устанавливается на серверах для мониторинга активности пользователей и процессов, а также для анализа данных событий в Elastic Stack без запуска Linux auditd. Компонент Auditbeat взаимодействует напрямую с фреймворком Linux audit, собирает аналогичный набор данных и в реальном времени отправляет данные в Elastic Stack. Кроме того, с его помощью вы можете следить за изменениями в определенных папках. Информация обо всех изменениях файлов отправляется в выбранный источник вывода в реальном времени, таким образом возможна идентификация потенциальных нарушений политики безопасности.
Компоненты Beats от сообщества
Разработчики из сообщества открытого исходного кода создают свои компоненты Beats, используя соответствующий фреймворк. В табл. 6.1 перечислено несколько таких компонентов.
Таблица 6.1
| Название компонента Beats | Описание |
| springbeat | Собирает сведения о метриках и рабочем состоянии из приложений Sping Boot, запущенных в пределах исполнительного модуля |
| rsbeat | Доставляет логи redis в Elasticsearch |
| nginxbeat | Читает статусы в Nginx |
| mysqlbeat | Выполняет запрос в MySQL и отправляет результаты в Elasticsearch |
| mongobeat | Мониторит процессы MongoDB и может отправлять различные типы документов в Elasticsearch в зависимости от конфигурации |
| gabeat | Собирает даннные из API Google Analytics в реальном времени |
| apachebeat | Читает статусы на серверах Apache HTTPD |
| amazonbeat | Считывает данные из выбранного продукта Amazon |
Полный список компонентов Beats от сообщества вы можете найти по следующей ссылке: https://www.elastic.co/guide/en/ beats/devguide/current/community-beats.html.

Имейте в виду, что компания Elastic.co не несет ответственности за компоненты Beats от сообщества, равно как и не осуществляет их поддержку.

Руководство разработчика Beats предоставляет необходимую информацию для создания собственного компонента. Руководство можно найти по следующей ссылке: https://www.elastic.co/guide/en/beats/devguide/current/index.html.
Logstash против Beats
Возможно, вы в небольшом замешательстве после прочтения предыдущих разделов с вводной информацией о компонентах Logstash и Beats, ведь не совсем понятно, взаимозаменяемы ли они и в чем между ними разница, в каких ситуациях использовать тот или иной компонент. Beats — это легковесные агенты, их особенность заключается в задействовании небольшого количества ресурсов. Следовательно, они устанавливаются на тех пограничных серверах, с которых необходимо собирать операционные данные. У компонента Beats нет мощного функционала Logstash в плане обработки и трансформации событий. Logstash имеет широкий ассортимент плагинов ввода, вывода, фильтрации, целью которых являются сбор, дополнение и преобразование данных из различных источников. Однако он требователен к ресурсам системы и также может использоваться как независимый продукт вне комплекса Elastic Stack. Рекомендуется устанавливать Logstash на выделенный сервер, а не на пограничные. Компоненты Beats и Logstash являются взаимодополняемыми и в зависимости от целей можно использовать их оба вместе либо по отдельности, как это описано в разделе «Введение в Beats».
Filebeat
Filebeat — это легковесный компонент с открытым исходным кодом, который устанавливается как агент для доставки логов из локальных файлов. Он мониторит определенные папки на наличие лог-файлов, отслеживает их и перенаправляет данные в Elasticsearch, Logstash, Redis или Kafka. Он легко масштабируется и способен доставлять логи из различных систем на централизированный сервер/в систему, где логи могут быть обработаны.
Скачивание и установка Filebeat
Перейдите по ссылке https://www.elastic.co/downloads/beats/filebeat и скачайте файл формата .tar/.zip в зависимости от вашей операционной системы. Установка компонента Filebeat довольно проста и понятна (рис. 6.5).
Рис. 6.5

Версии Beats 6.0.х совместимы с Elasticsearch 5.6.х и 6.0.х и Logstash версий 5.6.х и 6.0.х. Полную схему совместимости вы можете найти по ссылке: https://www.elastic.co/support/matrix#matrix_compatibility. Прежде чем рассматривать примеры использования Elasticsearch и Logstash совместно с Beats в этой главе, убедитесь, что у вас установлены совместимые версии.
Установка под Windows
Распакуйте скачанный файл. После распаковки перейдите в созданную папку, как показано в следующем фрагменте кода:
D:> cd D:\packt\filebeat-6.0.0-windows-x86_64

Для установки Filebeat как службы в Windows выполните следующие шаги.
1. Откройте Windows PowerShell как администратор и перейдите в папку с распакованными файлами.
2. Из командной строки PowerShell выполните следующие команды для установки Filebeat как службы Windows:
PS >cd D:\packt\filebeat-6.0.0-windows-x86_64
PS D:\packt\filebeat-6.0.0-windowsx86_
64>.\install-service-filebeat.ps1
Если в вашей системе отключено выполнение скриптов, необходимо настроить нужные политики для текущей сессии таким образом, чтобы вышеописанный скрипт был успешно выполнен. Например:
PowerShell.exe -ExecutionPolicy UnRestricted -File .\install-service-filebeat.ps1.
Установка под Linux
Распакуйте пакет tar.gz и перейдите в созданный каталог, как показано ниже:
$> tar -xzf filebeat-6.0.0-linux-x86_64.tar.gz
$> cd filebeat

Для установки с помощью deb или rpm выполните соответствующие команды в терминале:
deb:
curl -L -O
https://artifacts.elastic.co/downloads/beats/filebeat/fil
ebeat-6.0.0-amd64.deb
sudo dpkg -i filebeat-6.0.0-amd64.deb
rpm:
curl -L -O
https://artifacts.elastic.co/downloads/beats/filebeat/fil
ebeat-6.0.0-x86_64.rpm
sudo rpm -vi filebeat-6.0.0-x86_64.rpm
Filebeat будет установлен в папку /usr/share/filebeat. Файлы конфигурации расположены в папке /etc/filebeat. Скрипт init будет находиться в /etc/init.d/filebeat. Файлы log будут в папке /var/log/filebeat.
Архитектура
Filebeat состоит из трех ключевых компонентов, которые называются старателями (prospectors), сборщиками (harvesters) и спулерами (spooler). Эти компоненты работают совместно для отслеживания файлов и отправки данных событий в источник вывода согласно вашему выбору. Старатель отвечает за идентификацию списка файлов, из которых следует читать логи. В его настройках указываются один или несколько путей, по которым он находит файлы для чтения логов; для каждого файла запускается отдельный сборщик. Сборщик отвечает за чтение содержимого файла. Он читает каждый файл строка за строкой и отправляет содержимое в вывод. Он также отвечает за открытие и закрытие каждого файла, следовательно, во время его работы дескриптор файла остается открытым. Далее сборщик отправляет считанное содержимое (то есть события) спулеру, который занимается агрегацией и отправкой данных в настроенный вывод.
Каждый запущенный процесс Filebeat может быть настроен для работы с одним или несколькими старателями. В данный момент предусмотрена поддержка двух типов старателей: log и stdin. Если тип ввода — log, старатель находит все файлы на диске, которые соответствуют выбранным путям для файлов, и запускает сборщики для каждого файла. Каждый старатель работает по своему маршруту Go. Если тип ввода stdin, старатель будет считывать по стандартным вводам.
При каждом чтении файла в Filebeat сборщик запоминает последнюю позицию, и, если прочитанная строка отправлена в вывод, данные о ней сохраняются в файле реестра, который периодически выгружается на диск. Если нет доступа к источнику вывода (такому как Elasticsearch, Logstash, Redis или Kafka), текущая позиция чтения файла запоминается в Filebeat и чтение продолжится сразу же, как только станет доступен источник вывода. Пока Filebeat работает, информация о позиции хранится в памяти каждого старателя. Если Filebeat был перезапущен, для продолжения работы каждого сборщика будет использована информация о последней обработанной позиции из файла реестра.
Filebeat не считает строку лога доставленной до той поры, пока источник вывода не был опрошен и пока состояние доставки строк в выбранный вывод не записано в файл реестра. Filebeat гарантирует, что события будут доставлены в настроенный вывод как минимум один раз, без потери данных.

Место хранения файла реестра будет следующим: data/registry для архивов .tar.gz и .zip, /var/lib/filebeat/registry для пакетов DEB и RPM, C:\ProgramData\filebeat\registry для файлов .zip Windows, если Filebeat установлен как служба (рис. 6.6).
Более детальную информацию об этом вы найдете по ссылке: https://www.elastic.co/guide/en/beats/filebeat/6.0/images/filebeat.png.
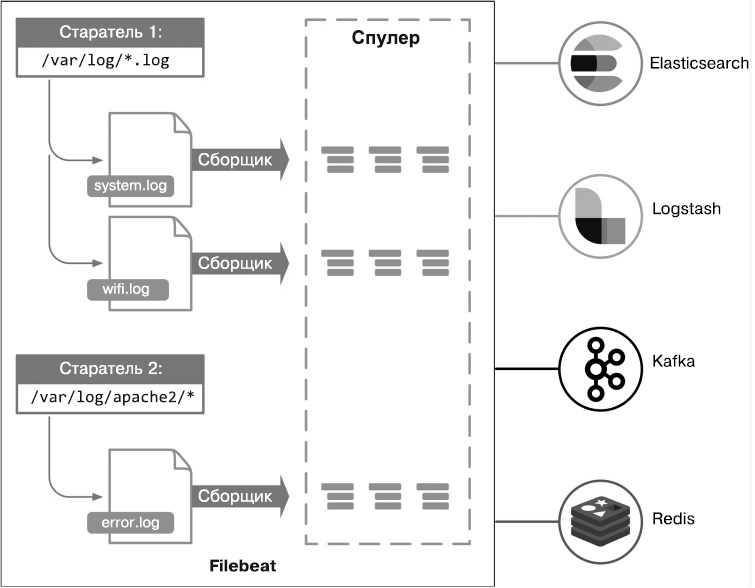
Рис. 6.6
Настройка Filebeat
Все настройки, связанные с Filebeat, хранятся в конфигурационном файле с названием filebeat.yml. Он использует синтаксис YAML.
Этот файл содержит разделы с информацией о таких показателях, как:
• старатели;
• глобальные настройки;
• общие настройки;
• конфигурация вывода;
• конфигурация обработки;
• конфигурация папок;
• конфигурация модулей;
• конфигурация панели управления;
• конфигурация сбора данных.

Файл filebeat.yml будет присутствовать в папке установки только в том случае, если использовались файлы .zip или .tar. Если для установки были запущены файлы DEB или RPM, тогда он будет расположен в каталоге /etc/filebeat.
Некоторые из этих разделов являются общими для всех типов компонентов Beats. Прежде чем мы рассмотрим их детально, взглянем на пример простой конфигурации. В примере ниже видно, что при запуске Filebeat ищет файлы с расширением .log в папке D:\packt\logs\. Он будет доставлять все записи каждого файла в Elasticsearch, который настроен как источник вывода и находится по адресу localhost:9200:
#filebeat.yml
#=========================== Filebeat prospectors
=============================
filebeat.prospectors:
- input_type: log
# Paths that should be crawled and fetched. Glob based paths.
paths:
- D:\packt\logs\*.log
#================================ Outputs
=====================================
#-------------------------- Elasticsearch output --------------------------
----
output.elasticsearch:
# Array of hosts to connect to.
hosts: ["localhost:9200"]

При внесении изменений в файл filebeat.yml необходимо перезапустить компонент Filebeat, чтобы изменения вступили в силу.
Рекомендуется тестировать конфигурацию каждый раз при внесении изменений. Для тестирования используйте флаг -configtest:
D:\packt\filebeat-6.0.0-windows-x86_64>filebeat.exe -configtest
filebeat.yml
Config OK

Для указания флагов Filebeat должен быть запущен в фоновом режиме. Невозможно указывать флаги командной строки, если Filebeat запущен с помощью скрипта init.d в виде deb или rpm или в виде службы Windows.
Разместите несколько лог-файлов в папке D:\packt\logs\. Чтобы Filebeat приступил к доставке логов, выполните следующую команду:
Windows:
D:\packt\filebeat-6.0.0-windows-x86_64>filebeat.exe
Linux:
[locationOfFilebeat]$ ./filebeat
Для проверки успешной доставки логов в Elasticsearch выполните такую команду:
D:\packt>curl -X GET http://localhost:9200/filebeat*/_search?pretty
Образец ответа:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 6,
"max_score" : 1.0,
"hits" : [
{
"_index" : "filebeat-2017.11.23",
"_type" : "doc",
"_id" : "AV_niRjbPYptcfAHfGNx",
"_score" : 1.0,
"_source" : {
"@timestamp" : "2017-11-23T06:20:36.577Z",
"beat" : {
"hostname" : "SHMN-IN",
"name" : "SHMN-IN",
"version" : "6.0.0"
},
"input_type" : "log",
"message" : "line2",
"offset" : 14,
"source" : "D:\\packt\\logs\\test.log",
"type" : "log"
}
},
{
"_index" : "filebeat-2017.11.23",
"_type" : "doc",
"_id" : "AV_niRjbPYptcfAHfGNy",
"_score" : 1.0,
"_source" : {
"@timestamp" : "2017-11-23T06:20:36.577Z",
"beat" : {
"hostname" : "SHMN-IN",
"name" : "SHMN-IN",
"version" : "6.0.0"
},
"input_type" : "log",
"message" : "line3",
"offset" : 21,
"source" : "D:\\packt\\logs\\test.log",
"type" : "log"
}
},
...
...
...

Доставленные логи будут размещены в индексе filebeat с меткой времени, которая создана по шаблону filebeat-YYYY.MM.DD. Лог-данные будут расположены в поле message.
Для запуска Filebeat при установке deb или rpm выполните команду sudo service filebeat start. Если он установлен в виде службы Windows, используйте следующую команду в PowerShell: PS C:\> Start-Service filebeat.
Старатели Filebeat
Этот раздел содержит список старателей, которые используются в Filebeat для обнаружения и обработки лог-файлов. Каждая запись начинается с дефиса (-) и содержит определенные для каждого старателя параметры, включая один или несколько путей для поиска файлов.
Образец конфигурации выглядит так, как показано на рис. 6.7.
Возможны следующие настройки для старателей.
• input_type — этот параметр принимает типы log или stdin. Тип log используется для чтения каждой строки логов из файла, а тип stdin — для чтения из стандартного источника ввода. Типом по умолчанию является log.
• paths применяется для указания одного или нескольких путей с целью поиска файлов для обработки. Каждый путь указывается с новой строки, начиная с дефиса (-). Параметр paths принимает пути на базе Golang glob, равно как и остальные шаблоны этого типа (более детально — по ссылке https://golang.org/pkg/path/filepath/#Glob).
• exclude_lines — принимает список регулярных выражений для соответствия. Он исключает из списка все строки, содержащие соответствия регулярному выражению. В предыдущем примере конфигурации исключаются все строки, которые начинаются с DBG.
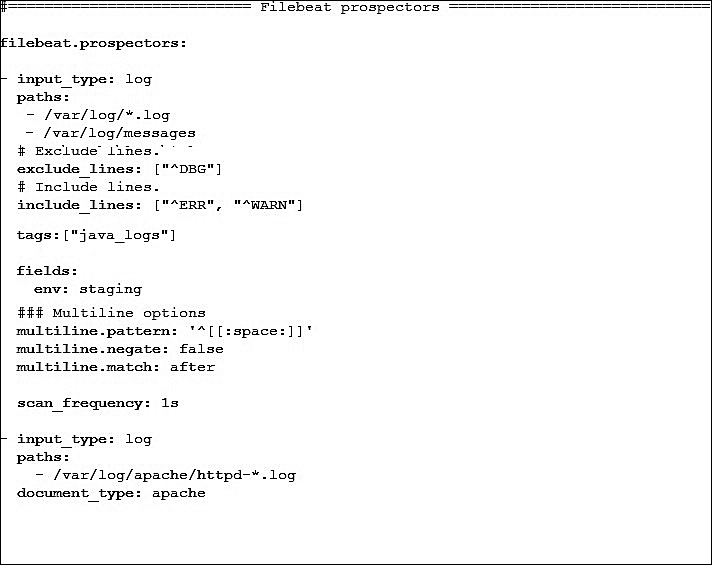
Рис. 6.7
• include_lines — параметр принимает список регулярных выражений для соответствия. Он экспортирует из списка все строки, содержащие соответствия регулярному выражению. В предыдущем примере конфигурации экспортируются все строки, которые начинаются с ERR или WARN.

Регулярные выражения (regex) создаются на основе RE2 (более детально — по ссылке: https://godoc.org/regexp/syntax). На данном сайте вы сможете найти все поддерживаемые шаблоны regex.
• tags — принимает список тегов, которые будут включены в поле tags каждого события, которое доставляется Filebeat. tags помогает с условной фильтрацией событий в Kibana или Logstash. В предыдущем примере конфигурации в список tags добавляется java_logs.
• fields — используется для указания опциональных полей, которые необходимо включать в каждое событие, которое доставляется Filebeat. По аналогии с tags этот параметр помогает с условной фильтрацией событий в Kibana или Logstash. Поля могут содержать скалярные значения, массивы, словари или любые комбинации из перечисленного. По умолчанию все указанные поля будут сгруппированы в словарь fields в документе вывода. В предыдущем примере конфигурации новое поле с названием env и значением staging будет создано под fields.

Для того чтобы сохранить поля как высокоуровневые, установите для параметра fields_under_root значение true.
• scan_frequency — применяется для указания интервала времени, после которого старатель проверяет наличие новых файлов в настроенных папках. В предыдущем примере конфигурации старатель проверяет наличие новых файлов каждую секунду. По умолчанию в параметре scan_frequency установлено 10 с.
• document_type — используется для указания типа индекса в выводе в Elasticsearch. Тип по умолчанию — log. В предыдущем примере конфигурации логи Apache настроены на тип apache таким образом, что во время индексирования в Elasticsearch их можно найти под типом apache. Название индекса и далее будет соответствовать шаблону filebeat-YYYY.MM.DD.
• multiline — указывает, как необходимо обрабатывать логи, разделенные по нескольким строкам. Это очень полезно для процессинга сообщений трассировки или исключений стека.
Параметр pattern определяет шаблон регулярного выражения для соответствия: negate указывает, следует ли отвергать шаблон, и match, который задает, как Filebeat сопоставляет соответствующие строки с событием. Параметр negate может иметь значение true либо false; по умолчанию установлено false. Параметр match может иметь значение after либо before. В предыдущем примере конфигурации все последующие строки, начинающиеся с пробела, объединяются с предыдущей строкой, которая не начинается с пробела.

Настройка after похожа на мультистроковую настройку previous в Logstash, равно как и before схожа с next.
Глобальные настройки Filebeat
Этот раздел содержит настройки конфигурации, которые контролируют поведение Filebeat на глобальном уровне. Ниже приведены некоторые из них.
• registry_file — используется для указания местонахождения файла реестра, который применяется для хранения информации о файлах, например о месте чтения и статусе получения считанных строк в настроенных источниках вывода. По умолчанию местонахождение файла реестра таково: ${path.data}/registry:
filebeat.registry_file: /etc/filebeat/registry

В качестве значения этого параметра допускается указать относительный или абсолютный путь. Если используется относительный путь, считается, что он относится к настройке ${path.data}.
• shutdown_timeout — эта настройка указывает, как долго Filebeat будет ожидать окончания публикации при завершении работы. Если завершение работы Filebeat происходит во время процесса передачи событий, он не будет ждать, пока источник вывода посчитает все события принятыми. Эта настройка дает Filebeat указание ожидать определенный промежуток времени, прежде чем завершать работу. Это выглядит следующим образом:
filebeat.shutdown_timeout: 10s
Общие настройки Filebeat
Этот раздел содержит настройки конфигурации и некоторые общие настройки, контролирующие поведение Filebeat.
• name — название отправителя, который публикует сетевые данные. По умолчанию для этого поля используется hostname:
name: "dc1-host1"
• tags — список тегов, который будет включен в поле tags для каждого события, которое доставляется с помощью Filebeat. Благодаря тегам можно легко группировать серверы по различным логическим свойствам, а также легко фильтровать события в Kibana и Logstash:
tags: ["staging", "web-tier","dc1"]
• max_procs — максимальное количество центральных процессоров (ЦП), которые могут быть использованы одновременно. По умолчанию задействуются все логические ЦП, доступные в системе:
max_procs: 2
Конфигурация вывода
Этот раздел используется для настройки выводов, в которые должны доставляться события. Возможна отправка в один или несколько выводов одновременно. Источниками вывода являются Elasticsearch, Logstash, Redis, Kafka, файл или консоль.
Некоторые из возможных источников вывода могут быть настроены, как показано ниже.
• elasticsearch — используется для отправки событий напрямую в Elasticsearch.
Образец конфигурации вывода в Elasticsearch выглядит следующим образом:
output.elasticsearch:
enabled: true
hosts: ["localhost:9200"]
С помощью настройки enabled можно включать или выключать вывод. Параметр hosts принимает один или несколько узлов/серверов Elasticsearch. Множественные хосты могут быть указаны с целью достижения устойчивости при сбоях. В случаях, когда настроено несколько хостов, события доставляются по этим узлам в циклическом порядке. Если настроена авторизация Elasticsearch, данные аутентификации могут быть введены с помощью параметров username и password:
output.elasticsearch:
enabled: true
hosts: ["localhost:9200"]
username: "elasticuser"
password: "password"
При доставке событий в контейнер узла поглощения Elasticsearch информацию о контейнере можно указать под параметром pipleline — тогда их можно будет предварительно обработать до хранения в Elasticsearch:
output.elasticsearch:
enabled: true
hosts: ["localhost:9200"]
pipeline: "apache_log_pipeline"
• logstash — используется для отправки событий в Logstash.

Чтобы задействовать Logstash как источник вывода, необходимо настроить его с плагином ввода Beats для получения входящих событий Beats.
Образец конфигурации вывода в Logstash выглядит следующим образом:
output.logstash:
enabled: true
hosts: ["localhost:5044"]
С помощью настройки enabled можно включать или выключать вывод. Параметр hosts принимает один или несколько узлов/серверов Logstash. Множественные хосты могут быть указаны с целью достижения устойчивости при сбоях. Если настроенный хост не отвечает, тогда события будут отправлены в один из других перечисленных в настройках хостов. В случаях, когда настроено несколько хостов, события доставляются по этим узлам в случайном порядке. Для включения балансировки нагрузки событий на хосты Logstash присвойте параметру loadbalance значение true:
output.logstash:
hosts: ["localhost:5045", "localhost:5046"]
loadbalance: true
• console — применяется для отправки событий в stdout. События будут записаны в формате JSON. Полезно для задач тестирования или отладки.
Образец конфигурации консоли выглядит следующим образом:
output.console:
enabled: true
pretty: true
Модули Filebeat
Модули Filebeat упрощают процесс сбора, обработки и визуализации логов популярных форматов.
Модуль состоит из одного или нескольких наборов файлов. В набор файлов входят следующие составляющие.
• Конфигурации старателя Filebeat, содержащие папки по умолчанию, в которых следует искать логи. Предоставляется также конфигурация для комбинирования мультистроковых событий при необходимости.
• Определение контейнера поглощения Elasticsearch для обработки и дополнения логов.
• Шаблоны Elasticsearch с определениями полей, используемых с целью корректной разметки полей для событий.
• Примеры панелей управления Kibana, которые могут быть задействованы для визуализации логов.

Для работы модулей Filebeat необходим узел поглощения Elasticsearch, а версия Elasticsearch должна быть не ниже 5.2.
Ниже перечислены модули по умолчанию, которые поставляются в комплекте с Filebeat:
• Apache2;
• Auditd;
• MySQL;
• Nginx;
• Redis;
• Icinga;
• модуль системы.
Каталог modules.d содержит конфигурации по умолчанию для всех модулей, доступных в Filebeat. Конфигурация каждого модуля хранится в файле .yml, а название файла соответствует названию модуля. Например, конфигурация модуля redis будет храниться в файле redis.yml.
Поскольку каждый модуль поставляется с конфигурацией по умолчанию, вы можете внести необходимые изменения в файле конфигурации модуля.
Базовая конфигурация для модуля redis будет выглядеть следующим образом:
#redis.yml
- module: redis
# Main logs
log:
enabled: true
# Set custom paths for the log files. If left empty,
# Filebeat will choose the paths depending on your OS.
#var.paths: ["/var/log/redis/redis-server.log*"]
# Slow logs, retrieved via the Redis API (SLOWLOG)
slowlog:
enabled: true
# The Redis hosts to connect to.
#var.hosts: ["localhost:6379"]
# Optional, the password to use when connecting to Redis.
#var.password:
Для включения модулей выполните команду modules enable, добавив одно или несколько названий модулей:
Windows:
D:\packt\filebeat-6.0.0-windows-x86_64>filebeat.exe modules enable redis mysql
Linux:
[locationOfFileBeat]$./filebeat modules enable redis mysql

Если модуль выключен, конфигурация для него в папке modules.d будет храниться с расширением файла .disabled.
Аналогичным образом для выключения модулей выполните команду modules disable, добавив одно или несколько названий модулей. Например:
Windows:
D:\packt\filebeat-6.0.0-windows-x86_64>filebeat.exe modules disable redis mysql
Linux:
[locationOfFileBeat]$./filebeat modules disable redis mysql
Как только модуль активизирован, выполните команду setup, чтобы загрузить рекомендованный шаблон индекса для записи в Elasticsearch и развернуть примеры панелей управления для визуализации данных в Kibana. Это происходит следующим образом:
Windows:
D:\packt\filebeat-6.0.0-windows-x86_64>filebeat.exe -e setup
Linux:
[locationOfFileBeat]$./filebeat -e setup
Флаг -е указывает вывод в stdout. Как только модули активизированы и выполнена команда setup, запустите Filebeat, как обычно, для загрузки шаблонов индекса и примеров панелей управления. Компонент приступит к доставке логов в Elasticsearch.

Вам необходимо выполнять команду setup во время установки или обновления Filebeat или после активизации нового модуля.
Некоторые модули имеют плагины зависимости, например ingest-geoip и ingest-user-agent. Для корректной работы их необходимо установить на Elasticsearch до настройки модулей, в противном случае установка завершится ошибкой.
Вместо того чтобы активизировать модули путем ввода их как параметров командной строки, вы можете включать их внутри самого конфигурационного файла filebeat.yml и запускать Filebeat, как обычно:
filebeat.modules:
- module: nginx
- module: mysql
Каждый модуль имеет назначенные ему наборы файлов, которые содержат определенные переменные. Их можно заменить своими, с помощью файла конфигурации или параметров командной строки, используя флаг -М во время работы Filebeat.
Если вы работаете с конфигурационным файлом, сделайте следующее:
filebeat.modules:
- module: nginx
access:
var.paths: ["C:\ngnix\access.log*"]
Если вы используете командную строку, сделайте следующее:
Windows:
D:\packt\filebeat-6.0.0-windows-x86_64>filebeat.exe -e -modules=nginx -M
"nginx.access.var.paths=[C:\ngnix\access.log*]"
Linux:
[locationOfFileBeat]$./filebeat -e -modules=nginx -M
"nginx.access.var.paths=[\var\ngnix\access.log*]"
Резюме
Из этой главы вы узнали о мощных возможностях фильтрации Logstash, которые предназначены для обработки и дополнения событий. Мы также рассмотрели некоторые из наиболее распространенных плагинов фильтрации. Помимо этого, мы поговорили о работе фреймворка Beats, провели обзор различных компонентов Beats, таких как Filebeat, Heartbeat, Packetbeat и др., а в компоненте Filebeat разобрались особенно детально.
В следующей главе мы обсудим различные возможности X-Pack — коммерческого предложения от Elastic.co, которое содержит такой функционал, как настройки безопасности для Elastic Stack, возможности мониторинга, рассылки уведомлений, построения графиков, создания отчетности и многое другое.

