5. Анализ журнальных данных
Логи содержат подробную информацию о состоянии и работе системы или приложения. Каждая система/приложение записывает логи при любом событии; частота, объем и формат информации в логах меняются от одной системы/приложения к другой. С таким объемом информации в нашем распоряжении сбор логов, извлечение важной информации из них и их анализ в реальном времени может оказаться трудной задачей.
В предыдущих главах вы уже узнали, как Elasticsearch с его широкими возможностями агрегации помогает анализировать огромные объемы данных в псевдореальном времени. Прежде чем приступать к анализу, нужно найти инструмент, который может содействовать процессу сбора логов или упрощать его, извлекать важную информацию из логов и передавать ее в Elasticsearch.
В этой главе мы познакомимся с Logstash, еще одним ключевым компонентом Elastic Stack, который в основном используется как движок ETL (Extract, Transform and Load — «извлечение, трансформация и загрузка»). Мы также рассмотрим следующие темы.
• Вызовы при анализе логов.
• Реакция Logstash на вызовы.
• Высокоуровневая архитектура Logstash.
• Плагины Logstash.
• Узел поглощения (ingest node) — новая функция Elasticsearch 5.x. Это легковесное решение для предварительной обработки и пополнения информацией документов внутри Elasticsearch.
Вызовы при анализе логов
Логи — это записи об инцидентах или наблюдениях. Логи создаются широким спектром ресурсов, таких как системы, приложения, устройства, люди и т.д. Лог обычно содержит два показателя: метку времени (время записи события) и информацию о событии:
Log = Timestamp + Data
Логи используются для следующих целей.
• Устранение неполадок. Когда сообщается о баге или проблеме, в первую очередь информацию об этом нужно искать в логе. Например, при отслеживании стека исключений в логах можно легко найти причину проблемы.
• Понимание поведения системы/приложения. Во время работы приложения/системы лог работает как черный ящик. Изучая логи, вы поймете, что происходит внутри системы/приложения. Например, в логах можно отслеживать время, использованное разными фрагментами кода внутри приложения, и таким образом выявить узкие места и оптимизировать код для лучшей производительности.
• Аудит. Многие организации должны придерживаться тех или иных процедур проверки на соответствие и вынуждены вести логи. Например, входы пользователей в систему или их транзакции обычно хранятся в логах определенный промежуток времени, чтобы можно было провести аудит или анализ злоумышленной деятельности пользователей/хакеров.
• Предиктивная аналитика. С развитием машинного обучения, искусственного интеллекта и методов извлечения данных появился новый тренд — предиктивная аналитика. Это область углубленной аналитики; специализируется на прогнозировании неизвестных событий, которые могут случиться в будущем. По результатам данных истории пользователя или транзакций возможно создать шаблоны и использовать их для выявления как возможностей, так и рисков в будущем. Предиктивная аналитика также позволяет организациям на основе полученных данных предугадывать результаты и поведение пользователей. Среди примеров применения предиктивной аналитики — предложения посетителям сайтов купить конкретную вещь или посмотреть фильм, выявление мошенничества, оптимизация маркетинговых кампаний и т.д.
Исходя из предыдущих примеров использования логов, можно прийти к выводу, что логи удобно задействовать для интенсивной обработки информации и применять для решения разного рода задач. Однако у логов есть свои особенности. Вот некоторые из них.
• Нестандартный/несовместимый формат. Каждая система записывает логи в своем собственном формате, поэтому администратору или конечному пользователю важно уметь разбираться в форматах логов, созданных каждой системой/приложением. Поскольку форматы различаются, поиск по разным типам логов может быть затруднительным. На рис. 5.1 показан типичный пример логов сервера SQL, исключений/логов Elasticsearch и логов NGNIX.
• Децентрализованные логи. Поскольку логи записываются широким спектром различных ресурсов, таких как системы, приложения, устройства и т.д., зачастую они разбросаны по нескольким серверам. С развитием облачных и распределенных вычислений стало намного сложнее выполнять поиск по логам, поскольку стандартные инструменты наподобие SSH и grep нельзя масштабировать. Следовательно, есть необходимость в централизованном управлении логами для упрощения поиска нужной информации аналитиками/администраторами.
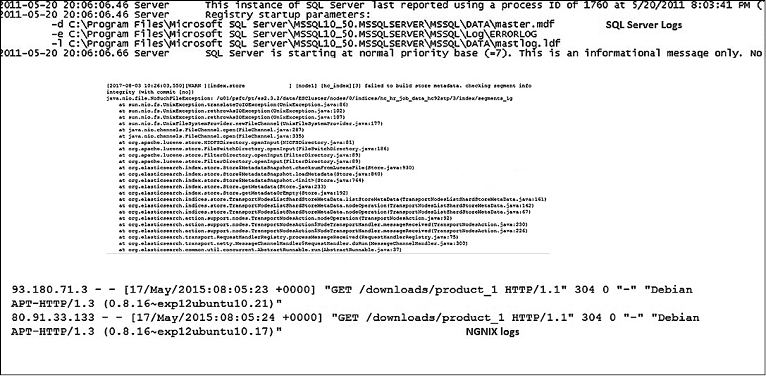
Рис. 5.1
• Несовместимый формат времени. Логи хранят метки даты/времени, каждая система/приложение записывает время в своем формате, делая затруднительным идентификацию точного времени события (некоторые форматы более удобны для машин, чем для людей). Взаимосвязанные события происходят одновременно в разных системах. Вот лишь несколько примеров форматов времени, которые можно встретить в логах:
Nov 14 22:20:10
[10/Oct/2000:13:55:36 -0700]
172720538
053005 05:45:21
1508832211657
• Неструктурированные данные. Лог-данные не структурированы, и из-за этого может быть затруднен их анализ. Данные необходимо приводить к правильному виду прежде, чем потребуется выполнять анализ или поиск. Многие инструменты для анализа зависят от того, структурированы ли данные полностью или частично.
В следующем разделе вы узнаете, как Logstash может помочь в преодолении упомянутых проблем и облегчить процесс анализа логов.
Logstash
Logstash — популярный движок сбора данных с открытым исходным кодом. Он также имеет возможности работы с контейнерами в реальном времени. Logstash позволяет легко строить контейнеры для сбора данных из широкого спектра источников и обрабатывать их, дополнять, унифицировать и отправлять на хранение в различные места. Logstash предоставляет набор плагинов, известных как фильтры ввода и плагины вывода. Они довольно просты в использовании и облегчают процесс унифицирования и нормализации больших объемов разнообразных данных. Logstash выполняет работу движка ETL (рис. 5.2).
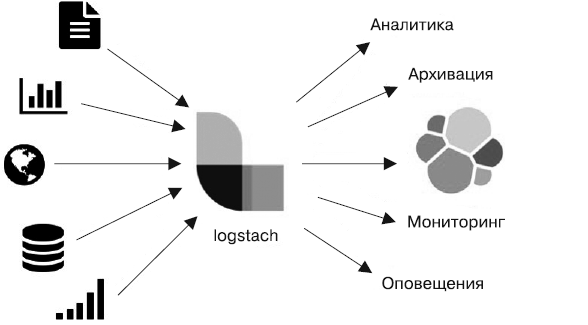
Рис. 5.2
Перечислим некоторые из особенностей Logstash.
• Гибкая архитектура, основанная на плагинах. Logstash содержит более 200 плагинов, разработанных компанией Elastic и сообществом открытого исходного кода. Вы можете использовать их для объединения, сопоставления и организации различных источников ввода, фильтров и выводов, а также создания контейнеров для обработки данных.
• Расширяемость. Компонент Logstash написан на Jruby и поддерживает гибкую архитектуру. Допускается создание собственных плагинов для персональных нужд.
• Централизованная обработка данных. Данные из любых источников можно легко извлекать с применением разнообразных плагинов ввода, а также дополнять их, изменять и отправлять различным получателям.
• Универсальность. Logstash поддерживает обработку всех типов логов, таких как логи Apache, NGINIX, системные логи, логи событий Windows. Он также предоставляет сбор метрик из широкого спектра приложений через TCP и UDP. Logstash может трансформировать запросы HTTP в события, поддерживает такие приложения, как Meetup, GitHub, JIRA и др. Возможен также сбор данных из имеющихся реляционных/NoSQL баз данных и очередей, включая Kafka, RabbitMQ и т.п. Контейнер обработки данных Logstash может быть легко масштабирован горизонтально. Начиная с версии Logstash 5, поддерживаются постоянные очереди, благодаря чему обеспечивается возможность надежно обрабатывать большие объемы входящих событий/данных.
• Совместная работа. Logstash имеет высокую связность с компонентами Elasticsearch, Beats и Kibana, что облегчает создание сквозных решений для анализирования логов.
Установка и настройка
В следующих разделах мы рассмотрим установку и настройку Logstash в вашей системе.
Системные требования. Для работы Logstash необходимы Java runtime, Java 8. Убедитесь, что JAVA_HOME установлена как переменная среды. Для проверки своей версии Java выполните следующую команду:
java -version
Вы должны увидеть такой вывод:
java version "1.8.0_65"
Java(TM) SE Runtime Environment (build 1.8.0_65-b17)
Java HotSpot(TM) 64-Bit Server VM (build 25.65-b01, mixed mode)

Для Java вы можете использовать официальный дистрибутив Oracle (http://www.oracle.com/technetwork/java/javase/downloads/index.html) или дистрибутив с открытым исходным кодом, например OpenJDK (http://openjdk.java.net/).
Скачивание и установка Logstash
Скачать и установить Logstash не составит труда. Перейдите по ссылке https://www.elastic.co/downloads/logstash#ga-release и в зависимости от вашей операционной системы скачайте файл ZIP/TAR, как указано на рис. 5.3.
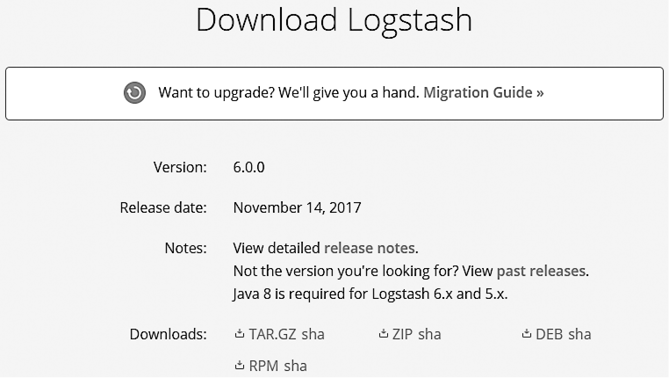
Рис. 5.3

Сообщество разработчиков Elastic динамично развивается, и релизы новых версий с обновленным функционалом и исправлениями выходят довольно часто. За время, которое вы уделили чтению этой книги, последняя версия Logstash могла измениться. Информация в книге актуальна для версии Logstash 6.0.0. Вы можете перейти по ссылке past releases (прошлые релизы) и скачать версию 6.0.0, если хотите продолжать как есть. Но материал хорошо подойдет и для любого релиза версии 6.х.
В отличие от Kibana, который требует совместимости с Elasticsearch как по основным, так и по младшим версиям, версии Logstash начиная с 5.6 совместимы с Elasticsearch. Полную схему совместимости вы можете найти по ссылке https://www.elastic.co/support/matrix#matrix_compatibility.
Установка под Windows
Распакуйте скачанный файл. После распаковки перейдите в созданный каталог, как показано в следующем фрагменте кода:
D:\>cd D:\packt\logstash-6.0.0

Мы будем указывать каталог установки Logstash как LOGSTASH_HOME.
Установка под Linux
Распакуйте пакет tar.gz и перейдите в созданный каталог, как показано ниже:
$> tar -xzf logstash-6.0.0.tar.gz
$>cd logstash/
Запуск Logstash
Для запуска Logstash необходимо указать конфигурацию. Это можно сделать напрямую, используя параметр -е при указании конфигурационного файла (файл .conf) или указав параметр/флаг -f.
С помощью терминала/командной строки перейдите к LOGSTASH_HOME/bin. Убедитесь, что Logstash корректно работает после установки, выполнив следующую команду с простой конфигурацией (контейнер logstash) в качестве параметра:
D:\packt\logstash-6.0.0\bin>logstash -e 'input { stdin { } } output {
stdout {} }'
Вы должны получить следующие логи:
Sending Logstash's logs to D:/packt/logstash-6.0.0/logs which is now configured via log4j2.properties
[2017-10-30T12:42:12,046][INFO ][logstash.modules.scaffold]
Initializing module {:module_name=>"fb_apache",
:directory=>"D:/packt/logstash-6.0.0/modules/fb_apache/configuration"}
[2017-10-30T12:42:12,052][INFO ][logstash.modules.scaffold]
Initializing module {:module_name=>"netflow",
:directory=>"D:/packt/logstash-6.0.0/modules/netflow/configuration"}
[2017-10-30T12:42:12,094][INFO ][logstash.agent ]
No persistent UUID file found. Generating new UUID
{:uuid=>"fd6c25ed-6450-40fd-912a-c83bf2aec638",
:path=>"D:/packt/logstash-6.0.0/data/uuid"}
[2017-10-30T12:42:12,429][INFO ][logstash.pipeline ]
Starting pipeline {"id"=>"main", "pipeline.workers"=>4,
"pipeline.batch.size"=>125, "pipeline.batch.delay"=>5,
"pipeline.max_inflight"=>500}
[2017-10-30T12:42:12,490][INFO ][logstash.pipeline ]
Pipeline main started
The stdin plugin is now waiting for input:
[2017-10-30T12:42:12,703][INFO ][logstash.agent ] Successfully started
Logstash API endpoint {:port=>9600}
Теперь введите любой текст и нажмите клавишу Enter. Logstash добавляет к введенному текстовому сообщению метку времени и информацию об IP-адресе. Для выхода из Logstash нажмите Ctrl+C в оболочке, где была запущена утилита.
Итак, мы только что успешно запустили Logstash с парой простых конфигураций (контейнер). В следующем разделе мы подробнее поговорим о контейнерах в Logstash.
Архитектура Logstash
Контейнер обработки событий в Logstash имеет три стадии: ввода, фильтрации, вывода (рис. 5.4). Обязательны лишь ввод и вывод. Фильтрация является опциональной.

Рис. 5.4
Ввод создает события, фильтры модифицируют события ввода, выводы доставляют их в пункт назначения. Вводы и выводы поддерживают кодеки, которые позволяют кодировать или декодировать данные в момент их входа в контейнер или выхода из него без необходимости использования отдельного фильтра.
Для буферизации Logstash использует ограниченные очереди памяти между стадиями контейнеров по умолчанию (из ввода в фильтр и из фильтра в вывод). Если программа терминируется небезопасным способом, любые события в памяти будут потеряны. Для избежания потерь вы можете сохранять текущие события на диск путем использования сохраняющихся очередей.

Сохраняющиеся очереди можно активизировать путем настройки queue.type: persisted в файле logstash.yml, который находится в папке LOGSTASH_HOME/config. logstash.yml — конфигурационный файл, который содержит настройки Logstash.
По умолчанию Logstash запускается с буфером размером 1 Гбайт. Вы можете изменить это в настройках Xms и Xmx в файле jvm.options, который находится в папке LOGSTASH_HOME/config.
Контейнер Logstash хранится в конфигурационном файле, имеющем расширение .conf. Ниже перечислены три секции конфигурационного файла:
input
{
}
filter
{
}
output
{
}
Каждая из этих секций содержит одну или несколько конфигураций плагинов. Вы можете настроить плагин, указав его имя и далее настройки в виде пары «ключ/значение». Значение ключу присваивается с помощью оператора =>.
Возьмем тот же конфигурационный файл, который мы использовали в предыдущем разделе, и с некоторыми изменениями сохраним его в файл:
#simple.conf
#A simple logstash configuration
input {
stdin { }
}
filter {
mutate {
uppercase => [ "message" ]
}
}
output {
stdout {
codec => rubydebug
}
}
Создадим папку conf в каталоге LOGSTASH_HOME. Создадим файл с названием simple.conf в папке LOGSTASH_HOME/conf.

На практике оптимально размещать все конфигурации в отдельных каталогах в папке LOGSTASH_HOME или в другом месте, вместо того чтобы хранить их в папке LOGSTASH_HOME/bin.
Возможно, вы обратили внимание, что файл содержит два обязательных элемента: ввод и вывод. В секции ввода фигурирует плагин с именем stdin, который принимает параметры по умолчанию. Секция вывода имеет плагин stdout, который принимает кодек rubydebug. Эти плагины используются для чтения из стандартного ввода и записи информации о событиях в стандартный вывод. Кодек rubydebug предназначен для вывода данных событий с помощью библиотеки Ruby Awesome Print. Он также содержит секцию фильтров с плагином mutate, который преобразует входящие сообщения событий в верхний регистр.
Запустим Logstash с новым контейнером/конфигурацией в файле simple.conf, как показано ниже:
D:\packt\logstash-6.0.0\bin>logstash -f ../conf/simple.conf
Как только Logstash запущен, введите любой текст, например LOGSTASH IS AWESOME. Вы должны увидеть следующий ответ:
{
"@version" => "1",
"host" => "SHMN-IN",
"@timestamp" => 2017-11-03T11:42:56.221Z,
"message" => "LOGSTASH IS AWESOME\r"
}
Как видите, вместе с сообщением ввода Logstash автоматически добавляет метку времени с указанием времени создания события, а также информацию о хосте и номере версии. Вывод имеет понятный вид благодаря кодеку rubydebug. Входящие события всегда сохраняются в поле под названием message.

Поскольку конфигурация была указана в файле, при запуске Logstash мы использовали флаг/параметр -f.
Обзор плагинов Logstash
Для Logstash существует обширная коллекция плагинов ввода, вывода, фильтрации, кодеков. Плагины доступны в виде автономных пакетов и размещаются на сайте RubyGems.org. По умолчанию многие распространенные плагины доступны как часть дистрибутива Logstash. Чтобы увидеть список плагинов, которые входят в текущую установку, выполните следующую команду:
D:\packt\logstash-6.0.0\bin>logstash-plugin list

Если к предыдущей команде добавить флаг --verbose, можно узнать версии каждого плагина.
Используя флаг --group с уточнением типа ввод, вывод, фильтр или кодек, мы можем узнать список установленных плагинов соответствующего типа. Например:
D:\packt\logstash-6.0.0\bin>logstash-plugin list --group filter
Кроме того, можно найти все плагины по фрагменту названия, если указать его следующим образом в logstash-plugin list:
D:\packt\logstash-6.0.0\bin>logstash-plugin list 'pager'

В предыдущем примере команда D:\packt\logstash-6.0.0\bin> будет ссылаться на каталог LOGSTASH_HOME\bin на вашем устройстве.
Установка или обновление плагинов
Если вы не нашли необходимый плагин в конфигурации по умолчанию, можете установить его с помощью команды bin\logstashplugin install. Например, для установки плагина logstash-output-email выполните следующую команду:
D:\packt\logstash-6.0.0\bin>logstash-plugin install logstash-output-email
Используя команду bin\logstash-plugin update с названием плагина в качестве параметра, вы можете получить самую свежую версию плагина:
D:\packt\logstash-6.0.0\bin>logstash-plugin update logstash-output-s3

Если выполнить команду bin\logstash-plugin update без указания названия плагина, произойдет обновление всех плагинов.
Плагины ввода
Плагин ввода предназначен для настройки набора событий, которые передаются в Logstash. Этот плагин позволяет настроить один или несколько источников ввода. Он работает на месте первой секции, как это требуется в конфигурационном файле Logstash. В табл. 5.1 приведен список всех доступных при установке плагинов ввода.
Таблица 5.1
| logstash-input-beats | logstash-input-couchdb_changes | logstash-input-elasticsearch | logstash-input-ganglia |
| logstash-input-xmpp | logstash-input-unix | logstash-input-syslog | logstash-input-stdin |
| logstash-input-udp | logstash-input-twitter | logstash-input-tcp | logstash-input-sqs |
| logstash-input-snmptrap | logstash-input-redis | logstash-input-pipe | logstash-input-log4j |
| logstash-input-s3 | logstash-input-rabbitmq | logstash-input-lumberjack | logstash-input-http_poller |
| logstash-input-exec | logstash-input-file | logstash-input-http | logstash-input-imap |
| logstash-input-gelf | logstash-input-jdbc | logstash-input-irc | logstash-input-generator |
| logstash-input-heartbeat | logstash-input-graphite |
|
|
Более детальную информацию обо всех этих плагинах, а также о других доступных плагинах, которые не входят в стандартный дистрибутив, вы можете найти по следующей ссылке: https://www.elastic.co/guide/en/logstash/6.0/input-plugins.html.
Плагины вывода
Плагин вывода используется для отправки данных в требуемое место назначения. С его помощью можно настроить один или несколько источников вывода. Он работает на месте последней секции, как это предусмотрено в конфигурационном файле Logstash. В табл. 5.2 приведен список всех доступных при установке плагинов вывода.
Таблица 5.2
| logstash-output-cloudwatch | logstash-output-nagios | logstash-output-irc | logstash-output-pagerduty |
| logstash-output-xmpp | logstash-output-tcp | logstash-output-stdout | logstash-output-redis |
| logstash-output-webhdfs | logstash-output-statsd | logstash-output-sns | logstash-output-rabbitmq |
| logstash-output-udp | logstash-output-sqs | logstash-output-s3 | logstash-output-pipe |
| logstash-output-csv | logstash-output-graphite | logstash-output-file | logstash-output-elasticsearch |
| logstash-output-http |
|
|
|
Более детальную информацию обо всех этих плагинах, а также о других доступных плагинах, которые не входят в стандартный дистрибутив, вы можете найти по следующей ссылке: https://www.elastic.co/guide/en/logstash/6.0/output-plugins.html.
Плагины фильтров
Плагин фильтра используется для обработки и трансформации данных. Вы можете комбинировать один или несколько плагинов. Порядок размещения плагинов определяет порядок, в котором будут обрабатываться данные. Это промежуточная секция между вводом и выводом, она не является обязательной в конфигурации Logstash. В табл. 5.3 приведен список всех доступных при установке плагинов фильтрации.
Таблица 5.3
| logstash-filter-cidr | logstash-filter-clone | logstash-filter-grok | logstash-filter-geoip |
| logstash-filter-date | logstash-filter-csv | logstash-filter-throttle | logstash-filter-xml |
| logstash-filter-fingerprint | logstash-filter-dns | logstash-filter-drop | logstash-filter-dissect |
| logstash-filter-syslog_pri | logstash-filter-useragent | logstash-filter-split | logstash-filter-translate |
| logstash-filter-uuid | logstash-filter-urldecode | logstash-filter-sleep | logstash-filter-ruby |
| logstash-filter-mutate | logstash-filter-metrics | logstash-filter-kv | logstash-filter-json |
Более детальную информацию обо всех этих плагинах, а также о других доступных плагинах, которые не входят в стандартный дистрибутив, вы можете найти по следующей ссылке: https://www.elastic.co/guide/en/logstash/6.0/filter-plugins.html.
Плагины кодеков
Плагины кодеков используются для кодирования или декодирования входящих или исходящих событий в Logstash. Их также можно применять во вводе или выводе. Кодеки ввода предоставляют удобное декодирование ваших данных еще до того, как они попадают на стадию ввода. Кодеки вывода обрабатывают данные прежде, чем они будут отправлены на стадию вывода. В табл. 5.4 приведен список всех доступных при установке плагинов кодеков.
Таблица 5.4
| logstash-codec-netflow | logstash-codec-cef | logstash-codec-es_bulk | logstash-codec-dots |
| logstash-codec-collectd | logstash-codec-multiline | logstash-codec-msgpack | logstash-codec-line |
| logstash-codec-rubydebug | logstash-codec-json | logstash-codec-json_lines | logstash-codec-fluent |
| logstash-codec-plain | logstash-codec-graphite | logstash-codec-edn_lines | logstash-codec-edn |
Более детальную информацию обо всех этих плагинах, а также о других доступных плагинах, которые не входят в стандартный дистрибутив, вы можете найти по следующей ссылке: https://www.elastic.co/guide/en/logstash/6.0/codec-plugins.html.
Обзор плагинов
В следующих разделах мы подробно разберем несколько наиболее распространенных плагинов ввода, вывода, фильтрации и кодеков.
Обзор плагинов ввода
Рассмотрим несколько часто используемых плагинов ввода.
File
Плагин File используется для трансляции событий из файлов строка за строкой. Он работает по принципу Linux/Unix-команд. Плагин отслеживает любые изменения в каждом файле и отправляет данные, начиная с того места, где файл был в последний раз прочитан. Он автоматически распознает сдвиг файлов. Доступна также опция чтения файла с самого начала.
Плагин File запоминает текущую позицию в каждом файле. Это происходит путем записи текущей позиции в отдельном файле с названием sincedb. Довольно удобно в том случае, если Logstash был перезапущен, продолжить работу с того места, на котором чтение файла было прекращено, при этом не упуская строки, добавленные в файл за то время, пока Logstash не работал.
Файл sincedb по умолчанию размещен в каталоге <path.data>/plugins/inputs/file, однако вы можете заменить этот путь любым другим, внеся изменения в параметр sincedb_path. Единственный обязательный параметр для этого плагина — path, указывающий на один или несколько файлов, из которых считываются данные.
Рассмотрим работу этого плагина на примере:
#sample configuration 1
#simple1.conf
input
{ file{
path => "/usr/local/logfiles/*"
}
}
output
{
stdout {
codec => rubydebug
}
}
Предыдущая конфигурация дает указание транслировать все новые записи в файлы, находящиеся по адресу /usr/local/logfiles/:
#sample configuration 2
#simple2.conf
input
{
file{
path => ["D:\es\app\*","D:\es\logs\*.txt"]
start_position => "beginning"
exclude => ["*.csv]
discover_interval => "10s"
type => "applogs"
}
}
output
{
stdout {
codec => rubydebug
}
}
Эта конфигурация дает указание транслировать (streaming) все записи/строки логов в файлы, находящиеся по адресу D:\es\app\*, а также только файлы типа .txt. Сюда же входят файлы, найденные по адресу D:\es\logs\*.txt. Записи считываются начиная с начала файла (указано параметром start_position => "beginning"), и в процессе поиска исключаются файлы типа .csv (указано параметром exclude => ["*.csv], который получает массив значений). Каждая транслируемая строка будет сохранена в поле сообщений по умолчанию. Предыдущая конфигурация также дает указание добавлять один дополнительный тип поля со значением applogs (задано параметром type => "applogs"). Добавление дополнительного поля полезно при преобразовании событий в плагинах фильтрации или при идентификации событий для вывода. Параметр discover_interval используется для определения того, как часто будет расширяться путь для поиска новых файлов, созданных в каталоге, указанном под параметром path.

Если указать параметры start_position => "beginning" и sincedb_path => "NULL", трансляция записей будет принудительно стартовать с начала файла при каждом перезапуске Logstash.
Beats
Плагин ввода Beats позволяет получать события из фреймворка Elatic Beats. Это коллекция легковесных демонов, используемых для сбора операционных данных с ваших серверов и доставки их в настраиваемые файлы вывода Logstash, Elasticsearch, Redis и др. Сюда входят такие компоненты, как Metricbeat, Filebeat, Winlogbeat и др. Filebeat отправляет данные логов с ваших серверов. Metricbeat является агентом мониторинга серверов, он периодически собирает метрики по сервисам и операционным системам, запущенным на ваших серверах. Winlogbeat отправляет логи событий Windows. Более детально о фреймворке Beats и его компонентах мы поговорим в следующих главах.
Используя плагин ввода Beats, мы можем сделать так, чтобы Logstash прослушивал выбранные порты на предмет входящих соединений:
#beats.conf
input {
beats {
port => 1234
}
}
output {
elasticsearch {
}
}
Единственным обязательным параметром для этого плагина является port. В приведенной конфигурации Logstash прослушивает входящие подключения beats и индексирует их в Elasticsearch. При запуске такой конфигурации вы можете заметить, что Logstash разворачивает входящий прослушиватель на порте 1234 в логах, как показано ниже:
D:\packt\logstash-6.0.0\bin>logstash -f ../conf/beats.conf -r
Sending Logstash's logs to D:/packt/logstash-6.0.0/logs which is now configured via log4j2.properties
[2017-11-06T15:16:46,534][INFO ][logstash.modules.scaffold] Initializing module {:module_name=>"fb_apache",
:directory=>"D:/packt/logstash-6.0.0/modules/fb_apache/configuration"}
[2017-11-06T15:16:46,539][INFO ][logstash.modules.scaffold] Initializing module {:module_name=>"netflow",
:directory=>"D:/packt/logstash-6.0.0/modules/netflow/configuration"}
[2017-11-06T15:16:47,905][INFO ][logstash.pipeline ] Starting pipeline
{"id"=>"main", "pipeline.workers"=>4, "pipeline.batch.size"=>125,
"pipeline.batch.delay"=>5, "pipeline.max_inflight"=>500
[2017-11-06T15:16:48,491][INFO ][logstash.inputs.beats ] Beats inputs:
Starting input listener {:address=>"0.0.0.0:1234"}
[2017-11-06T15:16:48,554][INFO ][logstash.pipeline ] Pipeline main started
[2017-11-06T15:16:48,563][INFO ][org.logstash.beats.Server] Starting server on port: 1234
[2017-11-06T15:16:48,800][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
Logstash запускает входящий прослушиватель по адресу 0.0.0.0, что является значением по умолчанию для параметра host этого плагина.
Вы можете запустить несколько прослушивателей, как видно ниже:
#beats.conf
input {
beats {
host => "192.168.10.229"
port => 1234
}
beats {
host => "192.168.10.229"
port => 5065
}
}
output {
elasticsearch {
}
}

Использование флага -r во время работы Logstash позволяет вам автоматически запускать конфигурацию, если она была изменена и сохранена. Это может быть полезно во время тестирования новых конфигураций без необходимости вручную перезапускать Logstash каждый раз, когда конфигурация изменилась.
JDBC
Этот плагин предназначен для импорта данных из базы данных в Logstash. Каждая строка в результатах станет событием, а каждый столбец — полем внутри события. Используя этот плагин, можно импортировать все данные за один раз путем выполнения запроса или же настроить расписание для импорта с помощью синтаксиса cron (в параметре schedule). При задействовании этого плагина пользователю необходимо указать путь к драйверам JDBC, которые подходят для выбранной базы данных. Библиотека драйверов определяется с помощью параметра jdbc_driver_library.
Запрос SQL может быть указан с помощью параметра statement или сохранен в файл; путь к файлу задается в параметре statement_filepath. Для указания запроса можно использовать statement или statement_filepath. Хорошей практикой является сохранение больших запросов в файл. Этот плагин принимает только один запрос SQL, множественные запросы не поддерживаются. Если пользователю нужно выполнить несколько запросов для сбора данных из нескольких таблиц/видов, то необходимо указать несколько вводов JDBC (по одному на каждый запрос) в секции ввода конфигурации Logstash.
Размер результирующего набора указывается в параметре jdbc_fetch_size. Плагин будет «настаивать» на параметре sql_last_value для указания файла метаданных, который сохраняется в папке, заданной параметром last_run_metadata_path. После выполнения запроса этот файл будет обновлен с текущим значением sql_last_value. Это значение используется для пошагового импорта данных из базы данных каждый раз, когда выполняется запрос, основанный на расписании schedule. Параметры запроса SQL могут быть указаны в настройке parameters, которая принимает хеш параметра запроса.
Взглянем на пример:
#jdbc.conf
input {
jdbc {
# path of the jdbc driver
jdbc_driver_library => "/path/to/mysql-connector-java-5.1.36-bin.jar"
# The name of the driver class
jdbc_driver_class => "com.mysql.jdbc.Driver"
# Mysql jdbc connection string to company database
jdbc_connection_string => "jdbc:mysql://localhost:3306/company"
# user credentials to connect to the DB
jdbc_user => "user"
jdbc_password => "password"
# when to periodically run statement, cron format (ex: every 30 minutes)
schedule => "30 * * * *"
# query parameters
parameters => { "department" => "IT" }
# sql statement
statement => "SELECT * FROM employees WHERE department= :department AND
created_at >= :sql_last_value"
}
}
output {
elasticsearch {
index => "company"
document_type => "employee"
hosts => "localhost:9200"
}
}
Приведенная конфигурация используется для подключения к схеме компании на базе модуля MySQLdb и предназначена для сбора записей работников из IT-отдела. Запрос SQL выполняется каждые 30 мин и проверяет, появились ли новые работники с момента последнего его запуска. Полученные строки отправляются в Elasticsearch и настраиваются как вывод.

По умолчанию до выполнения запроса параметр sql_last_value настраивается на четверг, 1 января 1970 года, и обновляется с меткой времени каждый раз, когда выполняется запрос. Вы можете принудительно задавать значение столбца, отличное от времени последнего выполнения. Для этого необходимо присвоить параметру use_column_value значение true и указать название столбца, который будет использоваться параметром tracking_column.
IMAP
Данный плагин используется для чтения сообщений электронной почты с серверов IMAP. Он предназначен для получения писем, которые в зависимости от контекста сообщения или определенных отправителей могут условно обрабатываться Logstash и далее использоваться для поднятия тикетов JIRA, событий PagerDuty и т.д. Обязательные поля в конфигурации: host, password и user. В зависимости от требований сервера IMAP, к которому вы подключаетесь, возможно, понадобится указать значения дополнительных настроек, таких как port, secure и др. В параметре hst вы указываете детали хоста IMAP, а user и password, соответственно, хранят пользовательские данные авторизации:
#email_log.conf
input {
imap {
host => "imap.packt.com"
password => "secertpassword"
user => "[email protected]"
port => 993
check_interval => 10
folder => "Inbox"
}
}
output {
stdout {
codec => rubydebug
}
elasticsearch {
index => "emails"
document_type => "email"
hosts => "localhost:9200"
}
}
По умолчанию плагин logstash-input-imap считывает сообщения из папки INBOX и опрашивает сервер IMAP каждые 300 секунд. В приведенной выше конфигурации при указании параметра check_interval задается пользовательский интервал каждые 10 с. Каждое новое сообщение электронной почты воспринимается как событие и согласно конфигурации выше будет отправляться в стандартный вывод и в Elasticsearch.
Плагины вывода
В следующих подразделах мы подробно рассмотрим несколько наиболее распространенных плагинов вывода.
Elasticsearch
Этот плагин используется для передачи событий из Logstash в Elasticsearch. Это не единственный способ такой передачи, но самый предпочтительный. Как только данные поступят в Elasticsearch, их можно далее использовать для визуализации в Kibana. Плагин не имеет обязательных параметров, подключение к Elasticsearch происходит автоматически, применяется порт localhost:9200.
Простая конфигурация этого плагина выглядит следующим образом:
#elasticsearch1.conf
input {
stdin{
}
}
output {
elasticsearch {
}
}
Нередко Elasticsearch размещается на других серверах, обычно безопасных, и может потребоваться хранить входящие данные в определенных индексах. Рассмотрим такой пример:
#elasticsearch2.conf
input {
stdin{
}
}
output {
elasticsearch {
index => "company"
document_type => "employee"
hosts => "198.162.43.30:9200"
user => "elastic"
password => "elasticpassword"
}
}
Как видно в этом коде, входящие события будут сохраняться в индексе Elasticsearch с названием компании (задано с помощью параметра index) под типом employee (указано с помощью параметра document_type). Elasticsearch размещен по адресу 198.162.43.30:9200 (задано с помощью параметра document_type) и использует данные авторизации elastic и elasticpassword (указаны в параметрах user и password).
Если индекс по умолчанию не указан, то шаблон индекса будет logstash-%(+YYYY.MM.dd), а document_type будет задан как тип события, даже если он уже существует, в ином случае тип документа будет назначен значением логов/событий.
Возможно также указать индекс document_type и document_id динамически, используя syntax %(fieldname). В параметре hosts может быть указан список хостов. Протоколом по умолчанию будет HTTP, если иное четко не определено при настройке хостов.

Рекомендуется указывать узлы данных или узлы поглощения в поле hosts.
CSV
Этот плагин используется для хранения вывода в формате CSV. Обязательными его параметрами являются path (для указания папки сохранения файла вывода) и fields (задает названия полей из событий, которые должны быть записаны в файл CSV). Если поле в событии не существует, будет записана пустая строка.
Рассмотрим пример. В следующей конфигурации Elasticsearch запрашивает по индексу "apachelogs" все документы, соответствующие statuscode:200. Поля "message", "@timestamp" и "host" записываются в файл .csv:
#csv.conf
input {
elasticsearch {
hosts => "localhost:9200"
index => "apachelogs"
query => '{ "query": { "match": { "statuscode": 200 } }}'
}
}
output {
csv {
fields => ["message", "@timestamp","host"]
path => "D:\es\logs\export.csv"
}
}
Kafka
Этот плагин предназначен для записи событий в топик Kafka. Он использует API Kafka Producer для записи сообщений в топик в брокере. Единственная необходимая настройка — это topic_id.
Рассмотрим конфигурацию Kafka:
#kafka.conf
input {
stdin{
}
}
output {
kafka {
bootstrap_servers => "localhost:9092"
topic_id => 'logstash'
}
}
Параметр bootstrap_servers собирает список всех серверных подключений в виде host1:port1, host2:port2. Эта информация будет использоваться только для получения метаданных (топиков, разделов и копий). Сокет-соединения для отправки фактических данных будут установлены на основе информации брокера, которая возвращается в метаданных. topic_id обозначает название темы, в которой будут опубликованы сообщения.

Обратите внимание: только Kafka версии 0.10.0.х совместима с Logstash версий от 2.4.х до 5.х.х и плагином вывода Kafka версии 5.х.х.
PagerDuty
Этот плагин вывода будет отправлять уведомления, базируясь на предварительно настроенных службах и политиках эскалации оповещения. Единственным обязательным параметром для этого плагина является service_key для указания ключа Service API.
Рассмотрим простой пример с базовой конфигурацией PagerDuty. Она настроена таким образом, чтобы Elasticsearch запрашивала в индексе "ngnixlogs" все документы, соответствующие statuscode:404, и для каждого найденного документа поднимались события pagerduty:
#kafka.conf
input {
elasticsearch {
hosts => "localhost:9200"
index => "ngnixlogs"
query => '{ "query": { "match": { "statuscode": 404} }}'
}
}
output {
pagerduty {
service_key => "service_api_key"
details => {
"timestamp" => "%{[@timestamp]}"
"message" => "Problem found: %{[message]}"
}
event_type => "trigger"
}
}
Плагины кодеков
В следующих разделах мы рассмотрим несколько наиболее распространенных плагинов кодеков.
JSON
Этот кодек полезен в тех случаях, если данные состоят из документов .json. Он предназначен для кодирования (если используется в плагинах вывода) или декодирования (в случаях с плагинами ввода) данных в формате .json. Если направляемые данные представляют собой массив JSON, будут создаваться множественные события (по одному на каждый элемент).
Пример простого применения плагина JSON выглядит следующим образом:
input{
stdin{
codec => "json"
}
}

Если у вас несколько записей JSON, разделенных \n, необходимо использовать кодек json_lines.
Если кодек JSON получает данные из ввода, состоящего из некорректных документов JSON, они будут обработаны как простой текст с добавлением тега _jsonparsefailure.
Rubydebug
Этот кодек может выводить ваши события Logstash с применением библиотеки Ruby Awesome Print.
Пример простого применения этого плагина кодека выглядит следующим образом:
output{
stdout{
codec => "rubydebug"
}
}
Multiline
Этот кодек полезен для слияния нескольких строк данных с единичным событием. Он подойдет и в тех случаях, когда необходимо отследить стек единичного события и информацию, которая разбита по нескольким строкам.
Ниже вы видите образец применения этого кодека:
input {
file {
path => "/var/log/access.log"
codec => multiline {
pattern => "^\s "
negate => false
what => "previous"
}
}
}
Кодек Multiline соединяет любую строку, начинающуюся с пробела, с предыдущей строкой.
Плагины фильтрации
Поскольку в следующей главе мы будем детально рассматривать различные способы изменения и дополнения данных логов с помощью разных плагинов фильтрации, сейчас мы пропустим связанную с этим информацию.
Узел поглощения данных
До версии Elasticsearch 5.0, если нам требовалась предварительная обработка документов до индексирования, единственным возможным способом сделать это было использовать Logstash или преобразовывать их вручную, а потом индексировать в Elasticsearch. Не хватало функционала для возможности предварительной обработки/трансформации документов, они индексировались в исходном виде. Однако в версии Elasticsearch 5.х и далее была представлена функция узла поглощения данных, которая является легковесным решением для предварительной обработки и дополнения документов в Elasticsearch до индексирования.
Если Elasticsearch запущена в конфигурации по умолчанию, она будет работать как главный узел, узел данных и узел поглощения. Для отключения функции поглощения измените следующую настройку в файле elasticsearch.yml:
node.ingest: false
Узел поглощения может быть использован для предварительной обработки документов до момента фактического индексирования. Эта обработка происходит путем перехвата составных и индексирующих запросов, применения трансформаций данных и отправки документов обратно к API. С появлением новой функции поглощения Elasticsearch переняла часть функционала Logstash, ответственную за фильтрацию, и теперь мы можем выполнять обработку сырых логов и дополнять их внутри Elasticsearch.
Для предварительной обработки логов перед индексированием необходимо указать контейнер (который выполняет последовательность действий по трансформации входящего документа). Для этого мы попросту указываем параметр pipeline в индексе или в составном запросе, чтобы узел поглощения знал, какой контейнер использовать:
POST my_index/my_type?pipeline=my_pipeline_id
{
"key": "value"
}
Определение контейнера
Контейнер определяет серию процессоров. Каждый процессор трансформирует документ в том или ином виде. Каждый процессор запускается в том порядке, в котором он определен в контейнере. Контейнер хранит два основных поля: описание и список процессоров. Параметр description — необязательное поле, которое предназначено для хранения информации, связанной с использованием контейнера; с помощью параметра processors можно указать список процессоров для трансформации документа.
Типичная структура контейнера выглядит следующим образом:
{
"description" : "...",
"processors" : [ ... ]
}
Узел поглощения имеет около 20 встроенных процессоров, включая gsub, grok, convert, remove, rename и пр. для использования в создании контейнеров. Вместе со встроенными процессорами вы также можете применять доступные плагины поглощения, такие как ingest attachment, ingest geo-ip, ingest user-agent. По умолчанию они недоступны, но можно установить их как любой другой плагин Elasticsearch.
Ingest API
Узел поглощения предоставляет набор API, известный как Ingest API. Вы можете использовать эти API для определения, симуляции, удаления или поиска информации о контейнерах. Конечная точка данного API — _ingest.
API определения контейнера
Этот API используется для определения и добавления нового контейнера, а также для обновления имеющихся контейнеров.
Рассмотрим пример. Как видно в следующем коде, мы определили новый контейнер с названием firstpipeline, который переводит значения поля message в верхний регистр:
curl -X PUT http://localhost:9200/_ingest/pipeline/firstpipeline -H
'content-type: application/json'
-d '{
"description" : "uppercase the incoming value in the message field",
"processors" : [
{
"uppercase" : {
"field": "message"
}
}
]
}'
При создании контейнера вы можете указать несколько процессоров, а порядок их выполнения зависит от порядка, в котором они указаны в конфигурации. Рассмотрим это на примере. Как видно в следующем коде, мы создали новый контейнер с именем secondpipeline, который преобразует значения поля "message" в верхний регистр и переименовывает поле "message" в "data". Он создает новое поле с названием "label" и значением testlabel:
curl -X PUT http://localhost:9200/_ingest/pipeline/secondpipeline -H
'content-type: application/json'
-d '{
"description" : "uppercase the incomming value in the message field",
"processors" : [
{
"uppercase" : {
"field": "message",
"ignore_failure" : true
}
},
{
"rename": {
"field": "message",
"target_field": "data",
"ignore_failure" : true
}
},
{
"set": {
"field": "label",
"value": "testlabel",
"override": false
}
}
]
}'
Используем второй контейнер для индексирования документа-образца:
curl -X PUT 'http://localhost:9200/myindex/mytpe/1?pipeline=secondpipeline'
H 'content-type: application/json' -d '{
"message":"elk is awesome"
}'
А теперь мы получим тот же документ и утвердим трансформацию:
curl -X GET http://localhost:9200/myindex/mytpe/1 -H
'content-type: application/json'
Ответ:
{
"_index": "myindex",
"_type": "mytpe",
"_id": "1",
"_version": 1,
"found": true,
"_source": {
"label": "testlabel",
"data": "ELK IS AWESOME"
}
}

Если отсутствует поле, используемое процессором, тогда процессор сгенерирует исключение и документ не будет проиндексирован. Для предотвращения исключений процессора мы можем присвоить параметру "ignore_failure" значение true.
API получения контейнера
Этот API используется для получения определения существующего контейнера. С его помощью можно найти детали определения одного контейнера или всех.
Команда для поиска определений всех контейнеров выглядит следующим образом:
curl -X GET http://localhost:9200/_ingest/pipeline -H
'content-type: application/json'
Для поиска определения существующего контейнера введите его идентификатор для получения .api контейнеров. В примере ниже вы можете увидеть поиск определения контейнера с названием secondpipeline:
curl -X GET http://localhost:9200/_ingest/pipeline/secondpipeline -H
'content-type: application/json'
API удаления контейнера
Данный API удаляет контейнеры согласно идентификатору или совпадению с универсальным символом. Далее вы увидите пример удаления контейнера с названием firstpipeline:
curl -X DELETE http://localhost:9200/_ingest/pipeline/firstpipeline -H
'content-type: application/json'
API симуляции контейнера
Используется для симуляции выполнения контейнера относительно набора документов, выбранных в теле запроса. Можно указать как существующий контейнер, так и определение необходимого контейнера. Для симуляции контейнера поглощения добавьте конечную точку "_simulate" к API контейнера.
Ниже приведен пример симуляции существующего контейнера:
curl -X POST
http://localhost:9200/_ingest/pipeline/firstpipeline/_simulate -H
'contenttype: application/json' -d '{
"docs" : [
{ "_source": {"message":"first document"} },
{ "_source": {"message":"second document"} }
]
}'
Далее вы увидите пример симулированного запроса с определением контейнера в теле запроса:
curl -X POST http://localhost:9200/_ingest/pipeline/_simulate –H
'contenttype: application/json' -d '{
"pipeline" : {
"processors":[
{
"join": {
"field": "message",
"separator": "-"
}
}]
},
"docs" : [
{ "_source": {"message":["first","document"]} }
]
}'
Резюме
В этой главе мы поговорили об основах Logstash. Мы установли и настроили Logstash, чтобы можно было начать работу с контейнерами данных, а также разобрались в архитектуре Logstash.
Вы узнали об узле поглощения (ingest node), который впервые появился в версии Elastic 5.x и который сегодня можно использовать вместо выделенной установки Logstash. Вы научились применять узел поглощения для предварительной обработки документов до момента фактического индексирования, а также познакомились с различными API.
В следующей главе мы поговорим о разнообразных фильтрах в арсенале Logstash, которые ставят его в один ряд с другими фреймворками потоковой обработки в реальном и псевдореальном времени с нулевым кодированием.

