4. Анализ данных с помощью Elasticsearch
На текущем этапе изучения Elastic Stack 6.0 вы уже должны были хорошо разобраться в работе Elasticsearch. В предыдущих двух главах мы рассмотрели фундаментальные основы этой программы, а также реальные примеры ее практического применения.
Технология в основе Elasticsearch — Apache Lucene — изначально создавалась для текстового поиска. Благодаря инновациям в разработке этих двух программ они зарекомендовали себя как мощный поисковый движок. В этой главе мы поговорим о том, что именно делает Elasticsearch хорошей поисковой системой. Мы рассмотрим следующие темы.
• Основы агрегации.
• Подготовка данных к анализу.
• Метрическая агрегация.
• Сегментарная агрегация.
• Агрегация контейнеров.
Все это мы изучим на реальном наборе данных. Начнем с основ агрегации.
Основы агрегации
В отличие от поиска аналитика предназначена для получения куда более полной картины. При поиске мы детально рассматриваем несколько записей; аналитика же позволяет взглянуть на данные шире и разбить их различными способами. Когда мы изучали поиск, мы использовали API следующего вида:
POST /<index_name>/<type_name>/_search
{
"query":
{
... тип запроса ...
}
}
Все запросы агрегации имеют схожий вид. Разберемся в структуре.
Агрегация, или элемент aggs, позволяет нам агрегировать данные. Все такие запросы имеют следующий вид:
POST /<index_name>/<type_name>/_search
{
"aggs": {
... тип агрегации ...
},
"query": { ... тип запроса ... }, // необязательная часть запроса
"size": 0 // обычно указывается размер 0
}
Элемент aggs должен содержать фактический запрос агрегации. Тело запроса зависит от желаемого типа агрегации. Необязательный элемент query указывает контекст агрегации. Агрегация будет учитывать все документы данного индекса и типа, если не указан элемент query (мы можем считать его равным запросу match_all, если нет иного запроса). Если мы хотим ограничить контекст агрегации, необходимо указать элемент query. Например, мы хотим, чтобы агрегация работала не по всем данным, а только по определенным документам, которые соответствуют конкретным условиям. Этот запрос фильтрует документы, которые будут обработаны запросом aggs.
Элемент size указывает, сколько соответствий поиска должно быть возвращено в ответе. Значение по умолчанию составляет 10. Если значение size не указано, ответ будет содержать десять соответствий из контекста запроса. Обычно, если мы заинтересованы только в получении результатов агрегации, необходимо присваивать элементу size значение 0, чтобы не получить иные результаты.
В широком понимании Elasticsearch поддерживает четыре типа агрегаций:
• сегментарные агрегации;
• метрические агрегации;
• матричные агрегации;
• агрегации контейнеров.
Сегментарные агрегации
Сегментарные агрегации разделяют данные запроса (обозначенные контекстом query) на различные сегменты, идентифицируемые сегментарным ключом. Такой тип агрегации оценивает документ в контексте путем вычисления, в какой именно сегмент он попадает. В результате мы получаем набор определенных сегментов со своими ключами и документами.
Люди, работающие с SQL, для этого используют запрос с оператором GROUP BY, например:
SELECT column1, count(*) FROM table1 GROUP BY column1;
Данный запрос разделяет таблицу по разным значениям в столбце 1 и возвращает количество документов в пределах каждого значения столбца 1. Это пример сегментарной агрегации. Elasticsearch поддерживает много разных типов сегментарной агрегации, мы еще рассмотрим их в этой главе.
Сегментарные агрегации могут быть указаны в самом верху или на внешнем уровне запроса агрегации. Их также можно добавлять в другие агрегации такого типа.
Метрические агрегации
Метрические агрегации работают с полями числовых типов. Они вычисляют ценность числового поля в конкретном контексте. Например, у нас есть таблица с результатами студенческих экзаменов. Каждая запись хранит отметки, полученные студентами. Метрическая агрегация позволяет вычислить разные сводные показатели этого столбца с отметками, например сумму, среднее, минимальное, максимальное значение и т.д.
В терминах SQL следующий запрос будет грубой аналогией того, что может сделать метрическая агрегация:
SELECT avg(score) FROM results;
Этот запрос считает среднюю отметку в данном контексте. В этом случае контекстом является вся таблица, то есть все студенты. Это пример метрической агрегации.
Метрические агрегации можно размещать в самом верху или на внешнем уровне запросов агрегаций. Их также можно добавлять в другие агрегации сегментарного типа. Но в метрические агрегации нельзя вставлять агрегации других типов.
Матричные агрегации
Матричные агрегации впервые были представлены в версии Elasticsearch 5.0. Они работают с несколькими полями и вычисляют матрицы по всем документам в пределах контекста запроса.
Матричные агрегации могут быть вставлены в сегментарные, но обратная вставка невозможна. Это все еще относительно новая функция. Детальное изучение матричных агрегаций не входит в задачи этой книги.
Агрегации контейнеров
Агрегации контейнеров являются агрегациями высшего порядка и могут использовать вывод других агрегаций. Это может быть полезным для вычисления чего-либо, например производных. Более подробно агрегации контейнеров мы рассмотрим далее в этой главе.
Итак, это был краткий обзор различных типов агрегаций, поддерживаемых в Elasticsearch. Агрегации контейнеров и агрегации матричного типа являются относительно новыми и применяются не так широко, как метрические или сегментарные. Оба этих типа мы рассмотрим более детально далее в этой главе.
В следующем разделе мы загрузим и подготовим данные, чтобы лучше разобраться в работе агрегаций, рассматриваемых в этой главе.
Подготовка данных к анализу
В качестве примера мы используем данные сетевого трафика, собранные с Wi-Fi-роутеров. На протяжении всей главы мы будем анализировать данные из этого примера. Важно понять, как выглядят записи рассматриваемой системы и что они обозначают. Мы рассмотрим следующие темы:
• структуру данных;
• загрузку данных с помощью Logtash.
Кроме того, подготовим и загрузим данные в локальный процесс Elasticsearch.
Структура данных. На рис. 4.1 показано устройство системы сбора данных с роутеров. Данные о сетевом трафике и использовании пропускной способности сети собираются, после чего поступают на хранение в Elasticsearch.
Эти данные собраны системой для следующих целей.
• В левой части рисунка вы видите несколько квадратов, которые обозначают клиентское оборудование: маршрутизаторы Wi-Fi, развернутые на месте, а также все устройства, подключенные к этим беспроводным маршрутизаторам. Среди подключенных устройств есть ноутбуки, мобильные устройства, настольные компьютеры и др. Каждое устройство имеет присвоенный ему уникальный идентификатор — MAC-адрес.
• В правой части рисунка вы видите централизованную систему для сбора и хранения данных от нескольких клиентов по кластерам Elasticsearch. Мы сфокусируемся на том, как правильно реализовать такой централизованный кластер и индекс, что позволит лучше понять их работу.
• Маршрутизаторы на каждой клиентской площадке собирают дополнительные показатели для каждого подключенного устройства: объем скачанных и переданных данных, а также ссылки URL или доменные имена, посещаемые клиентом в определенный интервал времени. Маршрутизаторы Wi-Fi собирают такие сведения и периодически отправляют их для длительного хранения и анализа на централизованный API-сервер.
• В момент передачи маршрутизаторами Wi-Fi эти данные состоят из нескольких полей: обычно это сведения о роутере и MAC-адреса конечных устройств, для которых собраны метрики. Сервер API рассматривает записи и добавляет в них больше полезной для аналитики информации и уже потом сохраняет в Elasticsearch. Например, поиск по MAC-адресу выполняется для того, чтобы найти ассоциированного пользователя, которому это устройство назначено в системе.
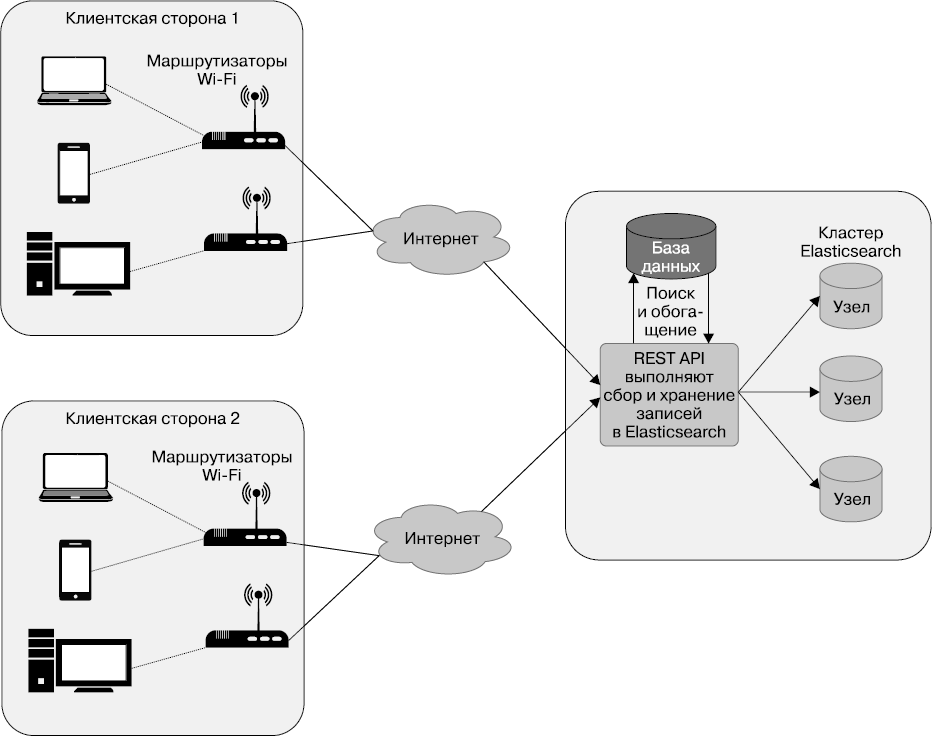
Рис. 4.1

Что такое метрика (показатель) и измерения? «Метрика» (metric) — это универсальный термин, который в мире аналитики используется для обозначения цифрового измерения. Простой пример метрики — объем трафика за определенный интервал времени. Термин «измерение» (dimension) обычно употребляется для определения дополнительной/внешней информации, зачастую — данных строкового типа. В текущем примере по MAC-адресу мы ищем дополнительную, связанную с ним информацию, а именно имя пользователя, к которому устройство приписано в системе, а также название отдела, к которому принадлежит пользователь. Эти сведения и являются измерениями.
В результате подробные записи хранятся в Elasticsearch в виде структуры данных. Одна запись выглядит следующим образом:
"_source": {
"customer": "Google" // Клиент, которому принадлежит роутер Wi-Fi
"accessPointId": "AP-59484", // Идентификатор маршрутизатора
// или точки доступа Wi-Fi
"time": 1506148631061, // Время записи в миллисекундах со времени
// эпохи 1 января 1970 года
"mac": "c6:ec:7d:c6:3d:8d", // MAC-адрес устройства клиента
"username": "Pedro Harrison", // Имя пользователя, которому назначено
// устройство
"department": "Operations", // Отдел пользователя,
// которому назначено устройство
"application": "CNBC", // Название приложения или домена
// для отчета трафика
"category": "News", // Категория приложения
"networkId": "Internal", // SSID-идентификатор сети
"band": "5 GHz", // Диапазон 5 ГГц или 2,4 ГГц
"location": "23.102789,72.595381", // Широта и долгота,
// разделенные запятой
"uploadTotal": 1340, // Байтов отправлено с момента последнего отчета
"downloadTotal": 2129, // Байтов принято с момента последнего отчета
"usage": 3469, // Общее количество байтов, отправленных
// и принятых в текущем периоде
"uploadCurrent": 22.33, // Скорость отправки в байтах/с в текущем периоде
"downloadCurrent": 35.48, // Скорость приема в байтах/с в текущем периоде
"bandwidth": 57.82, // Общая скорость в байтах/с
// (скорость отправки + скорость приема)
"signalStrength": -25, // Мощность сигнала между маршрутизатором Wi-Fi
// и устройством
...
}
Одна запись содержит различные метрики для выбранного устройства конечного пользователя и указанного промежутка времени.
Обратите внимание, что все данные в этом примере искусственно составленные. Несмотря на то что имена клиентов, пользователей и MAC-адресов выглядят реалистично, эти данные были созданы с использованием симулятора.
Теперь, когда вы знаете, что представляют собой приведенные данные и что значит каждая запись, приступим к загрузке данных в наш локальный экземпляр.
Загрузка данных с помощью Logtash
Для импортирования данных выполните шаги, перечисленные в сопроводительной информации к исходному коду этой книги (размещена в репозитории GitHub по следующей ссылке: https://github.com/pranav-shukla/learningelasticstack).
Скачайте репозиторий с GitHub. Инструкции по импорту данных вы найдете в следующем каталоге: chapter-04/README.md.
После того как вы импортировали данные, необходимо верифицировать их с помощью следующего запроса:
GET /bigginsight/usageReport/_search
{
"query": {
"match_all": {}
},
"size": 1
}
Вы должны увидеть ответ следующего вида:
{
...
"hits":
{
"total": 242835,
"max_score": 1,
"hits": [
{
"_index": "bigginsight",
"_type": "usageReport",
"_id": "AV7Sy4FofN33RKOLlVH0",
"_score": 1,
"_source": {
"inactiveMs": 1316,
"bandwidth": 51.03333333333333,
"signalStrength": -58,
"accessPointId": "AP-1D7F0",
"usage": 3062,
"downloadCurrent": 39.93333333333333,
"uploadCurrent": 11.1,
"mac": "d2:a1:74:28:c0:5a",
"tags": [],
"@timestamp": "2017-09-30T12:38:25.867Z",
"application": "Dropbox",
"downloadTotal": 2396,
"@version": "1",
"networkId": "Guest",
"location": "23.102900,72.595611",
"time": 1506164775655,
"band": "2.4 GHz",
"department": "HR",
"category": "File Sharing",
"uploadTotal": 666,
"username": "Cheryl Stokes",
"customer": "Microsoft"
}
}
]
}
}
Теперь, когда у вас есть необходимые данные, можете приступить к изучению различных типов агрегаций. Все запросы, использованные в этой главе, есть в материалах к этой книге, находятся в репозитории GitHub, в папке chapter-04/queries.txt. Эти запросы можно выполнить напрямую в Kibana Dev Tools, как вы уже видели ранее.
Метрические агрегации
Метрические агрегации работают с числовыми данными, вычисляя одну или несколько метрик в выбранном контексте. Контекст может быть запросом, фильтром или включать весь индекс/тип. Метрические агрегации можно вставлять в другие сегментарные агрегации. В таком случае выбранные метрики будут вычислены для каждого сегмента в пределах агрегации.
Мы начнем с простых метрических агрегаций без вложений. Когда далее в этой главе мы рассмотрим сегментарные агрегации, вы также узнаете, как вставлять в них метрические агрегации.
В текущем разделе мы изучим следующие типы метрических агрегаций:
• агрегации суммы, среднего, максимального и минимального значений;
• агрегации статистики, расширенной статистики;
• агрегация мощности.
Рассмотрим их по порядку.
Агрегации суммы, среднего, максимального и минимального значений
Поиск суммы поля, минимального или максимального значения или среднего числа являются довольно распространенными операциями. В SQL запрос для вычисления суммы выглядит следующим образом:
SELECT sum(downloadTotal) FROM usageReport;
Таким образом будет вычислена сумма поля downloadTotal по всем записям в таблице. Для этого необходимо пройтись по всем записям таблицы или по всем записям в выбранном контексте и добавить значения выбранных полей.
В Elasticsearch вы можете написать похожий запрос, используя агрегацию суммы.
Агрегация суммы
Вот как написать простую агрегацию суммы:
GET bigginsight/_search
{
"aggregations": { 1
"download_sum": { 2
"sum": { 3
"field": "downloadTotal" 4
}
}
},
"size": 0 5
}
1. Элементы aggs или aggregations на верхнем уровне должны служить оберткой агрегации.
2. Дайте агрегации имя. В данном случае мы выполняем агрегацию суммы в поле downloadTotal и выбрали соответствующее имя download_sum. Вы можете назвать ее как угодно. Это поле пригодится, когда нам понадобится найти эту конкретную агрегацию в результатах ответа.
3. Мы делаем агрегацию суммы, следовательно, применяется элемент sum.
4. Мы хотим сделать агрегацию терминов по полю downloadTotal.
5. Укажите size = 0, чтобы предотвратить попадание в ответ необработанных результатов. Нам нужны только итоги агрегации, а не результаты поиска. Поскольку мы не указали никаких высокоуровневых элементов query, запрос будет работать со всеми документами. Нам не нужны в ответе необработанные документы (или результаты поисковой выдачи).
Ответ должен выглядеть следующим образом:
{
"took": 92,
...
"hits": {
"total": 242836, 1
"max_score": 0,
"hits": []
},
"aggregations": { 2
"download_sum": { 3
"value": 2197438700 4
}
}
}
Разберемся в основных параметрах ответа.
1. Элемент hits.total показывает количество документов, соответствующих контексту запроса. Если не указан дополнительный запрос или фильтр, будут включены все документы в типе или индексе.
2. По аналогии с запросом этот ответ помещен внутрь агрегации для представления в таком виде.
3. Ответ запрошенной нами агрегации имеет название download_sum, следовательно, мы получаем наш ответ от агрегации суммы внутри элемента с таким же именем.
4. Фактическое значение выводится после применения агрегации суммы.
Агрегации среднего, максимального, минимального значений очень похожи. Кратко их рассмотрим.
Агрегация среднего значения
Агрегация среднего находит среднее значение по всем документам в контексте запроса:
GET bigginsight/_search
{
"aggregations": {
"download_average": { 1
"avg": { 2
"field": "downloadTotal"
}
}
},
"size": 0
}
Заметные отличия от агрегации суммы состоят в следующем.
1. Мы выбрали другое название, download_average, чтобы было ясно, что данная агрегация призвана вычислить среднее значение.
2. Тип выполняемой агрегации — avg вместо sum, как в предыдущем примере.
Структура ответа идентична ответу из предыдущего подраздела, но в поле значения мы увидим среднее значение запрошенных полей.
Агрегации минимального и максимального значений аналогичны.
Агрегация минимального значения
Найдем минимальное значение поля downloadTotal во всем индексе/типе:
GET bigginsight/_search
{
"aggregations": {
"download_min": {
"min": {
"field": "downloadTotal"
}
}
},
"size": 0
}
Агрегация максимального значения
Найдем максимальное значение поля downloadTotal во всем индексе/типе:
GET bigginsight/_search
{
"aggregations": {
"download_max": {
"max": {
"field": "downloadTotal"
}
}
},
"size": 0
}
Это очень простые агрегации. Теперь рассмотрим более усложненные агрегации статистики и расширенной статистики.
Агрегации статистики и расширенной статистики
Указанные агрегации вычисляют некоторые распространенные статистические значения в пределах одного запроса и без выполнения дополнительных запросов. Благодаря тому что статистические данные вычисляются в один заход, а не запрашиваются несколько раз, экономятся ресурсы Elasticsearch. Клиентский код также становится проще, если вы заинтересованы в нескольких видах таких данных. Взглянем на пример агрегации статистики.
Агрегация статистики
Агрегация статистики вычисляет сумму, среднее, максимальное, минимальное значение и общее количество документов в один заход:
GET bigginsight/_search
{
"aggregations": {
"download_stats": {
"stats": {
"field": "downloadTotal"
}
}
},
"size": 0
}
Запрос статистики по структуре аналогичен другим метрическим агрегациям, о которых вы уже знаете; ничего особенного здесь не происходит.
Ответ должен выглядеть следующим образом:
{
"took": 4,
...,
"hits": {
"total": 242836,
"max_score": 0,
"hits": []
},
"aggregations": {
"download_stats": {
"count": 242835,
"min": 0,
"max": 241213,
"avg": 9049.102065188297,
"sum": 2197438700
}
}
}
Как видите, ответ с элементом download_stats содержит общее количество, минимальное, максимальное, среднее значение и сумму. Такой вывод очень удобен, так как уменьшает количество запросов и упрощает клиентский код.
Взглянем на агрегацию расширенной статистики.
Агрегация расширенной статистики
Агрегация extended stats возвращает немного больше статистики в дополнение к предыдущему варианту:
GET bigginsight/_search
{
"aggregations": {
"download_estats": {
"extended_stats": {
"field": "downloadTotal"
}
}
},
"size": 0
}
Ответ будет выглядеть следующим образом:
{
"took": 15,
"timed_out": false,
...,
"hits": {
"total": 242836,
"max_score": 0,
"hits": []
},
"aggregations": {
"download_estats": {
"count": 242835,
"min": 0,
"max": 241213,
"avg": 9049.102065188297,
"sum": 2197438700,
"sum_of_squares": 133545882701698,
"variance": 468058704.9782911,
"std_deviation": 21634.664429528162,
"std_deviation_bounds": {
"upper": 52318.43092424462,
"lower": -34220.22679386803
}
}
}
}
В ответе вы также получаете сумму квадратов, расхождение, стандартное отклонение и его границы.
Агрегация мощности
Подсчет уникальных элементов может быть выполнен с помощью агрегации мощности. Это похоже на поиск результата запроса, как показано ниже:
select count(*) from (select distinct username from usageReport) u;
Определение мощности или количества уникальных значений для конкретного поля является довольно распространенной задачей. Например, если у вас есть поток кликов (click-stream) от различных посетителей вашего сайта, вы можете захотеть узнать, сколько уникальных посетителей на сайте в выбранный день, неделю или месяц.
Разберемся, как найти количество уникальных посетителей с помощью имеющихся данных сетевого трафика:
GET bigginsight/_search
{
"aggregations": {
"unique_visitors": {
"cardinality": {
"field": "username"
}
}
},
"size": 0
}
Ответ агрегации мощности выглядит так же, как и в других метрических агрегациях:
{
"took": 110,
...,
"hits": {
"total": 242836,
"max_score": 0,
"hits": []
},
"aggregations": {
"unique_visitors": {
"value": 79
}
}
}
Теперь, когда мы разобрались в простейших типах агрегаций, можем рассмотреть некоторые сегментарные агрегации.
Сегментарные агрегации
Сегментарные агрегации, или агрегации обобщения (bucket aggregations), полезны для анализирования того, как целое соотносится со своими частями, и получения более детальной картины. Они помогают разделять данные на небольшие части. Сегментарные агрегации всех типов разбивают данные на разные сегменты. Это наиболее распространенный вид агрегации, который используется в любом процессе анализа.
На базе примера данных сетевого трафика мы рассмотрим следующие темы.
• Сегментирование строковых данных.
• Сегментирование числовых данных.
• Агрегирование отфильтрованных данных.
• Вложенные агрегации.
• Сегментирование с нестандартными условиями.
• Сегментирование данных даты/времени.
• Сегментирование геопространственных данных.
Сегментирование строковых данных
Иногда требуется сегментировать данные или фрагмент данных, основанных на полях строкового типа, обычно это поля типа keyword в Elasticsearch. Ниже приведены некоторые примеры или сценарии применения, когда вам может понадобиться сегментировать данные по полю строкового типа.
• Сегментирование данных сетевого трафика по отделам.
• Сегментирование данных сетевого трафика по пользователям.
• Сегментирование данных сетевого трафика по приложениям или по категориям.
Самый распространенный способ сегментирования ваших данных строкового типа — с помощью агрегации терминов. Рассмотрим этот процесс детально.
Агрегация терминов (terms aggregation). Скорее всего, это самая популярная агрегация. Она полезна для сегментирования или группирования данных по выбранным определенным значениям. Предположим, в отношении примера с данными сетевого трафика, который мы загрузили, у нас есть следующий вопрос: каковы наиболее распространенные категории сайтов, которые посетило большинство пользователей?
Нам интересно узнать, какие сайты предпочитали пользователи, а не каков был объем трафика. В реляционной базе данных мы могли бы написать запрос следующего вида:
SELECT category, count(*) FROM usageReport GROUP BY category ORDER BY
count(*) DESC;
В запросе агрегаций Elasticsearch для получения аналогичного результата запрос может быть записан так:
GET /bigginsight/usageReport/_search
{
"aggs": { 1
"byCategory": { 2
"terms": { 3
"field": "category" 4
}
}
},
"size": 0 5
}
Разберемся с условиями запроса.
1. Элементы aggs или aggregations на верхнем уровне должны оборачивать любую агрегацию.
2. Дадим агрегации имя; в данном случае мы выполняем агрегацию терминов по полю категории и, следовательно, выбрали имя byCategory.
3. Поскольку у нас агрегация терминов, применяется элемент terms.
4. Требуется сделать агрегацию терминов по полю category.
5. Укажем size = 0, чтобы предотвратить попадание в ответ необработанных результатов. Нам нужны только результаты агрегации, но не результаты поиска. Поскольку мы не указали никаких элементов query высшего уровня, запрос будет работать со всеми документами. В результатах нам не нужны необработанные документы (или совпадения поиска).
Ответ должен выглядеть следующим образом:
{
"took": 11,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 242835, 1
"max_score": 0,
"hits": [] 2
},
"aggregations": { 3
"byCategory": { 4
"doc_count_error_upper_bound": 0, 5
"sum_other_doc_count": 0, 6
"buckets": [ 7
{
"key": "Chat", 8
"doc_count": 52277 9
},
{
"key": "File Sharing",
"doc_count": 46912
},
{
"key": "Other HTTP",
"doc_count": 38535
},
{
"key": "News",
"doc_count": 25784
},
{
"key": "Email",
"doc_count": 21003
},
{
"key": "Gaming",
"doc_count": 19578
},
{
"key": "Jobs",
"doc_count": 19429
},
{
"key": "Blogging",
"doc_count": 19317
}
]
}
}
}
Обратите внимание на следующие элементы ответа, отмеченные числами.
1. Элемент total под элементом hits (при навигации с вершины элемента JSON мы будем ссылаться на него как на hits.total) равен 242835. Это общее количество документов, обработанных агрегацией.
2. Массив hits.array пуст. Так произошло потому, что мы обозначили "size": 0, следовательно, сюда не были включены никакие результаты поиска. Мы заинтересованы в результатах агрегации, а не поиска.
3. Элемент aggregations на высшем уровне ответа JSON содержит все результаты агрегации.
4. Название агрегации — byCategory. Мы сами дали ей такое название. С его помощью будет легче ориентироваться в ответе запроса, поскольку ответ может быть создан для нескольких агрегаций одновременно.
5. Элемент doc_count_error_upper_bound отмечает ошибки во время агрегации. Данные разбиты на шарды; если каждый шард отправляет данные для всех ключей сегментирования, это приводит к слишком большому объему данных при отправке по сети. Elasticsearch отправляет только первые n сегментов по сети, если агрегация была запрошена для первых n позиций. В данном случае n — это количество сегментов агрегации, определенное параметром size. Более детально мы рассмотрим этот параметр далее в главе.
6. sum_other_doc_count — общее количество документов, которые не попали в возвращенные сегменты. По умолчанию агрегации терминов возвращают первые десять сегментов, если доступно более десяти разных сегментов. Оставшиеся документы помимо этих десяти суммируются и возвращаются в это поле. В данном случае есть только восемь категорий и, следовательно, это поле равно 0.
7. Агрегация возвращает список сегментов.
8. Ключ одного из сегментов относится к категории Chat.
9. Элемент doc_count показывает количество документов в сегменте.
Как вы можете видеть, в результатах запроса есть только восемь разных сегментов.
Далее нам нужно узнать наиболее распространенные приложения с точки зрения максимального количества записей для каждого приложения:
GET /bigginsight/usageReport/_search?size=0
{
"aggs": {
"byApplication": {
"terms": {
"field": "application"
}
}
}
}
Обратите внимание, что мы добавили size=0 как параметр запроса прямо в URL.
Мы получаем следующий ответ:
{
...,
"aggregations": {
"byApplication": {
"doc_count_error_upper_bound": 6325,
"sum_other_doc_count": 129002,
"buckets": [
{
"key": "Skype",
"doc_count": 26115
},
...
}
Обратите внимание, что sum_other_doc_count имеет большое значение — 129002. Это большое число по сравнению с суммарным количеством совпадений поиска. Как вы видели в предыдущем запросе, в индексе присутствует около 242 000 документов. Такая ситуация возникает по причине того, что по умолчанию эта агрегация терминов возвращает только десять сегментов. При текущих настройках первые десять сегментов с наиболее используемыми документами возвращаются в порядке убывания. Оставшиеся документы, не вошедшие в топ-10, обозначены в sum_other_doc_count. Фактически есть 30 разных приложений, которые используют наш сетевой трафик. Цифра в sum_other_doc_count — это количество оставшихся приложений, которые не попали в список сегментов.
Чтобы получить топ-n сегментов вместо десяти по умолчанию, мы можем использовать параметр size внутри агрегации терминов:
GET /bigginsight/usageReport/_search?size=0
{
"aggs": {
"byApplication": {
"terms": {
"field": "application",
"size": 15
}
}
}
}
Обратите внимание, что этот size (указанный внутри агрегации terms) отличается от size, указанного на верхнем уровне. На верхнем уровне параметр size используется для предотвращения попадания результатов поиска, а size внутри агрегации терминов указывает максимальное количество сегментов для возврата.
Агрегация терминов очень полезна для получения данных, которые можно использовать в графиках или диаграммах, если требуется анализировать относительные числа в полях строкового типа из определенного набора документов. В главе 7 вы узнаете, как применять агрегацию терминов для создания графиков и диаграмм.
Далее мы взглянем на то, как выполнять сегментирование полей числовых типов.
Сегментирование числовых данных
Еще один распространенный случай применения сегментированных агрегаций — необходимость разбиения данных на различные сегменты на основе числовых полей. Например, может потребоваться разбить данные о продуктах по различным ценовым диапазонам: до $10, от $10 до 50, от $50 до 100 и т.д. Возможно также разделить данные по возрастным группам, количеству сотрудников и другим параметрам.
В этом разделе мы рассмотрим следующие агрегации:
• агрегацию гистограммы;
• агрегацию диапазона.
Агрегация гистограммы
Агрегация гистограммы может разбивать данные на разные сегменты на основании числового поля. В запросе вы можете настроить диапазон каждого фрагмента, который также может называться интервалом.
Итак, у нас есть сведения об объеме сетевого трафика. Поле usage хранит число байтов, которые были использованы для приема или передачи данных. Попробуем разделить эти данные на фрагменты:
POST /bigginsight/_search?size=0
{
"aggs": {
"by_usage": {
"histogram": {
"field": "usage",
"interval": 1000
}
}
}
}
Агрегация выше будет разбивать все данные на следующие сегменты:
• от 0 до 999 — все записи, в которых usage ≥ 0 и < 1000;
• от 1000 до 1999 — все записи, в которых usage ≥ 1000 и < 2000;
• от 2000 до 3999 — все записи, в которых usage ≥ 2000 и < 3000.
И т.д.
Ответ будет выглядеть следующим образом (сокращен):
{
...,
"aggregations": {
"by_usage": {
"buckets": [
{
"key": 0,
"doc_count": 30060
},
{
"key": 1000,
"doc_count": 42880
},
Таким образом агрегация гистограммы создает сегменты равных значений, используя параметр interval, указанный в запросе. По умолчанию включаются все сегменты выбранного интервала, независимо от того, есть в них какие-либо документы или нет. Вы можете сделать так, чтобы получить только сегменты с документами. Для этого необходимо использовать параметр min_doc_count. Если он указан, агрегация гистограммы возвращает только те сегменты, в которых есть как минимум указанное количество документов.
Рассмотрим другой тип агрегаций — агрегацию диапазона, которую можно использовать для числовых данных.
Агрегация диапазона
Что, если мы не хотим, чтобы все сегменты имели один интервал? Вы можете создать неодинаковые по размеру сегменты с помощью агрегации диапазона.
Следующая агрегация разбивает данные на три сегмента: до 1 Кбайт, от 1 до 100 Кбайт и 100 Кбайт или больше. Обратите внимание, что в диапазоне мы можем указать from и to, но эти параметры необязательны. Если вы укажете только to, сегмент будет содержать все документы до указанного значения. Значение to эксклюзивно и не входит в текущий диапазон сегментов:
POST /bigginsight/_search?size=0
{
"aggs": {
"by_usage": {
"range": {
"field": "usage",
"ranges": [
{ "to": 1024 },
{ "from": 1024, "to": 102400 },
{ "from": 102400 }
]
}
}
}
}
Ответ на данный запрос выглядит следующим образом:
{
...,
"aggregations": {
"by_usage": {
"buckets": [
{
"key": "*-1024.0",
"to": 1024,
"doc_count": 31324
},
{
"key": "1024.0-102400.0",
"from": 1024,
"to": 102400,
"doc_count": 207498
},
{
"key": "102400.0-*",
"from": 102400,
"doc_count": 4013
}
]
}
}
}
Вы также можете создать свои метки key для сегментов диапазона, как в примере ниже:
POST /bigginsight/_search?size=0
{
"aggs": {
"by_usage": {
"range": {
"field": "usage",
"ranges": [
{ "key": "Upto 1 kb", "to": 1024 },
{ "key": "1 kb to 100 kb","from": 1024, "to": 102400 },
{ "key": "100 kb and more", "from": 102400 }
]
}
}
}
}
В результате полученные сегменты будут иметь набор ключей. Это удобно, если вы ищете релевантный сегмент в ответе и не хотите просматривать все возможные сегменты.
Для числовых данных доступно больше типов агрегаций, но рассмотрение всех не входит в задачи этой книги.
Далее мы разберемся в нескольких важных концепциях, связанных с сегментарной агрегацией и агрегациями в целом.
Агрегирование отфильтрованных данных
Немного отойдем от темы изучения различных сегментарных агрегаций и разберемся, как применять агрегации в отношении отфильтрованных данных. Вы уже научились применять агрегации для всех данных выбранного индекса/типа. На практике, прежде чем выполнять агрегации (метрические или сегментарные), вам почти всегда придется использовать некоторые фильтры.
Вернемся к примеру, который мы рассматривали в разделе «Сегментирование строковых данных». Мы нашли лидирующие категории по всему индексу и типу. Теперь нам необходимо найти такую категорию для конкретного клиента, а не для всех данных и всех клиентов:
GET /bigginsight/usageReport/_search?size=0
{
"query": {
"term": {
"customer": "Linkedin"
}
},
"aggs": {
"byCategory": {
"terms": {
"field": "category"
}
}
}
}
Мы изменили исходный запрос, который искал лидирующие категории, дополнив его (выделен выше жирным шрифтом). Мы написали запрос, внутри которого добавлен фильтр по конкретному интересующему нас клиенту.
Когда мы применяем тип запроса с любым типом агрегаций, меняется контекст данных, над которыми выполняется агрегация. Решение, к каким данным будет применяться агрегация, принимается запросом/фильтром.
Чтобы лучше понять, как это работает, взглянем на ответ на этот запрос:
{
"took": 18,
...,
"hits": {
"total": 76607,
"max_score": 0,
"hits": []
},
...
}
Общее количество результатов поиска в ответе сейчас намного ниже, чем в предыдущем запросе агрегации, проведенной по целому индексу/типу. Мы можем добавить дополнительные фильтры к запросу для уменьшения затраченного времени.
Следующий запрос применяет несколько фильтров и сужает работу агрегации — в пределах клиента и конкретного подмножества временных интервалов:
GET /bigginsight/usageReport/_search?size=0
{
"query": {
"bool": {
"must": [
{"term": {"customer": "Linkedin"}},
{"range": {"time": {"gte": 1506277800000, "lte": 1506294200000}}}
]
}
},
"aggs": {
"byCategory": {
"terms": {
"field": "category"
}
}
}
}
Таким образом, с помощью фильтров вы можете настраивать охват агрегации. Далее мы продолжим изучать разные сегментарные агрегации и вы узнаете, как вставлять метрические агрегации в сегментарные.
Вложенные агрегации
Сегментарные агрегации разбивают контекст на два или более сегмента. Можно ограничить контекст агрегации, уточняя элемент запроса, как вы уже видели в предыдущем разделе.
Когда метрическая агрегация вставляется в сегментарную, метрическая составляющая считается в пределах каждого сегмента. Для улучшения понимания попробуем ответить на следующий вопрос. Каков общий объем израсходованного трафика для каждого пользователя или конкретного клиента в определенный день?
Нам нужно будет выполнить следующие действия.
1. Сначала отфильтровать все данные для выбранного клиента и дня. Для этого мы можем выполнить глобальный запрос булева типа.
2. После фильтрации данных необходимо создать сегменты по каждому пользователю.
3. Как только это сделано, мы можем вычислить метрическую агрегацию суммы для поля общего потребления трафика (которое включает прием и передачу данных).
Следующий запрос выполняет все перечисленное. Вы можете свериться с цифрами и сносками по трем основным целям запроса:
GET /bigginsight/usageReport/_search?size=0
{
"query": { 1
"bool": {
"must": [
{"term": {"customer": "Linkedin"}},
{"range": {"time": {"gte": 1506257800000, "lte": 1506314200000}}}
]
}
},
"aggs": {
"by_users": { 2
"terms": {
"field": "username"
},
"aggs": {
"total_usage": { 3
"sum": { "field": "usage" }
}
}
}
}
}
Обратите внимание, что на верхнем уровне агрегация by_users, являющаяся агрегацией терминов, содержит еще один элемент aggs с метрической агрегацией total_usage внутри.
Ответ должен выглядеть следующим образом:
{
...,
"aggregations": {
"by_users": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 453,
"buckets": [
{
"key": "Jay May",
"doc_count": 2170,
"total_usage": {
"value": 6516943
}
},
{
"key": "Guadalupe Rice",
"doc_count": 2157,
"total_usage": {
"value": 6492653
}
},
...
}
Как видите, каждый сегмент агрегации терминов содержит дочерний элемент total_usage, хранящий значение метрической агрегации. Сегменты сортируются по количеству документов в каждом сегменте в порядке убывания. Вы можете изменить порядок сегментов, отредактировав соответствующий параметр в пределах сегментарной агрегации.
Взгляните на следующий фрагмент запроса, измененного для сортировки сегментов в порядке убывания метрики total_usage:
GET /bigginsight/usageReport/_search
{
...,
"aggs": {
"by_users": {
"terms": {
"field": "username",
"order": { "total_usage": "desc"}
},
"aggs": {
...
...
}
Выделенный пункт order в порядке убывания сортирует сегменты, используя вставленную агрегацию total_usage.
Сегментарные агрегации могут быть вставлены в другие агрегации такого же типа. Для улучшения понимания попробуем ответить на следующий вопрос: какие два пользователя в каждом отделе потребляют больше всего трафика? Следующий запрос поможет нам получить ответ:
GET /bigginsight/usageReport/_search?size=0
{
"query": { 1
"bool": {
"must": [
{"term": {"customer": "Linkedin"}},
{"range": {"time": {"gte": 1506257800000, "lte": 1506314200000}}}
]
}
},
"aggs": {
"by_departments": { 2
"terms": { "field": "department" },
"aggs": {
"by_users": { 3
"terms": {
"field": "username",
"size": 2,
"order": { "total_usage": "desc"}
},
"aggs": {
"total_usage": {"sum": { "field": "usage" }} 4
}
}
}
}
}
}
Обратите внимание на следующие пункты по числам в запросе.
1. Запрос, фильтрующий по конкретному клиенту и диапазону времени.
2. Агрегация терминов верхнего уровня для получения сегмента по каждому отделу.
3. Агрегация терминов второго уровня для получения топ-2 пользователей (обратите внимание на size = 2) в пределах каждого сегмента.
4. Метрическая агрегация, которая вычисляет общий объем трафика в пределах изначального сегмента. Для подсчета общего объема для каждого пользователя предназначена агрегация by_users, являющаяся текущим изначальным сегментом агрегации total_usage.
Таким образом мы можем вкладывать сегментарные и метрические агрегации друг в друга, чтобы быстро и эффективно получать ответы на сложные вопросы касательно хранимых в Elasticsearch больших данных.
Сегментирование с нестандартными условиями
Иногда нам нужно еще больше контроля над тем, как создаются сегменты. Уже рассмотренные нами агрегации работали с одним типом или полем. Если поле, на основе которого мы хотим разбить данные, строкового типа, мы обычно используем агрегацию терминов. Если поле числового типа, то есть несколько возможных вариантов, таких как агрегация гистограммы, агрегация диапазона и др., позволяющие разбивать данные на различные сегменты.
Следующие агрегации позволяют создать один или несколько сегментов на основании выбранных нами запросов/фильтров.
• Агрегация фильтра.
• Агрегация фильтров.
Рассмотрим их по очереди.
Агрегация фильтра
Зачем использовать агрегацию фильтра? Такой тип агрегации позволяет нам создать один сегмент по произвольному фильтру и оценить конкретные метрики в пределах этого сегмента.
Например, если бы мы хотели создать сегмент всех записей для категории Chat, мы могли бы использовать фильтр терминов. Мы хотим создать сегмент со всеми записями, которые соответствуют условию category = Chat.
POST /bigginsight/_search?size=0
{
"aggs": {
"chat": {
"filter": {
"term": {
"category": "Chat"
}
}
}
}
}
Ответ должен выглядеть следующим образом:
{
"took": 4,
...,
"hits": {
"total": 242836,
"max_score": 0,
"hits": []
},
"aggregations": {
"chat": {
"doc_count": 52277
}
}
}
Как видите, элемент aggregations содержит только один пункт, относящийся к категории Chat. Он включает 52 277 документов. Этот ответ можно увидеть как подмножество ответа агрегации терминов, которое содержит все категории, кроме Chat.
Рассмотрим агрегацию фильтров, которая позволяет сегментировать данные по нескольким фильтрам сразу.
Агрегация фильтров
С агрегацией фильтров вы можете создавать несколько сегментов, и каждый из них будет иметь свой фильтр, который сможет направлять документы в определенные для них сегменты. Рассмотрим пример.
Мы хотим создать несколько сегментов, чтобы узнать, сколько сетевого трафика использовано в категории Chat. В то же время мы хотим узнать, какая доля приходится на приложение Skype по сравнению с остальными приложениями в категории Chat. Для этой цели мы можем использовать агрегацию фильтров, поскольку она позволяет нам писать произвольные фильтры для создания сегментов:
GET bigginsight/_search?size=0
{
"aggs": {
"messages": {
"filters": {
"filters": {
"chat": { "match": { "category": "Chat" }},
"skype": { "match": { "application": "Skype" }},
"other_than_skype": {
"bool": {
"must": {"match": {"category": "Chat"}},
"must_not": {"match": {"application": "Skype"}}
}
}
}
}
}
}
}
Мы создали три фильтра для трех необходимых нам сегментов.
• Сегмент с ключом chat. Мы указали для фильтра category = Chat. Использованный нами запрос соответствия является высокоуровневым запросом, который понимает разметку базового поля. В данном случае категория базового поля — keyword и, следовательно, запрос соответствия ищет конкретное определение Chat.
• Сегмент с ключом Skype. Мы указали для фильтра application = Skype и включили только трафик Skype.
• Сегмент с ключом other_than_skype. Здесь мы использовали булев запрос для фильтрации документов в категории Chat, но не Skype.
Как вы можете видеть, агрегация фильтров является мощным инструментом, если требуется получить нестандартные сегменты с применением разных фильтров. Таким образом вы получаете полный контроль над процессом сегментирования. Вы можете выбрать свои поля и свои условия для создания сегментов по индивидуальным требованиям.
Далее мы разберемся, как разбивать данные в столбцах типа даты по различным временным интервалам.
Сегментирование данных даты/времени
Вы уже видели, как сегментировать (или разбивать) ваши данные на разные типы столбцов/полей. Анализ данных с учетом времени является еще одной распространенной задачей. В процессе работы могут возникать вопросы, для ответа на которые необходимо применять агрегации с учетом даты и времени. Вопросы могут быть следующими.
• Как меняются объемы продаж в разное время?
• Как меняется прибыль от месяца к месяцу?
В контексте примера с сетевым трафиком с помощью анализа данных вы можете получить ответы на следующие вопросы.
• Как в зависимости от времени меняются требования к пропускной способности сети в моей организации?
• Какие приложения в определенный период времени использовали больше всего трафика?
В Elasticsearch доступна мощная агрегация даты/гистограммы (date histogram aggregation), которая может помочь найти ответы на такие вопросы. Давайте детально рассмотрим пример ее использования.
Агрегация даты/гистограммы
Используя агрегацию даты/гистограммы, мы узнаем, как создавать сегменты по полю с датой. В процессе мы также рассмотрим такие задачи, как:
• создание сегментов по периодам времени;
• использование разных часовых поясов;
• вычисление других показателей в пределах «нарезанных» временных интервалов;
• фокусировка на определенном дне и изменение интервалов.
Создание сегментов по периодам времени
Следующий запрос разобьет данные по интервалам в один день. По тому же принципу, как мы уже выполняли сегментирование разных строковых значений, следующий запрос создаст сегменты по различным значениям времени, группируя их по интервалам в один день:
GET /bigginsight/usageReport/_search?size=0 1
{
"aggs": {
"counts_over_time": {
"date_histogram": { 2
"field": "time",
"interval": "1d" 3
}
}
}
}
1. Мы указали size = 0 как параметр запроса, вместо того чтобы задавать его в теле запроса.
2. Мы используем агрегацию date_histogram.
3. Мы хотим разбить данные по дням, поэтому задаем интервал как 1d (1 день). Можно указывать интервалы следующим образом: 1d (1 день), 1h (1 ч), 4h (4 ч), 30m (30 мин) и т.д., то есть выбор динамических критериев достаточно широк.
Ответ на данный запрос должен выглядеть следующим образом:
{
...,
"aggregations": {
"counts_over_time": {
"buckets": [
{
"key_as_string": "2017-09-23T00:00:00.000Z",
"key": 1506124800000,
"doc_count": 62493
},
{
"key_as_string": "2017-09-24T00:00:00.000Z",
"key": 1506211200000,
"doc_count": 5312
},
{
"key_as_string": "2017-09-25T00:00:00.000Z",
"key": 1506297600000,
"doc_count": 175030
}
]
}
}
}
Как видите, имеющиеся в нашем распоряжении данные охватывают лишь период в три дня. Сегменты в ответе содержат ключи двух видов: key и key_as_string. Поле key для миллисекунд с начала времени эпохи UNIX (1 января 1970 года), а key_as_string — для начала отсчета временного интервала по Всемирному координированному времени (UTC). В нашем случае был выбран интервал один день. Первый сегмент с ключом 2017-09-23T00:00:00.000Z является сегментом, содержащим документы между 23 и 24 сентября 2017 года.
Использование разных часовых поясов
Предположим, нужно разбить данные, ориентируясь на часовой пояс Индии (IST), а не на UTC. Для этого необходимо изменить параметр time_zone. Следует выбрать необходимое смещение указанного часового пояса относительно UTC. В данном случае оно составит +05:30, поскольку время IST отличается от UTC на 5 ч 30 мин:
GET /bigginsight/usageReport/_search?size=0
{
"aggs": {
"counts_over_time": {
"date_histogram": {
"field": "time",
"interval": "1d",
"time_zone": "+05:30"
}
}
}
}
Теперь ответ выглядит следующим образом:
{
...,
"aggregations": {
"counts_over_time": {
"buckets": [
{
"key_as_string": "2017-09-23T00:00:00.000+05:30",
"key": 1506105000000,
"doc_count": 62493
},
{
"key_as_string": "2017-09-24T00:00:00.000+05:30",
"key": 1506191400000,
"doc_count": 0
},
{
"key_as_string": "2017-09-25T00:00:00.000+05:30",
"key": 1506277800000,
"doc_count": 180342
}
]
}
}
}
Как видите, ключи key и key_as_string для всех сегментов изменились. Теперь они указывают на начало дня по времени IST. Кроме того, отсутствуют документы за 24 сентября 2017 года, так как это воскресенье.
Подсчет других показателей в пределах выбранных интервалов времени
Пока мы разбили данные на фрагменты, используя лишь агрегацию даты/гистограммы для создания сегментов по полю времени. Таким образом, мы получили количество документов в каждом сегменте. Далее попробуем ответить на вопрос: каков общий объем трафика за день для выбранного клиента? Следующий запрос позволит нам получить ответ:
GET /bigginsight/usageReport/_search?size=0
{
"query": { "term": {"customer": "Linkedin"} },
"aggs": {
"counts_over_time": {
"date_histogram": {
"field": "time",
"interval": "1d",
"time_zone": "+05:30"
},
"aggs": {
"total_bandwidth": {
"sum": { "field": "usage" }
}
}
}
}
}
Мы добавили фильтр термина для выбора данных только по одному клиенту. В пределах агрегации date_histogram мы разместили другую метрическую агрегацию — агрегацию суммы — для подсчета общего объема расходуемого трафика в пределах каждого сегмента. Таким образом мы получим общий объем данных за каждый день. Далее вы можете видеть сокращенный ответ на запрос:
{
..,
"aggregations": {
"counts_over_time": {
"buckets": [
{
"key_as_string": "2017-09-23T00:00:00.000+05:30",
"key": 1506105000000,
"doc_count": 18892,
"total_bandwidth": {
"value": 265574303
}
},
...
]
}
}
}
Фокусировка на определенном дне и изменение интервалов
Далее мы узнаем, как фокусироваться на определенном дне, фильтруя данные для других периодов времени и уменьшая значения интервала. Попытаемся получить почасовое распределение по объему передачи данных 25 сентября 2017 года.
То, что мы сейчас делаем, называется детализацией данных (drilling down). В частности, результат предыдущего запроса можно представить в виде линейного графика, где время будет на оси X, а трафик — на оси Y. Если мы хотим рассмотреть конкретный день на графике, пригодится следующий запрос:
GET /bigginsight/usageReport/_search?size=0
{
"query": {
"bool": {
"must": [
{"term": {"customer": "Linkedin"}},
{"range": {"time": {"gte": 1506277800000}}}
]
}
},
"aggs": {
"counts_over_time": {
"date_histogram": {
"field": "time",
"interval": "1h",
"time_zone": "+05:30"
},
"aggs": {
"hourly_usage": {
"sum": { "field": "usage" }
}
}
}
}
}
Сокращенный ответ будет выглядеть следующим образом:
{
...,
"aggregations": {
"counts_over_time": {
"buckets": [
{
"key_as_string": "2017-09-25T00:00:00.000+05:30",
"key": 1506277800000,
"doc_count": 465,
"hourly_usage": {
"value": 1385524
}
},
{
"key_as_string": "2017-09-25T01:00:00.000+05:30",
"key": 1506281400000,
"doc_count": 478,
"hourly_usage": {
"value": 1432123
}
},
...
}
Как видите, теперь у нас есть сегменты с данными с почасовым интервалом.
С помощью агрегации даты/гистограммы вы можете выполнять различные виды анализа данных, ориентируясь на время или дату. Как вы увидели в примерах, задать агрегацию с интервалом от одного часа до одного дня довольно просто. Вы можете разбивать данные по конкретным интервалам по необходимости, без предварительного планирования. Есть возможность делать это и с большими данными — вряд ли существуют другие системы хранения данных, предлагающие такой уровень гибкости при работе с большими данными.
Сегментирование геопространственных данных
Еще одной полезной функцией является возможность геопространственного анализа данных. Если у вас есть данные типа геоточки с указанными координатами, вы можете выполнять различные виды их анализа с возможностью нанесения на карту для улучшения понимания данных.
Рассмотрим два типа геопространственных агрегаций:
• по геодистанции;
• по сетке GeoHash.
Агрегация по геодистанции
Агрегация по геодистанции позволяет создавать сегменты по расстоянию от выбранной геоточки. Для лучшего понимания взгляните на рис. 4.2, где показана агрегация по геодистанции с указанными параметрами to (слева), а также to и from (справа).
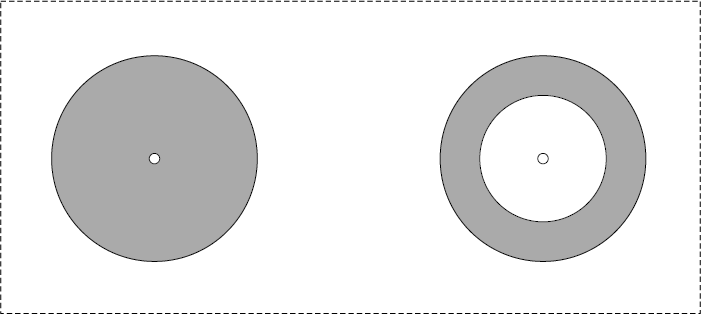
Рис. 4.2
Зона, обозначенная серым цветом, представляет собой область, включенную в агрегацию по геодистанции.
Следующая агрегация сформирует сегмент со всеми документами в пределах выбранного расстояния от конкретной геоточки. Результат совпадет с первым кругом (слева) на рис. 4.2. Закрашенная область от центра до края (выбранного радиуса) формирует круг:
GET bigginsight/usageReport/_search?size=0
{
"aggs": {
"within_radius": {
"geo_distance": {
"field": "location",
"origin": {"lat": 23.102869,"lon": 72.595692},
"ranges": [{"to": 5}]
}
}
}
}
Как видите, параметр ranges работает как агрегация диапазона, которую мы рассматривали ранее. Он включает все точки в радиусе 5 м от выбранного origin. Это полезно в случае с агрегациями для подсчета всех возможных объектов в радиусе 2 км от выбранной точки, что часто используется на многих сайтах. Это хороший способ найти все организации в пределах выбранного расстояния от вашего местонахождения (например, все кофейни и больницы в радиусе 2 км).
Единица измерения дистанции по умолчанию — метры, но вы можете указать иное в параметре unit, например километры, мили или другие варианты.
Теперь взглянем, что получится, если мы укажем оба параметра, from и to, в агрегации геодистанции. Результат будет соответствовать кругу на рис. 4.2, справа:
GET bigginsight/usageReport/_search?size=0
{
"aggs": {
"within_radius": {
"geo_distance": {
"field": "location",
"origin": {"lat": 23.102869,"lon": 72.595692},
"ranges": [{"from": 5, "to": 10}]
}
}
}
}
В данном случае мы сегментируем все точки, которые находятся не ближе чем 5 м и не далее чем 10 м от выбранной позиции. Аналогичным образом вы можете сформировать сегмент точек, которые расположены на расстоянии как минимум x единиц измерения от выбранной позиции, указав только параметр from.
Рассмотрим агрегацию по сетке GeoHash.
Агрегация по сетке GeoHash
Агрегация по сетке GeoHash задействует механизм GeoHash для разбиения карты на небольшие блоки. Вы можете более детально узнать о системе GeoHash по ссылке https://en.wikipedia.org/wiki/Geohash. Эта система представляет карту мира в виде сетки прямоугольных областей с различной степенью точности. Низкие значения точности используются для крупных географических зон, а высокие значения — для мелких, более конкретизированных областей:
GET bigginsight/usageReport/_search?size=0
{
"aggs": {
"geo_hash": {
"geohash_grid": {
"field": "location",
"precision": 7
}
}
}
}
Мы установили уровень точности равным 7, поскольку данные в нашем примере с сетевым трафиком относятся к совсем небольшой географической области. Поддерживаются значения точности от 1 до 12. Взглянем на ответ на этот запрос:
{
...,
"aggregations": {
"geo_hash": {
"buckets": [
{
"key": "ts5e7vy",
"doc_count": 161893
},
{
"key": "ts5e7vw",
"doc_count": 80942
}
]
}
}
}
После агрегации данных на блоки GeoHash с уровнем точности 7 все документы распределились по двум областям GeoHash, а также выполнен соответствующий подсчет документов, как вы видите в ответе. Мы можем уменьшить масштаб этой карты или запросить разбиение данных на меньшие фрагменты, увеличив значение точности.
Если вы попробуете использовать уровень точности 9, то увидите следующий ответ:
{
...,
"aggregations": {
"geo_hash": {
"buckets": [
{
"key": "ts5e7vy80k",
"doc_count": 131034
},
{
"key": "ts5e7vwrdb",
"doc_count": 60953
},
{
"key": "ts5e7vy84c",
"doc_count": 30859
},
{
"key": "ts5e7vwxfn",
"doc_count": 19989
}
]
}
}
}
Как видите, агрегация по сетке GeoHash является довольно мощным инструментом агрегации данных по географическим регионам различных размеров и с разными уровнями точности. Вы также можете создать визуализацию с помощью Kibana или использовать эти данные в своем приложении с библиотекой, которая способна нанести данные на карту.
Итак, вы узнали о широком спектре сегментарных агрегаций, которые позволяют разбивать данные различных типов. Мы рассмотрели агрегации текстовых, числовых, геопространственных данных, а также данных типа «дата/время». Далее вы узнаете, что представляют собой агрегации контейнеров.
Агрегации контейнеров
Агрегации контейнеров позволяют вам агрегировать результат других агрегаций. Контейнером называется результат одной агрегации при его использовании в качестве ввода для другой. Агрегация контейнеров является относительно новой функцией и до сих пор считается экспериментальной. Есть два типа агрегаций контейнеров.
• Родительский — агрегация контейнеров вложена в другую агрегацию.
• Потомственный — агрегация контейнеров является результатом изначальной агрегации.
Разберемся, как работает агрегация контейнеров, на примере агрегации общей суммы, которая является родительской.
Подсчет общей суммы использования трафика по времени. Когда мы изучали агрегацию даты/гистограммы в предыдущем разделе, мы рассмотрели агрегацию для подсчета почасового использования трафика в пределах одного дня. Выполнив задание, мы получили данные за 24 сентября с почасовым расходом трафика с 12 до 13, с 13 до 14 ч и т.д. Используя агрегацию общей суммы, мы также можем узнать общий расход трафика в конце каждого часа на протяжении дня. Взглянем на запрос и попробуем в нем разобраться:
GET /bigginsight/usageReport/_search?size=0
{
"query": {
"bool": {
"must": [
{"term": {"customer": "Linkedin"}},
{"range": {"time": {"gte": 1506277800000}}}
]
}
},
"aggs": {
"counts_over_time": {
"date_histogram": {
"field": "time",
"interval": "1h",
"time_zone": "+05:30"
},
"aggs": {
"hourly_usage": {
"sum": { "field": "usage" }
},
"cumulative_hourly_usage": { 1
"cumulative_sum": { 2
"buckets_path": "hourly_usage" 3
}
}
}
}
}
}
Только выделенный фрагмент кода является новым дополнением к запросу, который вы видели ранее. Нашей целью было подсчитать общую сумму по сегментам, созданным предыдущей агрегацией. Попробуем разобраться в новой части по указанным цифрам.
1. Даем понятное название для этой агрегации, размещаем ее внутри родительской агрегации даты/гистограммы.
2. Используем агрегацию общей суммы, следовательно, ссылаемся здесь на ее название, а именно — cumulative_sum.
3. Элемент bucket_path ссылается на метрику, основываясь на которой мы будем считать общую сумму. Нам необходимо суммировать полученные ранее значения метрики hourly_usage.
Ответ должен выглядеть следующим образом (сокращено):
{
...,
"aggregations": {
"counts_over_time": {
"buckets": [
{
"key_as_string": "2017-09-25T00:00:00.000+05:30",
"key": 1506277800000,
"doc_count": 465,
"hourly_usage": {
"value": 1385524
},
"cumulative_hourly_usage": {
"value": 1385524
}
},
{
"key_as_string": "2017-09-25T01:00:00.000+05:30",
"key": 1506281400000,
"doc_count": 478,
"hourly_usage": {
"value": 1432123
},
"cumulative_hourly_usage":
{
"value": 2817647
}
}
Как видите, cumulative_hourly_usage содержит сумму hourly_usage до текущего момента. В первом сегменте почасовой и общий почасовой расходы равны. Во втором и последующих сегментах в общую сумму входят все почасовые сегменты.
Агрегации контейнеров являются мощным инструментом. Они могут высчитывать производные, скользящее среднее, среднее число по другим сегментам (минимальное, максимальное и пр.), а также среднее по ранее вычисленным агрегациям.
Резюме
Из этой главы вы узнали, как использовать Elasticsearch для создания мощных аналитических приложений. Вы увидели, как разбивать данные для их лучшего восприятия. Мы начали с метрической агрегации, чтобы разобраться с числовыми типами данных. Далее вы узнали о сегментарных агрегациях, о том, как данные «нарезаются» на фрагменты для упрощения поиска.
Мы также поговорили о работе агрегаций контейнеров. Все задачи мы выполняли, используя реалистичный набор данных о сетевом трафике. Благодаря приведенным примерам вы могли увидеть, насколько гибким является Elasticsearch как движок аналитики. Он позволяет анализировать любое поле без дополнительного моделирования данных, даже если речь идет о больших данных. Это исключительная возможность, которую могут предложить не все хранилища данных. Как вы увидите в главе 7, многие из рассмотренных здесь агрегаций можно использовать в Kibana.
Итак, теперь у вас есть отличный базис для изучения остальных компонентов Elastic Stack. Начиная со следующей главы, мы сменим акцент и перейдем к изучению утилиты Logstash, которая занимается сбором данных для Elasticsearch из разнообразных источников.
Последовательность гиперссылок, по которой следует один посетитель сайта или несколько, представленная в порядке просмотра.

