3. Поиск — вот что важно
Одна из сильнейших сторон Elasticsearch — возможности поиска. В предыдущей главе мы подробно рассмотрели базовые концепции Elasticsearch, REST API и разобрались с основными операциями. С этими знаниями продолжим наш путь в освоении Elastic Stack. В данной главе будут рассмотрены следующие темы.
• Основы анализа текста.
• Поиск по структурированным данным.
• Написание сложных запросов.
• Полнотекстовый поиск.
Основы анализа текста
Анализ текста отличается от других видов анализа данных: чисел, даты и времени. Анализ числовых типов данных и даты/времени может выполняться определенным образом. Например, если вы ищете все записи, в которых указана цена 50 или выше, результат будет простым: «да» или «нет» для каждой записи. То есть либо запись соответствует запросу и выводу в результатах, либо нет. Аналогичным образом при поиске чего-либо по дате и времени критерий поиска четко обозначен — запись либо попадает в диапазон необходимых дат/времени, либо не попадает.
Однако анализ текстовых/строковых данных отличается. Текстовые данные могут иметь другую природу и могут использоваться для структурированного и неструктурированного анализа.
Например, к структурированным типам для строковых полей относятся коды стран, коды продуктов, нечисловые серийные номера/идентификаторы и пр. Типы данных этих полей могут быть строковыми, но зачастую для них приходится писать запросы точного соответствия.
Сначала мы рассмотрим принципы анализа неструктурированного текста, который также известен как полнотекстовый поиск.
В предыдущей главе мы уже разобрались с такими понятиями Elasticsearch, как индексы, типы и разметка внутри типа. Все поля текстового типа анализируются инструментом под названием анализатор.
В следующих подразделах мы изучим такие темы.
• Анализаторы Elasticsearch.
• Использование встроенных анализаторов.
• Добавление автозавершения в пользовательском анализаторе.
Анализаторы Elasticsearch
Основная задача анализатора — взять значение поля и разбить его на термы, или определения (слова, словосочетания или фразы). В главе 2 мы рассмотрели структуру обратного индекса. Работа анализатора состоит в том, чтобы брать документы и каждое поле документа, а затем извлекать из них термы. Благодаря этим термам возможен поиск по индексу, таким образом, мы можем найти, какие именно документы содержат конкретные ключевые слова.
Анализатор проводит процесс разбивки введенных символов на термы. Это происходит дважды:
• во время индексирования;
• во время поиска.
Основная задача анализатора — обработать поля документа и построить актуальный индекс.
Каждое поле текстового типа должно быть проанализировано до того, как документ будет проиндексирован. Именно этот процесс анализирования делает возможным поиск по документам с использованием любых поисковых терминов.
Анализаторы можно настроить для каждого поля, таким образом, мы можем иметь два поля текстового типа в пределах одного документа и каждое из них будет иметь отдельный анализатор.
Elasticsearch использует анализатор для обработки текстовых данных. В него входят следующие компоненты:
• фильтры символов — ноль или более;
• токенизатор — ровно один;
• фильтры токенов — ноль или более.
На следующей схеме показано, как эти компоненты расположены в анализаторе (рис. 3.1).
Рассмотрим назначение каждого компонента.
Фильтры символов
Во время настройки анализатора мы можем выбрать один или несколько фильтров символов либо не выбрать ни одного. Фильтр символов работает с потоком символов в поле ввода; каждый фильтр может добавлять, удалять или изменять символы в поле ввода.
Elasticsearch поставляется со встроенными фильтрами символов, которые можно сразу использовать. Либо можно создать свой собственный анализатор.
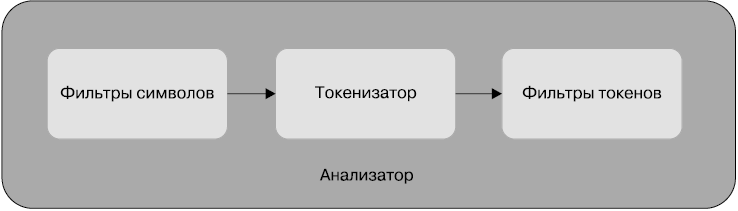
Рис. 3.1
Например, один из встроенных фильтров символов Elasticsearch называется Mapping Char Filter. Он может преобразовывать символ или последовательность символов в нужные вам символы.
Например, вы хотите превратить смайлики в текст, который описывал бы их смысл:
• :) должен быть преобразован в _smile_ (улыбка);
• :( должен быть преобразован в _sad_ (грусть);
• :D должен быть преобразован в _laugh_ (смех).
Это можно сделать с помощью Mapping Char Filter:
"char_filter": {
"my_char_filter": {
"type": "mapping",
"mappings": [
":) => _smile_",
":( => _sad_",
":D => _laugh_"
]
}
}
Если данный фильтр символов использовать для создания анализатора, мы получим следующий результат:
Доброе утро всем :) будет преобразовано в Доброе утро всем _улыбка_.
Сегодня я себя плохо чувствую :( будет преобразовано в Сегодня я себя плохо чувствую _грусть_.
Поскольку фильтры символов находятся в самом начале цепи обработки, выполняемой анализатором (см. рис. 3.1), токенизатор всегда видит замененные символы. Фильтры символов удобны для замены символов чем-нибудь более понятным в определенных случаях, например замены числовых символов из других языков на понятные в вашей среде. Иначе говоря, числа из таких языков, как хинди, арабский и др., могут быть преобразованы в ноль, один, два и т.д.
Вы можете найти список доступных встроенных фильтров символов по следующей ссылке: https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-charfilters.html.
Токенизатор
В анализаторе всегда есть один токенизатор. В его задачу входят получение потока символов и создание потока токенов. Эти токены используются для постройки обратного индекса. Токен примерно соответствует слову. В дополнение к разбивке символов на слова или токены токенизатор также создает стартовые и конечные точки для каждого токена в потоке ввода.
Elasticsearch поставляется с несколькими токенизаторами, которые могут быть использованы для создания собственных анализаторов. Сама Elasticsearch также применяет эти токенизаторы для составления встроенных анализаторов.
Список доступных встроенных токенизаторов вы можете найти по ссылке https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-tokenizers.html.
Стандартный токенизатор — один из самых популярных, поскольку подходит для большинства языков. Взглянем поближе на его возможности.
Стандартный токенизатор. В упрощенном понимании стандартный токенизатор разбивает поток символов, разделяя их знаками пунктуации и пробелами.
В следующем примере вы можете видеть, как стандартный токенизатор разбивает поток символов на токены:
POST _analyze
{
"tokenizer": "standard",
"text": "Tokenizer breaks characters into tokens!"
}
Данная команда приводит к следующему выводу. Обратите внимание на объекты start_offset, end_offset и positions:
{
"tokens": [
{
"token": "Tokenizer",
"start_offset": 0,
"end_offset": 9,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "breaks",
"start_offset": 10,
"end_offset": 16,
"type": "<ALPHANUM>",
"position": 1
},
{
"token": "characters",
"start_offset": 17,
"end_offset": 27,
"type": "<ALPHANUM>",
"position": 2
},
{
"token": "into",
"start_offset": 28,
"end_offset": 32,
"type": "<ALPHANUM>",
"position": 3
},
{
"token": "tokens",
"start_offset": 33,
"end_offset": 39,
"type": "<ALPHANUM>",
"position": 4
}
]
}
Если необходимо, этот поток токенов может быть обработан фильтрами токенов анализатора.
Фильтры токенов
В анализаторе может быть один или несколько фильтров токенов либо не быть их вовсе. Каждый фильтр токенов может добавлять, удалять или изменять токены во входящем потоке токенов. Поскольку в анализаторе допускается наличие нескольких фильтров токенов, вывод каждого из них отправляется следующему, пока не будут пройдены все.
Elasticsearch поставляется с несколькими фильтрами токенов, и вы можете использовать их для создания собственного анализатора.
Вот несколько примеров встроенных фильтров токенов.
• Фильтр токенов нижнего регистра. Заменяет все токены на вводе версиями в нижнем регистре.
• Стоп-токен-фильтр. Убирает стоп-слова, то есть слова, которые не имеют особого значения для контекста. Например, в английском языке это слова is, a, an и the, которые не несут особого смысла в предложении. Для решения многих проблем текстового поиска имеет смысл убирать такие слова.
Список доступных встроенных фильтров токенов можно найти по следующей ссылке: https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-tokenfilters.html.
Итак, мы рассмотрели назначение фильтров символов, токенизаторов и фильтров токенов. Следовательно, вы готовы узнать, как работают встроенные анализаторы Elasticsearch.
Использование встроенных анализаторов
Elasticsearch поставляется с несколькими встроенными анализаторами, которые вы можете использовать напрямую. Почти все из них сразу готовы к работе и не требуют изменений в конфигурации, но при этом они достаточно гибкие для настройки различных параметров.
Вот некоторые популярные анализаторы, поставляемые в комплекте с Elasticsearch.
• Стандартный анализатор. Анализатор по умолчанию. Если не настроены дополнительные анализаторы уровня поля, типа или индекса, он будет анализировать все поля.
• Языковые анализаторы. Разные языки ориентируются на разные правила грамматики. Следовательно, различаются и виды потока символов, а также преобразования их в токены или слова. У каждого языка также есть свой настраиваемый список стоп-слов.
• Анализатор пробелов. Этот компонент разбивает ввод на токены в тех случаях, если в тексте найден пробел, отступ, перенос строки.
Вы можете найти список доступных встроенных фильтров токенов по следующей ссылке: https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-analyzers.html.
Стандартный анализатор. Подходит для многих языков и ситуаций. Кроме того, вы можете настроить его под конкретный язык или ситуацию. Он состоит из следующих компонентов.
• Токенизатор: стандартный токенизатор. Для разделения токенов по пробелам.
• Фильтры токенов.
• Стандартный фильтр токенов. Применяется как метка-заполнитель в пределах стандартного анализатора. Не изменяет входящие токены, но может быть использован в будущем для выполнения задач.
• Фильтр токенов нижнего регистра. Преобразует все токены ввода в нижний регистр.
• Стоп-токен-фильтр. Убирает указанные стоп-слова. По умолчанию в качестве списка стоп-слов задано _none_, следовательно, никакие стоп-слова не удаляются.
Взглянем на работу стандартного анализатора с настройками по умолчанию:
PUT index_standard_analyzer
{
"settings": {
"analysis": {
"analyzer": {
"std": {
"type": "standard"
}
}
}
},
"mappings": {
"my_type": {
"properties": {
"my_text": {
"type": "text",
"analyzer": "std"
}
}
}
}
}
Здесь создан индекс index_standard_analyzer. Обратите внимание на две вещи.
• Под элементом settings мы явно указали один анализатор с именем std. Тип анализатора — standard. Кроме этой, никаких других настроек стандартного анализатора мы не выполняли.
• В индексе мы создали один тип с названием my_type и явно указали для анализатора единственное поле — my_text.
Посмотрим, как Elasticsearch станет выполнять анализ поля my_text каждый раз, когда любой документ в пределах этого индекса будет проиндексирован. Мы можем провести подобный тест с помощью API _analyze:
POST index_standard_analyzer/_analyze
{
"field": "my_text",
"text": "The Standard Analyzer works this way."
}
Данная команда выведет следующие токены:
{
"tokens": [
{
"token": "the",
"start_offset": 0,
"end_offset": 3,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "standard",
"start_offset": 4,
"end_offset": 12,
"type": "<ALPHANUM>",
"position": 1
},
{
"token": "analyzer",
"start_offset": 13,
"end_offset": 21,
"type": "<ALPHANUM>",
"position": 2
},
{
"token": "works",
"start_offset": 22,
"end_offset": 27,
"type": "<ALPHANUM>",
"position": 3
},
{
"token": "this",
"start_offset": 28,
"end_offset": 32,
"type": "<ALPHANUM>",
"position": 4
},
{
"token": "way",
"start_offset": 33,
"end_offset": 36,
"type": "<ALPHANUM>",
"position": 5
}
]
}
Обратите внимание, что в данном случае в качестве анализатора уровня поля для my_field был явно выбран стандартный анализатор. Даже если не оставлять подобного указания, стандартный анализатор будет анализатором по умолчанию при условии, что не было указано иных вариантов.
Как видите, все токены в выводе записаны в нижнем регистре. Несмотря на то что стандартный анализатор имеет стоп-токен-фильтр, ни один из токенов не был отфильтрован. Поэтому в выводе _analyze все слова являются токенами.
Создадим другой индекс, который будет использовать стоп-слова английского языка:
PUT index_standard_analyzer_english_stopwords
{
"settings": {
"analysis": {
"analyzer": {
"std": {
"type": "standard",
"stopwords": "_english_"
}
}
}
},
"mappings": {
"my_type": {
"properties": {
"my_text": {
"type": "text",
"analyzer": "std"
}
}
}
}
}
Обратите внимание на разницу. Новый индекс использует стоп-слова _english_. Вы можете указать список стоп-слов напрямую, например stopwords: (a, an, the). Значение _english_ включает все подобные слова на английском языке.
Когда вы попробуете использовать API _analyze в новом индексе, увидите, что он удаляет такие стоп-слова, как the и this:
POST index_standard_analyzer_english_stopwords/_analyze
{
"field": "my_text",
"text": "The Standard Analyzer works this way."
}
Вы получите ответ следующего вида:
{
"tokens": [
{
"token": "standard",
"start_offset": 4,
"end_offset": 12,
"type": "<ALPHANUM>",
"position": 1
},
{
"token": "analyzer",
"start_offset": 13,
"end_offset": 21,
"type": "<ALPHANUM>",
"position": 2
},
{
"token": "works",
"start_offset": 22,
"end_offset": 27,
"type": "<ALPHANUM>",
"position": 3
},
{
"token": "way",
"start_offset": 33,
"end_offset": 36,
"type": "<ALPHANUM>",
"position": 5
}
]
}
Как видите, были удалены английские стоп-слова the и this. Таким образом, с небольшими настройками можно использовать стандартный анализатор для английского и многих других языков.
Рассмотрим практический пример создания собственного анализатора.
Добавление автозавершения в пользовательском анализаторе
В определенных ситуациях может понадобиться создать свой нестандартный анализатор путем выбора фильтров, токенизаторов и фильтров токенов. Создадим анализатор, который сможет предоставить такой функционал, как автозавершение текста.
Для добавления автозавершения мы не можем использовать стандартный анализатор или один из встроенных анализаторов Elasticsearch. Анализатор отвечает за создание термов во время индексирования. Наш анализатор должен уметь создавать такие термы, которые помогут с автозавершением. Для облегчения понимания перейдем к конкретному примеру.
Если бы во время индексирования мы использовали стандартный анализатор, то для поля со значением Learning Elastic Stack 6 получили бы следующий вывод:
GET /_analyze
{
"text": "Learning Elastic Stack 6",
"analyzer": "standard"
}
Ответ на такой запрос будет содержать слова Learning, Elastic, Stack и 6. Именно такие термы создала бы система Elasticsearch, сохранив их в индексе при использовании стандартного анализатора. Теперь нужно сделать следующее: когда пользователь начнет набирать отдельные буквы слова, программа должна предлагать подходящие результаты. Например, если пользователь набрал elas, он должен получить такой результат: Learning Elastic Stack 6. Составим анализатор, который мог бы генерировать термы типа el, ela, elas, elast, elasti, elastic, le, lea и т.д.:
PUT /custom_analyzer_index
{
"settings": {
"index": {
"analysis": {
"analyzer": {
"custom_analyzer": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"lowercase",
"custom_edge_ngram"
]
}
},
"filter": {
"custom_edge_ngram": {
"type": "edge_ngram",
"min_gram": 2,
"max_gram": 10
}
}
}
}
},
"mappings": {
"my_type": {
"properties": {
"product": {
"type": "text",
"analyzer": "custom_analyzer",
"search_analyzer": "standard"
}
}
}
}
}
В данном случае в индексе работает нестандартный анализатор, который использует стандартный токенизатор для создания токенов, и два фильтра токенов — фильтр нижнего регистра и фильтр токенов edge_ngram. Последний разбивает каждый токен на два, три, четыре символа вплоть до десяти. При входящем токене-слове elastic будут созданы токены el, ela и т.д. Это позволит осуществлять поиск с автозавершением.
При условии, что оба продукта проиндексированы и пользователь уже ввел Ela, поиск должен вывести оба продукта:
POST /custom_analyzer_index/my_type
{
"product": "Learning Elastic Stack 6"
}
POST /custom_analyzer_index/my_type
{
"product": "Mastering Elasticsearch"
}
GET /custom_analyzer_index/_search
{
"query": {
"match": {
"product": "Ela"
}
}
}
Поскольку индекс содержит термы el, ela и т.д., мы получим ответ в виде обоих названий. Это было бы невозможным при использовании стандартного анализатора в момент индексирования. На текущий момент можно считать, что стандартный анализатор (настроенный как search_analyzer) работает с учетом имеющихся критериев поиска, а полученный вывод использует для выполнения поиска. В этом примере он начнет искать термин ela в индексе. Поскольку индекс создан с использованием нестандартного анализатора с фильтром токенов _ngram, будут найдены соответствия для обоих названий.
Итак, анализаторы играют важную роль в функционировании Elasticsearch. Они решают, какие именно выражения сохраняются в индексе. Таким образом, от типа применяемого во время индексирования анализатора зависит, какие виды поисковых операций возможны с этим индексом. Например, стандартный анализатор не подойдет, если требуется поддержка функции автозавершения.
Прежде чем мы перейдем к следующему разделу и рассмотрим другие типы запросов, создадим необходимый для дальнейшей работы индекс и добавим нужные данные. Мы будем использовать данные каталога товаров популярного сервиса электронной коммерции www.amazon.com. Их можно скачать по ссылке http://dbs.uni-leipzig.de/file/Amazon-GoogleProducts.zip.
Для начала создадим индекс и импортируем данные:
PUT /amazon_products
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0,
"analysis": {
"analyzer": {
}
}
},
"mappings": {
"products": {
"properties": {
"id": {
"type": "keyword"
},
"title": {
"type": "text"
},
"description": {
"type": "text"
},
"manufacturer": {
"type": "text",
"fields": {
"raw": {
"type": "keyword"
}
}
},
"price": {
"type": "scaled_float",
"scaling_factor": 100
}
}
}
}
}
Нужно проанализировать поля названия и описания — текстовые поля. Таким образом мы сделаем их доступными для полнотекстового поиска. Поле производителя является текстовым, но также присутствует поле с необработанным названием. Это поле сохраняется в двух видах: как text (manufacturer) и keyword (manufacturer.raw). Все поля типа keyword на внутреннем уровне используют анализатор ключевых слов, который состоит из кольцевого токенизатора ключевых слов. Он попросту возвращает весь ввод как один токен. Помните, что наличие фильтров символов и токенов в анализаторе не обязательно. Таким образом, указывая для поля тип keyword, мы выбираем кольцевой анализатор и тем самым пропускаем для этого поля весь процесс анализа.
Для поля цены выбран тип scaled_float. Это новый тип, появившийся в версии Elastic 6.0. Он на внутреннем уровне хранит переменные как целые числа с возможностью масштабирования. Например, 13.99 будет храниться как 1399 с фактором масштабирования 100. Это экономит занимаемую память, так как типы данных float и double занимают больше места.
Для импортирования данных проследуйте по инструкциям в сопроводительной информации и исходном коде к этой книге, которые размещены в репозитории GitHub по следующей ссылке: https://github.com/pranav-shukla/learningelasticstack. Инструкции по импортированию находятся в файле chapter-03/README.md.
Выполнив нужные действия, убедитесь, что импортировали данные, с помощью следующего запроса:
GET /amazon_products/products/_search
{
"query": {
"match_all": {}
}
}
В следующем разделе мы поговорим о запросах структурированного поиска.
Поиск по структурированным данным
В некоторых ситуациях требуется узнать, следует включать определенный документ в результаты поиска или нет, и для этого подойдет обычный бинарный ответ. С другой стороны, есть другие типы запросов, основанные на релевантности. Эти запросы возвращают оценку для каждого документа, чтобы обозначить, насколько хорошо он вписывается в запрос. Большинство структурированных запросов не нуждаются в оценке релевантности, и ответ всегда представляет собой простое «да/нет» для любого пункта, который включен в результаты или исключен из них. Эти структурированные запросы также называют запросами на уровне термов (term level queries).
Рассмотрим порядок выполнения такого запроса (рис. 3.2).
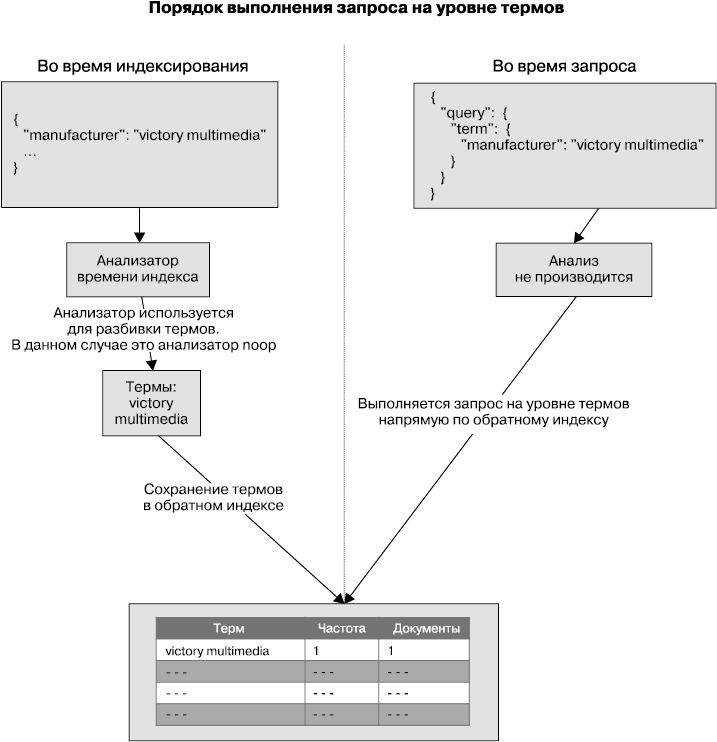
Рис. 3.2
Как видите, рисунок разделен на две части. Левая половина показывает происходящее во время индексирования, а в правой вы видите, что происходит во время выполнения запроса на уровне термов.
Взглянем на левую часть рисунка — на происходящее во время индексирования. В частности, мы видим построение обратного индекса и создание запроса для поля manufacturer.raw. Вспомним, что согласно нашему определению индекса поле manufacturer.raw имеет тип keyword. Поля этого типа не анализируются; значение поля сохраняется напрямую как терм в обратном индексе.
В правой части рисунка показано, что происходит, когда мы ищем по запросу term, который является запросом на уровне термов. Запрос term, как мы увидим в этом разделе позже, напрямую переходит к поиску терма victor multimedia, не разбивая его и не используя анализатор. Такие запросы полностью пропускают процесс анализа и ищут необходимый терм напрямую в обратном индексе.
Запросы на уровне термов создают слой-основу, на котором строятся другие, высокоуровневые полнотекстовые запросы. Их мы рассмотрим в следующем разделе.
Мы изучим такие типы запросов:
• запрос диапазона;
• запрос существования;
• term-запрос (термин-запрос);
• запрос терминов.
Запрос диапазона
Запросы диапазона (range query) могут применяться к полям с типами данных, которые естественно упорядочены. Например, к нормально упорядоченным относятся целые числа и даты. Не составляет труда выяснить, какое значение меньше, равно или больше других значений. Благодаря нормальному порядку, свойственному этим типам данных, мы можем выполнять по отношению к ним запрос диапазона.
Мы обсудим, как применять запросы диапазона в следующих случаях:
• для числовых типов;
• с увеличением оценки;
• для дат.
Взглянем на типичный запрос диапазона для числового поля.
Запрос диапазона для числового типа
Предположим, что мы храним продукты с их ценами в индексе Elasticsearch и хотим выбрать все продукты в пределах определенного диапазона. Запрос для выбора продуктов в диапазоне от $10 до 20 выглядит следующим образом:
GET /amazon_products/products/_search
{
"query": {
"range": {
"price": {
"gte": 10,
"lte": 20
}
}
}
}
Ответ на такой запрос выглядит так:
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
},
"hits": {
"total": 201, 1
"max_score": 1, 2
"hits": [
{
"_index": "amazon_products",
"_type": "products",
"_id": "AV5lK4WiaMctupbz_61a",
"_score": 1, 3
"_source": {
"price": "19.99", 4
"description": "reel deal casino championship edition
(win 98 me nt 2000 xp)",
"id": "b00070ouja",
"title": "reel deal casino championship edition",
"manufacturer": "phantom efx",
"tags": []
}
},
Обратите внимание на следующее.
1. В поле hits.total мы видим, сколько всего результатов было найдено. В данном случае мы имеем 201 соответствие условиям поиска.
2. Поле hits.max_score показывает оценку документа, который лучше всех соответствует запросу. Поскольку запрос диапазона является структурированным и не учитывает релевантность, он работает как фильтр. Он не меняет оценку документа. Все документы имеют оценку 1.
3. Массив hits.hits представляет собой список всех фактических соответствий. По умолчанию Elasticsearch не возвращает 201 результат в один заход. Возвращаются только первые десять записей. Если вы хотите увидеть все результаты, можете это легко сделать с помощью нескольких запросов, которые мы рассмотрим позже.
4. Поле price во всех результатах поиска будет в пределах запрошенного диапазона, то есть 10: ≤ price ≤ 20.
Запрос диапазона с увеличением оценки
По умолчанию запрос диапазона присваивает оценку 1 каждому соответствующему документу. Но допустим, вы используете запрос диапазона вместе с каким-нибудь другим запросом и хотите присвоить более высокую оценку полученным документам, если они удовлетворяют тем или иным условиям. Можно использовать составные запросы, такие как булев, где допустимо совмещать разные типы запросов. Запрос диапазона позволяет установить параметр boost для изменения оценки документа в зависимости от условий других запросов:
GET /amazon_products/products/_search
{
"from": 0,
"size": 10,
"query": {
"range": {
"price": {
"gte": 10,
"lte": 20,
"boost": 2.2
}
}
}
}
Все документы, которые пройдут фильтр, в этом запросе получат оценку 2.2 вместо 1.
Запрос диапазона для дат
Вы можете выполнить запрос диапазона для полей с датами, так как они также имеют естественный порядок. Во время такого запроса можно указать формат отображения данных:
GET /orders/order/_search
{
"query": {
"range" : {
"orderDate" : {
"gte": "01/09/2017",
"lte": "30/09/2017",
"format": "dd/MM/yyyy"
}
}
}
}
Такой запрос отфильтрует все заказы, сделанные в сентябре 2017 года.
Elasticsearch позволяет использовать в запросах даты с указанием или без указания времени. Поддерживается также использование особых условий, включая now для отметки текущего времени. Например, в коде далее запрашиваются данные за последние семь дней до сегодняшнего, а именно данные за 24 × 7 часов до текущего момента с точностью до миллисекунд:
GET /orders/order/_search
{
"query": {
"range" : {
"orderDate" : {
"gte": "now-7d",
"lte": "now"
}
}
}
}
Возможность использовать условия типа now облегчает охват при поиске.

Elasticsearch поддерживает много математических операций с датами. Для дат возможно также использование ключевого слова now. Кроме того, поддерживается добавление или вычитание времени с различными единицами измерения. Вы можете использовать сокращения до одного символа, такие как y (год), M (месяц), w (неделя), d (день), h или H (часы), m (минуты) и s (секунды). Например: now – 1y будет означать выбор времени длительностью один год до текущего момента. Время можно округлять в разных единицах. Например, чтобы округлить интервал до дня, включая оба начальных и конечных промежутка, используйте выражение "gte": "now – 7d/d" или "lte": "now/d". Добавляя /d, вы округлите время до дней.
Запрос диапазона работает в контексте фильтра по умолчанию. Он не вычисляет оценки и всегда присваивает оценку 1 для всех соответствующих документов.
Запрос существования
Иногда полезно получить только те записи, которые имеют не нулевые и не пустые значения в конкретных полях. Например, так выполняется выбор всех полей с заполненным описанием:
GET /amazon_products/products/_search
{
"query": {
"exists": {
"field": "description"
}
}
}
Запрос существования делает из запроса фильтр; другими словами, он работает в контексте фильтра. Его работа схожа с действием запроса диапазона, когда оценки не имеют значения.

Что такое контекст фильтра? Когда запрос выполняется только для фильтрации документов, а именно для решения о включении конкретного документа в результаты, важно пропустить процесс оценки. Elasticsearch может пропускать этот процесс для определенных типов запросов и присваивать универсальную оценку 1 каждому документу, который соответствует критериям фильтрации. Это не только ускоряет выполнение запроса (благодаря пропуску процесса оценки), но и позволяет Elasticsearch кэшировать результаты фильтров. В Elasticsearch результаты фильтрации кэшируются путем обслуживания массивов единиц и нулей.
Term-запрос
Как найти все продукты от конкретного производителя? Мы знаем, что в наших данных поле производителя имеет строковый тип. Название производителя может содержать пробелы. В данный момент нам нужен точный поиск. Например, когда мы ищем victory multimedia, нам не нужны результаты, содержащие только victory или только multimedia. Для выполнения такого поиска мы можем использовать term-запрос, или термин-запрос (term query).
Определяя поле производителя, мы сохраняем его с типом text или keyword. Для точного запроса нам нужно использовать поле типа keyword:
GET /amazon_products/products/_search
{
"query": {
"term": {
"manufacturer.raw": "victory multimedia"
}
}
}
Term-запрос является низкоуровневым в том понимании, что он не выполняет никакого анализа термина. Он также напрямую работает с обратным индексом, который сформирован из указанных полей, в данном случае это поле manufacturer.raw. По умолчанию термин-запрос работает в контексте запроса и, следовательно, вычисляет оценку.
Ответ на запрос выглядит следующим образом (вы видите только его часть):
{
...
"hits": {
"total": 3,
"max_score": 5.965414,
"hits": [
{
"_index": "amazon_products",
"_type": "products",
"_id": "AV5rBfPNNI_2eZGciIHC",
"_score": 5.965414,
...
Как видите, каждому документу дана оценка по умолчанию. Для выполнения термин-запроса в контексте фильтра без оценки его нужно запустить внутри фильтра constant_score.
Теперь этот запрос вернет одинаковые результаты для всех соответствующих документов. Запрос constant_score мы еще рассмотрим более детально далее в этой главе. На текущий момент вы можете считать, что он делает оценивающий запрос неоценивающим. Во всех случаях, когда нам не нужно знать, насколько хорошо документ соответствует запросу, мы можем ускорить работу запроса, используя constant_score с параметром filter. Есть и другие типы составных запросов, которые помогут нам конвертировать разные типы запросов и комбинировать их с другими. Мы подробно рассмотрим их во время изучения сложных составных запросов.
Полнотекстовый поиск
Полнотекстовые запросы могут работать с неструктурированными текстовыми полями. Эти запросы знают о процессе анализа и применяют анализатор к полям до того, как фактически начинать процесс поиска. Сначала проводится подбор корректного анализатора путем проверки определения search_analyzer, а также наличия анализатора, в обоих случаях — на уровне поля. Если анализаторы на уровне поля не выявлены, предпринимается попытка использовать анализатор, определенный на уровне индекса.
Таким образом, полнотекстовые запросы выполняют необходимые процессы анализа полей до осуществления фактических запросов. Их также можно называть высокоуровневыми запросами. Разберемся в структуре выполнения высокоуровневого запроса (рис. 3.3).
Здесь мы можем видеть, как будет выполнен один высокоуровневый запрос для поля названия. Вспомните, что согласно определению нашего индекса тип поля названия — text. Во время индексирования значение поля обрабатывается анализатором. В данном случае был применен стандартный анализатор, следовательно, обратный индекс был разбит на термины, такие как god, heroes, rome и т.д.
Во время запроса (обратите внимание на правую часть рисунка) мы выполняем высокоуровневый запрос match. Более детально о запросе соответствия мы еще поговорим далее в разделе; это один из возможных высокоуровневых запросов. Поисковые термины обрабатываются запросом match и анализируются стандартным анализатором. После его применения отдельные термины далее используются для отдельных запросов на уровне термов.
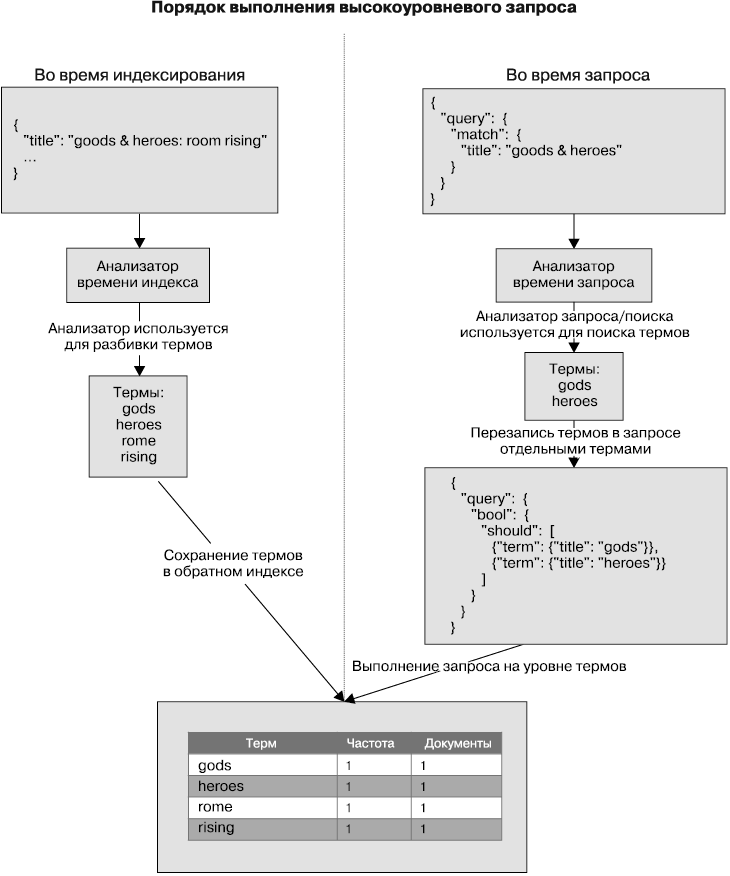
Рис. 3.3
В данном примере результатом будет несколько запросов на уровне термов — по одному на каждый терм после применения анализатора. Исходным поисковым запросом было выражение gods heroes, в результате было получено два терма — gods и heroes, которые используются как отдельные термы со своими запросами. Далее эти два запроса комбинируются с помощью составного запроса bool. Подробнее о составных запросах мы поговорим в следующем разделе.
Далее мы рассмотрим полнотекстовые запросы:
• соответствия;
• соответствия фразы;
• нескольких соответствий.
Запрос соответствия
Запрос соответствия (match query) — это запрос, который по умолчанию применяется в большинстве случаев полнотекстового поиска. Это один из высокоуровневых запросов, который знает об использовании анализатора для исходного поля. Посмотрим, как это работает.
Например, когда вы применяете запрос соответствия для поля типа keyword, он знает о наличии типа keyword у поля и, следовательно, во время запроса поисковые термины не анализируются:
GET /amazon_products/products/_search
{
"query": {
"match": {
"manufacturer.raw": "victory multimedia"
}
}
}
В данном случае запрос соответствия работает так же, как термин-запрос, о котором мы говорили в предыдущем разделе. Он не анализирует элемент victory multimedia как раздельные термины victory и multimedia. Это связано с тем, что мы выполняем запрос в отношении поля keyword, а именно — manufacturer.raw. Фактически в этом конкретном случае запрос соответствия конвертируется в термин-запрос, как видно ниже:
GET /amazon_products/products/_search
{
"query": {
"term": {
"manufacturer.raw": "victory multimedia"
}
}
}
В таком случае термин-запрос возвращает те же оценки, что и запрос соответствия, так как оба выполнены для поля keyword.
Теперь посмотрим, что произойдет, если выполнить запрос соответствия в отношении поля text, что является типичным примером полнотекстового запроса:
GET /amazon_products/products/_search
{
"query": {
"match": {
"manufacturer": "victory multimedia"
}
}
}
Когда мы выполняем запрос соответствия, мы ожидаем от него следующих действий.
1. Искать термины victory multimedia по всем документам в пределах поля производителя.
2. Найти лучшие соответствия, отсортированные по оценке в порядке убывания.
3. Если оба термина найдены рядом и в том же порядке, документ должен получить более высокую оценку, чем другие документы, в которых есть совпадение по обоим терминам в том же порядке, но не рядом друг с другом.
4. Включать в результаты поиска документы, в которых есть либо victory, либо multimedia, но присваивать им более низкую оценку.
Запрос соответствия с параметрами по умолчанию может выполнить все перечисленные шаги и найти лучшие соответствующие документы, а также отсортировать их согласно оценке (от высокой к низкой).
Работа запроса соответствия по умолчанию предусматривает наличие только поисковых терминов. Но вы можете указать для него дополнительные параметры. К стандартным параметрам относятся следующие:
• оператор;
• параметр minimum_should_match;
• параметр fuzziness (нечеткости).
Оператор
По умолчанию, если поисковый термин после работы анализатора разбивается на несколько термов, требуется способ скомбинировать результаты из отдельных терминов. Как вы уже убедились на предыдущем примере, стандартное поведение запроса match состоит в комбинировании результатов с помощью оператора or, то есть один из терминов должен присутствовать в поле документа.
Вы можете изменить оператор на and с помощью следующего запроса:
GET /amazon_products/products/_search
{
"query": {
"match": {
"manufacturer": {
"query": "victory multimedia",
"operator": "and"
}
}
}
}
В таком случае в поле производителя в документе должны присутствовать оба термина: и victory, и multimedia.
minimum_should_match
Мы можем не менять оператор с or на and и хотя бы указать, сколько терминов должно быть найдено в документе для того, чтобы он был включен в результаты поиска. Таким образом вы можете контролировать точность результатов поиска:
GET /amazon_products/products/_search
{
"query": {
"match": {
"manufacturer": {
"query": "victory multimedia",
"minimum_should_match": 2
}
}
}
}
Запрос выше работает схожим образом, как при использовании оператора and, поскольку в нем есть два термина и мы указали, что минимальное количество совпадений — два.
С помощью параметра minimum_should_match мы можем указать минимальное количество совпадений в документе.
Нечеткость
С параметром fuzziness мы можем превратить запрос соответствия в запрос нечеткости. Его работа основана на расстоянии Левенштейна для преобразования одного поискового термина в другой путем выполнения нескольких правок исходного текста. Под правками мы подразумеваем вставки, удаления, замещения или изменения мест символов в оригинальном термине. Параметр fuzziness может иметь одно из следующих значений: 0, 1, 2 или AUTO.
Например, в следующем запросе есть опечатка: victor вместо victory. Используя параметр fuzziness со значением 1, мы все равно найдем все записи касательно victory multimedia:
GET /amazon_products/products/_search
{
"query": {
"match": {
"manufacturer": {
"query": "victor multimedia",
"fuzziness": 1
}
}
}
}
Если мы хотим оставить больше маневров для исправления ошибок, то увеличим значение нечеткости до 2. При таком значении параметра fuzziness возможен поиск даже по запросу victer, поскольку это слово преобразуется в victory двумя исправлениями:
GET /amazon_products/products/_search
{
"query": {
"match": {
"manufacturer": {
"query": "victer multimedia",
"fuzziness": 2
}
}
}
}
Выбор AUTO будет автоматически подбирать числовое значение нечеткости из 0, 1, 2 в зависимости от длины исходного термина. При автоматической настройке термины длиной до двух символов будут иметь допустимую нечеткость 0 (должно быть четкое соответствие), термины от трех до пяти символов будут иметь нечеткость 1, а термины с пятью и более символами — нечеткость, равную 2.
Нечеткость имеет свою цену, так как Elasticsearch обязан создавать дополнительные термы для соответствий. Поддерживаются следующие параметры для контролирования количества термов:
• max_expansions — максимальное количество термов после расширения;
• prefix_lenght — число, например 0, 1, 2 и т.д. Задает размер префикса, помогает отсеять количество слов при поиске.
Запрос соответствия фразы
Запрос соответствия фразы может быть полезен, когда требуется найти сочетание слов, а не отдельные термины в документе.
Например, следующий текст представлен как часть описания к одному из продуктов:
real video saltware aquarium on your desktop!
Нам нужно найти все продукты, в описании которых есть именно такое сочетание слов: real video saltware aquarium. Для получения необходимого результата мы можем использовать запрос match_phrase. Запрос match не сработает, так как он не учитывает сочетание терминов и их близость друг к другу. Такой запрос попросту включит в результаты все документы, в которых встречается какое-либо слово из перечисленных, даже если они не имеют указанного порядка в документе:
GET /amazon_products/products/_search
{
"query": {
"match_phrase": {
"description": {
"query": "real video saltware aquarium"
}
}
}
}
Ответ будет выглядеть следующим образом:
{
...,
"hits": {
"total": 1,
"max_score": 22.338196,
"hits": [
{
"_index": "amazon_products",
"_type": "products",
"_id": "AV5rBfasNI_2eZGciIbg",
"_score": 22.338196,
"_source": {
"price": "19.95",
"description": "real video saltware aquarium on your
desktop!product information see real fish swimming on your
desktop in fullmotion video! you'll find exotic saltwater
fish such as sharks angelfish and more! enjoy the beauty
and serenity of a real aquarium at yourdeskt",
"id": "b00004t2un",
"title": "sales skills 2.0 ages 10+",
"manufacturer": "victory multimedia",
"tags": []
}
}
]
}
}
Запрос match_phrase также поддерживает параметр slop, который позволяет указать целое число: 0, 1, 2, 3 и т.д. slop уменьшает количество слов/терминов, которые могут быть пропущены во время запроса.
Например, при значении slop, равном 1, даже при одном отсутствующем слове из всей фразы документ все равно будет обозначен как соответствующий поиску:
GET /amazon_products/products/_search
{
"query": {
"match_phrase": {
"description": {
"query": "real video aquarium",
"slop": 1
}
}
}
}
Таким образом, slop 1 разрешит пользователю ввести для поиска real video aquarium или real saltware aquarium и все равно найти документ, который содержит полную фразу real video saltware aquarium. Значение slop по умолчанию равно 0.
Запрос нескольких соответствий
Запрос нескольких соответствий представляет собой расширение обычного запроса соответствия. Он позволяет нам запускать запрос match по нескольким полям, а также имеет несколько вариаций для подсчета общей оценки документов.
Вы можете использовать запрос нескольких соответствий с различными параметрами. Мы рассмотрим следующие виды этого запроса:
• запрос по нескольким полям по умолчанию;
• запрос с увеличением оценки одного или нескольких полей.
Запрос по нескольким полям по умолчанию
Мы хотим предоставить своему веб-приложению функционал поиска по продуктам. Когда конечный пользователь ищет какие-либо термины, нам требуется выполнять запросы по обоим полям названия и описания. Это возможно с помощью запроса по нескольким полям.
Следующий запрос найдет все документы, которые имеют слова monitor или aquarium в полях названия или описания:
GET /amazon_products/products/_search
{
"query": {
"multi_match": {
"query": "monitor aquarium",
"fields": ["title", "description"]
}
}
}
Такой запрос уделяет одинаковое внимание обоим полям. Рассмотрим, как повысить оценку одного или нескольких полей.
Увеличение оценки одного или нескольких полей
В веб-приложениях для электронной коммерции нередко бывает так, что пользователь ищет какие-либо товары, используя некоторые ключевые слова. Что, если мы хотим сделать поле названия более важным, чем поле описания? Если одно или несколько ключевых слов совпадет в названии, это будет более релевантный продукт, чем тот, который имеет совпадения только в описании. Можно увеличить оценку документа в тех случаях, если совпадение найдено в определенных полях.
Сделаем поле названия в три раза более важным, чем поле описания. Для этого можно использовать следующий синтаксис:
GET /amazon_products/products/_search
{
"query": {
"multi_match": {
"query": "monitor aquarium",
"fields": ["title^3", "description"]
}
}
}
Запрос нескольких соответствий предлагает больше контроля для комбинирования оценок из разных полей.
В этом разделе мы поговорили о полнотекстовых запросах, известных также как высокоуровневые запросы. Эти запросы находят лучшие соответствующие документы согласно оценке. Высокоуровневые запросы на внутреннем уровне используют некоторые запросы на уровне термов. В следующем разделе вы узнаете, как писать сложные составные запросы.
Написание составных запросов
Запросы этого типа можно использовать при необходимости совмещения одного или нескольких запросов. Некоторые составные запросы конвертируют оценивающие запросы в неоценивающие либо комбинируют несколько оценивающих и неоценивающих запросов. Мы рассмотрим следующие типы составных запросов:
• запрос постоянной оценки;
• булев запрос.
Запрос постоянной оценки
Elasticsearch поддерживает структурированные и полнотекстовые запросы. Первые не нуждаются в механизме оценок, в то время как вторым необходимы оценки для поиска лучшего соответствия среди документов. Запрос постоянной оценки позволяет конвертировать запрос оценки, который обычно работает в контексте запроса, для выполнения в контексте неоценивающего фильтра. Запрос постоянной оценки наверняка займет важное место среди вашего инструментария.
Например, термин-запрос обычно работает в контексте запроса. Это значит, что при выполнении такого запроса Elasticsearch не только фильтрует документы, но и оценивает их:
GET /amazon_products/products/_search
{
"query": {
"term": {
"manufacturer.raw": "victory multimedia"
}
}
}
Обратите внимание на выделенный код. Этот фрагмент фактически и есть термин-запрос. По умолчанию выделенный JSON-элемент query определяет контекст запроса.
Ответ содержит оценку для каждого документа. Рассмотрите следующую часть ответа:
{
...,
"hits": {
"total": 3,
"max_score": 5.966147,
"hits": [
{
"_index": "amazon_products",
"_type": "products",
"_id": "AV5rBfasNI_2eZGciIbg",
"_score": 5.966147,
"_source": {
"price": "19.95",
...
}
Здесь мы намеревались фильтровать документы, следовательно, не было необходимости вычислять оценку релевантности каждого документа.
Оригинальный запрос может быть конвертирован для работы в контексте фильтра, для этого используем следующий составной запрос оценки:
GET /amazon_products/products/_search
{
"query": {
"constant_score": {
"filter": {
"term": {
"manufacturer.raw": "victory multimedia"
}
}
}
}
}
Как видите, мы обернули оригинальный выделенный объект term и его дочерний объект. Таким образом мы присваиваем нейтральную оценку 1 каждому документу по умолчанию. Рассмотрите часть ответа в следующем коде:
{
...,
"hits": {
"total": 3,
"max_score": 1,
"hits": [
{
"_index": "amazon_products",
"_type": "products",
"_id": "AV5rBfasNI_2eZGciIbg",
"_score": 1,
"_source": {
"price": "19.95",
"description": ...
}
...
}
Можно указать параметр boost, который присвоит эту оценку вместо нейтральной:
GET /amazon_products/products/_search
{
"query": {
"constant_score": {
"filter": {
"term": {
"manufacturer.raw": "victory multimedia"
}
},
"boost": 1.2
}
}
}
В чем толк от увеличения оценки каждого документа до 1.2 этим фильтром? Толка нет, если этот запрос используется сам по себе. Но если его комбинировать с другими запросами, применяя, например, запрос bool, увеличенная оценка обретает смысл. Все документы, прошедшие этот фильтр, будут иметь более высокую оценку по сравнению с другими документами, комбинированными с другими запросами.
Булев запрос
Булев запрос в Elasticsearch — ваш швейцарский нож. Он поможет вам с написанием многих видов сложных запросов. И если у вас есть опыт работы с SQL, вы уже знаете, как работают фильтры с операторами AND и OR в условии WHERE. Булев запрос разрешает вам комбинировать несколько оценивающих и неоценивающих запросов.
Сначала рассмотрим, как внедрить простые операторы AND и OR.
Булев запрос имеет следующие разделы:
GET /amazon_products/products/_search
{
"query": {
"bool": {
"must": [...], scoring queries executed in query context
"should": [...], scoring queries executed in query context
"filter": {}, non-scoring queries executed in filter context
"must_not": [...] non-scoring queries executed in filter context
}
}
}
Запросы с условиями must и should выполняются в контексте запроса, кроме тех случаев, когда весь булев запрос включен в контексте фильтра.
Фильтр и запросы must_not всегда выполняются в контексте фильтра. Они всегда будут возвращать нулевую оценку и обеспечивать фильтрацию документов.
Разберемся, как сформировать неоценивающий запрос, который занимается исключительно неструктурированным поиском. Мы рассмотрим, как формулировать следующие типы структурированных поисковых запросов с помощью булева запроса:
• комбинирование условий OR;
• комбинирование условий AND и OR;
• добавление условий NOT.
Комбинирование условий OR
Далее приведен код, позволяющий найти все продукты в ценовом диапазоне от 10 до 13 или (OR) произведенные компанией valuesoft:
GET /amazon_products/products/_search
{
"query": {
"constant_score": {
"filter": {
"bool": {
"should": [
{
"range": {
"price": {
"gte": 10,
"lte": 13
}
}
},
{
"term": {
"manufacturer.raw": {
"value": "valuesoft"
}
}
}
]
}
}
}
}
}
Поскольку мы применяем условие OR, мы поместили его под строкой should. Поскольку нам не нужны оценки, мы обернули наш запрос bool в запрос постоянной оценки.
Комбинирование условий AND и OR
Следующий код позволяет найти все продукты в ценовом диапазоне от 10 до 13 и (AND) произведенные компанией Valuesoft или Pinnacle:
GET /amazon_products/products/_search
{
"query": {
"constant_score": {
"filter": {
"bool": {
"must": [
{
"range": {
"price": {
"gte": 10,
"lte": 30
}
}
}
],
"should": [
{
"term": {
"manufacturer.raw": {
"value": "valuesoft"
}
}
},
{
"term": {
"manufacturer.raw": {
"value": "pinnacle"
}
}
}
]
}
}
}
}
}
Обратите внимание, что все условия, для которых необходим союз OR, размещены внутри should. А условия, относящиеся к AND, находятся в элементе must. Тем не менее вы можете поместить все условия, которым необходим оператор AND, в элемент filter.
Добавление условий NOT
Мы можем добавить оператор NOT, например, для того, чтобы отфильтровать определенные элементы, используя условие must_not в фильтре bool.
Найдем все продукты стоимостью от 10 до 20, которые не произведены компанией encore. Для этого выполним следующий запрос:
GET /amazon_products/products/_search
{
"query": {
"constant_score": {
"filter": {
"bool": {
"must": [
{
"range": {
"price": {
"gte": 10,
"lte": 20
}
}
}
],
"must_not": [
{
"term": {
"manufacturer.raw": "encore"
}
}
]
}
}
}
}
}
Запрос bool с элементом must_not полезен для отрицания любого запроса. Для применения фильтра NOT к запросу он должен быть обернут в булев запрос в строке must_not, как показано ниже:
GET /amazon_products/products/_search
{
"query": {
"bool": {
"must_not": {
... оригинальный запрос для выполнения операции NOT...
}
}
}
}
Обратите внимание, что не требуется оборачивать весь запрос в запрос постоянной оценки, если мы используем только must_not для отрицания запроса. Запрос must_not всегда выполняется в контексте фильтра.
Итак, мы рассмотрели различные типы сложных составных запросов. Elasticsearch поддерживает еще больше таких запросов, включая следующие:
• запрос Dis Max;
• запрос оценки функции;
• запрос увеличения оценки;
• запрос индексов.
В данной книге мы не будем рассматривать эти виды запросов. При необходимости вы можете сами изучить их, ведь у вас уже есть базовое понимание составных запросов, используемых в Elasticsearch. Для этого обратитесь к документации Elasticsearch.
Резюме
В этой главе мы еще подробнее рассмотрели возможности поиска Elasticsearch. Мы разобрались, в чем значение анализаторов и из чего они состоят. Поговорили о том, как использовать некоторые из встроенных анализаторов Elasticsearch, как создавать свои собственные нестандартные анализаторы.
На текущий момент вы изучили два основных типа запросов: запросы на уровне термов и полнотекстовые запросы. Кроме того, научились создавать более сложные, составные запросы.
В этой главе вы получили основные сведения, на которые можете опираться при работе с запросами данных в Elasticsearch. Есть много других типов запросов, поддерживаемых Elasticsearch, но мы рассмотрели лишь самые важные из них. Благодаря этим знаниям вы уже сейчас можете начать работу, а разобраться в других типах запросов вам поможет документация Elasticsearch.
В главе 4 рассказывается о возможностях аналитики, предоставляемых данной программой. Мы изучим основной компонент Elastic Stack и Elasticsearch, а также другие полезные инструменты.
Расстояние Левенштейна между двумя строками в теории информации и компьютерной лингвистике — это минимальное количество операций вставки одного символа, удаления одного символа и замены одного символа на другой, необходимых для превращения одной строки в другую («Википедия»). — Здесь и далее примеч. ред.

