2. Начало работы с Elasticsearch
В первой главе мы поговорили о том, зачем изучать Elastic Stack, и рассмотрели примеры его использования.
В этой главе мы начнем наше путешествие по миру Elastic Stack с его самого главного компонента — Elasticsearch. Это движок для поиска и аналитики внутри Elastic Stack. Мы разберем основные понятия Elasticsearch на практических примерах, по пути узнав все необходимое о запросах, фильтрации и поиске.
В данной главе мы рассмотрим следующие темы.
• Работа с пользовательским интерфейсом (UI) Kibana Console.
• Основные понятия Elasticsearch.
• CRUD-операции.
• Создание индексов и контролирование разметки.
• Обзор REST API.
Пользовательский интерфейс Kibana Console
Прежде чем вы начнете писать первые запросы для работы с Elasticsearch, вам следует ознакомиться с важным инструментом: Kibana Console. Он пригодится при работе с REST API для любых возможных операций Elasticsearch. Kibana Console представляет собой удобный редактор, который поддерживает функцию автозавершения и форматирования запросов во время их написания.

Что такое REST API? REST означает Representational State Transfer. Это архитектурный стиль для взаимодействия систем друг с другом. REST развивался вместе с протоколом HTTP, и почти все системы, основанные на REST, используют HTTP как свой протокол. HTTP поддерживает различные методы: GET, POST, PUT, DELETE, HEAD и др. Например, GET предназначен для получения или поиска чего-либо, POST используется для создания нового ресурса, PUT может применяться для создания или обновления существующего ресурса, а DELETE — для безвозвратного удаления.
В главе 1 мы успешно установили Kibana и запустили пользовательский интерфейс по ссылке http://localhost:5601. Как уже говорилось, Kibana — это окно в Elastic Stack. Утилита не только позволяет визуализировать данные, но и содержит инструменты для разработчиков, такие как Console (Консоль). Пользовательский интерфейс консоли представлен на рис. 2.1.
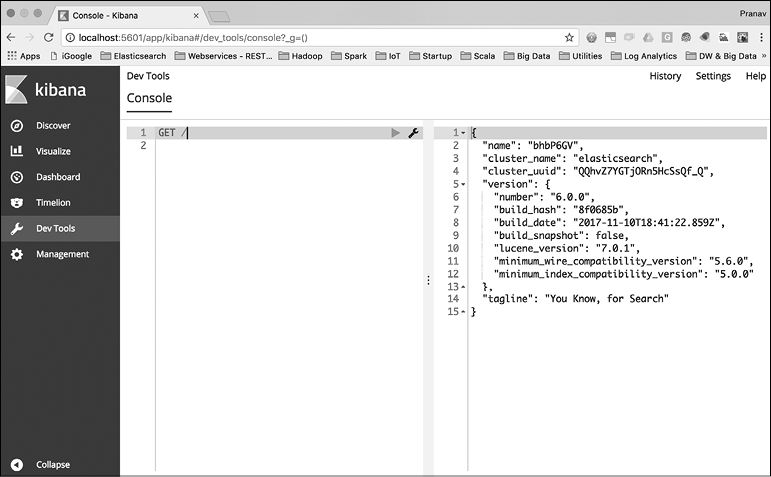
Рис. 2.1
После запуска Kibana нужно выбрать ссылку Dev Tools (Инструменты для разработчиков) на навигационной панели слева. Консоль разделена на две части: поле редактора и поле результатов. Можно вводить команды REST API, и после щелчка на зеленом треугольнике запрос будет отправлен в Elasticsearch (или кластер).
Здесь мы просто отправили запрос GET /. Это аналог команды curl, которую мы отправляли в Elasticsearch при проверке установки. Как видите, команда, отправленная через консоль, уже намного короче. Нам не нужно набирать http, хост и порт узла Elasticsearch, а именно http://localhost:9200. Но, как уже было сказано ранее, суть не только в том, что можно пропускать хост и порт при каждом запросе. Как только мы начинаем набирать текст в редакторе консоли, мы получаем список возможных команд (рис. 2.2).
Теперь, когда у нас есть правильный инструмент для генерирования и отправки запросов в Elasticsearch, перейдем к изучению базовых понятий.
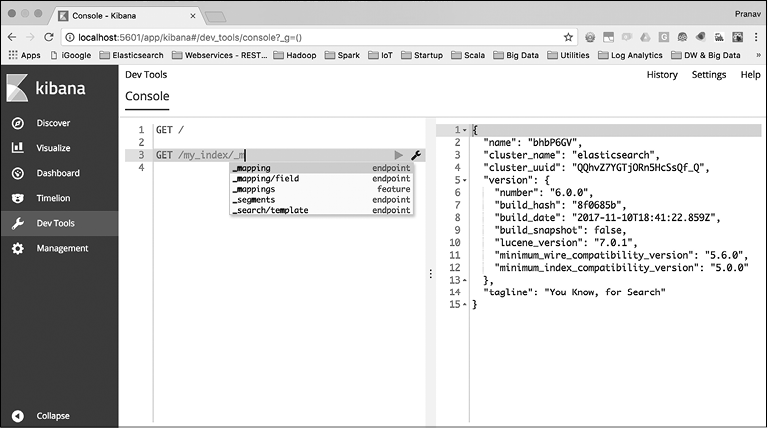
Рис. 2.2
Основные понятия Elasticsearch
Чтобы работать с реляционными базами данных, нужно разбираться в таких понятиях, как строки, столбцы, таблицы и схемы. Elasticsearch и другие хранилища, ориентированные на документы, работают по иному принципу. Система Elasticsearch имеет четкую ориентацию на документы. Лучше всего для нее подходят JSON-документы. Они организованы с помощью различных типов и индексов. Далее мы рассмотрим ключевые понятия Elasticsearch:
• индекс;
• тип;
• документ;
• кластер;
• узел;
• шарды и копии;
• разметку и типы данных;
• обратный индекс.
Начнем с такого примера:
PUT /catalog/product/1
{
"sku": "SP000001",
"title": "Elasticsearch for Hadoop",
"description": "Elasticsearch for Hadoop",
"author": "Vishal Shukla",
"ISBN": "1785288997",
"price": 26.99
}
Скопируем этот пример в редактор консоли Kibana UI и выполним его. Таким образом мы проиндексируем документ, представляющий собой продукт в каталоге продуктов системы. Все примеры, приведенные для консоли Kibana UI, можно легко конвертировать в команды curl и выполнить в командной строке. Ниже показана версия curl для предыдущей команды консоли Kibana UI:
curl -XPUT http://localhost:9200/catalog/product/1 -d '{ "sku": "SP000001",
"title": "Elasticsearch for Hadoop", "description": "Elasticsearch for
Hadoop", "author": "Vishal Shukla", "ISBN": "1785288997", "price": 26.99}'
Мы используем этот пример для знакомства с индексами, типами и документами.
В предыдущем фрагменте кода первая строка содержит команды PUT /catalog/product/1 и далее документ JSON.
PUT — HTTP-метод, используемый для индексирования нового документа. В нашем примере catalog — это имя индекса, product — имя типа, согласно которому документ будет индексироваться, а 1 — идентификатор, присвоенный документу после индексирования.
Индекс
Индекс — это контейнер, который в Elasticsearch хранит документы одного типа и управляет ими. Индекс может содержать документы одного типа, как показано на рис. 2.3.
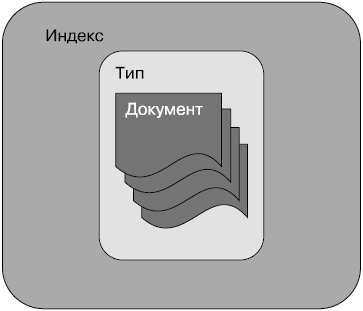
Рис. 2.3
Индекс — это логический контейнер типов. Одни параметры указываются на уровне индексов, другие — на уровне типов. Более наглядно эти различия мы рассмотрим в последующих разделах этой главы.
Индексы в Elasticsearch приблизительно аналогичны по структуре базе данных в реляционных базах данных. Продолжая аналогию, тип в Elasticsearch соответствует таблице, а документ — записи в ней. Но имейте в виду, что такую аналогию можно проводить сугубо для упрощения понимания. Отличие состоит в том, что в структуре реляционных баз данных почти всегда содержится несколько таблиц, а индекс может содержать только один тип.

До версии Elasticsearch 6.0 один индекс мог содержать несколько типов. Но начиная с версии 6.0 в пределах индекса допускается хранить только один тип. Если у вас уже есть индекс с несколькими типами, созданный в версии до 6.0, и вы обновляетесь до версии 6.0, вы сможете и далее пользоваться своими старыми индексами. Но не получится создать индекс, содержащий более одного типа, в Elasticsearch 6.0 и выше.
Тип
В нашем примере с каталогом продуктов проиндексированный документ был типа «продукт». Каждый документ, сохраненный с этим типом, соответствует одному продукту. Один и тот же индекс не может иметь другие типы, такие как «клиенты», «заказы», «позиции заказа» и т.д. Типы помогают логически группировать или организовывать однотипные документы по индексам.
Обычно документы с наиболее распространенным набором полей группируются под одним типом. Elasticsearch не требует наличия структуры, позволяя вам хранить любые документы JSON с любым набором полей под одним типом. На практике следует избегать смешивания разных сведений в одном типе, таких как «клиенты» и «продукты». Имеет смысл хранить их в разных типах и с разными индексами.
Документ
Как уже было сказано, JSON-документы лучше всего подходят для использования в Elasticsearch. Документ состоит из нескольких полей и является базовой единицей информации, хранимой в Elasticsearch. Например, у вас может быть документ, соответствующий одному продукту, одному клиенту или одной позиции заказа.
На рис. 2.3 показано, что документы хранятся внутри индексов и типов.
Документы содержат несколько полей. В документах JSON каждое поле имеет определенный тип. В примере с каталогом продуктов, который мы видели ранее, были поля sku, title, description, price и др. Каждое поле и его значение можно увидеть как пару «ключ — значение» в документе, где ключ — это имя поля, а значение — значение поля. Имя поля можно сопоставить с именем столбца в реляционных базах данных. Значение поля может восприниматься как значение столбца для выбранной строки, то есть значение выбранной ячейки в таблице.
В дополнение к пользовательским полям в документе Elasticsearch хранятся следующие внутренние метаполя:
• _id — уникальный идентификатор документа внутри типа по аналогии с первичным ключом в таблице базы данных. Он может генерироваться автоматически или выбираться пользователем;
• _type — это поле содержит тип документа;
• _index — хранит имя индекса документа.
Узел
Elasticsearch — распределенная система. Она состоит из множества процессов, запущенных на разных устройствах в сети и взаимодействующих с другими процессами. В главе 1 мы скачали, установили и запустили Elasticsearch. Таким образом мы запустили так называемый единичный узел кластера Elasticsearch.
Узел Elasticsearch — это единичный сервер системы, который может быть частью большого кластера узлов. Он участвует в индексировании, поиске и выполнении других операций, поддерживаемых Elasticsearch. Каждому узлу Elasticsearch в момент запуска присваиваются уникальный идентификатор и имя. Можно также назначить узлу статическое имя с помощью параметра node.name в конфигурационном файле Elasticsearch config/elasticsearch.yml.

Каждому узлу Elasticsearch соответствует основной конфигурационный файл, который находится в подкаталоге настроек. Формат файла YML (полное название — YAML Ain’t Markup Language). Вы можете использовать этот файл для изменения значений по умолчанию, таких как имя узла, порты, имя кластера.
На базовом уровне узел соответствует одному запущенному процессу Elasticsearch. Он отвечает за управление соответствующей ему частью данных.
Кластер
Кластер содержит один или несколько индексов и отвечает за выполнение таких операций, как поиск, индексирование и агрегации. Кластер формируется одним или несколькими узлами. Любой узел Elasticsearch всегда является частью кластера, даже если это кластер единичного узла. По умолчанию каждый узел пытается присоединиться к кластеру с именем Elasticsearch. Если вы запускаете несколько узлов внутри одной сети без изменения параметра cluster.name в файле config/elasticsearch.yml, они автоматически объединяются в кластер.

Рекомендуется изменять параметр cluster.name в конфигурационном файле Elasticsearch, чтобы избежать подключения к другому кластеру в той же сети. Согласно настройкам по умолчанию узел соединяется с существующим кластером внутри сети, и ваш локальный узел может попробовать соединиться с другим узлом для формирования кластера. Это может происходить на компьютерах разработчиков и другом оборудовании в том случае, если узлы находятся в одной сети.
Кластер состоит из нескольких узлов, каждый из которых отвечает за хранение своей части данных и управление ею. Один кластер может хранить один или несколько индексов. Индекс логически группирует разные типы документов.
Шарды и копии
Для начала разберемся, что такое кластер. Один индекс содержит документы одного или нескольких типов. Шарды помогают распределить индекс по кластеру. Они распределяют документы из одного индекса по различным узлам. Объем информации, который может храниться в одном узле, ограничивается дисковым пространством, оперативной памятью и вычислительными возможностями этого узла. Шарды помогают распределять данные одного индекса по всему кластеру и тем самым оптимизировать ресурсы кластера.
Процесс разделения данных по шардам называется шардированием. Это неотъемлемая часть Elasticsearch, необходимая для масштабируемой и параллельной работы с выполнением оптимизации:
• дискового пространства по разным узлам кластера;
• вычислительной мощности по разным узлам кластера.
По умолчанию каждый индекс настроен так, чтобы иметь пять шардов в Elasticsearch. В момент создания индекса можно обозначить количество шардов, на которые будут разделены данные вашего индекса. После того как индекс создан, количество шардов невозможно изменить.
На рис. 2.4 показано, как пять шардов могут быть распределены по кластеру из трех узлов.
На рисунке шарды обозначены символами от Р1 до Р5. Каждый шард содержит примерно 1/5 всех данных, хранимых в индексе. Когда происходит запрос по этому индексу, Elasticsearch проверяет все шарды и объединяет результат.
Теперь представим, что один из узлов (узел 1) вышел из строя. Вместе с ним мы теряем часть данных, которая хранилась в шардах P1 и P2 (рис. 2.5).
Распределенные системы наподобие Elasticsearch приспособлены к работе даже при неполадках оборудования. Для этого предусмотрены реплики шардов, или копии. Каждый шард индекса может быть настроен таким образом, чтобы у него было некоторое количество копий или не было ни одной. Реплики шардов — это дополнительные копии оригинального или первичного шарда для обеспечения высокого уровня доступности данных.
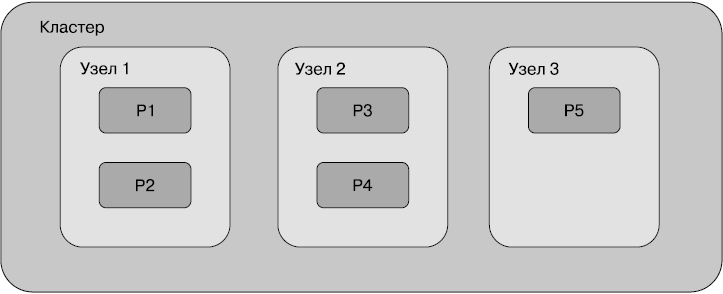
Рис. 2.4
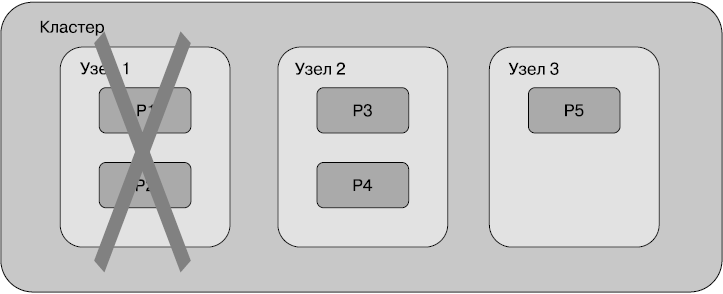
Рис. 2.5
На рис. 2.6 показаны пять первичных шардов и по одной копии на каждый шард.
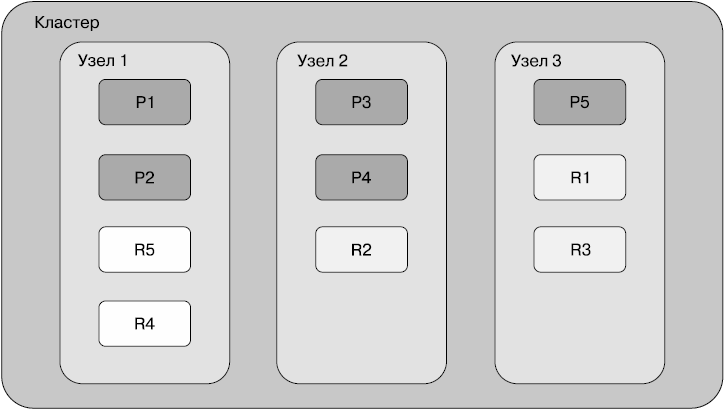
Рис. 2.6
Первичные шарды указаны темно-серым цветом, копии — светлым. При наличии копий, если узел 1 выходит из строя, все равно будут доступны все шарды в узлах 2 и 3. Реплики могут становиться первичными шардами в тех случаях, когда соответствующие им шарды недоступны.
Копии шардов не только обеспечивают высокий уровень доступности данных, но и полезны для распределения запросов по копиям. Операции чтения данных, такие как поиск, запросы и агрегирование, могут выполняться и по копиям. Elasticsearch распределяет выполнение запросов по узлам кластера, в котором находятся копии.
Подводя итоги, можно сказать, что узлы соединяются для формирования кластера. Кластеры обеспечивают физический уровень для создания индексов. Индекс может содержать один или несколько типов, а каждый тип — миллионы или миллиарды документов. Индексы разделяются на шарды, которые являются фрагментами данных внутри индекса. Шарды распределяются по узлам кластера. Реплики — копии первичных шардов, обеспечивающие высокий уровнень доступности данных при неполадках оборудования.
Разметка и типы данных
Elasticsearch — неструктурированная система, благодаря чему в ней можно хранить документы с любым количеством полей и типов полей. В реальности данные никогда не бывают абсолютно бесструктурными. Всегда есть некий набор полей, общий для всех документов этого типа. Фактически типы внутри индексов должны создаваться на основе общих полей. Обычно один тип документов внутри индекса содержит несколько общих полей.
Реляционные базы данных имеют четкую структуру. На момент создания таблицы необходимо разметить ее структуру именами столбцов и типами данных для каждого столбца. Невозможно вставить запись с новым столбцом или другим типом данных во время работы с таблицей.
Важно понимать, какие типы данных поддерживает Elasticsearch.
Типы данных
Elasticsearch поддерживает широкий набор типов данных для различных сценариев хранения текстовых данных, чисел, булевых, бинарных объектов, массивов, объектов, вложенных типов, геоточек, геоформ и многих других специализированных типов данных, например адресов IPv4 и IPv6.
В документе каждое поле имеет ассоциированный тип данных. Ниже приведен полный список типов данных, поддерживаемых Elasticsearch.
Основные типы данных
Рассмотрим основные типы данных в Elasticsearch.
• Строковые:
• text — полезен для полнотекстового поиска по полям, которые содержат длинные текстовые значения. Эти поля анализируются до индексирования для поддержки полнотекстового поиска;
• keyword — позволяет выполнять анализ строковых полей. Поля такого типа поддерживают сортировку, фильтрацию и агрегацию.
• Числовые:
• byte, short, integer и long — целые числа со знаком с 8-, 16-, 32- и 64-битной точностью соответственно;
• float и double — числа с плавающей точкой по стандарту IEEE 754 с 32-битной одиночной точностью и 64-битной двойной точностью;
• half-float — число с плавающей точкой по стандарту IEEE 754 с 16-битной половинной точностью;
• scaled_float — число с плавающей точкой (float), но хранится как long c помощью умножения на коэффициент масштабирования.
• Даты: date. Используется для представления полей даты. Если формат не указан, Elasticsearch пытается проанализировать поле даты, используя формат yyyy-MM-dd'T'HH:mm:ssz. Поддерживает хранение точных меток времени вплоть до миллисекунды.
• Булевы типы: boolean. Известный тип данных для всех языков программирования. Используется для представления логических полей (true или false).
• Бинарный тип данных: binary. Делает возможным хранение произвольных бинарных значений после выполнения кодировки Base64.
• Диапазон: integer_range, float_range, long_range, double_range и data_range. Обозначает диапазоны целых чисел, плавающих чисел, длинных чисел и т.д.

scaled_float — очень полезный тип данных для хранения таких значений, как цены, которые всегда имеют ограниченное количество знаков после десятичной точки. Цена может указываться с коэффициентом масштабирования 100, следовательно, ценник $10.98 может храниться как 1098 центов и обрабатываться как целое число. Тип scaled_float гораздо эффективнее для хранения, чем другие типы, поскольку целые числа лучше сжимаются.
Комплексные типы данных
В Elasticsearch поддерживаются следующие комплексные типы данных.
• Массив — определяет массивы одного типа. Например, массивы строковых данных, массивы целых чисел и т.д. В массивах не разрешается смешивать типы данных.
• Объект — допускает использование внутренних объектов в документах JSON.
• Вложенный тип данных — каждый объект в массиве индексируется как новый вложенный документ. Поскольку объекты обрабатываются внутри как отдельные документы, следует использовать специальный тип запроса для запроса вложенных документов.
Другие типы данных
Elasticsearch также поддерживает следующие типы данных.
• Геоточка — делает возможным хранение геоточек по широте и долготе. Например, тип данных «геоточка» полезен для таких запросов, как поиск по всем банкоматам в радиусе 2 км от указанной точки.
• Геоформа — используется для хранения геометрических форм, таких как полигоны, карты и пр. Тип данных «геоформа» позволяет выполнять запросы по поиску всех предметов определенной формы.
• Тип данных IP — используется для хранения адресов IPv4 и IPv6.
Разметка
Для понимания принципа работы разметки добавим в каталог еще один товар:
PUT /catalog/product/2
{
"sku": "SP000002",
"title": "Google Pixel Phone 32GB - 5 inch display",
"description": "Google Pixel Phone 32GB - 5 inch display (Factory
Unlocked US Version)",
"price": 400.00,
"resolution": "1440 x 2560 pixels",
"os": "Android 7.1"
}
Скопируем данный пример в редактор консоли Kibana UI и выполним его.
Как видно, у товара есть много разных полей. Тем не менее некоторые поля являются общими для всех товаров.
Вспомните, что, в отличие от реляционных баз данных, в Elasticsearch нам не нужно назначать поля, которые будут частью каждого документа. Фактически нам даже не нужно создавать индекс с именем каталога. После того как первый документ типа «продукт» проиндексирован в каталоге индексов, Elasticsearch выполняет следующие действия:
• создает индекс с именем каталога;
• обозначает разметку для типа продукта.
Создание индекса с именем каталога
В первую очередь нужно создать индекс, поскольку он еще не существует. Индекс создается с количеством шардов, заданным по умолчанию. В Elasticsearch существует такое понятие, как шаблон индексов, который позволяет построить шаблон для любого индекса. Иногда индекс формируется на ходу, например, когда добавление первого документа автоматически приводит к созданию нового индекса. В таких случаях для него используется соответствующий шаблон. Таким образом, новые индексы создаются контролируемо, то есть с необходимым количеством шардов и разметкой типов.
Индексы можно создавать и заблаговременно. В Elasticsearch есть отдельный API для индексов (https://www.elastic.co/guide/en/elasticsearch/reference/current/indices.html), который работает с операциями уровня индекса. К ним относятся создание, удаление, получение индекса, создание разметки и др.
Установка разметки для типа продукта
Второй шаг включает в себя определение разметки (mappings) для типов продуктов. Это действие выполняется потому, что каталога типов не существует, пока не проиндексирован первый документ. Проведем аналогию с типами в реляционных базах данных. До того как добавить столбец, нужно создать таблицу. Когда создается таблица в РСУБД (реляционная система управления базами данных), мы обозначаем поля (столбцы) и их типы в выражении CREATE TABLE.
Когда первый документ индексируется в пределах типа, который еще не существует, Elasticsearch пытается обозначить типы данных для всех полей. Эта функция называется динамической разметкой типов. По умолчанию разметка типов в Elasticsearch включена.
Чтобы увидеть разметку типов товаров в индексе каталогов, выполните следующую команду в консоли Kibana UI:
GET /catalog/_mapping/product
Это пример Get Mapping API (https://www.elastic.co/guide/en/elasticsearch/reference/current/indices-get-mapping.html). Вы можете запросить разметку определенного типа, все типы в пределах индекса или нескольких индексов.
Вывод должен выглядеть следующим образом:
{
"catalog": {
"mappings": {
"product": {
"properties": {
"ISBN": {
"type": "text"
}
},
"author": {
"type": "text"
}
},
"description": {
"type": "text"
}
},
"price": {
"type": "float"
},
"sku": {
"type": "text"
},
"title": {
"type": "text"
}
}
}
На верхнем уровне JSON-ответа каталог представляет собой индекс, для которого была запрошена разметка. Дочерний продукт разметки означает, что эта разметка — для типа продуктов.
В результате мы получим немного другую разметку типов, чем показано в предыдущем коде. Как видите, тип данных float задан только для цены, остальные поля размечены как текстовые. В реальности каждое поле типа данных text размечается следующим образом:
"field_name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
Как вы можете заметить, каждое поле, установленное строкой, получило тип данных text. Текстовый тип данных делает возможным полнотекстовый поиск по полю. То же поле хранится как мультиполе и как keyword. Это позволяет выполнять не только полнотекстовый поиск, но и анализ данных (сортировку, агрегацию и фильтрацию) по одному и тому же полю.
Обратный индекс
Обратный индекс — это основная структура данных в Elasticsearch и любой другой системе, которая поддерживает полнотекстовый поиск. Обратный индекс похож на глоссарий в конце книги. Он размечает термы (определения, термины), имеющиеся в документах.
Например, вы можете построить обратный индекс из следующих строк (табл. 2.1).
Таблица 2.1
| Идентификатор документа | Документ |
| 1 | Завтра воскресенье |
| 2 | Воскресенье — последний день недели |
| 3 | Выбор за вами |
По результатам индексирования трех документов Elasticsearch построит структуру данных, которая будет выглядеть так, как показано в табл. 2.2. Такая структура данных называется обратным индексом.
Таблица 2.2
| Терм (определение) | Частота | Документы (постинги) |
| вами | 1 | 3 |
| воскресенье | 2 | 1, 2 |
| выбор | 1 | 3 |
| день | 1 | 2 |
| завтра | 1 | 1 |
| неделя | 1 | 2 |
| последний | 1 | 2 |
Обратите внимание на следующее.
• Документы разбиваются на определения без учета пунктуации и прописных букв.
• Термы сортируются по алфавиту.
• Столбец «Частота» показывает, как часто данное определение встречается во всем наборе документов.
• Третий столбец показывает, в каких документах было найдено определение. Кроме того, там могут содержаться точные места нахождения (офсеты внутри документа).
При поиске определений содержащие их документы находятся довольно быстро. Если пользователь ищет определение «воскресенье», поиск по столбцу определений будет быстрым благодаря тому, что все они отсортированы в индексе. Даже если есть миллион определений, их легко и быстро найти, когда они отсортированы.
Представим сценарий, когда пользователь ищет два слова, например «последнее воскресенье». Обратный индекс может быть настроен на поиск отдельно слов «последнее» и «воскресенье». Документ 2 содержит оба определения, следовательно, это более подходящее соответствие, чем документ 1, содержащий только одно определение. Подобным образом легко узнать частоту появления определения внутри индекса.
Обратные индексы — это структурные блоки, из которых состоит быстрый поиск. Конечно, Elasticsearch использует и другие нововведения, помимо обычного обратного индекса, что обеспечивает хорошие возможности для поиска и аналитики.
По умолчанию Elasticsearch строит обратный индекс для всех полей документа, указывая на документ, в котором присутствует конкретное поле.
Операции CRUD
В этом разделе мы поговорим о том, как выполнять операции CRUD — основные операции для любого хранилища данных. В системе Elasticsearch операции CRUD нацелены на документы. Для их выполнения она предоставляет отличный REST API.
Для понимания принципа работы операций CRUD мы рассмотрим следующие API. Все они относятся к API документов:
• Index API;
• Get API;
• Update API;
• Delete API.
Index API
В терминологии Elasticsearch добавление (или создание) документа в тип внутри индекса называется операцией индексирования. Чаще всего это добавление документа в индекс путем обработки всех полей внутри документа и постройки обратного индекса.
Есть два способа индексирования документа:
• индексирование с предоставлением идентификатора;
• индексирование без предоставления идентификатора.
Индексирование документа с предоставлением идентификатора
Мы уже встречались с таким видом операции индексирования. Пользователь может предоставить идентификатор документа, используя метод PUT.
Формат такого запроса следующий: PUT /<index>/<type>/<id> — с документом JSON в теле запроса:
PUT /catalog/product/1
{
"sku": "SP000001",
"title": "Elasticsearch for Hadoop",
"description": "Elasticsearch for Hadoop",
"author": "Vishal Shukla",
"ISBN": "1785288997",
"price": 26.99
}
Индексирование документа без предоставления идентификатора
Если нет желания контролировать генерирование идентификаторов для документов, можно использовать метод POST.
Формат такого запроса следующий: POST /<index>/<type> — с документом JSON в теле запроса:
POST /catalog/product
{
"sku": "SP000003",
"title": "Mastering Elasticsearch",
"description": "Mastering Elasticsearch",
"author": "Bharvi Dixit",
"price": 54.99
}
В данном случае идентификатор будет сгенерирован Elasticsearch. Он находится в выделенной хеш-строке:
{
"_index": "catalog",
"_type": "product",
"_id": "AVrASKqgaBGmnAMj1SBe",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": true
}

По соглашениям REST POST используется для создания нового ресурса, а PUT — для обновления существующего ресурса. В нашем случае использование PUT означает следующее: «Я знаю, какой идентификатор хочу присвоить, следовательно, я указываю его в процессе индексирования документа».
Get API
Get API полезен для получения документа в тех случаях, когда уже известен его идентификатор. По сути, это операция GET по основному ключу:
GET /catalog/product/AVrASKqgaBGmnAMj1SBe
Формат запроса следующий: GET /<index>/<type>/<id>. Вывод должен быть таким:
{
"_index": "catalog",
"_type": "product",
"_id": "AVrASKqgaBGmnAMj1SBe",
"_version": 1,
"found": true,
"_source": {
"sku": "SP000003",
"title": "Mastering Elasticsearch",
"description": "Mastering Elasticsearch",
"author": "Bharvi Dixit",
"price": 54.99
}
}
Update API
Update API используется для обновления существующего идентификатора документа.
Формат такого запроса следующий: POST <index>/<type>/<id>/_update — с документом JSON в теле запроса:
POST /catalog/product/1/_update
{
"doc": {
"price": "28.99"
}
}
Свойства, указанные в элементе doc, объединились в существующий документ. Стоимость предыдущей версии документа с идентификатором 1 составляла 26,99. Эта операция просто обновляет цену и оставляет остальные поля документа без изменений. Данный тип обновления означает, что doc используется как часть документа для слияния с существующим документом. Поддерживаются и другие типы обновления.
Вывод по запросу обновления выглядит следующим образом:
{
"_index": "catalog",
"_type": "product",
"_id": "1",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
}
}
Elasticsearch хранит версию каждого документа. При каждом обновлении документа номер версии увеличивается.
Продемонстрированное выше частичное обновление возможно только в том случае, если документ существовал изначально. Если документа с заданным идентификатором не существует, Elasticsearch выведет ошибку и сообщение о том, что документ отсутствует. Разберемся, как выполнить операцию upsert, используя Update API. Термин upsert в широком понимании означает update (обновить) или insert (вставить), то есть обновить документ, если он существует, или вставить новый документ — если нет.
Параметр doc_as_upsert проверяет, существует ли документ с предоставленным идентификатором и объединяет предоставленный элемент doc с существующим документом. Если документ с таким идентификатором не существует, будет вставлен новый документ с необходимым содержимым.
В следующем примере мы используем doc_as_upsert для слияния с документом (идентификатор 3) или вставки нового документа, если он не существует:
POST /catalog/product/3/_update
{
"doc": {
"author": "Albert Paro",
"title": "Elasticsearch 5.0 Cookbook",
"description": "Elasticsearch 5.0 Cookbook Third Edition",
"price": "54.99"
},
"doc_as_upsert": true
}
Мы можем обновить значение поля, базируясь на текущем значении этого или другого поля в документе. В следующем коде используется встроенный скрипт, увеличивающий стоимость определенного продукта на два:
POST /catalog/product/AVrASKqgaBGmnAMj1SBe/_update
{
"script": {
"inline": "ctx._source.price += params.increment",
"lang": "painless",
"params": {
"increment": 2
}
}
}
Поддержка скриптов позволяет прочитать текущее значение, увеличить его на какую-либо величину и сохранить в пределах одной операции. Этот встроенный скрипт создан с помощью собственного скриптового языка Elasticsearch. Синтаксическая конструкция для увеличения существующей переменной такая же, как в большинстве языков программирования.
Delete API
Delete API используется для удаления документа по идентификатору:
DELETE /catalog/product/AVrASKqgaBGmnAMj1SBe
Вывод операции удаления выглядит следующим образом:
{
"found": true,
"_index": "catalog",
"_type": "product",
"_id": "AVrASKqgaBGmnAMj1SBe",
"_version": 4,
"result": "deleted",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
}
}
Именно так Elasticsearch выполняет базовые операции CRUD. Имейте в виду, что Elasticsearch сохраняет данные в особой структуре, а именно в обратном индексе, используя возможности Apache Lucene. В реляционных базах данных используются B-древа, которые лучше подходят для типовых CRUD-операций.
Создание индексов и контролирование разметки
В предыдущем разделе мы рассмотрели, как выполнять операции CRUD в Elasticsearch. В процессе мы также узнали, как индексирование первого документа по несуществующему индексу приводит к созданию нового индекса и разметки типа.
Чаще всего разработчики предпочитают не полагаться на автоматику, а самостоятельно контролировать, как создаются индексы и разметка. Сейчас мы узнаем, как взять контроль над этим процессом на себя, и рассмотрим следующие операции:
• создание индекса;
• создание разметки;
• обновление разметки.
Создание индекса
Вы можете создать индекс и указать количество шардов и копий:
PUT /catalog
{
"settings": {
"index": {
"number_of_shards": 5,
"number_of_replicas": 2
}
}
}
Можно также указать разметку для типа во время создания индекса. Следующая команда создаст индекс с названием catalog, с пятью шардами и двумя копиями. Дополнительно мы также укажем тип с названием my_type с двумя полями, один типа text и второй — типа keyword:
PUT /catalog
{
"settings": {
"index": {
"number_of_shards": 5,
"number_of_replicas": 2
}
},
"mappings": {
"my_type": {
"properties": {
"f1": {
"type": "text"
},
"f2": {
"type": "keyword"
}
}
}
}
}
Создание разметки типов в существующем индексе
Тип может быть добавлен внутри индекса после его создания. Можно указать разметку типа следующим образом:
PUT /catalog/_mapping/category
{
"properties": {
"name": {
"type": "text"
}
}
}
Эта команда создает в существующем каталоге индекса тип под названием category с одним полем текстового типа. Добавим несколько документов после создания нового типа:
POST /catalog/category
{
"name": "books"
}
POST /catalog/category
{
"name": "phones"
}
После того как документы были индексированы, решено было добавить поля для хранения описания категории. Elasticsearch назначит тип автоматически, основываясь на том, что именно мы вставляем в новое поле. Для предположения типа поля рассматривается лишь первое значение:
POST /catalog/category
{
"name": "music",
"description": "On-demand streaming music"
}
Когда новая категория проиндексирована с полями, назначается тип данных на основании его значения в исходном документе. Взглянем на разметку после индексирования документа:
{
"catalog": {
"mappings": {
"category": {
"properties": {
"description": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"name": {
"type": "text"
}
}
}
}
}
}
Для описания поля был установлен тип данных text, задано поле под названием keyword одноименного типа. Это значит, что существует два поля: description и description.keyword. Поле description анализируется во время индексирования, в то время как description.keyword не анализируется и хранится без какой-либо оценки. По умолчанию поля индексируются в первый раз с двойными кавычками и хранятся одновременно как типы text и keyword.
Если нужно контролировать типы, следует указать разметку для поля до того, как проиндексируется первый документ, содержащий это поле. Тип поля не может быть изменен после того, как один или несколько документов были проиндексированы в пределах этого поля. Взглянем, как обновлять разметку для добавления поля необходимого типа.
Обновление разметки
Разметка для новых полей может быть добавлена после того, как создан тип. Разметка может быть обновлена с помощью API разметки PUT. Добавим поле code с типом keyword без анализа:
PUT /catalog/_mapping/category
{
"properties": {
"code": {
"type": "keyword"
}
}
}
Эта разметка объединена в существующую разметку типа category. После слияния она выглядит следующим образом:
{
"catalog": {
"mappings": {
"category": {
"properties": {
"code": {
"type": "keyword"
},
"description": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"name": {
"type": "text"
}
}
}
}
}
}
Любые последующие документы, которые проиндексированы с полем code, получают соответствующий тип данных:
POST /catalog/category
{
"name": "sports",
"code": "C004",
"description": "Sports equipment"
}
Таким образом мы можем контролировать процесс создания индексов и назначения разметки типов, а также добавлять поля после создания типа.
Обзор REST API
Итак, мы разобрались, как выполнять базовые операции CRUD. Elasticsearch поддерживает широкий спектр типов операций. Одни операции выполняются с документами: создание, чтение, обновление, удаление и т.д. Другие обеспечивают поиск и агрегацию. Могут быть и операции уровня кластера, например мониторинг. В целом в Elasticsearch работают следующие виды API:
• API документов;
• API поиска;
• API агрегации;
• API индексов;
• API кластеров;
• CAT API.
В справочной документации Elasticsearch описаны все эти API, и в книге мы не будем углубляться в данную тему. Мы лишь рассмотрим несколько примеров их реального использования, а именно, как можно задействовать API для получения оптимальных результатов в Elasticsearch и других компонентах Elastic Stack.
В следующем разделе мы ознакомимся с общими правилами API, которые распространяются на все REST API.
Общие правила API
У всех REST API в Elasticsearch есть общие черты. Они работают схожим образом почти во всех API. Мы рассмотрим следующие функции:
• форматирование вывода JSON;
• управление несколькими индексами.
Форматирование вывода JSON
По умолчанию ответы на все запросы не форматируются. Вы получаете неотформатированную строку JSON:
curl -XGET http://localhost:9200/catalog/product/1
Вывод не отформатирован:
{"_index":"catalog","_type":"product","_id":"1","_version":3,
"found":true,"_source":{
"sku": "SP000001",
"title": "Elasticsearch for Hadoop",
"description": "Elasticsearch for Hadoop",
"author": "Vishal Shukla",
"ISBN": "1785288997",
"price": 26.99
}}
Для форматирования вывода нужно ввести pretty=true:
curl -XGET http://localhost:9200/catalog/product/1?pretty=true
{
"_index" : "catalog",
"_type" : "product",
"_id" : "1",
"_version" : 3,
"found" : true,
"_source" : {
"sku" : "SP000001",
"title" : "Elasticsearch for Hadoop",
"description" : "Elasticsearch for Hadoop",
"author" : "Vishal Shukla",
"ISBN" : "1785288997",
"price" : 26.99
}
}
Надо отметить, что в консоли Kibana UI все выводы по умолчанию отформатированы.
Управление несколькими индексами
Можно выполнять такие операции, как поиск и агрегация, для нескольких индексов в одном запросе. Для поиска по конкретным индексам в запросе используются разные URL-ссылки. Разберемся, как можно применять URL для поиска в разных индексах и типах внутри них. Мы рассмотрим следующие сценарии работы с несколькими индексами внутри кластера:
• поиск по всем документам во всех индексах;
• поиск по всем документам в одном индексе;
• поиск по всем документам в одном типе одного индекса;
• поиск по всем документам в нескольких индексах;
• поиск по всем документам конкретного типа во всех индексах.
Следующий запрос соответствует поиску по всем документам. В данном случае реальное количество документов в выводе запроса будет ограничено десятью. По умолчанию ограничение size для результата равно 10, если в запросе не выбрано иное:
GET /_search
В выводе мы получим все документы из всех индексов данного кластера. Ответ будет похож на следующий, но здесь он сокращен, чтобы избежать бесполезного повторения документов:
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 16,
"successful": 16,
</span>"failed": 0
},
"hits": {
"total": 4,
"max_score": 1,
"hits": [
{
"_index": ".kibana",
"_type": "doc",
"_id": "config:6.0.0",
"_score": 1,
"_source": {
"type": "config",
"config": {
"buildNum": 16070
}
}
},
...
...
]
}
}
Очевидно, что это не самая полезная операция. Но мы рассмотрим ее для понимания результатов поиска:
• took — время, за которое ответил кластер, в миллисекундах;
• timed_out: false — строка означает, что операция прошла успешно, без превышения времени ожидания;
• _shards — показывает, сколько всего шардов на весь кластер было опрошено, успешно или нет;
• hits — количество соответствующих документов. Это суммарное количество документов по всем индексам, которое отвечает критериям поиска. Объект max_score показывает количество лучших соответствий поиску. Его дочерний объект hits выводит фактический перечень документов.

Список hits для массива данных не содержит все до единого соответствующие документы. Было бы неэффективно выводить абсолютно все, что отвечает критериям поиска, поскольку результаты могут исчисляться миллионами или миллиардами. Elasticsearch сокращает вывод согласно ограничению size, которое можно изменить по своему усмотрению, воспользовавшись параметром GET /_search?size=100. Значение по умолчанию равно 10, следовательно, исходный массив совпадений поиска будет содержать 10 записей.
Поиск по всем документам в одном индексе
С помощью следующей команды можно выполнять поиск по всем документам, но только в пределах индекса каталога:
GET /catalog/_search
Возможно также добавить фильтрацию по типу, а не только по индексу, например:
GET /catalog/product/_search
Поиск по всем документам в нескольких индексах
Выполнить поиск по всем документам в пределах индекса каталога и индекса под названием my_index можно с помощью такой команды:
GET /catalog,my_index/_search
Поиск по всем документам конкретного типа во всех индексах
Используя следующую команду, можно искать по всем индексам кластера, но только документы типа product:
GET /_all/product/_search
Эта функция может быть полезной, если у вас несколько индексов и каждый из них содержит один и тот же тип. Такой запрос поможет найти данные нужного типа из всех индексов.
Резюме
В этой главе мы познакомились с консолью Kibana UI, командой curl и узнали, как в Elasticsearch реализованы REST API. Мы также рассмотрели базовые понятия Elasticsearch. Мы выполняли стандартные операции CRUD, необходимые для работы с любым хранилищем данных. Кроме того, детально рассмотрели такие операции, как создание индексов и разметки. Завершили главу обзором REST API в Elasticsearch, а также ознакомились с общими правилами, принятыми в большинстве API.
В следующей главе мы разберем, какие возможности поиска предоставляет Elasticsearch, и узнаем, как получить от поискового движка максимальную пользу.

