25. Конвейеры обработки данных
Автор — Дэн Дэннисон
Под редакцией Тима Харви
В этой главе рассматриваются сложности, с которыми вам придется столкнуться при управлении сложными конвейерами обработки данных. В ней рассказывается, когда нужно использовать циклические конвейеры, которые запускаются очень редко, а когда — непрерывные, которые никогда не останавливаются. Поговорим также о том, какие прерывания могут приводить к заметным операционным проблемам. Свежий взгляд на модель лидера — последователя позволяет представить ее как более надежную и качественно масштабируемую альтернативу циклическим конвейерам для обработки больших данных.
Происхождение шаблона проектирования «Конвейер»
Классический подход к обработке данных заключается в том, чтобы написать программу, которая считывает данные, преобразует их в желаемую форму и выводит новые данные. Обычно такая программа должна работать под контролем циклической программы планирования наподобие cron.
Такой шаблон проектирования называется конвейером обработки данных. Конвейерами можно считать сопрограммы [Conway, 1963], коммуникационные файлы DTSS [Bull, 1980], конвейеры UNIX [McIlroy, 1986] ETL, но внимание к ним возросло с появлением больших данных, или «наборов данных настолько больших и сложных, что традиционные приложения для обработки данных для них не подходят».
Основной эффект, который большие данные оказывают на шаблон простого конвейера
Программы, которые выполняют периодические или продолжительные преобразования больших данных, обычно называют простыми однофазными конвейерами.
Учитывая масштаб и сложность обработки, связанные с большими данными, программы обычно организуют в цепочки, где выходные данные одной программы становятся входными данными для следующей. Такую компоновку можно обосновывать по-разному, но, как правило, она разрабатывается для простоты рассмотрения системы и не предназначена для повышения операционной эффективности. Программы, организованные таким образом, называются мультифазными конвейерами, поскольку каждая программа в цепочке действует как отдельный этап обработки данных.
Количество программ, объединенных в серию, — это показатель, который известен как глубина конвейера. Неглубокий конвейер может иметь только одну программу, его глубина будет равна единице. Глубокий же конвейер может иметь глубину, равную десяткам или сотням.
Сложности, связанные с шаблоном циклического конвейера
Циклические конвейеры обычно стабильны, когда имеют достаточное количество работников для указанного объема данных и спрос на вычислительную работу не выходит за рамки их возможностей. Вдобавок неустойчивости наподобие узких мест можно избежать, когда количество связанных работ и относительная полоса пропускания между задачами остаются постоянными.
Циклические конвейеры полезны и удобны, и в компании Google их задействуют довольно регулярно. Они написаны с помощью фреймворков вроде MapReduce [Dean, 2004], Flume [Chambers, 2010] и др.
Однако коллективный опыт SR-инженеров показал, что модель циклических конвейеров довольно нестабильна. Мы обнаружили, что, когда для такого конвейера задаются параметры, такие как периодичность, прием разбиения данных и др., производительность поначалу не снижается. Однако естественный рост и изменения неизбежно приводят к напряжению в системе, и появляются проблемы, например истечение дедлайна для задач, истощение ресурсов и зависшая обработка фрагментов данных, которые влекут за собой соответствующую операционную нагрузку.
Проблемы, вызванные неравномерным распределением работы
Основным прорывом модели больших данных было широкое распространение «массово параллельных» [Moler, 1986] алгоритмов, позволяющих разбить большую нагрузку на фрагменты такого размера, которые могут уместиться на отдельных машинах. Иногда эти фрагменты требовали неодинакового объема ресурсов, и далеко не всегда сразу можно было понять, почему некоторые фрагменты требуют большего их количества. Например, при загрузке, фрагментированной по клиентам, фрагменты данных для одних клиентов могут быть гораздо крупнее, чем для других. Поскольку клиент является неделимым объектом, общее время работы равно времени работы самого крупного клиента.
Проблема «висящих фрагментов» может привести к тому, что ресурсы будут распределяться на основе разницы между машинами в кластере или отводиться для заданий с избытком. Она возникает из-за трудностей, связанных с операциями в реальном времени для потоков наподобие сортировки данных. Типичное поведение клиентского кода заключается в том, чтобы подождать, пока не завершатся все вычисления, и только потом переходить на следующий этап конвейера, в основном потому, что может быть использована сортировка, для выполнения которой потребуются все данные. Это может значительно задержать работу конвейера, поскольку все задачи не будут завершены до тех пор, пока не завершится самая медленная из них, что продиктовано используемой технологией разбиения на фрагменты.
Если эта проблема обнаружена инженерами или инфраструктурой наблюдения за кластером, реакция на нее может еще сильнее ухудшить ситуацию. Например, ответ по умолчанию на эту проблему мгновенно завершит задачу и позволит ей перезапуститься, поскольку блокировка может оказаться результатом влияния недетерминированных факторов. Но поскольку реализация конвейера по умолчанию не предполагает наличия контрольных точек, работа для всех фрагментов будет возобновлена, что приведет к потере времени, циклов процессора и человеческих усилий, приложенных на предыдущем цикле.
Недостатки циклических конвейеров в распределенных средах
Циклические конвейеры, работающие с большими данными, широко используются в Google, поэтому наше решение по управлению кластерами включает в себя альтернативный механизм планирования для таких конвейеров. Этот механизм необходим, поскольку, в отличие от непрерывных конвейеров, циклические обычно запускают пакетные задачи с низким приоритетом. Назначения с низким приоритетом работают хорошо, так как в этом случае пакетная работа не будет чувствительной к задержкам настолько, насколько чувствительны веб-сервисы. В дополнение к этому, для того чтобы контролировать затраты путем максимизации нагрузки машин, Borg (система управления кластерами Google [Verma, 2015]) дает указание доступным машинам выполнять пакетную работу. Такой приоритет может вызвать увеличение задержки при запуске, поэтому задачи конвейера, запускаясь, могут испытывать постоянные задержки.
Задачи, вызванные с помощью этого механизма, имеют несколько естественных ограничений, из-за чего начинают вести себя по-разному. Например, на задачи, выполнение которых запланировано в промежутках между выполнением задач пользовательских веб-сервисов, могут влиять доступность ресурсов с малой задержкой, цена и стабильность доступа к ресурсам. Стоимость выполнения обратно пропорциональна запрошенной задержке запуска и прямо пропорциональна количеству потребленных ресурсов. Несмотря на то что пакетное планирование на практике может работать гладко, избыточное использование пакетного планировщика (см. главу 24) подвергает задачи риску откачки (см. [Verma, 2015, раздел 2.5]), когда нагрузка кластера высока из-за того, что пользователям не хватает пакетных ресурсов. В свете риска появления компромиссов успешный запуск циклического конвейера представляет собой тонкий баланс между высокой стоимостью ресурсов и риском откачки.
Задержки продолжительностью до нескольких часов могут оказаться приемлемыми для конвейеров, которые запускаются раз в день. Однако по мере увеличения частоты запланированных запусков минимальное время между выполнениями может быстро достичь минимального среднего времени ожидания. Тогда следует установить нижнюю границу задержки, которую может позволить циклический конвейер. Интервал выполнения задач ниже этой границы приводит к нежелательному поведению, а не помогает продвинуться в выполнении задачи. Конкретный тип сбоя зависит от применяемой политики пакетного планирования. Например, каждый новый запуск может накладываться на другие в планировщике кластера, поскольку предыдущий запуск еще не завершен. Что еще хуже, выполняющийся в данный момент и практически завершенный запуск может быть прерван в момент, когда должна запускаться следующая задача.
На рис. 25.1 показана точка, в которой пересекаются стремящаяся вниз линия интервала простоя и запланированная задержка. В этом сценарии интервал выполнения менее 40 минут для этой примерно 20-минутной работы может привести к появлению параллелизма и, соответственно, к нежелательным последствиям.
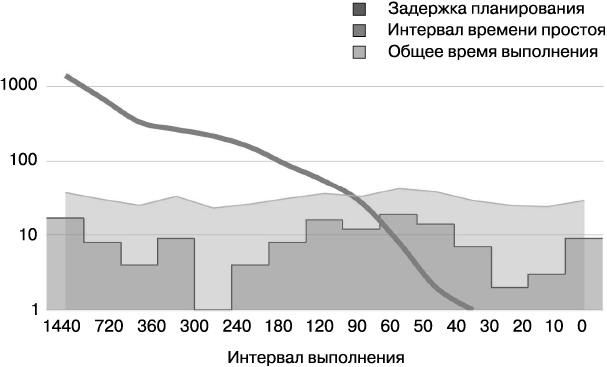
Рис. 25.1. Интервал запуска циклического конвейера и время простоя (логарифмическая шкала)
Для решения этой проблемы нужно зарезервировать достаточную производительность сервера, чтобы иметь возможность выполнять работу. Однако получение ресурсов в разделяемой распределенной среде зависит от предложения и спроса. Ожидается, что команды разработчиков будут отказываться проходить через процесс получения ресурсов, когда ресурсы должны будут оказываться в общем пуле и становиться совместными. Таким образом, нужно разграничить ресурсы для потокового планирования и ресурсы, необходимые для производственной системы, чтобы рационализировать затраты на их получение.
Наблюдение за проблемами в циклических конвейерах
Для конвейеров, довольно долго выполняющих свою работу, наличие поступающей в режиме реального времени информации о показателях производительности среды выполнения может оказаться таким же важным (если не важнее), как и знание общих показателей. Это происходит потому, что данные в реальном времени важны для предоставления операционной поддержки, которая включает в себя и реагирование на чрезвычайные ситуации. На практике стандартная модель наблюдения включает в себя сбор данных по всем показателям во время выполнения задач и отправку этих данных только по завершении работы. Если ни одна задача не даст сбой во время выполнения, статистики мы не получим.
У непрерывных конвейеров нет таких проблем, поскольку их задачи выполняются постоянно и их телеметрия спроектирована таким образом, чтобы показатели в реальном времени были доступны. Циклические конвейеры не должны иметь характерных проблем с наблюдением.
Проблемы «шумной толпы»
В дополнение к вызовам, создаваемым выполнением и наблюдением, существует проблема «шумной толпы», характерная для распределенных систем, которая также рассматривается в главе 24. Возьмем довольно большой циклический конвейер, в каждом цикле которого тысячи модулей могут начать действовать одновременно. Если их количество слишком велико, так как неверно сконфигурировано или обусловлено некорректной логикой выполнения повторных попыток, то серверы, на которых они работают, будут перегружены, как и лежащие в их основе разделяемые сервисы кластеров и любая использованная сетевая инфраструктура.
Еще сильнее ухудшает эту ситуацию то, что, если логика выполнения повторов не реализована, проблемы с корректностью могут привести к тому, что при сбоях задача не будет выполнена повторно. Если логика выполнения повторных попыток прослеживается, но реализована примитивно или плохо, повторные попытки могут ухудшить проблему.
Вмешательство человека также способно повлиять на этот сценарий. Инженеры с небольшим опытом управления конвейерами, как правило, усугубляют проблему, добавляя в конвейер большее количество модулей, когда задача не выполняется за желаемый промежуток времени.
Независимо от источника проблемы «шумной толпы», для инфраструктуры кластера и SR-инженеров, отвечающих за расположенные в нем различные сервисы, нет ничего хуже, чем 10 000 задач конвейера, работающих некорректно.
Интерференция нагрузки
Иногда проблема «шумной толпы» обнаруживается не сама по себе. Может возникнуть связанная с ней проблема, которую мы называем «интерференцией нагрузки» (Moire load pattern). Она проявляется в тех случаях, когда два или более конвейера работают одновременно и последовательности выполняемых ими операций случайно накладываются друг на друга, приводя к потреблению одних и тех же разделяемых ресурсов. Эта проблема может возникать даже в непрерывно действующих конвейерах, однако там она менее характерна, поскольку нагрузка поступает более равномерно.
Интерференция нагрузки больше всего проявляется в сценариях, где конвейеры задействуют общие ресурсы. Например, на рис. 25.2 показан уровень использования ресурсов тремя циклическими конвейерами. На рис. 25.3, который представляет собой вариант отображения данных предыдущей диаграммы с наложением (суммированием) значений, пиковое воздействие, за которым последует подъем по тревоге дежурной смены, произойдет при достижении суммарной нагрузки 1,2 миллиона.
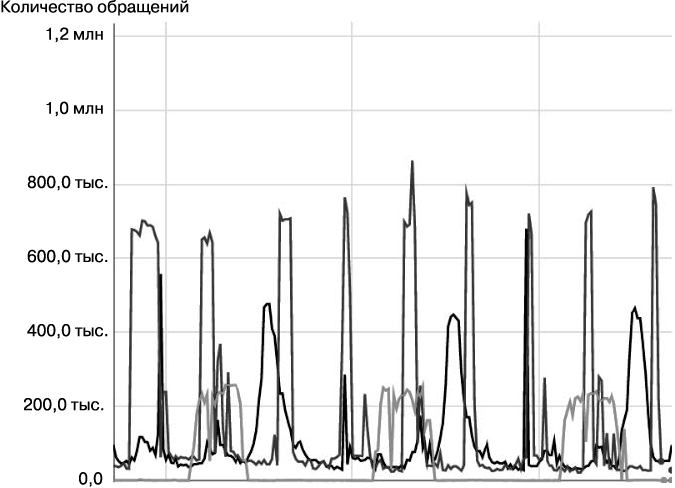
Рис. 25.2. Интерференция нагрузки в инфраструктуре с независимыми ресурсами
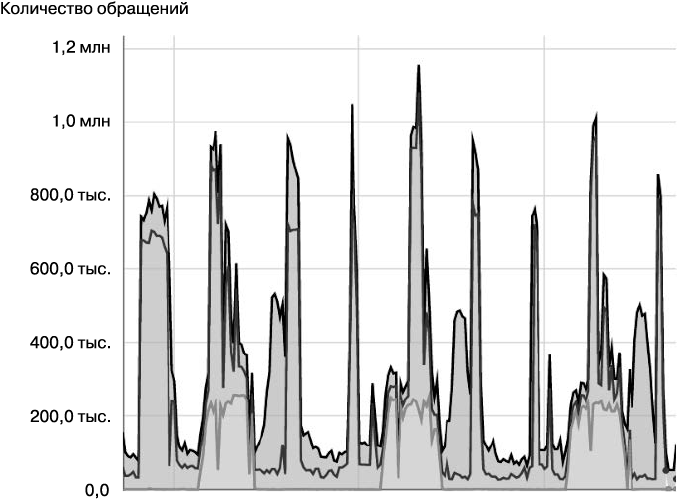
Рис. 25.3. Интерференция нагрузки в инфраструктуре с разделяемыми ресурсами
Знакомство с Google Workflow
Когда по умолчанию одноразовый пакетный конвейер перегружен бизнес-запросами, требующими непрерывно поступающих обновленных результатов, команда разработчиков конвейера обычно рассматривает либо возможность рефакторинга оригинального проекта для удовлетворения текущих потребностей, либо переход на модель непрерывного конвейера.
К несчастью, бизнес-запросы обычно появляются в самое неудобное время для выполнения рефакторинга системы конвейера, переходящего в реализацию продолжительной системы обработки. Новые и более крупные клиенты, которые столкнулись с необходимостью масштабирования, обычно также хотят присоединения новой функциональности и надеются, что их требования будут выполнены четко в оговоренные сроки. Ожидая такого вызова, важно уточнить некоторые детали в начале проектирования системы, в том числе информацию о предлагаемом конвейере обработки данных. Убедитесь, что вы определили траекторию ожидаемого роста, спрос на модификации проекта, ожидаемые дополнительные ресурсы и ожидаемые требования к задержке обработки данных.
Столкнувшись с этими потребностями, компания Google в 2003 году разработала систему Workflow, которая позволила масштабировать продолжительную обработку данных. Workflow использует шаблон «Лидер — последователь» (иногда называют работником), характерный для распределенных систем [Shao, 2000], а также шаблон системного преобладания. Эта комбинация позволяет создавать крупномасштабные транзакционные конвейеры, гарантируя корректность благодаря семантике exactly-once («строго однократная доставка»).
Workflow как шаблон «Модель — представление — контроллер»
Из-за способа работы шаблона системного преобладания (System Prevalence) можно считать Workflow эквивалентом шаблона «Модель — представление — контроллер» для распределенных систем, хорошо известного разработчикам интерфейсов. Этот шаблон проектирования разделяет заданное приложение на три связанные друг с другом части, чтобы отделить внутреннюю реализацию информации от способов ее представления или получения от пользователя (рис. 25.4).
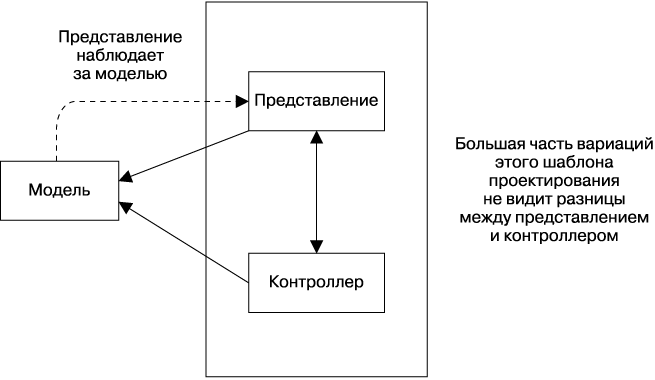
Рис. 25.4. Шаблон «Модель — представление — контроллер» применяется при проектировании пользовательских интерфейсов
Адаптируя этот шаблон для Workflow, можно сказать, что модель находится на сервере, который называется мастером задач. Он использует шаблон системного преобладания, чтобы удерживать в памяти состояние всех задач для быстрого получения доступа к ним, а синхронные изменения журналов при этом отправляет на диск.
Представление — это работники, которые постоянно обновляют состояние системы транзакционно с помощью мастера в соответствии со своим положением как подкомпонентов конвейера. Несмотря на то что все данные конвейера могут храниться в мастере задач, наилучшая производительность обычно достигается, когда в нем хранятся только указатели на работу, а сами входные и выходные данные располагаются в файловой системе или в другом хранилище. В соответствии с этой аналогией, работники совсем не имеют состояния и могут быть в любой момент удалены.
Контроллер можно опционально добавить как третий компонент системы для эффективного обеспечения влияющих на конвейер второстепенных действий системы, таких как масштабирование конвейера во время работы, получение снимков, управление состоянием рабочего цикла, откат состояния конвейера или даже реализация глобальных ограничений для непрерывности бизнеса. Этот шаблон проектирования показан на рис. 25.5.

Рис. 25.5. Шаблон проектирования «Модель — представление — контроллер», адаптированный для Google Workflow
Этапы выполнения в Workflow
Внутри Workflow можно увеличить глубину конвейера на любое значение, разбив выполняющиеся задачи на группы, хранимые в мастере задач. Каждая группа задач определяет работу, соответствующую этапу конвейера, который может выполнять произвольные операции для какого-то фрагмента данных. Так можно довольно эффективно выполнять сравнение, перетасовку, сортировку, разбиение, объединение или любую другую операцию.
С этапом обычно связан некий тип работников. Одновременно могут существовать несколько экземпляров заданного типа работников, и они способны планировать свою деятельность самостоятельно в том смысле, что могут искать разные типы работ и выбирать, что именно будут делать.
Работники используют элементы работы с предыдущих этапов и создают элементы выходных данных. Выходные данные могут быть итоговыми, а могут стать входными данными для другого этапа обработки.
Гарантии корректности Workflow
Сохранять все подробности состояния конвейера внутри мастера задач непрактично, поскольку он ограничен размером оперативной памяти. Однако в этом случае имеется гарантия двойной корректности, так как мастер хранит коллекцию указателей на данные, именованные уникальным образом, и у каждого элемента работы есть уникальный объект аренды. Работники получают работу с помощью объекта аренды и могут отправлять ее только для тех задач, для которых имеют корректный объект аренды.
Для того чтобы избежать ситуации, когда «осиротевший» работник продолжает трудиться над элементом, уничтожая тем самым результаты действующего работника, каждый выходной файл, открытый работником, должен иметь уникальное имя. Таким образом, даже «осиротевшие» работники могут продолжать выполнять запись независимо от мастера до тех пор, пока не попытаются завершить транзакцию. Сделать это они не смогут, поскольку данный элемент работы арендует другой работник. Кроме того, «осиротевшие» работники не могут уничтожить работу, выполненную действующим работником, поскольку схема уникальных имен файла гарантирует, что каждый работник выполняет запись в отдельный файл. Так реализуется двойная гарантия корректности: выходные файлы всегда уникальны, а состояние конвейера всегда корректно благодаря задачам с арендой.
Если двойной гарантии корректности вам недостаточно, Workflow позволяет присваивать каждой задаче свой номер версии. Если обновляется задача или изменяется аренда, каждая операция получает новую задачу, заменяющую предыдущую, и ей присваивается новый идентификатор. Поскольку все конфигурации Workflow хранятся внутри мастера задач в том же виде, что и сами элементы работы, то для фиксации выполненной работы работник должен владеть активной арендой и сослаться на идентификатор конфигурации, использованной для получения результата. Если во время работы над задачей конфигурация изменилась, все работники этого типа не смогут выполнить фиксацию, несмотря на то что владеют действующими арендами. Поэтому вся работа, выполняемая после смены конфигурации, связана с новой конфигурацией, что определяется работой, сбрасываемой работниками, которым «повезло» обладать устаревшими арендами.
Эти меры предоставляют гарантию тройной корректности: конфигурация, владение арендой и уникальность файловых имен. Однако в некоторых случаях даже этого может оказаться недостаточно. Например, что, если изменился сетевой адрес мастера задач и его по этому адресу заменил другой мастер? А если из-за повреждения памяти изменился IP-адрес или номер порта, что привело к появлению другого мастера задач? Еще чаще встречается ситуация, когда кто-то неверно сконфигурировал своего мастера задач, добавив балансировщик нагрузки для множества независимых мастеров задач.
Workflow встраивает токен сервера — уникальный идентификатор для конкретного мастера задач — в метаданные каждой задачи, чтобы предотвратить ситуации, когда чужой или неверно сконфигурированный мастер задач портит конвейер. Клиент и сервер проверяют этот токен для каждой операции, что позволяет избежать очень трудноуловимых ошибок конфигурации, и все операции работают гладко до того, как произойдет столкновение модификаторов задач.
Итак, перечислим четыре гарантии корректности для Workflow.
• Результат труда работников с помощью конфигурационных задач создает барьеры, на которых основывается работа.
• Фиксация выполненной работы требует наличия у работника аренды, действительной в данный момент.
• Работники дают выходным файлам уникальные имена.
• Клиент и сервер проверяют правильность мастера задач путем проверки токена сервера в каждой операции.
В этот момент вы можете захотеть отказаться от специализированного мастера задач и использовать Spanner [Corbett, 2012] или другую базу данных. Однако Workflow особенный, поскольку каждая задача уникальна и неизменяема. Эти свойства предотвращают множество потенциальных трудноуловимых проблем, связанных с распределением работы в больших масштабах. Например, аренда, полученная работником, является частью самой задачи, что требует создания новой задачи даже при изменения аренды. Если база данных используется напрямую и журналы ее транзакций выступают в роли журнала регистрации, то каждая операция чтения должна быть частью долгоиграющей транзакции. Такая конфигурация практически наверняка реализуема, но ужасно неэффективна.
Гарантируем непрерывность бизнеса
Конвейеры, работающие с большими данными, должны продолжать действовать, несмотря на все виды сбоев, включая возникшие из-за перерезанного кабеля, погодных катаклизмов и каскадного отключения питания. Такие сбои могут отключить целые дата-центры. Вдобавок конвейеры, которые не пользуются шаблоном системного преобладания для получения гарантий того, что задача будет выполнена, зачастую отключены и находятся в неопределенном состоянии. Подобный недостаток архитектуры приводит к тому, что нельзя гарантировать непрерывность работы, и приходится удваивать усилия для восстановления конвейеров и данных, а это обходится недешево.
Workflow окончательно решает эту проблему для конвейеров непрерывной обработки. Для достижения глобальной устойчивости мастер задач сохраняет журналы в Spanner, используя повсеместно доступную и чрезвычайно устойчивую файловую систему с низкой полосой пропускания. Чтобы определить мастер задач, который может выполнять операции записи, каждый мастер задач использует распределенный сервис блокировки, который называется Chubby [Burrows, 2006], для выбора программы, выполняющей запись, а затем результат сохраняет в Spanner. Наконец, клиенты выполняют поиск текущего мастера задач с помощью внутренних сервисов именования.
Поскольку Spanner не может обеспечить работу системы с высокой пропускной способностью, глобально распределенные Workflows используют два или больше локальных Workflows, работающих в разных кластерах, в дополнение к ссылочным задачам, хранящимся в глобальном Workflow. По мере того как конвейер потребляет элементы работы (задачи), эквивалентные справочные задачи внедряются в глобальный Workflow с помощью бинарного файла, имеющего метку «Этап 1» (рис. 25.6). По мере выполнения задач справочные задачи транзакционно удаляются из глобального Workflow, как показано на этапе n. Если задачи не могут быть удалены из глобального Workflow, локальный Workflow заблокирует их до тех пор, пока глобальный Workflow не станет доступным, что гарантирует корректность транзакций.
Для того чтобы автоматизировать переход, вспомогательный бинарный файл, помеченный как «Этап 1» (см. рис. 25.6), работает в каждом локальном Workflow. В противном случае локальный Workflow не изменяется, как это описывается в блоке «Выполнение работы» на схеме. Этот вспомогательный бинарный файл с точки зрения MVC действует как контроллер, отвечает за создание справочных задач, а также за обновление специальной задачи, содержащей контрольные сигналы и расположенной внутри глобального Workflow. Если задача, содержащая контрольные сигналы, не обновляется по окончании тайм-аута, удаленный вспомогательный бинарный файл Workflow захватит выполняемую работу, что задокументировано справочными задачами, и работа конвейера, на которую не повлияла среда, продолжится.
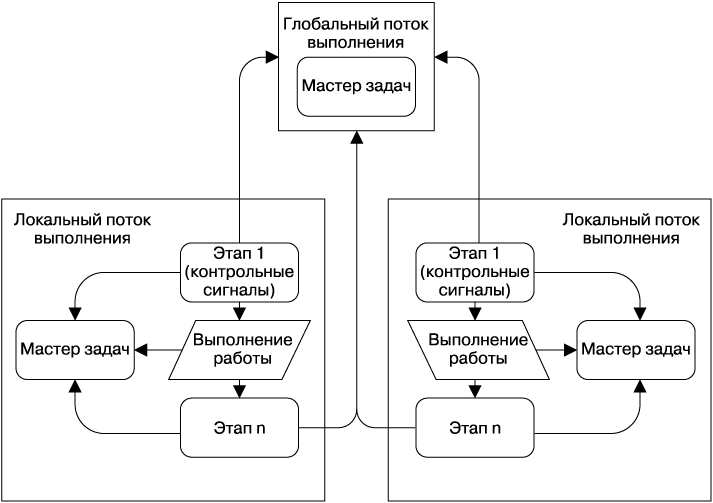
Рис. 25.6. Пример распределенных данных и потока процессов, использующих конвейеры Workflow
Итоги главы и завершающие ремарки
Циклические конвейеры очень полезны. Но не используйте их, если задача обработки данных носит продолжительный характер или стремится к тому. Вместо этого применяйте технологию, напоминающую Workflow.
По нашему опыту, продолжительная обработка данных с гарантированным качеством, обеспечиваемым технологией Workflow, хорошо функционирует и масштабируется в распределенной инфраструктуре кластеров, давая надежные результаты, на которые могут положиться наши пользователи. Эта система является стабильной и надежной, удобной в управлении и обслуживании для SRE-команды.
«Википедия». ETL // .
«Википедия». Большие данные // .
Лекция Джеффа Дина под названием Software Engineering Advice from Building Large-Scale Distributed Systems — это отличный ресурс [Dean, 2007].
«Википедия»: System Prevalence, .
Шаблон «Модель — представление — контроллер» изначально использовался для описания структуры дизайна графических интерфейсов пользователя [Fowler, 2008].

