26. Сохранность данных: как пишется, так и читается
Авторы — Рэймонд Блюм и Рандив Синг
Под редакцией Бетси Бейер
Что такое сохранность данных? Когда речь идет о пользователях, сохранность данных — это то, чем она является по их мнению.
Мы можем сказать, что сохранность данных — это мера доступности и точности, которую хранилища данных должны обеспечить пользователям, предоставив адекватный уровень обслуживания. Но это неполное определение.
Например, если из-за ошибки пользовательского интерфейса в сервисе Gmail довольно долго отображается, что в почтовом ящике нет писем, пользователи могут решить, что данные потеряны. Поэтому, если на самом деле данные не были потеряны, мир может поставить под сомнение способность компании Google действовать как ответственный распорядитель данных и целесообразность облачных вычислений может оказаться под угрозой. Независимо от того, было отображено сообщение об ошибке или сообщение об обслуживании, пока восстанавливается «лишь небольшой фрагмент метаданных», доверие пользователей Google будет подорвано.
Каково максимальное время, в течение которого данные могут быть недоступны? Как показал реальный сбой, произошедший с сервисом Gmail в 2011 году [Hickins, 2011], четыре дня — это долго, возможно, даже слишком долго. В итоге мы считаем, что 24 часа — это хорошая стартовая точка для понятия «слишком долго», когда речь идет о приложениях Google.
Аналогичные соображения применяются к приложениям вроде Google Photos, Drive, Cloud Storage и Cloud Datastore, поскольку пользователи не всегда замечают разницу между этими продуктами. (Они обосновывают это так: «Продукт — это все еще часть Google» или «Google, Amazon — какая разница? Этот продукт все еще является частью облака».) Потери данных, их повреждение и продолжительные периоды недоступности обычно неразличимы для пользователей. Поэтому требование сохранности данных должно применяться ко всем типам данных для всех сервисов. При рассмотрении вопроса сохранности данных важно то, что сервисы в облаке остаются доступными для пользователей. Доступность данных для пользователей особенно важна.
Прямые требования к сохранности данных
При рассмотрении потребности в надежности заданной системы может показаться, что потребность во времени функционирования (доступность сервиса) должна быть строже, чем потребность в сохранности данных. Например, пользователь может посчитать, что отключение сервиса электронной почты на час — это неприемлемо, при этом он может раздраженно ожидать в течение четырех дней, пока будет восстанавливаться почтовый ящик. Однако существует более подходящий способ рассмотреть потребность во времени функционирования и сохранности данных.
Целевое значение для времени функционирования, равное 99,99 %, позволяет сервису находиться в отключенном состоянии всего лишь один час в год. Оно задает довольно высокую планку, которая, скорее всего, превышает ожидания большинства интернет- и промышленных пользователей.
В противоположность этому целевое значение количества хороших байтов, равное 99,99 %, для двухгигабайтового артефакта обозначает повреждение документов, исполняемых файлов и баз данных (может быть искажено до 200 Кбайт). Такой объем повреждений в большинстве случаев катастрофичен — это приводит к появлению исполняемых файлов со случайными кодами операций и совершенно незагружаемых баз данных.
С точки зрения пользователя, к каждому сервису предъявляются независимые требования относительно времени функционирования и сохранности данных, даже если эти требования неявные. Самый худший момент для того, чтобы не согласиться в этом с пользователями, — тот, когда все их данные только что утрачены!

Для того чтобы уточнить приведенное ранее определение сохранности данных, мы можем сказать, что сохранность данных означает, что сервисы, расположенные в облаках, останутся доступными пользователю. Для него возможность получить доступ к данным особенно важна, поэтому механизмы доступа должны оставаться идеальными.
Теперь предположим, что один артефакт повреждается или теряется ровно один раз в год. Если эта потеря окажется невосполнимой, время функционирования упомянутого артефакта для этого года будет потеряно. Скорее всего, чтобы избежать таких потерь, станут использовать упреждающий поиск, объединенный с быстрым ремонтом.
Предположим, что в альтернативной Вселенной повреждение данных обнаружено мгновенно — еще до того, как оно затронуло пользователя, и этот артефакт удален, исправлен и возвращен сервису в течение получаса. Если кроме этих 30 минут никаких других простоев по техническим причинам не возникнет, такой объект будет доступен 99,99 % времени в год.
Удивительно, по крайней мере с точки зрения пользователя, что в этом сценарии показатель сохранности данных будет равен 100 % или близок к этому значению в течение всего периода доступности объекта. В этом примере было показано, что секрет исключительной сохранности данных состоит в упреждающем обнаружении проблем и быстром восстановлении.
Выбор стратегии для обеспечения отличной сохранности данных
Существует множество стратегий, которые можно применить для быстрого обнаружения, исправления и восстановления потерянных данных. Все эти стратегии обменивают время функционирования на сохранность данных, уважая пользователей, которых коснулась данная ситуация. Одни стратегии работают лучше остальных, другие требуют более сложных инженерных инвестиций. Учитывая, что доступных вариантов очень много, какую стратегию следует использовать? Ответ зависит от вашей парадигмы вычислений. Большая часть приложений для облачных вычислений стремится найти баланс между временем функционирования, задержкой, масштабом, скоростью и приватностью. Дадим определение каждому из этих терминов.
• Время функционирования. Количество времени, в течение которого сервис может быть использован. Также называется доступностью.
• Задержка. Насколько быстро сервис отзывается на обращения пользователей.
• Скорость. Как быстро сервис может вводить новшества, чтобы пользователи получили большую пользу по разумной цене.
• Приватность. Это концептуально сложное требование. Для простоты в этой главе под приватностью подразумевается то, что данные должны быть уничтожены в разумное время после их удаления пользователем.
Многие облачные приложения непрерывно развиваются на базе API ACID и BASE для того, чтобы соответствовать требованиям по этим пяти параметрам. BASE предоставляет большую доступность, чем ACID, она дается взамен более мягких гарантий распределенной устойчивости. В частности, BASE может гарантировать только то, что значение фрагмента данных, который больше не обновляется, в итоге станет согласованным в потенциально распределенных местах хранилища. В следующем сценарии показано, как работают компромиссы для времени выполнения, задержки, масштаба, скорости и приватности.
Когда остальные требования приносят в жертву ради скорости, получившиеся приложения будут зависеть от произвольной коллекции API, с которыми лучше всего знакомы определенные разработчики этих приложений.
Например, приложение может пользоваться эффективным API хранилища BLOB, таким как Blobstore, которое пренебрегает распределенной устойчивостью ради масштабирования при высоких нагрузках с продолжительным функционированием, малой задержкой и низкой стоимостью. Для того чтобы это компенсировать:
• приложение может передавать небольшие объемы метаданных, принадлежащих его блобам, что приведет к созданию приложения, основанного на Paxos, с большей задержкой, низкой доступностью и более высокой стоимостью — наподобие Megastore [Baker, 2011], [Lamport, 1998];
• некоторые клиенты приложения могут кэшировать определенный объем этих метаданных локально и получать доступ к блобам непосредственно, еще больше снижая задержку с точки зрения пользователей;
• другое приложение может хранить метаданные в Bigtable, частично жертвуя устойчивостью, поскольку его разработчики были знакомы с Bigtable.
Такие облачные приложения сталкиваются с разнообразными серьезными трудностями во время выполнения программы, например со ссылочной целостностью между хранилищами данных (в предыдущем примере — Blobstore, Megastore и кэши на стороне клиента). Влияние высокой скорости говорит о том, что изменения схемы, миграция данных, создание новой функциональности на основе старой, переписывание кода и развитие точек взаимодействия с другими приложениями создают окружение, усложненное запутанными отношениями между разными фрагментами данных, в которых полностью не разбирается ни один инженер.
Для того чтобы данные такого приложения не деградировали до того, как попадут на глаза пользователям, необходимо создать систему внеполосных проверок и баланса внутри хранилищ данных и между ними. Такая система рассматривается в подразделе «Третий уровень: раннее обнаружение» далее в этой главе.
В дополнение к этому, если такое приложение полагается на независимые некоординируемые резервные копии нескольких хранилищ (в предыдущем примере Blobstore и Megastore), то его способность эффективно использовать данные, полученные в ходе восстановления, ухудшается из-за разнообразных отношений между восстановленными и рабочими данными. Приложению из нашего примера пришлось бы выделять необходимые данные из восстановленных блобов и рабочих данных из Megastore, восстановленных данных из Megastore и рабочих данных из блобов, восстановленных блобов и восстановленных данных из Megastore, а также взаимодействовать с кэшами клиентов.
Учитывая все эти зависимости и сложности, сколько ресурсов нужно выделить на сохранность данных и где?
Резервные копии или архивы?
Как правило, компании защищают данные от потерь путем инвестиций в разработку стратегий резервного копирования. Однако эти усилия должны быть сосредоточены не на создании резервных копий, а на восстановлении данных, что позволяет отличать резервные копии от архивов. Как иногда говорится, никто не хочет делать резервные копии, но все хотят восстановления данных.
Является ли ваша резервная копия архивом, подходящим для восстановления данных в случае катастрофы?

Наиболее важным различием между резервными копиями и архивами является то, что резервные копии могут быть загружены обратно в приложение, а архивы — нет. Поэтому резервные копии имеют разное применение.
В архивах данные безопасно хранятся в течение длительного времени для проведения проверок, обнаружения и соблюдения правил. Восстанавливать данные для этих целей не обязательно в рамках требований к времени функционирования сервиса. Например, вам может понадобиться сохранить данные о финансовых транзакциях за 7 лет. Для этого можете перемещать собранные журналы проверок в долгосрочное архивное хранилище, расположенное за пределами площадки, раз в месяц. Получение и восстановление журналов во время финансовой проверки, длящейся один месяц, может занять целую неделю, и для архива такое продолжительное время восстановления будет приемлемым.
Однако, если случится катастрофа, данные должны быть быстро восстановлены из резервных копий, причем желательно, чтобы это произошло в соответствии с потребностями во времени функционирования сервиса. В противном случае пользователи, которых коснется эта ситуация, не смогут работать с приложением с момента появления проблемы с сохранностью данных до того, как восстановление данных завершится.
Важно также иметь в виду следующее: поскольку большая часть недавно полученных данных находится под угрозой до тех пор, пока не будет сделана их резервная копия, лучше запланировать регулярное создание реальных резервных копий (в противоположность архивам): ежедневно, ежечасно или по подходящему вам графику.
Поэтому при формулировании стратегии создания резервных копий задумайтесь, как быстро вам нужно восстанавливаться после возникновения проблем и какое количество данных вы можете позволить себе потерять.
Требования к облачному окружению на перспективу
При создании облачного окружения наблюдается уникальная комбинация технических сложностей.
• Если окружение использует транзакционные и нетранзакционные резервные копии и решения по восстановлению, то восстановленные данные не обязательно будут корректными.
• Если сервисы должны развиваться, не отключаясь, разные версии бизнес-логики могут работать с данными параллельно.
• Если взаимодействующие сервисы получают версии независимо друг от друга, несовместимые версии разных сервисов могут какое-то время взаимодействовать между собой, повышая вероятность того, что данные будут случайно повреждены или потеряны.
В дополнение к этому, для поддержания принципа экономии на масштабе поставщики услуг должны предоставлять ограниченное количество API. Эти API должны быть простыми, чтобы их можно было использовать в большинстве приложений, или они будут пригодны лишь для нескольких пользователей. В то же время API должны быть достаточно продуманными и иметь следующую функциональность:
• локальность данных и кэширование;
• локальное и глобальное распределение данных;
• высокую устойчивость или устойчивость в конечном счете;
• долговечность данных, резервное копирование и восстановление.
В противном случае взыскательные клиенты не смогут перенести приложение в облако и простые приложения, которые станут сложными и крупными, нужно будет полностью переписать для того, чтобы использовать другие, более сложные API.
Проблемы появляются, когда указанные особенности API задействуются в определенных комбинациях. Если поставщик услуг не может решить эти проблемы, приложение, которое столкнется с такими сложностями, должно определить их и разрешить самостоятельно.
Целевые значения показателей сохранности и доступности данных для SRE
Да, глобальная цель SRE, которая заключается в поддержании целостности устойчивых данных, неплоха, но мы стремимся к конкретным целям с измеряемыми показателями. Служба SRE определяет ключевые показатели, которые мы применяем для формирования ожиданий от наших систем и процессов с помощью тестирования. Эти показатели используются также для того, чтобы отследить производительность систем во время реального события.
Сохранность данных — это средство, доступность данных — цель
Сохранность данных — это точность и устойчивость данных на протяжении периода их существования. Пользователям нужно знать, что информация будет корректной и после ее создания не изменится непредсказуемым образом. Но достаточно ли такой уверенности?
Рассмотрим ситуацию, когда данные поставщика услуг электронной почты были недоступны целую неделю [Kincaid, 2009]. В течение десяти дней пользователям приходилось искать другие, временные средства ведения бизнеса в надежде, что они скоро вернутся к привычной электронной почте с контактами и историей переписки.
Но позже произошло самое плохое: провайдер объявил, что, несмотря на все ожидания, часть электронных писем и контактов пропала, они попросту безвозвратно испарились. Казалось, что серия сбоев при управлении сохранностью данных оставила поставщика услуг без резервных копий. Разъяренные пользователи либо продолжили использовать временные аккаунты, либо создали новые, уйдя от прежнего поставщика услуг электронной почты.
Но погодите! Через несколько дней после сообщения о полной потере данных поставщик объявил, что личная информация пользователей может быть восстановлена. Данные не утрачены, произошло лишь отключение. Все хорошо!
Кроме того, что не все было хорошо. Пользовательские данные сохранились, но люди, которым они были нужны, слишком долго не могли получить к ним доступ.
Мораль такова: с точки зрения пользователя, если данные есть, но к ним нельзя получить доступ, то их, по сути, нет.
Создаем систему восстановления, а не систему резервного копирования
Создание резервных копий — это классическая задача системного администрирования, выполнением которой пренебрегают, которую стремятся переложить на плечи других или задвинуть в долгий ящик. Резервное копирование ни для кого не высокоприоритетно — оно представляет собой постоянную трату времени и ресурсов и не приносит мгновенного видимого эффекта. Кто-то может поспорить, что, как и для большей части мер по защите от низкоуровневых опасностей, такой подход является прагматичным. Основная проблема, связанная с этой стратегией, заключается в том, что возможные опасности могут нести небольшой риск, но при этом оказывать серьезное воздействие. Если данные сервиса недоступны, ваша реакция может определить будущее сервиса, продукта или даже всей компании.
Вместо того чтобы концентрироваться на сложностях резервного копирования, гораздо полезнее, не говоря уже о том, что проще, обосновывать его необходимость, сосредотачиваясь на задачах с видимым результатом, то есть на восстановлении! Создание резервных копий — это «налог», который уплачивается на постоянной основе муниципальным службам, гарантирующим доступность данных. Вместо того чтобы делать акцент на «налоге», обращайте внимание на «налоговые» сервисы — доступность данных. Мы не заставляем команды тренироваться выполнять резервное копирование, вместо этого они:
• определяют целевые значения показателей (SLO) для сохранности данных при разных типах неисправностей;
• тренируются и демонстрируют свою способность соответствовать этим SLO.
Типы сбоев, которые ведут к потере данных
На самом высоком уровне существует 24 вида сбоев, когда три фактора могут соединиться в любой комбинации (рис. 26.1). Вы должны рассмотреть каждый из потенциальных сбоев при разработке программы сохранности данных. Рассмотрим факторы сохранности данных при возможных неполадках.
• Основная причина. Невосстановимая потеря данных может быть вызвана многими причинами — действиями пользователя, ошибкой в работе, ошибкой приложения, дефектами инфраструктуры, сбоем оборудования или аварией на площадке.
• Масштаб. Одни потери данных распространяются широко, влияя на множество объектов. Другие узконаправленные — иногда оказываются удалены или повреждены данные, необходимые небольшому количеству пользователей.
• Уровень. Одни потери данных похожи на «большой взрыв» (например, один миллион рядов был заменен десятью рядами всего за минуту), а другие нарастают постепенно (например, десять рядов данных удаляются каждую минуту в течение нескольких недель).
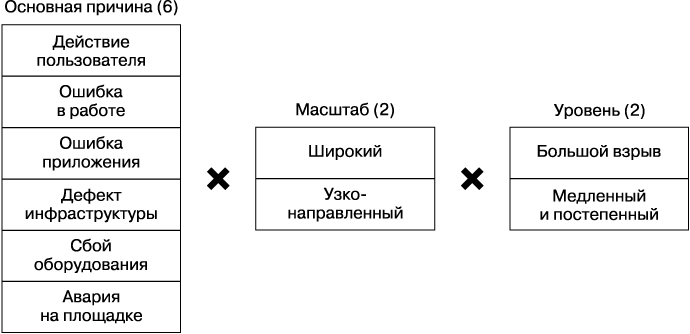
Рис. 26.1. Факторы сохранности данных при возможных неполадках
Эффективный план восстановления должен учитывать все эти типы неполадок, происходящих в самых разнообразных комбинациях. Идеальная эффективная стратегия защиты от потери данных, вызванной нарастающим количеством ошибок приложения, может оказаться абсолютно бесполезной, если ваш дата-центр начнет гореть.
Исследования 19 попыток восстановления данных в компании Google показали, что потери данных, наиболее заметные пользователям, включают в себя удаление данных или нарушение ссылочной целостности, вызванные ошибками программного обеспечения. Наиболее сложные случаи повреждения или удаления данных были обнаружены спустя недели или даже месяцы после первого появления ошибок в производственной среде. Поэтому меры безопасности, предпринимаемые в компании Google, должны подходить для предотвращения таких потерь или восстановления после них.
Чтобы восстановиться при таком развитии событий, крупное и успешное приложение должно получать данные, сгенерированные за дни, недели или месяцы для миллионов возможных пользователей. Приложению также может понадобиться восстанавливать каждый затронутый объект к определенному лишь для него моменту времени. Такой сценарий восстановления данных за пределами компании Google называется использование точки восстановления, а внутри нее — путешествие во времени.
Решение о создании резервных копий и восстановлении данных, которое обеспечивает возможность восстанавливать данные с помощью точки восстановления для хранилищ данных, основанных на семантиках ACID и BASE, соответствуя при этом целевым значениям времени функционирования, задержки, масштабируемости, скорости и стоимости, на сегодняшний день является несбыточной мечтой!
Решение этой проблемы усилиями собственных инженеров приведет к тому, что вам придется пожертвовать скоростью. Многие проекты идут на компромисс, используя многоуровневую стратегию резервного копирования без функциональности точек восстановления. Например, API, лежащий в основе вашего приложения, может поддерживать множество механизмов восстановления данных. Дорогие локальные снимки способны дать частичную защиту от ошибок приложения, поэтому вы можете хранить такие снимки, выполнявшиеся каждые несколько часов, на протяжении нескольких дней. Эффективные с точки зрения стоимости полные и инкрементные копии, создаваемые каждые два дня, могут храниться дольше. Точка восстановления — это полезная функциональность, если ее поддерживают одна или несколько стратегий.
Рассмотрим варианты восстановления данных, обеспечиваемые облачными API, которые вы скоро начнете применять. Смените возможность их выполнения с помощью точек восстановления на многоуровневую стратегию, если это необходимо, но обязательно используйте хотя бы один из этих способов! Если вы можете задействовать обе функции, сделайте это. Каждая из этих функций или даже обе в какой-то момент окажутся полезными.
Сложности поддержания высокой сохранности данных
При разработке программы поддержания целостности данных важно иметь в виду, что репликация и избыточность — это не восстанавливаемость.
Проблемы масштабирования: возможности резервных копий и восстановления
Классическим неверным ответом на вопрос: «У вас есть резервная копия?» является: «У нас есть кое-что получше — репликация!» Репликация имеет множество преимуществ, включая локальность данных и защиту от катастроф в местах расположения, но она не может защитить вас от множества способов потерять данные. В хранилищах данных, которые автоматически синхронизируют несколько реплик, повреждение столбцов базы данных или случайное удаление данных произойдет во всех копиях, скорее всего, еще до того, как вы сможете устранить проблему.
Для того чтобы решить эту проблему, вы можете создавать необслуживающие копии ваших данных в другом формате, например часто выполнять экспорт из базы данных в исходный файл. Эта дополнительная мера дает защиту от ошибок, от которых репликация спасти не может, — пользовательских ошибок и ошибок на уровне приложения, но она не способна ничего сделать с потерями данных на более низком уровне. Эта мера также создает риск появления ошибок во время конвертирования данных (в обоих направлениях) и во время сохранения исходного файла в дополнение к возможным несоответствиям между двумя форматами. Представьте атаку нулевого дня, которой подвергся некий низкий уровень вашего стека, например файловая система или драйвер устройства. Все копии, которые относились к атакованному программному компоненту, включая экспорт из базы данных, записанный для файловой системы, поддерживающей вашу базу данных, становятся уязвимыми.
Поэтому мы видим, что очень важно обеспечить разнообразие: защита от сбоя на слое Х требует сохранения данных на разных компонентах этого слоя. Изоляция носителей защищает от их недостатков: ошибка или атака на драйвер дискового устройства, скорее всего, не повлияют на накопители на магнитной ленте. Если бы мы могли, то создавали бы резервные копии ценных данных на глиняных табличках.
Что важнее: поддерживать данные в актуальном состоянии и восстанавливать их или обеспечить полную их защиту? Чем ниже в стеке находится снимок данных, тем больше времени потребуется на то, чтобы сделать их копию, что означает снижение частоты выполнения резервного копирования. На уровне баз данных репликация транзакции может занять несколько секунд, экспортирование снимка базы данных в файловую систему — 40 минут. Создание полной резервной копии файловой системы может длиться часы.
Вы можете потерять данные, которые появились за эти 40 минут, если выполняете восстановление из последнего снимка. Восстановление из резервной копии файловой системы может повлечь за собой утрату многих часов транзакций. Наверняка вы хотели бы получить самую свежую копию максимально быстро, но в зависимости от типа сбоя эта самая свежая и мгновенно доступная копия может оказаться плохим вариантом.
Сохранность
Сохранность — показатель того, как долго вы храните копии ваших данных, — это еще один фактор, который следует принимать во внимание при создании планов восстановления данных.
Скорее всего, вы или ваши клиенты быстро обнаружите исчезновение всей базы данных, но на то чтобы постепенная потеря данных привлекла внимание нужных людей, может потребоваться несколько дней. Восстановление утерянных данных в последнем сценарии потребует использования сделанных ранее снимков. При получении настолько старых данных вы, вероятно, захотите объединить восстановленные данные с данными в текущем состоянии. Это значительно усложнит процесс восстановления.
Как служба SRE справляется с трудностями обеспечения сохранности данных
Мы думаем, что системы, лежащие в основе наших сервисов, ненадежны, и точно так же предполагаем, что все механизмы защиты могут дать сбой в самый неподходящий момент. Поддержание гарантии сохранности данных в больших масштабах — это вызов, который еще больше усложняется высокой степенью изменений связанных программных систем и требует выполнения вспомогательных, но несвязанных приемов, каждый из которых сам по себе предлагает высокую степень защиты.
Двадцать четыре комбинации типов сбоев с точки зрения сохранности данных
Способов, которыми можно потерять данные, множество (как описано ранее), поэтому не существует панацеи, которая защитила бы нас от всех комбинаций типов сбоев. Вместо этого вам нужна глубокая защита. Она объединяет несколько слоев, где каждый последующий уровень защищает от все менее распространенных сценариев потери данных. На рис. 26.2 показаны путь объекта от мягкого удаления до разрушения, а также перечислены стратегии восстановления данных, которые следует применять на протяжении этого пути для того, чтобы гарантировать глубокую защиту.
Первый уровень — это мягкое (или ленивое) удаление, которое показало себя эффективным способом защиты от сценариев непреднамеренного удаления данных. Вторая линия обороны — это резервные копии и связанные с ними методы восстановления. Третий, последний уровень — это обычная проверка данных, она рассматривается в подразделе «Третий уровень: раннее обнаружение» далее. Для всех этих уровней наличие репликации полезно лишь иногда и при определенных сценариях (планы восстановления данных не должны полагаться на репликацию).
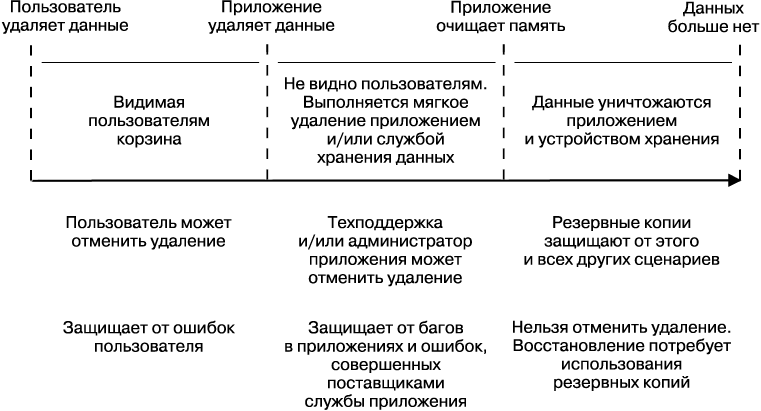
Рис. 26.2. Путь объекта от мягкого удаления до разрушения
Первый уровень: мягкое удаление
Когда скорость разработки высока и имеет значение приватность, ошибки в приложениях ответственны за бо'льшую часть событий, связанных с потерей и повреждением данных. Фактически ошибки, связанные с удалением данных, могут стать настолько распространенными, что способность отменять удаление данных в рамках ограниченного промежутка времени станет основным способом защиты от потерь данных, которые в противном случае станут постоянными.
Любой продукт, который гарантирует конфиденциальность данных своих пользователей, должен позволять им удалять выбранные фрагменты данных и/или их все. Такие продукты трудно поддерживать из-за риска случайного удаления. Возможность отменить удаление данных (например, с помощью корзины) снижает, но не может полностью избавить вас от этих трудностей, особенно если ваш сервис поддерживает и сторонние надстройки, которые также могут удалять данные.
Мягкое удаление может значительно снизить количество трудностей поддержки или даже полностью избавить от них. Мягкое удаление означает, что удаленные данные мгновенно помечаются как удаляемые, что делает их недоступными для использования для большей части кода приложения, исключая административные его ветви. С административными ветвями кода могут быть связаны предоставление информации по запросу, восстановление похищенных учетных записей, промышленное администрирование, поддержка пользователей, поиск проблем и соответствующая этим аспектам функциональность. Выполняйте мягкое удаление, когда пользователь очищает свою корзину, и предоставьте ему инструмент поддержки, который позволяет авторизованным администраторам отменить случайное удаление данных. Компания Google реализует эту стратегию для того, чтобы большинство наших популярных приложений были продуктивными, в противном случае трудности, связанные с поддержкой пользователей, были бы невыносимыми.
Вы можете расширить стратегию мягкого удаления, предоставив пользователям способ восстановить удаленные данные. Например, корзина в приложении Gmail дает пользователям возможность получить доступ к удаленным сообщениям в течение 30 дней.
Часто нежелательное удаление данных происходит из-за хищения учетных записей. В этом случае похититель, как правило, удаляет данные владельца учетной записи перед тем, как использовать ее для рассылки спама и других незаконных целей. Когда вы связываете случайное удаление данных пользователем с риском их уничтожения похитителем, необходимость программного интерфейса мягкого удаления и его отмены в вашем приложении становится очевидной.
Мягкое удаление данных подразумевает, что данные, помеченные как удаляемые, будут уничтожены по прошествии определенного времени. Длина этого промежутка зависит от политики организации и применяемых законов, доступных ресурсов хранилища и их стоимости, цены продукта и позиционирования рынка, особенно при наличии большого количества недолговечных данных. Распространенными вариантами таких промежутков являются 15, 30, 45 или 60 дней. Опыт компании Google свидетельствует, что большая часть случаев хищения учетных записей и проблем с целостностью данных обнаруживаются в течение 60 дней. Поэтому хранить данные после мягкого удаления больше 60 дней не имеет смысла. Мы также обнаружили, что наиболее ощутимые разрушения данных вызваны разработчиками, незнакомыми с существующим кодом, которые работают над кодом, связанным с удалением данных, особенно если это конвейеры с пакетной обработкой (например, офлайн-конвейер MapReduce или Hadoop). Разрабатывать интерфейсы так, чтобы помешать разработчикам, незнакомым с вашим кодом, обмануть механизм мягкого удаления с помощью нового кода, довольно полезно.
Одним из эффективных способов сделать это является реализация программы облачных вычислений, которые включают в себя встроенные API мягкого удаления и его отмены, позволяющие гарантировать, что у нас будет необходимая функциональность. Даже наилучшая броня окажется бесполезной, если вы ее не наденете.
Стратегии мягкого удаления охватывают функциональность по удалению данных в потребительских продуктах вроде Gmail или Google Drive, но что, если вы хотите вместо этого воспользоваться программой облачных вычислений?
Если предположить, что программа облачных вычислений уже поддерживает программное мягкое удаление и его отмену с разумными параметрами по умолчанию, то прочие сценарии случайного удаления данных будут проистекать из ошибок, допущенных либо внутренними разработчиками, либо разработчиками — потребителями вашего сервиса.
В таких случаях может быть полезно создать дополнительный уровень мягкого удаления, который мы называем «ленивым» удалением. Вы можете подумать, что мягкое удаление — это закулисное очищение, которым управляет система хранения (мягкое удаление управляется и реализуется в клиентском приложении или сервисе). В случае использования «ленивого» удаления данные, удаленные облачным приложением, мгновенно становятся недоступными, но поставщик облачных услуг сохраняет их в течение нескольких недель до полного удаления. «Ленивое» удаление рекомендуется применять не для всех стратегий глубокой защиты. Длительный период «ленивого» удаления может оказаться дорогим для систем, работающих с большим количеством недолгосрочных данных. Оно также может быть неэффективным в системах, которые должны гарантировать уничтожение удаленных данных за разумный промежуток времени, то есть в системах, предлагающих гарантированную приватность.
Подытоживая разговор о первом уровне глубокой защиты, отметим следующее.
• Создание корзины, которая позволяет пользователям отменить удаление данных, — это основной способ защиты от пользовательских ошибок.
• Мягкое удаление — основной способ защиты от ошибок внешних разработчиков и вторичный — от пользовательских ошибок.
• В программах для разработчиков ленивое удаление — это основной способ защиты от ошибок внутренних разработчиков и вторичный — от ошибок внешних разработчиков.
Как насчет истории исправлений? Некоторые продукты предоставляют возможность откатить элементы к предыдущему состоянию. Когда такая функциональность становится доступной пользователям, она представляет собой некую форму корзины. Если она доступна разработчикам, ее можно использовать вместо мягкого удаления в зависимости от ее реализации.
В Google история исправлений оказалась полезной для восстановления после того, как реализовались некоторые сценарии повреждения данных, но она не годится для восстановления в большинстве случаев потери данных, включающих случайное их удаление. Это происходит потому, что некоторые реализации истории исправлений считают удаление особым случаем, при котором предыдущие состояния должны быть удалены, в противоположность изменению элемента, чья история может быть сохранена на определенный период времени. Для того чтобы предоставить адекватную защиту от нежелательного удаления, следует применять мягкое удаление и для истории исправлений.
Второй уровень: резервные копии и связанные с ними методы восстановления
Резервные копии и восстановление данных — это вторая линия защиты после мягкого удаления. Наиболее важным принципом для этого слоя является то, что сами резервные копии ничего не значат — важно только восстановление. Факторы, поддерживающие успешное восстановление, должны управлять вашими решениями при создании резервных копий, но не наоборот.
Другими словами, прежде чем определять политику резервного копирования, задайте себе следующие вопросы.
• Какие методы создания резервных копий и восстановления данных нужно использовать?
• Насколько часто вы будете создавать точки восстановления, создавая полные или инкрементные резервные копии своих данных?
• Где вы будете хранить резервные копии?
• Как долго станете сохранять резервные копии?
Сколько недавно полученных данных вы готовы потерять во время восстановления? Чем меньше данных вы можете позволить себе потерять, тем серьезнее должны отнестись к стратегии создания инкрементных резервных копий. В одном из самых запоминающихся случаев, произошедших в компании Google, мы создавали резервные копии для более старой версии сервиса Gmail практически в реальном времени.
Даже если деньги не являются для вас ограничивающим фактором, частое создание резервных копий может оказаться накладным в другом смысле. Наиболее примечательно то, что этот процесс создает вычислительные сложности для работающих хранилищ данных вашего сервиса во время обслуживания пользователей, что заставляет сервис приближаться к границам масштабируемости и производительности. Для того чтобы облегчить ситуацию, вы можете в непиковые часы создавать полные резервные копии, а в то время, когда сервис занят сильнее, — инкрементные резервные копии.
Как быстро нужно восстанавливаться? Чем быстрее ваши пользователи должны быть спасены, тем более локальными должны быть резервные копии. Зачастую компания Google сохраняет более дорогие, но и более быстрые для восстановления снимки на короткое время внутри экземпляра хранилища и чуть дольше хранит более поздние резервные копии в распределенном хранилище с произвольным доступом внутри того же или близлежащего дата-центра. Такая стратегия сама по себе не защитит вас от катастроф в местах расположения, поэтому зачастую эти резервные копии отправляют в ближайшие (или офлайн-) пункты на более продолжительное время, перед тем как они уступят место новым резервным копиям.
Насколько старыми могут быть резервные копии? Стратегия создания резервных копий становится более дорогой по мере увеличения возраста самых старых копий, но при этом увеличивается количество сценариев, при которых можно выполнить восстановление (однако это увеличение влечет за собой снижение эффективности).
Опыт компании Google показывает, что ошибки, связанные с низкоуровневой мутацией данных или их удалением, находящиеся в коде приложения, требуют возврата назад на наибольший промежуток времени, поскольку некоторые из них обнаруживаются лишь спустя несколько месяцев после того, как вы начнете терять данные. Такие ситуации предполагают, что вы можете вернуться в прошлое так далеко, как только возможно.
В то же время в высокоскоростном окружении разработки изменения кода и структуры могут сделать старые резервные копии дорогими или их и вовсе станет невозможно использовать. Помимо этого, будет трудно восстановить разные наборы данных из разных точек восстановления, поскольку это потребует применения нескольких резервных копий. Однако именно таким образом вы сможете восстановиться после низкоуровневого повреждения данных или их удаления.
Стратегии, описанные в подразделе «Третий уровень: раннее обнаружение» далее, должны ускорить обнаружение низкоуровневых мутаций данных или багов в коде, связанных с удалением данных, хотя бы частично снижая необходимость выполнения такого сложного процесса восстановления. Как же вы можете обеспечить разумную защиту до того, как поймете, какого рода проблемы вам придется искать?
Наше решение — выбрать срок от 30 до 90 дней хранения резервных копий для большинства сервисов. Попадание сервиса в это окно зависит от его терпимости к потере данных и инвестиций в раннее обнаружение.
Подытоживая совет по защите от 24 комбинаций типов отказа с точки зрения сохранности данных: устранение последствий развития большого количества сценариев за разумную стоимость требует применения многоуровневой стратегии создания резервных копий. Первый уровень состоит в создании большого количества резервных копий, с помощью которых можно быстро выполнить восстановление и которые хранятся максимально близко к работающим хранилищам данных, возможно, использующим ту же или похожую технологию хранения, что и источники данных. Это дает защиту от большинства проблем, включая ошибки в программном обеспечении и ошибки разработчиков. Из-за относительной дороговизны резервные копии сохраняются на этом уровне от нескольких часов до десяти дней, и для восстановления с их помощью потребуется всего несколько минут.
Второй уровень состоит из меньшего количества резервных копий, которые могут храниться на протяжении нескольких недель в распределенных файловых системах с произвольным порядком выборки. Для того чтобы выполнить восстановление данных с помощью этих резервных копий, может потребоваться несколько часов, они дают дополнительную защиту от сбоев, влияющих на определенные технологии хранения обслуживающего стека, но не на технологии, использованные для хранения резервных копий. Этот уровень защищает также от ошибок приложения, которые были обнаружены слишком поздно, когда первый уровень защиты уже не может помочь. Если вы создаете новые версии кода два раза в неделю, имеет смысл сохранить эти резервные копии минимум на неделю или две.
Последующие уровни пользуются полуоперативными хранилищами, такими как специализированные библиотеки работы с лентами и расположенные вне площадок хранилища запасных носителей, например на накопителях на магнитной ленте или на дисковых накопителях. Резервные копии на этих уровнях предоставляют защиту от проблем, возникающих на площадке, таких как отключения питания дата-центра или повреждения распределенной системы из-за ошибки.
Перемещать большие объемы данных между уровнями дорого. В то же время производительность хранилища на более высоких уровнях не конкурирует с ростом количества экземпляров обслуживающих производственных хранилищ сервиса. В результате резервное копирование на этих уровнях выполняется реже, но копии сохраняются дольше.
Основной уровень: репликация
В идеальном мире каждый экземпляр хранилища, включая те, что содержат резервные копии, должен быть реплицирован. Во время восстановления данных последнее, что вы хотите обнаружить, — это то, что резервные копии сами потеряли необходимые данные или что дата-центр, содержащий наиболее полезные резервные копии, находится на профилактическом обслуживании.
По мере увеличения объема данных становится не всегда возможно выполнить репликацию каждого экземпляра хранилища. В таких случаях имеет смысл разместить успешные резервные копии на разных площадках, каждая из которых может дать сбой независимо от других, и записать резервные копии с помощью избыточного метода, например RAID, кодов Рида — Соломона или репликации GFS.
При выборе избыточной системы не полагайтесь на нечасто применяемую схему, единственные «тесты» эффективности которой представляют собой лишь ваши нечастые попытки восстановления данных. Вместо этого выберите популярную схему, которую часто применяют многие пользователи.
От терабайта к экзабайту — это не просто «больше»
Процессы и практики, применяемые к объемам данных, измеряемых в терабайтах (Т), плохо масштабируются для данных, измеряемых в экзабайтах (Е). Проверка, копирование и тестирование нескольких гигабайт структурированных данных — это интересная задача. Однако, если предположить, что вы хорошо знаете свою схему и модель транзакций, выполнить это упражнение не составит особого труда. Как правило, вам будет достаточно лишь получить ресурсы машины для того, чтобы пройтись по данным, реализовать логику проверки и выделить достаточно места для сохранения нескольких копий данных.
Теперь поднимем ставки: вместо нескольких гигабайт попробуем проверить 700 Пбайт структурированных данных и обеспечить их безопасность. Если предположить, что идеальная производительность SATA 2.0 — 300 Мбайт/с, то выполнение одной задачи, которая проходит по всем данным и проделывает примитивные проверки, займет восемь десятилетий. Создание нескольких полных резервных копий при условии, что имеется достаточно места, займет как минимум столько же времени. Время восстановления, учитывая постобработку, будет еще больше. Теперь потребуется почти 100 лет для того, чтобы восстановить данные из резервной копии, которой было 80 лет на момент, когда началось восстановление. Очевидно, такую стратегию стоит пересмотреть.
Наиболее распространенным и довольно эффективным приемом резервного копирования больших объемов данных является создание точек доверия в данных — порции сохраненных данных, которые были проверены после того, как их пометили как неизменяемые, обычно по прошествии какого-то времени. Как только мы узнаем, что заданный профиль пользователя или транзакция уже зафиксированы и не изменятся, мы можем проверить их внутреннее состояние и создать подходящие для восстановления копии этих данных. Далее вы можете создавать инкрементные резервные копии, которые включают в себя только данные, измененные или добавленные с момента создания последней резервной копии. Такой прием позволяет сократить время на создание резервных копий, сделав его пропорциональным времени обработки основной ветви. Это означает, что частое создание инкрементных копий может спасти вас от проверки и копирования данных, которые будут длиться 80 лет.
Однако помните, что нас интересует восстановление, а не сами резервные копии. Предположим, что мы создали полную резервную копию некоторых данных три года назад и с тех пор делали инкрементные резервные копии. При полном восстановлении данных будут последовательно обработаны более 1000 зависимых друг от друга инкрементных резервных копий. Каждая такая обработка повышает риск сбоя, не говоря уже о логистических трудностях планирования и стоимости выполнения этих задач.
Еще одним способом снижения фактического времени, которое требуется для копирования и проверки, является распределение нагрузки. Если вы хорошо сегментировали данные, у вас будет возможность запустить параллельно N задач, каждая из которых отвечает за копирование и проверку 1/N части данных. Это потребует предварительного продумывания и планирования дизайна схемы и физического развертывания данных, чтобы:
• корректно сбалансировать данные;
• гарантировать независимость каждого сегмента;
• избежать возникновения разногласий среди конкурирующих задач одного уровня.
Сочетая «горизонтальное» распараллеливание нагрузки и «вертикальное» разграничение содержимого резервных копий по времени, мы можем сократить длительность восстановления на несколько порядков, получив вместо восьми десятилетий вполне приемлемую оперативность.
Третий уровень: раннее обнаружение
«Плохие» данные не бездействуют, они распространяются. Ссылки на отсутствующие или поврежденные данные копируются и разветвляются, и с каждым обновлением общее качество хранилища данных снижается. Последующие зависимые транзакции и потенциальные изменения формата данных с течением времени все больше усложняют процесс восстановления данных. Чем раньше вы узнаете о потере данных, тем проще будет восстановить их и тем полнее будет результат.
Сложности, с которыми сталкиваются разработчики облачных систем
В высокоскоростных окружениях облачные приложения и сервисы инфраструктуры сталкиваются с множеством трудностей, связанных с сохранностью данных. К ним относятся, например, следующие:
• ссылочная целостность между хранилищами данных;
• изменения схемы;
• старение кода;
• миграция данных с нулевым временем работы вхолостую;
• изменение точек взаимодействия с другими сервисами.
Если не прилагать никаких усилий для отслеживания возникающих связей данных, их качество со временем будет ухудшаться.
Зачастую новые разработчики облачных сервисов, выбирающие распределенный устойчивый API хранилища, например Megastore, делегируют заботу о сохранности данных приложения алгоритму достижения распределенного консенсуса, реализованному под API, например Paxos (см. главу 23). Разработчики заключают, что выбранный API сам по себе сможет поддерживать данные приложения в хорошей форме. В результате они объединяют все данные приложения в единое решение для хранения, которое гарантирует распределенную устойчивость, и избегают проблем, связанных со ссылочной целостностью, в обмен на сниженную производительность и/или возможность масштабирования.
Несмотря на то что такие алгоритмы в теории безупречны, их реализация зачастую усложняется «костылями» — оптимизацией и обоснованными предположениями. Например, в теории алгоритм Paxos игнорирует давшие сбой вычислительные узлы и продолжает работать до тех пор, пока имеется кворум работающих узлов. Однако на практике игнорирование давшего сбой узла может привести к тайм-аутам, повторным попыткам и применению других способов обработки сбоев, характерных для конкретной реализации Paxos [Chandra, 2007]. Как долго Paxos должен пытаться связаться с неотзывающимся узлом до его отключения по тайм-ауту? То, что конкретная машина дает сбой (возможно, периодически) определенным способом, в определенный момент и в определенном дата-центре, может вызвать непредсказуемое поведение. Чем больше масштаб приложения, тем чаще на него влияют такие противоречия. Если эта логика останется верной, даже будучи примененной к реализации Paxos (так было у компании Google), она должна быть еще более верной для реализаций, устойчивых в конечном счете, наподобие Bigtable (что также было верно). Затронутые приложения не могут знать, что 100 % их данных в порядке, пока не выполнят проверку: доверяйте системам хранения, но проверяйте!
Эту проблему усугубляет то, что для восстановления после низкоуровневого повреждения данных или сценариев удаления мы должны восстанавливать разные наборы данных из разных точек восстановления с помощью разных резервных копий, при этом изменения кода и схемы могут сделать старые резервные копии неэффективными в высокоскоростном окружении.
Внеполосная проверка данных
Для того чтобы предотвратить ухудшение качества данных до того, как пользователь это увидит, а также чтобы обнаружить сценарии повреждения данных и их потери, прежде чем они станут невосстановимыми, нужна система проверок и уравновешивания внеполосных проверок как внутри каждого хранилища данных приложения, так и между ними.
Зачастую конвейеры для подтверждения данных реализуются как коллекции задач MapReduce или Hadoop. Такие конвейеры с опозданием добавляются в уже популярные и успешные сервисы. Иногда конвейеры применяются, когда сервис достигает предела масштабируемости и перестраивается с нуля. Мы создали валидаторы для каждой из этих ситуаций.
Переключение некоторых разработчиков на работу над конвейером по проверке данных может на короткое время снизить скорость разработки. Однако выделение инженерных ресурсов для проверки данных позволяет другим разработчикам двигаться быстрее в долгосрочной перспективе, поскольку инженеры знают, что в этом случае меньше вероятность того, что баги, вызывающие повреждение данных, останутся незамеченными и попадут в производственные системы. Как и применение юнит-тестов на ранних этапах жизненного цикла приложения, наличие конвейера проверки данных приведет к общему ускорению разработки проектов.
Рассмотрим конкретный пример: сервис Gmail sports имеет некоторое количество валидаторов, каждый из которых обнаружил проблемы, связанные с сохранностью данных, в системе, находящейся в промышленной эксплуатации. Разработчиков сервиса успокаивает то, что эти ошибки, вносящие несоответствия в данные работающей системы, будут обнаружены в течение 24 часов, и они вздрагивают при мысли о том, чтобы запускать валидаторы данных реже чем один раз в день. Эти валидаторы наряду с модульным и регрессионным тестированием позволили разработчикам Gmail вносить изменения в реализацию производственного хранилища чаще чем раз в неделю.
Корректно реализовать внеполосную проверку данных непросто. Если проверка слишком строгая, то даже простые надлежащим образом внесенные изменения заставят ее дать сбой. В результате инженеры прекратят попытки проверять данные. Если проверка данных недостаточно строгая, то данные могут быть повреждены и пользователи заметят это. Для того чтобы найти верный баланс, проверяйте только постоянные величины, которые вызывают проблемы у пользователей.
Например, сервис Google Drive периодически проверяет, соответствует ли содержимое файла листингам в каталогах Drive. Если эти два элемента не соответствуют друг другу, данные некоторых файлов будут утрачены — наступят катастрофические последствия. Разработчики инфраструктуры сервиса Drive приложили столько усилий к обеспечению целостности данных, что вдобавок к этому улучшили свои валидаторы так, чтобы они автоматически исправляли подобные несоответствия.
Эта мера безопасности в 2013 году превратила требующую срочного вмешательства ситуацию потери данных: «Свистать всех наверх! О боже мой, файлы пропадают!» в обычную: «Пойдемте домой, причину исправим в понедельник». Преобразуя неотложные ситуации в обычные, валидаторы помогают повысить моральный дух инженеров, качество жизни и предсказуемость.
Внеполосные валидаторы могут дорого обойтись в случае масштабирования. Для проверки значительной части вычислительных ресурсов сервиса Gmail потребуется целая группа ежедневно запускаемых валидаторов. Повышают эти расходы валидаторы, которые одновременно снижают частоту попаданий кэша на стороне сервера, уменьшая скорость ответа сервера пользователям. Для того чтобы сгладить последствия подобной потери обратной связи, сервис Gmail предоставляет набор рычагов управления для ограничения скорости своих валидаторов и периодически проводит их рефакторинг, чтобы снизить количество состязаний за диск. В ходе выполнения такого рефакторинга мы уменьшили количество состязаний за дисководы на 60 %. Несмотря на то что большая часть валидаторов для сервиса Gmail запускаются каждый день, нагрузка самого крупного из них разделена на 10–14 сегментов и ежедневно запускается проверка только одного сегмента.
Google Compute Storage — это еще один пример сложности обеспечения сохранности данных, которую привносит масштабирование. Когда внеполосные валидаторы не могут завершить свою работу в течение дня, инженеры, отвечающие за сервис Compute Storage, должны придумать более эффективный способ проверять метаданные вместо того, чтобы использовать исключительно метод ручного перебора. По аналогии с восстановлением данных многоуровневая стратегия также может оказаться полезной при внеполосной проверке данных. По мере масштабирования сервиса пожертвуйте строгостью ежедневных валидаторов. Убедитесь, что валидаторы, работающие ежедневно, продолжают отлавливать наиболее аварийные сценарии в течение 24 часов, но выполняйте более строгие проверки с меньшей частотой, для того чтобы сдержать рост стоимости и уменьшить задержку.
Поиск проблем в давших сбой проверках может потребовать значительных усилий. Причины прерывания таких проверок могут исчезнуть через минуты, часы или дни. Поэтому способность быстро разобраться в журналах проверки очень важна. Продуманные и завершенные сервисы компании Google предоставляют дежурным инженерам полную документацию и инструменты для поиска проблем. Например, инженеры, обслуживающие сервис Gmail, имеют в своем распоряжении:
• набор рекомендаций, описывающих, как нужно реагировать на оповещение о сбое проверки данных;
• инструмент исследования проблемы наподобие BigQuery;
• информационную панель проверки данных.
Для эффективной внеполосной проверки данных требуется все нижеперечисленное:
• управление задачами проверки;
• мониторинг, оповещения и информационные панели;
• функциональность для ограничения уровня;
• инструменты для поиска проблем;
• производственные сценарии;
• API для проверки данных, которые позволяют легко добавлять валидаторы и выполнять их рефакторинг.
Бо'льшая часть маленьких команд инженеров, с высокой скоростью разрабатывающих функциональность, не может позволить себе одновременно разрабатывать, создавать и поддерживать все эти системы. Если им придется делать это, результатом окажется нестабильное, ограниченное и затратное одноразовое решение, которое быстро станет неремонтируемым. Поэтому вам следует структурировать свои команды инженеров так, чтобы основная команда, отвечающая за инфраструктуру, предоставила фреймворк проверки данных для остальных команд, занимающихся разработкой продукта. Основная команда, занимающаяся инфраструктурой, поддерживает фреймворк внеполосной проверки данных, а команды разработчиков продуктов поддерживают свою бизнес-логику, лежащую в основе валидатора, чтобы идти в ногу с развивающимися продуктами.
Знаем, что восстановление данных сработает
Когда лампочка перегорает? Тогда, когда щелчок на выключателе не приводит к включению света? Не всегда — зачастую лампочка уже перегорела, и вы замечаете это из-за того, что щелчок на выключателе не дает результатов. К этому моменту в комнате темно, и вы ударяетесь мизинцем.
Аналогично зависимости для восстановления данных (в большинстве случаев имеются в виду резервные копии) могут быть неисправными, о чем вы не будете знать до того, как попробуете восстановить с их помощью данные.
Если вы обнаружите, что процесс восстановления данных не работает, до того, как понадобится выполнить восстановление, то сможете справиться с уязвимостью, прежде чем станете ее жертвой: использовать другую резервную копию, предоставить дополнительные ресурсы и изменить целевые значения SLO. Но для того чтобы предпринимать превентивные действия, следует понять, что их вообще нужно предпринимать. Для обнаружения этих уязвимостей необходимо:
• постоянно тестировать процесс восстановления данных наряду с другими повседневными операциями;
• настроить оповещения, которые срабатывают, когда процесс восстановления не может выдать контрольные сигналы, информирующие о его успехе.
Что может пойти не так с процессом восстановления? Все что угодно. И именно поэтому единственный тест, который позволит вам ночью спокойно спать, — это полный сквозной тест. Но лучше один раз увидеть, чем сто раз услышать. Даже если вы недавно успешно выполнили восстановление данных, некоторые части процесса восстановления все равно могут оказаться недействующими. Если из этой главы вы вынесете всего один урок, то пусть он будет следующим: вы сможете узнать, что данные подлежат восстановлению, только когда восстановите их.
Если тест восстановления данных — это действие, выполняемое вручную в несколько этапов, тестирование становится очень неприятной работой, которая выполняется либо недостаточно глубоко, либо недостаточно часто. Поэтому следует автоматизировать эти тесты, когда возможно, и постоянно выполнять их.
Существует множество аспектов плана восстановления, которые нуждаются в подтверждении.
• Являются ли резервные копии полными и корректными или же они пусты?
• Имеется ли у вас достаточное количество вычислительных ресурсов для того, чтобы выполнить всю настройку, восстановление и постобработку задач, из которых состоит процесс восстановления?
• Выполняется ли процесс восстановления данных за разумное время?
• Можно ли наблюдать за состоянием процесса восстановления данных по мере его выполнения?
• Свободны ли вы от критической зависимости от ресурсов, неподконтрольных вам, таких как доступ к хранилищу накопителей, которое находится за пределами площадки и к которому нельзя получать доступ все 24 часа 7 дней в неделю?
Тестирование выявило упомянутые ранее сбои, а также сбои многих других компонентов успешного восстановления данных. Если бы мы не обнаружили эти сбои в обычных тестах, то есть если бы столкнулись с ними в момент, когда понадобилось бы восстановить данные в критический ситуации, вполне возможно, что наиболее успешные продукты компании Google не прошли бы проверку временем.
Сбоев избежать нельзя. Если вы оттягиваете их обнаружение до момента, когда окажетесь перед лицом реальной потери данных, то вы играете с огнем. Если в результате тестирования сбои происходят до того, как случится реальная катастрофа, вы сможете исправить проблемы, прежде чем они вам навредят.
Примеры
Как вы и предполагали, жизнь обеспечила нам неприятные и неизбежные возможности протестировать процессы восстановления данных под давлением реального мира. В этой книге рассматриваются два наиболее заметных и интересных примера такого тестирования.
Gmail — февраль 2011 года: восстановление с помощью GTape
Первый пример, который мы рассмотрим, уникален в нескольких смыслах: потерю данных вызвало множество причин и нам пришлось много работать с последней линией обороны — системой GTape, предназначенной для выполнения резервного копирования в режиме офлайн.
Воскресенье, 27 февраля 2011 года, поздний вечер
На пейджер инженеров, обслуживающих систему резервного копирования сервиса Gmail, поступило сообщение, которое содержало телефонный номер для участия в конференции. Произошло то, чего мы так долго опасались и что являлось основной причиной существования системы резервного копирования, — сервис Gmail потерял значительный объем данных пользователей. Несмотря на множество мер безопасности, внутренних проверок и избыточных элементов, данные Gmail исчезли.
Это было первое крупномасштабное применение GTape — глобального сервиса резервного копирования для сервиса Gmail — для восстановления пользовательских данных. К счастью, мы выполняли такое восстановление не впервые, поскольку моделировали подобные ситуации много раз. Так что мы смогли сделать следующее:
• оценить, сколько времени потребуется для восстановления бо'льшей части пострадавших учетных записей;
• в течение нескольких часов восстановить все учетные записи, исходя из первоначальной оценки;
• восстановить свыше 99 % данных до того, как истечет запланированное время.
Была ли удачей способность сформулировать такую оценку? Нет — наш успех стал результатом планирования, применения оптимальных приемов и кооперации, и мы были рады увидеть, что наш вклад в каждый из этих элементов оправдал себя. Мы смогли своевременно восстановить данные, выполнив план, разработанный в соответствии с лучшими методами глубокой защиты и подготовки к неотложным ситуациям.
Когда компания Google публично заявила, что мы восстановили данные с помощью не афишированной ранее системы резервного копирования на носители на магнитной ленте [Sloss, 2011], люди были удивлены. Накопители на ленте? Разве у компании Google нет множества дисков и быстрой сети для репликации таких важных данных? Конечно, у компании Google есть такие ресурсы, но принцип глубокой защиты гласит, что мы должны обеспечить несколько слоев защиты для того, чтобы застраховаться от сбоя любого единственного механизма защиты.
Создание резервных копий онлайн для систем вроде Gmail обеспечивает глубокую защиту из двух слоев:
• при сбое внутренней избыточности сервиса Gmail и систем выполнения резервного копирования;
• при широкомасштабных сбоях или уязвимости нулевого дня в драйвере устройства или в файловой системе, которая влияет на лежащие в его основе медиаустройства (диск).
Этот сбой появился на основе первого сценария — несмотря на то что для сервиса Gmail имелись внутренние средства восстановления утраченных данных, эту потерю восстановить с их помощью не удалось.
Одними из наиболее почитаемых в нашей компании факторов восстановления данных сервиса Gmail были степень скооперированности и четкая координация процесса восстановления. Многие команды, часть из которых не были связаны с сервисом Gmail или восстановлением данных, взялись нам помогать. Восстановление не прошло бы успешно и гладко, если бы не существовало основного плана руководства такой сложной операцией. Этот план был продуктом регулярных репетиций и прогонов вхолостую.
Готовясь к ситуациям, требующим неотложного вмешательства, мы начали считать такие сбои неизбежными. Принимая эту неизбежность, мы не надеемся, что нам удастся избежать этих катастроф, а также можем прогнозировать их появление. Поэтому нам нужен план того, как справляться не только с ожидаемыми сбоями, но и с каким-то количеством случайных универсальных сбоев.
Короче говоря, мы всегда знали, что следует использовать лишь наилучшие методы, и было приятно увидеть, что это правило оказалось верным.
Google Music — март 2012 года: определение бесконтрольного удаления данных
Второй сбой, который мы рассмотрим, повлек за собой трудности в логистике, уникальные для восстанавливаемого хранилища данных: где вы храните более 5000 лент и как эффективно (или даже реалистично) считываете такое количество данных с офлайн-носителей в разумный промежуток времени?
Вторник, 6 марта 2012 года, вторая половина дня
Обнаружение проблемы. Пользователь сервиса Google Music сообщает о том, что треки, которые ранее были проблемными, теперь оказываются пропущенными. Команда, ответственная за взаимодействие с пользователями сервиса Google Music, оповещает инженеров. Проблему рассматривают как возможный сбой потоковой передачи мультимедиа.
Седьмого марта инженер, который исследовал проблему, обнаружил, что у метаданных невоспроизводимых треков отсутствуют ссылки, которые должны указывать на данные самой песни. Он удивлен. Очевидным решением является поиск аудиоданных и восстановление ссылок на них.
Однако инженеры компании Google гордятся своей культурой устранения основных причин проблемы, поэтому этот инженер копнул глубже. Когда он обнаружил причину нарушения сохранности данных, у него чуть не случился сердечный приступ: ссылка на аудиоданные была удалена защищающим приватность конвейером по удалению данных. Эта часть сервиса Google Music была разработана для того, чтобы удалять большие количества аудиозаписей в рекордные сроки.
Оценка ущерба. Политика конфиденциальности компании Google защищает личные данные пользователя. Для сервиса Google Music это означает, что файлы музыки и релевантные метаданные удаляются в течение разумного промежутка времени после того, как их удаляет пользователь. По мере взлета популярности сервиса Google Music объем данных быстро увеличивался, поэтому в 2012 году оригинальная реализация должна была быть перепроектирована для повышения эффективности. Шестого февраля обновленный конвейер удаления данных был запущен в первый раз и удалил релевантные метаданные.
В тот момент показалось, что все в порядке, поэтому мы позволили на следующем шаге удалить также связанные с этими метаданными аудиоданные.
Мог ли оказаться реальностью худший кошмар инженера? Работник немедленно забил тревогу, повысил приоритет этого случая до максимально возможного и сообщил о проблеме менеджерам и службе SRE. Небольшая команда разработчиков Google Music и SR-инженеры собрались для того, чтобы решить проблему, и конвейер-нарушитель был временно отключен для того, чтобы не увеличить количество пострадавших пользователей.
Проверить вручную метаданные миллиардов файлов, расположенных в нескольких дата-центрах, было бы невозможно. Поэтому команда создала быструю задачу MapReduce для оценки урона и в отчаянии ожидала ее завершения.
Восьмого марта инженеры получили результат и обмерли: процесс рефакторинга конвейер удаления данных «убил» примерно 600 000 ссылок на аудиоданные, которые не нужно было трогать, а это повлияло на аудиофайлы 21 000 пользователей. Поскольку быстрый конвейер диагностики сделал несколько упрощений, реальный масштаб урона оказался намного меньше.
Прошло больше месяца с тех пор, как конвейер удаления данных был запущен в первый раз и в итоге удалил сотни тысяч аудиозаписей, которые не должен был трогать. Можно ли было надеяться на то, что мы восстановим данные? Если бы треки не были восстановлены или были восстановлены недостаточно быстро, компании Google пришлось бы скрыть музыку от пользователей. Как мы могли не заметить такой сбой?
Решение проблемы. Одновременные идентификация ошибки и попытки восстановления.
Первый шаг решения проблемы заключался в том, чтобы идентифицировать сбой и определить, почему это произошло. До тех пор пока основная причина не определена и не исправлена, любые попытки восстановления данных были бы тщетными. Нам пришлось бы снова запустить конвейер, чтобы удовлетворить запросы пользователей, которые удалили свои аудиотреки, но это навредило бы ни в чем не повинным пользователям, которые продолжали бы терять купленную музыку или, что еще хуже, собственные кропотливо записанные аудиофайлы. Единственным способом избежать уловки-22 было быстрое исправление основной причины сбоя.
Мы не могли терять время до запуска процесса восстановления. Сами аудиотреки были сохранены на носители на магнитной ленте, но в отличие от примера с сервисом Gmail, носители с резервными копиями для сервиса Google Music были вывезены в офлайн-хранилища, поскольку это позволяло отвести больше места для объемных резервных копий пользовательских аудиоданных. Для того чтобы быстро восстановить возможность работать с сервисом для пострадавших пользователей, команда решила найти основную причину проблемы и параллельно получить расположенные за пределами площадки накопители (довольно затратный по времени вариант восстановления).
Инженеры разбились на две группы. Наиболее опытные SR-инженеры работали над восстановлением данных, а разработчики анализировали код удаления данных и пытались исправить ошибку, связанную с потерей данных. Из-за того что полного понимания основной проблемы не было, восстановление пришлось проводить в несколько этапов. Был определен первый пакет, состоящий из примерно полумиллиона аудиотреков, и в 4:54 пополудни по тихоокеанскому времени 8 марта команда, которая отвечала за систему восстановления данных с помощью носителей на магнитной ленте, была оповещена о попытке восстановления данных.
На команду восстановления работал один фактор: процесс восстановления проходил спустя всего лишь несколько недель после проведения внутри компании ежегодной тренировки по восстановлению данных (см. [Krishan, 2012]). Команда восстановления с носителей на магнитной ленте уже знала о возможностях и ограничениях их подсистем, которые были субъектами тестирования Dirt, и начала сдувать пыль с нового инструмента, который протестировала во время тренировки. Используя этот инструмент, объединенная команда восстановления начала кропотливый процесс проверки сотен тысяч аудиозаписей.
Таким образом команда определила, что процесс начального восстановления потребует доставки более чем 5000 носителей на грузовике. После этого техники дата-центра должны будут освободить место для лент в соответствующих библиотеках. Затем начнется долгий и сложный процесс регистрации лент и извлечения данных с них, что потребует, в частности, использования обходных путей и сглаживания последствий на случай, если ленты или диски окажутся плохими.
К сожалению, в резервных копиях были найдены только 436 223 из примерно 600 000 потерянных аудиозаписей, что означало, что около 161 000 аудиозаписей были «съедены» еще до того, как могла быть сделана их резервная копия. Команда восстановления решила определить, как можно было бы восстановить 161 000 отсутствующих аудиозаписей, после того как был запущен процесс восстановления аудиозаписей, для которых имелись резервные копии.
В то же время команда, которая искала основную причину, сделала ложное заключение, а затем отказалась от него: сначала они думали, что сервис хранения, от которого зависел сервис Google Music, предоставил данные, содержащие ошибку, что заставило конвейер удалить неверные данные. Более тщательное расследование показало, что эта теория неверна. Члены команды, искавшие основную причину, почесали голову и продолжили искать неуловимую ошибку.
Первый этап восстановления. Как только команда, отвечавшая за восстановление, определила нужные резервные копии, а это произошло 8 марта, была предпринята первая попытка восстановления. Запрос 1,5 Пбайт данных, распределенных между тысячами лент из хранилища, — это одна проблема, но извлечение данных с лент — совершенно другая. Наш стек для работы с резервными копиями, записанными на ленты, не был спроектирован так, чтобы обработать одну операцию по восстановлению такого масштаба, поэтому пришлось разбить эту задачу на 5475 задач поменьше. Для выполнения такого количества операций по восстановлению от человека-оператора потребовалось бы вводить по одной команде каждую минуту на протяжении трех дней, и, несомненно, он допустил бы множество ошибок. Только для того чтобы запросить восстановление с помощью системы резервного копирования, SR-инженерам пришлось разрабатывать программное решение.
К полуночи 9 марта SR-инженеры закончили запрашивать выполнение всех 5475 операций восстановления. Система резервного копирования начала колдовать над восстановлением. Четыре часа спустя она выдала список из 5337 резервных копий, которые нужно было вернуть из мест их размещения вне дата-центра. Еще через 8 часов ленты прибыли в дата-центр на грузовиках.
Пока машины были в дороге, техники дата-центра отключили от обслуживания несколько библиотек, работающих с лентами, и удалили тысячи лент, чтобы освободить место для масштабной операции по восстановлению данных. Когда ранним утром тысячи лент прибыли, техники начали кропотливо загружать их вручную. Проведенные ранее тренировки с помощью DiRT показали, что этот ручной процесс при выполнении крупных операций в сотни раз быстрее, чем основанные на использовании роботов методы, которые приняты у поставщиков библиотек работы с лентами. В течение 3 часов библиотеки снова были включены и начали сканировать ленты и выполнять тысячи операций восстановления для распределенного вычислительного хранилища.
Несмотря на то что команда уже имела опыт работы с DiRT, масштабное восстановление 1,5 Пбайт данных продлилось больше двух дней, которые мы на него отводили. К утру 10 марта только 74 % от 436 223 аудиофайлов были успешно переведены из 3475 полученных резервных копий в распределенное хранилище файловой системы в ближайшем компьютерном кластере. Еще 1862 резервные копии были пропущены поставщиком. Вдобавок процесс восстановления приостановился из-за 17 плохих лент. В ожидании сбоя, связанного с плохими лентами, для создания резервных копий файлов была использована избыточная кодировка. В ходе дополнительной доставки на грузовиках были переданы лишние ленты вместе с 1862 лентами, которые были пропущены в первой партии.
К утру 11 марта операция восстановления была завершена более чем на 99,95 % и выполнялся возврат дополнительных лент для оставшихся файлов. Несмотря на то что данные уже находились в распределенных файловых системах, необходимо было предпринять еще несколько шагов для того, чтобы сделать их доступными пользователям. Команда Google Music начала осуществлять эти шаги восстановления данных параллельно для небольшого фрагмента восстановленных аудиофайлов, чтобы убедиться, что процесс выполняется в соответствии с ожиданиями.
В этот момент пейджеры команды Google Music сообщили о не связанном с предыдущими событиями критическом сбое, который влиял на пользователей, — команда потратила еще на два дня на его устранение. Процесс восстановления данных продолжился 13 марта, когда все 436 223 аудиозаписи снова стали доступными для пользователей. Почти за семь дней 1,5 Пбайт данных были восстановлены с помощью резервных копий, пять дней из них занял сам процесс восстановления данных.
Второй этап восстановления. Когда первая волна процесса восстановления данных прошла, команда переключилась на 161 000 отсутствующих аудиофайлов, которые были удалены из-за ошибки еще до того, как мы смогли сделать их резервные копии. Бо'льшая часть этих файлов была куплена в магазинах и являлась рекламными треками, а оригинальные копии в магазинах не были затронуты ошибкой.
Эти треки были быстро восстановлены, и пользователи снова могли наслаждаться музыкой.
Однако небольшую часть 161 000 аудиофайлов пользователи загрузили самостоятельно. Команда Google Music дала задание своим серверам попросить клиентов перезагрузить файлы 14 марта и позже. Данный процесс занял больше недели. Этим завершился полный процесс восстановления после инцидента.
Решение основной проблемы. В итоге команда разработчиков Google Music определила, в чем заключается недостаток конвейера удаления данных. Для того чтобы это понять, вы сперва должны узнать, как офлайн-системы обработки данных развиваются в больших масштабах.
Для больших и сложных сервисов, состоящих из нескольких подсистем и сервисов хранения, даже такая простая задача, как уничтожение удаленных данных, должна выполняться в несколько этапов, каждый из который задействует разные хранилища данных.
Для того чтобы обработка данных завершалась быстро, ее распараллеливают между десятками тысяч машин, которые распределяют большую нагрузку на разные подсистемы. Это может замедлить работу сервиса для пользователей или спровоцировать сбой при большой нагрузке. Чтобы избежать этих нежелательных сценариев, инженеры, занимающиеся облачными вычислениями, зачастую делают недолговременную копию данных во вторичном хранилище, где затем выполняется обработка данных. Если относительный возраст вторичных копий не координируется, такая практика приводит к состоянию гонки.
Например, два этапа конвейера могут быть спроектированы так, чтобы работать строго друг за другом с промежутком 3 часа, чтобы второй этап мог сделать упрощающее допущение о корректности своих входных данных. Без этого допущения логику второго этапа может быть трудно распараллелить. Но по мере роста объемов данных выполнение этапов может занимать больше времени. В итоге предположения, сделанные для оригинального проекта, могут оказаться неверными для некоторых фрагментов данных, необходимых на втором этапе.
Поначалу гонки могут происходить для небольших фрагментов данных. Но по мере увеличения объема данных они могут затрагивать все большие и большие фрагменты данных. Такой сценарий является вероятным — конвейер работает корректно для большей части данных большую часть времени. Когда случаются гонки в конвейере удаления данных, случайно могут быть удалены неверные данные.
Конвейер удаления данных для Google Music был разработан с учетом возможных ошибок. Но когда по мере роста сервиса предшествующие этапы конвейера начали требовать большего количества времени, мы выполнили оптимизацию производительности для того, чтобы сервис Google Music мог продолжить соответствовать требованиям к приватности. В результате вероятность непреднамеренно удаляющего данные состояния гонки в этом конвейере начала повышаться. Когда конвейер прошел рефакторинг, она снова значительно возросла до точки, когда гонки стали происходить более регулярно.
По результатам процесса восстановления команда разработчиков Google Music перепроектировала конвейер обработки данных и избавилась от гонок. К тому же мы улучшили наблюдение за производственной средой и настроили системы оповещения, чтобы обнаруживать аналогичные крупномасштабные бесконтрольные ошибки, связанные с удалением данных, и исправлять такие проблемы до того, как пользователи их заметят.
Общие принципы SRE, применяемые для сохранности данных
Общие принципы SRE могут быть применены в области сохранности данных и облачных вычислений, как показано в этом разделе.
Мышление новичка
В крупномасштабных сложных системах имеются заложенные изначально ошибки, которые невозможно исследовать полностью. Никогда не думайте, что вы разбираетесь в работе крупной системы достаточно хорошо для того, чтобы сказать, что она не даст определенный сбой. Доверяйте, но проверяйте и применяйте глубокую защиту.
Доверяй, но проверяй
Любой API, от которого вы зависите, не будет все время идеально работать. Учитывайте, что независимо от качества вашей инженерной работы или тестирования API будет иметь дефекты. Проверяйте корректность наиболее критических элементов данных, применяя внеполосные валидаторы, даже если семантика API предполагает, что этого делать не нужно. Идеальные алгоритмы могут не иметь идеальной реализации.
Надежда — плохая стратегия
Системные компоненты, которые используются непостоянно, дадут сбой в тот момент, когда они нужнее всего. Докажите, что процесс восстановления данных работает, регулярного применяя его, или же он просто не будет функционировать. Людям не хватает терпения постоянно тестировать системные компоненты, поэтому в данном вопросе автоматизация — ваш друг. Однако, когда вы нанимаете для написания решения по автоматизации инженера, имеющего конкурирующие приоритеты, вам может понадобиться найти ему временную замену.
Глубокая защита
Даже наиболее устойчивая система подвержена воздействию багов и ошибок операторов. Для того чтобы можно было исправить проблемы, связанные с сохранностью данных, сервисы должны быстро определять такие проблемы. Любая стратегия непременно даст сбой в изменяющихся средах. Наилучшими стратегиями сохранения данных являются многоуровневые стратегии — несколько стратегий, которые используются совместно, решают широкий диапазон сценариев и имеют разумную стоимость.
| Возвращайтесь и перепроверяйте То, что данные были в порядке вчера, никак не поможет вам завтра и даже сегодня. Системы и инфраструктуры меняются, и нужно доказывать, что ваши предположения и процессы остаются релевантными перед лицом прогресса. Подумайте о следующем. Сервис Shakespeare получил высокие оценки в прессе, и число его пользователей постепенно увеличивается. Но при сборке сервиса не было уделено достаточно внимания сохранности данных. Конечно, мы не хотим, чтобы сервис поставлял плохие биты, но если индекс для Bigtable будет потерян, мы легко сможем восстановить его с помощью оригинальных текстов Шекспира и MapReduce. Это займет совсем немного времени, поэтому мы никогда не делаем резервных копий индекса. Теперь рассмотрим ситуацию, когда новая функциональность позволит пользователям создавать текстовые аннотации. Оказывается, наше множество данных не может быть с легкостью восстановлено, при этом ценность пользовательских данных будет постоянно повышаться. Поэтому нужно пересмотреть варианты репликации — мы выполняем ее не только для того, чтобы улучшить показатели задержки и полосы пропускания, но и чтобы обеспечить сохранность данных. Эта процедура также периодически тестируется на практических занятиях по использованию DiRT для того, чтобы гарантировать, что мы можем восстановить пользовательские аннотации из резервных копий ко времени, указанному в SLO. |
Итоги главы
Обеспечение доступности данных — важнейшая задача любой системы, основанной на работе с данными. Не зацикливаясь на одних лишь инструментах, SR-инженеры считают полезным позаимствовать также идеи разработки, управляемой тестированием, и убедиться, что наши системы действительно смогут обеспечить доступность данных с прогнозируемым значением времени отключения не хуже заданного. Методы и средства, которые мы используем для достижения этой цели, являются необходимым злом. Сосредоточившись на этой цели, мы избегаем ловушки, когда «операция была выполнена успешно, но система погибла». Понимание того, что «не так» может пойти не «что-то», а сразу все, — это большой шаг навстречу подготовке к реальной чрезвычайной ситуации. Сценарии всех возможных комбинаций катастроф и планы реагирования на них позволят вам крепко спать как минимум одну ночь, поддерживаемые в актуальном состоянии планы восстановления позволят вам спать и остальные 364 ночи в году.
По мере того как вы научитесь восстанавливаться после любого сбоя за разумное время N, найдите способы сократить его за счет более быстрого и качественного выявления потерь, поставив перед собой цель приблизиться к значению N = 0. Далее можете переключиться с планирования восстановления на планирование предотвращения проблем, стремясь достичь Святого Грааля всех данных всех времен. Добейтесь этой цели — и сможете спать на пляже во время заслуженного отпуска.
Atomicity, Consistency, Isolation, Durability — атомарность, согласованность, изолированность, долговечность, см. . Базы данных SQL, такие как MySQL и PostgreSQL, стремятся соответствовать этим свойствам.
Basically Available, Soft state, Eventual consistency — доступность в большинстве случаев, неустойчивое состояние, согласованность в конечном счете, см. . Системы, основанные на семантике BASE, наподобие Bigtable или Megastore, зачастую описываются как NoSQL.
Для получения более полной информации о семантиках ACID и BASE обратитесь к [Golab, 2014] и [Bailis, 2013].
Binary Large Object — двоичный большой объект, см. .
См. ).
Глиняные таблички — это старейший из известных примеров письма. Для того чтобы получить более подробную информацию о сохранении данных на длительный срок, см. [Conway, 1996].
Во время чтения этого совета кто-то может задаться вопросом: если вам нужно предоставить API на базе хранилища данных для того, чтобы реализовать мягкое удаление, зачем ограничивать себя только им, если можно обеспечить обширную функциональность, которая поможет защитить данные от случайного удаления пользователями? В качестве примера приведем реальную ситуацию, произошедшую в компании Google, и рассмотрим Blobstore: вместо того чтобы позволить клиентам непосредственно удалять данные и метаданные, API для Blob реализовал широкую функциональность для безопасности, включая политику создания резервных копий (офлайн-реплики), сквозные контрольные суммы и периоды существования по умолчанию (мягкое удаление). Оказалось, что во многих случаях мягкое удаление спасало клиентов Blobstore от потери данных, которая могла все усложнить. Конечно, обширную функциональность для защиты от удаления стоит реализовать, но для компаний, имеющих конкретные сроки удаления данных, мягкое удаление — это наиболее подходящая защита от ошибок и случайного удаления, как и в случае Blobstore.
Снимок в этом контексте является статическим экземпляром хранилища, предназначенным только для чтения, например снимок базы данных SQL. Снимки зачастую реализуются с помощью семантики «копирования при записи» для эффективности хранения. Они могут быть дорогими по двум причинам: во-первых, они соперничают за работу с той же производительностью, что и работающие хранилища данных, и во-вторых, чем быстрее изменяются данные, тем менее эффективным будет копирование при записи.
Чтобы получить более подробную информацию о репликации GFS, см. [Ghemawat, 2003]. Для получения более подробной информации о кодах Рида — Соломона см. .
См. ).
На практике создать программное решение было нетрудно, поскольку большая часть SR-инженеров имеет опыт разработки ПО. Необходимость такого опыта значительно усложняет процесс поиска и найма SR-инженеров, и теперь вы наконец понимаете, почему в службу SRE нанимают практикующих инженеров-программистов; см. [Jones, 2015].
Из нашего опыта, инженеры, занимающиеся облачными вычислениями, зачастую не хотят настраивать производственные оповещения для удаления данных из-за естественных отклонений в количестве удаляемых пользователями данных. Но поскольку такие оповещения предназначены для определения глобального, а не локального удаления данных, полезнее будет оповещать о том, что выполняется удаление большого количества данных, собранных для всех пользователей, которое превышает определенную границу (например, 10х от наблюдаемого 95-го процентиля), чем рассылать менее полезные уведомления об удалении данных каждому пользователю индивидуально.

