24. Cron: планирование и расписание в распределенных системах
Автор — Штепан Давидович
Под редакцией Кавиты Гулианы
В этой главе описывается реализация компанией Google сервиса cron, обслуживающего большинство внутренних команд, которым нужно периодическое планирование вычислительных задач. На протяжении всего периода существования сервиса cron мы усвоили много уроков, касающихся проектирования и реализации того, что может показаться простым сервисом. Здесь мы обсудим проблемы, с которыми сталкиваются распределенные реализации сервиса cron, и покажем некоторые потенциальные решения.
Cron — это широко распространенная утилита Unix, спроектированная для периодического запуска произвольных пользовательских задач в заданные время или интервалы времени. Сначала мы проанализируем основные принципы cron и ее самые распространенные реализации, далее рассмотрим, как приложение наподобие cron может работать в крупных распределенных средах для того, чтобы повысить надежность систем при сбое одной машины. Мы опишем распределенную систему cron, которая развернута на небольшом количестве машин, но может запускать задачи cron во всем дата-центре вместе с системой планирования для дата-центра, такой как Borg [Verma, 2015].
Cron
Рассмотрим, как сервис cron обычно используется на одной машине, прежде чем рассматривать варианты его запуска как сервиса, который работает для нескольких дата-центров.
Введение
Сервис cron спроектирован таким образом, что системные администраторы и обычные пользователи могут указывать необходимые для запуска команды, а также время, когда их нужно запустить. Сервис cron выполняет разные виды работ, включая сборку мусора и периодический анализ данных. Наиболее распространенный формат указания времени называется crontab. Он поддерживает простые интервалы (например, «каждый полдень» или «в начале каждого часа»). Вы также можете задать сложные интервалы, например «каждую субботу, если она приходится на 30-е число месяца».
Сервис cron обычно реализуется с помощью одного компонента, который называют crond. crond — это демон, который загружает список запланированных задач сервиса cron. Эти задачи запускаются в соответствии с заданным временем выполнения.
Надежность
Некоторые аспекты сервиса cron следует рассмотреть с точки зрения надежности.
• Его область отказа, по сути, является одной машиной. Если машина не работает, то ни планировщик, ни задачи, которые он должен запустить, не будут запущены. Рассмотрим очень простой случай: есть две машины, для которых планировщик запускает задачи на другой рабочей машине (например, с помощью SSH). Этот сценарий представляет две отдельные области отказа, которые могут повлиять на способность запускать задачи: могут дать сбой либо машина-планировщик, либо машина-получатель.
• Единственное состояние, которое нужно сохранить при перезапусках crond, включая перезагрузки самой машины, — это конфигурация crontab. Запуски cron работают по принципу «запустил и забыл», и crond даже не пытается отследить их.
• anacron является заметным исключением из этого правила. anacron пытается запускать задачи, которые должны были быть запущены, пока система была отключена. Возможность перезапуска ограничена задачами, которые запускаются раз в день или реже. Эта функциональность очень полезна для запуска заданий по обслуживанию на рабочих станциях и ноутбуках, ее поддерживает файл, в котором сохраняются временные метки последнего запуска для всех зарегистрированных задач cron.
Задачи cron и идемпотентность
Задачи cron разработаны для того, чтобы выполнять повторяющуюся работу, но, помимо этого, трудно знать заранее, какие функции они получат. Разнообразие требований, которое влечет за собой широкий набор задач cron, очевидным образом влияет на требования к надежности.
Некоторые задачи cron, например процессы сборки мусора, являются идемпотентными. В случае сбоя системы будет безопасно запустить их несколько раз. Другие задачи cron, например процессы, которые отправляют новости по электронной почте большому кругу получателей, не должны запускаться больше одного раза.
Ситуацию усложняет тот, что для одних задач cron сбой запуска приемлем, а для других — нет. Например, запланировано выполнять задачу по сборке мусора каждые пять минут, и один запуск можно пропустить, но задача cron, отвечающая за начисление зарплаты и запускающаяся раз месяц, не может быть пропущена.
Такое разнообразие задач cron затрудняет рассуждения о типах сбоев: системы вроде cron не дают единого ответа, который подошел бы для всех ситуаций. В общем случае мы предпочитаем пропускать запуски, чем рисковать, запуская задачу дважды, насколько это позволяет инфраструктура. Мы выбираем такой вариант, потому что восстановиться после пропущенного запуска проще, чем после двойного. Владельцы задач cron могут (и должны!) наблюдать за своими задачами. Например, владелец может заставить сервис cron показывать состояние управляемых им задач или настроить независимое наблюдение за воздействием, которое оказывают эти задачи. В случае пропущенного запуска владельцы задач cron могут действовать в соответствии с природой задачи cron. Однако ликвидировать последствия двойного запуска, например, упомянутой рассылки новостей может быть трудно или невозможно. Поэтому мы предпочитаем «закрываться при отказе», для того чтобы избежать систематического возникновения плохого состояния.
Масштабирование Cron
Переход от отдельных компьютеров к крупномасштабным развертываниям требует фундаментального пересмотра способа заставить cron хорошо работать в такой среде.
Перед тем как представить детали решения компании Google, мы обсудим различия между развертываниями в малом и крупном масштабе, а также опишем, как нужно изменить проект для проведения крупномасштабных развертываний.
Расширенная инфраструктура
В своих обычных реализациях сервис cron ограничен одной машиной. Крупномасштабные развертывания распространяют решение на несколько машин.
Размещение сервиса cron на одной машине может быть катастрофическим с точки зрения надежности. Предположим, что такая машина находится в дата-центре, содержащем 1000 машин. Сбой всего 1/1000-й из доступного парка отключит весь сервис cron. По очевидным причинам такая реализация неприемлема.
Для того чтобы повысить надежность сервиса cron, мы отвязываем процессы от машин. Если вы хотите запустить сервис, просто укажите требования к нему и дата-центр, в котором он должен быть запущен. Система планирования для дата-центров (которая должна быть надежной сама по себе) определяет машину или машины, на которых следует развернуть сервис, а вдобавок обрабатывает «падения» машин. Запуск задачи в дата-центре, по сути, станет отправкой одной или нескольких RPC планировщику дата-центра.
Однако этот процесс нельзя назвать мгновенным. Определение мертвых машин влечет за собой тайм-ауты для проверки состояния, а перевод сервиса на другую машину потребует времени для установки ПО и запуска нового процесса.
Поскольку перемещение процесса на другую машину зачастую означает потерю состояния, хранимого локально на старой машине (если только не используется живая миграция), а время на перепланирование может превысить минимальный интервал, равный 1 минуте, нужны процедуры для того, чтобы смягчить как негативные последствия потери данных, так и повышенные требования к времени. Вы можете при необходимости сохранить состояние старых машин в распределенной файловой системе наподобие GFS, а затем использовать ее во время запуска для того, чтобы определить задачи, давшие сбой из-за перепланирования. Однако такое решение не оправдывает ожиданий, связанных со своевременностью: если вы будете запускать задачу cron каждые 5 минут, задержка 1 или 2 минуты, вызванная общей загрузкой системы перепланирования, потенциально может быть неприемлемо весомой. В таком случае горячий резерв, который способен быстро включиться и возобновить работу, может значительно сократить это временное окно.
Расширенные требования
В одномашинных системах все работающие процессы обычно изолируются лишь в ограниченной степени. Несмотря на то что контейнеры сейчас широко распространены, нет необходимости использовать их для изоляции каждого компонента сервиса, который развернут на одной машине. Поэтому, если cron был развернут на одной машине, crond и все задачи cron, которые он запускает, скорее всего, не будут изолированы.
Развертывание в масштабе дата-центра обычно означает развертывание в контейнеры с принудительной изоляцией. Изоляция в этом случае необходима, поскольку все базируется на том, что независимые процессы, запущенные в одном дата-центре, не должны негативно влиять друг на друга. Для того чтобы выполнить это, вы должны знать количество ресурсов, которые понадобятся для того, чтобы запустить любой желаемый процесс, как для системы cron, так и для задач, которые она запускает. Задача cron может быть отложена, если ресурсов дата-центра недостаточно для того, чтобы соответствовать ее запросам. Требования к ресурсам, в дополнение к спросу пользователей на наблюдение за запусками задач cron, означают, что нужно отслеживать состояние запусков задач cron в целом, начиная от запланированного запуска до их отключения.
Отвязывание запуска процессов от конкретной машины грозит системе cron частичным сбоем при запуске. Гибкость конфигурации задач cron также означает, что для запуска новой задачи cron в дата-центре может понадобиться несколько RPC, таким образом, иногда мы сталкиваемся со сценарием, когда некоторые RPC выполняются успешно, а некоторые — нет, например, из-за того, что процесс, отправляющий RPC, «умер» во время выполнения этих задач. Процедура восстановления cron также должна учитывать этот сценарий.
С точки зрения типов сбоев дата-центр является значительно более крупной экосистемой, чем одна машина. Сервис cron, который начал свой путь как относительно простой бинарный файл, при развертывании в больших масштабах имеет множество очевидных и неочевидных зависимостей. Мы хотим гарантировать, что, даже если дата-центр даст частичный сбой (например, из-за отключения питания или проблем с сервисами хранилища), сервис, такой же простой, как cron, все еще сможет функционировать. Требуя, чтобы планировщик дата-центра располагал реплики сервиса cron в разных локациях внутри дата-центра, мы избегаем сценария, при котором один элемент распределения питания даст сбой и это уничтожит все процессы сервиса cron.
Можно развернуть один сервис cron для всего мира, но развертывание сервиса внутри одного дата-центра имеет свои преимущества: сервис насладится малой задержкой и разделит судьбу с планировщиком дата-центра, от которого он в основном зависит.
Создание cron в Google
В этом разделе рассматриваются проблемы, которые должны быть решены для того, чтобы надежно развернуть крупномасштабный сервис cron. Также в нем подчеркиваются некоторые важные решения, сделанные для распределенного сервиса cron в компании Google
Отслеживание состояния задач cron
Как говорилось в предыдущих разделах, нам нужно удерживать какую-то информацию о состояниях задач cron и иметь возможность восстановить ее в случае сбоя. Более того, устойчивость этого состояния чрезвычайно важна. Вспомните: многие задачи cron наподобие расчета зарплаты или отправки новостной рассылки, не являются идемпотентными.
У нас есть два способа отслеживания задач cron:
• хранение данных снаружи в общедоступных распределенных хранилищах;
• использование системы, которая сохраняет небольшое количество информации о состоянии внутри самого сервиса cron.
При проектировании распределенного сервиса cron мы выбрали второй вариант. Остановились на нем по нескольким причинам.
• Распределенные файловые системы наподобие GFS или HDFS часто поддерживают очень большие файлы (например, выходных данных веб-краулеров), в то время как информация о задачах cron, которую нужно сохранить, незначительного размера. Небольшие операции записи для распределенных файловых систем выполнять очень дорого. Также нам придется столкнуться с большой задержкой, поскольку файловая система не оптимизирована для выполнения подобных операций записи.
• Базовые сервисы, на которые отключения будут серьезно влиять, например cron, должны иметь очень мало зависимостей. Даже если мы потеряем какую-то часть дата-центра, сервис cron должен функционировать еще какое-то время. Но это требование не означает, что хранилище должно стать непосредственной частью процесса cron (работа с хранилищем — это уже детали реализации). Однако сервис cron должен иметь возможность работать независимо от систем, расположенных далее в технологической цепочке, которые обслуживают большое количество внутренних пользователей.
Использование Paxos
Мы развертываем несколько реплик сервиса cron и используем алгоритм достижения распределенного консенсуса Paxos (см. главу 23), для того чтобы убедиться, что они устойчивы. До тех пор пока большая часть групп доступна, распределенная система может обрабатывать как единое целое изменения состояния, несмотря на природу связанных подмножеств инфраструктуры.
Распределенная система cron использует одну задачу-лидера, которая является единственной репликой, способной модифицировать общее состояние, а также запускать задачи cron (рис. 24.1). Мы воспользовались тем, что наш вариант протокола Paxos, Fast Paxos [Lamport, 2006], использует реплику-лидер для оптимизации — лидер-реплика протокола Fast Paxos выступает также в роли лидера сервиса cron.
Если реплика-лидер погибает, то механизм, проверяющий состояние группы Paxos, быстро определяет это — в течение нескольких секунд. Поскольку другой процесс cron уже запущен и доступен, можно выбрать нового лидера. Как только новый лидер выбран, мы следуем протоколу выбора лидера, характерному для сервиса cron, который отвечает за выполнение всей работы, оставленной предыдущим лидером. Лидер для сервиса cron является лидером также для протокола Paxos, но сервису cron нужно выполнить дополнительные действия. Высокая скорость реакции при перевыборе лидера позволяет оставаться в рамках приемлемого времени перехода, равного 1 минуте.
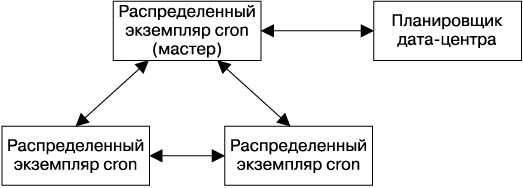
Рис. 24.1. Взаимодействия между распределенными репликами сервиса cron
Наиболее важное состояние, которое мы храним с помощью протокола Paxos, — это информация о том, какие задачи cron сейчас запущены. Мы синхронно информируем кворум реплик о начале и завершении каждой задачи cron.
Роли лидера и последователя
Как было описано ранее, протокол Paxos и его развертывания в сервисе cron имеют две роли: лидера и ведомого. В следующих разделах описана каждая из них.
Лидер
Реплика-лидер — единственная, которая активно запускает задачи cron. Лидер имеет внутренний планировщик, который, как и простой демон crond, описанный в начале этой главы, поддерживает список задач cron, упорядоченный по времени их запуска.
Реплика-лидер ожидает наступления времени запуска первой задачи. Когда это произойдет, она объявляет, что готова запустить задачу, и определяет новое время запуска, как сделала бы обычная реализация демона crond. Конечно же, как и в случае с обычным демоном crond, спецификация запуска задачи cron могла измениться с момента последнего запуска, поэтому она должна быть синхронизирована с последователями. Простой идентификации задачи cron недостаточно, мы также должны уникально идентифицировать конкретный запуск, используя время, в которое он выполняется, в противном случае при запуске задачи cron вы можете столкнуться с неоднозначностью. (Возникновение неоднозначности особенно вероятно в случае, если задачи стартуют каждую минуту.) Такое взаимодействие осуществляется с помощью протокола Paxos (рис. 24.2).
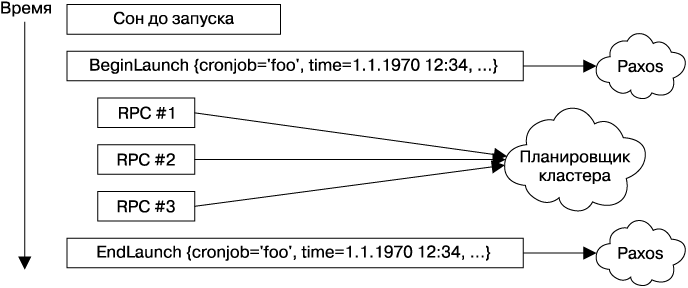
Рис. 24.2. Иллюстрация процесса запуска задачи cron с точки зрения лидера
Важно, чтобы взаимодействие, обеспечиваемое протоколом Paxos, оставалось синхронным и реальные запуски задач cron не происходили до того, как кворум протокола Paxos получит уведомление о запуске. Сервис cron должен понять, запущена ли каждая задача cron, для того чтобы определиться с действиями на случай перехода лидера на другой ресурс. Выполнение этой задачи асинхронно означает, что запуск задачи cron произойдет на лидере и об этом не будут знать другие реплики. В случае перехода реплики-последователи могут попробовать вновь выполнить тот же запуск, поскольку они не знают, что он уже состоялся.
О завершении запуска задачи cron другим репликам объявляется синхронно с помощью протокола Paxos. Обратите внимание на то, что неважно, насколько успешным будет этот запуск из-за внешних причин, например при недоступности планировщика дата-центра. Здесь мы просто отслеживаем тот факт, что сервис cron попытался выполнить запуск в запланированное время. Также нам нужно разрешить сбои системы cron в середине этой операции, что будет рассмотрено в следующем разделе.
Еще одна очень важная особенность лидера заключается в том, что как только он по какой-то причине теряет лидерство, то должен немедленно перестать взаимодействовать с планировщиком дата-центра. Удержание лидерства должно гарантировать взаимное исключение доступа к планировщику дата-центра. В отсутствие этого условия взаимного исключения старый и новый лидеры могут выполнять конфликтующие между собой действия на планировщике дата-центра.
Последователь
Реплики-последователи отслеживают состояние среды выполнения, предоставленное лидером, для того чтобы в любой момент взять управление на себя, если это необходимо. Все изменения состояния, отслеживаемые репликами-последователями, они получают с помощью протокола Paxos от реплики-лидера. Как и лидер, последователи должны поддерживать список всех задач cron системы, и этот список должен быть одинаковым во всех репликах (это достигается с помощью протокола Paxos).
При получении уведомления о произведенном запуске реплика-последователь обновляет локальное время следующего запуска для заданной задачи cron. Это очень важное изменение состояния, выполняемое синхронно, гарантирует, что все запланированные задачи cron внутри системы будут устойчивыми. Мы отслеживаем все открытые запуски (начатые, но не завершенные).
Если реплика-лидер погибает или работает неверно, например отсоединяется от других реплик сети, один из последователей должен быть выбран новым лидером. Выбор должен быть выполнен быстрее чем за 1 минуту, для того чтобы избежать риска пропустить или отложить запуск новых задач. Как только лидер будет выбран, все открытые запуски (то есть частичные сбои) должны быть завершены. Этот процесс может быть довольно сложным, предъявляющим дополнительные требования как к системе cron, так и к инфраструктуре дата-центра. В следующем разделе рассматривается разрешение подобных частичных сбоев.
Разрешение частичных сбоев
Как упоминалось ранее, взаимодействие между репликой-лидером и планировщиком дата-центра может дать сбой в процессе отправки нескольких RPC, которые описывают один логический запуск задач cron. Наши системы должны иметь возможность отследить этот состояние. Вспомним, что каждая задача cron имеет две точки синхронизации:
• когда мы готовы выполнить запуск;
• когда завершили запуск.
Эти две точки позволяют установить границы для запуска. Если запуск состоит из одной RPC, то как мы узнаем, что она действительно была отправлена? Рассмотрим случай, когда мы знаем, что запланированный запуск был начат, но мы не были оповещены о том, что он завершился перед тем, как реплика погибла.
Для того чтобы определить, была ли отправлена RPC, нужно, чтобы соблюдалось одно из следующих условий.
• Все операции для внешних систем, которые может понадобиться продолжить после перевыбора лидера, должны быть идемпотентными, то есть их можно безопасно выполнить снова.
• Должна существовать возможность выполнить поиск состояния всех операций для внешних систем, чтобы однозначно определить, завершились ли они.
Каждое из этих условий накладывает значительные ограничения, и их может быть трудно реализовать, но возможность соответствовать хотя бы одному из этих условий лежит в основе исправной работы сервиса cron в распределенной среде, в которой могут произойти один или несколько частичных сбоев. Недостаточно качественная обработка этих условий может привести к пропущенным или двойным вызовам задачи.
Большая часть инфраструктуры, которая запускает логические задачи в дата-центрах, например Mesos, предоставляет функциональность для именования этих задач, что позволяет выполнять поиск состояния задач, останавливать их или реализовывать другие виды обслуживания. Разумное решение проблемы идемпотентности заключается в предварительном создании имен задач (тем самым можно избежать создания мутирующих операций в планировщике дата-центра), а затем их распространении по всем репликам сервиса cron. Если лидер сервиса cron погибнет во время запуска, новый лидер просто выполнит поиск состояния всех заранее вычисленных имен и запустит задачи с недостающими именами.
Обратите внимание на следующий момент: как и при определении отдельных запусков задач cron с помощью их имени и времени запуска, важно, чтобы созданные имена задач содержали в планировщике дата-центра определенное время запуска или чтобы эту информацию можно было получить другим способом. В режиме плановой эксплуатации при сбое лидера сервис cron должен выполнять переход быстро, но так получается не всегда.
Давайте вспомним, что мы отслеживаем запланированное время запуска, когда сохраняем внутреннее состояние между репликами. Аналогично следует снимать неоднозначность взаимодействия с планировщиком дата-центра также с помощью запланированного времени запуска. Например, рассмотрим недолговечную, но часто запускаемую задачу cron. Задача cron запускается, но до того, как информация об этом отсылается всем репликам, лидер дает сбой и необычно долго выполняет переход — достаточно долго для того, чтобы задача успешно завершилась. Новый лидер выполняет поиск состояния этой задачи, видит, что она завершилась, и пытается выполнить ее снова. Если бы он знал о времени запуска, то понял бы, что задача в планировщике дата-центра появилась из-за этого вызова, и в таком случае двойного запуска не было бы.
Реальная реализация имеет более сложную систему поиска состояния, которой управляют детали реализации лежащей в ее основе инфраструктуры. Однако в приведенном здесь описании рассматриваются независимые от реализации требования к любой подобной системе. В зависимости от того, какая инфраструктура вам доступна, может понадобиться рассмотреть также возможность компромисса между риском двойного запуска и риском незапуска.
Сохраняем состояние
Использование протокола Paxos для достижения консенсуса — это только часть задачи сохранения состояния. Paxos, по сути, является журналом, хранящим изменения состояния, запись в который производится синхронно с выполнением изменений. Из этой характеристики протокола Paxos вытекает следующее.
• Чтобы журнал не разросся до бесконечности, он должен быть сжат.
• Журнал нужно где-то хранить.
Для того чтобы предотвратить бесконечное разрастание журнала Paxos, можно просто сделать снимок текущего состояния, что позволит восстановить его, не воспроизводя все изменения, записанные в журнале. Например, если в журнале сохранено изменение состояния «увеличить счетчик на 1», то после 1000 итераций у там будет 1000 записей, которые можно заменить на снимок «установить значение счетчика равным 1000».
Если журнал будет утрачен, мы потеряем лишь те изменения состояния, которые произошли после создания последнего снимка. Снимки фактически являются наиболее критической сущностью — если мы лишимся снимков, то, по сути, придется начинать с нуля, поскольку будет утрачено внутреннее состояние. В то же время потеря журналов просто вызовет утрату состояния и отправит систему cron назад во времени, к точке, когда был сделан последний снимок.
Есть два основных варианта хранения данных:
• во внешнем распределенном хранилище, к которому имеется свободный доступ;
• в системе, которая сохраняет небольшую часть информации о состоянии как часть самого сервиса cron.
При проектировании системы мы объединяем элементы обоих вариантов.
Мы храним журналы протокола Paxos на локальном диске машины, где запланированы реплики сервиса cron. Наличие трех реплик при плановой эксплуатации подразумевает, что у нас будут три копии журналов. Мы также храним эти снимки на локальном диске. Но, поскольку они являются критически важными, мы храним их резервную копию в распределенной файловой системе, защищая себя от сбоев, влияющих на все три машины.
Мы не храним журналы в распределенной файловой системе. Мы приняли осознанное решение, которое заключается в том, что потеря журналов, представляющих небольшой объем самых недавних изменений состояния, — это приемлемый риск. Хранение журналов в распределенной файловой системе может повлечь за собой значительное снижение производительности, вызванное выполнением множества небольших операций записи. Одновременная потеря все трех машин маловероятна, а если это все-таки случится, данные будут автоматически восстановлены с помощью снимка. Таким образом, мы теряем лишь небольшое количество журналов — записи, сделанные с момента последнего снимка, которые выполняются через конфигурируемые промежутки времени. Конечно, эти компромиссы могут различаться в зависимости от деталей инфраструктуры, как и требования, предъявляемые к системе cron.
В дополнение к тому, что журналы и снимки хранятся на локальном диске, а резервные копии снимков — в распределенной файловой системе, только что запущенная реплика может получить снимок состояния и все журналы от уже работающей реплики по сети. Эта способность позволяет сделать запуск реплики независимым от состояния локальной машины. Поэтому переназначение реплики на другую машину после перезапуска (или «смерти» машины), по сути, не влияет на надежность сервиса.
Запуск большого экземпляра Cron
Существуют и более простые, но такие же интересные способы применения запуска крупного развертывания сервиса cron. Традиционный сервис cron имеет небольшую емкость: обычно он содержит не более нескольких десятков задач cron. Но если вы запустите сервис cron для тысяч машин дата-центра, нагрузка на него увеличится и вы можете столкнуться с проблемами.
Остерегайтесь серьезной и хорошо известной проблемы распределенных систем, которая называется «шумная толпа». Основываясь на конфигурации пользователя, сервис cron может вызвать значительные скачки загруженности дата-центра. Когда люди думают о ежедневно выполняемой задаче cron, они обычно конфигурируют ее так, чтобы она выполнялась в полночь. Это сработает, если задача будет запущена на той же машине, но что, если задача cron может запускать задачу MapReduce с тысячей процессов-исполнителей? И что, если 30 разных команд решат запустить таким образом задачи cron в одном дата-центре? Для того чтобы решить эту проблему, мы ввели расширение для формата crontab.
В обычном crontab пользователи указывают минуту, час, день месяца (или недели) и месяц, в которые должна быть выполнена задача, или звездочку, если может быть использовано любое значение. Для запуска задачи каждый день в полночь следует использовать нотацию «0 0 * * *» (то есть нулевая минута нулевого часа каждого дня недели каждого месяца и каждый день недели). Мы также используем знак вопроса, который означает, что приемлемо любое значение и система cron сама может его выбирать. Пользователи задают это значение путем хеширования конфигурации задачи cron в заданном временном промежутке (например, 0…23 для часов), что позволяет распределить запуски более равномерно.
Несмотря на это изменение, загрузка, вызванная задачами cron, все еще может сильно скакать. График, показанный на рис. 24.3, иллюстрирует среднее глобальное количество запусков задач cron в Google. Он подчеркивает частые пики запусков задач cron, которые зачастую бывают вызваны задачами cron, которые должны быть запущены в определенное время, например, из-за временной зависимости или внешних событий.
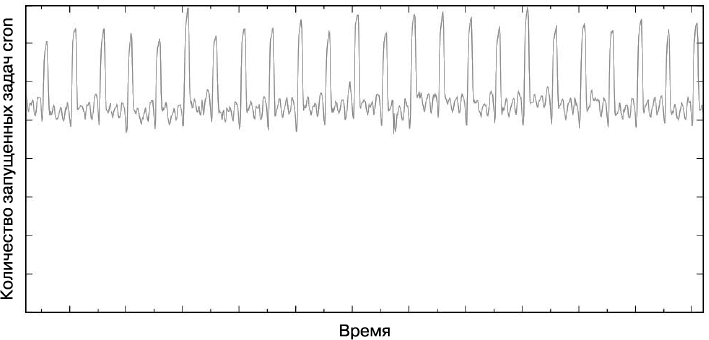
Рис. 24.3. Количество задач cron, запущенных глобально
Итоги главы
Наличие сервиса cron — фундаментальная особенность UNIX-систем на протяжении многих десятилетий.
Однако отрасль перешла на использование крупных распределенных систем, где минимальным рассматриваемым аппаратным блоком может считаться дата-центр, и это требует изменений в большой части стека. Система cron не стала исключением. В основе нового дизайна Google лежит тщательное изучение необходимых свойств сервиса cron и требований задач cron.
Мы рассмотрели новые ограничения, связанные с распределенной средой, и возможный проект сервиса cron, основанный на решении Google. Это решение требует гарантированной целостности и устойчивости в распределенной среде. Поэтому ядром распределенной реализации cron является Paxos — широко распространенный алгоритм достижения консенсуса в ненадежных средах. Применение Paxos и корректный анализ новых типов сбоев задач cron в крупномасштабных распределенных средах позволили создать устойчивый сервис cron, широко используемый в компании Google.
Эта глава была ранее частично опубликована в ACM Queue (март 2015 года, том 13, выпуск 3).
Сбои отдельных задач лежат за пределами этого анализа.

