23. Разрешение конфликтов: консенсус в распределенных системах и обеспечение надежности
Автор — Лаура Нолан
Под редакцией Тима Харви
Процессы дают сбои, и иногда их нужно перезапускать. Сбои дают и жесткие диски. Природные катастрофы могут разрушить несколько дата-центров в каком-то регионе. SR-инженеры должны прогнозировать сбои такого рода и разработать стратегии, которые помогают поддерживать системы в рабочем состоянии, несмотря на все эти факторы. Эти стратегии обычно влекут за собой запуск подобных систем на нескольких сайтах. Географическое распределение системы относительно прямолинейно, но оно показывает необходимость постоянного наблюдения за состоянием системы, что имеет много нюансов и в целом сложновыполнимо.
Группы процессов могут хотеть надежно приходить к консенсусу по следующим вопросам.
• Какой процесс является лидером группы?
• Какие процессы входят в группу?
• Попало ли сообщение в распределенную очередь?
• Должен ли процесс удерживать аренду?
• Какое значение лежит в хранилище для заданного ключа?
Мы обнаружили, что консенсус в распределенных системах эффективен для сборки надежных общедоступных систем, за состоянием которых требуется постоянное наблюдение. Задача консенсуса в распределенных системах позволяет достичь соглашения для группы процессов, связанных ненадежной коммуникационной сетью. Например, несколько процессов распределенной системы могут нуждаться в возможности формировать устойчивое представление о критическом фрагменте конфигурации независимо от того, удерживается ли распределенная блокировка, или же сообщение в очереди было обработано. Это одна из основных концепций распределенных вычислений, на которую мы полагаемся при создании практически любого из предлагаемых нами сервисов. На рис. 23.1 показана простая модель того, как группа процессов может получить устойчивое представление о состоянии системы с помощью консенсуса.
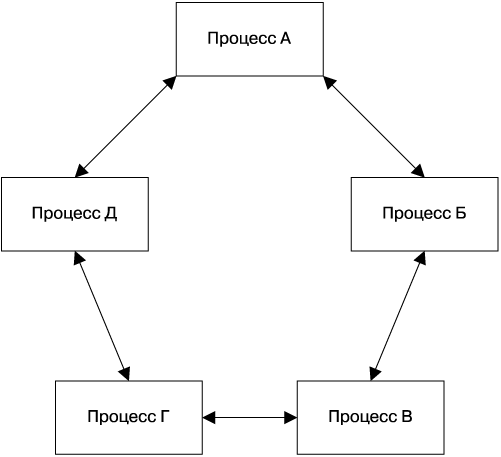
Рис. 23.1. Консенсус в распределенных системах: соглашение между группой процессов
Когда вы видите выборы лидера, разделяемое критическое состояние или распределенные блокировки, стоит использовать распределенные системы, пришедшие к консенсусу, которые формально доказали свою полезность и были качественно протестированы. Неформальные подходы к решению этой проблемы могут привести к сбоям и, что еще более неприятно, к неуловимым и сложным для исправления проблемам с устойчивостью данных, которые могут продлить время отключения системы.
| ТЕОРЕМА CAP Теорема CAP ([Fox, 1999], [Brewer, 2012]) утверждает, что распределенная система не может иметь одновременно три следующих свойства: устойчивое представление о данных в каждом узле; доступность данных в каждом узле; толерантность к нарушениям связности сети [Gilbert, 2002]. Логика интуитивно понятна: если два узла не могут общаться друг с другом, поскольку связность сети нарушена, тогда система, рассматриваемая как целое, может остановить обслуживание некоторых или всех запросов на некоторых или всех узлах, снижая доступность, или же обслуживать запросы как обычно, что приведет к появлению неустойчивых представлений о данных в каждом узле. |
Поскольку нарушений связности сети избежать нельзя (кабели могут быть перерезаны, пакеты могут потеряться или задержаться из-за перегрузки, аппаратная часть может сломаться, сетевые компоненты могут быть неверно сконфигурированы и т.д.), понимание консенсуса в распределенных системах эквивалентно пониманию устойчивости и возможности работать для конкретного приложения. Коммерческое давление зачастую требует высокого уровня доступности, и многим приложениям необходимо устойчивое представление их данных.
Системные и программные инженеры зачастую знакомы с традиционной семантикой хранилищ данных ACID (Atomicity, Consistency, Isolation, Durability — «атомарность, согласованность, изолированность, долговечность»), но растущее число технологий создания распределенных хранилищ предоставляет другой набор семантик, известный как BASE (Basically Available, Soft state, Eventual consistency — «доступность в большинстве случаев, неустойчивое состояние, согласованность в конечном счете»). Хранилища данных, которые поддерживают семантику BASE, имеют полезные приложения для данных определенного рода и могут обработать большие объемы данных и транзакций, которые было бы гораздо дороже или даже невозможно обрабатывать с помощью хранилищ данных, поддерживающих семантику ACID.
Большинство систем, которые поддерживают семантику BASE, полагаются на репликацию с несколькими хозяевами, где операции записи могут быть выполнены для разных процессов многопоточно, а также имеется механизм для разрешения конфликтов, зачастую довольно простой — «кто позже, тот и победил». Такой подход часто называют устойчивостью в конечном счете. Однако такая устойчивость может привести к удивительным результатам [Lu, 2015], в частности в случае дрейфа часов (сlock drift), что неизбежно в распределенных системах, или нарушения связности сети [Kingsbury, 2015]. Кроме того, разработчикам трудно создавать системы, которые хорошо работают с хранилищами данных, поддерживающими только семантику BASE. Джефф Шуте [Shute, 2013], например, утверждает: «Мы находим, что разработчики тратят значительную часть своего времени на создание крайне сложных и ненадежных механизмов, помогающих справиться с устойчивостью в конечном счете и обрабатывать данные, которые могли устареть. Мы думаем, что такая ноша неприемлема для разработчиков и проблемы с устойчивостью должны решаться на уровне баз данных».
Разработчики систем не могут пожертвовать корректностью для того, чтобы добиться надежности или производительности, особенно в критическом состоянии. Например, рассмотрим систему, которая обрабатывает финансовые транзакции: требования к надежности или производительности не приносят большой пользы, если финансовые данные некорректны. Системы должны надежно синхронизировать критические состояния между несколькими процессами. Алгоритмы достижения консенсуса для распределенных систем предоставляют такую функциональность.
Мотивация к использованию консенсуса: сбои координации распределенных систем
Распределенные системы сложны и трудны для понимания, наблюдения и поиска ошибок. Инженеров, работающих с ними, часто удивляет их поведение при сбоях. Последние происходят довольно редко, и, как правило, работа системы в таких условиях не тестируется. Очень трудно обосновывать поведение системы во время сбоев. Нарушения связности сети вызывают особые сложности — проблема, которая, как могло показаться, вызвана таким нарушением, может оказаться результатом:
• очень медленной работы сети;
• потери некоторых, но не всех сообщений;
• подавления, произошедшего только в одном направлении.
В следующих разделах рассмотрены примеры проблем, наблюдавшихся в реальных распределенных системах, также в них обсуждается, как выбор лидера и алгоритмы достижения распределенного консенсуса можно было использовать для предотвращения таких проблем.
Пример 1: возникновение двух и более ведущих в схеме с ведущим и ведомыми
Сервис представляет собой репозиторий контента, который позволяет нескольким пользователям взаимодействовать друг с другом. Для надежности он применяет наборы, состоящие из двух реплицированных файловых серверов, находящихся в разных стойках. Сервис должен избежать записывания данных в оба файловых сервера, поскольку это может привести к повреждению данных, после которого их, возможно, нельзя будет восстановить.
Каждая пара файловых серверов имеет одного лидера и одного ведомого. Серверы наблюдают друг за другом с помощью контрольных сигналов. Если один файловый сервер не может связаться со своим партнером, он отправляет ему команду STONITH (Shoot The Other Node in the Head — «Выстрелить другому узлу в голову»), чтобы отключить его и завладеть его файлами. Такой прием является стандартным методом снижения количества проявлений этой проблемы, несмотря на то что, как мы увидим, это неправильный способ.
Что произойдет, если сеть станет медленной или начнет отклонять пакеты? В этом случае файловые серверы превысят тайм-ауты контрольных сигналов и, как и было задумано, отправят команды STONITH своим партнерам, чтобы стать ведущими. Однако команды могут быть не доставлены из-за ошибок работы сети. Пары файловых серверов в таком случае могут оказаться в состоянии, когда оба узла должны быть активными для одного ресурса или оба отключены, поскольку получили команду STONITH. Это приводит либо к повреждению, либо к недоступности данных.
Проблема заключается в том, что система пытается решить задачу выбора лидера с помощью простых тайм-аутов. Выбор лидера — это переформулированная задача достижения распределенного асинхронного консенсуса, которую нельзя решить правильно с помощью контрольных сигналов.
Пример 2: восстановление после сбоя требует вмешательства человека
Высокосегментированная система баз данных имеет первичную реплику для каждого сегмента, который синхронно реплицируется во вторичный сегмент в другом дата-центре. Внешняя система проверяет состояние первичных реплик и, если они больше не работают, повышает ранг вторичной реплики до первичной. Если первичная реплика не может определить состояние своей вторичной реплики, она становится недоступной и отправляет сигнал человеку, чтобы избежать сценария, описанного в примере 1.
Это решение не приводит к потере данных, но ухудшает их доступность. Оно также без необходимости повышает операционную нагрузку на инженеров, поддерживающих систему, а потребность в человеческом вмешательстве плохо масштабируется. Такого рода события, когда первичная и вторичная реплики испытывают проблемы в общении, могут произойти, если возникнет крупная проблема с инфраструктурой, когда отвечающие за нее инженеры могут быть перегружены другими задачами. Если сеть так сильно затронута, что выбрать мастера с помощью распределенного консенсуса нельзя, человек, скорее всего, также не сможет сделать это.
Пример 3: некорректные алгоритмы членства в группе
Система имеет компонент, который выполняет индексирование и поиск по сервисам. В начале работы узлы используют протокол-«сплетник» для обнаружения друг друга и присоединения к кластеру. В случае, когда из-за нарушения связности сети кластер сегментируется, каждая сторона некорректно выбирает мастера и принимает операции по записи и удалению данных, что приводит к возникновению двух и более ведущих и повреждению данных.
Задача определения устойчивого представления членства в группе процессов — это еще один пример задачи распределенного консенсуса. Фактически многие проблемы распределенных систем на практике оказываются одной из множества версий распределенного консенсуса, включая выбор мастера, определение членства в группе, все виды распределенного блокирования и выдачи аренды, надежной распределенной буферизации и доставки сообщений, а также обслуживание любого рода критического разделенного состояния, за которым постоянно должна наблюдать группа процессов. Все эти проблемы могут быть решены путем использования алгоритма распределенного консенсуса, который формально доказал свою корректность и чья реализация была тщательно протестирована. Прямолинейные решения таких задач наподобие контрольных сигналов и протоколов-«сплетников» на практике всегда будут иметь проблемы с надежностью.
Как работает распределенный консенсус
Проблема консенсуса имеет несколько вариантов. При работе с распределенными системами мы заинтересованы в достижении асинхронного распределенного консенсуса, что применяется к средам с потенциально несвязанными задержками при анализе сообщений. (Синхронный консенсус применяется к системам реального времени, в которых специализированное аппаратное обеспечение гарантирует, что сообщения будут приходить точно в обозначенный срок.)
Алгоритмы достижения распределенного консенсуса могут быть двух видов: crash-fail (что подразумевает, что «упавшие» узлы никогда не возвращаются в систему) или crash-recover. Алгоритмы crash-recover гораздо более полезны, чем crash-fail, поскольку большинство проблем в реальных системах являются временными по своей природе из-за медленной сети, перезапусков и т.д.
Алгоритмы могут работать как с византийскими, так и с невизантийскими сбоями. Византийский сбой происходит, когда процесс передает некорректное сообщение из-за ошибки или вредоносной активности, их относительно дорого обрабатывать, но и встречаются они реже.
Технически решение задачи достижения распределенного асинхронного консенсуса в ограниченное время невозможно. Как доказано теоремой Фишера, Линча и Паттерсона о невозможности консенсуса в системе со сбоями (FLP impossibility result), удостоенной премии Дейкстры [Fischer, 1985], ни один алгоритм достижения распределенного асинхронного консенсуса не может гарантировать прогресс при ненадежной работе сети.
На практике мы подходим к решению проблемы достижения распределенного асинхронного консенсуса в ограниченное время, гарантируя, что система будет иметь достаточное количество рабочих реплик, а также соединение с сетью, что позволит стабильно прогрессировать большую часть времени. Вдобавок система должна иметь выдержку с рандомизированными задержками. Это позволяет предотвращать ситуацию, когда выполнение повторных попыток вызовет каскадный эффект, и избежать проблемы конфликтующих заявителей, которая будет описана позже в этой главе. Протоколы гарантируют безопасность, а адекватная избыточность в системе способствует живучести.
Оригинальным решением проблемы достижения распределенного консенсуса был протокол Лампорта Paxos [Lamport, 1998], но существуют и другие протоколы, способные решить эту проблему, например Raft [Ongaro, 2014], Zab [Junqueira, 2011] и Mencius [Mao, 2008]. Сам протокол Paxos имеет множество вариаций, предназначенных для повышения производительности [ZooKeeper, 2014]. Они обычно различаются одной деталью, например возможностью назначения на роль лидера одного процесса для упрощения протокола.
Обзор Paxos: пример протокола. Paxos работает как последовательность предложений, которые могут быть приняты или не приняты большинством процессов системы. Если предложение не принято, оно дает сбой. Каждое предложение имеет номер последовательности, который навязывает прямой порядок всех операций системы.
В первой фазе работы протокола заявитель отправляет порядковый номер получателям. Каждый получатель согласится с предложением только в том случае, если еще не видел предложения с более высоким номером. Заявители могут отправить более высокий порядковый номер, если это необходимо. Они должны использовать уникальные порядковые номера, например полученные из непересекающихся множеств или путем внедрения их имени хоста в порядковый номер.
Если заявитель получает согласие от большинства получателей, он может зафиксировать предложение, отправив сообщение о завершении транзакции со значением.
Прямая последовательность предложений решает любые проблемы, связанные с порядком сообщений системы. Требование, которое заключается в том, что для фиксации необходимо большинство, означает, что два разных значения не могут быть зафиксированы для одного предложения, поскольку любые два большинства будут пересекаться как минимум в одном узле. Получатели должны вести журнал в постоянном хранилище, в который они будут записывать информацию о принятых предложениях, поскольку должны соблюдать эти гарантии после перезапуска.
Paxos сам по себе не очень полезен: все, что он позволяет вам сделать, — это достичь соглашения о значении и один раз предложить число. Поскольку лишь кворум определенного размера должен согласиться со значением, любой заданный узел может не иметь полного представления о наборе значений, с которыми уже согласились. Это ограничение верно для большинства алгоритмов достижения распределенного консенсуса.
Шаблоны системной архитектуры для распределенного консенсуса
Алгоритмы достижения распределенного консенсуса низкоуровневые и примитивные: они просто позволяют набору узлов один раз согласиться со значением. Они плохо подходят для выполнения реальных задач по проектированию. Полезными такие алгоритмы делает добавление высокоуровневых системных компонентов вроде хранилищ данных или конфигурации, очередей, блокировок и сервисов выбора лидеров — все это предоставляет практическую функциональность, которой не имеют сами алгоритмы. Использование высокоуровневых компонентов снижает сложность для проектировщиков системы. Также это позволяет алгоритмам достижения распределенного консенсуса изменяться при необходимости в ответ на изменения среды, в которой работает система, или на изменения в нефункциональных требованиях.
Многие системы, которые успешно применяют алгоритмы достижения консенсуса, делают это как клиенты некоторого сервиса, реализующего эти алгоритмы, например Zookeeper, Consul и т.д.
Система Zookeeper [Hunt, 2010] стала первой системой достижения консенсуса с открытым исходным кодом и сразу завоевала популярность в отрасли, поскольку ее просто использовать даже в приложениях, которые не были разработаны для применения распределенного консенсуса. Сервис Chubby заполняет такую же нишу в компании Google. Его авторы указывают [Burrows, 2006], что предоставление примитивов консенсуса как сервиса, а не как библиотеки, которую инженеры встраивают в свои приложения, освобождает тех, кто будет поддерживать приложение, от необходимости развертывать системы так же, как и общедоступные системы достижения консенсуса: запуск правильного количества реплик, работа с членством в группе, налаживание производительности и т.д.
Надежные машины с реплицированным состоянием
Машина с реплицированным состоянием (replicated state machine, RSM) — это система, которая выполняет одинаковый набор операций в одном и том же порядке в нескольких процессах. RSM — это основной элемент полезных компонентов распределенных систем и сервисов, таких как хранилища данных или конфигурации, блокировок и выбора лидера (более подробно будет описано позже).
Операции на RSM заказываются глобально с помощью алгоритма достижения консенсуса. Это очень мощная концепция: в нескольких статьях ([Aguilera, 2010], [Kirsch, 2008], [Schneider, 1990]) показывается, что любая детерминистская программа может быть реализована как общедоступный реплицированный сервис, если его выполнить как RSM.
Как показано на рис. 23.2, машина с реплицированным состоянием — это система, реализованная на логическом уровне, расположенном над алгоритмом достижения консенсуса. Этот алгоритм справляется с соглашением о порядке операций, и RSM выполняет операции в заданном порядке. Поскольку не каждый член группы консенсуса обязательно является членом каждого кворума, RSM должны синхронизировать состояние с помощью одноранговых узлов.

Рис. 23.2. Отношение между алгоритмом достижения консенсуса и машиной с реплицированным состоянием
Надежные реплицированные хранилища данных и конфигураций
Надежные реплицированные хранилища данных являются прикладным уровнем машин с реплицированным состоянием. Реплицированные хранилища данных используют алгоритм достижения консенсуса на критическом этапе своей работы. Поэтому производительность, пропускная способность и возможность масштабироваться очень важны для таких проектов. Как и хранилища данных, построенные с помощью других технологий, основанные на консенсусе хранилища данных могут предоставить множество семантик устойчивости для операций чтения, что значительно отличает способ масштабирования этого хранилища от прочих. Эти компромиссы рассмотрены в разделе «Производительность систем с распределенным консенсусом» далее в этой главе.
Другие системы (нераспределенные, но основанные на консенсусе) зачастую попросту полагаются на временные метки для создания граничного значения для возраста возвращаемых данных. Временные метки очень проблематично создать в распределенных системах, поскольку невозможно гарантировать, что часы синхронизированы на всех машинах. Spanner [Corbett, 2012] переадресует эту проблему путем моделирования самого худшего случая неопределенности и замедления обработки там, где это необходимо, для разрешения неопределенности.
Общедоступная обработка, применяющая алгоритм выбора лидера
Выбор лидера в распределенных системах — это задача, эквивалентная достижению распределенного консенсуса. Реплицированные сервисы, которые используют одного лидера для выполнения некоего вида работы в системе, широко распространены, механизм одного лидера — это способ гарантировать взаимное исключение на низком уровне.
Дизайн такого вида подходит для тех случаев, когда функции сервиса-лидера могут быть выполнены одним процессом или сегментированы. Дизайнеры системы могут создать общедоступный сервис, написав его как простую программу, реплицировав этот процесс и задействовав выбор лидера для того, чтобы гарантировать, что в любой заданный момент времени будет работать только один лидер (рис. 23.3). Зачастую работа, которую выполняет лидер, заключается в координировании некоторого пула рабочих систем. Этот шаблон был использован в GFS [Ghemawat, 2003] (которая была заменена на Colossus) и хранилище ключей-значений Bigtable [Chang, 2006].
В компонентах такого вида, в отличие от реплицированных хранилищ данных, алгоритм достижения консенсуса не находится на критическом этапе основной работы, которую выполняет система, поэтому пропускная способность обычно не является серьезной проблемой.
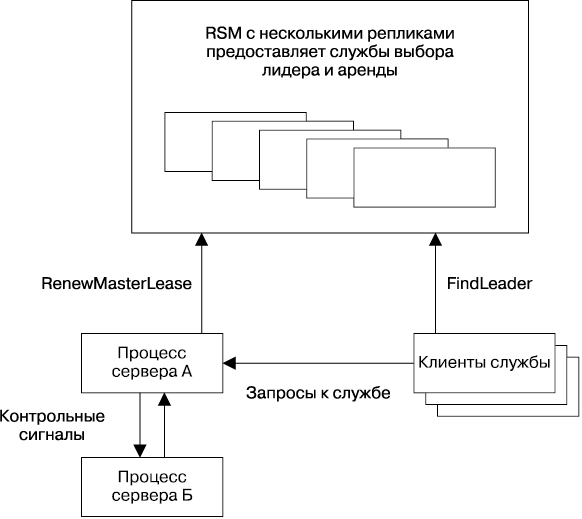
Рис. 23.3. Общедоступная система, применяющая реплицированный сервис для выбора лидера
Распределенная координация и блокировка сервисов
Барьером в распределенных вычислениях является примитив, который блокирует группу процессов до тех пор, пока не будет выполнено какое-то условие (например, пока не будут завершены все части одной фазы расчетов). Барьер, по сути, разделяет распределенные вычисления на логические фазы. Например, барьер может быть использован при реализации модели MapReduce [Dean, 2004], которая позволяет гарантировать, что вся фаза Map будет выполнена до того, как начнется фаза Reduce (рис. 23.4).
Барьер может быть реализован одним процессом-координатором, но это добавляет единую точку отказа, что обычно неприемлемо. Барьер также может быть реализован как RSM. Сервис консенсуса Zookeeper может реализовать шаблон барьера (см. [Hunt, 2010] и [ZooKeeper, 2014]).
Блокировки — это еще один полезный примитив, который может быть реализован как RSM. Рассмотрим распределенную систему, в которой рабочие процессы автоматически потребляют входные файлы и выдают результат. Распределенные блокировки могут быть использованы для предотвращения того, что множество работников будут обрабатывать один и тот же файл. На практике очень важно применять обновляемую аренду с тайм-аутами вместо блокировок, поскольку это предотвратит появление бесконечных блокировок, созданных давшими сбой процессорами. Мы не будем в этой главе рассматривать распределенные блокировки, но нужно иметь в виду, что это низкоуровневые системные примитивы, которые стоит использовать осторожно. Большая часть приложений должна задействовать более высокоуровневые системы, которые предоставляют распределенные транзакции.
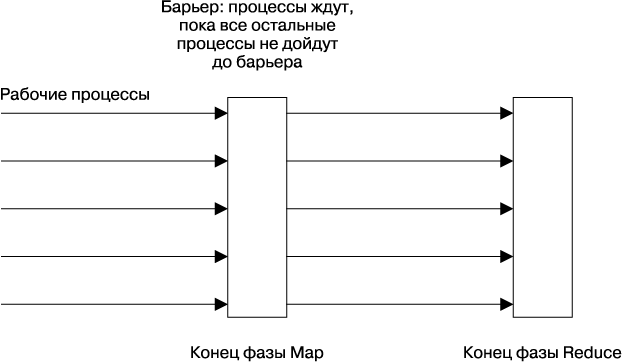
Рис. 23.4. Барьеры для координации процессов при вычислениях MapReduce
Надежный распределенный механизм помещения в очередь и отправки сообщений
Очереди распространены в структурах данных, зачастую их применяют для распределения задач между каким-то количеством рабочих процессов.
Системы, основанные на очередях, могут выдержать сбои и потерю рабочих узлов относительно легко. Однако система должна гарантировать, что указанные задачи будут успешно обработаны. Для этой цели рекомендуется использовать систему аренды (она рассмотрена ранее в разделе о блокировках) вместо прямого удаления из очереди. Недостатком систем, основанных на очередях, является то, что потеря очереди мешает работать всей системе. Реализация очереди как RSM может снизить этот риск и сделать всю систему гораздо более работоспособной.
Атомарная трансляция — это примитив распределенных систем, в котором сообщения доставляются надежно и в одинаковом порядке всем получателям. Он является особенно мощной концепцией распределенных систем, которая очень полезна при разработке дизайна практических систем. Множество инфраструктур публикации-подписки существует для использования дизайнерами системы, несмотря на то что не все они гарантируют атомарность. Чандра и Туг [Chandra, 1996] показывают равенство атомарной трансляции и консенсуса.
Шаблон размещения в очереди для распределения работы, который использует очереди как инструмент балансировки нагрузки (рис. 23.5), можно рассматривать как двухсторонний обмен сообщениями. Системы обмена сообщениями также обычно реализуют очередь публикации — подписки, где сообщения могут потребляться большим количеством клиентов, подписанных на канал или тему. В этом случае, если работа идет по схеме «один ко многим», сообщения в очереди хранятся в виде устойчивого упорядоченного списка.
Системы публикации — подписки могут быть использованы для многих типов приложений, которые требуют от клиента подписаться для получения уведомлений о том, что произошло какое-то событие. Системы публикации — подписки можно применить также для реализации понятных распределенных кэшей.
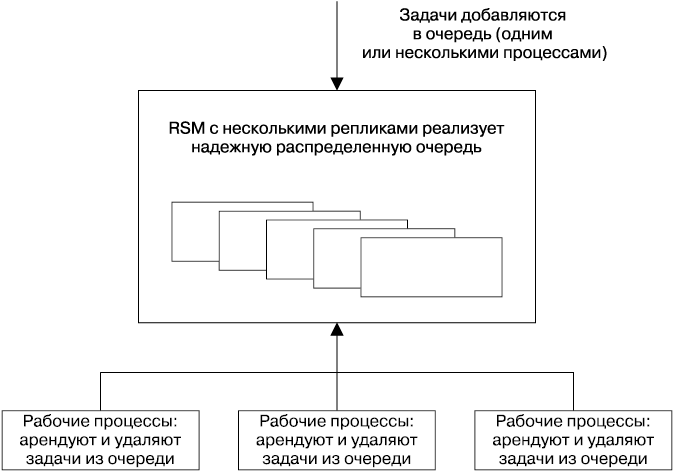
Рис. 23.5. Система распределения работы, основанная на очередях, использующая надежный, основанный на консенсусе компонент размещения в очередях
Системы для размещения в очереди и обмена сообщениями зачастую требуют отличной пропускной способности, но, поскольку пользователи работают с ними редко, им не нужна очень малая задержка. Однако очень длительные задержки в системах, похожих на описанную, которые имеют множество работников, получающих задачи из очереди, могут стать проблемой, если процент времени обработки для каждой задачи значительно вырастет.
Производительность систем с распределенным консенсусом
По общему мнению, алгоритмы достижения консенсуса слишком медленные и слишком дорогие для использования во многих системах, которые требуют широкой полосы пропускания и малой задержки [Bolosky, 2011]. Эта концепция попросту неверна — несмотря на то что реализовываться она может медленно, существует несколько приемов, которые могут улучшить ее производительность. Алгоритмы достижения распределенного консенсуса лежат в основе многих критически важных систем компании Google, описанных в [Ananatharayan, 2013], [Burrows, 2006], [Corbett, 2012] и [Shute, 2013], и они доказали свою высокую эффективность на практике. Масштаб компании Google в этой ситуации является не преимуществом, а скорее недостатком, поскольку из-за него возникают две главные сложности: наши наборы данных, как правило, велики, а системы работают на больших географических расстояниях. Крупные наборы данных, к тому же имеющие несколько реплик, обусловливают значительную стоимость вычисления, а значительные расстояния увеличивают задержку между репликами, что, в свою очередь, снижает производительность.
Не существует «лучшего» алгоритма распределенного консенсуса и алгоритма репликации конечных машин с точки зрения производительности, поскольку она зависит от нескольких факторов, связанных с нагрузкой, целевыми значениями производительности системы и способом развертывания последней. В следующих разделах рассматриваются исследования, предназначенные для того, чтобы лучше понять способы достижения распределенного консенсуса. Многие описанные системы уже доступны и используются.
Нагрузку можно варьировать множеством способов, и понимание того, как она может изменяться, критически важно для обсуждения производительности. В системах с консенсусом нагрузка может зависеть от следующих условий:
• пропускной способности — количества предложений, сделанных элементом за единицу времени при пиковой нагрузке;
• типа запросов — доли операций, которые могут изменять состояние;
• семантики устойчивости, необходимой для операций чтения;
• размеров запросов, если размер данных, представляющих собой полезную нагрузку, может различаться.
Стратегии развертывания также могут быть различными.
• Развертывание проводится локально или на большой площади?
• Какого рода кворумы применяются и где находится большинство процессов?
• Использует ли система сегментирование, конвейерную или пакетную обработку?
Многие системы с консенсусом задействуют определенный процесс-лидер и требуют, чтобы все запросы переходили на этот особый узел. Как показано на рис. 23.6, в результате этого производительность системы, воспринимаемая клиентами в разных географических локациях, может значительно различаться просто потому, что множество узлов имеют длительное время обращения к процессу-лидеру.
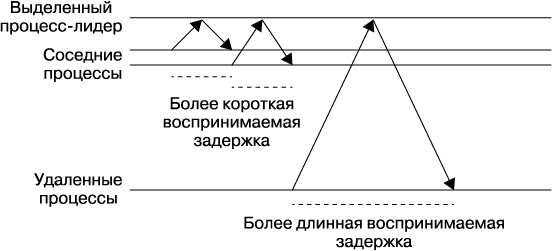
Рис. 23.6. Влияние удаленности от процесса-сервера на воспринимаемую производительность
Multi-Paxos: детализированный поток сообщений
Протокол Multi-Paxos использует сильный процесс-лидер: если лидер не был выбран или произошел какой-то сбой, требуется прохождение всего одного цикла между заявителем и кворумом получателей для достижения консенсуса. Использование сильного процесса-лидера оптимально с точки зрения количества передаваемых сообщений, этот подход применяется во многих протоколах достижения консенсуса.
На рис. 23.7 показано исходное состояние, когда заявитель выполняет первую фазу подготовки/обещания. На этом этапе создается новое пронумерованное представление — время действия лидера. При последующих вызовах протокола, поскольку представление остается тем же самым, выполнять первую фазу не обязательно, так как заявитель, который создал представление, может просто отправлять сообщения Accept, и консенсус будет достигнут, как только будет получен кворум ответов.
Еще один процесс в группе может принять на себя роль заявителя для создания сообщений в любой момент, но изменение заявителя может стоить производительности. Это потребует дополнительного цикла для выполнения фазы 1 протокола и, что более важно, может вызвать появление конфликтующих заявителей, когда предложения раз за разом прерывают друг друга и ни одно не принимается (рис. 23.8). Поскольку этот сценарий является формой активной блокировки, он может продолжаться бесконечно.
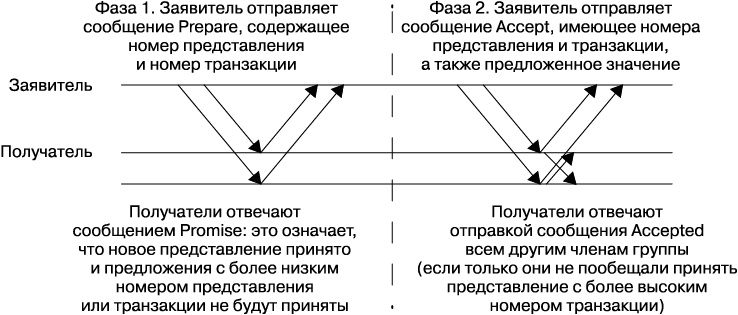
Рис. 23.7. Базовый поток сообщений протокола Multi-Paxos
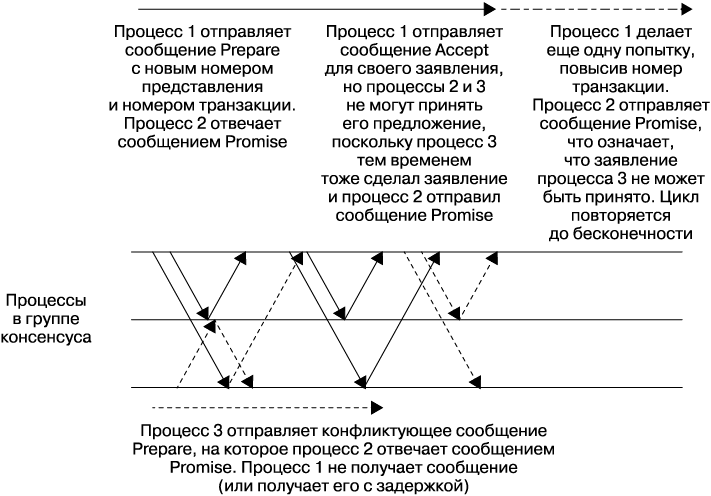
Рис. 23.8. Конфликтующие заявители в Multi-Paxos
Все применяемые на практике системы достижения консенсуса обычно решают эту проблему коллизий выбором процесса-заявителя, который будет создавать все предложения системы, или чередованием заявителя, выделяющего каждому процессу отдельное место в этих предложениях.
Для систем, которые используют процесс-лидер, его выбор должен быть тщательно настроен для того, чтобы сбалансировать вероятность недоступности системы из-за того, что лидера нет, с риском появления конфликтующих заявителей. Важно реализовать правильные стратегии тайм-аутов и выдержки. Если несколько процессов обнаруживают, что лидера нет, и пытаются стать лидером одновременно, то, скорее всего, ни один из них не преуспеет (опять же из-за конфликтующих заявителей). Здесь лучше всего поможет введение элемента случайности. Raft [Ongaro, 2014], например, имеет хорошо продуманный метод выбора процесса-лидера.
Масштабирование нагрузки, связанной с операциями чтения
Масштабирование нагрузки, связанной с чтением, зачастую критически важно, поскольку большая ее часть связана именно с этими операциями. Реплицированные хранилища данных обладают преимуществом, которое заключается в том, что данные доступны в нескольких местах. Это означает, что, если не требуется высокий уровень устойчивости для всех операций чтения, данные могут быть считаны из любой реплики. Прием чтения из реплик хорошо работает для определенных приложений, например системы Photon компании Google [Ananatharayan, 2013], которая использует распределенный консенсус для того, чтобы координировать работу нескольких конвейеров. Photon применяет атомарные операции сравнения и установки для изменения состояния, основанные на атомарных регистрах, которые гарантируют корректность и целостность данных. Однако операции чтения могут быть обслужены с помощью любой реплики, поскольку, если данные устареют, будет только выполнена лишняя работа — это не будет считаться ошибкой [Gupta, 2015]. Компромисс стоит того.
Для того чтобы гарантировать актуальность и целостность считываемых данных при любых изменениях, сделанных до операции чтения, необходимо произвести одну из следующих операций.
• Выполнить операцию по достижению консенсуса в режиме «только чтение».
• Считать данные из реплики, которая гарантированно является самой свежей. В системе, использующей стабильный процесс-лидер (как поступают многие реализации распределенного консенсуса), лидер может дать такую гарантию.
• Применить кворумные аренды, в которых некоторым репликам выдается аренда на все данные системы или их часть, что позволяет выполнять очень устойчивые операции чтения локально за счет некоторого количества производительности при записи. Этот прием детально рассматривается в следующем разделе.
Кворумная аренда
Кворумная аренда [Moraru, 2014] — это недавно разработанный способ оптимизации производительности распределенного консенсуса, нацеленный на снижение задержки и повышение пропускной способности для операций чтения. Как говорилось ранее, в случае использования классического протокола Paxos и большинства других протоколов распределенного консенсуса выполнение очень устойчивых операций чтения (например, гарантирующих наличие самых свежих данных) требует либо реализации операции распределенного консенсуса, которая читает из кворума реплик, либо наличия стабильной реплики-лидера, которая гарантированно видела все недавние операции изменения статуса. Во многих системах число операций чтения значительно превосходит количество операций записи, поэтому такая зависимость от распределенной операции либо одной реплики ухудшает задержку и системную полосу пропускания.
При кворумной аренде попросту выдается аренда на чтение некоторому подмножеству состояний реплицированных хранилищ данных. Аренда выдается на конкретный (обычно небольшой) промежуток времени. Любая операция, которая изменяет состояние этих данных, должна быть подтверждена всеми репликами кворума. Если любая из реплик становится недоступной, данные не могут быть модифицированы до тех пор, пока не истечет срок аренды.
Кворумная аренда особенно полезна для нагрузки, когда операции чтения для определенных подмножеств данных сконцентрированы в одном географическом регионе.
Производительность распределенного консенсуса и задержка сети
Системы консенсуса сталкиваются с двумя серьезными физическими ограничениями производительности, когда изменяют состояние. Одно из них заключается во времени обращения к сети, а второе — во времени, которое требуется для записи данных в устойчивое хранилище (его мы рассмотрим позже).
Время обращения к сети может значительно различаться в зависимости от местоположения источника и приемника, а также наличия перегрузки сети. Время цикла прохождения данных между машинами внутри одного дата-центра должно измеряться миллисекундами. Обычное время цикла (round-trip-time, RTT) внутри Соединенных Штатов составляет 45 миллисекунд, а между Нью-Йорком и Лондоном — 70 миллисекунд.
Производительность системы с консенсусом внутри локальной сети может быть сравнима с производительностью асинхронной системы «лидер — ведомый» [Bolosky, 2011], которую многие традиционные базы данных применяют для репликации. Но, чтобы воспользоваться большей частью преимуществ доступности систем с распределенным консенсусом, нужно, чтобы реплики были удалены друг от друга, для того чтобы они находились в разных областях отказов.
Многие системы с консенсусом используют в качестве коммуникационного протокола TCP/IP. Протокол TCP/IP ориентирован на соединения и обеспечивает высокие гарантии надежности в отношении последовательности сообщений FIFO. Однако при создании нового TCP/IP-подключения требуется перед получением или отправкой данных получить трехстороннее подтверждение установки соединения, с проходом информации по сети туда и обратно. Медленный старт протокола TCP/IP изначально ограничивает полосу пропускания соединения до тех пор, пока не будут установлены его границы. Начальный размер окна TCP/IP изменяется от 4 до 15 Кбайт.
Медленный старт протокола TCP/IP, возможно, не является проблемой для процессов, которые формируют группу консенсуса: они установят соединения друг с другом и будут поддерживать их открытыми для повторного использования, поскольку часто общаются друг с другом. Однако для систем с очень большим количеством клиентов поддержание постоянных открытых соединений с кластерами консенсуса может быть нецелесообразным, поскольку открытые соединения TCP/IP потребляют некоторое количество ресурсов, например дескрипторы файлов, в дополнение к генерированию keepalive-сообщений. Эти издержки могут оказаться серьезной проблемой для приложений, которые задействуют высокосегментированные хранилища данных, основанные на консенсусе, содержащие тысячи реплик и еще большее количество клиентов. Решением проблемы является использование пула региональных прокси (рис. 23.9), которые будут хранить постоянные соединения TCP/IP с группой консенсуса для того, чтобы избежать появления накладных расходов, связанных с установкой соединения для длинных дистанций. Прокси также могут помочь вам инкапсулировать сегментирование и стратегии балансировки нагрузки, а также обнаружение членов кластеров и лидеров.
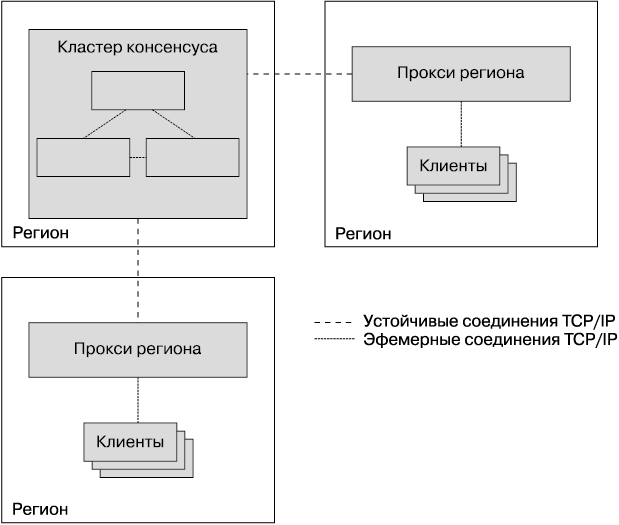
Рис. 23.9. Использование прокси для снижения необходимости открытия соединений TCP/IP между регионами
Размышляем о производительности: Fast Paxos
Fast Paxos [Lamport, 2006] — это версия алгоритма Paxos, разработанная для улучшения производительности для широкомасштабных сетей. Применив Fast Paxos, каждый клиент может отправить сообщения с предложениями непосредственно каждому члену группы приемников вместо того, чтобы действовать через лидера, как он делал бы при использовании алгоритмов Classic Paxos или Multi-Paxos. Суть заключается в том, чтобы заменить одну операцию отправки параллельных сообщений от клиента всем приемникам Fast Paxos двумя операциями отправки сообщений с помощью Classic Paxos:
• одно сообщение от клиента одному заявителю;
• параллельное сообщение отправляет операцию от заявителя другим репликам.
На первый взгляд может показаться, что Fast Paxos должен быть быстрее алгоритма Classic Paxos. Однако это не так: если клиент системы Fast Paxos имеет высокое RTT (round-trip time — «время оборота») с приемниками, а приемники выполняют быстрые соединения друг с другом, мы заменяем N параллельных сообщений, идущих через медленные узлы сети (в Fast Paxos), на одно сообщение, идущее через медленные узлы, плюс N параллельных сообщений между быстрыми узлами (Classic Paxos). Из-за эффекта хвостовой задержки, наблюдающегося большую часть времени, выполнение одного цикла между медленными узлами с распределенными задержками будет быстрее, чем кворум (как показано в [Junqueira, 2007]), и поэтому в данном случае Fast Paxos окажется медленнее, чем Classic Paxos.
Многие системы объединяют несколько операций в одну транзакцию для получателей, чтобы повысить пропускную способность. Поскольку клиенты действуют как заявители, затрудняется возможность отправки пакетных предложений. Причина заключается в том, что предложения поступают независимо от приемников, поэтому вы не можете устойчиво их объединять.
Стабильные лидеры
Мы видели, как Multi-Paxos выбирает стабильного лидера для того, чтобы улучшить производительность. Zab [Junqueira, 2011] и Raft [Ongaro, 2014] также являются примерами протоколов, которые выбирают стабильного лидера из соображений производительности. Этот подход позволяет оптимизировать операции чтения, поскольку лидер находится в самом новом состоянии, но в то же время несет в себе следующие проблемы.
• Все операции, которые изменяют состояние, должны быть отправлены через лидера, это требование повышает задержку сети для клиентов, которые расположены далеко от лидера.
• Выходная пропускная способность сети процесса-лидера является узким местом сети [Mao, 2008], поскольку его сообщение Accept содержит все данные, связанные со всеми предложениями, а другие сообщения содержат только подтверждения пронумерованных транзакций, не имеющих полезной нагрузки.
• Если лидер располагается на машине, которая испытывает проблемы с производительностью, то пропускная способность всей системы будет понижена.
Практически все системы, использующие распределенный консенсус, которые были спроектированы так, чтобы обращать внимание на производительность, задействуют либо шаблон единого стабильного лидера, либо систему сменяемого руководства, в которой каждый пронумерованный алгоритм достижения распределенного консенсуса заранее присвоен реплике (обычно с помощью простого численного идентификатора транзакции). Этот подход применяют множество алгоритмов, в том числе Mencius [Mao, 2008] и Egalitarian Paxos [Moraru, 2012].
Для широкомасштабных сетей, чьи клиенты распределены географически, а реплики групп консенсуса расположены довольно близко к клиентам, такой выбор лидера приводит к уменьшению наблюдаемой задержки для клиентов, поскольку время обращения запроса к сети для ближайшей реплики в среднем будет меньше, чем для произвольного лидера.
Пакетная обработка
Пакетная обработка, как описано в подразделе «Размышляем о производительности: Fast Paxos» ранее, повышает пропускную способность системы, но все еще оставляет реплики в состоянии покоя, пока они ожидают ответа на отправленные ими сообщения. Неэффективность, представленную свободными репликами, можно исправить, используя конвейерную обработку, которая позволяет отправлять по нескольку предложений сразу. Такая оптимизация очень похожа на оптимизацию, которая применялась в случае с протоколом TCP/IP, где протокол пытался поддерживать конвейер заполненным с помощью подхода, который называется «скользящее окно». Конвейерная обработка зачастую комбинируется с пакетной обработкой.
Пакеты запросов в конвейере все еще упорядочиваются глобально с учетом номеров представления и транзакции, поэтому этот метод не нарушает свойства глобального упорядочения, необходимые для запуска машины с реплицированным состоянием. Такой метод оптимизации рассматривается в [Bolosky, 2011] и [Santos, 2011].
Доступ к диску
Вносить записи в журнал, находящийся в устойчивом хранилище, необходимо, поэтому узел, который дал сбой и вернулся в кластер, учитывает любые предыдущие фиксации, которые он сделал по отношению к протекающим транзакциям консенсуса. В протоколе Paxos, например, приемники не могут согласиться с предложением, если они уже согласились с предложением, имеющим больший порядковый номер. Если детали предложения, с которым согласились и которое зафиксировали, не записаны в устойчивое хранилище, то приемник может нарушить протокол, если он даст сбой и перезапустится, что приведет к неустойчивому состоянию
Время, которое требуется для создания записи в журнале на диске, значительно различается в зависимости от используемой аппаратной части или виртуальной среды, но, скорее всего, не превысит нескольких миллисекунд.
Поток сообщений для протокола Multi-Paxos рассматривался в подразделе «Multi-Paxos: детализированный поток сообщений» ранее, но в нем не говорилось, где протокол должен вносить изменения состояния в журнал, хранящийся на диске. Запись на диск должна выполняться, когда процесс внесет изменение, с которым следует считаться. Во второй фазе протокола Multi-Paxos, зависимой от производительности, это будет происходить до того, как приемник отправит сообщение Accepted в ответ на предложение, и до того, как заявитель отправит сообщение Accept, поскольку это сообщение Accept также неявно является сообщением Accepted [Lamport, 1998].
Это означает, что задержка для операции с одним консенсусом включает в себя:
• одну операцию записи для заявителя;
• параллельные сообщения для приемников;
• параллельные записи на диск для приемников;
• возвращаемые сообщения.
Существует версия протокола Multi-Paxos, которая полезна для ситуаций, когда преобладают операции записи на диск: этот вариант не рассматривает сообщение Accept заявителя как неявное сообщение Accepted. Вместо этого заявитель выполняет запись на диск одновременно с другими процессами и отправляет явное сообщение Accept. Далее задержка становится пропорциональной времени, затраченному на отправку двух сообщений и на выполнение синхронной операции записи на диск для кворума процессов.
Если задержка для выполнения небольшой произвольной записи на диск измеряется десятками миллисекунд, уровень операций консенсуса будет ограничен примерно сотней операций в минуту. Эти показатели времени подразумевают, что временем обращения к сети можно пренебречь, и заявитель выполняет журналирование одновременно с приемниками.
Как мы уже видели, алгоритмы достижения распределенного консенсуса зачастую используются как основа для создания машин с реплицированным состоянием. RSM также должны сохранять журналы транзакций для потенциального восстановления (по тем же причинам, что и для любого другого хранилища данных). Журнал алгоритма консенсуса и журнал транзакций RSM могут быть объединены в один. Объединение этих журналов позволяет избежать необходимости постоянно переключаться между записями в два разных места на диске [Bolosky, 2011], что уменьшает время, потраченное на операции поиска. Диски могут выдерживать больше операций в секунду, и поэтому система как единое целое может выполнять больше транзакций.
В хранилище данных диски имеют и другое предназначение, помимо поддержки журналов: состояние системы обычно поддерживается на диске. Записи в журнал должны быть сброшены непосредственно на диск, но записи об изменении состояния могут быть добавлены в кэш и сброшены на диск позже, будучи перестроенными для того, чтобы использовать наиболее эффективное расписание [Bolosky, 2011].
Еще одним вариантом оптимизации является пакетная обработка операций клиента и размещение их в одной операции на заявителе ([Ananatharayan, 2013], [Bolosky, 2011], [Chandra, 2007], [Junqueira, 2011], [Mao, 2008], [Moraru, 2012]). Это погашает фиксированную стоимость журналирования диска и задержки сети для большого количества операций, повышая пропускную способность.
Развертывание распределенных систем, основанных на консенсусе
Наиболее важные решения, которые проектировщики систем должны принимать при развертывании систем, основанных на консенсусе, касаются количества развертываемых реплик и их местоположения.
Количество реплик
Как правило, системы, основанные на консенсусе, работают с использованием большинства кворумов, то есть группы из 2f + 1 реплик могут выдержать f сбоев (для византийских сбоев, когда требуется устойчивость системы к репликам, возвращающим некорректный результат, нужно применить 3f + 1 реплик для устойчивости к f сбоям [Castro, 1999]). Для невизантийских сбоев минимальным количеством развертываемых реплик может быть три — если развернуты две реплики, то не будет никакой устойчивости к сбою любого процесса. Три реплики могут выдержать один сбой. Простой большинства систем — это результат запланированного отключения [Kendrick, 2012]: три реплики позволяют системе работать в обычном режиме, когда одна из них отключена для обслуживания (предполагается, что две оставшиеся реплики смогут обработать нагрузку системы с приемлемой производительностью).
Если незапланированный сбой происходит во время окна обслуживания, то система, основанная на консенсусе, становится недоступной. Недоступность такой системы обычно неприемлема, поэтому следует запускать пять реплик, что позволит ей работать и после двух сбоев. Вмешательства не потребуется, если в системе консенсуса останутся работать четыре из пяти реплик, но если остается только три реплики, следует добавить одну или две.
Если система консенсуса теряет так много своих реплик, что не может сформировать кворум, то теоретически она находится в невосстанавливаемом состоянии, поскольку нельзя получить доступ к долговечным журналам как минимум одной из недостающих реплик. Если кворума нет, то, возможно, было принято решение, видимое только недостающим репликам. Администраторы могут иметь возможность навязать изменение членов группы и добавить новые реплики, которые получат всю необходимую информацию у уже существующих реплик, но вероятность потери данных все еще остается — этой ситуации лучше всего избегать.
В случае катастрофы администраторы должны решить, выполнять такое переконфигурирование или подождать какое-то время, пока машины, хранящие состояние системы, не станут доступными. Когда принимаются подобные решения, управление системным журналом (в дополнение к данным наблюдения) становится критически важным. Теоретические статьи зачастую указывают, что консенсус может быть использован для создания реплицированного журнала, но не могут показать, как справляться с репликами, которые могут давать сбой и восстанавливаться (и поэтому пропускать некоторые последовательности решений консенсуса) или подвисать из-за низкой скорости своей работы. Для поддержки устойчивости системы важно, чтобы эти реплики наверстали упущенное.
Реплицированный журнал не всегда является персоной первого класса в теории распределенного консенсуса, но он представляет собой очень важный аспект производственных систем. Raft описывает метод управления устойчивостью реплицированных журналов [Ongaro, 2014], явно определяя, как должны быть заполнены любые лакуны в журналах. Если система Raft, состоящая из пяти экземпляров, потеряет всех своих членов, кроме загрузчика, лидер все еще будет иметь всю информацию о принятых решениях. В то же время, если среди недостающих членов будет находиться и лидер, то нельзя будет гарантировать, что данные реплик будут свежими.
Существует соотношение между производительностью и количеством реплик системы, которым не нужно формировать часть кворума: более медленные реплики, находящиеся в меньшинстве, могут отставать, позволяя кворуму быстро работающих реплик действовать быстрее (до тех пор пока быстро работают лидеры). Если производительность реплики значительно меняется, то каждый сбой может снизить производительность всей системы, поскольку медленные, не поддерживающие общего темпа реплики должны будут войти в кворум. Чем больше сбоев или висящих реплик может выдержать система, тем выше будет ее общая производительность.
При управлении репликами стоит рассмотреть также проблему стоимости, так как каждая реплика задействует ценные вычислительные ресурсы. Если система является одним кластером процессов, стоимость запуска реплик будет относительно небольшой. Однако она может оказаться значительной для систем вроде Photon [Ananatharayan, 2013], которые используют сегментацию, где каждый сегмент представляет собой группу процессов, для которых запущен алгоритм консенсуса. По мере увеличения числа сегментов увеличивается и стоимость каждой дополнительной реплики, поскольку в систему необходимо добавить процессы в количестве, эквивалентном количеству сегментов.
Решение о количестве реплик для любой системы является компромиссом для следующих факторов:
• необходимой надежности;
• частоты плановых отключений, влияющих на систему;
• риска;
• производительности;
• стоимости.
Такие расчеты могут быть своими для каждой системы, так как системы имеют разные целевые значения надежности; некоторые организации выполняют отключения более регулярно, чем другие; организации используют аппаратное обеспечение разных стоимости, качества и надежности.
Расположение реплик
Решение о том, где разворачивать процессы, которые составляют кластер консенсуса, принимается на основе двух факторов: компромисса между областями отказов, которые система должна обработать, и требований к задержке для системы. На определение расположения реплик влияет множество сложных моментов.
Область отказов является набором компонентов системы, который может стать недоступным в результате одного сбоя. Примеры областей отказов:
• физическая машина;
• стойка дата-центра, которую обслуживает один источник питания;
• несколько стоек дата-центра, которые обслуживает один элемент сетевого оборудования;
• дата-центр, который может стать недоступным из-за того, что был перерезан оптоволоконный кабель;
• множество дата-центров в одной географической области, где произошла природная катастрофа, например ураган.
В общем, по мере увеличения расстояния между репликами увеличивается и время прохождения данных между ними, а также размер сбоя, который система сможет выдержать.
Для большинства систем, основанных на консенсусе, увеличение времени прохождения данных между репликами увеличит и задержку выполнения операций.
Влияние задержки, а также способность пережить сбой в заданной области очень зависят от системы. Архитектуры некоторых систем, основанных на консенсусе, не требуют особенно большой пропускной способности или малой задержки: например, система, которая должна предоставлять услуги по размещению членов группы и выбору лидера, скорее всего, не будет сильно загружена, и если время транзакции консенсуса составляет лишь небольшую долю времени аренды лидера, то производительность некритична.
Системы, ориентированные на пакетную обработку, также меньше зависят от задержки: для увеличения пропускной способности можно увеличить размеры пакетов.
Не всегда имеет смысл последовательно увеличивать размер области отказа, потерю которой система может пережить. Например, если все клиенты, использующие систему, основанную на консенсусе, работают внутри одной области отказа (допустим, в районе Нью-Йорка) и развертывание распределенной системы, основанной на консенсусе, на большей территории позволит ей оставаться доступной во время сбоев в этой области отказа (к примеру, вызванных ураганом «Сэнди»), будет ли оно того стоить? Наверняка нет, поскольку клиенты системы также будут отключены и система не увидит трафик. Дополнительная стоимость с точки зрения задержки, пропускной способности и вычислительных ресурсов не принесет пользы.
Вы должны учитывать необходимость восстановления после катастроф при определении места, где будут размещаться реплики: в системе, которая хранит критически важные данные, реплики консенсуса, по сути, также являются онлайн-копиями этих данных. Но когда такие данные находятся под угрозой, важно создавать их резервные копии везде, где можно, даже если устойчивые системы, основанные на консенсусе, размещены в нескольких областях отказа. Существует две области отказа, от которых вам не удастся спрятаться: само ПО и человеческие ошибки, допускаемые системными администраторами. Баги в ПО могут проявиться при неожиданных обстоятельствах и вызвать потерю данных, к подобной ситуации может привести и неверное конфигурирование системы. Люди-операторы также могут ошибаться или саботировать работу, из-за чего данные будут потеряны.
Принимая решение о размещении реплик, помните, что наиболее важной мерой производительности является восприятие клиента: в идеале время обращения клиентов к репликам системы, основанной на консенсусе, должно быть минимизировано. В широкомасштабных сетях протоколы без лидера вроде Mencius или Egalitarian Paxos могут иметь лучшую производительность, особенно если ограничения устойчивости приложения означают, что для любой реплики системы можно выполнять только операции чтения, если не выполняется операция консенсуса.
Производительность и балансировка нагрузки
При проектировании развертывания вы должны убедиться, что располагаете достаточной производительностью, способной справиться с загрузкой. В случае сегментированного развертывания можете скорректировать производительность, изменив количество сегментов. Однако в системах, которые могут выполнять чтение с членов группы консенсуса, не являющихся лидерами, вы можете повысить производительность для операций чтения, добавив дополнительные реплики. Добавление реплик имеет свою цену: в алгоритме, который задействует сильного лидера, оно повлечет за собой увеличение нагрузки на процесс лидера, а при использовании протокола взаимодействия равноправных систем увеличит нагрузку на все процессы. Если же существует резерв производительности для операций записи, но нагрузка, состоящая из таких операций, напрягает систему, добавление реплик может оказаться лучшим выходом.
Следует заметить, что добавление реплики в большинство систем кворумов может потенциально снизить доступность системы (рис. 23.10). Типичное развертывание Zookeeper или Chubby задействует пять реплик, поэтому бо'льшая часть кворумов требует наличия трех. Система все еще будет работать, если две реплики, или 40 %, недоступны. При наличии шести реплик кворум требует наличия четырех действующих: всего 33 % реплик могут быть недоступны, чтобы система продолжала работу.
Ограничения, связанные с областями отказа, становятся еще строже по мере добавления шестой реплики: если организация имеет пять дата-центров и обычно запускает группы консенсуса с пятью процессами, то потеря одного дата-центра все еще оставляет одну свободную реплику в каждой группе. Если шестая реплика развертывается в одном из пяти дата-центров, то его отключение лишает группы обеих свободных реплик, снижая этим производительность на 33 %.
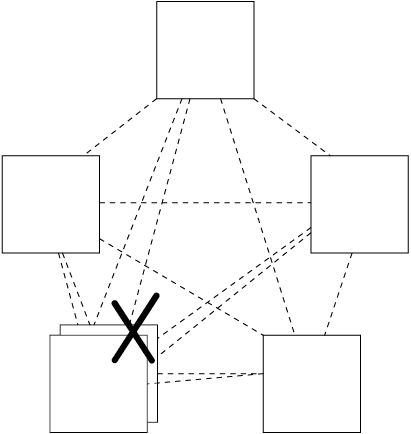
Рис. 23.10. Добавление реплики в одном регионе может уменьшить доступность системы. Совместное размещение нескольких реплик в одном дата-центре может уменьшить доступность системы: при этом существует кворум, у которого нет избыточности
Если клиенты кучно располагаются в одном географическом регионе, лучше всего разместить эти реплики ближе к ним. Однако определение того, где именно их размещать, может потребовать тщательного обдумывания балансировки нагрузки и преодоления перегрузок. Как показано на рис. 23.11, если система просто направляет запросы клиента на чтение ближайшей реплике, то большой скачок нагрузки, сконцентрированный в одном регионе, может перегрузить ближайшую реплику, затем следующую и т.д. — это называется каскадным сбоем (см. главу 22). Перегрузки такого типа зачастую возникают в начале выполнения пакетных задач, особенно одновременно нескольких.
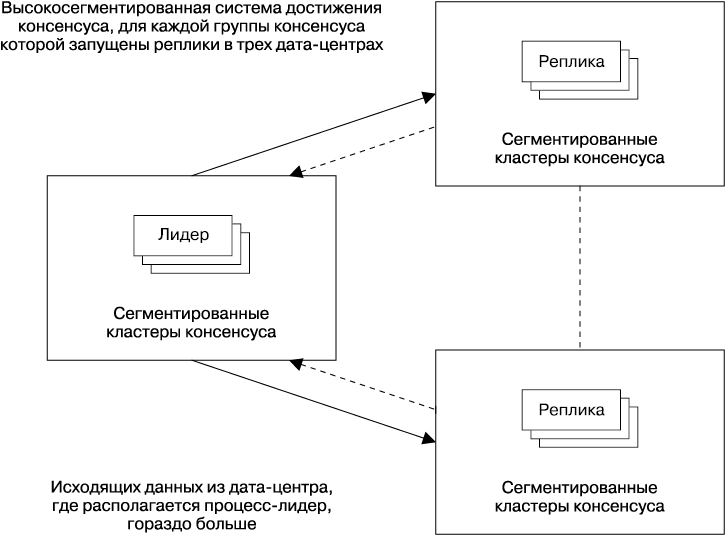
Рис. 23.11. Совместное размещение процессов-лидеров приводит к неравномерному использованию полосы пропускания
Мы уже рассмотрели причину, по которой многие системы, основанные на распределенном консенсусе, используют процесс-лидер для улучшения производительности. Однако важно понимать, что реплики-лидеры будут задействовать большее количество вычислительных ресурсов, особенно исходящую производительность сети. Это происходит потому, что лидер отправляет сообщения-предложения, который включают в себя предлагаемые данные, но реплики отправляют более мелкие сообщения, обычно содержащие лишь соглашения с идентификатором транзакции определенного консенсуса. Организации, которые запускают высокосегментированные системы консенсуса с очень большим количеством процессов, могут посчитать необходимым гарантировать, что процессы-лидеры для разных сегментов относительно равномерно распределены между дата-центрами. Это позволяет предотвратить ситуацию, когда система как единое целое становится узким местом для исходящей производительности сети лишь для одного дата-центра, и позволяет гораздо лучше использовать производительность системы.
Еще одним недостатком размещения групп консенсуса в разных дата-центрах (см. рис. 23.11) является экстремальное изменение системы, которое может произойти, если дата-центр, в котором находятся лидеры, испытает масштабный сбой (например, произойдет отключение питания, поломка сетевого оборудования или будет перерезан провод). При таком сценарии сбоя все лидеры должны переключиться на другой дата-центр, либо разделившись поровну, либо массово направившись в один дата-центр (рис. 23.12). В любом случае узел, расположенный между двумя другими дата-центрами, получит гораздо больше трафика от этой системы. В этот момент меньше всего хочется обнаружить, что производительности этого узла недостаточно.
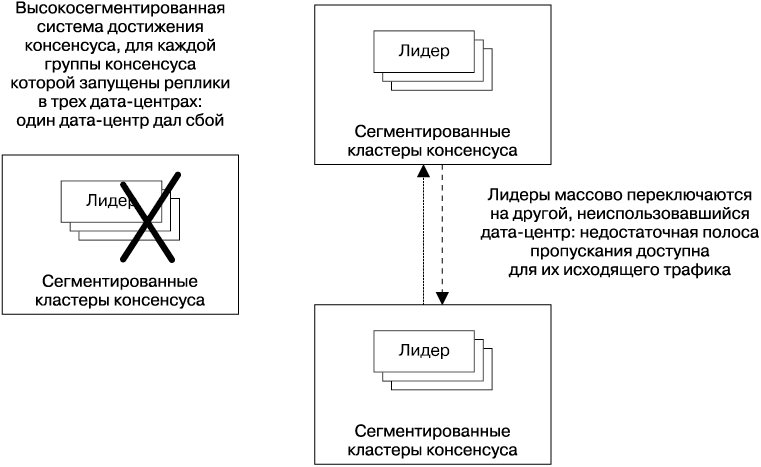
Рис. 23.12. Когда совместно размещенные лидеры массово переключаются на другой дата-центр, шаблоны использования сети могут значительно измениться
Однако такой тип развертывания легко может оказаться непредусмотренным результатом протекающих в системе автоматических процессов, которые влияют на выбор лидеров, например.
• Любые операции, обрабатываемые лидером, будут протекать с меньшей задержкой, если он располагается очень близко к клиентам. Алгоритм, который пытается расположить лидеров рядом с большинством клиентов, может этим воспользоваться.
• Алгоритм может попытаться определить местоположение лидеров на машинах с наилучшей производительностью. Ловушка, связанная с этим подходом, заключается в том, что если один из трех дата-центров имеет более быстрые машины, то ему будет отправлено непропорциональное количество трафика, что приведет к экстремальным изменениям уровня последнего, если дата-центр станет недоступным. Для того чтобы избежать этой проблемы, алгоритмы должны учитывать возможности машин при их выборе.
• Алгоритм выбора лидера может отдавать предпочтение процессам, которые работают дольше. Более долгоиграющие процессы с большей вероятностью будут связаны с местоположением, если релизы ПО будут выполняться для каждого дата-центра.
Композиция кворумов
При определении расположения реплик в группе консенсуса важно учитывать эффект географического распределения (или, точнее, сетевые задержки между репликами), который будет влиять на производительность группы.
Одним из подходов является максимально равномерное распределение реплик, чтобы RTT для них были примерно равными. Если равными будут и все прочие факторы, такие как нагрузка, аппаратная часть и производительность сети, это даст относительно стабильное значение производительности для всех регионов независимо от того, где находится лидер группы (или для каждого члена группы консенсуса, если используется протокол без лидера).
География может значительно усложнить применение этого подхода. Это особенно верно при сравнении внутриконтинентального трафика и трафика, пересекающего Тихий или Атлантический океан. Рассмотрим систему, которая охватывает Северную Америку и Европу: невозможно расположить реплики равноудаленно друг от друга, поскольку всегда будет существовать увеличение задержки для трансатлантического трафика по сравнению с внутриконтинентальным. Несмотря ни на что, транзакции из одного региона должны будут пересечь океан, для того чтобы достичь консенсуса.
Однако, чтобы попытаться распределить трафик максимально равномерно, проектировщики систем могут выбрать следующий вариант размещения пяти реплик: две в центре Соединенных Штатов, одна на Восточном побережье и две в Европе (рис. 23.13). Такое распределение будет означать, что в типичном случае консенсуса можно достичь в Северной Америке, не дожидаясь ответа реплик из Европы, а если консенсуса нужно достичь из Европы, общаться нужно будет только с репликой, расположенной на побережье. Реплика, размещенная на Восточном побережье, выступает своего рода связующим звеном, где пересекаются два возможных кворума.
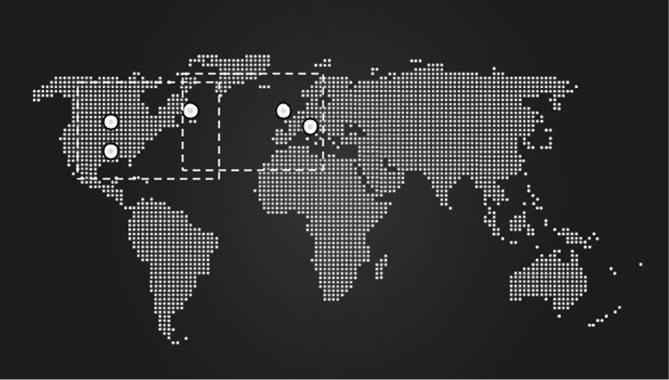
Рис. 23.13. Пересечение кворумов, где одна реплика играет роль связующего звена
Потеря этой реплики означает, что задержка системы значительно увеличится: вместо того чтобы сильно зависеть от RTT либо между центром США и Восточным побережьем, либо между Восточным побережьем и Европой, она будет основана на RTT между Европой и центром США (рис. 23.14) и окажется на 50 % выше, чем задержка, основанная на RTT между Европой и Восточным побережьем. Географическая дистанция и RTT между ближайшим возможным кворумом значительно увеличиваются.
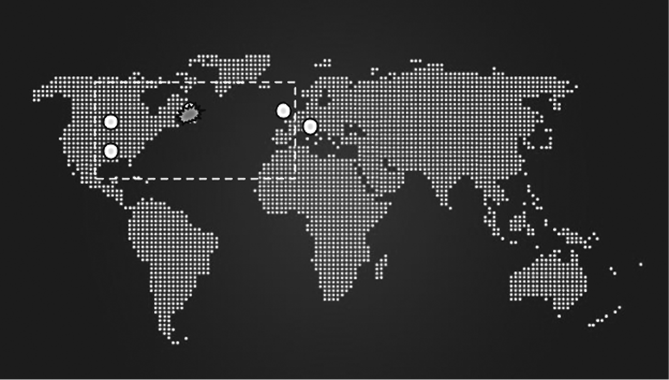
Рис. 23.14. Потеря связующей реплики немедленно приводит к повышению RTT для любого кворума
Этот сценарий является основным слабым местом простого кворума большинства, когда он применим к группам, состоящим из реплик, имеющих различающиеся RTT. В таких случаях может оказаться полезным иерархический подход сборки кворума. Десять реплик могут быть развернуты в трех группах по три реплики (рис. 23.15). Кворум может быть сформирован по принципу большинства групп, и группа может быть включена в кворум, если доступна большая часть ее членов. Это означает, что даже потеря реплики центральной группы не повлияет на общую производительность системы, поскольку центральная группа все еще может голосовать за транзакции с помощью двух и трех реплик. Существует, однако, проблема расхода ресурсов, связанная с запуском большего количества реплик. В высокосегментированной системе с нагрузкой, состоящей из операций чтения, которая качественно обрабатывается репликами, мы можем справиться с этой проблемой, используя меньшее количество групп консенсуса. Такая стратегия означает, что общее количество процессов в системе не изменится.
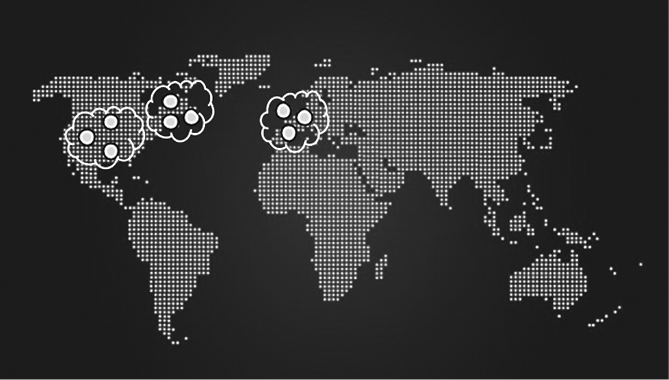
Рис. 23.15. Иерархические кворумы могут быть применены для снижения зависимости от центральной реплики
Наблюдение за распределенными системами, основанными на консенсусе
Как мы уже видели, алгоритмы достижения распределенного консенсуса лежат в основе большинства критически важных систем компании Google ([Ananatharayan, 2013], [Burrows, 2006], [Corbett, 2012], [Shute, 2013]). Все важные производственные системы нуждаются в наблюдении для того, чтобы обнаруживать отключения или проблемы, а также для поиска проблем. Опыт показывает, что существуют некоторые аспекты распределенных систем, основанных на консенсусе, которым требуется особое внимание. Давайте их рассмотрим.
• Количество членов, запущенных в каждой группе консенсуса, и состояние каждого процесса (работоспособный или нет). Процесс может быть запущен, но по какой-то причине, например связанной с аппаратной частью, не способен развиваться.
• Постоянно отстающие реплики. Работоспособные члены группы консенсуса могут находиться в разных состояниях. Член группы может находиться в состоянии восстановления, выполняемого с помощью одноранговых узлов после запуска, или отставать от группы кворума, или полноценно участвовать в работе, или быть лидером.
• Существует лидер или нет. Необходимо контролировать систему, основанную на алгоритме вроде Multi-Paxos, который берет на себя роль лидера. Важно гарантировать, что лидер существует, поскольку, если у системы нет лидера, она будет недоступна.
• Количество смен лидера. Многократная быстрая смена лидера снижает производительность систем, основанных на консенсусе, которые используют стабильного лидера, поэтому нужно следить за количеством смен лидера. Алгоритмы консенсуса зачастую помечают изменение лидерства с помощью нового срока или номера представления, это число является полезным показателем для наблюдения. Слишком быстрое увеличение частоты смены лидера может быть связано с проблемой с сетевым соединением. Снижение частоты может указывать на серьезную ошибку.
• Номер транзакции консенсуса. Операторам нужно знать, продвигается ли работа в системе, основанной на консенсусе. Большинство алгоритмов достижения консенсуса обозначают прогресс, увеличивая номер транзакции консенсуса. Если система работоспособная, этот номер должен увеличиваться с течением времени.
• Видимое количество предложений; количество предложений, с которыми согласились. Эти числа показывают, корректно ли работает система.
• Пропускная способность и латентность. Несмотря на то что эти характеристики свойственны не только для распределенных систем, администраторы должны следить за ними.
Для того чтобы понять, какова производительность системы, и упростить поиск связанных с ней проблем, вы можете наблюдать:
• за распределением задержки для принятия предложений;
• распределением сетевых задержек, наблюдаемых между частями системы в разных локациях;
• количеством времени, которое приемники потратили на долговечное журналирование;
• общим количеством байтов, полученных системой за секунду.
Итоги главы
Мы рассмотрели задачу распределенного консенсуса и представили некоторые типовые архитектурные решения для систем, основанных на распределенном консенсусе, а также обсудили вопросы производительности и некоторые эксплуатационные аспекты для таких систем.
В рамках этой главы мы намеренно избегали глубокой дискуссии о конкретных алгоритмах, протоколах и реализациях. Средства координирования распределенных систем и технологии, лежащие в их основе, меняются быстро, и эта информация очень скоро устареет, в отличие от основ, которые мы рассмотрели. А эти основы наряду с упомянутыми в главе статьями позволят вам применять как инструменты распределенного координирования, доступные сегодня, так и ПО, которое появится в будущем.
Если вы не запомните ничего другого из этой главы, не забывайте хотя бы о проблемах, которые могут быть решены с помощью распределенного консенсуса, и о тех проблемах, которые могут появиться при использовании ситуационных методов управления наподобие контрольных сигналов. Когда вы встретите ситуацию выбора лидера, критическое разделяемое состояние или распределенные блокировки, вспомните о распределенном консенсусе: любой другой подход будет напоминать бомбу с часовым механизмом, готовую разрушить ваши системы.
Кайл Кингсберри написал большую серию статей о корректности распределенных систем, которая содержит множество примеров неожиданного или некорректного поведения хранилищ данных такого вида. См. .
В частности, производительность оригинального алгоритма Paxos неидеальна, но она значительно улучшилась с течением времени.

